近日 Meta 突然开源了它的 ShapeR 项目,ShapeR 可以利用基于对象多模态数据的 Rectified Flow Transformer,将普通图像序列转换为完整的度量场景重建,说人话就是:
从随手拍的视频/多张照片里,把真实物体恢复成可用 3D 模型(Mesh)
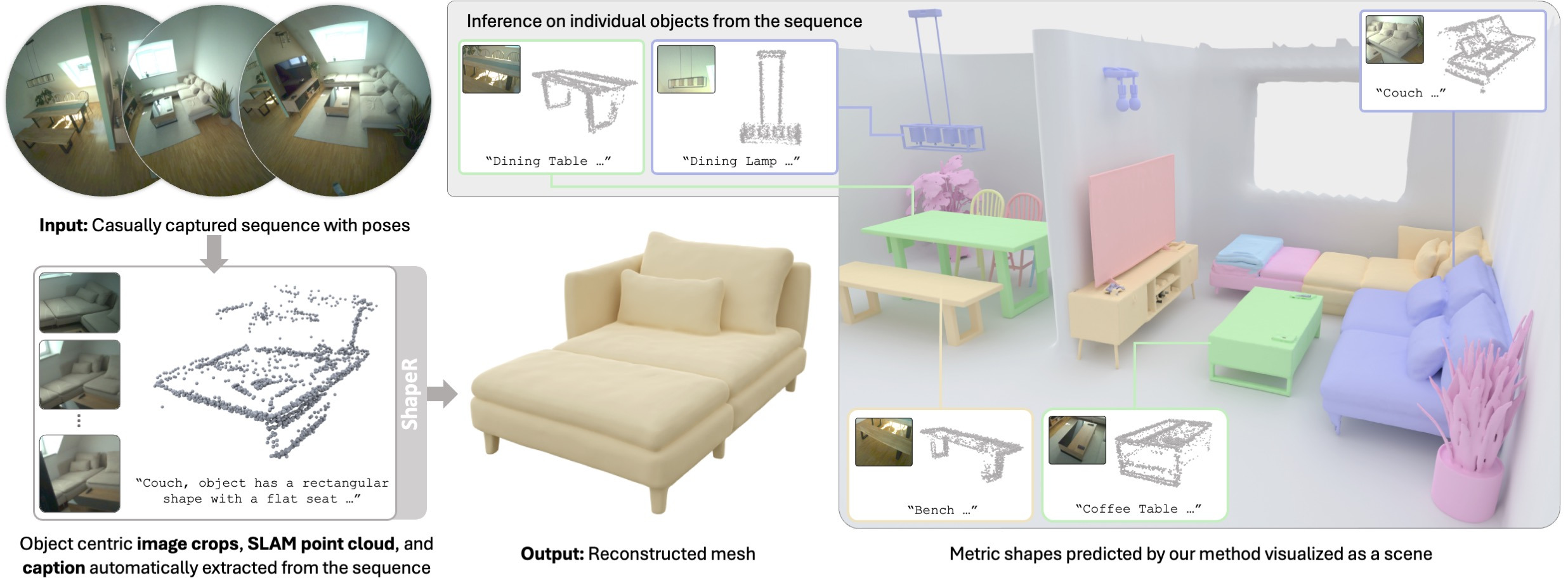

简单来说就是,你可以拿着手机绕着一个物体拍一圈(图片序列 / 视频帧序列),ShapeR 会结合:
- SLAM 得到的稀疏点云 + 相机位姿
- 物体检测/实例分割得到的对象实例
- VLM 生成的文本 caption(描述物体),把这些多模态条件喂给生成模型,最后得到物体的 metric 3D mesh(带真实尺度)
看到这么多名词是不是有点懵?这些概念性的东西我们需要简单聊聊:
SLAM
这个是 ShapeR 的地基核心,SLAM (Simultaneous Localization and Mapping) 其实就是用算法解决摄像头在陌生化环境的定位和建图,实现定位的时候建图,建图的时候定位的支持,简单来说就是:
- 摄像头采集数据
- 通过画面比对计算移动距离
- 通过算法来修正误差
- 通过回环检测来解决漂移和消除误差
用人话来说就是:用 SLAM 可以得到 "摄影师的足迹"和"物体的骨架",具体来自:
- 相机位姿 :相当于记录了你拿着手机绕着物体走动时,每一步具体站在哪里,手机镜头朝向哪里(比如:向左走了 1 米,镜头向下倾斜 30 度)
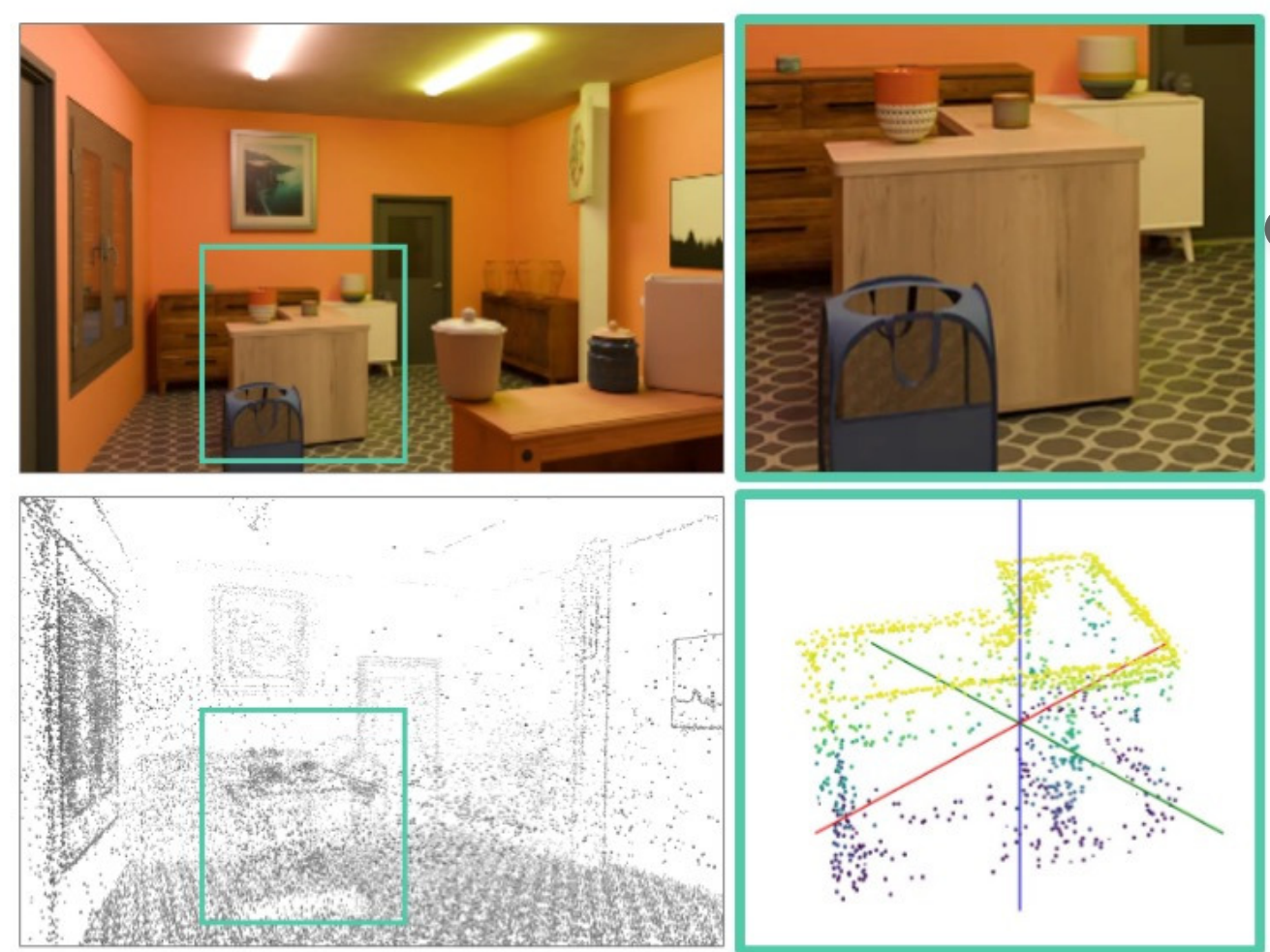
- 稀疏点云 :相当于你在物体上撒了一把荧光粉,SLAM 并不试图重建整个物体表面,它只抓取最明显的特征点(比如桌角、杯子的把手尖),看起来稀稀拉拉像个幽灵,但它锁定了物体的真实尺寸和空间位置

SLAM 之所以能做到这一点,核心依赖于几何学的三角测量和概率学的误差优化,简单来说:
-
当你拿着手机移动时(比如向右移动了 10 厘米),SLAM 会对比前后两帧画面:
- **A点(比如桌上的杯子)**在画面里移动了 100 个像素 -> 推算:它离我很近
- **B点(窗外的树)**在画面里只移动了 2 个像素 -> 推算:它离我很远
通过这种视差,配合手机摄像头移动的距离(IMU 传感器提供),算法就能画出一个个三角形,通过几何公式算出每个特征点在三维空间中的精确坐标,这在室内导航 BLE 测距离也会有类似的三角测量用法
-
SLAM 并不是真的知道自己移动了多少米,它最聪明的地方在于不追求一步到位,而是不断"猜"和"改",通过假设和推算不断去修正误差
-
最后有个回环检测,比如误差越来越大,但是当你绕了一圈回到原点时,摄像头拍到了之前的场景,比对之后会发,这个画面和之前 5 分钟的画面重合,那么它会把过去 5 分钟积累的所有位置偏差强制拉回

这就是 SLAM 的简单概念,实际上这也是移动开发里的 ARCore 和 ARkit 的基础概念之一,同时对于机器人、无人机或者 XR ,SLAM 也是非常重要的基础,如果用人话来说就是,SLAM 是把硬件数据(IMU 的加速度、摄像头的像素变化)转化为了几何约束:
- 眼睛(Camera):提供角度信息(我知道杯子在那个方向)
- 前庭(IMU):提供尺度信息(我感觉我向前冲了 1 米)
- 大脑(Algorithm):通过几何公式把角度和尺度结合,算出距离,再通过记忆(回环检测)修正走过的路
物体检测 / 实例分割
物体检测 / 实例分割(Object Detection / Instance Segmentation)简单说就是 "自动抠图"和"聚光灯" :
- 你拍的是整个房间,但你只想重建桌上的那个茶壶
- 这就需要一个算法,能自动在乱糟糟的背景里把茶壶给"圈出来"(画个框),甚至精确到把茶壶的每一个像素都涂上颜色,把背景剔除掉,这就是把茶壶从环境里"抠"出来
具体到实现上就是:
- 物体检测 (Detection) :输出一个 Bounding Box(边界框),告诉系统物体大概在哪(比如
[x1, y1, x2, y2]) - 实例分割 (Instance Segmentation):输出一个 Binary Mask(二值掩码),在这个掩码图里,属于茶壶的像素是 1,背景是 0
ShapeR 是 Object-Centric(以物体为中心)的,它需要这些 Mask 来告诉生成模型:"只准重建这个茶壶,不要把后面的墙壁和下面的桌子也算进去了"
VML
最后是 VLM (Visual Language Model generated Captions) 生成的文本 Caption,通俗理解来说就是"给 AI 的命题作文":
- 虽然有了照片,但生成模型有时候比较"笨",它可能看不清照片里的细节(比如模糊了,或者被挡住了)
- 这时,就需要一个专门懂图片的 AI(VLM,类似 GPT-4V),让它看一眼照片,然后写一段话:"这是一个红色的复古木质椅子,椅背有雕花,坐垫是天鹅绒材质。"
也就是针对图形增加一点文本表述,提供更准确的语义,照片提供了"几何外观",文本提供了"概念理解",防止照片里因为反光或遮挡导致细节丢失时,模型可以根据这段文本描述,利用其训练库里关于"复古木质椅子"的知识,合理地"脑补"出看不清的细节。
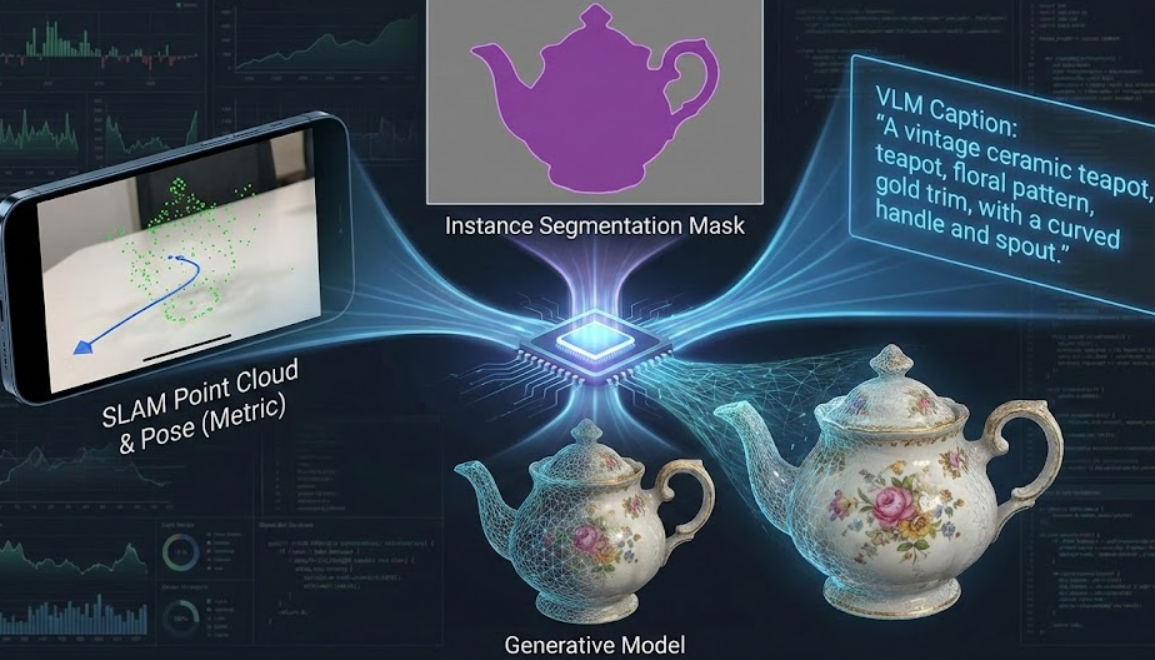
所以 ShapeR 基本概念就是通过这三者完成建模:
- SLAM 提供骨架和尺子:"雕像必须这么高,膝盖必须在这里,不能乱动。"(保证准确度)
- 实例分割提供一个轮廓剪影:"只能在这个范围内雕刻,别把旁边的花瓶也雕进去了。"(保证独立性)
- VLM Caption 提供附录:"这可是个由桃花心木做的 18 世纪风格椅子,纹理要细腻。"(保证细节和合理性)

那么从前面的概念也可以看出来,ShapeR 的特点是:它不是直接重建一个整体 NeRF / TSDF 场景块,而是先检测场景中的多个对象 ,然后对每个对象单独重建 mesh ,最后再组装成场景 。

所以在 ShapeR 里,你可以:
-
单独拿出某个物体(比如椅子/桌子)
-
替换/移动/重新摆放
-
导出到 DCC/引擎里编辑(Blender/Unity/Unreal)
换个概念简单理解,以前你只能得到一个 PNG,现在你可以得到一个 PSD
那你可能会说,它有什么作用?实际上它的作用还挺丰富,比如:
- AR 场景理解 / 虚拟摆放
- 机器人避障、navigation
- 具身 AI 的数据集构建(真实物体 mesh + 尺度)
ShapeR 可以把"现实物体"的视频快速转成结构化的 3D 资产(mesh 级别),当然,事实上 ShapeR 不是"直接吃视频就出 3D",它吃的是 预处理后的 per-object 数据包(pkl),里面包含:
- 物体的稀疏 metric point cloud(来自 SLAM / SfM)
- 带位姿的多视图图像(posed images)
- 物体的 caption 文本描述
- 物体的 2D/3D 实例信息(用于从场景里拆出物体)
所以 ShapeR 的核心难点确实不在模型推理本身,而在于数据准备 ,目前 ShapeR 的代码库明确指出,它的前提是假设数据已经通过 Aria MPS (Machine Perception Services) 流水线处理过。
所以不得不说,官方宣传的"随手拍"很美好,但是实际上并不是想象中那么简单,在他们提供的场景下:
- 录制设备 :Meta 内部的 Project Aria 眼镜(智能眼镜)
- 数据准备 :使用 【Aria MPS 服务】+ 【3D 实例检测】 + 【VLM caption】将眼镜录制的数据转换为上述的
.pkl格式
这里的 Aria MPS 是闭源的服务,MPS 内部使用的 SLAM(定位与地图构建)、3D 重建、手部追踪等核心算法,暂时只面向 Project Aria Research Kit(ARK)研究合作伙伴开放。
目前官方已经发布 ShapeR Evaluation Dataset ,里面每个样本就是推理要用的 .pkl(包含点云、multi-view 图像、相机参数/位姿、caption、GT mesh 等),如果只是想测试,可以下载他们的 evaluation dataset(HuggingFace 上的 facebook/ShapeR-Evaluation,项目页也有 Data 链接),直接跑推理:
sh
python infer_shape.py --input_pkl <sample.pkl> --config balance --output_dir output所以,如果你不是合作伙伴,没有 Project Aria 眼镜,那么你只能用它已有的数据集玩玩,从项目看,大概率这会是一个服务收费的项目。
那我们有没有机会自己玩一下呢?也是有的,ShapeR 特意提供了一个 explore_data.ipynb 来解释这个 pkl 的结构:

只是自己做数据这个过程就相当麻烦了,你需要的路径就会复杂很多,并且也不确定是否可以走的通,我们需要使用 ARKit/ARCore 采集数据(录 RGB 帧 + 时间戳 + IMU + 相机内参,最好还有 VIO/轨迹),比如用 iPhone 的 Stray Scanner 数据采集的 App,它能记录 video + depth( LiDAR)+ ARKit 的 VIO(里程计/位姿) 。
当然,Stray Scanner 导出的数据格式不能直接支持 ShapeR 要求的输入格式(单一结构化
.pkl),所以需要转为它支持的格式,这个目前需要自己参考项目数据结构去变更,工作量巨大。
另外,官方也提供了一个叫 MapAnything 的"通用、前馈式 metric 3D 重建模型",可以从输入图像(ShapeR 甚至可以从单目图像 生成度量三维形状,而无需重新训练)直接回归带度量尺度的几何和相机信息,所以也可以作为 ShapeR "替代 MPS 的 metric points 生成器" 。
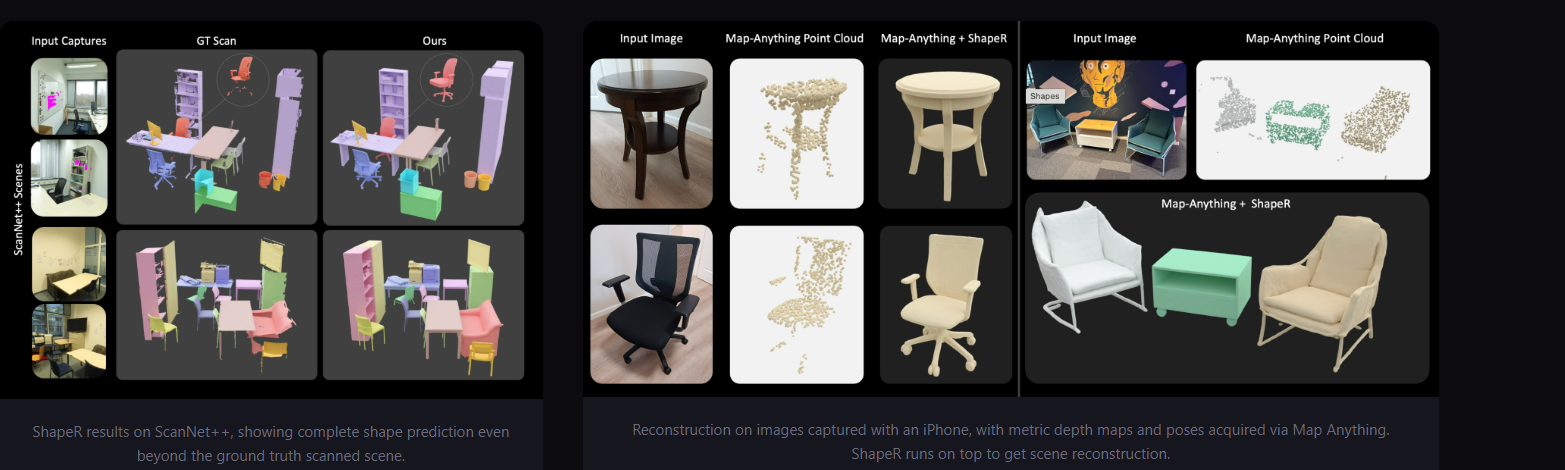
所以,一般来说,我们只能期待后续有更完善的转换工具,或者社区第三方的工具支持,这才是真的可以做到随手建模,甚至实时运算的效果,但是这个路线,不管对于智能眼镜,XR 场景还是机器人的导航能力,都是一个非常不错的尝试方向。
最后总结一下,ShapeR 的核心就是即使数据不全不干净,也可以脑补出完整模型,并且具备精准的尺寸和独立的模型与坐标。
ShapeR 不是为了替代 Gaussian Splatting 做场景漫游的,它的目标是:当你戴着 AR 眼镜(或拿着手机)扫过房间时,它能把你看到的每一个具体的物体(杯子、椅子、键盘)瞬间变成一个个独立的、有真实尺寸的、完整的 3D 模型,哪怕你只是匆匆扫了一眼。
这就是为什么 Meta 如此重视它,因为这是大概率通往下一代空间计算理解物理世界的关键技术。
