日志
错误日志
错误日志是 MySQL 中最重要的日志之一,它记录了当 mysqld 启动和停止时,以及服务器在运行过程中发生任何严重错误时的相关信息。当数据库出现任何故障导致无法正常使用时,建议首先查看此日志。
该日志是默认开启的,默认存放目录 /var/log/,默认的日志文件名为 mysqld.log 。查看日志位置:
show variables like '%log_error%';
二进制日志
介绍
二进制日志(BINLOG)记录了所有的 DDL(数据定义语言)语句和 DML(数据操纵语言)语句,但不包括数据查询(SELECT、SHOW)语句。
作用:①. 灾难时的数据恢复;②. MySQL的主从复制。在MySQL8版本中,默认二进制日志是开启着的,涉及到的参数如下:
show variables like '%log_bin%';
log_bin_basename:当前数据库服务器的binlog日志的基础名称(前缀),具体的binlog文件名需要再该basename的基础上加上编号(编号从000001开始)。
log_bin_index:binlog的索引文件,里面记录了当前服务器关联的binlog文件有哪些。
日志格式
MySQL服务器中提供了多种格式来记录二进制日志,具体格式及特点如下:

查看默认日志格式
show variables like '%binlog_format%';
如果需要配置二进制日志的格式,只需要在 /etc/my.cnf 中配置 binlog_format 参数即可。
查看日志
由于日志是以二进制方式存储的,不能直接读取,需要通过二进制日志查询工具 mysqlbinlog 来查
看,具体语法:
mysqlbinlog 参数选项 logfilename
参数选项:
-d 指定数据库名称,只列出指定的数据库相关操作。
-o 忽略掉日志中的前n行命令。
-v 将行事件(数据变更)重构为SQL语句
-vv 将行事件(数据变更)重构为SQL语句,并输出注释信息
删除
对于比较繁忙的业务系统,每天生成的binlog数据巨大,如果长时间不清除,将会占用大量磁盘空
间。可以通过以下几种方式清理日志:
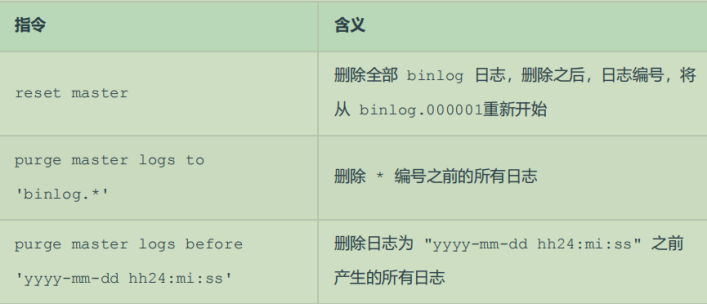
也可以在mysql的配置文件中配置二进制日志的过期时间,设置了之后,二进制日志过期会自动删除。
show variables like '%binlog_expire_logs_seconds%';
查询日志
查询日志中记录了客户端的所有操作语句,而二进制日志不包含查询数据的SQL语句。默认情况下,查询日志是未开启的。
如果需要开启查询日志,可以修改MySQL的配置文件 /etc/my.cnf 文件,添加如下内容:
#该选项用来开启查询日志 , 可选值 : 0 或者 1 ; 0 代表关闭, 1 代表开启
general_log=1
#设置日志的文件名 , 如果没有指定, 默认的文件名为 host_name.log
general_log_file=mysql_query.log
开启了查询日志之后,在MySQL的数据存放目录,也就是 /var/lib/mysql/ 目录下就会出现mysql_query.log 文件。之后所有的客户端的增删改查操作都会记录在该日志文件之中,长时间运行后,该日志文件将会非常大。
慢查询日志
慢查询日志记录了所有执行时间超过参数 long_query_time 设置值并且扫描记录数不小于min_examined_row_limit 的所有的SQL语句的日志,默认未开启。long_query_time 默认为10 秒,最小为 0, 精度可以到微秒。
如果需要开启慢查询日志,需要在MySQL的配置文件 /etc/my.cnf 中配置如下参数:
#慢查询日志
slow_query_log=1
#执行时间参数
long_query_time=2
默认情况下,不会记录管理语句,也不会记录不使用索引进行查找的查询。可以使用log_slow_admin_statements和 更改此行为 log_queries_not_using_indexes,如下所述。
#记录执行较慢的管理语句
log_slow_admin_statements =1
#记录执行较慢的未使用索引的语句
log_queries_not_using_indexes = 1
上述所有的参数配置完成之后,都需要重新启动MySQL服务器才可以生效
主从复制
概述
主从复制是指将主数据库的 DDL 和 DML 操作通过二进制日志传到从库服务器中,然后在从库上对这些日志重新执行(也叫重做),从而使得从库和主库的数据保持同步。
MySQL支持一台主库同时向多台从库进行复制, 从库同时也可以作为其他从服务器的主库,实现链状复制。
MySQL 复制的优点主要包含以下三个方面:
主库出现问题,可以快速切换到从库提供服务。
实现读写分离,降低主库的访问压力。
可以在从库中执行备份,以避免备份期间影响主库服务。
原理
MySQL主从复制的核心就是 二进制日志,具体的过程如下:
-
Master 主库在事务提交时,会把数据变更记录在二进制日志文件 Binlog 中。
-
从库读取主库的二进制日志文件 Binlog ,写入到从库的中继日志 Relay Log 。
-
slave重做中继日志中的事件,将改变反映它自己的数据。
搭建
首先需要配置主从服务器的防火墙。
准备好两台服务器之后,在上述的两台服务器中分别安装好MySQL,并完成基础的初始化准备(安装、密码配置等操作)工作。 其中:
192.168.200.200 作为主服务器master
192.168.200.201 作为从服务器slave
主库配置
修改配置文件 /etc/my.cnf
#mysql 服务ID,保证整个集群环境中唯一,取值范围:1 -- 232-1,默认为1
server-id=1
#是否只读,1 代表只读, 0 代表读写
read-only=0
#忽略的数据, 指不需要同步的数据库
#binlog-ignore-db=mysql
#指定同步的数据库
#binlog-do-db=db01
重启MySQL服务器
systemctl restart mysqld
登录mysql,创建远程连接的账号,并授予主从复制权限
#创建itcast用户,并设置密码,该用户可在任意主机连接该MySQL服务
CREATE USER 'itcast'@'%' IDENTIFIED WITH mysql_native_password BY 'Root@123456'
;
#为 'itcast'@'%' 用户分配主从复制权限
GRANT REPLICATION SLAVE ON *.* TO 'itcast'@'%';
通过指令,查看二进制日志坐标
show master status ;
字段含义说明:
file : 从哪个日志文件开始推送日志文件
position : 从哪个位置开始推送日志
binlog_ignore_db : 指定不需要同步的数据库
从库配置
修改配置文件 /etc/my.cnf
#mysql 服务ID,保证整个集群环境中唯一,取值范围:1 -- 2^32-1,和主库不一样即可
server-id=2
#是否只读,1 代表只读, 0 代表读写 (还有一个参数是super-read-only,管理超级管理员权限)
read-only=1
重新启动MySQL服务
systemctl restart mysqld
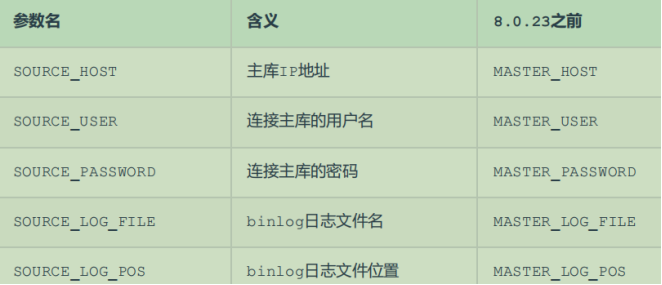
登录mysql,设置主库配置
CHANGE REPLICATION SOURCE TO SOURCE_HOST='192.168.200.200', SOURCE_USER='itcast',
SOURCE_PASSWORD='Root@123456', SOURCE_LOG_FILE='binlog.000004',
SOURCE_LOG_POS=663;
上述是8.0.23中的语法。如果mysql是 8.0.23 之前的版本,执行如下SQL:
CHANGE MASTER TO MASTER_HOST='192.168.200.200', MASTER_USER='itcast',
MASTER_PASSWORD='Root@123456', MASTER_LOG_FILE='binlog.000004',
MASTER_LOG_POS=663;
开启同步
start replica ; #8.0.22之后
start slave ; #8.0.22之前
查看主从同步状态
show replica status ; #8.0.22之后
show slave status ; #8.0.22之前
分库分表
介绍
随着互联网及移动互联网的发展,应用系统的数据量也是成指数式增长,若采用单数据库进行数据存储,存在以下性能瓶颈:
- IO瓶颈
- 热点数据太多,数据库缓存不足,产生大量磁盘IO,效率较低
- 请求数据太多,带宽不够,网络IO瓶颈
- CPU瓶颈
- 排序、分组、连接查询、聚合统计等SQL会耗费大量的CPU资源
- 请求数太多,CPU出现瓶颈
为了解决上述问题,我们需要对数据库进行分库分表处理 。
分库分表的中心思想 :将数据分散存储,使得单一数据库/表的数据量变小,来缓解单一数据库的性能问题,从而达到提升数据库性能的目的。
拆分策略
分库分表的形式主要有两种:垂直拆分 和水平拆分 。拆分的粒度分为分库 和分表 ,组成的拆分策略如下:
拆分策略
├── 垂直拆分
│ ├── 垂直分库
│ └── 垂直分表
└── 水平拆分
├── 水平分库
└── 水平分表
垂直拆分
垂直分库
定义 :以表为依据,根据业务将不同表拆分到不同库中。
特点 :
- 每个库的表结构都不一样
- 每个库的数据也不一样
- 所有库的并集是全量数据
本质 :按照业务维度划分,每个库承载不同的业务模块。
优点 :
- 业务清晰,易于维护和扩展
- 不同库可独立优化和备份
缺点 :
- 跨业务的联接操作困难
- 涉及分布式事务,一致性难以保证
垂直分表
定义 :以字段为依据,根据字段属性将不同字段拆分到不同表中。
特点 :
- 每个表的结构都不一样
- 每个表的数据也不一样,一般通过主键/外键关联
- 所有表的并集是全量数据
本质 :按照字段的冷热度或访问频率进行分离,将常访问字段和非常访问字段分开存储。
优点 :
- 减少单表宽度,查询性能提升
- 大字段和小字段分离,提高缓存命中率
- 同库操作,避免分布式事务问题
缺点 :
- 仍在同一库中,并未缓解单库的IO和CPU压力
- 需要通过外键维护表间关联
水平拆分
水平分库
定义 :以字段为依据,按照一定策略,将一个库的数据拆分到多个库中。
特点 :
- 每个库的表结构都一样
- 每个库的数据都不一样
- 所有库的并集是全量数据
本质 :将数据按某个维度(如用户ID、订单ID)的范围分散到不同的物理库,每个库只保存部分数据。
优点 :
- 有效降低单个数据库的数据量和压力
- 提升并发处理能力
- 支持数据的线性扩展
缺点 :
- 跨库join、跨库事务处理困难
- 分布式事务一致性难以保证
- 运维和部署复杂度提高
水平分表
定义 :以字段为依据,按照一定策略,将一个表的数据拆分到多个表中。
特点 :
- 每个表的表结构都一样
- 每个表的数据都不一样
- 所有表的并集是全量数据
本质 :在同一个库中将大表拆分成多个小表,通过某种策略(如哈希、范围)将数据分散。
优点 :
- 数据在同一库中,联接操作相对简单
- 避免跨库事务问题
- 便于后期扩展,可逐步改造为分库
缺点 :
- 并未缓解单个数据库服务器的IO和CPU压力
- 并发能力提升有限
- 路由和查询逻辑复杂
拆分策略总结
|----------|-------|----------|--------------------|
| 策略 | 拆分维度 | 解决的问题 | 适用场景 |
| 垂直分库 | 业务模块 | 业务单库负载 | 业务清晰,存在明显的业务边界 |
| 垂直分表 | 字段冷热度 | 单表宽度过大 | 表宽度大,冷热字段分离明显 |
| 水平分库 | 数据分片 | 单库数据量/并发 | 数据量大,并发高,需要多库分散 |
| 水平分表 | 数据分片 | 单表数据量 | 单表数据量大,但并发在单库承受范围内 |
实现技术
在实际项目中,分库分表的实现主要有两种技术方案:
|----------|---------------|----------------|
| 技术 | ShardingJDBC | MyCat |
| 架构类型 | 客户端中间件(应用层) | 服务器中间件(数据库层) |
| 实现原理 | AOP拦截SQL,改写路由 | 独立服务,代理SQL请求 |
| 支持语言 | 仅Java | 多语言(通过MySQL协议) |
| 代码改动 | 需要引入依赖和配置 | 无需改动业务代码 |
| 性能 | 较高 | 中等 |
ShardingJDBC
工作原理 :基于AOP拦截应用层的SQL,在JDBC层面进行解析、改写和路由。
特点 :
- 在应用程序内部执行拦截,属于嵌入式方案
- 需要自行编码配置,只支持Java
- 性能较高,无网络开销
MyCat
工作原理 :部署为一个独立的数据库代理服务,应用程序将其视为MySQL,所有SQL由MyCat解析和路由。
特点 :
- 独立中间件,与业务代码解耦
- 支持多种编程语言的应用
- 性能相对较低,但部署和维护更简单
MyCat概述
介绍
MyCat 是开源的、基于Java编写的MySQL数据库中间件。应用程序可以像使用MySQL一样使用MyCat,对于开发人员来说根本感觉不到MyCat的存在。
核心价值 :
- 开发人员只需连接MyCat即可,无需关心底层用了多少台数据库、每台库存储了什么数据
- 具体的分库分表策略通过配置文件指定,无需修改业务代码
MyCat屏蔽了分布式复杂性,提供了透明化的数据访问 。
逻辑结构与物理结构
MyCat的整体架构分为两层:
逻辑结构(应用程序看到的) 物理结构(真实数据存储)
↓ ↓
逻辑库(Schema) → 映射关系 → 数据库服务器1、2、3...
├── 逻辑表1 → 分片规则 → 物理库、物理表
├── 逻辑表2
└── 逻辑表3
逻辑结构 :应用程序直接操作的虚拟库表,完全透明的、统一的数据库视图。
物理结构 :真实的MySQL数据库服务器和其中的库表。
映射关系 :由分片规则确定,决定逻辑表的数据如何分散到物理表中。
核心概念
|-----------------|-----------------------|
| 概念 | 含义 |
| 逻辑库(Schema) | 应用程序连接的虚拟数据库,由MyCat提供 |
| 逻辑表(Table) | 逻辑库中的虚拟表,实际对应多个物理表 |
| 物理库 | 真实的MySQL数据库实例 |
| 物理表 | 真实的MySQL表,分散在各个物理库中 |
| 分片键 | 确定数据分片的字段,用于计算目标分片 |
| 分片规则 | 根据分片键计算数据所属分片的算法 |
| 数据节点 | 物理库在MyCat中的逻辑表示 |
MyCat分片原理
分片的本质
分片的本质 :根据分片键的值,用分片规则计算出这条数据应该存储在哪个物理表/物理库中。
公式 :

其中
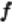
是分片规则定义的计算函数。
分片规则详解
1. 取模分片 (Modulo Hash)
原理 :对分片键进行取模运算。
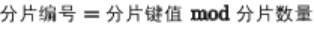
特点 :
- 数据分布均匀
- 算法简单,性能最高
- 不支持动态扩容(扩容需要全量数据迁移)
适用场景 :用户ID、订单ID等均匀分布的数字型字段
2. 范围分片 (Range)
原理 :根据分片键的值范围确定分片位置,预先设定范围边界。
示例 :
分片键值 范围 目标分片
1-1000000 → 分片0
1000001-2000000 → 分片1
2000001-3000000 → 分片2
3000001-∞ → 分片3
特点 :
- 易于理解和实现
- 便于扩容(只需添加新的范围区间)
- 数据分布可能不均(热点数据集中)
适用场景 :时间范围(年、月)、ID连续范围、地域范围等
3. 一致性Hash分片 (Consistent Hash)
原理 :
- 将分片键映射到一个虚拟的哈希环 [0, 2^32)
- 将物理分片也映射到同一个哈希环上
- 数据沿哈希环顺时针找到第一个物理分片
特点 :
- 数据分布相对均匀
- 扩容时只需迁移部分数据(不影响其他分片)
- 算法复杂度高,性能略低
适用场景 :需要支持动态扩容的场景,减少扩容时的数据迁移量
4. 枚举分片 (Enum)
原理 :根据分片键的枚举值,显式配置映射关系。
示例 :
分片键值 (城市) 目标分片
北京 → 分片0
上海 → 分片1
广州 → 分片2
深圳 → 分片3
特点 :
- 精确控制数据分布
- 配置相对复杂
- 只适用于值域有限的字段
适用场景 :城市代码、类别、部门等离散的有限值
5. 按天分片算法 (Partition By Date)
原理 :根据日期字段自动分片,每天一个分片。

特点 :
- 按时间自动分片,数据均衡分布
- 便于按时间范围查询和维护
- 适合日志、事件等时间序列数据
适用场景 :日志、行为记录等日增量数据
具体例子 :
- user_log_20260116 → 2026年1月16日
- event_20260120 → 2026年1月20日
6. 自然月分片 (Partition By Month)
原理 :根据日期字段按自然月份分片,每月一个分片。

特点 :
- 按月自动分片
- 便于月度统计和分析
- 月度数据量差异较大时可能出现热点
适用场景 :月度统计数据、按月份查询的业务
具体例子 :
- order_202601 → 2026年1月
- statistics_202602 → 2026年2月
7. 字符串Hash分片 (String Hash)
原理 :对字符串字段进行哈希,类似取模分片但作用于字符串。
特点 :
- 适用于非数字字段
- 数据分布相对均匀
- 性能与取模分片相当
适用场景 :用户名、手机号、邮箱等字符串字段
分片规则对比
|-------------|-------|------|-------|-------|
| 规则 | 数据均衡性 | 扩容难度 | 算法复杂度 | 热点敏感性 |
| 取模 | 优 | 困难 | 简单 | 低 |
| 范围 | 中 | 简单 | 简单 | 高 |
| 一致性Hash | 中 | 简单 | 复杂 | 中 |
| 枚举 | 可控 | 困难 | 简单 | 取决于数据 |
| 按天 | 优 | 自动 | 简单 | 低 |
| 按月 | 中 | 自动 | 简单 | 中 |
| 字符串Hash | 优 | 困难 | 中 | 低 |
MyCat工作原理
核心流程
MyCat的核心工作流程包括五个环节:
应用程序
↓
- SQL接收 (应用发送SQL到MyCat)
↓ - 解析 (词法/语法/语义分析)
↓ - 路由 (识别分片键,计算目标分片)
↓ - 执行 (改写SQL,发送到物理库并行执行)
↓ - 聚合 (合并多库结果集)
↓
应用程序 (返回结果)
详细说明 :
1. SQL接收 :应用程序通过MySQL协议连接MyCat,发送SQL语句。
2. 解析 :MyCat对SQL进行词法、语法、语义分析,构建抽象语法树,识别表名、分片键、查询条件等信息。
3. 路由 :根据SQL中的分片键值和分片规则,计算出目标分片位置(哪个物理库的哪个物理表)。
4. 执行 :将逻辑表名改写为物理表名,生成改写后的SQL,并发送到各个目标物理库执行。
5. 聚合 :收集所有物理库的查询结果,进行合并、排序、分页等处理,返回给应用程序。
关键特性
1. 透明性
- 应用程序无感知MyCat的存在
- 像操作单库一样操作分布式数据库
- SQL语句无需修改
2. 并行执行
- 利用多个物理库的并行能力
- 支持多个分片的并发查询
- 提升整体查询性能
3. 智能路由
- 根据分片键精确定位数据位置
- 避免全库扫描
- 支持多个分片的查询合并
4. 结果聚合
- 自动合并多库查询结果
- 处理ORDER BY、GROUP BY、LIMIT等聚合操作
- 返回给应用的结果集与单库查询一致
分布式事务问题
在使用MyCat进行分库分表后,会面临分布式事务的一致性问题:
问题的本质 :一条业务操作可能涉及多个物理库的多张表,传统的ACID事务(在单个数据库中)无法保证跨多个数据库的事务一致性。
具体表现 :
- 一个事务中的SQL可能修改多个库中的数据
- 某个库的操作成功,另一个库的操作失败
- 无法进行原子性的回滚
常见解决方案 :
- 两阶段提交(2PC)
- 通过协调器协调多个数据库的提交
- 性能较差,响应时间长
- 不推荐在高并发场景使用
- 最终一致性
- 通过消息队列、业务补偿等手段保证最终一致
- 允许短时间内的数据不一致
- 实现复杂但性能较好
- 事务补偿
- 业务层面的回滚机制
- 如果后续操作失败,主动调用补偿逻辑
- 需要业务代码支持
读写分离
介绍
随着应用系统的并发访问量不断增加,对数据库的读写性能要求也越来越高。单个数据库服务器往往存在以下问题:
- 读操作压力大
- 应用程序中读操作通常占比80%以上
- 大量的SELECT查询占用数据库连接和资源
- 频繁的磁盘IO和网络IO成为瓶颈
- 写操作影响读性能
- 写操作(INSERT、UPDATE、DELETE)会锁表或锁行
- 大量写操作会阻塞读操作的执行
- 读写操作竞争数据库资源,相互影响
- 单库容量限制
- 磁盘容量有限
- 数据库连接数有上限
- CPU和内存资源有限
为了解决上述问题,我们可以采用读写分离 的架构。
读写分离的中心思想 :将数据库的读操作和写操作分散到不同的数据库实例上,通过主从复制实现数据同步,从而提升整体的读写性能和系统并发能力。
一主一从
定义与架构
一主一从 :部署一个主数据库(Master)和一个从数据库(Slave),主从之间通过二进制日志(Binlog)进行数据同步。
架构设计 :
应用程序
↓
主数据库 (Master)
↓ (Binlog复制)
从数据库 (Slave)
工作原理
主从复制的核心原理 :
- 写操作流程
- 应用程序发送写SQL到主数据库
- 主数据库执行INSERT、UPDATE、DELETE操作
- 主数据库将操作记录在二进制日志(Binlog)中
- 同步流程
- 从数据库与主数据库建立连接
- 从数据库向主数据库请求Binlog内容
- 主数据库将Binlog文件推送给从数据库
- 从数据库接收Binlog,应用到本地数据库中
- 数据一致性
- 从数据库通过重放主数据库的Binlog来实现数据同步
- 存在短暂的复制延迟,从库数据可能不是最新的
- 最终数据会保持一致
核心特点
主库(Master)特点 :
- 接收所有写操作(INSERT、UPDATE、DELETE)
- 记录所有数据变更到Binlog
- 数据是最新的、权威的
从库(Slave)特点 :
- 接收主库通过Binlog传来的数据变更
- 被动地应用主库的操作
- 数据与主库保持一致(可能有延迟)
优点与缺点
优点 :
- 架构简单,易于部署和维护
- 成本低,只需两台数据库服务器
- 实现了基础的数据备份和高可用
缺点 :
- 读性能提升有限(只有一个从库分担读操作)
- 主库发生故障时,系统无法自动切换到从库
- 从库数据存在复制延迟,可能读到过期数据
- 无法支持写操作的扩展
一主一从读写分离
定义与架构
一主一从读写分离 :在一主一从的基础上,应用程序根据SQL操作类型进行路由,写操作发送到主库,读操作发送到从库。
架构设计 :
应用程序
├─ 写操作 (INSERT、UPDATE、DELETE)
│ ↓
└─ 主数据库 (Master)
↓ (Binlog复制)
从数据库 (Slave)
↑
└─ 读操作 (SELECT)
├─ 从应用程序
读写路由原理
路由的本质 :应用程序在执行SQL之前,先判断操作类型,然后选择目标数据库。
路由逻辑 :
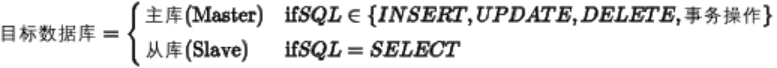
关键考虑 :
- 事务的特殊性
- 事务中的SQL都应该发送到主库
- 避免事务中的读操作读到过期数据
- 保证事务的一致性
- 复制延迟问题
- 主库的写操作需要时间同步到从库
- 短时间内,从库的数据可能落后于主库
- 应用需要考虑这种延迟的影响
- 强一致性要求
- 如果业务要求读操作必须读到最新数据
- 应该将读操作也发送到主库
- 这种情况下无法发挥读写分离的优势
核心特点
读操作特点 :
- 发送到从库执行
- 充分利用从库的读取能力
- 降低主库的读压力
写操作特点 :
- 发送到主库执行
- 保证数据的一致性和完整性
- 主库通过Binlog同步到从库
优点与缺点
优点 :
- 有效分散读操作压力
- 80%左右的读操作由从库承担,主库压力明显降低
- 提升整体系统的读取性能和并发能力
- 成本相对较低
缺点 :
- 从库数据存在复制延迟,可能读到过期数据
- 复制延迟无法完全消除,应用需要容忍
- 主库故障时无法自动切换
- 主库仍然是单点,写入仍然受到主库容量限制
- 不支持写操作的扩展和分散
双主双从
定义与架构
双主双从 :部署两个主数据库和两个从数据库,两个主库互为主从,每个主库都配置一个从库。形成两个独立的主从复制链路。
架构设计 :
主库1 (Master1) 主库2 (Master2)
↓ ↑ (互为主从复制) ↓ ↑ (互为主从复制)
从库1 (Slave1) 从库2 (Slave2)
↓ ↓
└────────────┬────────────┘
↑
应用程序
工作原理
双主互备的复制原理 :
- 两个主库的关系
- 主库1和主库2互为主从
- 主库1的变更通过Binlog复制到主库2
- 主库2的变更通过Binlog复制到主库1
- 两个主库的数据保持一致
- 主从链路
- 主库1维护一个从库1,接收主库1的数据变更
- 主库2维护一个从库2,接收主库2的数据变更
- 形成两条独立的复制链路
- 数据流向
主库1 → 主库2、从库1
主库2 → 主库1、从库2
最终所有四个库的数据保持一致
核心特点
两个主库的特点 :
- 都可以接收写操作
- 互相同步对方的数据变更
- 形成循环复制,需要特殊的机制避免无限循环
- 同时作为对方的从库,接收对方的Binlog复制
两个从库的特点 :
- 各自接收其对应主库的数据变更
- 被动地应用主库的操作
- 作为读操作的承载方
数据一致性 :
- 任一主库的数据变更都会同步到另一个主库
- 再由另一个主库同步到其从库
- 最终四个库的数据都保持一致
优点与缺点
优点 :
- 两个主库互为备份,主库故障时可以快速切换
- 提高了系统的高可用性
- 两个主库都可以处理写操作,分散写压力
- 从库可以分担读操作
缺点 :
- 架构复杂,部署和维护成本较高
- 需要处理两个主库的并发写冲突
- 双主模式容易产生数据不一致问题
- 需要额外的冲突检测和解决机制
- 复制延迟仍然存在
双主双从读写分离
定义与架构
双主双从读写分离 :在双主双从的基础上,应用程序进行智能路由,将写操作分散到两个主库,将读操作分散到两个从库。
架构设计 :
应用程序
├─ 写操作1 → 主库1 (Master1) 写操作2 → 主库2 (Master2)
│ ↓ ↑ (互为主从) ↓ ↑
│ 主库2 (Master2) 主库1 (Master1)
│
└─ 读操作1 → 从库1 (Slave1) 读操作2 → 从库2 (Slave2)
路由与负载均衡原理
写操作路由 :

其中

可以是用户ID、订单ID等分片键。
读操作路由 :

负载均衡策略 :
- 基于分片键的哈希:同一个业务对象的读写操作路由到同一主从对
- 轮询策略:按顺序轮流分发读操作到各从库
- 随机策略:随机选择一个从库进行读操作
核心特点
写操作分散 :
- 写操作分散到主库1和主库2
- 每个主库承担一部分写操作负担
- 通过两个主库互相复制来保持数据一致
读操作分散 :
- 读操作分散到从库1和从库2
- 每个从库承担一部分读操作负担
- 从库从其对应的主库接收数据更新
主从对应关系 :
- 主库1与从库1形成一对,共享数据
- 主库2与从库2形成一对,共享数据
- 同一数据的读写操作应该路由到同一主从对
关键问题
1. 写冲突问题
- 两个主库都可以接收写操作
- 同一条数据可能同时在两个主库上被修改
- 需要冲突检测和解决机制
2. 数据一致性问题
- 不同的写操作可能路由到不同的主库
- 主库之间的复制延迟导致短时间的数据不一致
- 应用程序需要处理读到过期数据的情况
3. 复制延迟问题
- 主库1的更新需要时间同步到主库2和从库1
- 主库2的更新需要时间同步到主库1和从库2
- 复制链路越长,延迟越大
优点与缺点
优点 :
- 读写操作都得到了分散,整体性能提升最明显
- 写操作分散到两个主库,提高了写入能力
- 读操作分散到两个从库,提高了读取能力
- 两个主库互为备份,高可用性强
- 系统的并发处理能力和吞吐量最高
缺点 :
- 架构最为复杂,部署和维护成本最高
- 需要处理两个主库之间的写冲突
- 数据一致性问题最难解决
- 复制延迟问题突出
- 容易出现脑裂(两个主库独立运行)
- 故障诊断和处理难度大
- 需要专业的数据库运维团队
架构对比总结
|--------------|-----|-----|-----|-----|------|-----|--------------|
| 架构 | 主库数 | 从库数 | 读性能 | 写性能 | 高可用性 | 复杂度 | 推荐场景 |
| 一主一从 | 1 | 1 | 低 | 低 | 低 | 低 | 小型应用,读写并不高 |
| 一主一从读写分离 | 1 | 1 | 中 | 低 | 低 | 中 | 读多写少的应用 |
| 双主双从 | 2 | 2 | 中 | 中 | 中 | 高 | 需要高可用的应用 |
| 双主双从读写分离 | 2 | 2 | 高 | 中 | 高 | 高 | 高并发、读写都频繁的应用 |
关键问题与解决方案
复制延迟问题
问题描述 :从库数据总是滞后于主库,导致读到过期数据。
常见场景 :
- 用户在主库写入数据后立即从从库读取
- 可能读到修改前的旧数据
解决方案 :
- 强制读主库
- 对强一致性要求高的操作,读操作也发送到主库
- 牺牲读性能来保证数据一致性
- 延迟判断
- 记录操作时间戳
- 根据复制延迟时间决定是否从从库读取
- 复制延迟过大时重试或读主库
- 缓存方案
- 关键数据写入后立即缓存到应用
- 短时间内从缓存读取而不是数据库
- 缓存过期后再从数据库读取
数据不一致问题
问题描述 :双主模式下,两个主库可能因为同时接收写操作而产生数据不一致。
具体表现 :
- 同一条数据在两个主库上的值不同
- 主库之间的复制可能丢失某些操作
- 从库可能接收到不一致的数据
解决方案 :
- 分片路由
- 同一数据始终路由到同一个主库
- 避免同一数据的多主并发写
- 通过分片键确保数据的单点写入
- 冲突检测与解决
- 检测冲突的写操作
- 采用时间戳、版本号等机制解决冲突
- 保留较新的数据或合并两个版本
- 最终一致性
- 允许短时间的数据不一致
- 通过额外的同步机制最终达成一致
- 如定期对账、消息队列同步等
主库故障切换问题
问题描述 :主库发生故障时,需要自动切换到其他库继续提供服务。
切换的复杂性 :
- 需要判断主库是否真正故障(网络分割问题)
- 需要确保从库数据是最新的
- 需要自动更新应用程序的连接指向
- 需要防止脑裂(两个独立的主库同时运行)
解决方案 :
- 故障检测
- 应用程序定期ping主库
- 心跳检测或健康检查机制
- 快速发现主库故障
- 自动切换
- 从库晋升为主库
- 自动更新应用程序的数据库连接
- 需要中间件或专门的管理工具支持
- 防止脑裂
- 采用Quorum(多数派)机制
- 只有得到多数投票的节点才能成为主库
- 避免网络分割导致的错误切换