PRL:让大模型推理不再"开盲盒"------过程奖励学习的理论与实践
论文标题 : PRL: Process Reward Learning Improves LLMs' Reasoning Ability and Broadens the Reasoning Boundary
作者 : Jiarui Yao, Ruida Wang, Tong Zhang
机构 : 伊利诺伊大学厄巴纳-香槟分校 (UIUC)
论文链接: https://arxiv.org/abs/2601.10201
🎯 一句话总结
PRL 把"只看结果"的强化学习改造成"边做边评"的模式,用严格的数学推导把稀疏的最终奖励"拆解"成每一步的过程奖励,让模型在推理过程中能获得更细粒度的反馈,从而既提升平均性能,又拓宽模型的推理能力边界。
📖 这篇论文在解决什么问题?
想象你在教一个小学生做数学应用题。传统的强化学习方法就像这样批改作业:只看最后答案对不对,对了给满分,错了零分。这种方式存在一个显而易见的问题------学生可能前面九步都做对了,最后一步算错,结果整道题拿零分;也可能前面乱写一通,最后碰巧蒙对了答案。
这就是当前大语言模型(LLM)推理训练面临的核心困境:结果奖励太稀疏,无法为多步推理提供有效指导。
信用分配问题:一个老生常谈的难题
这个问题在强化学习领域有个专业术语叫信用分配问题(Credit Assignment Problem, CAP)。最早可以追溯到1984年Sutton的论文《Temporal Credit Assignment in Reinforcement Learning》。
核心难题是:当你最后拿到一个奖励(或惩罚)时,怎么判断是哪一步决策导致了这个结果?
在LLM推理场景下,这个问题更加突出:
- 一道数学题可能需要10+步推理
- 每一步都可能出错
- 但奖励信号只在最后才给出
用博弈论的语言说,这就像**"三个和尚没水喝"**的困境:每个步骤都想"搭便车"(依赖其他步骤拿分),结果整体表现就很差。
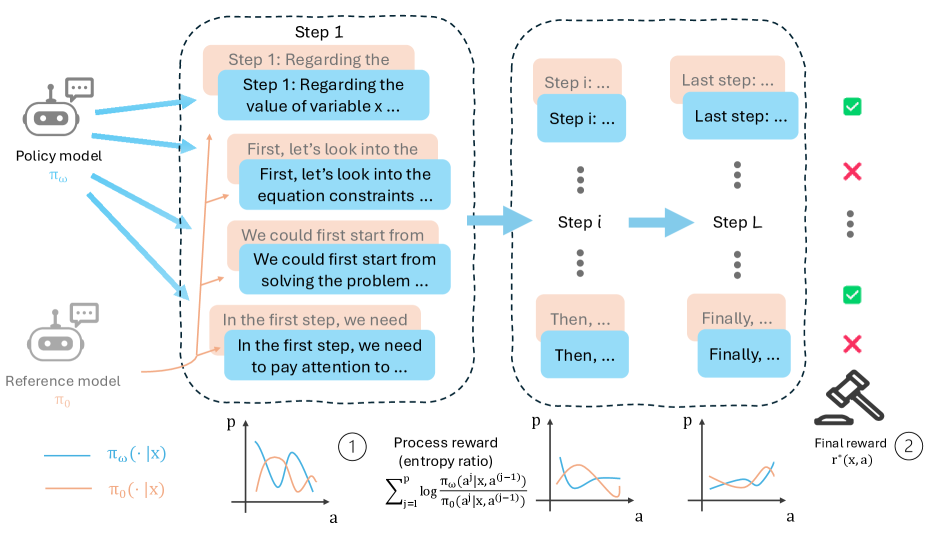
图1:PRL方法的核心思想------将最终奖励分解为每一步的过程奖励。策略模型和参考模型在每个推理步骤上的输出分布差异,被用来计算细粒度的过程信号。图中展示了从稀疏的结果奖励到密集的过程奖励的转变过程。
现有方案为什么不够好?
学术界当然意识到了这个问题,也有多种尝试:
1. MCTS(蒙特卡洛树搜索)方案
借鉴AlphaGo的思路,通过大量模拟来估计每一步的价值。OpenAI o1据传就用了类似的方法。
问题是------太贵了!每个训练样本都要跑成百上千次模拟,训练成本直接爆炸。假设每个问题需要100次模拟,每次生成500 token,那10万条训练数据就需要生成50亿token,光是推理成本就是天文数字。
2. 单独训练过程奖励模型(PRM)
谷歌DeepMind和OpenAI都在这条路上有深入研究。核心思路是:先训练一个专门评估中间步骤的模型,再用它来指导主模型。
谷歌最近提出的**过程优势验证器(PAV)**就是这个方向的代表作,通过全自动标注逐步骤奖励,在数学推理上提升了8%的准确率。
但这种方法有两个问题:
- 需要大量带步骤标注的数据:人工标注每一步的对错非常昂贵
- 多训一个模型本身就是额外负担:PRM的参数量往往也要到7B以上才能有好效果
3. 启发式方法
比如简单地把最终奖励平均分配给每一步,或者用某种衰减函数。
直觉上好像有道理,但缺乏理论支撑------凭什么这样分配是对的?会不会引入bias?
PRL的野心
PRL想要的是:既要理论严谨,又要工程简洁。
具体来说:
- ✅ 不需要MCTS的高昂计算开销
- ✅ 不需要单独训练PRM
- ✅ 有严格的数学推导支撑,不是拍脑袋设计
- ✅ 可以直接嵌入现有的GRPO训练框架
🧠 核心思想:从"结果导向"到"过程导向"
理论基础:熵正则化强化学习
PRL的出发点是一个经典的强化学习目标函数:
Q(π)=ExEa∼π(⋅∣x)r∗(x,a)−1ηKL(π∥π0)Q(\pi) = \mathbb{E}_x \left \\mathbb{E}_{a \\sim \\pi(\\cdot\|x)} r\^\*(x,a) - \\frac{1}{\\eta} \\text{KL}(\\pi \\\| \\pi_0) \\rightQ(π)=ExEa∼π(⋅∣x)r∗(x,a)−η1KL(π∥π0)
翻译成人话就是:我们希望策略模型 π\piπ 生成的回答能拿到高分(第一项),但又不能跟原始模型 π0\pi_0π0 差太远(第二项的KL惩罚)。
这个KL惩罚项非常关键------它防止模型在追求高分的过程中"走火入魔",生成一些语法混乱但碰巧能拿高分的奇怪输出。这种现象在强化学习文献中叫reward hacking。
为什么需要KL正则化?
假设没有KL惩罚,模型可能会:
- 为了数学题得分,生成一堆无意义但包含正确答案的token
- 过度拟合训练集的格式,泛化能力变差
- 输出分布变得极端(熵降为0),失去多样性
有了KL惩罚后,模型必须在"拿高分"和"不离谱"之间找平衡。
最优策略的闭式解
作者证明了一个漂亮的结论(定理3.1):上述优化问题的最优解是:
π∗(a∣x)∝π0(a∣x)⋅eη⋅r∗(x,a)\pi^*(a|x) \propto \pi_0(a|x) \cdot e^{\eta \cdot r^*(x,a)}π∗(a∣x)∝π0(a∣x)⋅eη⋅r∗(x,a)
直觉上很好理解:最优策略应该在参考模型的基础上,根据奖励值进行"指数加权"------奖励高的回答应该被提升概率,奖励低的应该被压低。
这个结果和**DPO(Direct Preference Optimization)**中的Bradley-Terry模型有异曲同工之妙,都是在说:最优策略是参考策略乘以奖励的指数函数。
关键洞察:过程奖励的严格定义
接下来是这篇论文最精彩的部分。作者问了一个问题:如果我们只完成了部分推理步骤,应该给多少分?
假设完整答案是 a=a1,a2,...,aLa = a_1, a_2, ..., a_La=a1,a2,...,aL,部分答案是 a(ℓ)=a1,...,aℓa^{(\ell)} = a_1, ..., a_\\ella(ℓ)=a1,...,aℓ。PRL定义的过程奖励是:
rℓ∗(x,a(ℓ))=Ea(−ℓ)∼π∗r∗(x,a)−1η∑j=ℓ+1Llnπ∗(aj∣x,a(j−1))π0(aj∣x,a(j−1))r_\ell^*(x, a^{(\ell)}) = \mathbb{E}_{a^{(-\ell)} \sim \pi^*} \left r\^\*(x,a) - \\frac{1}{\\eta} \\sum_{j=\\ell+1}\^L \\ln \\frac{\\pi\^\*(a_j\|x, a\^{(j-1)})}{\\pi_0(a_j\|x, a\^{(j-1)})} \\rightrℓ∗(x,a(ℓ))=Ea(−ℓ)∼π∗ r∗(x,a)−η1j=ℓ+1∑Llnπ0(aj∣x,a(j−1))π∗(aj∣x,a(j−1))
这个公式看起来吓人,但拆解一下很清晰:
| 组成部分 | 数学表达 | 直觉含义 |
|---|---|---|
| 未来期望收益 | Ea(−ℓ)∼π∗r∗(x,a)\mathbb{E}_{a^{(-\ell)} \sim \pi^*}r\^\*(x,a)Ea(−ℓ)∼π∗r∗(x,a) | 如果后面都按最优策略走,能拿多少分 |
| 未来KL成本 | 1η∑j=ℓ+1Llnπ∗(aj)π0(aj)\frac{1}{\eta} \sum_{j=\ell+1}^L \ln \frac{\pi^*(a_j)}{\pi_0(a_j)}η1∑j=ℓ+1Llnπ0(aj)π∗(aj) | 完成剩余步骤需要"偏离"参考模型多少 |
| 过程奖励 | 未来期望收益 - 未来KL成本 | 当前状态的"净价值" |
换句话说,过程奖励 = 未来期望收益 - 未来必须支付的成本。
为什么这个定义有效?
这个定义有一个重要的数学性质(定理3.3 ):状态一致性。
无论你从哪条路径走来,只要走到同一个中间状态,过程奖励都是一样的。数学上表述为:
rℓ∗(x,a(ℓ))=rℓ∗(x,a~(ℓ))if a(ℓ)=a~(ℓ)r_\ell^*(x, a^{(\ell)}) = r_\ell^*(x, \tilde{a}^{(\ell)}) \quad \text{if } a^{(\ell)} = \tilde{a}^{(\ell)}rℓ∗(x,a(ℓ))=rℓ∗(x,a~(ℓ))if a(ℓ)=a~(ℓ)
这个性质保证了训练信号的一致性------不会出现"同一个状态,不同的分数"的情况。
一个更直观的类比
用一个类比来解释:想象你在下围棋。
- 结果奖励:只有棋局结束才知道输赢,中间落子全靠蒙
- 过程奖励:每下一步,都有人告诉你"从这个局面出发,如果后面都下最优解,大概能赢/输多少目"
后者显然能提供更有效的学习信号。但问题是,围棋需要AlphaGo那样的价值网络来估计每一步的价值,而PRL的妙处在于:它用数学推导直接得出了过程奖励的计算公式,不需要额外训练任何模型。
🏗️ 方法架构:如何落地实现?
GRPO:一种高效的无Critic强化学习算法
在介绍PRL的具体实现之前,需要先了解它的基础框架------GRPO(Group Relative Policy Optimization)。
GRPO是DeepSeek团队在2024年提出的一种创新型强化学习算法,核心思想是:用组内样本的相对比较来计算优势,省去了训练Critic模型的麻烦。
传统PPO需要维护一个和Actor同等规模的Critic模型来估计状态价值,这在LLM场景下代价很高------你想训练一个7B的Actor,就得再配一个7B的Critic,显存直接翻倍。
GRPO的解法很聪明:
- 对同一个问题,生成G个不同的回答(比如G=8)
- 用奖励模型给每个回答打分
- 计算组内均值和标准差,做归一化:Ai=Ri−μσA_i = \frac{R_i - \mu}{\sigma}Ai=σRi−μ
- 用归一化后的优势更新策略
这样就完全不需要Critic了,显存省了一半,训练速度也快了不少。
| 特性 | PPO | GRPO |
|---|---|---|
| 是否需要Critic | 需要(同等规模) | 不需要 |
| 显存占用 | 高 | 低(约50%) |
| 训练稳定性 | 一般 | 较好(组内归一化) |
| 适用场景 | 通用RL | LLM微调 |
PRL在GRPO基础上的改进
PRL的关键改进是:把逐token的KL惩罚替换成了基于过程奖励的优势估计。
步骤1:采样多条推理轨迹
对于每个问题,让模型生成 nnn 条不同的推理路径(比如 n=5n=5n=5)。
python
trajectories = []
for _ in range(n):
traj = model.generate(question, do_sample=True, temperature=0.7)
trajectories.append(traj)步骤2:计算每条轨迹的对数概率比
log_ratioj=logπω(aj∣x,a(j−1))π0(aj∣x,a(j−1))\text{log\_ratio}j = \log \frac{\pi\omega(a_j|x, a^{(j-1)})}{\pi_0(a_j|x, a^{(j-1)})}log_ratioj=logπ0(aj∣x,a(j−1))πω(aj∣x,a(j−1))
这衡量的是当前策略相对于参考模型在每一步的偏离程度。如果 log_ratioj>0\text{log\_ratio}_j > 0log_ratioj>0,说明当前策略比参考模型更倾向于这个token;反之亦然。
步骤3:计算"未来KL惩罚"
future_klℓ=∑j=ℓ+1Llog_ratioj\text{future\kl}\ell = \sum_{j=\ell+1}^L \text{log\_ratio}_jfuture_klℓ=j=ℓ+1∑Llog_ratioj
这是从步骤 ℓ\ellℓ 之后所有步骤的累积KL散度。注意这里用的是从当前位置到结尾的累积,而不是全局KL。
步骤4:计算过程优势
ρℓ=r∗(x,a)−1η⋅future_klℓ\rho_\ell = r^*(x, a) - \frac{1}{\eta} \cdot \text{future\kl}\ellρℓ=r∗(x,a)−η1⋅future_klℓ
把最终奖励和未来KL成本结合起来,得到每一步的过程优势。
注意一个有趣的性质:越靠前的步骤,future_kl越大,所以相对惩罚越重。这符合直觉------早期决策影响后续所有步骤,应该更谨慎。
步骤5:用过程优势更新策略
使用PPO风格的截断目标函数:
L(ω)=∑j=1Lmin{ρj⋅πωπold,ρj⋅clip(πωπold,1±ε)}\mathcal{L}(\omega) = \sum_{j=1}^L \min \left\{ \rho_j \cdot \frac{\pi_\omega}{\pi_{\text{old}}}, \rho_j \cdot \text{clip}\left( \frac{\pi_\omega}{\pi_{\text{old}}}, 1 \pm \varepsilon \right) \right\}L(ω)=j=1∑Lmin{ρj⋅πoldπω,ρj⋅clip(πoldπω,1±ε)}
截断(clip)机制是PPO的核心创新,防止单次更新步长过大导致训练崩溃。
步骤划分:一个被低估的细节
论文探讨了两种划分推理步骤的方式:
方式一:按换行符分割
把每个"思考段落"作为一步。比如:
Step 1: 设方程为 ax + b = c [一个步骤]
Step 2: 移项得 ax = c - b [一个步骤]
Step 3: 两边除以a,x = (c-b)/a [一个步骤]优点是语义上比较自然,每一步是一个完整的推理动作。
方式二:按固定token长度分割
比如每256个token算一步,不管语义。
[token 0-255] → 步骤1
[token 256-511] → 步骤2
...实验发现:固定长度分割在某些场景下表现更好!
为什么?论文分析了可能的原因:
| 分割方式 | 优点 | 缺点 |
|---|---|---|
| 换行符 | 语义清晰 | 步骤长度差异大(有的几个token,有的几百) |
| 固定长度 | 步骤长度一致 | 可能切断语义完整性 |
步骤长度差异太大会导致一个问题:短步骤的KL惩罚很小,长步骤的KL惩罚很大,这种不平衡可能影响学习信号的质量。
论文建议256 token是一个不错的平衡点------既不会太短导致无法捕捉完整推理,也不会太长导致信号稀疏。
🧪 实验结果:数字说话
实验设置
| 项目 | 配置 |
|---|---|
| 模型 | Qwen2.5-Math (1.5B, 7B)、Llama-3.2 (1B, 3B) |
| 训练数据 | NuminaMath数据集,约15万样本 |
| 评估基准 | MATH500, Minerva Math, Olympiad Bench, AIME24, AMC23 |
| 硬件 | 4张 Nvidia H100 GPU |
| 训练参数 | 学习率 1e-6,batch size 64,epoch 3 |
评估基准的难度梯度:
- MATH500:从MATH数据集中采样的500道题,中等难度
- Minerva Math:Google Minerva项目的数学测试集
- Olympiad Bench:奥林匹克竞赛级别的数学题
- AIME24:2024年美国数学邀请赛真题(最难)
- AMC23:2023年美国数学竞赛真题
主要结果
| 模型 | 方法 | MATH500 | Minerva | Olympiad | AIME24 | AMC23 | 平均 |
|---|---|---|---|---|---|---|---|
| Qwen2.5-Math-7B | GRPO | 84.70 | 37.60 | 48.17 | 33.33 | 67.50 | 54.26 |
| Qwen2.5-Math-7B | PRL | 85.10 | 38.20 | 48.53 | 36.67 | 67.50 | 55.20 |
| Qwen2.5-Math-1.5B | GRPO | 76.20 | 28.40 | 33.82 | 13.33 | 52.50 | 40.85 |
| Qwen2.5-Math-1.5B | PRL | 77.00 | 29.80 | 34.44 | 16.67 | 55.00 | 42.58 |
| Llama-3.2-3B | GRPO | 57.10 | 13.40 | 16.30 | 0 | 22.50 | 21.86 |
| Llama-3.2-3B | PRL | 57.60 | 15.00 | 16.59 | 3.33 | 22.50 | 23.00 |
| Llama-3.2-1B | GRPO | 38.60 | 7.80 | 8.96 | 0 | 12.50 | 13.57 |
| Llama-3.2-1B | PRL | 40.20 | 8.60 | 9.85 | 0 | 15.00 | 14.73 |
表1:Pass@8 指标对比(即采样8次,只要有一次对就算对)
几个值得注意的发现:
1. PRL在几乎所有配置上都优于GRPO基线
唯一打平的是AMC23上的Qwen2.5-Math-7B,其他全部有提升。
2. 难题上提升更明显
AIME24是最难的竞赛级题目,Qwen2.5-Math-7B从33.33%提升到36.67%(相对提升10%),Llama-3.2-3B更是从0%提升到3.33%------虽然绝对数字不高,但实现了"从无到有"的突破。
3. 小模型受益更大
Qwen2.5-Math-1.5B的平均分从40.85提升到42.58(+4.2%),而7B模型只从54.26提升到55.20(+1.7%)。这说明细粒度监督对小模型尤其有帮助------大模型本身能力强,"吃大锅饭"的负面影响相对较小。
关键发现:拓宽推理边界
论文强调了一个重要观察:PRL不仅提升平均性能(Average@n),更显著提升Pass@n指标。
| 指标 | 含义 | 反映的能力 |
|---|---|---|
| Average@n | 采样n次的平均准确率 | 稳定性、可靠性 |
| Pass@n | 采样n次至少成功一次的概率 | 能力上限、潜力 |
Pass@n的提升意味着什么?
想象一个场景:你让模型做100道题,每道题采样8次。
- Average@8高意味着:大部分题都能稳定做对
- Pass@8高意味着:即使有些题不稳定,但多试几次总能做对
PRL的Pass@n提升说明它让模型能够解决一些之前完全解决不了的难题------这就是"拓宽推理边界"的含义。
论文中有一个很有说服力的例子:Llama-3.2-3B在AIME24上,GRPO训练后Pass@8=0%,PRL训练后Pass@8=3.33%。这意味着有几道题是只有PRL训练的模型才能解出来的。
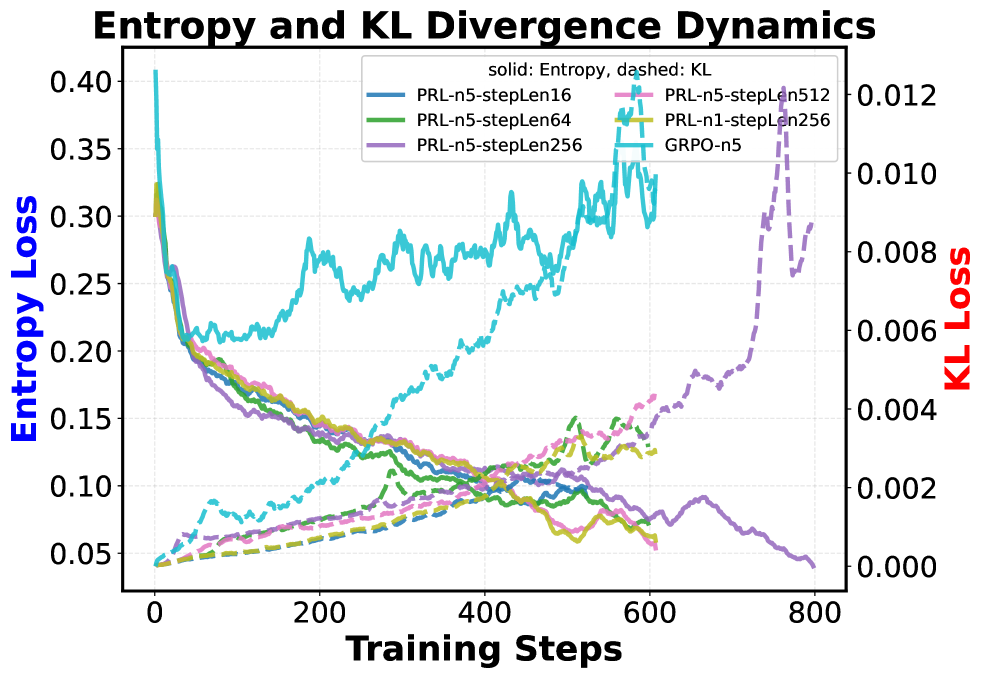
图2:训练过程中熵(实线)和KL散度(虚线)的变化。可以看到PRL在不同步长设置下的训练动态。较长的步长(如512)倾向于保持更高的熵,这意味着模型保持了更多的探索能力,不会过早收敛到局部最优。
消融实验:每个组件的贡献
实验1:步骤长度的影响
| 步骤长度(token) | MATH500 | Minerva | 平均 |
|---|---|---|---|
| 16 | 76.40 | 28.80 | 41.23 |
| 64 | 76.80 | 29.20 | 41.85 |
| 256 | 77.00 | 29.80 | 42.58 |
| 512 | 76.60 | 29.40 | 42.10 |
| 换行符 | 76.20 | 28.60 | 41.02 |
256 token的固定长度效果最佳。太短(16)信号太密集,噪声大;太长(512)信号太稀疏,学不到东西。
实验2:KL系数η的影响
| η值 | MATH500 | 训练稳定性 |
|---|---|---|
| 0.001 | 75.20 | 很稳定但学得慢 |
| 0.01 | 76.60 | 较稳定 |
| 0.1 | 77.00 | 平衡点 |
| 1.0 | 73.80 | 不稳定 |
η太小,KL惩罚太重,模型不敢探索;η太大,惩罚太轻,模型容易跑偏。
实验3:采样数量n的影响
| 采样数n | MATH500 | 计算成本 |
|---|---|---|
| 2 | 75.80 | 低 |
| 5 | 77.00 | 中等 |
| 8 | 77.20 | 高 |
n=5是一个不错的平衡点。增加到8只提升0.2%,但计算成本增加60%。
🔬 技术分析与深度讨论
为什么PRL有效?从多个角度分析
角度1:信用分配更准确
传统方法给所有步骤相同的奖励信号,但实际上不同步骤对最终结果的贡献差异很大。
PRL通过future_kl项,自然地实现了时间差异惩罚:
- 第1步的future_kl包含后面所有步骤的KL,值最大
- 最后一步的future_kl=0
这意味着早期步骤获得更大的奖励权重------因为早期决策影响后续所有步骤,应该更谨慎。这和强化学习中的**时间差分(TD)**思想一脉相承。
角度2:学习信号更平滑
稀疏奖励导致梯度信号要么是零,要么是很大的跳变,训练很不稳定。
用一个简单的对比来说明:
| 方法 | 梯度模式 | 训练稳定性 |
|---|---|---|
| 结果奖励 | 0, 0, 0, ..., 0, 大跳变 | 差 |
| PRL | 小更新, 小更新, ..., 小更新 | 好 |
过程奖励把一个大的跳变分解成多个小的更新,训练曲线更平滑。
角度3:更好的探索
从图2可以看到,PRL训练过程中保持了更高的熵值。
熵高意味着什么?意味着模型在学习过程中保持了更多的随机性,有助于探索不同的推理路径,而不是过早收敛到局部最优。
这和强化学习中的**探索-利用权衡(Exploration-Exploitation Trade-off)**直接相关。PRL的设计让模型在早期保持足够的探索能力,后期再逐渐收敛。
与其他过程奖励方法的深度对比
| 方法 | 原理 | 是否需要MCTS | 是否需要额外PRM | 理论保证 | 计算开销 |
|---|---|---|---|---|---|
| OpenAI o1风格 | MCTS + PRM | 是 | 是 | 弱 | 极高 |
| Google PAV | 全自动步骤标注 | 否 | 是(隐式) | 中等 | 中等 |
| 启发式分配 | 平均/衰减分配 | 否 | 否 | 无 | 低 |
| 隐式PRM | 用ORM间接生成过程奖励 | 否 | 否(但需要ORM) | 中等 | 中等 |
| PRL | 数学推导直接分解 | 否 | 否 | 强 | 低 |
PRL的独特优势在于:
- 不需要额外模型:不用训练PRM或Critic,用现有的策略模型和参考模型就够了
- 不需要多次采样:一次rollout就能给出所有步骤的奖励
- 有理论保证:不是经验设计,而是从熵正则化RL目标函数严格推导出来的
- 计算高效:相比GRPO只多了一些对数概率的计算,几乎没有额外开销
与GRPO的关系:改进而非替代
PRL不是要取代GRPO,而是在GRPO基础上的改进。可以这样理解:
| 组件 | GRPO | PRL |
|---|---|---|
| 采样策略 | 组内多次采样 | 相同 |
| 优势计算 | 组内相对归一化 | 组内归一化 + 过程分解 |
| KL惩罚 | 逐token惩罚 | 按步骤累积惩罚 |
| 策略更新 | PPO-clip | 相同 |
核心改变就是优势计算方式:从粗粒度的轨迹级优势,变成细粒度的步骤级过程优势。
潜在局限性的深入分析
局限1:模型规模有限
实验最大只做到7B参数,是否能扩展到70B、100B级别还不清楚。
我的推测:PRL在大模型上可能依然有效,但边际收益可能递减。原因有二:
- 大模型本身能力更强,"吃大锅饭"的负面影响相对较小
- 大模型的推理链通常更短(更高效),步骤分解的收益降低
局限2:步骤划分比较粗糙
固定token长度的划分方式可能不符合实际推理的语义结构。
理想的步骤划分应该是语义驱动的:每个"思考单元"是一步。但这需要额外的分割模型,又增加了复杂度。
一个可能的改进方向是:训练一个轻量级的步骤分割器,或者用规则+启发式方法来识别语义边界。
局限3:奖励函数受限
当前只用了正确/错误的二元奖励(0/1),更复杂的奖励函数(比如部分分)下表现如何还需探索。
数学题还好说,答案对就是对。但对于代码生成、逻辑推理等任务,"部分正确"是很常见的------比如代码通过了一半的测试用例。PRL能否处理这种连续奖励信号,是一个开放问题。
局限4:泛化性验证不足
主要在数学推理上验证,代码生成、逻辑推理、科学问答等其他领域效果如何?
论文的实验集中在数学领域有其道理------数学答案可以精确验证,奖励信号clean。但实际应用中,很多任务的奖励本身就是noisy的(比如用LLM打分),PRL在这种场景下是否依然有效,值得进一步研究。
💡 工程落地建议
如果想在实际项目中尝试PRL,这里有几点建议:
适用场景判断
| 场景 | 是否适合 | 原因 |
|---|---|---|
| 数学推理 | ✅ 非常适合 | 论文验证的主场景 |
| 代码生成 | ✅ 适合 | 执行结果可验证 |
| 逻辑推理 | ✅ 适合 | 有明确的对错 |
| 多步问答 | ⚠️ 需改造 | 步骤划分不明确 |
| 开放式对话 | ❌ 不适合 | 很难定义"正确"的推理步骤 |
| 创意写作 | ❌ 不适合 | 无法定义结果奖励 |
实现要点
1. 数据准备
你需要有明确可验证的奖励信号。对于数学题,就是答案对不对;对于代码,可以是单元测试通过率。
如果原始数据没有明确答案,可以考虑:
- 用GPT-4生成参考答案
- 用规则+人工校验
- 退回到用LLM打分(但效果可能打折扣)
2. 超参数选择
| 超参数 | 建议值 | 调节建议 |
|---|---|---|
| 步骤长度 | 256 token | 根据任务调整,推理越复杂可以越长 |
| KL系数η | 0.1 | 如果训练不稳定就调小,学得慢就调大 |
| 采样数n | 5 | 计算资源充足可以增加到8 |
| clip系数ε | 0.2 | 标准PPO设置,一般不用动 |
3. 监控指标
除了常规的loss和accuracy,建议监控:
python
# 关键监控指标
metrics = {
"entropy": ..., # 策略熵,应该逐渐下降但不要降到0
"kl_divergence": ..., # 和参考模型的KL,不要太大(>15是warning)
"future_kl_mean": ..., # 平均future_kl,看过程奖励是否合理
"grad_norm": ..., # 梯度范数,排查训练不稳定
}4. 代码实现参考
核心改动在于优势计算:
python
def compute_process_advantages(
log_probs: torch.Tensor, # [batch, seq_len] 当前策略的对数概率
ref_log_probs: torch.Tensor, # [batch, seq_len] 参考策略的对数概率
rewards: torch.Tensor, # [batch] 最终奖励
step_boundaries: List[int], # 步骤边界位置
eta: float = 0.1
):
"""计算PRL的过程优势"""
batch_size, seq_len = log_probs.shape
# 计算逐token的log ratio
log_ratios = log_probs - ref_log_probs # [batch, seq_len]
# 按步骤累积future_kl
advantages = []
for b in range(batch_size):
traj_advantages = []
for i, (start, end) in enumerate(zip(step_boundaries[:-1], step_boundaries[1:])):
# future_kl = sum of log_ratios from current step to end
future_kl = log_ratios[b, end:].sum()
# process advantage = reward - future_kl / eta
adv = rewards[b] - future_kl / eta
traj_advantages.extend([adv] * (end - start))
advantages.append(traj_advantages)
return torch.tensor(advantages)📊 总结与展望
论文贡献总结
PRL这篇论文的贡献可以概括为:
1. 理论贡献
证明了熵正则化RL目标可以自然分解为过程奖励,给出了严格的数学推导。这不是拍脑袋设计的启发式方法,而是有坚实理论基础的。
2. 方法贡献
提出了不依赖MCTS或额外PRM的过程奖励计算方法。只需要策略模型和参考模型的对数概率,就能计算出每一步的过程优势。
3. 实证贡献
在多个数学推理基准上验证了方法的有效性,特别是在高难度竞赛题上展现了"拓宽推理边界"的能力。
更大的视角
从更宏观的角度看,PRL这篇工作反映了当前LLM推理训练的一个重要趋势:从粗粒度到细粒度,从结果导向到过程导向。
这个趋势在多个方向上都有体现:
| 方向 | 粗粒度(早期) | 细粒度(当前) |
|---|---|---|
| 奖励信号 | 结果奖励(ORM) | 过程奖励(PRM/PRL) |
| 训练粒度 | 完整回答级 | 步骤级/token级 |
| 评估方式 | Exact Match | 多指标综合评估 |
| 模型结构 | 单一模型 | 推理+验证+批评 |
PRL为"不用额外模型也能获得细粒度监督"这条路提供了一个优雅的解法。虽然效果可能不如重金打造的PRM系统(比如传闻中OpenAI o1用的那套),但其理论优雅性和工程简洁性使它成为一个很有价值的baseline。
未来展望
短期可改进的方向:
- 自适应步骤划分:根据任务特点动态调整步骤长度
- 连续奖励支持:扩展到部分分场景
- 更大规模验证:在70B+模型上验证效果
长期研究问题:
- 与搜索方法的结合:PRL能否与MCTS等搜索方法配合使用?
- 跨任务迁移:在数学上训练的过程奖励能力,能否迁移到代码、逻辑等其他领域?
- 理论深化:过程奖励的最优划分粒度是否有理论界?
📚 延伸阅读
- DeepSeek-R1技术报告:了解GRPO的原始设计和大规模推理模型训练
- OpenAI o1系列解读:对比不同的过程奖励建模思路
- Google PAV论文:全自动步骤标注的过程奖励方法
- PRMBench:过程奖励模型的标准化评估基准
- 《Temporal Credit Assignment in Reinforcement Learning》:信用分配问题的经典论文
📝 参考信息
- 论文标题:PRL: Process Reward Learning Improves LLMs' Reasoning Ability and Broadens the Reasoning Boundary
- 作者:Jiarui Yao, Ruida Wang, Tong Zhang
- 机构:伊利诺伊大学厄巴纳-香槟分校 (UIUC)
- 论文链接:https://arxiv.org/abs/2601.10201