接上篇:【Linux内核八】进程管理模块:进程调度队列Struct rq
上篇将进程的等待队列rq结构简单的记录了一下。提到队列,内核中还有一个比较常用的结构:队列钩子结构------list_head。
队列钩子结构:list_head
在内核中,很多都是采用了双向列表。而双向列表的主要结构就是list_head
c
struct list_head {
struct list_head *next, *prev;
};这个结构非常的简单,实际上这各结构就是一个钩子,连接前面和后面的两个实体,任何的一个实体都可以拥有这样一个钩子,用来挂在一个队列上。
task_struct中的tasks,使用list_head构造全进程双向链表
task_struct中的tasks成员变量,配合上面的list_head结构一起,就可以将所有的进程结构串起来,形成一个双向链表。
每个task都可以通过list_head结构的tasks钩子,很方便的找到前一个和后一个链表成员。
c
struct list_head tasks;
对于这样一个钩子结构,内核中的任何结构体,如果需要形成一个双向列表,都可以再结构体中增加一个list_head XXX的成员即可实现。
利用钩子结构看current进程的前后进程信息
c
// 辅助函数:输出进程核心信息
static void print_task_info(struct task_struct *task, const char *desc)
{
printk(KERN_INFO "===== %s =====\n", desc);
printk(KERN_INFO "进程PID:%d\n", task->pid); // 进程ID
printk(KERN_INFO "进程名:%s\n", task->comm); // 进程名
printk(KERN_INFO "进程状态:%ld\n", task->__state); // 进程状态(0=运行态,1=睡眠态等)
}
// 1. 模块初始化函数(加载模块时执行,对应insmod命令)
// __init:告诉内核这个函数只在初始化时用,执行后可释放内存
static int __init hello_kernel_init(void)
{
struct task_struct *prev_task, *next_task;
// 内核打印用printk,KERN_INFO是日志级别(对应dmesg的info级)
// current是内核全局指针,指向当前运行的进程
printk(KERN_INFO "=== Hello Kernel! ===\n");
printk(KERN_INFO "Current PID: %d\n", current->pid);
printk(KERN_INFO "Current process name: %s\n", current->comm);
prev_task = list_prev_entry(current, tasks);
print_task_info(prev_task, "current的前一个进程");
next_task = list_next_entry(current, tasks);
print_task_info(next_task, "current的后一个进程");
// 返回0表示初始化成功,非0则加载失败
return 0;
}dmesg的输出为:
bash
[ 923.813769] Current PID: 5628
[ 923.813770] Current process name: insmod
[ 923.813771] ===== current的前一个进程 =====
[ 923.813772] 进程PID:5627
[ 923.813773] 进程名:systemd-udevd
[ 923.813774] 进程状态:1
[ 923.813775] ===== current的后一个进程 =====
[ 923.813775] 进程PID:0
[ 923.813776] 进程名:swapper/0
[ 923.813776] 进程状态:0list_prev_entry和list_next_entry宏定义
在上面的代码中,list_prev_entry和list_next_entry是比较奇怪的用法,在整个函数中没有tasks的变量,如果list_prev_entry和list_next_entry是函数的话,是会报错的。
但是list_prev_entry和list_next_entry这两个货是一个宏定义,只是把tasks这个串作为宏定义的参数传入宏,真正的函数执行在后面。
这两个宏定义在include/linux/list.h中:
c
/**
* list_next_entry - get the next element in list
* @pos: the type * to cursor
* @member: the name of the list_head within the struct.
*/
#define list_next_entry(pos, member) \
list_entry((pos)->member.next, typeof(*(pos)), member)
/**
* list_prev_entry - get the prev element in list
* @pos: the type * to cursor
* @member: the name of the list_head within the struct.
*/
#define list_prev_entry(pos, member) \
list_entry((pos)->member.prev, typeof(*(pos)), member)把上面的代码list_next_entry(current, tasks)展开后就是:
c
list_entry(current->tasks.prev, typeof(*(current)), tasks)再看看list_entry。
真正实现双向链表遍历:list_entry宏
list_entry也是一个宏定义:
c
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)而container_of是内核的 "地址偏移神器":
c
#define container_of(ptr, type, member) ({ \
// 1. 计算member在type结构体中的偏移量
const typeof(((type *)0)->member) *__mptr = (ptr); \
// 2. 用节点地址 - 偏移量 = 结构体首地址
(type *)((char *)__mptr - offsetof(type, member)); \
})根据list_entry传入的内容,也就是找到current进程结构体(task_struct)的tasks的地址。
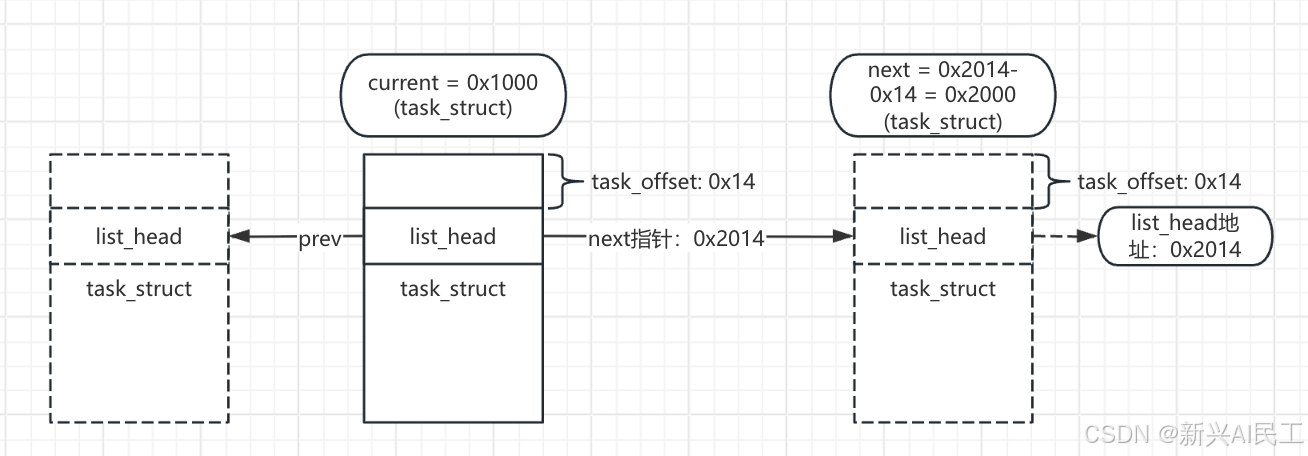
假设:
- current(当前进程)的task_struct首地址是0x1000;
- tasks在task_struct中的偏移是0x14(即offsetof(task_struct, tasks)=0x14);
- current->tasks.next指向的下一个list_head节点地址是0x2014(属于另一个进程的tasks节点)。
- 执行list_entry(current->tasks.next, struct task_struct, tasks):
- offsetof(struct task_struct, tasks) → 计算出tasks在task_struct中的偏移0x14;
(char *)0x2014 - 0x14 → 得到0x2000(下一个task_struct的首地址); - 强制转换为struct task_struct * → 拿到下一个进程的完整结构体。
这一段有点绕,我画一张图来说明一下:
对应到上面的宏定义里面去,container_of(ptr, type, member):
-
ptr就是tasks->next,也就是上图中的0x2014。
-
代码const typeof(((type *)0)->member) *__mptr = (ptr); 就是获得这个指针的类型,也就是member, 也就是tasks,也就是类型是list_head的结构体类型的指针,此时的__mptr也还是0x2014。
-
代码offsetof(type, member)),就是计算这个member到这个type(task_struct)的偏移量,也就是图中的0x14.
-
offsetof也是一个宏定义:
c#define offsetof(type, member) ((size_t)&((type *)0)->member) -
(type *)0:将数字0强制转换为type类型的结构体指针(比如struct task_struct *),相当于 "假设结构体首地址在内存 0 地址处";
-
((type *)0)->member:访问这个 "0 地址结构体" 的member成员(比如tasks);
-
&((type *)0)->member:取这个成员的地址 ------ 因为结构体首地址是 0,成员地址就是它在结构体中的偏移量;
-
(size_t):将地址值转换为size_t(无符号整数),得到最终的偏移量(字节数)。
-
-
最后再用0x2014 - 0x14就可以得到下一个结构体的首地址了。
-
最后在调用list_entry的最外层,强制转换成tast_struct的结构体就可以了。
-
所有的过程都是通过宏定义来实现所有结构体类型的适配,所以任何结构体想形成一个双向链表,只需要在结构体中定义一个list_head的成员变量就可以了。
学习使用offsetof的方式
之前没有想到过有这种方式来求一个结构体中的偏移量,试了一个:
c
struct demo_s{
int a;
int b;
int c;
};
size_t s = ((size_t)&((demo_s *)0)->c);
cout << s << endl;输出就是8。
又学习到了一些奇奇怪怪的知识。
之前代码中的一些宏定义函数
在内核中还定义了一些常用的宏定义
其中有一个就是和这个list_head的双向列表有关:init_task。也就是这个双向列表的第一个元素。
可以直接通过代码验证一下:
c
extern struct task_struct init_task; // 是一个在其他地方定义的全局变量,导入即可。
printk(KERN_INFO "init task name: %s\n", init_task.comm);
bash
[59801.979963] init task name: swapper/00号进程
系统启动时,内核会先创建init_task(0 号进程):swapper。
在init_task.h中有一个宏定义:
c
#define INIT_TASK_COMM "swapper"简单了解了一下这个0号进程:swapper:
0 号进程(init_task)的进程名在x86 架构下默认是 swapper,在 ARM 等架构下可能是 idle------
本质上它是内核的空闲进程,是 Linux 系统中最基础、最特殊的内核态进程,核心作用是CPU 空闲时 "兜底运行",同时也是系统启动的
"创世进程"。下面从名字由来、核心功能、运行机制三个维度讲透: 一、为什么叫 swapper?名字的历史渊源 swapper
这个名字是Linux 内核的 "历史遗留产物",背后对应了它早期的核心功能: 早期内核的内存交换职责 在 Linux 0.1x
等早期版本中,0 号进程不仅是空闲进程,还负责内存页面的换入 / 换出(swap)------
当内存不足时,它会把不活跃的进程数据写到磁盘交换分区,腾出内存给活跃进程。因此被命名为 swapper。 现代内核的职责分离
随着内核发展,内存交换功能被拆分给了专门的内核线程(如 kswapd0),0 号进程不再负责 swap。但 swapper 这个名字在
x86 架构中被保留了下来,成为一种历史习惯。 不同架构的命名差异 x86/x86_64:沿用历史名称 swapper;
ARM/ARM64:更贴合现代功能,命名为 idle(直接体现 "空闲" 属性); 本质上两者是同一个进程,只是名字不同。 二、0
号进程(swapper)的核心作用 它是内核态进程,没有用户空间代码,也不执行任何业务逻辑,核心职责有 3 个:
- CPU 空闲时的 "兜底进程"------ 避免 CPU "无事可做" 这是 0 号进程最核心的功能。 调度逻辑:当 CPU 上没有任何可运行的进程(包括用户进程、其他内核线程)时,调度器会选择 0 号进程运行; 核心动作:0 号进程执行 cpu_idle()
函数,让 CPU 进入低功耗状态(如 x86 的 HALT 指令、ARM 的 WFI 指令),直到有新的进程被唤醒(如中断触发);
性能意义:如果没有这个兜底进程,CPU 会陷入 "空循环",导致功耗飙升、温度升高。0 号进程的存在是 Linux 系统节能的关键机制之一。