一、项目介绍
本项目是一个基于Text-CNN深度学习模型的中文文本情感识别Web应用系统。系统采用前后端分离架构,后端使用Flask框架构建RESTful API,深度学习模型采用TensorFlow/Keras实现的Text-CNN卷积神经网络,前端框架支持跨平台访问。
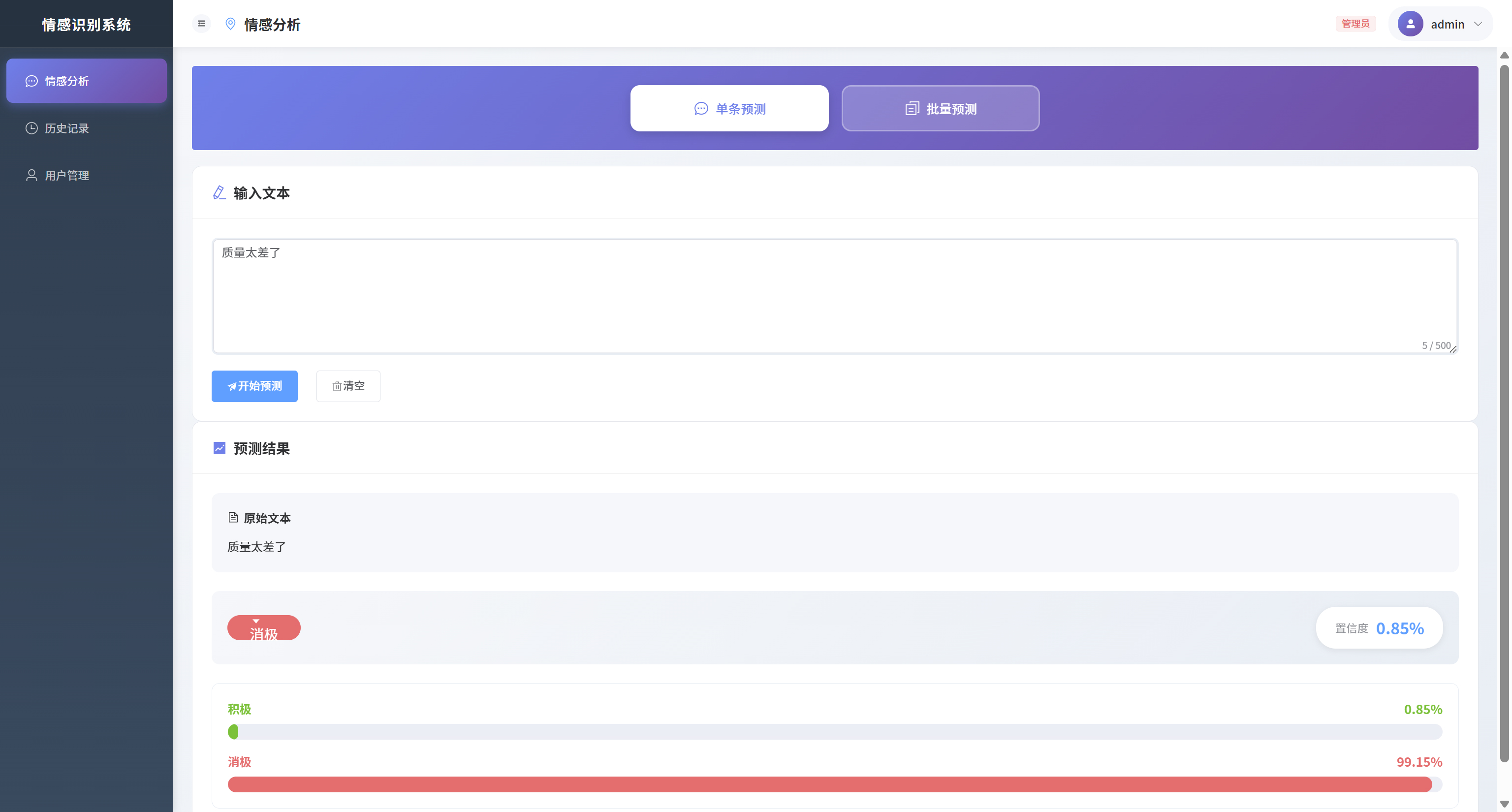
系统核心功能包括用户注册登录、JWT身份认证、中文文本情感分析、批量预测处理以及历史记录管理等。系统使用jieba分词对中文文本进行预处理,通过训练好的Text-CNN模型对文本情感进行二分类判断(积极/消极),并提供直观的置信度可视化展示。系统支持用户角色管理(普通用户和管理员),实现了基于RBAC的权限控制机制,确保数据安全和用户隐私。系统采用SQLite数据库存储用户信息和预测历史,使用Flask-Migrate进行数据库版本管理,保证了系统的可维护性和可扩展性。

二、选题背景与意义
随着互联网技术的快速发展和社交媒体的普及,网络上产生了海量的文本数据,如用户评论、社交媒体帖子、产品评价等。这些文本数据中蕴含着丰富的情感信息,对于企业了解用户需求、改进产品服务、进行舆情监控等方面具有重要价值。传统的人工分析方式效率低下且成本高昂,无法满足大规模文本情感分析的需求,因此开发自动化的文本情感识别系统具有重要的现实意义。
中文文本情感识别相比英文更具挑战性,主要原因是中文语言的复杂性,包括分词困难、语义表达多样、网络用语丰富等特点。本系统针对中文文本特性,采用基于深度学习的Text-CNN模型进行情感分析,相比传统的机器学习方法(如SVM、朴素贝叶斯等),能够自动提取文本特征,避免了繁琐的人工特征工程,同时具有更高的准确率和更好的泛化能力。
本系统的设计和实现具有重要的理论意义和应用价值。在理论层面,探索了卷积神经网络在中文文本情感分析中的应用,验证了Text-CNN模型在中文情感二分类任务上的有效性。在应用层面,系统可应用于电商评论分析、社交媒体舆情监控、客户反馈分析等多个场景,为企业决策提供数据支持,具有广泛的实用价值。
三、关键技术栈:text-cnn
Text-CNN(Text Convolutional Neural Network)是本系统的核心深度学习模型,由Yoon Kim在2014年提出,将卷积神经网络成功应用于文本分类任务。相比传统的循环神经网络(RNN)和长短期记忆网络(LSTM),Text-CNN具有并行计算能力强、训练速度快、能够捕捉文本局部特征等优势,特别适合文本分类任务。
Text-CNN的模型结构主要包含四个部分:嵌入层(Embedding Layer)、卷积层(Convolutional Layer)、池化层(Pooling Layer)和全连接层(Fully Connected Layer)。在嵌入层,系统将预处理后的中文分词转换为密集的词向量表示,捕捉词语的语义信息。卷积层使用多个不同尺寸的卷积核(如3、4、5个词窗口)对文本进行卷积操作,提取文本的局部特征,类似于N-gram特征提取。池化层采用最大池化(Max Pooling)操作,从每个卷积核的输出中提取最重要的特征,降低特征维度并保留最显著的情感特征。全连接层将池化后的特征进行整合,通过Softmax激活函数输出分类概率。
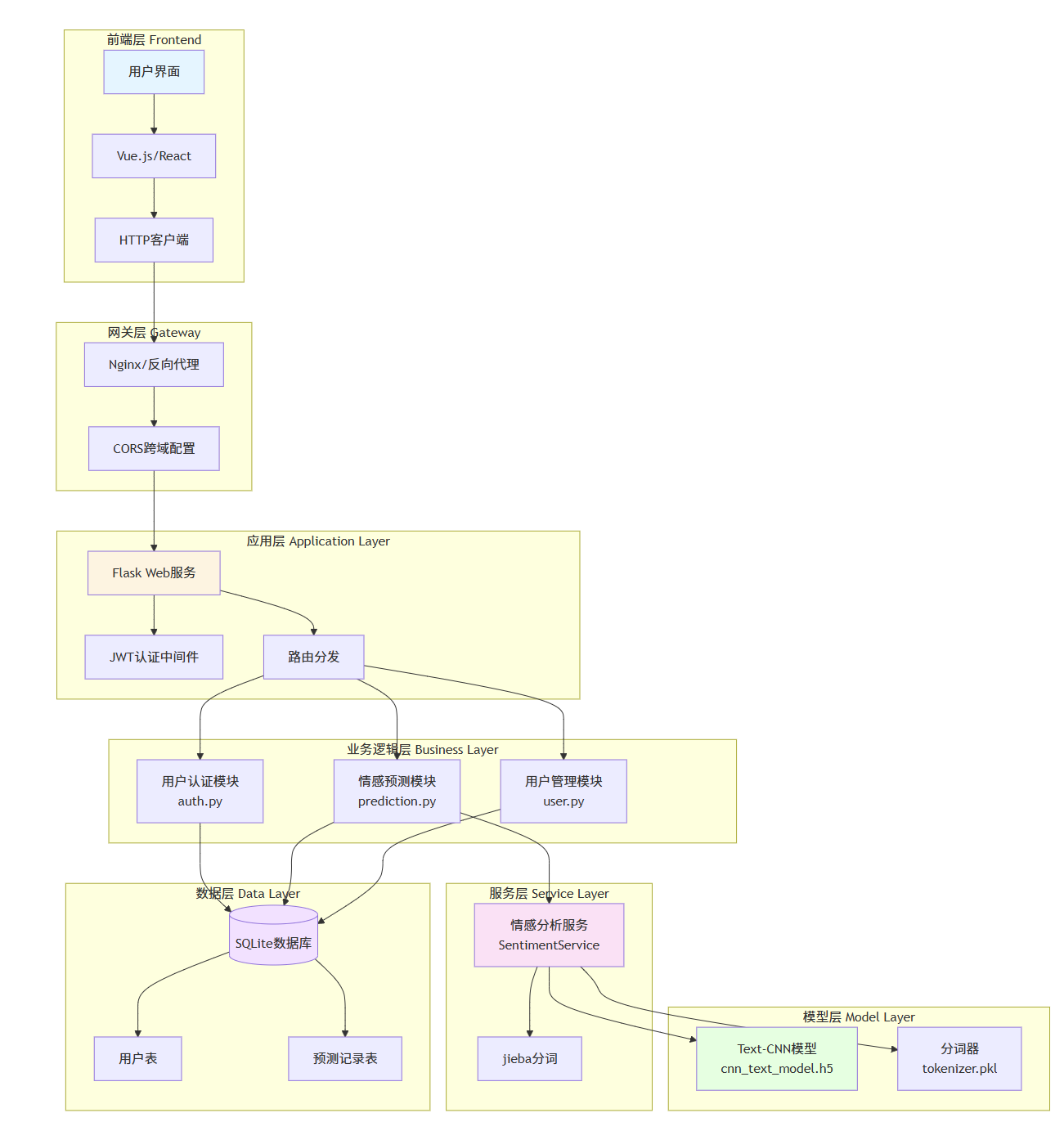
四、技术架构图
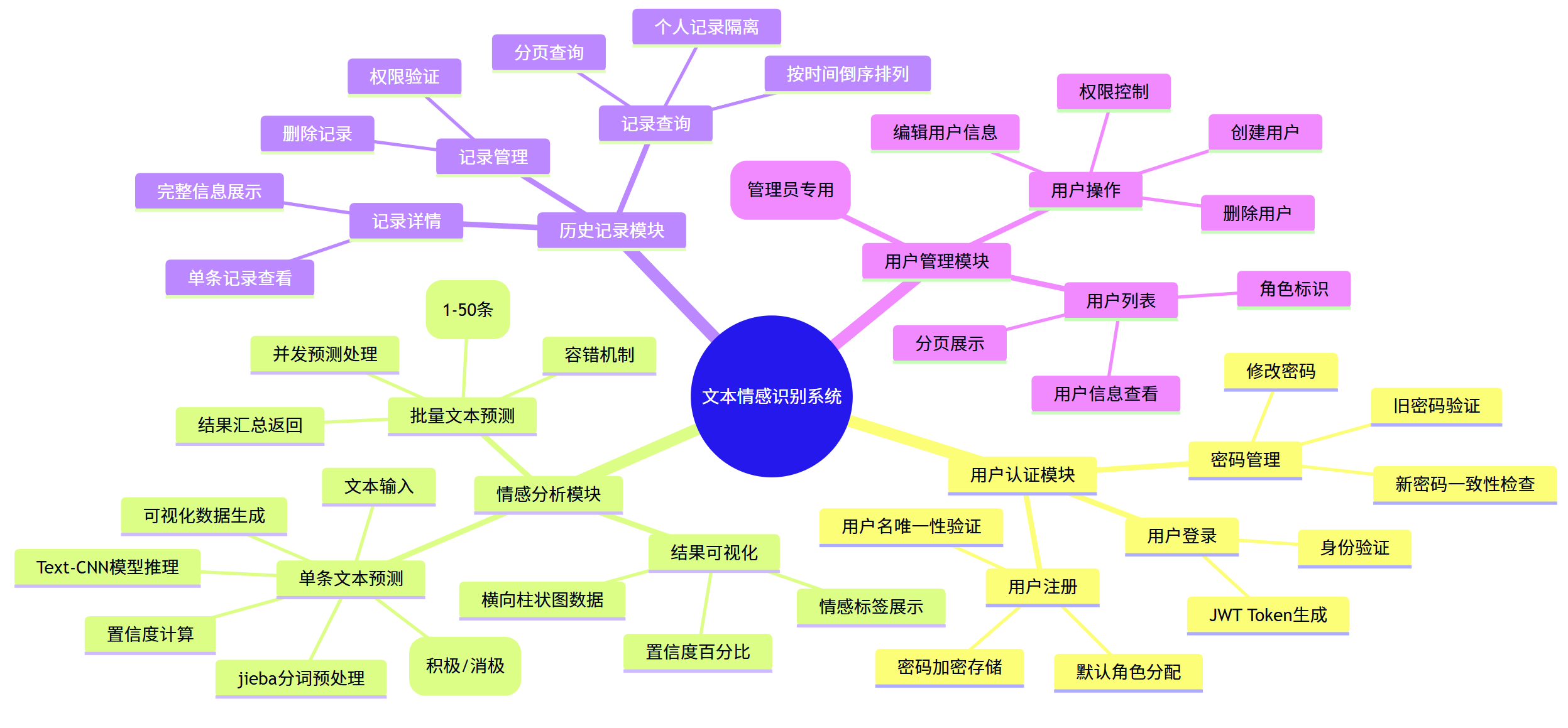
五、系统功能模块图
演示视频 and 完整代码 and 安装
请点击下方卡片↓↓↓添加作者获取,或在我的主页添加作者获取。