什么是序列化和反序列
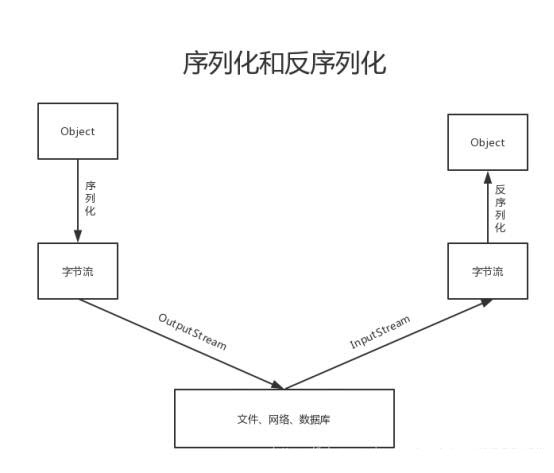
序列化定义:就是把内存中的对象,转换为字节序列,以便于存储到磁盘或网络传输,此过程被称为序列化。
反序列化定义:将字节序列或磁盘中的持久化字节数据,转换为内存中的对象的过程。
hadoop为什么需要序列化和反序列化
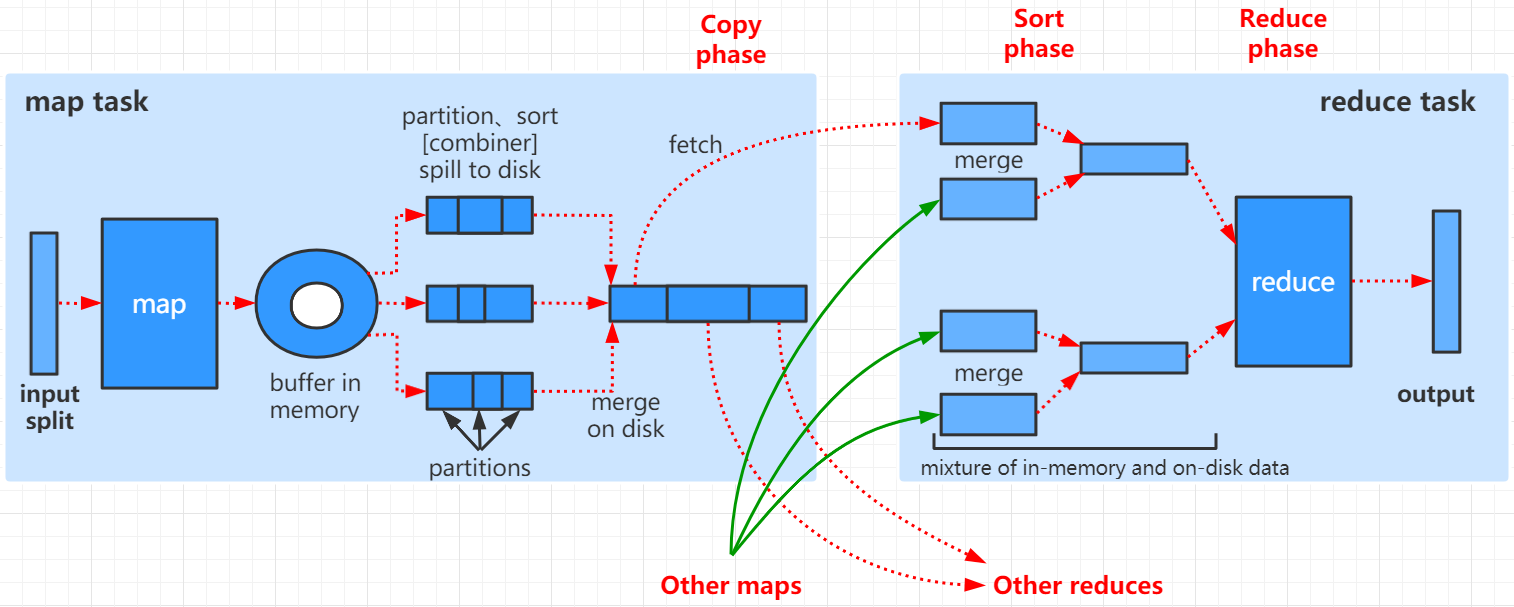
数据经过mapper 任务的处理后,会产生溢出文件,这些文件会被保存到磁盘上。mapper任务完成后,reducer会通过http get的方式从mapper端拷贝对应分区的数据,中间需要经过网络传输。需要做持久化(存盘)或网络传输,这中间就需要做数据的序列化和反序列操作。
为什么不使用Java自带的序列化(Serializable)
Java的序列化是一个偏重量序列化,一个对象被序列化后,会带有很多的额外的信息,比如各种校验信息、继承体系、Header,从而导致体积较大。又由于hadoop处理的数据量一般都比较大,所以该方式不利于数据的传输。
Hadoop序列化的特点:
-
紧凑:节省存储空间
-
快捷:读写数据的额外开销比较小
-
可扩展型更强:可以随着通讯协议升级而升级。
-
跨语言:支持多语言的交互。
如何使用Hadoop的序列化和反序列化
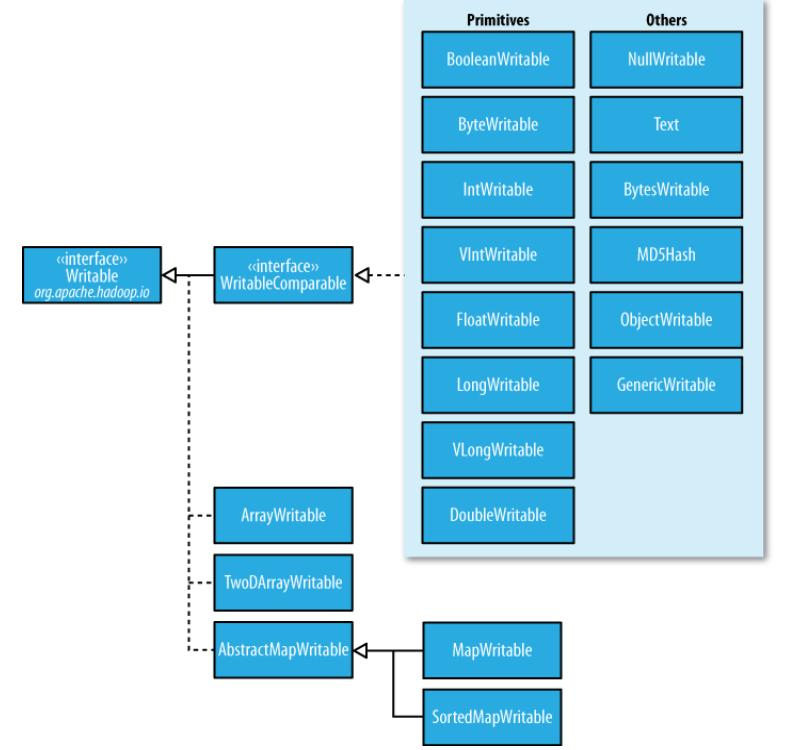
| Java类型 | Hadoop Writable类型 |
|---|---|
| Byte | ByteWritable |
| Int | IntWritable |
| Long | LongWritable |
| Float | FloatWritable |
| Double | DoubleWritable |
| Boolean | BooleanWritable |
| String | Text |
| Map | MapWritable |
| Array | ArrayWritable |
| Null | NullWritable |
有些时候这些基本的类不能满足我们的开发需求,需要自定义类,那么这些自定义的类如何实现序列化和反序列化呢?
具体实现的步骤如下:
-
实现Writable接口
-
预置一个空的构造函数,这是因为在发序列化时会被调用的
java
public Xxx(){
super();
}3.重写序列化的方法
java
@Override
public void write(DataOutput out) throws IOException{
out.writeInt(age);
out.writeLong(xx);
....
}4.重写反序列化的方法
java
@Override
public void readFields(DataInput in) throws IOException{
age = in.readInt();
xx = in.readLong();
....
}顺序一定要保持一致,先序列化的谁,一定要先反序列化谁。
5.重写类的toString()方法
6.如果该类需要作为Mapper的key中使用,还需要实现Comparable接口,这是因为Shuffle过程中需要对Mapper的key做排序。