Faiss:用来将结构化数据转换成向量存储在向量数据库中,之后进行检索等操作
通过FAISS检索出Top-K结果需要 5个步骤
1.获取数据来源
2.将数据构造成向量数据集(向量数据的归化)
3.使用FAISS 构建索引
4.将向量数据集添加到索引中
5.在索引中进行相似度搜索
6.返回相似度最高的 Top-K结果
#安装插件
#支持大量预训练模型(多语言 / 中文 / 专用领域)
pip install sentence-transformers
pip install modelscope
#阿里开源的中文优化语义模型
modelscope download --model BAAI/bge-small-zh-v1.5完整代码
import logging
import faiss
import numpy as np
from sentence_transformers import SentenceTransformer
from cs.models import Products
class ProductVectorStore:
def __init__(self):
"""使用sentence-transformers简化版本"""
# model_local_path = "/Users/jiajiamao/.cache/modelscope/hub/models/sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2"
# self.model = SentenceTransformer(model_local_path)
#使用阿里 bge-small-zh 语义
model_local_path = "/Users/jiajiamao/.cache/modelscope/hub/models/BAAI/bge-small-zh-v1.5"
self.model = SentenceTransformer(model_local_path)
"""引索"""
self.product_index = None
self.product_texts = []
self.getProduct()
"""
获取商品数据
"""
def getProduct(self):
#从mongo中获取 商品信息
products_mongos = Products.objects.only('product_id', 'name', 'description')
#转换成pbm
products_dict = [products_mongo.to_dict() for products_mongo in products_mongos]
logging.info(f"products_dict 商品列表 {products_dict}")
#模型期望的是文本列表。需要从每个字典中提取文本信息,然后组合成模型可以处理的文本
product_texts = [f"{p.get('name', '')} {p.get('description', '')}" for p in products_dict]
self.product_texts = product_texts
logging.info(f"提取文本信息 {self.product_texts}")
logging.info(f"已添加 {len(self.product_texts)} 条中文文本")
"""转换商品向量 直接批量转换为向量 """
product_vectors = self.model.encode(product_texts,convert_to_numpy=True)
product_vectors = product_vectors.astype(np.float32)
"""归化 是不是就可以理解成 转换成一种比例"""
"""Faiss内置归一化函数"""
faiss.normalize_L2(product_vectors)
logging.info(f"商品归化列表 {product_vectors}")
"""
创建索引 ------ 使用内积索引(适合归一化后的向量,等同于余弦相似度)
"""
if self.product_index is None:
"""维数"""
dimension = product_vectors.shape[1]
#欧几里得距离(L2距离)索引,它计算的是向量之间的几何距离,不是语义相似度。
# self.product_index = faiss.IndexFlatL2(dimension)
#内积索引 内积 = 余弦相似度
self.product_index = faiss.IndexFlatIP(dimension)
"""增加到索引中"""
self.product_index.add(product_vectors)
logging.info(f"增加到索引中数据总数 {self.product_index.ntotal} 条中文文本")
def searchProduct(self,query,top):
""" 转换向量 """
search_product_vector = self.model.encode(query,convert_to_numpy=True)
search_product_vector = search_product_vector.astype(np.float32)
"""把一维向量变成二维:(1, D)"""
search_product_vector = search_product_vector.reshape(1, -1)
"""归化"""
faiss.normalize_L2(search_product_vector)
"""搜索 top条 相似商品 返回两个数组:距离数组和索引数组 """
scores, indices = self.product_index.search(search_product_vector,top)
"""将结果格式化为字典列表"""
results = []
for score, idx in zip(scores[0], indices[0]):
if idx != -1 and idx < len(self.product_texts): # 检查索引有效性
# 从product_texts中获取商品文本,但实际可能需要完整商品信息
results.append({
'index': int(idx), # 索引位置
'text': self.product_texts[idx], # 商品文本
'score': float(score) # 距离分数(越小越相似)
})
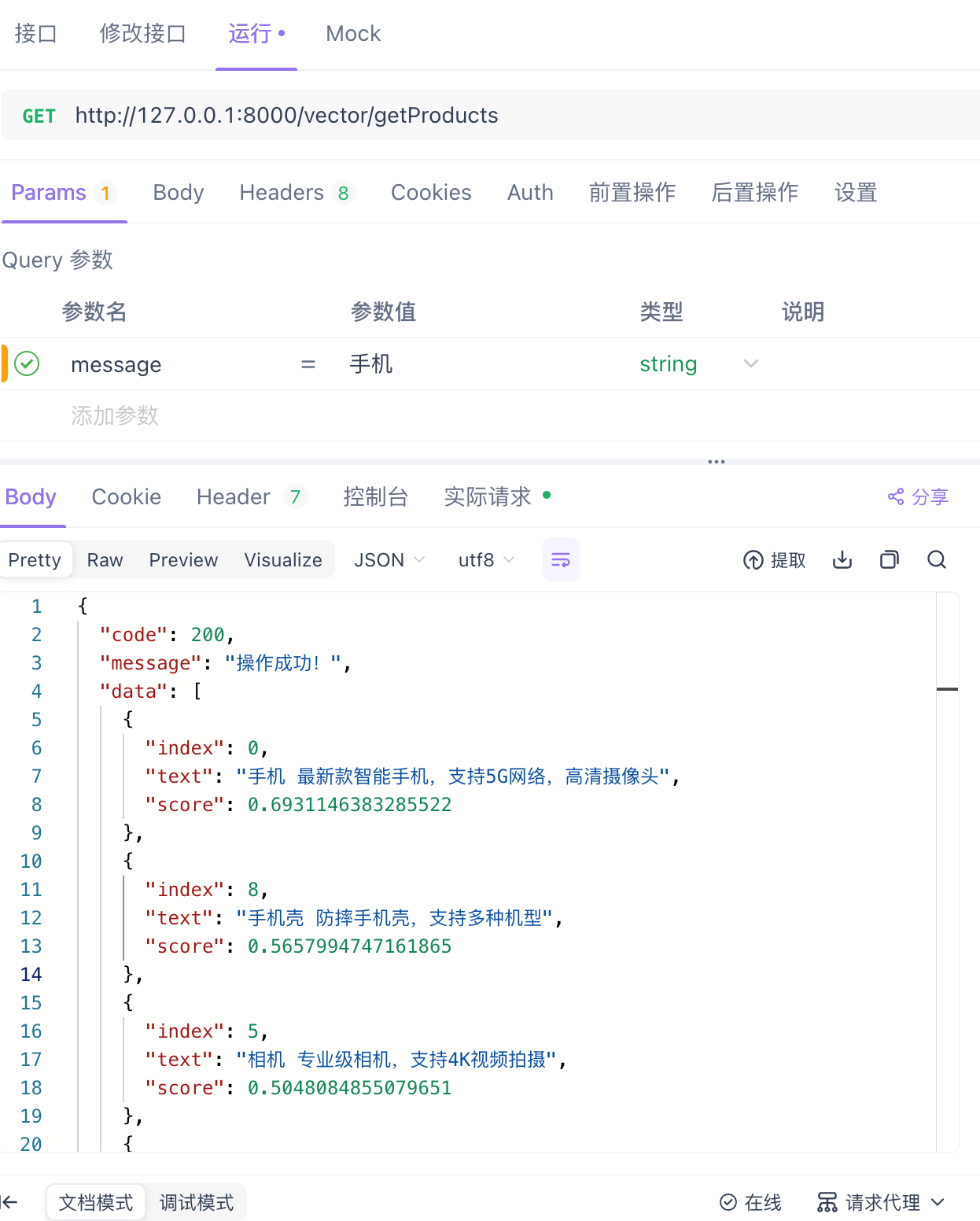
return results测试 发送请求
@csrf_exempt
def getProducts(request):
try:
if request.method == 'GET':
keywords = request.GET.get("message")
#取10条结果数据
vector = ProductVectorStore().searchProduct(keywords, 10)
else:
raise BusinessException(ResponseCodeEnum.METHOD_ERROR.status_code,
ResponseCodeEnum.METHOD_ERROR.status_message)
return JsonResponse(CommonResult.success_data(vector), json_dumps_params={'ensure_ascii': False})
except BusinessException as e:
return JsonResponse(CommonResult.error(e.code, e.message), json_dumps_params={'ensure_ascii': False})