MG-Nav: 基于稀疏空间记忆的双尺度视觉导航 --- MG-Nav: Dual-Scale Visual Navigation via Sparse Spatial Memory





当然!我们用一个真实生活中的例子 ,把 MG-Nav 的两个核心技术 ------ SMG(稀疏空间记忆图) 和 VGGT-Adapter ------ 用"说人话"的方式讲清楚。
🧍♂️ 场景设定:
你第一次去朋友家做客。
他发给你一张他家门口的照片 (目标图像),并说:"我家在3栋2单元,你从小区东门进来找就行。"
但小区没地图、不能问人、手机也没网------你只能靠眼睛看、自己走。
这就像机器人做 ImageNav(图像目标导航):只给一张目标照片,要在陌生环境里找到它。
一、SMG 是什么?------ 你的"脑内简略地图"
❌ 普通人做法(笨办法):
边走边记每一棵树、每辆车、每个垃圾桶......结果信息太多,脑子炸了,还容易迷路。
✅ MG-Nav 的做法(聪明人):
你只记住几个关键路口/地标,比如:
- "进门后左转有个红色邮筒"
- "往前走到喷泉,右拐能看到3栋楼"
- "3栋楼下有辆蓝色自行车"
这些就是 SMG 的节点(大概5~10个就够了)。
🔑 SMG = 一张你自己画的草图,只标关键点 + 怎么连起来
具体怎么建这张图?
假设你朋友之前带别人来过,留下了一段走路录像(演示轨迹)。MG-Nav 就从这段录像里自动挑出:
- 哪些位置最值得记(比如转弯处、楼门口)→ 用"最远点采样"选
- 每个位置拍几张不同角度的照片(正面、侧面)→ 防止你换个角度看就认不出
- 顺便记下那里有什么东西(邮筒、自行车、绿植)→ 用 AI 自动识别
最后生成一张"记忆地图",像这样:
text
编辑
[东门] ------ [红邮筒] ------ [喷泉] ------ [3栋楼下(蓝车)] ------ [目标:家门口]当你实际去找的时候,系统会不断比对你眼前的画面和这张图上的节点,判断:"我现在应该在'喷泉'附近",然后规划下一步去"3栋楼下"。
✅ 这就是 SMG:不记细节,只记骨架 + 关键视觉线索,轻量又管用。
二、VGGT-Adapter 是什么?------ 你的"空间直觉"
❌ 普通导航模型的问题:
你走到3栋楼下,看到一排单元门。目标照片是"中间那个棕色木门"。
但你现在站在斜对面,看到的是门的侧面,颜色也因为阴影看起来发黑。
普通模型可能想:"这跟我手里的照片不一样!是不是走错了?" → 开始乱转。
✅ VGGT-Adapter 的作用:
它能理解三维空间关系,就像你脑子里知道:
"虽然现在看的是侧面,但这个门的位置、形状、旁边窗户的排列,跟照片里是同一个!只是角度不同。"
它是怎么做到的?
- 虽然只输入两张平面照片(你眼前的 + 目标照片),
- 但它背后有个叫 VGGT 的"空间感知大脑"(提前在大量3D场景中学过),
- 这个大脑能猜出:"这两张图大概是从什么相对位置拍的"、"是不是同一个物体"。
然后,它把这个"空间直觉"悄悄告诉导航系统:"别慌,你没走错,再往前两步正对着看就对了。"
✅ VGGT-Adapter 就像一个懂透视、懂遮挡、懂视角变化的"导航副驾驶",专门帮你判断"是不是同一个地方"。
🎯 合起来看整个过程:
- 你进小区 → 系统用 SMG 判断:"你现在靠近'东门'节点"
- 系统查图 → "下一个要去'红邮筒'"
- 你走到喷泉附近 → 系统用当前画面匹配 SMG,确认位置
- 你看到3栋楼 → SMG 告诉你:"目标在家门口,就在'蓝车'节点附近"
- 你面对一排门犹豫 → VGGT-Adapter 说:"左边第二个!虽然角度歪,但结构对得上!"
- 你成功敲门 → 导航成功!
💡 总结成一句话:
SMG 是你的"脑内简略地图",VGGT-Adapter 是你的"空间直觉"------一个管大局路线,一个管细节辨认,配合起来就能在陌生地方精准找门。
这种设计不需要提前建精细地图,也不需要重新训练,真正做到了"看一眼照片就能找过去"。
如果你还想听另一个例子(比如在办公室找打印机、在商场找奶茶店),我也可以继续讲!
***********************
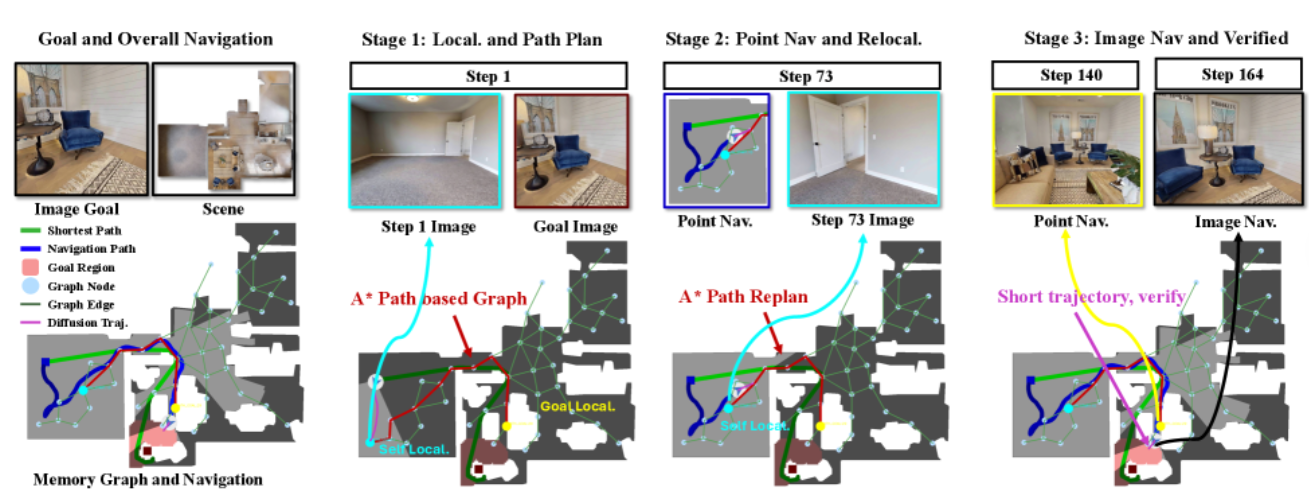
MG-Nav 系统一共包含 4 个核心模块,每个模块各司其职,配合起来实现"看一眼照片就能在陌生环境里找到目标"的零样本视觉导航能力。
下面用最直白的人话 + 功能说明,告诉你每个模块是干嘛的、为什么需要它:
✅ 模块 1:SMG(稀疏空间记忆图)
🧠 作用:记住"关键地标",画一张脑内简略地图
- 干啥的 ?
从别人走过的录像(演示轨迹)里,自动挑出几个值得记住的位置 (比如楼门口、喷泉、转角),每个位置存:- 几张不同角度的照片
- 这里有什么东西(沙发、绿植、自行车)
- 它在地图上的坐标
- 为什么需要它 ?
不可能记住每一帧画面!SMG 只记"骨架信息",轻量又抗干扰。就像你去新公司,只记"电梯→茶水间→右拐第三间"就够了。 - 什么时候用 ?
离线构建一次 (提前准备好),在线用来定位和规划大方向。
✅ 模块 2:全局规划器(Global Planner)
🗺️ 作用:看图找路,决定"下一步往哪走"
- 干啥的 ?
- 拿你当前看到的画面,去 SMG 里比对:"我现在大概在哪个地标附近?"(定位)
- 然后查 SMG 地图:"从这儿怎么走到目标?" → 用 A* 算法找出一串中间路点(路径规划)
- 输出下一个要去的"路点坐标"(比如"先走到喷泉那儿")
- 为什么需要它 ?
局部导航只能看眼前几米,容易绕晕。全局规划器像"高德地图",给你指大方向。 - 什么时候用 ?
低频运行(每2~5秒一次,或迷路时触发)。
✅ 模块 3:局部控制器(Local Controller)
🦶 作用:控制机器人"迈哪条腿、转多少度"
-
干啥的 ?
接收两个输入:- 当前摄像头画面
- 目标(可能是中间路点坐标,也可能是最终目标照片)
然后输出动作:前进 / 左转 / 右转 / 停止
-
底层是谁 ?
通常是一个预训练好的零样本导航策略(如 NavDP),本身就能做简单导航。 -
为什么需要它 ?
全局规划只给"目的地",但怎么走过去、怎么避障、怎么对准门------全靠它实时决策。 -
什么时候用 ?
高频运行(每秒5~10次),是实际执行动作的"手脚"。
✅ 模块 4:VGGT-Adapter(几何增强适配器)
👁️🗨️ 作用:帮局部控制器"看懂三维空间",别被角度骗了
- 干啥的 ?
- 输入:当前画面 + 目标画面
- 输出:一个"几何相似度特征",告诉控制器:"虽然看起来不一样,但这是同一个地方,只是你看歪了"
- 怎么做到的 ?
背后有个叫 VGGT 的模型(在大量3D场景中学过),能猜出两张图的相对视角和3D结构关系 。
Adapter 是一个轻量小网络,把这种"空间直觉"注入到局部控制器里。 - 为什么需要它 ?
没它的话,机器人看到目标门的侧面,会以为"这不是照片里的门",然后放弃或乱转。
有它,就能理解:"哦,这是同一个门,我再往前走两步正对着看就对了。" - 什么时候用 ?
只在局部控制器内部调用,尤其是接近最终目标时最关键。
🔗 四个模块怎么协作?(流程串起来)
- 你给一张目标照片 → 系统知道要找什么
- SMG 提供记忆地图(提前建好)
- 全局规划器 :
- 看你当前在哪(匹配 SMG)
- 规划一条"地标跳转路径" → 输出第一个路点
- 局部控制器 :
- 控制机器人走向这个路点
- 走着走着,VGGT-Adapter 一直在后台判断:"是不是快到了?是不是同一个东西?"
- 到达路点后,全局规划器再算下一步......直到最后逼近目标
- 最后几米,局部控制器直接拿目标照片 + VGGT-Adapter 精准对齐
🎯 一句话总结四个模块:
表格
| 模块 | 人类类比 | 技术角色 |
|---|---|---|
| SMG | 脑子里记得几个关键地标 | 长期记忆 + 语义地图 |
| 全局规划器 | "先去喷泉,再右拐" | 高层决策 |
| 局部控制器 | 脚和眼睛:迈步、转弯、避障 | 底层执行 |
| VGGT-Adapter | 空间直觉:"这门就是照片那个!" | 几何感知增强器 |
如果你打算复现或部署,这四个模块可以分阶段开发:
先跑通局部控制器 → 再加 SMG 和全局规划 → 最后插 VGGT-Adapter 提升精度。
需要我画个框图、给代码结构,或者推荐每个模块的开源替代方案吗?