文章目录
-
- [1. 国际主流 TSDB 的三种典型路线](#1. 国际主流 TSDB 的三种典型路线)
- [2. 指标模型 vs 树形路径:在"标签自由"与"层级清晰"之间取舍](#2. 指标模型 vs 树形路径:在“标签自由”与“层级清晰”之间取舍)
-
- [2.1 国际主流的标签模型:强在灵活,弱在层级表达](#2.1 国际主流的标签模型:强在灵活,弱在层级表达)
- [2.2 IoTDB 的树形路径:优先服务"物理世界的层级"](#2.2 IoTDB 的树形路径:优先服务“物理世界的层级”)
- [3. 与大数据生态的结合:文件格式与计算引擎协同](#3. 与大数据生态的结合:文件格式与计算引擎协同)
- [4. 写入与查询路径:与云原生部署模式的契合度](#4. 写入与查询路径:与云原生部署模式的契合度)
-
- [4.1 写入路径:LSM + 压缩 + 合并](#4.1 写入路径:LSM + 压缩 + 合并)
- [4.2 查询路径:从单节点到 MPP](#4.2 查询路径:从单节点到 MPP)
- [5. 与国际 TSDB 对比时可以问的"关键问题"](#5. 与国际 TSDB 对比时可以问的“关键问题”)
- [6. 代码示例:与云原生组件的协作方式](#6. 代码示例:与云原生组件的协作方式)
-
- [6.1 SQL:以路径前缀表达工业层级](#6.1 SQL:以路径前缀表达工业层级)
- [6.2 Java:与流处理框架协同(示意)](#6.2 Java:与流处理框架协同(示意))
- [7. 总结:在全局 TSDB 谱系中理解 IoTDB 的位置](#7. 总结:在全局 TSDB 谱系中理解 IoTDB 的位置)
- 资源链接
1. 国际主流 TSDB 的三种典型路线
如果从云原生与大数据视角看现在常见的时序数据库,大致可以抽象为三类路线:
- 监控型 TSDB:以云原生监控为目标,常见于 Kubernetes/基础设施监控场景,强调标签灵活、短期数据高性能写入、与 Prometheus 生态深度集成。
- 日志/指标一体化平台:将日志、指标、追踪统一抽象,强调 schema 灵活与查询语言表达力,多用于运维平台与观测场景。
- 工业/物联网型 TSDB :更关注设备层级建模、高压缩比、边缘部署能力,以及与大数据/AI 平台的协同。
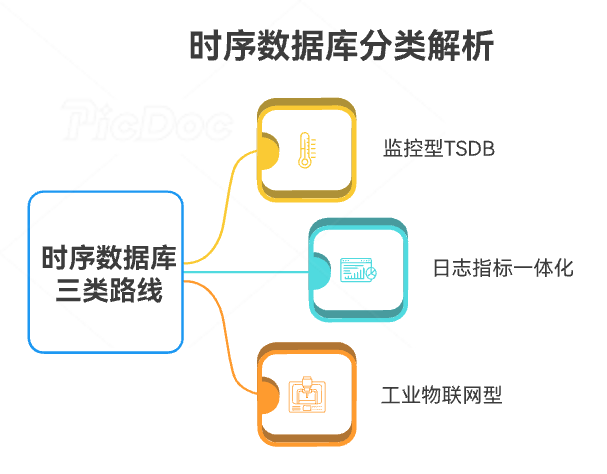
很多产品在功能上可以覆盖多类场景,但在架构决策时往往会偏向一个主场景。选型时,理解"主场景"比看功能列表更重要。
从这个视角看,Apache IoTDB 明确站在第三类:以工业/物联网场景为核心,围绕"设备层级 + 高压缩 + 端边云协同"做优化。
2. 指标模型 vs 树形路径:在"标签自由"与"层级清晰"之间取舍
2.1 国际主流的标签模型:强在灵活,弱在层级表达
监控型 TSDB 往往使用"度量名 + 标签集"的指标模型,一条时间序列可以用 metric + {tag1, tag2, ...} 来描述。这种模型在云原生监控里非常自然:
text
http_requests_total{job="api", instance="10.0.0.1:8080", method="GET"}优点是:
- 动态扩展标签字段,适配复杂部署维度
- Query 语言可以灵活组合标签条件
但对于拥有复杂物理层级的工业场景,这种表达方式需要额外维护层级信息(如 group、factory、workshop 等),往往通过标签组合来模拟,容易出现高基数问题。
2.2 IoTDB 的树形路径:优先服务"物理世界的层级"
IoTDB 的路径模型为:
text
root.group.factory.workshop.line.machine.sensor比如:
text
root.g1.plantA.wf01.line02.motor07.temperature从建模角度看,这条路径本身就承载了物理层级信息。与国际主流标签模型相比,它的取舍是:
- 少了一部分"标签任意组合"的灵活性
- 换来更直接的层级表达与前缀查询效率
对于需要按车间、产线、设备维度做管理和权限控制的场景,这种取舍可以显著简化应用层逻辑。
3. 与大数据生态的结合:文件格式与计算引擎协同
在云原生与大数据环境下,TSDB 不再是一个孤立组件,而是大数据流水线的一部分。国际上常见的两种集成模式是:
- 数据先入 TSDB,再通过导出/CDC 等方式进入大数据平台(如数据湖)。
- 数据直接写入流处理或数据湖,再由查询引擎提供时序能力。
IoTDB 的做法是:以 TsFile 作为底层文件格式,将"数据库内核"和"大数据引擎"通过统一格式连接。
IoT 设备/系统
IoTDB 引擎(写入/查询)
TsFile 文件(本地/分布式存储)
Spark/Flink/MapReduce
离线/流式计算应用
这种方式的关键点不在于"文件名",而在于:
- 数据落盘即为大数据可读格式,减少 ETL 环节的重复序列化
- 可以在"不绕过 IoTDB 的前提下"直接接入 Spark/Flink,保持读写能力分层
对于已经有大数据平台的团队,这种设计可以把 TSDB 与现有架构相对自然地衔接起来。
4. 写入与查询路径:与云原生部署模式的契合度
4.1 写入路径:LSM + 压缩 + 合并
与很多云原生数据库类似,IoTDB 的写入路径基于"预写日志 + 内存结构 + 持久化文件 + 合并",重点是将随机写转化为顺序写,并在后台通过合并提高历史数据的局部性。
写入路径可以用下面的流程图表示:
客户端/SDK/网关
WAL 预写日志
内存表(MemTable)
Flush 到 TsFile(L0)
后台合并(Compaction)
对象存储/分布式文件系统
这种架构与许多云原生存储系统(如基于 LSM Tree 的 KV/列存)在理念上是相通的:前台快速响应,后台整理数据;差异在于 IoTDB 针对时序特性做了针对性的编码与分块组织。
4.2 查询路径:从单节点到 MPP
在云端集群部署模式下,IoTDB 引入了 ConfigNode + DataNode 的分层结构。查询会被分解成多个可以并行执行的任务(Fragment),分发到不同 DataNode 上执行,再汇总返回。
DataNode2 DataNode1 ConfigNode Client DataNode2 DataNode1 ConfigNode Client 提交查询(SQL) 下发部分计划(Fragment 1) 下发部分计划(Fragment 2) 返回部分结果 返回部分结果 汇总结果集
这种 MPP 风格的查询路径与国际上一些云原生分析型数据库的思路类似,但 IoTDB 的优化重点放在:
- 时序聚合(如 Group By time)
- 多测点对齐查询(Align by device)
- 前缀路径上的范围扫描优化
5. 与国际 TSDB 对比时可以问的"关键问题"
选型时,很容易陷入"功能列表对比",但更有效的方式是提出一组与自己场景强相关的问题,用同一套 benchmark 去验证。
下面这组问题可以直接用在 PoC 里:
- 在你的数据模型下,单机压缩比是多少?
- 同一条样本数据,用不同系统写入,比较实际磁盘占用。
- 在典型下采样查询下,延迟与资源占用如何?
- 如"最近 7 天,每小时平均温度"的查询,在并行写入时的 P95 延迟。
- 工业层级建模的复杂度如何?
- 工厂/产线/设备/测点的层级是否需要额外的关系表或标签约束。
- 边缘部署与云原生部署是否共用一套内核?
- 是否可以在小型边缘设备和云端集群上用同一种数据模型与查询语言。
- 与现有大数据平台的集成成本如何?
- 是否需要额外的导出/转换作业?是否有统一的文件格式或连接器?
IoTDB 在这些问题上给出的答案,基本都围绕"工业/物联网场景"进行了优化。
6. 代码示例:与云原生组件的协作方式
6.1 SQL:以路径前缀表达工业层级
下面是一组典型的 SQL,用于创建存储组、设备时间序列并做跨设备聚合:
sql
-- 创建存储组
CREATE STORAGE GROUP root.plantA;
-- 创建设备测点
CREATE TIMESERIES root.plantA.workshop01.line01.motor01.temperature
WITH DATATYPE=FLOAT, ENCODING=RLE;
CREATE TIMESERIES root.plantA.workshop01.line01.motor01.vibration
WITH DATATYPE=FLOAT, ENCODING=RLE;
-- 插入数据
INSERT INTO root.plantA.workshop01.line01.motor01(timestamp, temperature, vibration)
VALUES (1700000000000, 36.5, 0.12);
-- 跨设备聚合:按产线维度统计平均温度
SELECT AVG(temperature)
FROM root.plantA.workshop01.line01.*
GROUP BY ([now() - 1d, now()), 1h)6.2 Java:与流处理框架协同(示意)
在实际云原生架构中,时序数据往往通过消息队列进入流处理框架,然后由业务决定写入 IoTDB 或数据湖。下面是一个简化示意,用 Java 代码形态表达"消费消息并写入 IoTDB"的流程:
java
import org.apache.iotdb.session.Session;
public class StreamToIoTDB {
private final Session session;
public StreamToIoTDB() throws Exception {
session = new Session("iotdb-service", 6667, "root", "root");
session.open();
}
public void handleMessage(DeviceMetric metric) throws Exception {
String deviceId = metric.getDevicePath();
long time = metric.getTimestamp();
session.insertRecord(
deviceId,
time,
metric.getMeasurements(),
metric.getTypes(),
metric.getValues()
);
}
}实际场景可以用 Flink/Spark Streaming 消费 Kafka 或其他消息系统,再调用类似的写入逻辑。
7. 总结:在全局 TSDB 谱系中理解 IoTDB 的位置
从国际 TSDB 的大图来看,每个系统都在不同维度做了取舍:
- 有的偏重云原生监控,有的偏重日志分析平台
- 有的更接近大数据引擎,有的更接近工业现场
Apache IoTDB 的特点在于:
- 以工业/物联网场景为主,采用树形路径与高压缩 TsFile 组织数据
- 兼顾边缘与云端部署,支持端边云一体化数据流
- 通过 TsFile 与 Connector 等方式,与大数据生态保持协同
对于正处在"既有工业现场,又在推进云原生与大数据平台"的团队来说,把 IoTDB 放在整体架构里考虑,而不是单独看"数据库性能指标",往往能得到更平衡的方案。
资源链接
- IoTDB 下载:https://iotdb.apache.org/zh/Download/

- 企业版官网:https://timecho.com
