今天在网上看到一篇教学分享,一个博主说很多人有个错误的观念:虽然可以使用GPU跑模型,但是大家都认为自己电脑只有一个显卡,然后参数workers>0的时候就会报错,所以默认都设置workers=0就不会报错。
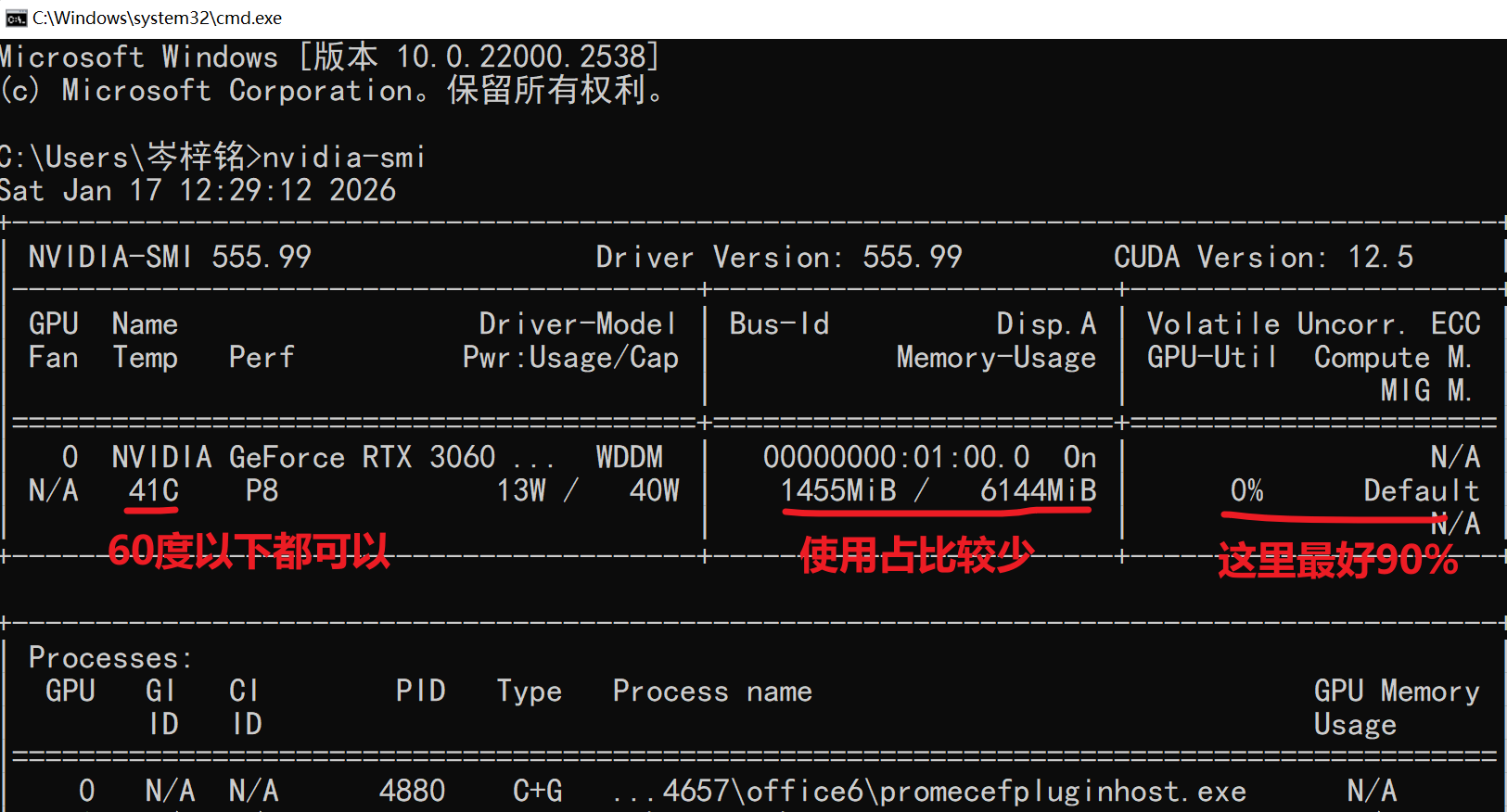
但实际这样并没有最大程度利用我们的GPU,我们输入命令【nvidia-smi】可以看到我们的显卡信息就可以看到我们是并没有充分利用的
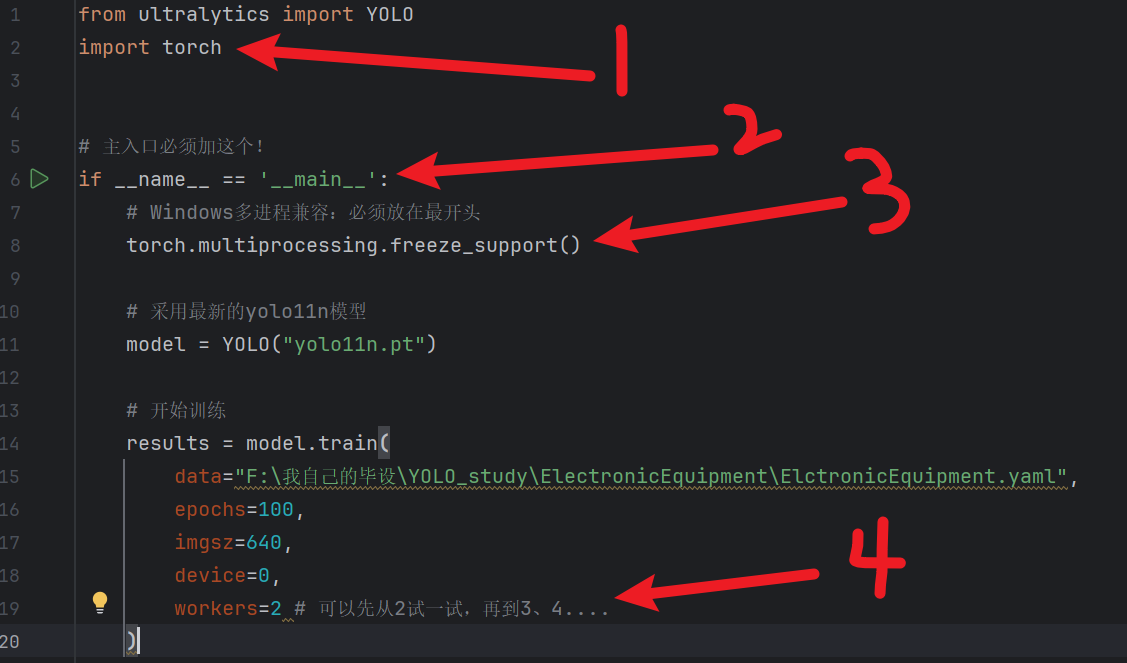
解决方法就是:
- 把训练代码放到
if __name__ == '__main__':代码块里
- Windows 下开启
workers>0必须满足用【if __name__ == '__main__':】包裹训练逻辑- 在块的最开头加
torch.multiprocessing.freeze_support()

例子
速度将会直线飞升!!!!!!!!