三种安装方式区别
Hive中metastore (元数据存储)的三种模式:
a)内嵌Derby模式
b)直连数据库模式
c)远程服务器模式
内嵌 Derby 模式
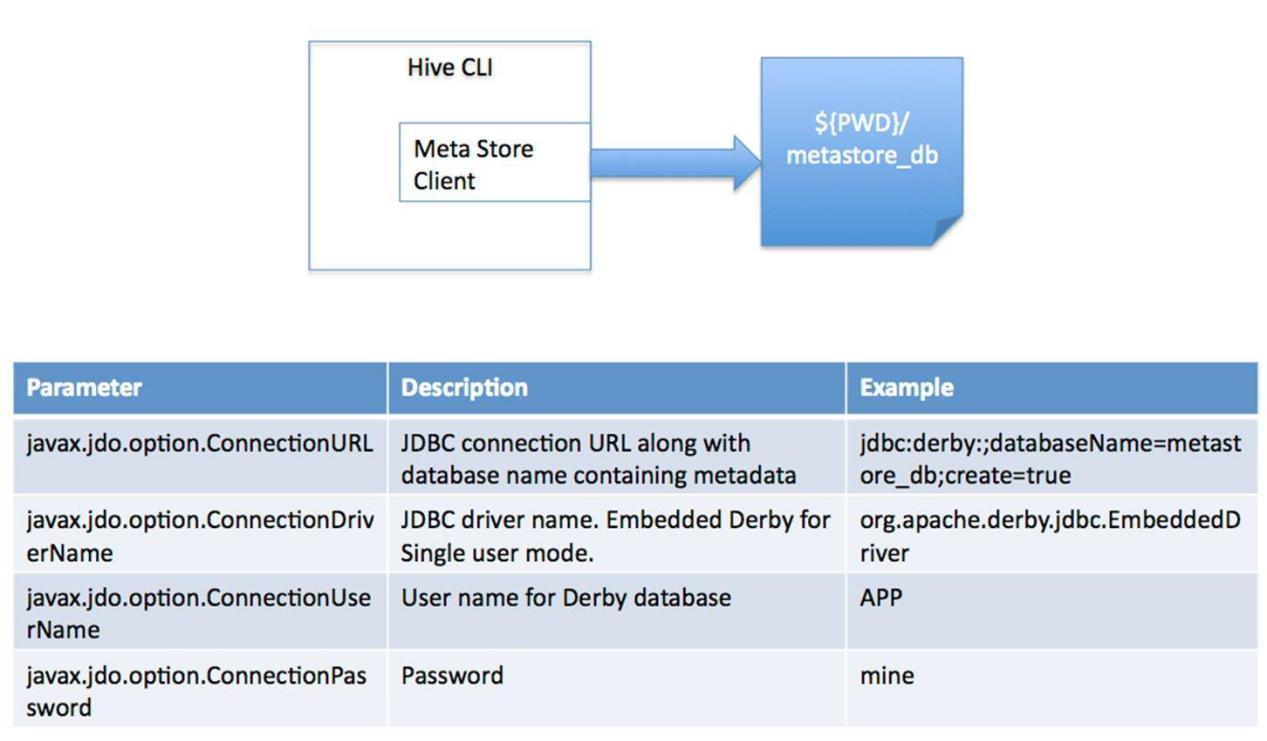
此模式连接到一个In-memory 的数据库Derby ,一般用于Unit Test(单元测试目前用的也少), 一台服务器即可,基本不用。
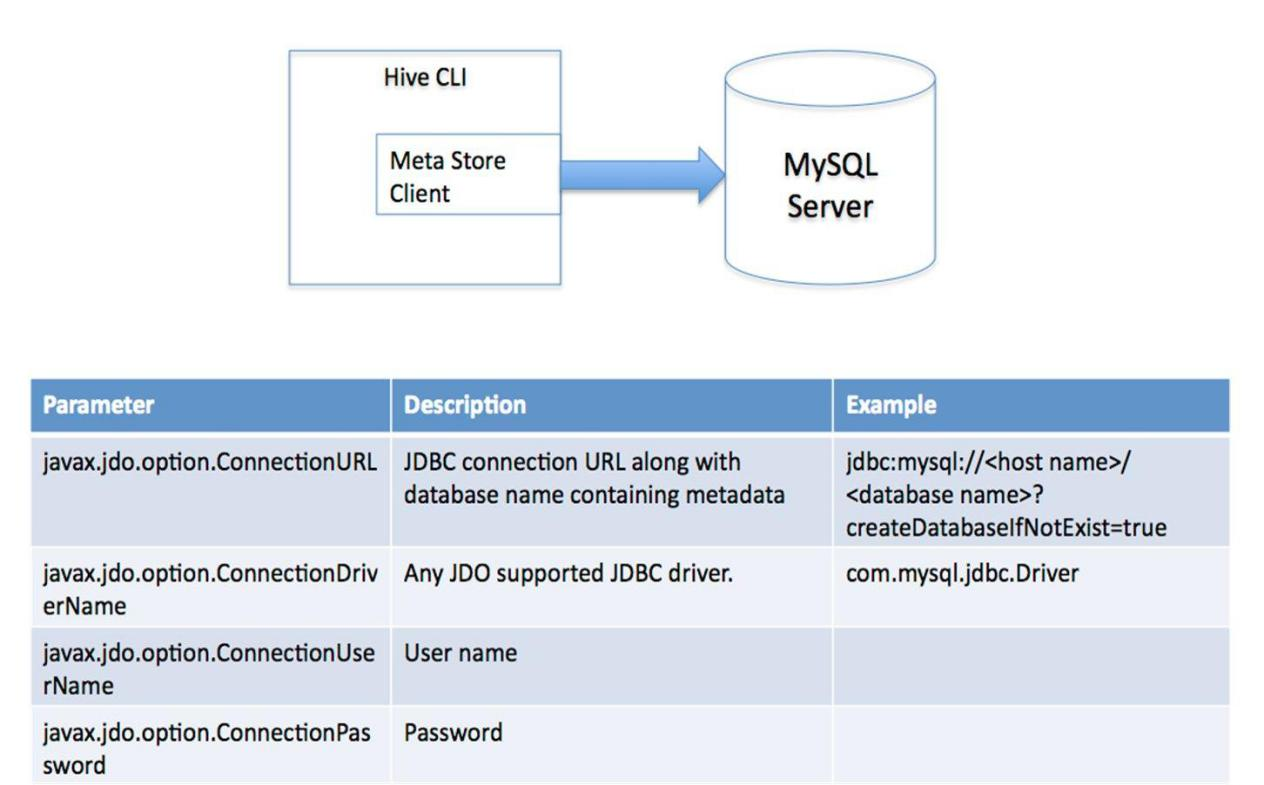
直连数据库模式( mysql )
通过网络连接到一个数据库中。
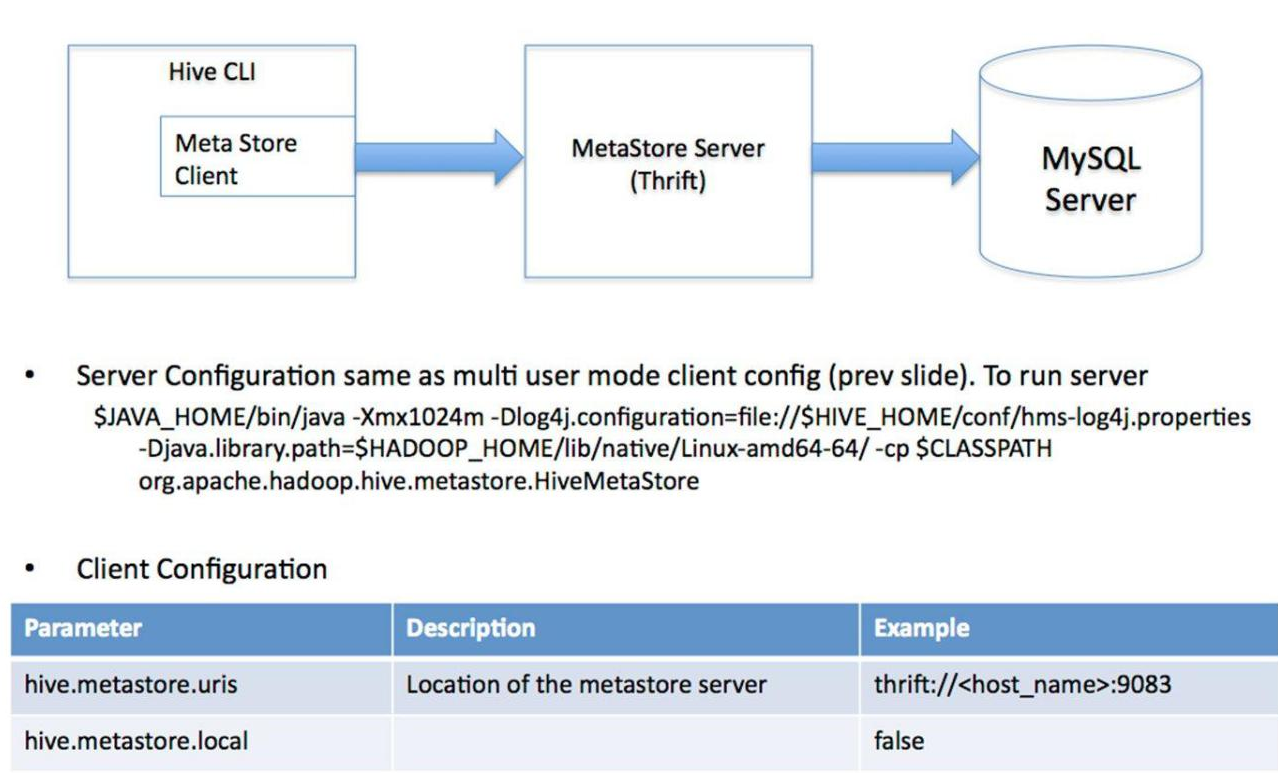
 远程服务模式
远程服务模式
用于非Java客户端访问元数据库,在服务器端启动MetaStoreServer,客户端利用Thrift协议通过MetaStoreServer访问元数据库。起到了解耦的作用,如果更换其他数据库只需要修改MetaStoreServer即可。
官方文档介绍
下载地址
-
Hive官网地址: http://hive.apache.org/
-
下载地址
https://dlcdn.apache.org/hive/
以下网址可以选择的版本更加全面:
http://archive.apache.org/dist/hive/
- 文档查看地址
https://hive.apache.org/docs/latest/
- github地址:https://github.com/apache/hive
Metadata
默认情况下Metadata(元数据存储)在嵌入式Derby数据库中,其磁盘存储位置由名为javax.jdo.option.Connectionurl的hive配置变量决定。默认情况下,此位置为./metastore_db(参见conf/hive-default.xml)。在嵌入式模式下使用Derby最多一次允许一个用户。若要将Derby配置为在服务器模式下运行,请参见服务器模式下使用Derby的Hive。若要为Hive元存储配置除Derby以外的数据库,请参见:Apache Hive : AdminManual Metastore Administration
MySQL安装
Hive 3.1.2对关系型数据库版本要求如下:
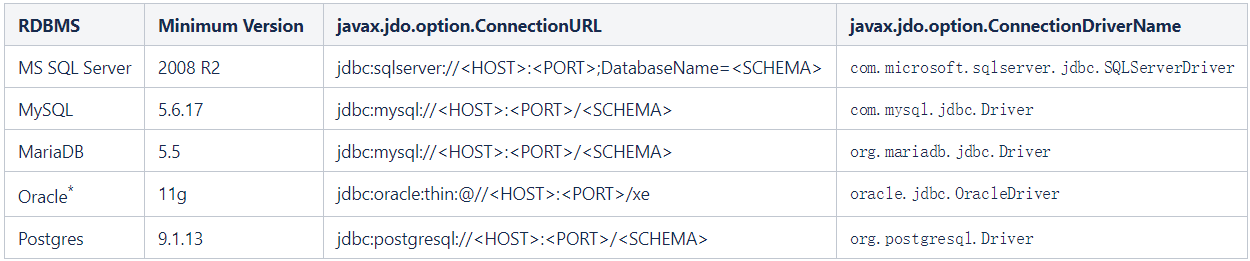
先将四台虚拟机拍快照(安装出问题的时候方便回退到初始状态),然后再进行安装, node1上安装:
1.将mysql的五个rpm包上传到/opt/apps目录
下载链接:https://download.csdn.net/download/m0_62491477/92566309
[root@node1 ~]# cd /opt/apps
#拷贝mysql的安装的rpm包2.检查当前节点上是否存在MySQL安装包,存在则删除:
bash
[root@node1 apps]# rpm -qa | grep mysql
[root@node1 apps]# rpm -qa | grep mariadb-libs
mariadb-libs-5.5.68-1.el7.x86_64
[root@node1 apps]# rpm -e --nodeps mariadb-libs
#如果不处理 mariadb-libs,后续安装的时候会出现如下错误提示:
错误:依赖检测失败:
mariadb-libs 被 mysql-community-libs-5.7.28-1.el7.x86_64 取代
mariadb-libs 被 mysql-community-libs-compat-5.7.28-1.el7.x86_64 取代
#如果出现上述报错,找到的mysql相关的包都删除,*号指代实际包名, 请实际情况输入完整包名
#rpm -e --nodeps mysql-community-libs-*
#rpm -e --nodeps mysql-community-server-*
#rpm -e --nodeps mysql-community-common-*
#rpm -e --nodeps mysql-community-client-*
#rpm -e --nodeps mysql-community-libs-compat-*3. 检查并删除老版本mysql的开发头文件和库
bash
[root@node1 apps]# find / -iname 'mysql*'
#rm -rf /var/lib/mysql
#rm -f /etc/my.cnf注意:第二步如果有删除,卸载后 /var/lib/mysql 中的数据及 /etc/my.cnf 不会删除,如果确定没用后就手工删除
4. 安装依赖包:net-tools libaio
bash
yum install -y net-tools libaio5. 安装mysql
bash
rpm -ivh mysql-community-*6. 修改/etc/my.cnf文件,设置数据库的编码方式:
bash
[client]
default-character-set=utf8
[mysql]
default-character-set=utf8
[mysqld]
character_set_server=utf87. 初始化数据库
bash
[root@node1 apps]# mysqld --initialize --user=mysql如果出现错误,请查看 /etc/my.cnf 文件中指定的错误 log 日志的文件 :log-error=/var/log/mysqld.log
8. 找到随机密码:
在 /var/log/mysqld.log 中有一行:
A temporary password is generated for root@localhost ,后面就是随机密码

9. 启动服务:systemctl start mysqld
10. 使用随机密码登录mysql数据库:
bash
[root@node1 apps]# mysql -uroot -p
Enter password: 输入临时密码11. 修改默认密码
bash
mysql> set password for 'root'@'localhost'=password('123456');12. 查看编码方式:
bash
mysql> show variables like '%character%';13. 给root设置远程登录权限
bash
mysql>GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123456' WITH
GRANT OPTION;
mysql>FLUSH PRIVILEGES;
mysql> exit
Bye
[root@node1 apps]# mysql -uroot -p123456直连数据库(mysql)模式安装
注意:接下来的这种配置方式,是将 hive 的服务器端和客户端放在一台服务器上( node2 )。如果想通过jdbc 程序访问该 hive 是没有办法的,这是因为 hive 没有开启 hiveserver2 服务。
1. 把apache-hive-3.1.2-bin.tar.gz上传到node2的/opt/apps目录下
2. 解压apache-hive-3.1.2-bin.tar.gz到/opt/目录下面
bash
[root@node2 apps]# tar -zxvf /opt/apps/apache-hive-3.1.2-bin.tar.gz -C /opt/3. 修改apache-hive-3.1.2-bin.tar.gz的名称为hive-3.1.2
bash
[root@node2 apps]# mv /opt/apache-hive-3.1.2-bin/ /opt/hive-3.1.24. 修改/etc/profile,添加环境变量
bash
[root@node2 apps]# vim /etc/profile
#添加内容
# hive环境变量配置
export HIVE_HOME=/opt/hive-3.1.2
export PATH=$PATH:$HIVE_HOME/bin
#使环境变量生效
[root@node2 hive-3.1.2]# source /etc/profile5. 解决日志Jar包冲突
bash
[root@node2 apps]# mv $HIVE_HOME/lib/log4j-slf4j-impl-2.10.0.jar $HIVE_HOME/lib/log4j-slf4j-impl-2.10.0.bak_up20266. 上传MySQL的JDBC驱动到Hive的lib目录下
MySQL的JDBC驱动: https://download.csdn.net/download/m0_62491477/92567162
先解压到本地,再将其中的驱动上传到 Hive 的 lib 目录下 
bash
[root@node2 lib]# pwd
/opt/hive-3.1.2/lib7. 配置Metastore到MySql
- 修改hive-site.xml
bash
[root@node2 apps]# vim $HIVE_HOME/conf/hive-site.xml- 添加如下配置内容:
XML
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- jdbc连接的URL设置 -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node1:3306/hive?useSSL=false</value>
</property>
<!-- jdbc连接的Driver类设置-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- 指定jdbc连接的username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- 指定jdbc连接mysql的password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!-- Hive默认在HDFS的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<!-- Hive元数据存储的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!-- 元数据存储授权 -->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
</configuration>8. 在node1上mysql数据库中创建数据库实例hive
XML
[root@node1 ~]# mysql -uroot -p123456
mysql> create database hive;
Query OK, 1 row affected (0.00 sec)
mysql> use hive
Database changed
mysql> show tables;
Empty set (0.00 sec) # 什么表都没有,根本没有hive的元数据
mysql> quit;
Bye9. 在node2上初始化hive的元数据到mysql数据库的hive实例下
bash
[root@node2 conf]# schematool -initSchema -dbType mysql -verbose10. 在node1的mysql数据库中查看hive实例下表,会发现多了74张表。
直连数据库式启动和使用
1. 启动hadoop集群
在node1上执行startha.sh(脚本参考Yarn资源调度器-CSDN博客),如果有namenode没有启动起来,只需要在对应的节点上执行命令:hdfs --daemon start namenode
2. 在node2上启动hive:
bash
[root@node2 ~]# hive3. 使用hive,创建表:
bash
hive> show databases;
OK
default
Time taken: 0.923 seconds, Fetched: 1 row(s)
hive> show tables;
OK
Time taken: 0.081 seconds
hive> create table tb_test(id int);
OK
Time taken: 1.001 seconds
hive> show tables;
OK
tb_test
Time taken: 0.087 seconds, Fetched: 1 row(s)
hive> create table test(id int,age int);
OK
Time taken: 0.123 seconds
hive> show tables;
OK
tb_test
test4. 访问active的namenode,查看文件列表
http://node2:9870/explorer.html#/user/hive/warehouse
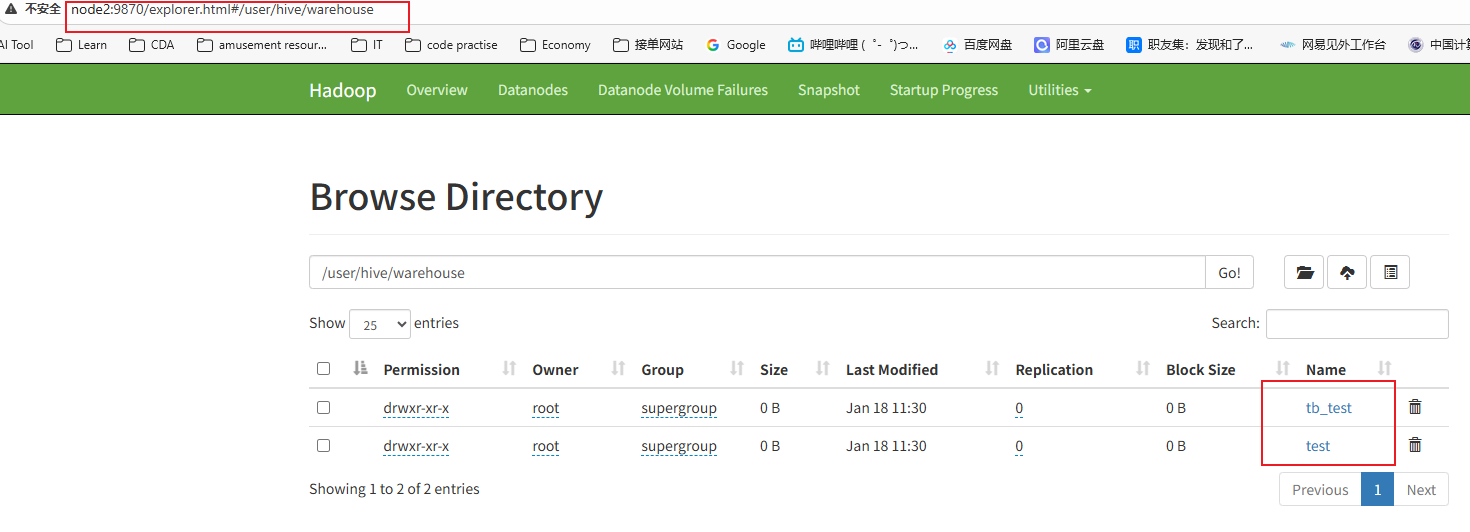
5. 向test表插入数据
bash
hive> insert into test values(1,1);6.查看Yarn的web页面:
http://node3:8088/cluster
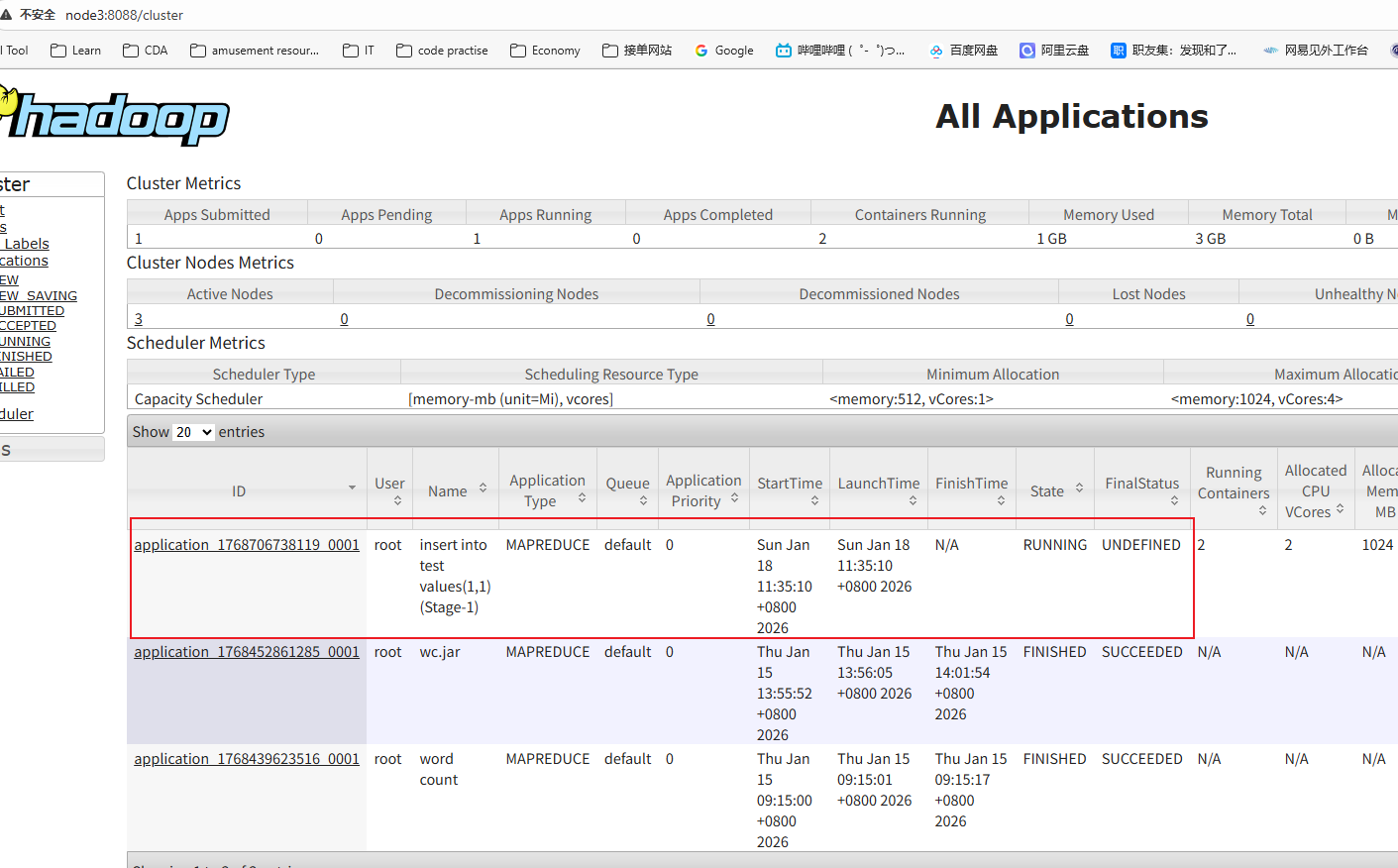
当任务执行完之后,再查看 HDFS 的文件列表页面,在test目录下多出文件。 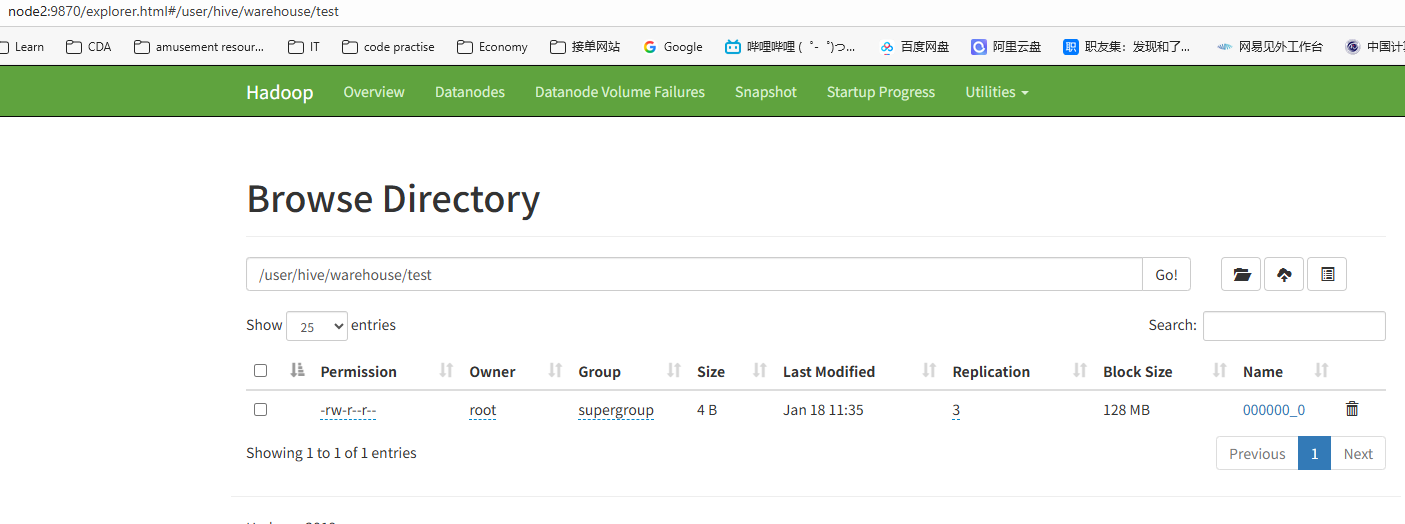
7. 在node1中连接上mysql查看表中的数据
bash
[root@node1 ~]# mysql -uroot -p123456
mysql> use hive;
Database changed
mysql> show tables;
+-------------------------------+
| Tables_in_hive |
+-------------------------------+
......
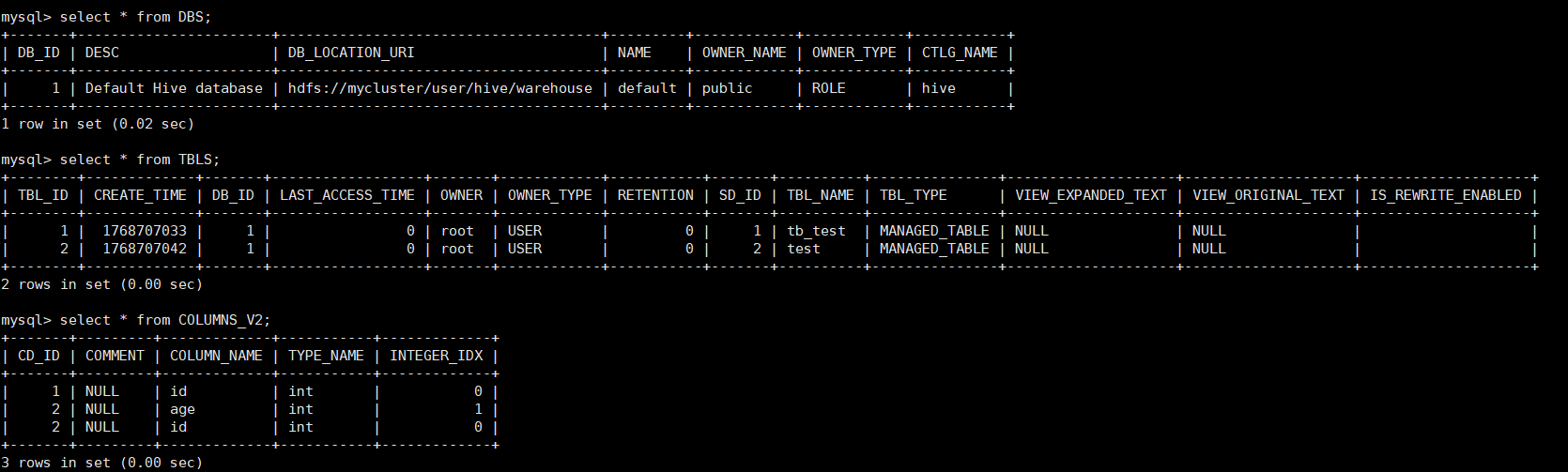
| COLUMNS_V2 | 保存表中列的数据
......
| DBS | 保存的是数据库实例
......
| TBLS | 保存的表数据
......8. 在MySQL中查看刚刚在hive上创建的数据库实例,表数据,列数据
远程服务模式安装
思考: hive 是如何连接到 hdfs 的?
答案:通过环境变量。
规划: node3 为服务器端 node4 为客户端
具体安装配置步骤:
- 从 node2 上将 /opt/hive-3.1.2 拷贝到 node3 和 node4 上
bash
[root@node2 ~]# scp -r /opt/hive-3.1.2/ node3:/opt
[root@node2 ~]# scp -r /opt/hive-3.1.2/ node4:/opt- 配置 node3 上 hive 的环境变量:
bash
[root@node3 ~]# vim /etc/profile
#在文件的最下位置添加如下内容
# hive环境变量配置
export HIVE_HOME=/opt/hive-3.1.2
export PATH=$PATH:$HIVE_HOME/bin
[root@node3 ~]# source /etc/profilenode4同理
3.修改node3上的hive_site.xml文件
bash
[root@node3 conf]# vim $HIVE_HOME/conf/hive-site.xml
XML
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- jdbc连接的URL设置 将hive改为hive_remote-->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node1:3306/hive_remote?useSSL=false</value>
</property>
<!-- jdbc连接的Driver类设置-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- 指定jdbc连接的username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- 指定jdbc连接mysql的password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!-- Hive默认在HDFS的工作目录 将hive改为hive_remote -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive_remote/warehouse</value>
</property>
<!-- Hive元数据存储的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!-- 元数据存储授权 -->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
</configuration>4.在node1的mysql中创建一个数据库实例:hive_remote
XML
[root@node1 ~]# mysql -uroot -p123456
mysql> create database hive_remote;5.在node3上初始化hive的元数据到mysql数据库的hive_remote实例下
XML
[root@node3 conf]# schematool -initSchema -dbType mysql -verbose6.在node1的mysql数据库中查看hive_remote实例下表,会发现多了74张表。到目前位置这个和直 连数据的方式是一样,hive的服务器和客户端都在node3上,没有启动Metastore或hiveserver2, 通过jdbc也无法访问。
7.在 node3 上查看被占用的端口号:
XML
[root@node3 conf]# yum install -y net-tool
[root@node3 conf]# netstat -nlpt经过观察发现 9083 端口没有被占用。
- 在node3上启动metastore服务
XML
[root@node3 ~]# hive --service metastore该命令为阻塞命令,如上所示执行命令后无法继续输入命令了。
9.复制一个 node3 连接的窗口
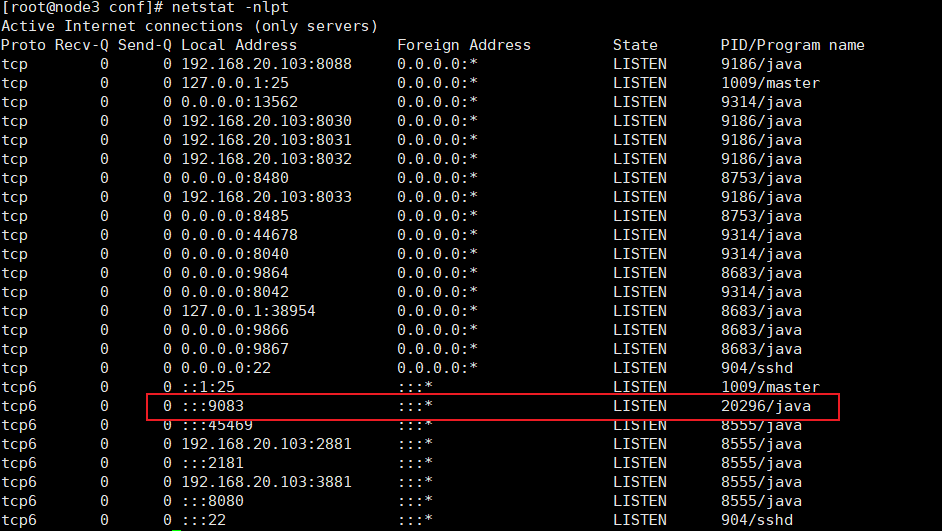
9083 端口便被 metastore 占用了。
10.如果在 9 步骤不需要窗口的命令被阻塞,也可以通过如下方式:
XML
[root@node3 ~]# hive --service metastore &11.修改node4上的hive-site.xml配置文件:
XML
[root@node4 ~]#vim $HIVE_HOME/conf/hive-site.xml文件中配置如下:
XML
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- Hive默认在HDFS的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive_remote/warehouse</value>
</property>
<!-- 指定hive服务器端连接地址 -->
<property>
<name>metastore.thrift.uris</name>
<value>thrift://node3:9083</value>
</property>
<!-- Hive元数据存储的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!-- 元数据存储授权 -->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
</configuration>12.node4上hive客户端启动hive
远程服务器模式测试
1.在node4上hive客户端上创建表psn,并向该表添加一条数据
XML
hive> create table psn(id int,age int);
hive> insert into psn values(1,18);2.查看HDFS文件列表
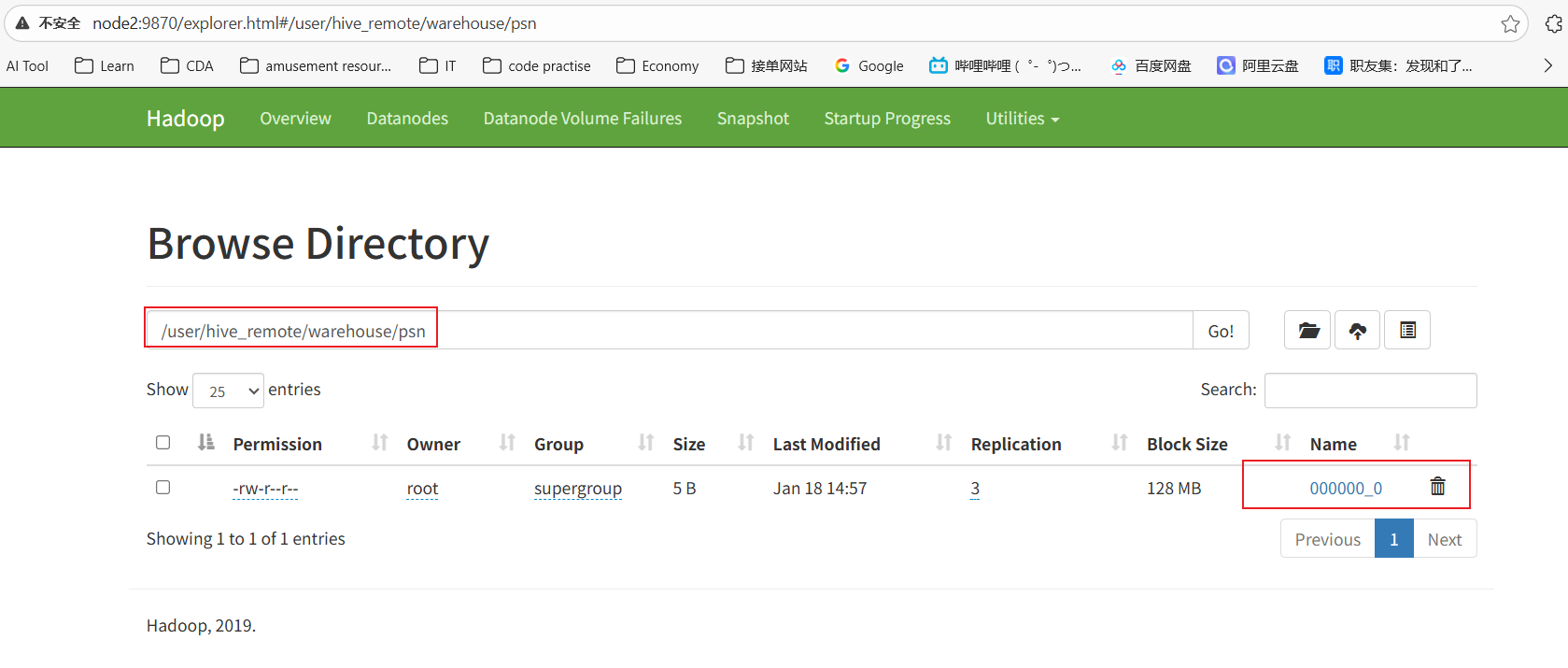
3. 通过 hdfs 命令查看该文件下的内容:
XML
[root@node3 ~]# hdfs dfs -cat /user/hive_remote/warehouse/psn/000000_0
118 #直接无法分辨出两个字段的值从哪里分割开的
[root@node3 ~]# hdfs dfs -get /user/hive_remote/warehouse/psn/000000_0
[root@node3 ~]# cat -A 000000_0
1^A18$^A 它是 hive 的默认分隔符