目录
前言
碎碎念:我翻山越岭,纵然这世间再也无人像你
梳理llama架构,和transformer很像,新学到 embedding后的词向量RMSnorm,和qk矩阵融合的Rope旋转编码,SwiGLU激活函数,GQA分组查询注意力机制
llama

分词器
l和l组合的概率高,所以把它重新组成为一个ll的词元
比如 it's 42! it, 's , 42, !
在自然语言处理中的 BPE 分词器的工作原理如下:
-
初始化 :首先,将所有词汇表中的单词分解为单个字符或符号。例如,单词 "hello" 会被表示为
["h", "e", "l", "l", "o"]。 -
统计频率:接下来,统计所有字符对(相邻字符组合)的出现频率。例如,如果 "l" 和 "l" 出现在一起的频率最高,那么它们会被作为一个新的词元 "ll"。
-
合并频率最高的字符对:将出现频率最高的字符对合并成一个新的词元。然后重复这个过程,直到达到预定义的词元数量或不能再合并为止。
-
生成词汇表:最终生成的词汇表包含了从单个字符到更复杂的子词的所有词元,这些词元可以组合成原始的单词和短语。
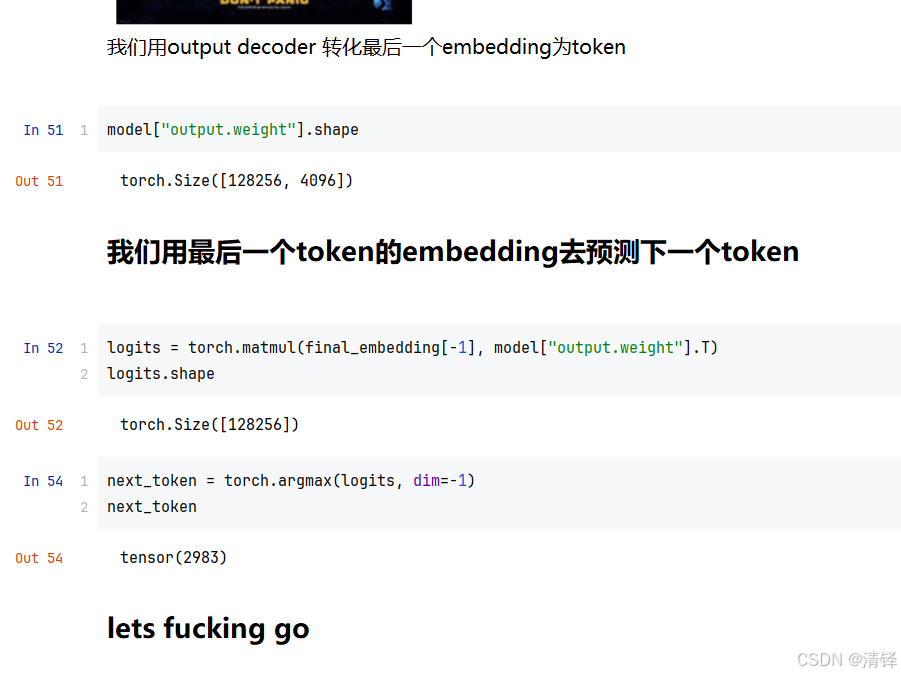
分词完后通过id 到embedding去查token向量,id=279,就到大矩阵里拿280列向量
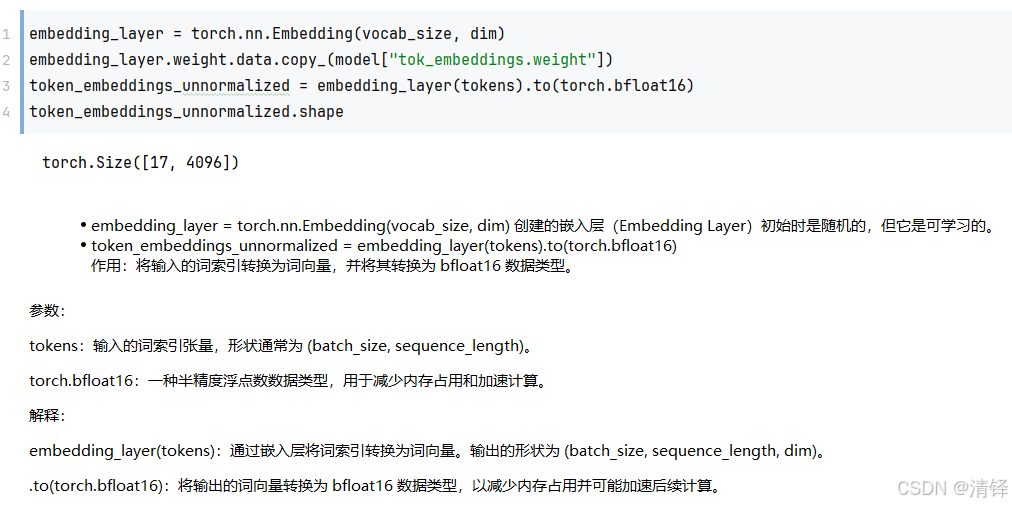
RMS对嵌入向量进行归一化

ROPE
先构建第一层的注意力机制,为什么不直接位置编码?
因为ROPE融入了QKV
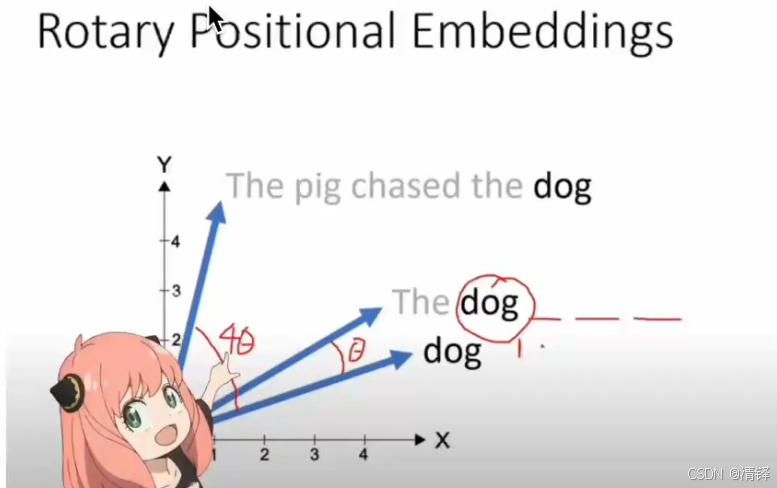
RoPE(旋转位置编码)
RoPE 是一种高效的位置编码方法,通过旋转向量的方式将位置信息注入到查询(query)和键(key)向量中。
- 核心思想
-
对查询向量和键向量进行 旋转,旋转的角度与 token 的位置相关。
-
旋转后的向量既保留了原始信息,又包含了位置信息。
- 公式

- 效果
-
对于不同位置的相同 token(例如三个 "the"),RoPE 会生成不同的查询向量。
-
旋转后的查询向量既包含了 token 的语义信息,也包含了位置信息。
为什么不用PE, ROPE优势是什么



Q和K旋转完了之后,V要不要旋转?
词和词之间的相对关系。 苹果性能好,怎么把苹果向手机上偏移呢
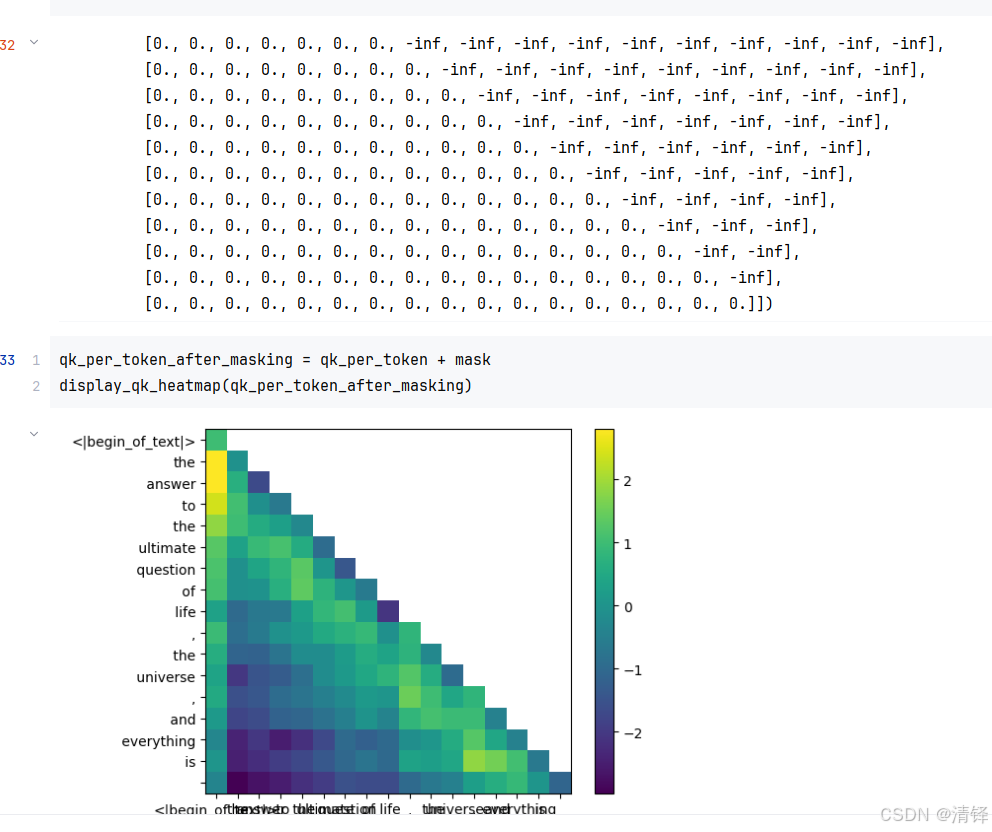
mask
上半角的矩阵代表后面单词对前面单词的影响,底下代表前面对后面的影响
姑且把纵向作为后面的单词,在decoder里 纵向的单词对横向即前面的单词是没影响的。所以把右上角的三角的矩阵掩码
再经过wo得到attention_score后先进行一次rms归一化
ffn
swishGLU 激活函数