文章目录
- 摘要
- abstract
- 一、智能体强化学习
- [1.1工业级 Agent开发痛点:](#1.1工业级 Agent开发痛点:)
-
- [1.2 Agentic RL 核心](#1.2 Agentic RL 核心)
- [1.3 微软 Agent-Lightning 框架详解:](#1.3 微软 Agent-Lightning 框架详解:)
- [二、Clip-《Learning Transferable Visual Models From Natural Language Supervision》](#二、Clip-《Learning Transferable Visual Models From Natural Language Supervision》)
-
- [2.1 模型架构,双编码器结构:](#2.1 模型架构,双编码器结构:)
- 2.2零样本迁移
- 2.3零样本迁移广泛分析CLIP的任务学习能力:
- 2.4优缺点
- 三、实践------使用Clip进行零样本迁移
- 总结
摘要
本周学习智能体强化学习(Agentic RL)与视觉语言预训练模型CLIP的应用。Agentic RL通过"决策-反馈-改进"闭环实现智能体自主迭代,解决工业级Agent开发的成本-效率平衡难题,并结合微软Agent-Lightning框架和GRPO算法提升小模型工具调用准确率与泛化能力。另一方面,CLIP利用大规模图文对训练,通过对比学习实现零样本迁移,在CIFAR-10等任务上展现强大泛化性能,同时分析了其依赖提示工程、存在数据偏见等局限性。展示了通过动态学习与大规模预训练推动AI系统自适应演进的重要方向。
abstract
This week, I studied the application of Agentic Reinforcement Learning (ARRL) and the visual-language pre-trained model CLIP. Agentic RL achieves autonomous iteration of agents through a closed-loop "decision-feedback-improvement" process, solving the cost-efficiency balance challenge in industrial-grade agent development. It also improves the accuracy and generalization ability of small models by combining the Microsoft Agent-Lightning framework and the GRPO algorithm. On the other hand, CLIP utilizes large-scale image-text pairs for training and achieves zero-shot transfer learning through contrastive learning, demonstrating strong generalization performance on tasks such as CIFAR-10. However, we also analyzed its limitations, including reliance on cue engineering and data bias. This demonstrates an important direction for promoting the adaptive evolution of AI systems through dynamic learning and large-scale pre-training.
一、智能体强化学习
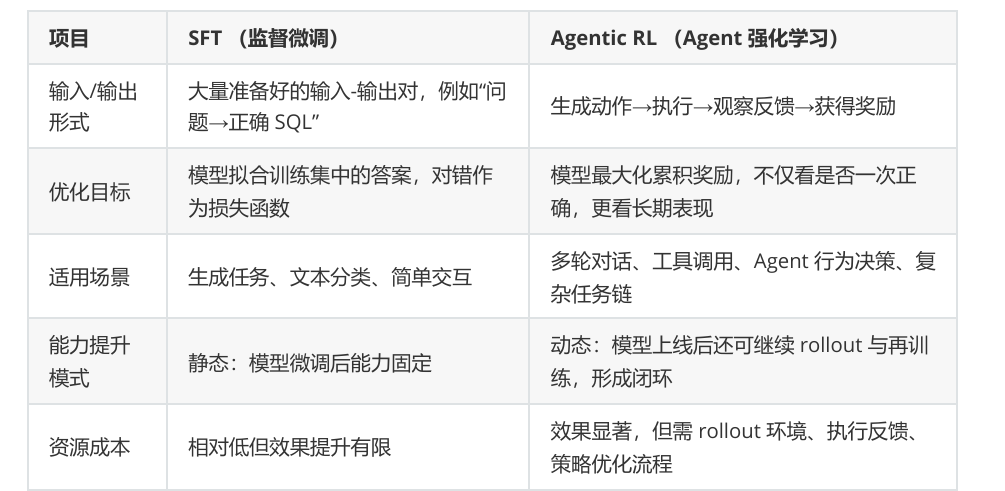
Agentic RL(智能体强化学习) ,聚焦工业级 Agent 开发的成本 - 效率平衡难题,解释了概念、训练框架、微软 Agent-Lightning 实战流程及 SQL Agent 落地,核心是通过 "行为 - 反馈 - 优化" 闭环实现智能体自主迭代。
1.1工业级 Agent开发痛点:
强模型:性能强但部署成本高、数据隐私风险大。
轻量模型:部署高效但复杂任务能力弱、泛化差。
垂域训练 / SFT:垂域训练成本高,SFT 静态学习,缺乏自主纠错与迭代能力。
1.2 Agentic RL 核心
将强化学习(RL)应用于智能体,通过 "生成→执行→反馈→奖励→策略优化" 闭环,实现 Agent 自主学习、持续迭代。
与 SFT 的核心区别:SFT 依赖固定输入 - 输出对,静态;
Agentic RL 动态学习,关注长期累积奖励,适合多轮交互、工具调用等复杂场景。
核心优势:提升小模型工具调用准确率、降低训练成本、支持部署后持续优化。
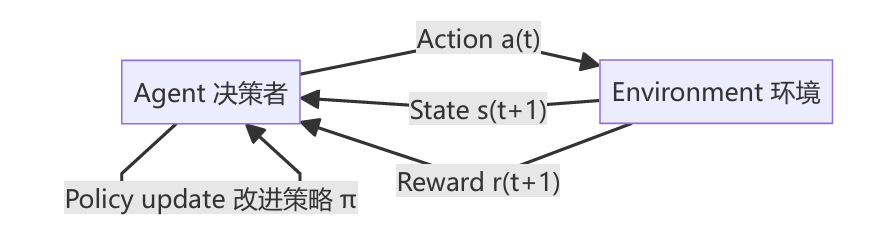
决策---反馈---改进的闭环。在每个时间步 t,智能体依据状态 s(t) 选动作 a(t),环境返回新状态 s(t+1) 与奖励 r(t+1);智能体据此更新策略 π,让自己在未来获得更高的总收益。整个学习过程并不是"先学完再用",而是一边行动、一边吃反馈、一边变更好。
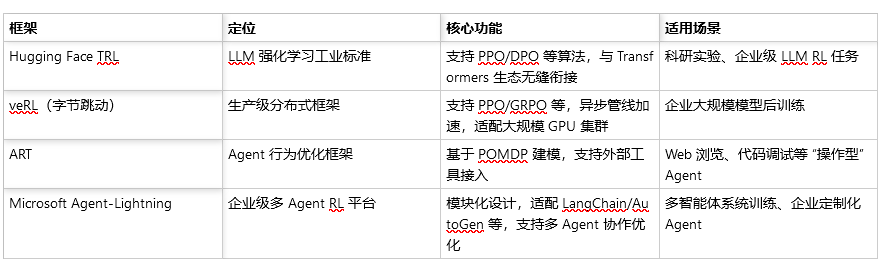
常见的强化学习+AI框架:
1.3 微软 Agent-Lightning 框架详解:
两大核心模块:
- 运行模块(Agent 运行脚本):
该部分由 LangGraph 构建的 SQL-Agent 负责,实现从自然语言问题到 SQL 执行结果的完整推理流程。模块重点在于如何让 Agent 具备可观测、可追踪的行为,从而为后续强化学习提供高质量的数据轨迹。 - 训练模块(Agent 训练脚本):
这一部分主要依托 Agent-Lightning 框架与 veRL 训练系统完成。作用是利用运行模块产生的行为轨迹,对底层基座模型进行基于 GRPO 算法的优化,从而实现策略提升与能力迁移。
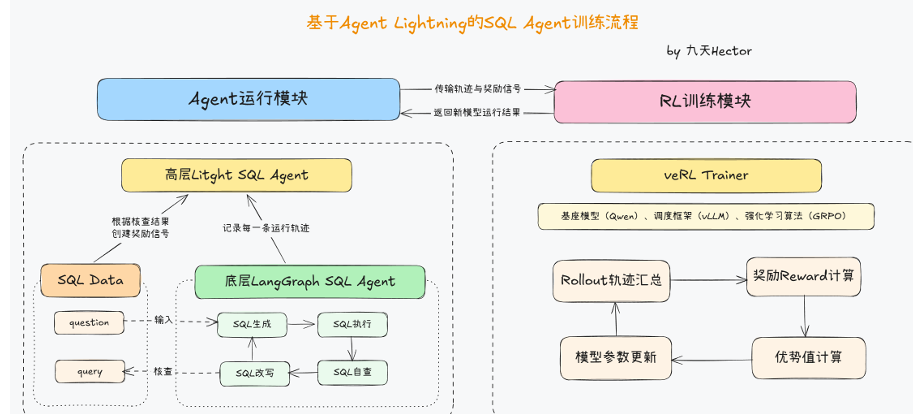
1.运行模块专注于生成和记录,训练模块专注于分析与更新,两者之间通过轨迹数据(trajectory)和奖励信号(reward signal)进行衔接。换言之,运行脚本产出数据,训练脚本消化数据。
设计逻辑
核心思想是:将 Agent 的推理过程抽象为一张有向图,每一个节点代表 Agent 的一个关键步骤,而节点之间的边则代表决策路径或执行顺序。
在一次运行中可能经历多个"生成-执行-反馈"循环,从而体现出自我纠错的特征。,LangGraph 天然支持状态持久化与轨迹记录。每一次执行、判断与重写都会被记录为一条"状态-动作-反馈"数据,这正是强化学习算法所需要的经验数据。
2.中间封装逻辑:
- 轨迹采集:每次 Agent 执行过程中自动记录输入问题、生成的 SQL、执行结果、反馈内容及执行日志。这些轨迹数据被打包成 rollout 样本,供后续 RL 算法使用。
2.奖励信号传递:运行脚本在每次 Agent 完成一个任务后,会调用 evaluate_query 函数对结果进行评分。若生成的 SQL 与标准答案一致(或执行结果正确),则 reward = 1;否则 reward = 0。这一奖励信号是 GRPO 算法计算梯度的重要依据。
3.可扩展接口:Agent-Lightning 在运行层面提供了标准化接口,使得训练模块可以直接通过 rollout 调用 Agent 执行。例如,在 train 脚本中可以统一调用 agent.rollout(task, resources, rollout) 而不必关心 Agent 内部结构。解耦式设计可以轻松替换 Agent 或模型。
3.训练模块:基于 veRL 的 GRPO 强化学习逻辑(veRL 字节跳动开源的强化学习训练框架,支持多种算法,包括 PPO、DPO、GRPO 等)
train 脚本主要通过 veRL 调用 GRPO 算法来实现训练:
- 1.Rollout 阶段:每个 Agent 根据当前模型策略生成 SQL 、执行、反馈,形成 rollout 轨迹。
-
- Reward 计算:训练器调用 evaluate_query 对每个 Agent 的输出进行评分。若执行结果正确,则给出正向奖励,否则为 0。所有样本的 reward 值将与模型生成的 log prob 概率一同送入 GRPO 优化器。
-
- Advantage 估计与策略更新:GRPO 算法根据组内样本的相对表现计算 advantage(优势函数),不依赖额外 critic 网络。表现较优的样本获得更大权重,劣质样本权重降低,从而实现"优胜劣汰"的参数更新。
-
- 参数同步与保存:训练器更新模型参数后,会定期保存检查点(checkpoint),供下一轮 rollout 使用。新参数会替换旧参数,使下一轮 Agent 行为更优。
关键:
强化学习核心:决策 - 反馈 - 改进闭环,通过累积奖励优化策略。
GRPO 算法:无需 critic 网络,基于组内样本相对表现更新参数,适配 LLM 训练。
泛化能力提升:通过 "执行反馈" 学习任务底层规律,而非死记训练数据。
迁移性:相同架构可迁移至数据分析、检索问答等多类型 Agent。
总结:Agent 任务中,模型的核心价值不再是"回答正确",而是"完成任务"。而 Agentic RL 的动态学习机制符合这一逻辑,通过执行与反馈的循环,让 Agent 逐渐学习如何在复杂任务链中实现目标。
二、Clip-《Learning Transferable Visual Models From Natural Language Supervision》
实验内:利用互联网上大规模的(图像,文本)对,通过对比学习的方式,训练一个通用视觉模型,使其能通过自然语言提示(prompt) 实现零样本迁移(zero-shot transfer) 到任意下游视觉任务。
注:主要点在于,利用大模型的自然语言处理匹配一句描述图片的话与图片形成映射,来训练,然后零样本迁移(使用语言定义分类器)。
创新点在于:
预训练任务简单但有效:预测一批(图像,文本)对中哪些是真实配对(即图文匹配),而非生成文本或分类固定类别。
零样本能力:无需任何下游任务的训练数据,仅通过类别的自然语言描述(如 "a photo of a dog")即可构建分类器。
规模效应:在4亿对图文数据上训练,模型性能随计算量平滑提升,最大的 ViT-L/14@336px 模型在 ImageNet 上零样本准确率达 76.2%,媲美有监督 ResNet-50。
泛化能力强:在30+个不同任务(OCR、动作识别、地理定位、细粒度分类等)上表现稳健,尤其在自然分布偏移下比传统 ImageNet 模型更鲁棒。
训练数据集:WIT(WebImageText)
规模:4亿个(图像,文本)对,公开网络数据,通过50万个关键词(来自 Wikipedia + WordNet + 高频 n-gram)搜索构建。
平衡策略:每个关键词最多采样2万对,避免长尾分布。
文本形式:标题、描述、标签等原始文本,保留自然语言多样性。
评估数据集(30+个)
通用分类:ImageNet、CIFAR、STL-10、Caltech101 等
细粒度分类:Stanford Cars、Flowers102、FGVC Aircraft
视频动作识别:UCF101、Kinetics-700、RareAct
OCR 任务:MNIST、SVHN、Rendered SST2、Hateful Memes
地理定位:Country211(新构建)、IM2GPS
鲁棒性测试:ImageNet-V2、ObjectNet、ImageNet-Sketch 等7个自然分布偏移数据集。
因为要进行零样本迁移,数据量很大,然后为例分析性能,有需要与很多已有的实验进行比较(实验采用了不同的数据集合)。零样本迁移:用自然语言描述构建分类器
2.1 模型架构,双编码器结构:
图像编码器:ResNet(改)或 Vision Transformer (ViT)
文本编码器:Transformer(类似 GPT-2,使用 BPE 分词,vocab=49,152)
多模态嵌入空间:两个编码器输出通过线性投影映射到同一维度的 L2 归一化向量空间。
预训练方法:
最开始考虑的是预测目标与图片配对,但效果很差,转换将预测目标替换为对比目标,观察到在向ImageNet零样本迁移的速率上,效率进一步提高了4倍。
给定一批N个(图像,文本)对,CLIP被训练来预测这批数据中N×N种可能的(图像,文本)配对中哪些是真实发生的。
CLIP通过联合训练一个图像编码器和一个文本编码器来学习一个多模态嵌入空间,以最大化批次中N个真实配对的图像和文本嵌入的余弦相似度,同时最小化N²−N个错误配对的嵌入的余弦相似度。在这些相似度得分上优化一个对称的交叉熵损失。

使用一个线性投影将每个编码器的表示映射到多模态嵌入空间。(推测非线性投影可能与当前仅使用图像的自监督表示学习方法的细节共同适应)。
图像编码器考虑了两种不同的架构。第一种,使用ResNet-50作为图像编码器的基础架构,使用ResNet-D和抗锯齿rect-2模糊池化对原始版本进行了几项修改,将全局平均池化层替换为注意力池化机制。第二种,Transformer(ViT),在Transformer之前为组合的patch和位置嵌入添加了一个额外的层归一化,并使用略有不同的初始化方案。
文本编码器是一个Transformer,修改基础尺寸,使用一个6300万参数的12层、512维宽、8个注意力头的模型。该Transformer在一个小写的字节对编码(BPE)文本表示上运行,词汇表大小为49,152。最大序列长度被限制在76。文本序列用SOS和EOS标记括起来,Transformer在EOS标记处最高层的激活被视为文本的特征表示,该表示经过层归一化后线性投影到多模态嵌入空间。
扩展模型:图像编码器同等增加模型的宽度、深度和分辨率。对于文本编码器,只按比例扩展模型的宽度(与ResNet计算量增加所对应的宽度增加成比例),而完全不扩展深度(实验发现CLIP的性能对文本编码器的容量不太敏感)。
训练一系列5个ResNet和3个视觉Transformer。对于ResNet,训练了一个ResNet-50、一个ResNet-101,然后又训练了3个遵循EfficientNet式模型扩展的模型,其计算量分别约为ResNet-50的4倍、16倍和64倍。它们分别被记为RN50x4、RN50x16和RN50x64。对于视觉Transformer,训练了ViT-B/32、ViT-B/16和ViT-L/14。对所有模型都训练了32个轮次。
使用Adam优化器,对所有非增益(gain)或偏置(bias)的权重应用解耦权重衰减正则化,使用余弦调度(Loshchilov & Hutter, 2016)衰减学习率。
初始超参数是通过对基线ResNet-50模型在1个轮次训练时进行网格搜索、随机搜索和手动调整的组合来设定的。
然后,由于计算资源的限制,启发式地为更大的模型调整了超参数。可学习的温度参数τ被初始化为Wu等人(2018)中的等效值0.07,并被裁剪以防止logits缩放超过100(实验发现这对于防止训练不稳定是必要的)。使用了非常大的小批量(minibatch)尺寸32,768。
2.2零样本迁移
非零样本迁移多义性:缺乏上下文,无法区分词的哪种含义。
预训练数据集中,与图像配对的文本很少只是一个单词。文本是一个完整句子,以某种方式描述图像。使用提示模板"A photo of a {label}."(一张{label}的照片)是一个很好的默认选择,有助于指定文本是关于图像内容的,比仅使用标签文本的基线表现更好。
提示工程:实验发现在几个细粒度图像分类数据集上,指定类别是有帮助的,如宠物,数据集,飞机类型...。尝试对多个零样本分类器进行集成:分类器是通过使用不同的上下文提示计算得出的,提示工程和集成将ImageNet的准确率提高了近5%。
2.3零样本迁移广泛分析CLIP的任务学习能力:
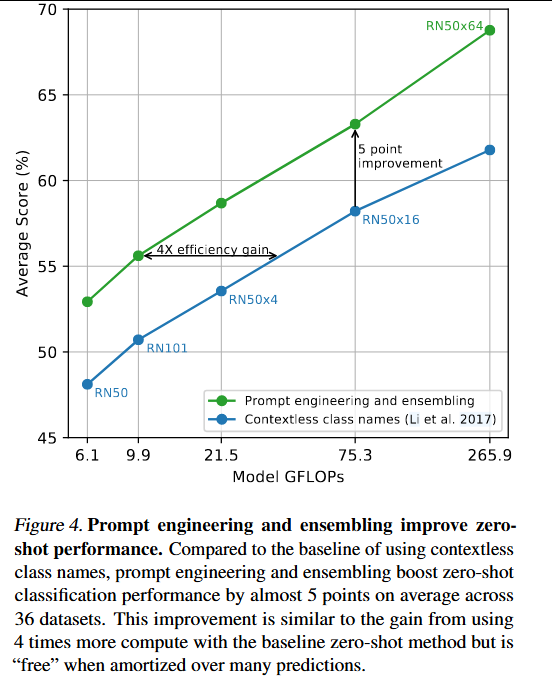
可视化提示工程和集成改变一组CLIP模型的性能。
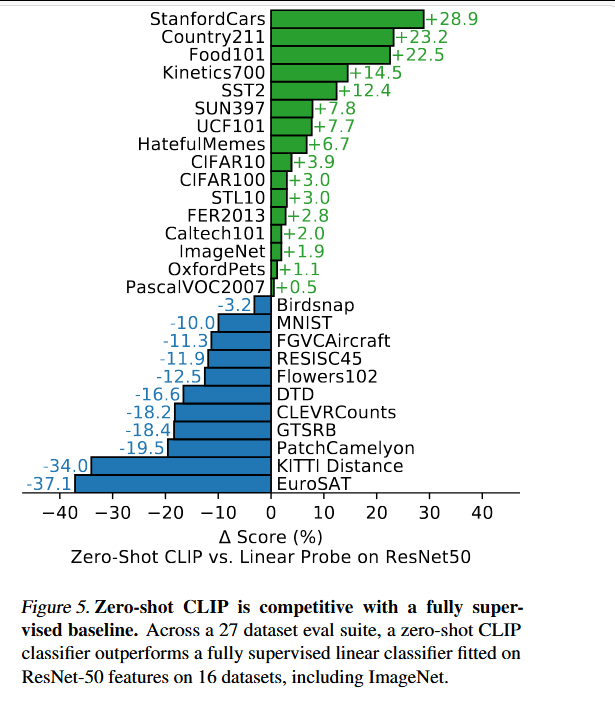
对CLIP的零样本分类器的各种属性进行了研究。
简单的现成基线进行比较:在标准ResNet-50的特征上拟合一个全监督、正则化的逻辑回归分类器。
零样本CLIP略多地优于这一基线,并在27个数据集中的16个上获胜。
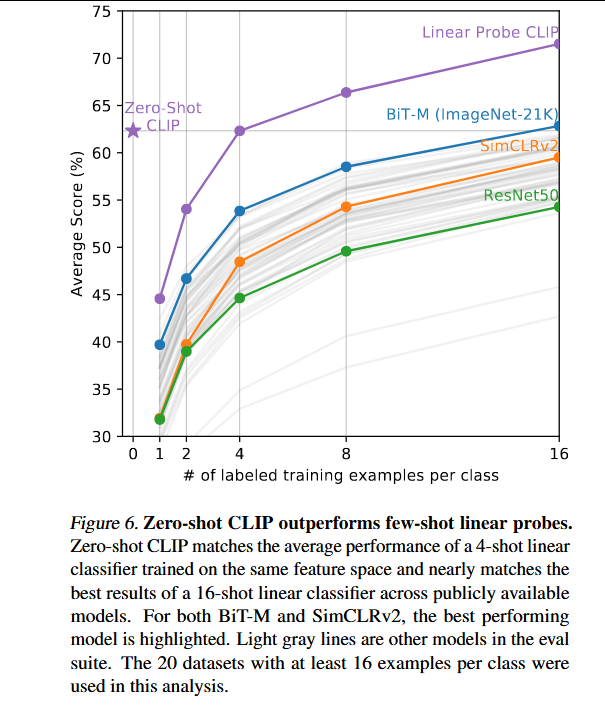
与少样本方法进行比较:预计零样本会比单样本表现差,但发现零样本CLIP与在同一特征空间上训练的4样本逻辑回归的性能相当。
CLIP的零样本分类器是通过自然语言生成的,这允许直接指定("传达")视觉概念。
相比之下,"正常"的监督学习必须从训练样本中间接推断概念。无上下文的基于示例的学习有一个缺点------许多不同的假设都可以与数据一致,尤其是在单样本情况下。单张图像通常包含许多不同的视觉概念。
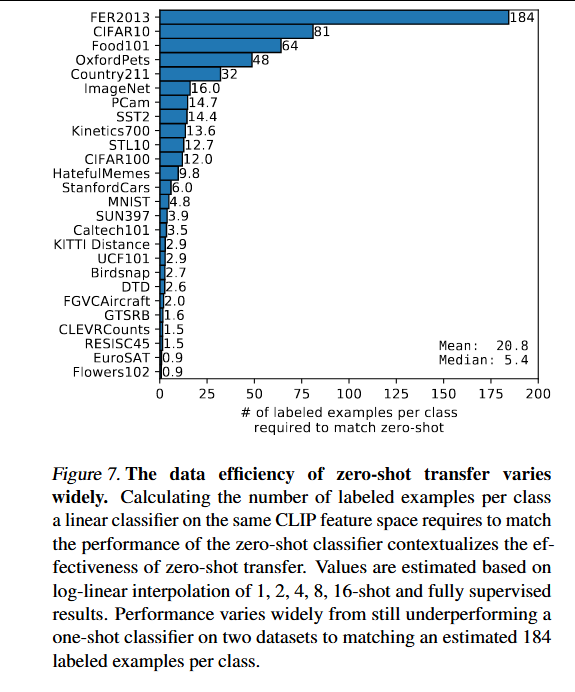
训练的逻辑回归分类器需要多少个每类标注样本才能匹配零样本CLIP的性能。
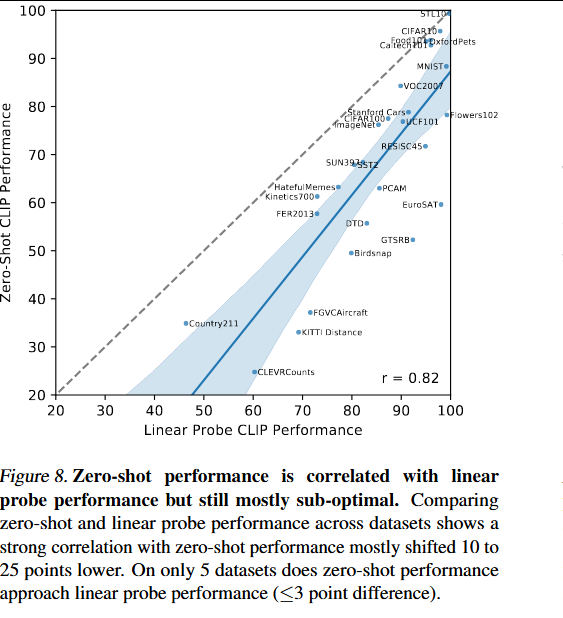
将CLIP的零样本性能与全监督线性分类器在各个数据集上的性能进行了比较。虚线y=x代表一个"最优"的零样本分类器,其性能与其全监督等效物相匹配。对于大多数数据集,零样本分类器的性能仍然比全监督分类器低10%到25%,这表明CLIP的任务学习和零样本迁移能力仍有很大的提升空间。
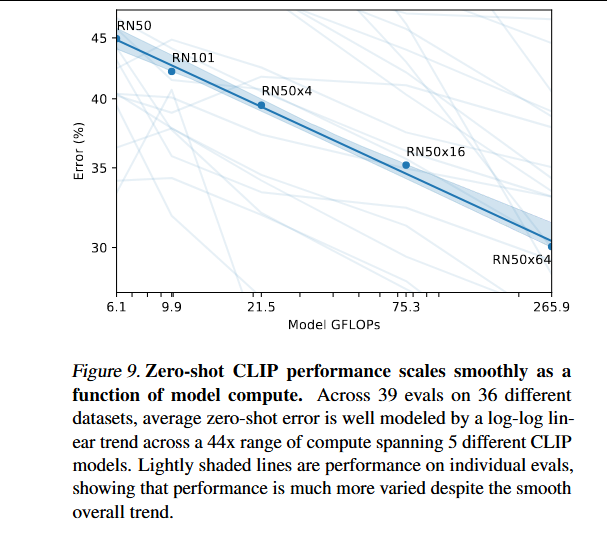
检查CLIP的零样本性能是否遵循类似的缩放模式。在36个不同数据集的39次评估中绘制了5个ResNet CLIP模型的平均错误率,发现一个类似的对数-对数线性缩放趋势在44倍的模型计算量范围内适用于CLIP。
尽管总体趋势是平滑的,但单个评估的性能可能会嘈杂得多。不确定这是由子任务的个别训练运行之间的高方差掩盖了稳步改善的趋势,还是性能实际上在某些任务上是计算量的非单调函数。
2.4优缺点
优点
- 零样本迁移能力强:无需任何下游任务的训练数据,仅通过自然语言提示(如 "a photo of a dog")即可对新类别进行分类。在 ImageNet 上达到 76.2% 零样本准确率,媲美有监督 ResNet-50。
- 通用性强,支持任意文本定义的类别:用户可"自定义分类器",例如识别"小偷"、"卫星图中的机场"等非标准类别,无需重新训练。支持细粒度、抽象或跨模态任务(如 OCR、动作识别、地理定位)。
- 大规模预训练带来强泛化能力:在 4 亿个网络图文对上训练,覆盖广泛视觉概念。对自然分布偏移(如 ObjectNet、ImageNet-Sketch)表现出比传统 ImageNet 模型更高的鲁棒性。
- 统一的多模态嵌入空间:图像和文本被映射到同一语义空间,支持图文检索、跨模态搜索等应用。
可用于图像→文本、文本→图像的双向检索。 - 可扩展性好:性能随模型规模(计算量)平滑提升,ViT-L/14@336px 是当前最强公开版本之一。
支持 Vision Transformer 和 ResNet 两种主干网络。
缺点
- 对未见/低频概念表现差:若预训练数据中缺乏某类样本(如手写数字 MNIST),性能可能接近随机。在抽象任务(如计数、逻辑推理)上表现薄弱。
- 依赖高质量提示工程(Prompt Engineering):零样本性能高度依赖文本提示的设计。多义词(如 "crane" 可指起重机或鹤)易导致混淆。
- 存在社会偏见(Bias):会继承互联网数据中的性别、种族等偏见(如将黑人误判为"大猩猩",年轻人误判为"罪犯")。类别设计不当可能放大有害输出。
- 计算与数据效率低:需要数十亿级图文对和大量算力(RN50x64 训练需 592×V100×18 天)。相比自监督方法(如 SimCLR、MoCo),数据利用效率较低。
5.少样本性能差:零样本性能有时优于 1~2 样本微调,说明其未充分利用少量标注数据。与人类学习方式差距大(人类看一个例子就能显著提升)。
三、实践------使用Clip进行零样本迁移
之前使用的CNN跑的CIFAR-10数据分类结果:
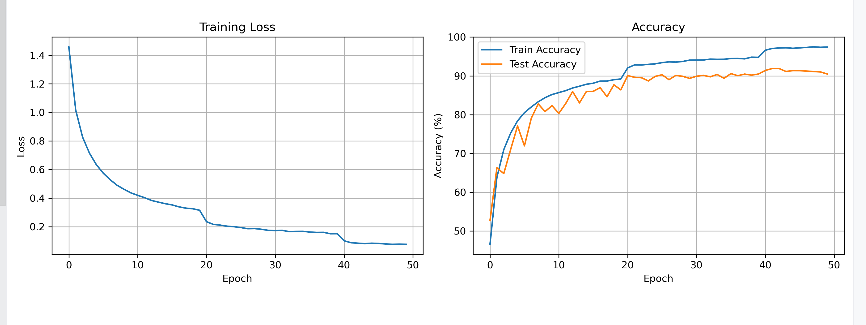
采用clip零样本的结果:
j
from torchvision.datasets import CIFAR10
from torchvision import transforms
from torch.utils.data import DataLoader
import os
def get_cifar10_loader(batch_size=32, split="test"):
# 替换为你本地cifar-10-batches-py的上级目录
data_root = r"D:\myenv1_PyCharm_code\CNN\CIFAR-10_1\data"
# 确定训练/测试集
is_train = (split == "train")
# 修正预处理:仅保留ToTensor和Resize(CLIP processor自动归一化)
preprocess = transforms.Compose([
transforms.ToTensor(), # 输出[0,1]范围的张量(C,H,W)
# 匹配CLIP训练时的插值方式
transforms.Resize((224, 224), interpolation=transforms.InterpolationMode.BICUBIC)
])
# 加载本地CIFAR-10(download=False:本地已有数据)
dataset = CIFAR10(
root=data_root,
train=is_train,
download=False,
transform=preprocess
)
# CIFAR-10固定类别名
class_names = [
"airplane", "automobile", "bird", "cat", "deer",
"dog", "frog", "horse", "ship", "truck"
]
# 创建DataLoader
loader = DataLoader(dataset, batch_size=batch_size, shuffle=False)
return loader, class_names
j
from transformers import CLIPProcessor, CLIPModel
import torch
from PIL import Image
import numpy as np
class CLIPZeroShotClassifier:
def __init__(self, model_name="openai/clip-vit-base-patch32", device="cuda"):
self.device = device
# 加载模型并强制32位精度(匹配输入)
self.model = CLIPModel.from_pretrained(model_name).to(device).float()
self.processor = CLIPProcessor.from_pretrained(model_name)
self.model.eval() # 评估模式,关闭dropout
def encode_images(self, images):
"""将PyTorch张量转PIL图像,用CLIP processor处理"""
# 1. 确保输入是32位浮点数([0,1]范围)
images = images.float() # shape: [batch, 3, 224, 224]
# 2. 转成PIL图像(C,H,W → H,W,C,0-1→0-255)
pil_images = []
for img in images:
img_np = (img.permute(1, 2, 0).cpu().numpy() * 255).astype(np.uint8)
pil_images.append(Image.fromarray(img_np))
# 3. CLIP原生processor处理(自动归一化到训练参数)
inputs = self.processor(
images=pil_images,
return_tensors="pt"
).to(self.device)
with torch.no_grad(): # 关闭梯度计算,节省显存
image_embeds = self.model.get_image_features(**inputs)
# 特征归一化(CLIP要求)
return image_embeds / image_embeds.norm(dim=-1, keepdim=True)
def encode_texts(self, class_names, template="a photo of a {}"):
"""编码文本标签(适配CLIP)"""
texts = [template.format(name) for name in class_names]
inputs = self.processor(
text=texts,
return_tensors="pt",
padding=True # 自动补齐文本长度
).to(self.device)
with torch.no_grad():
text_embeds = self.model.get_text_features(**inputs)
return text_embeds / text_embeds.norm(dim=-1, keepdim=True)
def predict_with_multiple_templates(self, images, class_names):
"""多模板平均,提升准确率(核心优化)"""
# CIFAR-10适配的CLIP文本模板
templates = [
"a photo of a {}",
"a picture of a {}",
"an image of a {}",
"a photo of a {} object"
]
logits_total = 0.0
for template in templates:
text_feats = self.encode_texts(class_names, template)
image_feats = self.encode_images(images)
# 用模型自带的logit_scale(不是手动写100)
logits_total += self.model.logit_scale.exp() * image_feats @ text_feats.T
# 多模板结果平均后softmax
return (logits_total / len(templates)).softmax(dim=-1)
j
import torch
from tqdm import tqdm
from dataset import get_cifar10_loader
from model import CLIPZeroShotClassifier
def main():
# 自动选择设备(优先cuda)
device = "cuda" if torch.cuda.is_available() else "cpu"
print(f"Using device: {device}")
# 加载本地CIFAR-10测试集
test_loader, class_names = get_cifar10_loader(batch_size=64, split="test")
print(f"Classes: {class_names}")
# 加载CLIP模型(自动从国内镜像下载)
clip_classifier = CLIPZeroShotClassifier(
model_name="openai/clip-vit-base-patch32",
device=device
)
# 统计准确率
correct = 0
total = 0
# 无梯度计算,加速推理
with torch.no_grad():
for batch in tqdm(test_loader, desc="Evaluating Zero-Shot CLIP"):
# 本地数据集返回元组:(图像张量, 标签)
images = batch[0].to(device)
labels = batch[1].to(device)
# 多模板预测(核心:提升准确率)
probs = clip_classifier.predict_with_multiple_templates(images, class_names)
preds = probs.argmax(dim=-1)
# 更新统计
correct += (preds == labels).sum().item()
total += labels.size(0)
# 计算并打印准确率
accuracy = 100 * correct / total
print(f"\n✅ Zero-Shot Accuracy on CIFAR-10: {accuracy:.2f}%")
if __name__ == "__main__":
main()第一次结果不行:只有25%,原因是图像预处理流程错误导致图像严重失真,其次预处理参数 / 模板不符合 CLIP 的训练预期。

调整后:

总结
在粗略学习推荐算法后,我计划转向多模态或智能体的学习,在粗略了解后,计划接下来会学习多模态的内容,本周学的智能体强化学习上,很有启发,将强化学习的方法放在智能体的更新上,是一个现阶段增强智能体能力的重要方式,或许会在以后设计模型时采用这种方式增加模型的参数更新。多模态的学习,只是看了一篇重要的CLIP框架,了解他的基本内容,零样本的思想------使用自定义文本语言作为分类器,达到专门设计分类器的80%左右或以上的结果,感觉很强。简单跑了个关于分类CIFAR-10的代码,并采用CLIP的零样本进行了实验,性能确实差一点,但泛化更广,接下来会继续学习多模态相关的内容。