目录
[1. 核心业务需求](#1. 核心业务需求)
[2. 非功能需求](#2. 非功能需求)
[1. 初始化与基础配置(__init__方法)](#1. 初始化与基础配置(__init__方法))
[2. UI 组件开发(create_widgets 方法)](#2. UI 组件开发(create_widgets 方法))
[3. 日志系统开发(log_message/clear_log 方法)](#3. 日志系统开发(log_message/clear_log 方法))
[4. 文件导入模块开发](#4. 文件导入模块开发)
[(2)单文件 / 批量 / 文件夹导入](#(2)单文件 / 批量 / 文件夹导入)
[5. 核心数据处理模块开发](#5. 核心数据处理模块开发)
(2)单个文件处理(process_single_file)
[6. 汇总表生成模块(generate_summary_button)](#6. 汇总表生成模块(generate_summary_button))
[7. 重置功能(reset_all)](#7. 重置功能(reset_all))
[1. 核心测试场景](#1. 核心测试场景)
[2. 关键优化点](#2. 关键优化点)
[步骤 1:创建并激活纯净虚拟环境打开 Anaconda Prompt,执行以下命令(复制粘贴即可)](#步骤 1:创建并激活纯净虚拟环境打开 Anaconda Prompt,执行以下命令(复制粘贴即可))
[步骤 2:切换目录并快速打包](#步骤 2:切换目录并快速打包)
[步骤 3:验证结果](#步骤 3:验证结果)
一、引言
本文介绍的项目是一款面向学习通签到数据的可视化统计工具,核心目标是解决学习通导出的签到表格手动统计效率低、易出错的问题。下面将详细讲解学习通签到统计工具开发过程以及Python代码完整实现。
项目体验地址:针对高校教师统计学习通签到数据的通用工具资源-CSDN下载
二、第一阶段:需求分析与功能规划
开发前首先明确核心需求,确保工具贴合实际使用场景:
1. 核心业务需求
- 支持导入单文件、多文件、整个文件夹的学习通签到文件(Excel/CSV 格式);
- 自动识别文件中 "签到状态" 相关表头(解决学习通导出文件表头行不固定的问题);
- 多维度统计签到状态:区分 "已签、教师代签、迟到、未参与",并计算 "最终签到统计"(前三者算有效签到,未参与算无效);
- 生成单个文件的统计结果(带新增统计列),并支持多文件汇总(按学生维度统计总次数);
- 处理过程中给出可视化反馈(进度条、状态提示),并记录操作日志(便于排查问题)。
2. 非功能需求
- 易用性:GUI 界面操作,无需命令行,适配普通用户;
- 容错性:处理文件时捕获权限错误、列缺失、格式错误等异常,给出友好提示;
- 兼容性:支持 Excel(.xlsx)和 CSV 格式,过滤临时文件(如~$ 开头的 Excel 临时文件);
- 可回溯:日志记录所有操作,支持清空日志、重置所有数据。
三、第二阶段:技术选型
结合需求与开发成本,选择轻量、易部署的技术栈:
| 技术 / 库 | 选型理由 |
|---|---|
| Python 3.8+ | 生态丰富,数据处理库成熟,跨平台,打包成 exe 后无需安装运行环境 |
| tkinter + ttk | Python 内置 GUI 库,无需额外安装,足够支撑轻量桌面应用;ttk 提升界面美观度 |
| pandas | 高效处理表格数据,支持 Excel/CSV 读写、分组统计,是 Python 表格处理的首选库 |
| openpyxl | pandas 写入 Excel 的依赖库,支持.xlsx 格式,处理大数据量更稳定 |
| os/pathlib | 处理文件路径、遍历文件夹,跨平台兼容 |
| datetime | 生成日志时间戳,记录操作时间 |
| warnings | 过滤 openpyxl 的样式警告,提升运行体验 |
| pyinstaller(后续打包) | 将代码打包成 exe,方便非技术用户使用 |
四、第三阶段:架构设计
采用面向对象(OOP) 设计,将功能封装为AttendanceApp类,核心优势是 "数据与逻辑封装、代码复用、便于维护"。类的核心结构如下:

核心设计思路:
- 全局变量 :
file_paths存储导入的文件路径,summary_data缓存汇总数据,避免重复计算; - UI 与逻辑分离 :
create_widgets()只负责 UI 渲染,业务逻辑封装在独立方法中; - 异常分层处理:批量处理时捕获单个文件的异常,不影响其他文件处理;
- 用户反馈闭环:操作→进度条更新→状态提示→日志记录,全程可视化。
五、第四阶段:分模块详细开发
1. 初始化与基础配置(__init__方法)
python
def __init__(self, root):
self.root = root
self.root.title("学习通签到统计工具")
self.root.geometry("900x700") # 固定窗口大小,适配主流屏幕
# 全局变量初始化:存储文件路径和汇总数据
self.file_paths = []
self.summary_data = []
# 过滤openpyxl的样式警告(提升用户体验)
warnings.filterwarnings('ignore', category=UserWarning, module='openpyxl')
# 初始化UI
self.create_widgets()- 初始化主窗口的标题、尺寸,定义核心全局变量;
- 过滤第三方库的无关警告,避免日志 / 控制台出现冗余信息。
2. UI 组件开发(create_widgets 方法)
按 "功能分区" 构建 UI,确保布局清晰、操作符合用户习惯:
| 组件区域 | 核心控件与作用 |
|---|---|
| 顶部说明区 | Label 控件:显示工具名称、功能说明,字体放大提升辨识度 |
| 按钮操作区 | Button 控件:导入文件(单 / 多 / 文件夹)、重置、处理文件、生成汇总表,按 "操作流程" 排列 |
| 文件列表区 | Listbox + Scrollbar:显示已导入文件,支持滚动查看,适配多文件场景 |
| 进度反馈区 | Progressbar + Label:显示处理进度、当前状态(如 "等待导入文件") |
| 日志记录区 | ScrolledText + Button:滚动日志框(禁用手动编辑)、清空日志按钮 |
关键实现细节:
- 按钮区使用
ttk.Frame包裹,通过side=tk.LEFT/RIGHT排列,保证布局整齐; - 日志框设置为
tk.DISABLED状态,避免用户误编辑,仅通过log_message方法写入; - 所有控件的
pack方法添加padx/pady(内边距),提升界面美观度。
3. 日志系统开发(log_message/clear_log 方法)
日志是工具的 "调试与追溯" 核心,设计要点:
python
def log_message(self, message, level="INFO"):
timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S") # 精确到秒的时间戳
log_entry = f"[{timestamp}] [{level}] {message}\n" # 标准化日志格式
# 临时启用日志框,写入内容后禁用
self.log_text.config(state=tk.NORMAL)
self.log_text.insert(tk.END, log_entry)
self.log_text.see(tk.END) # 自动滚动到最新日志
self.log_text.config(state=tk.DISABLED)- 日志包含 "时间戳 + 级别 + 内容",级别分为 INFO/WARNING/ERROR,便于区分操作类型;
- 自动滚动到最新日志,无需用户手动翻页;
clear_log方法提供日志清空功能,同时记录 "日志已清空" 的操作,保证日志链完整。
4. 文件导入模块开发
解决 "如何便捷导入文件并过滤无效文件" 的问题,核心是 3 个导入方法 + 1 个辅助方法:
(1)临时文件过滤(is_temp_file)
学习通导出文件时可能生成临时文件(如~$xxx.xlsx),需过滤避免处理错误:
python
def is_temp_file(self, file_path):
filename = os.path.basename(file_path)
return filename.startswith('~$') or filename.startswith('.') # 过滤Excel临时文件/隐藏文件(2)单文件 / 批量 / 文件夹导入
import_single_file:调用filedialog.askopenfilename选择单个文件,校验后加入列表;import_multiple_files:调用askopenfilenames选择多文件,批量校验、统计导入 / 跳过数量;import_folder:调用askdirectory选择文件夹,通过os.walk遍历所有 Excel/CSV 文件,批量导入;- 所有导入方法最终调用
update_file_list更新 Listbox 显示,并通过日志反馈导入结果。
关键设计:
- 校验文件是否已导入(避免重复)、是否为临时文件(避免无效处理);
- 统计 "成功导入 / 跳过" 数量,通过日志和状态标签反馈,提升透明度。
5. 核心数据处理模块开发
这是工具的 "业务核心",解决 "如何解析学习通文件并统计数据" 的问题,分为 3 个核心方法:
(1)动态查找表头行(find_header_row)
学习通导出的签到文件表头行不固定(可能第 1 行是标题,第 2 行是表头),需动态定位包含 "签到状态" 的行:
python
def find_header_row(self, df):
for i, row in df.iterrows():
if '签到状态' in str(row.values): # 遍历每行,查找包含目标字段的行
return i
return None # 未找到则返回None,后续抛出异常- 先以
header=None读取整个文件(无表头),遍历所有行查找 "签到状态"; - 找到后再以该行为表头重新读取文件,确保列名正确。
(2)单个文件处理(process_single_file)
这是数据处理的核心,步骤拆解:
-
读取文件 :根据后缀(xlsx/csv)选择
pd.read_excel/read_csv,先读取全量数据找表头; -
校验表头 :若未找到 "签到状态" 行,抛出
ValueError; -
重新读取 + 列名清理:以找到的表头行重新读取,清理列名空格(避免 "姓名" 和 "姓名" 被识别为不同列);
-
关键列校验 :检查是否包含
['姓名', '学号/工号', '签到状态']等必填列,缺失则抛出KeyError; -
多维度统计 :
python# 已签统计:仅"已签"算1,其他状态算0 df['已签统计'] = df['签到状态'].apply(lambda x: 1 if str(x).strip() == '已签' else 0 if str(x).strip() in ['教师代签', '迟到', '未参与'] else None) # 最终签到统计:已签/教师代签/迟到算1,未参与算0(核心统计维度) df['最终签到统计'] = df['签到状态'].apply(lambda x: 1 if str(x).strip() in ['已签', '教师代签', '迟到'] else 0 if str(x).strip() == '未参与' else None)- 每个统计列仅针对目标状态标 1,其他有效状态标 0,未知状态标 None(便于后续排查异常);
-
保存统计结果 :
- 优先保存到原文件同目录(命名为 "原文件名_统计结果.xlsx");
- 若原路径无权限(如文件在只读文件夹),弹出保存对话框让用户选择路径;
-
缓存汇总数据 :将当前文件的统计结果存入
summary_data,为后续汇总表做准备。
(3)批量处理文件(process_files)
实现 "批量处理 + 异常隔离 + 进度反馈":
- 校验是否有导入文件,无则提示并返回;
- 初始化进度条(最大值为文件数量),重置汇总数据;
- 遍历所有文件,逐个调用
process_single_file; - 异常处理:捕获
PermissionError(文件被占用)、KeyError(列缺失)、通用Exception,记录失败数,不中断批量处理; - 实时更新进度条(
self.root.update_idletasks()强制刷新 UI); - 处理完成后,通过弹窗 + 日志反馈 "成功 / 失败数量"。
6. 汇总表生成模块(generate_summary_button)
解决 "多文件按学生维度汇总" 的需求,核心逻辑:
- 校验
summary_data是否为空(无处理结果则提示); - 将汇总数据转为 DataFrame,按
['姓名', '学号/工号', '学校', '院系', '专业', '行政班级']分组(确保学生唯一); - 对所有统计列求和(
agg({'已签统计':'sum', ...})),并重命名为 "总 XXX 统计"; - 弹出保存对话框,将汇总结果保存为 Excel 文件;
- 反馈汇总结果(统计学生数量、保存路径)。
7. 重置功能(reset_all)
支持用户 "清空所有数据重新操作",设计要点:
- 弹出确认对话框(避免误操作);
- 清空全局变量(
file_paths/summary_data)、文件列表、进度条、状态标签; - 记录重置日志,反馈重置完成。
六、第五阶段:测试与优化
开发完成后,需覆盖多场景测试,修复问题并优化体验:
1. 核心测试场景
| 测试场景 | 测试目的 | 测试结果 |
|---|---|---|
| 导入单个 Excel/CSV 文件 | 验证文件读取、表头查找、统计是否正确 | 统计列生成正常,文件保存成功 |
| 导入临时文件(~$xxx.xlsx) | 验证临时文件过滤逻辑 | 自动跳过,日志提示 "跳过临时文件" |
| 导入缺失 "签到状态" 列的文件 | 验证列校验、异常提示 | 弹出错误提示,日志记录 KeyError |
| 导入被占用的文件 | 验证权限错误处理、保存对话框弹出 | 提示权限错误,弹出保存对话框 |
| 批量导入 10 + 文件 | 验证进度条、批量处理、异常隔离 | 进度条实时更新,失败文件不影响其他 |
| 生成汇总表 | 验证分组求和、列重命名、保存 | 汇总数据正确,列名符合预期 |
| 重置所有数据 | 验证数据清空、UI 重置 | 所有数据 / UI 恢复初始状态 |
2. 关键优化点
- 过滤 openpyxl 的样式警告(避免日志冗余);
- 日志自动滚动到最新条目(无需手动翻页);
- 进度条实时刷新(
update_idletasks强制 UI 更新); - 列名清理(
col.strip()):解决学习通文件列名带空格的问题; - 多维度统计:满足用户对不同签到状态的细分统计需求。
七、学习通签到统计工具的Python代码完整实现
python
import tkinter as tk
from tkinter import ttk, filedialog, messagebox, scrolledtext
import pandas as pd
import os
from pathlib import Path
import datetime
import warnings
class AttendanceApp:
def __init__(self, root):
self.root = root
self.root.title("学习通签到统计工具")
self.root.geometry("900x700")
# 全局变量
self.file_paths = []
self.summary_data = []
# 过滤openpyxl的样式警告
warnings.filterwarnings('ignore', category=UserWarning, module='openpyxl')
# 创建UI组件
self.create_widgets()
def create_widgets(self):
# 顶部说明
ttk.Label(self.root, text="学习通签到统计工具", font=("微软雅黑", 16)).pack(pady=10)
ttk.Label(self.root, text="支持CSV/Excel文件导入,自动统计签到次数").pack(pady=5)
# 按钮区域
button_frame = ttk.Frame(self.root)
button_frame.pack(pady=10, fill=tk.X, padx=20)
ttk.Button(button_frame, text="导入单个文件", command=self.import_single_file).pack(side=tk.LEFT, padx=5)
ttk.Button(button_frame, text="批量导入文件", command=self.import_multiple_files).pack(side=tk.LEFT, padx=5)
ttk.Button(button_frame, text="导入文件夹", command=self.import_folder).pack(side=tk.LEFT, padx=5)
# 重置按钮
ttk.Button(button_frame, text="重置所有", command=self.reset_all).pack(side=tk.RIGHT, padx=5)
ttk.Button(button_frame, text="处理选中文件", command=self.process_files).pack(side=tk.RIGHT, padx=5)
# padx参数移到pack方法中(ttk.Button初始化不支持padx)
ttk.Button(button_frame, text="生成汇总表", command=self.generate_summary_button).pack(side=tk.RIGHT, padx=10)
# 文件列表显示
file_frame = ttk.Frame(self.root)
file_frame.pack(pady=5, fill=tk.BOTH, expand=True, padx=20)
ttk.Label(file_frame, text="已导入文件列表:").pack(anchor=tk.W)
self.file_listbox = tk.Listbox(file_frame, height=8)
self.file_listbox.pack(side=tk.LEFT, fill=tk.BOTH, expand=True)
# 滚动条
file_scroll = ttk.Scrollbar(file_frame, orient=tk.VERTICAL, command=self.file_listbox.yview)
file_scroll.pack(side=tk.RIGHT, fill=tk.Y)
self.file_listbox.config(yscrollcommand=file_scroll.set)
# 进度条
self.progress = ttk.Progressbar(self.root, orient=tk.HORIZONTAL, length=400, mode='determinate')
self.progress.pack(pady=5)
# 状态标签
self.status_label = ttk.Label(self.root, text="等待导入文件...")
self.status_label.pack(pady=5)
# 日志区域
log_frame = ttk.Frame(self.root)
log_frame.pack(pady=5, fill=tk.BOTH, expand=True, padx=20)
ttk.Label(log_frame, text="操作日志:").pack(anchor=tk.W)
self.log_text = scrolledtext.ScrolledText(log_frame, height=15, state=tk.DISABLED, wrap=tk.WORD)
self.log_text.pack(fill=tk.BOTH, expand=True)
# 清空日志按钮
ttk.Button(log_frame, text="清空日志", command=self.clear_log).pack(side=tk.RIGHT, pady=5)
def log_message(self, message, level="INFO"):
"""添加日志信息"""
# 生成时间戳
timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
# 格式化日志内容
log_entry = f"[{timestamp}] [{level}] {message}\n"
# 启用文本框,添加内容,然后禁用
self.log_text.config(state=tk.NORMAL)
self.log_text.insert(tk.END, log_entry)
# 自动滚动到最后
self.log_text.see(tk.END)
self.log_text.config(state=tk.DISABLED)
def clear_log(self):
"""清空日志"""
self.log_text.config(state=tk.NORMAL)
self.log_text.delete(1.0, tk.END)
self.log_text.config(state=tk.DISABLED)
self.log_message("日志已清空", "INFO")
def reset_all(self):
"""重置所有状态(重新统计)"""
# 确认重置操作
if messagebox.askyesno("确认重置", "是否确定重置所有数据?这将清空已导入的文件和统计数据!"):
# 清空全局变量
self.file_paths = []
self.summary_data = []
# 清空文件列表
self.file_listbox.delete(0, tk.END)
# 重置进度条
self.progress['value'] = 0
# 重置状态标签
self.status_label.config(text="等待导入文件...")
# 日志记录
self.log_message("已重置所有数据:清空文件列表和汇总数据", "WARNING")
messagebox.showinfo("重置完成", "所有数据已重置,可重新导入文件进行统计")
def import_single_file(self):
"""导入单个文件"""
file_path = filedialog.askopenfilename(
filetypes=[("Excel文件", "*.xlsx"), ("CSV文件", "*.csv")]
)
if file_path and file_path not in self.file_paths and not self.is_temp_file(file_path):
self.file_paths.append(file_path)
self.update_file_list()
self.log_message(f"成功导入单个文件:{os.path.basename(file_path)}")
elif self.is_temp_file(file_path):
self.log_message(f"跳过临时文件:{os.path.basename(file_path)}", "WARNING")
def import_multiple_files(self):
"""批量导入多个文件"""
files = filedialog.askopenfilenames(
filetypes=[("Excel文件", "*.xlsx"), ("CSV文件", "*.csv")]
)
imported_count = 0
skipped_count = 0
for file in files:
if file not in self.file_paths and not self.is_temp_file(file):
self.file_paths.append(file)
imported_count += 1
elif self.is_temp_file(file):
skipped_count += 1
self.update_file_list()
self.log_message(f"批量导入完成:成功导入{imported_count}个文件,跳过{skipped_count}个临时文件")
def import_folder(self):
"""导入整个文件夹"""
folder_path = filedialog.askdirectory()
if folder_path:
imported_count = 0
skipped_count = 0
for root, _, files in os.walk(folder_path):
for file in files:
if file.endswith(('.xlsx', '.csv')):
file_path = os.path.join(root, file)
if file_path not in self.file_paths and not self.is_temp_file(file_path):
self.file_paths.append(file_path)
imported_count += 1
elif self.is_temp_file(file_path):
skipped_count += 1
self.update_file_list()
self.log_message(f"文件夹导入完成:从{folder_path}导入{imported_count}个文件,跳过{skipped_count}个临时文件")
def is_temp_file(self, file_path):
"""判断是否是临时文件(包含~或隐藏文件)"""
filename = os.path.basename(file_path)
return filename.startswith('~$') or filename.startswith('.')
def update_file_list(self):
"""更新文件列表显示"""
self.file_listbox.delete(0, tk.END)
for file in self.file_paths:
self.file_listbox.insert(tk.END, os.path.basename(file))
self.status_label.config(text=f"已导入 {len(self.file_paths)} 个文件")
def process_files(self):
"""处理所有导入的文件(仅生成单个文件统计结果,不汇总)"""
if not self.file_paths:
messagebox.showwarning("警告", "请先导入文件!")
self.log_message("处理文件失败:未导入任何文件", "ERROR")
return
self.progress['value'] = 0
self.progress['maximum'] = len(self.file_paths)
self.summary_data = [] # 重置汇总数据
self.log_message(f"开始处理{len(self.file_paths)}个文件...")
success_count = 0
fail_count = 0
for i, file_path in enumerate(self.file_paths):
try:
self.log_message(f"正在处理文件:{os.path.basename(file_path)}")
self.process_single_file(file_path)
self.progress['value'] = i + 1
self.root.update_idletasks()
success_count += 1
self.log_message(f"文件处理成功:{os.path.basename(file_path)}")
except PermissionError:
fail_count += 1
error_msg = f"权限错误:无法访问文件{os.path.basename(file_path)},请确保文件未被打开且有读写权限"
messagebox.showerror("权限错误", error_msg)
self.log_message(error_msg, "ERROR")
except KeyError as e:
fail_count += 1
error_msg = f"列名错误:文件{os.path.basename(file_path)}缺少关键列{str(e)}"
messagebox.showerror("列名错误", error_msg)
self.log_message(error_msg, "ERROR")
except Exception as e:
fail_count += 1
error_msg = f"处理文件{os.path.basename(file_path)}时出错:{str(e)}"
messagebox.showerror("错误", error_msg)
self.log_message(error_msg, "ERROR")
self.progress['value'] = 0
self.status_label.config(text=f"文件处理完成:成功{success_count}个,失败{fail_count}个")
self.log_message(f"文件处理结束:成功{success_count}个,失败{fail_count}个")
if success_count > 0:
messagebox.showinfo("完成",
f"文件处理完成!成功{success_count}个,失败{fail_count}个\n可点击'生成汇总表'按钮创建汇总文件")
def find_header_row(self, df):
"""动态查找包含'签到状态'的表头行"""
for i, row in df.iterrows():
if '签到状态' in str(row.values):
return i
return None
def process_single_file(self, file_path):
"""处理单个签到文件"""
# 读取整个文件,用于动态检测表头
if file_path.endswith('.xlsx'):
full_df = pd.read_excel(file_path, header=None)
elif file_path.endswith('.csv'):
full_df = pd.read_csv(file_path, header=None)
# 动态查找表头行
header_row = self.find_header_row(full_df)
if header_row is None:
raise ValueError("未找到包含'签到状态'的表头行,请确认文件格式")
# 用找到的表头行重新读取文件
if file_path.endswith('.xlsx'):
df = pd.read_excel(file_path, header=header_row)
elif file_path.endswith('.csv'):
df = pd.read_csv(file_path, header=header_row)
# 清理列名中的空格和特殊字符
df.columns = [col.strip() for col in df.columns]
# 验证关键列是否存在
required_columns = ['姓名', '学号/工号', '学校', '院系', '专业', '行政班级', '签到状态']
for col in required_columns:
if col not in df.columns:
raise KeyError(col)
# 生成已签统计
df['已签统计'] = df['签到状态'].apply(
lambda x: 1 if str(x).strip() == '已签' else 0 if str(x).strip() in ['教师代签', '迟到', '未参与'] else None
)
# 生成教师代签统计
df['教师代签统计'] = df['签到状态'].apply(
lambda x: 1 if str(x).strip() == '教师代签' else 0 if str(x).strip() in ['已签', '迟到', '未参与'] else None
)
# 生成迟到统计
df['迟到统计'] = df['签到状态'].apply(
lambda x: 1 if str(x).strip() == '迟到' else 0 if str(x).strip() in ['已签', '教师代签', '未参与'] else None
)
# 生成未参与统计
df['未参与统计'] = df['签到状态'].apply(
lambda x: 1 if str(x).strip() == '未参与' else 0 if str(x).strip() in ['已签', '教师代签', '迟到'] else None
)
# 生成最终签到统计(已签/教师代签/迟到都算1,未参与算0)
df['最终签到统计'] = df['签到状态'].apply(
lambda x: 1 if str(x).strip() in ['已签', '教师代签', '迟到'] else 0 if str(x).strip() == '未参与' else None
)
# 保存处理后的文件
try:
output_path = f"{os.path.splitext(file_path)[0]}_统计结果.xlsx"
df.to_excel(output_path, index=False)
self.log_message(f"统计文件已保存:{os.path.basename(output_path)}")
except PermissionError:
# 如果原路径无法写入,让用户选择保存位置
self.log_message(f"原路径无写入权限,弹出保存对话框:{os.path.basename(file_path)}", "WARNING")
output_path = filedialog.asksaveasfilename(
defaultextension=".xlsx",
initialfile=f"{os.path.splitext(os.path.basename(file_path))[0]}_统计结果.xlsx",
filetypes=[("Excel文件", "*.xlsx")]
)
if output_path:
df.to_excel(output_path, index=False)
self.log_message(f"统计文件已保存到指定位置:{os.path.basename(output_path)}")
else:
raise PermissionError("用户取消了文件保存操作")
# 收集汇总数据(包含所有需要的字段)
file_name = os.path.basename(file_path)
for _, row in df.iterrows():
self.summary_data.append({
'姓名': row['姓名'],
'学号/工号': row['学号/工号'],
'学校': row['学校'],
'院系': row['院系'],
'专业': row['专业'],
'行政班级': row['行政班级'],
'文件名': file_name,
'已签统计': row['已签统计'],
'教师代签统计': row['教师代签统计'],
'迟到统计': row['迟到统计'],
'未参与统计': row['未参与统计'],
'最终签到统计': row['最终签到统计']
})
def generate_summary_button(self):
"""独立的汇总表生成按钮处理函数"""
if not self.summary_data:
messagebox.showwarning("警告", "暂无汇总数据!请先处理文件")
self.log_message("生成汇总表失败:暂无汇总数据", "WARNING")
return
self.log_message("开始生成汇总表...")
try:
summary_df = pd.DataFrame(self.summary_data)
# 按分组对所有统计列求和
final_summary = summary_df.groupby(
['姓名', '学号/工号', '学校', '院系', '专业', '行政班级']
).agg({
'已签统计': 'sum',
'教师代签统计': 'sum',
'迟到统计': 'sum',
'未参与统计': 'sum',
'最终签到统计': 'sum'
}).reset_index()
# 重命名列名为"总XXX统计"
final_summary.rename(columns={
'已签统计': '总已签统计',
'教师代签统计': '总教师代签统计',
'迟到统计': '总迟到统计',
'未参与统计': '总未参与统计',
'最终签到统计': '总最终签到统计'
}, inplace=True)
# 保存汇总表
save_path = filedialog.asksaveasfilename(
defaultextension=".xlsx",
initialfile="学习通签到汇总表.xlsx",
filetypes=[("Excel文件", "*.xlsx")]
)
if save_path:
final_summary.to_excel(save_path, index=False)
self.log_message(f"汇总表生成成功:{os.path.basename(save_path)}")
self.log_message(f"汇总数据:共统计{len(final_summary)}名学生的签到情况,包含多维度签到统计")
messagebox.showinfo("成功",
f"汇总表已保存!\n文件路径:{save_path}\n共统计{len(final_summary)}名学生\n包含:总已签、总教师代签、总迟到、总未参与、总最终签到统计")
else:
self.log_message("用户取消了汇总表保存操作", "WARNING")
except Exception as e:
error_msg = f"生成汇总表时出错:{str(e)}"
messagebox.showerror("错误", error_msg)
self.log_message(error_msg, "ERROR")
if __name__ == "__main__":
root = tk.Tk()
app = AttendanceApp(root)
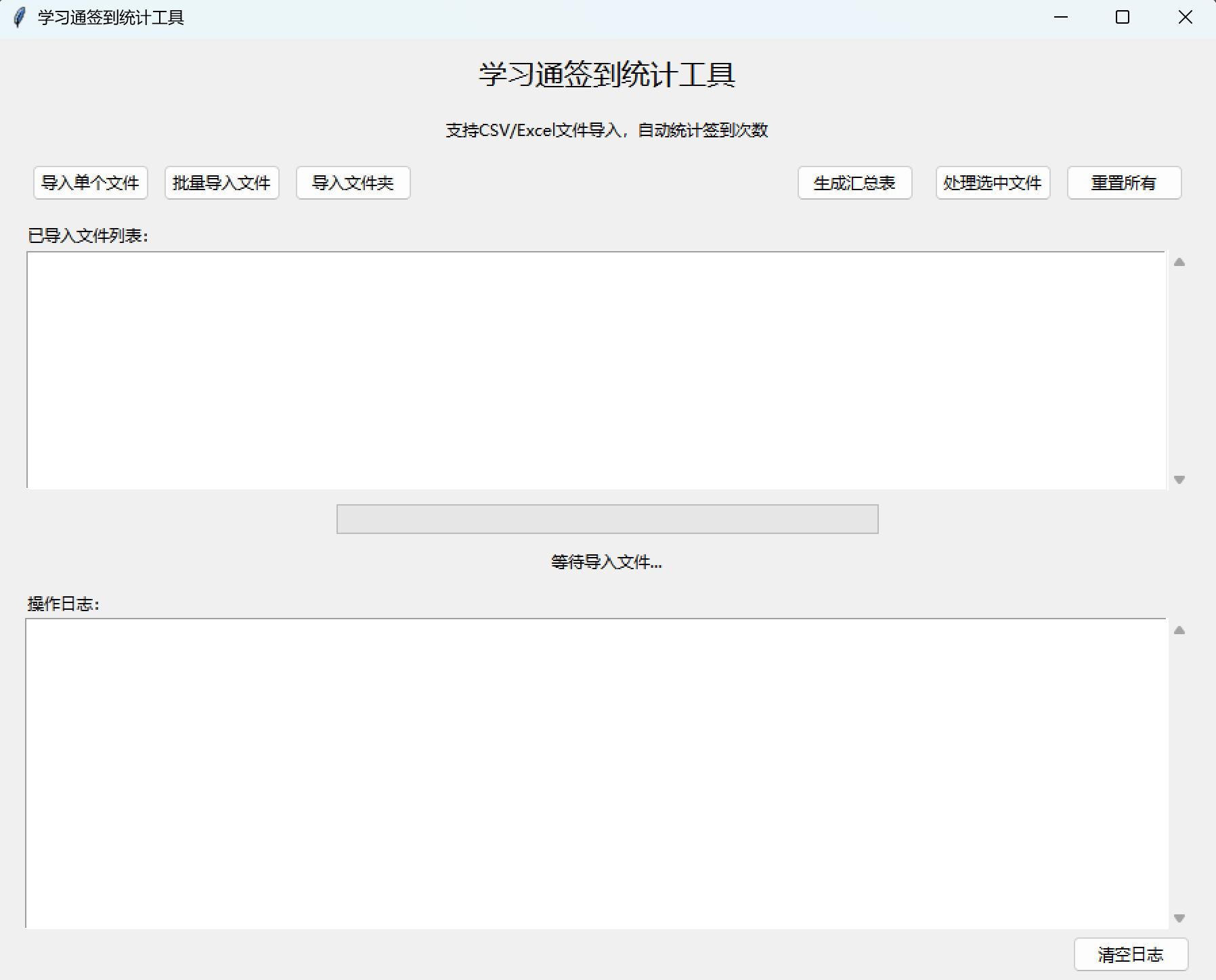
root.mainloop()八、程序运行部分截图展示
九、打包项目
步骤 1:创建并激活纯净虚拟环境打开 Anaconda Prompt,执行以下命令(复制粘贴即可)
bash
# 1. 创建仅包含Python 3.10的纯净环境(兼容性最佳,适配tkinter/pandas)
conda create -n attendance_tool python=3.10 -y
# 2. 激活该环境
conda activate attendance_tool
# 3. 仅安装必需依赖(无任何冗余,清华源加速)
pip install pandas openpyxl pyinstaller -i https://pypi.tuna.tsinghua.edu.cn/simple/步骤 2:切换目录并快速打包
bash
# 切换到你的学习通签到工具代码所在文件夹(替换为实际路径)
cd C:\Users\ABC\PycharmProjects\AttendanceTool
# 用目录模式打包(-D),速度快、体积小、稳定性高;-w隐藏控制台(GUI工具必备)
pyinstaller -w -n 学习通签到统计工具 -D 学习通签到统计工具.py步骤 3:验证结果
打包时间:仅需 1-2 分钟即可完成;
exe 位置:dist / 学习通签到统计工具 / 目录下的学习通签到统计工具.exe;
体积:约 60-90MB(对比全局环境打包的 1GB+,大幅精简);
功能:双击 exe,测试文件导入、签到统计、汇总表生成等核心功能,和原代码完全一致。
十、总结
本文介绍了一款基于Python开发的学习通签到数据统计工具,该工具通过GUI界面实现高效自动化处理,主要解决手动统计Excel/CSV签到表格效率低、易出错的问题。工具核心功能包括:支持单文件/多文件/文件夹导入;自动识别动态表头;多维度统计签到状态(已签、教师代签、迟到、未参与);生成带统计列的单个文件和汇总表。采用tkinter+ttk构建界面,pandas处理数据,具有异常处理、日志记录和进度反馈机制。经过测试验证,工具能准确处理学习通导出的各类签到文件,并通过pyinstaller打包为60-90MB的独立exe程序,方便非技术用户使用。