目录
[一. 前言](#一. 前言)
3.使用vscode打开刚才下载的yolo库文件ultralytics-main
[1.打开train.py ,前面已经创建的,没有创建就创建一个,将下面代码复制进去。](#1.打开train.py ,前面已经创建的,没有创建就创建一个,将下面代码复制进去。)
2.在ultralytics-main目录新建一个data目录-->放入自己的数据集。
3.新建一个.yaml的文件,内需要根据自己打标时定义的class名填写。
4.复制一份官方的yolo11.yaml改名为yolo11_cap.yaml,并修改下面内容,其他不用修改。
一. 前言
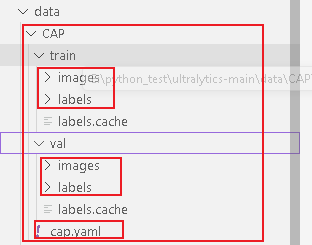
yolov11的数据集格式需要是如下:

我这里省去了test测试集的图片。
如果需要自己训练数据集和标注的可以看这一篇文章,ISAT标注教程。
二.yolo下载并配置环境
1.下载yolo
官网链接:https://github.com/ultralytics/ultralytics
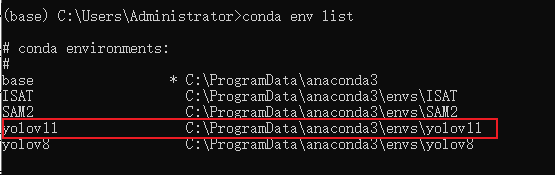
2.使用anacoda创建虚拟环境
可以创建一个名叫yolov11的虚拟环境,名字可以随便取。不会创建的看一看这一篇教程,2025最新anaconda安装并创建环境教程。
3.使用vscode打开刚才下载的yolo库文件ultralytics-main
需要提前装好CUDA,cudnn,这里就不给出了,请找其他教程,也可以先安装好这里的库再去安装CUDA,cudnn。
下一步是安装pytroch ,需要选择和CUDA对应的torch版本,
我安装的是12.6对应的版本,官方链接:https://pytorch.org/get-started/previous-versions/
如果遇到错误请多问问AI。
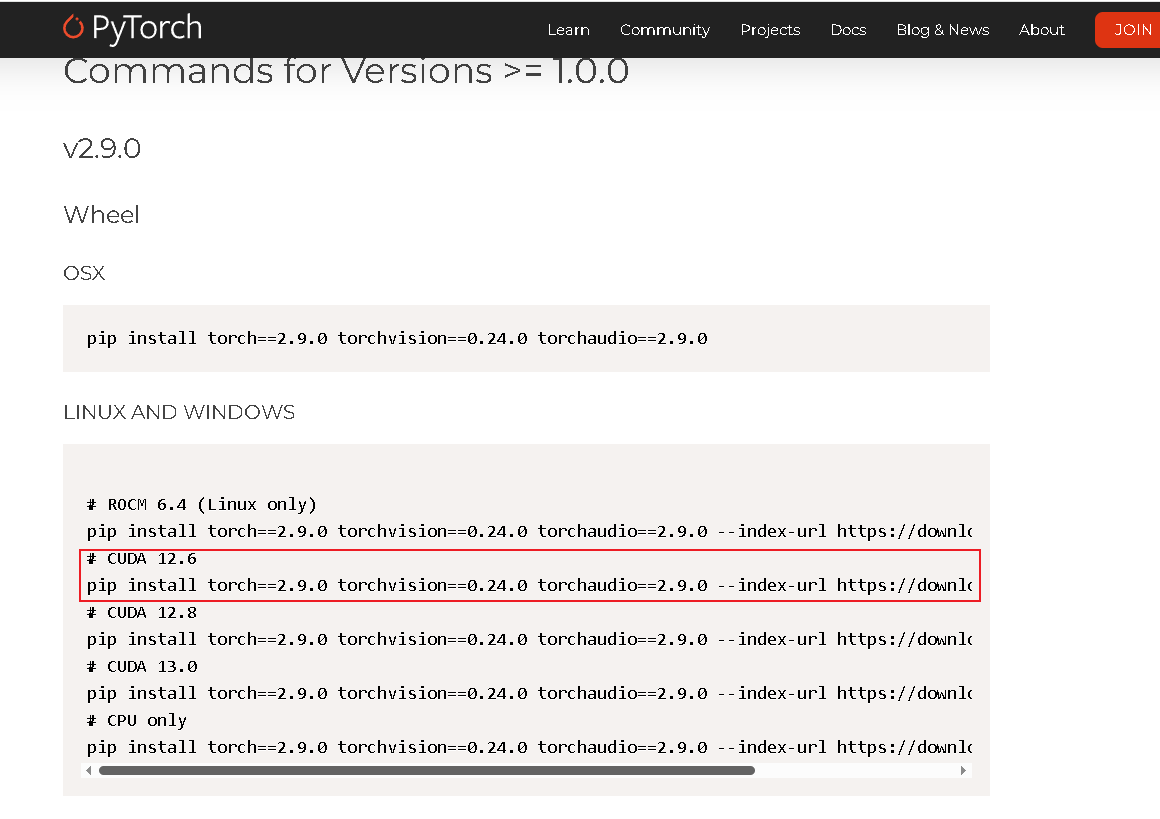
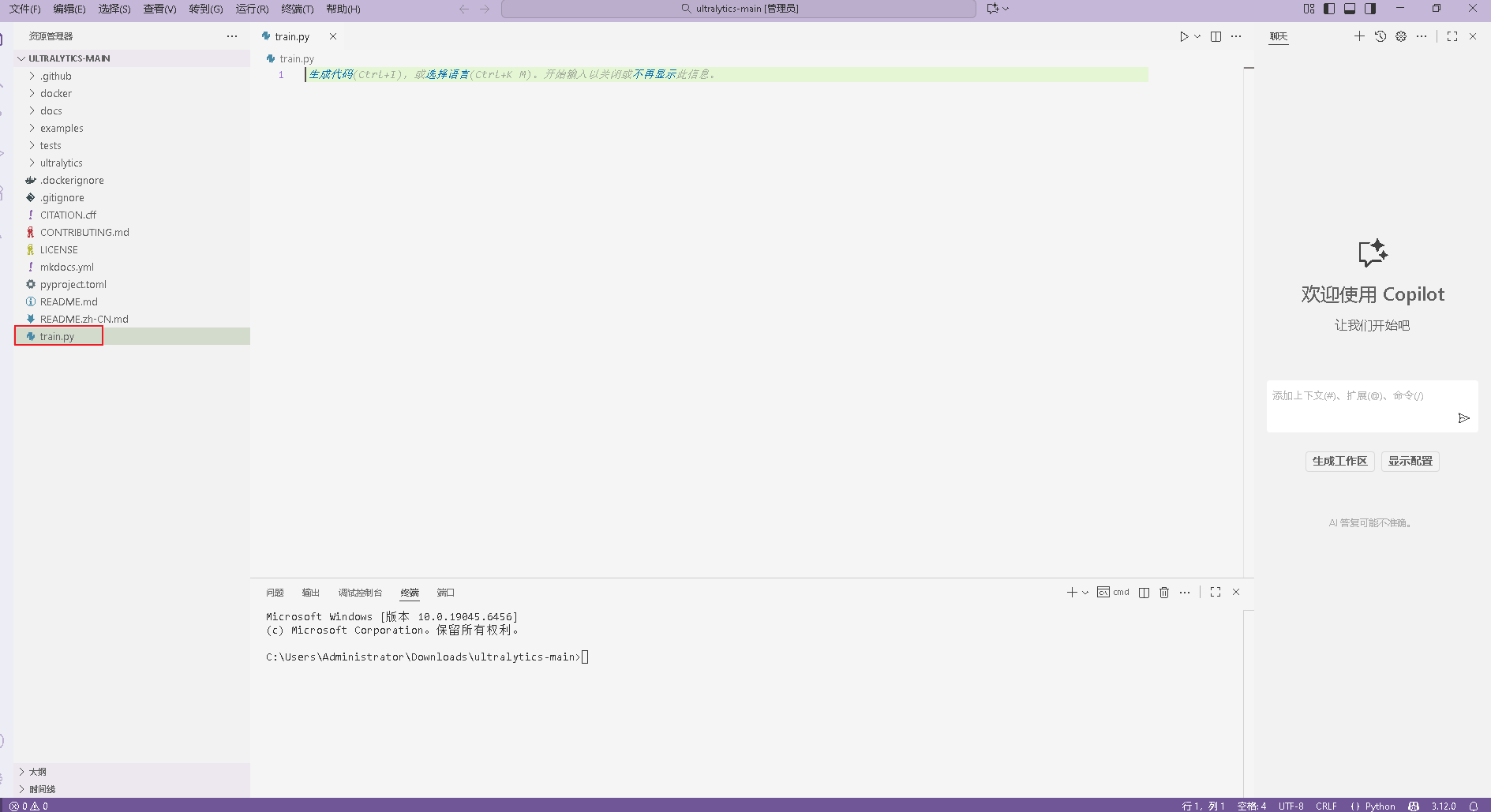
新建一个名为train.py的python文件
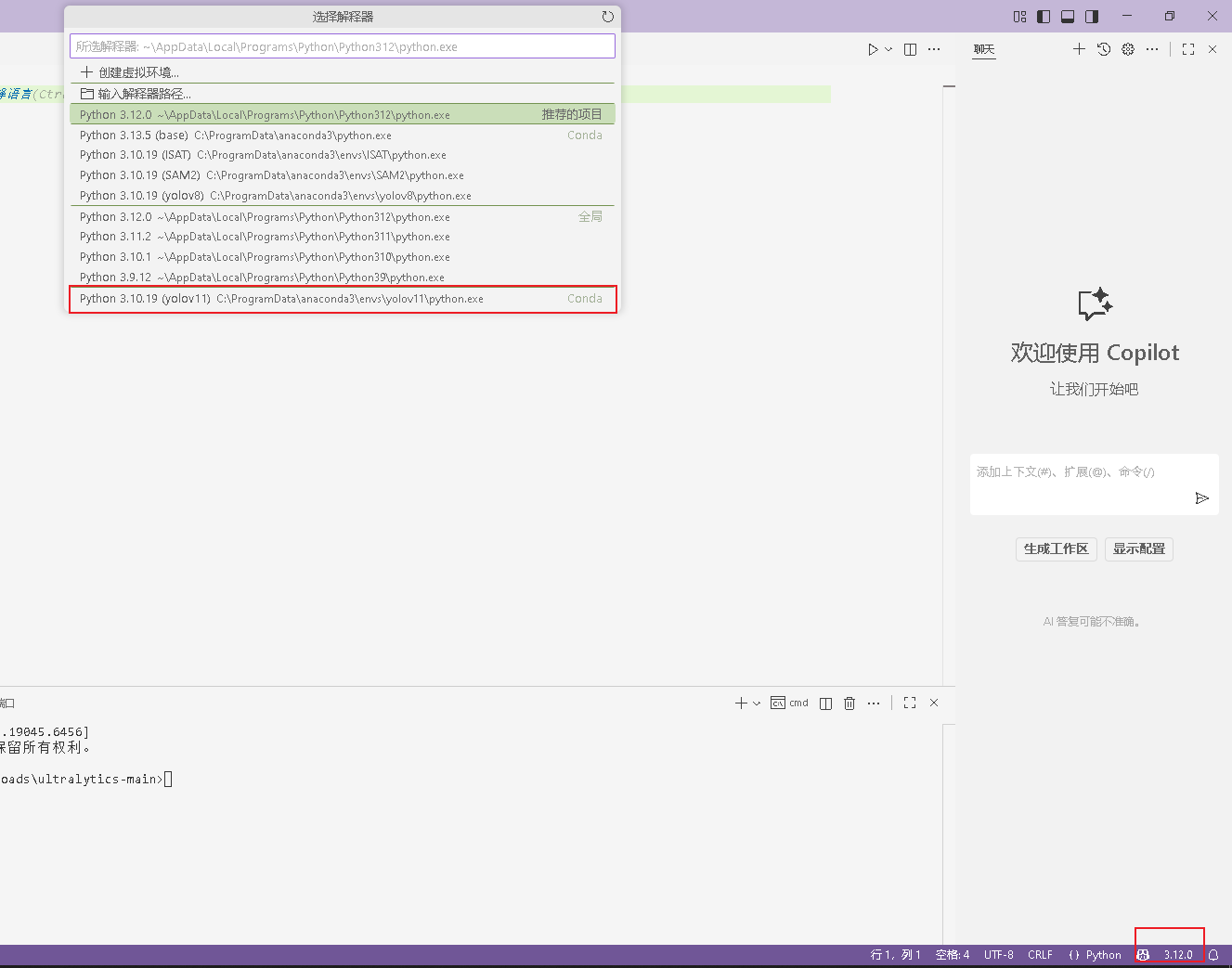
点击右下角的标志,弹出弹窗,选择刚才创建的yolov11虚拟环境
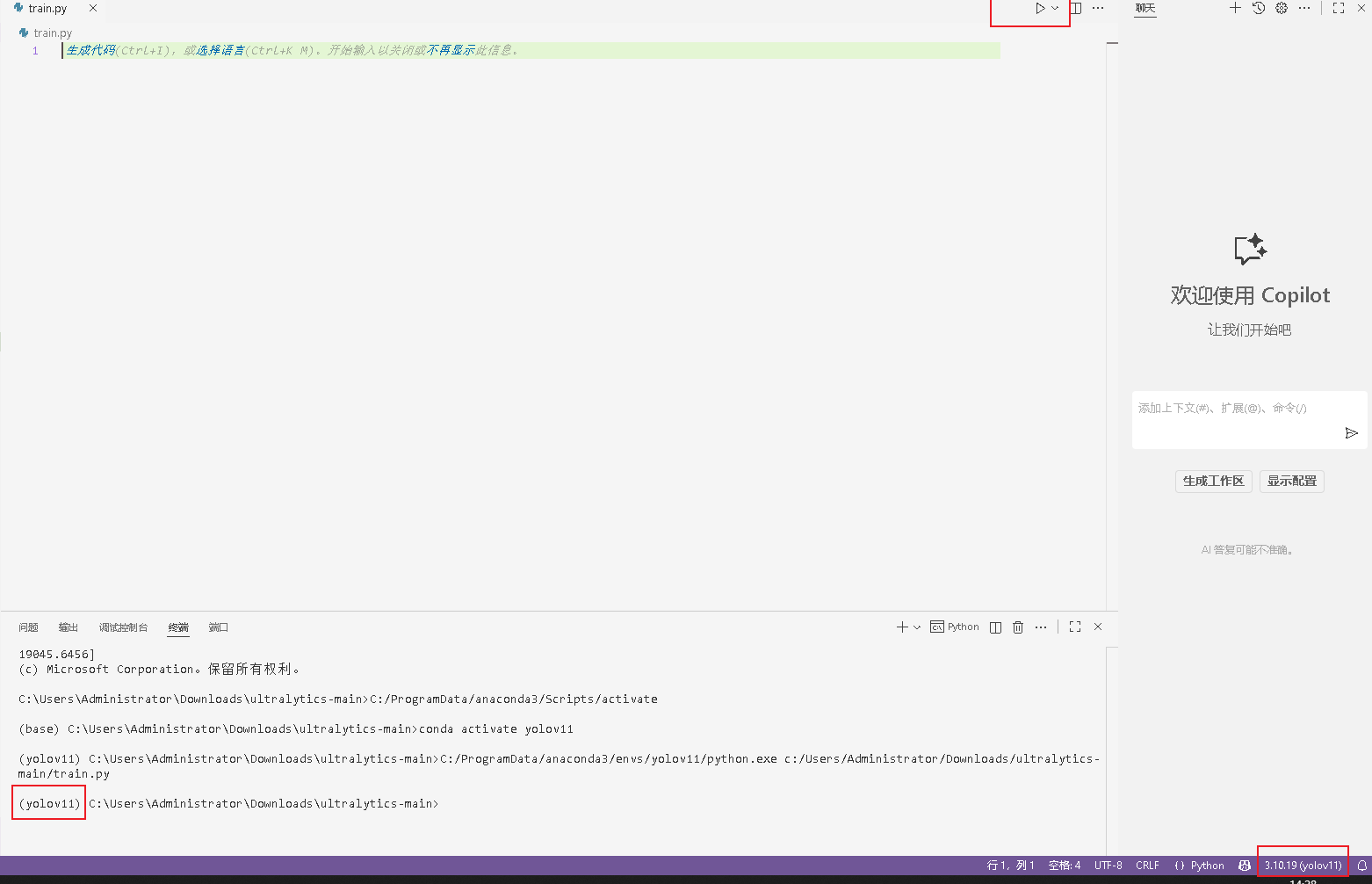
点击运行可以看到已经切换成yolov11的虚拟环境了
之后就是安装所有需要的库
新建一个文件 命名为 requirements.txt
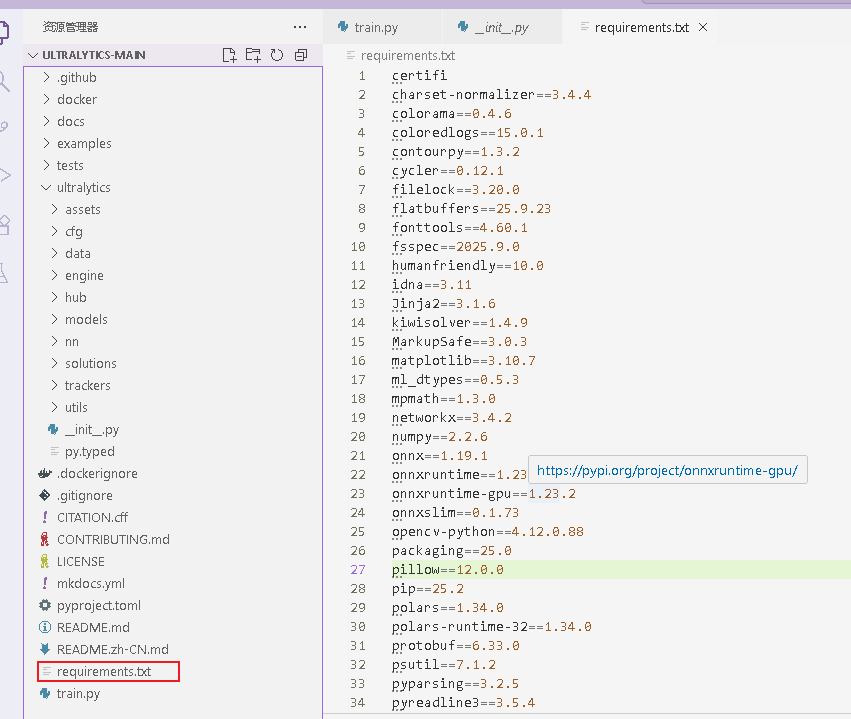
执行安装库命令 pip install -r requirements.txt
certifi
charset-normalizer==3.4.4
colorama==0.4.6
coloredlogs==15.0.1
contourpy==1.3.2
cycler==0.12.1
filelock==3.20.0
flatbuffers==25.9.23
fonttools==4.60.1
fsspec==2025.9.0
humanfriendly==10.0
idna==3.11
Jinja2==3.1.6
kiwisolver==1.4.9
MarkupSafe==3.0.3
matplotlib==3.10.7
ml_dtypes==0.5.3
mpmath==1.3.0
networkx==3.4.2
numpy==2.2.6
onnx==1.19.1
onnxruntime==1.23.2
onnxruntime-gpu==1.23.2
onnxslim==0.1.73
opencv-python==4.12.0.88
packaging==25.0
pillow==12.0.0
pip==25.2
polars==1.34.0
polars-runtime-32==1.34.0
protobuf==6.33.0
psutil==7.1.2
pyparsing==3.2.5
pyreadline3==3.5.4
python-dateutil==2.9.0.post0
PyYAML==6.0.3
requests==2.32.5
scipy==1.15.3
setuptools==80.9.0
six==1.17.0
sympy==1.14.0
#torch==2.9.0+cu126
#torchvision==0.24.0+cu126
tqdm==4.67.1
#typing_extensions==4.15.0
ultralytics==8.3.221
ultralytics-thop==2.0.17
urllib3==2.5.0
wheel==0.45.1如果遇到版本不同,或库不存在这个版本,需要查找AI,让他给出适合的版本。
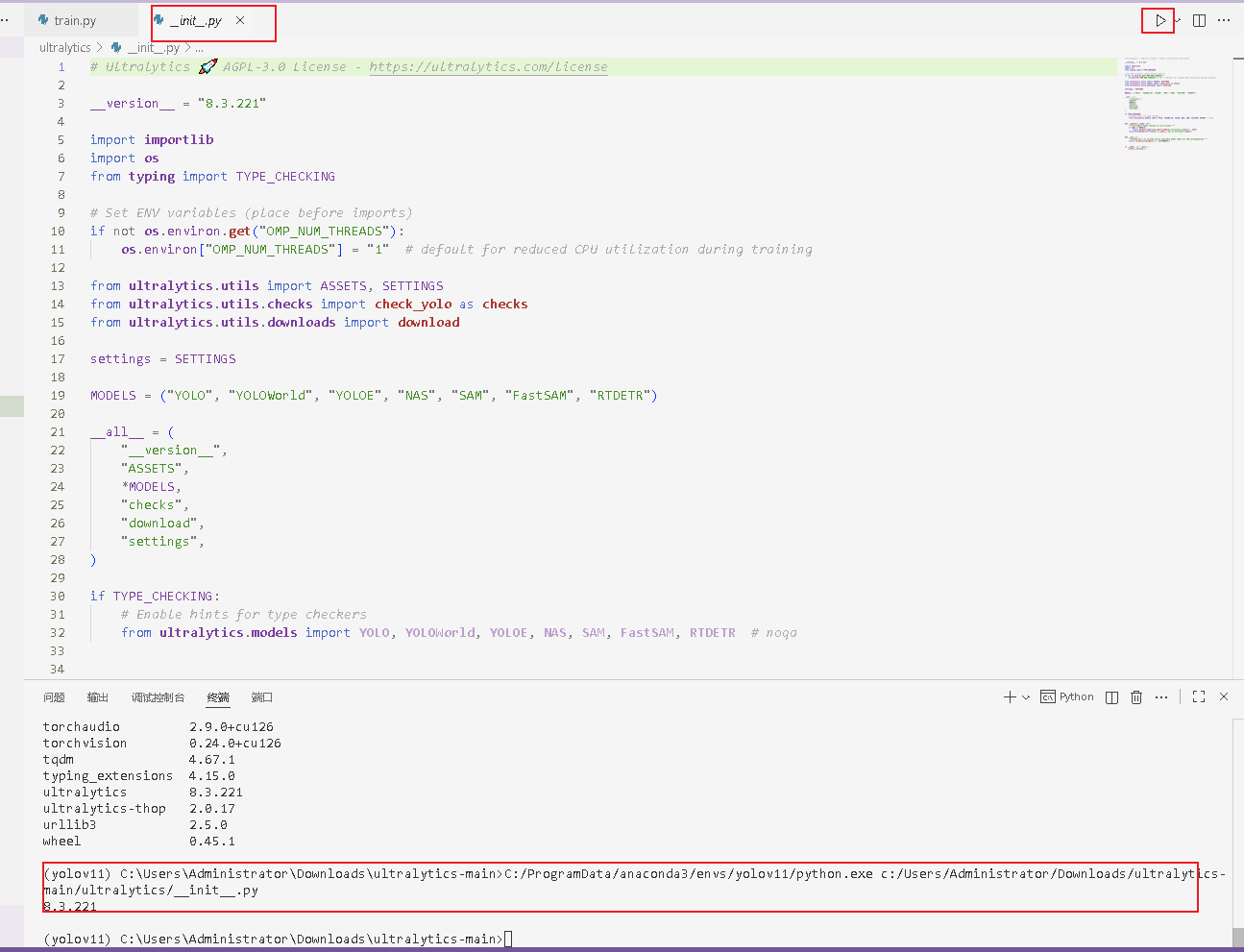
环境安装完成,运行_init_.py测试一下,像这样就可以了
三.训练自己的数据集
1.打开train.py ,前面已经创建的,没有创建就创建一个,将下面代码复制进去。
python
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO('ultralytics/cfg/models/11/yolo11_cap.yaml') # 指定YOLO模型对象,并加载指定配置文件中的模型配置
#model.load('yolov8s.pt') #加载预训练的权重文件'yolov8s.pt',加速训练并提升模型性能
model.train(data='data/CAP/cap.yaml', # 指定训练数据集的配置文件路径,这个.yaml文件包含了数据集的路径和类别信息
cache=False, # 是否缓存数据集以加快后续训练速度,False表示不缓存
imgsz=640, # 指定训练时使用的图像尺寸,640表示将输入图像调整为640x640像素
epochs=200, # 设置训练的总轮数为200轮
batch=16, # 设置每个训练批次的大小为16,即每次更新模型时使用16张图片
close_mosaic=10, # 设置在训练结束前多少轮关闭 Mosaic 数据增强,10 表示在训练的最后 10 轮中关闭 Mosaic
workers=8, # 设置用于数据加载的线程数为8,更多线程可以加快数据加载速度
patience=50, # 在训练时,如果经过50轮性能没有提升,则停止训练(早停机制)
device='0', # 指定使用的设备,'0'表示使用第一块GPU进行训练
optimizer='SGD', #设置优化器为SGD(随机梯度下降),用于模型参数更新
)2.在ultralytics-main目录新建一个data目录-->放入自己的数据集。
3.新建一个.yaml的文件,内需要根据自己打标时定义的class名填写。
python
train: ./train/images #训练集路径
val: ./val/images #验证集路径
nc: 3 #class数量
names: ["Capacitor", "Negative", "Positive"] #class名称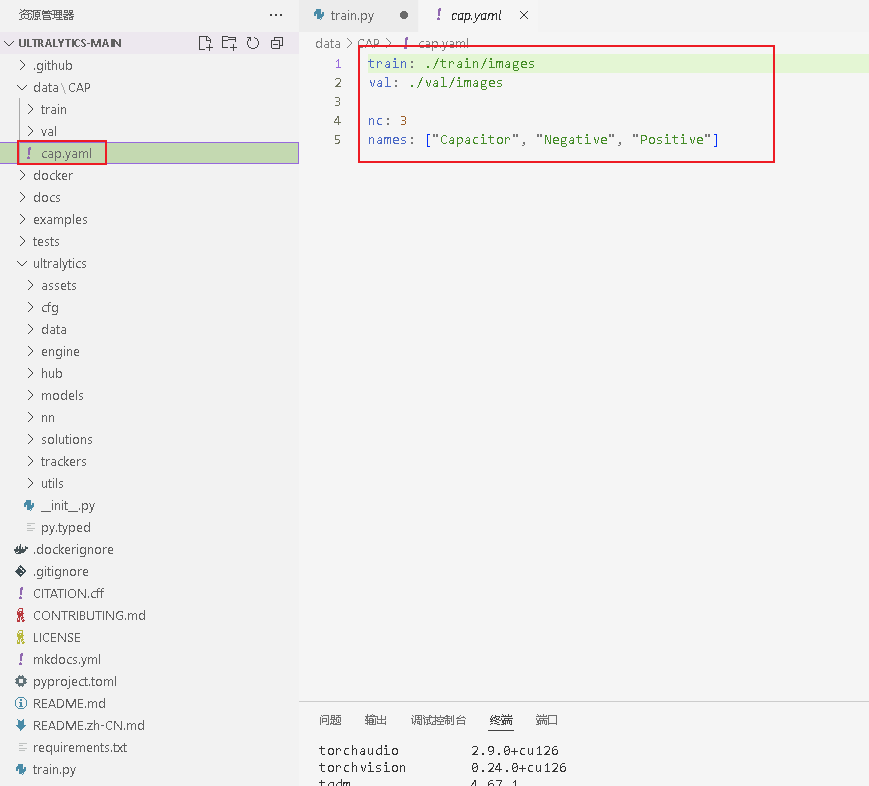
4.复制一份官方的yolo11.yaml改名为yolo11_cap.yaml,并修改下面内容,其他不用修改。
python
nc: 3 #表示目标检测的类别总数
names: ["Capacitor", "Negative", "Positive"] #表示类别名称列表,与 nc 对应
scales: #YOLO 系列的 "复合缩放" 参数,用于生成不同大小的模型
s: [0.50, 0.50, 1024] # summary: 181 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
#每行对应一个模型版本(n 对应 nano,s 对应 small,m 对应 medium,l 对应 large,x 对应 xlarge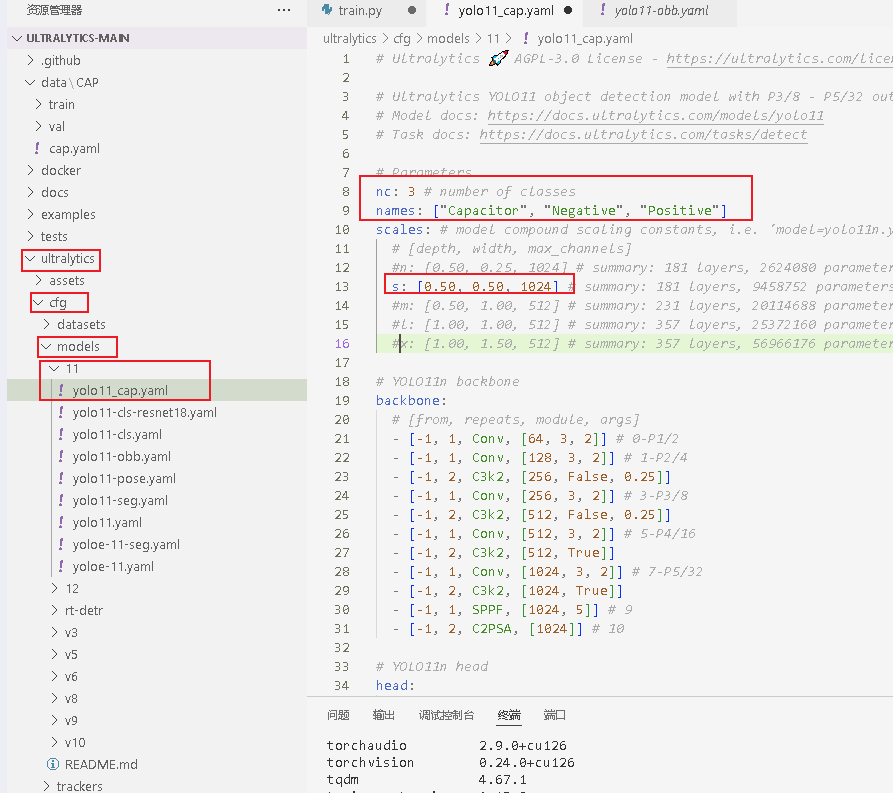
5.回到train.py,注意代码中的两个.yaml路径就是上面创建的文件,运行代码
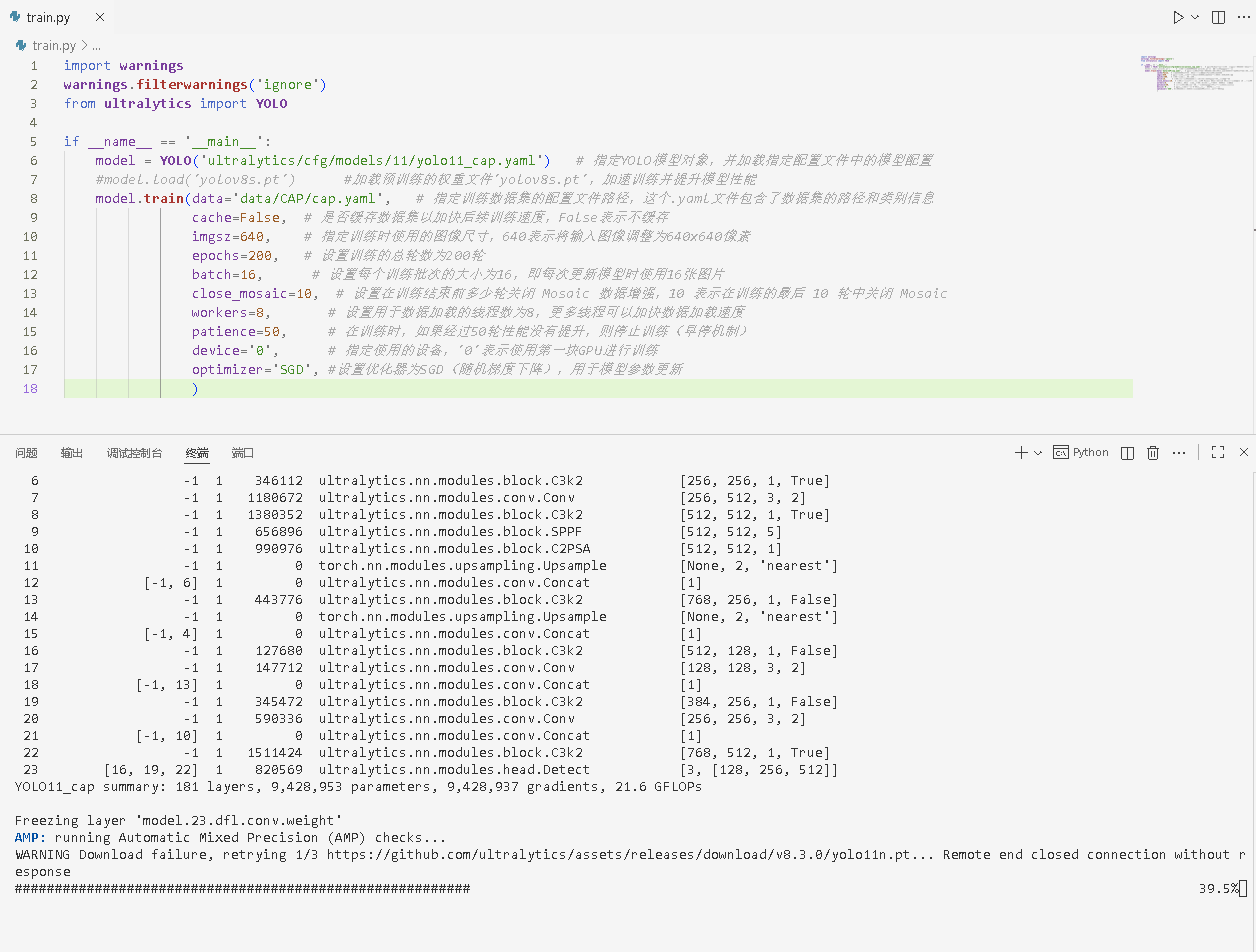
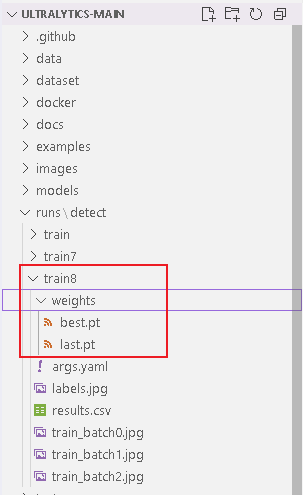
这样等他自己训练完成就会在run目录下生成想要的模型了,best.pt就是生成的最好模型了。