文章目录
-
- [1. 线程初体验](#1. 线程初体验)
-
- [1.1 demo](#1.1 demo)
- [1.2 实验结果](#1.2 实验结果)
- [1.3 实验现象与结论分析](#1.3 实验现象与结论分析)
-
- [1. 同一个进程,多个执行流](#1. 同一个进程,多个执行流)
- [2. 用 ps 观察线程](#2. 用 ps 观察线程)
- [3. 信号是针对进程的](#3. 信号是针对进程的)
- [4. pthread 需要额外链接库](#4. pthread 需要额外链接库)
- [5. 抽象进程 PCB 结构](#5. 抽象进程 PCB 结构)
- [1.4 一些重要补充](#1.4 一些重要补充)
-
- [1. 调度时间片](#1. 调度时间片)
- [2. 线程的健壮性问题](#2. 线程的健壮性问题)
- [3. 多线程打印混乱的原因](#3. 多线程打印混乱的原因)
- [2. 为什么要引入 pthread 库?](#2. 为什么要引入 pthread 库?)
-
- [2.1 POSIX 线程库(pthread)](#2.1 POSIX 线程库(pthread))
- [3. 线程创建:pthread_create](#3. 线程创建:pthread_create)
-
- [3.1 函数原型](#3.1 函数原型)
- [3.2 参数详解](#3.2 参数详解)
- [3.3 返回值](#3.3 返回值)
- [4. 线程等待:pthread_join](#4. 线程等待:pthread_join)
-
- [4.1 函数原型](#4.1 函数原型)
- [4.2 参数说明](#4.2 参数说明)
- [4.3 返回值](#4.3 返回值)
- [4.4 demo](#4.4 demo)
- [5. 关于线程 ID(pthread_t)](#5. 关于线程 ID(pthread_t))
-
- [5.1 demo](#5.1 demo)
- [5.2 实验结果](#5.2 实验结果)
- [5.3 实验结论](#5.3 实验结论)
- [5.4 关于 pthread_self](#5.4 关于 pthread_self)
-
- [1. 函数原型](#1. 函数原型)
- [2. 核心特点](#2. 核心特点)
- [6. 线程终止问题](#6. 线程终止问题)
-
- [6.1 pthread_exit](#6.1 pthread_exit)
- [6.2 线程退出的几种方式对比](#6.2 线程退出的几种方式对比)
- [6.3 pthread_cancel](#6.3 pthread_cancel)
- [6.4 非阻塞 join:线程分离(detach)](#6.4 非阻塞 join:线程分离(detach))
-
- [6.4.1 线程的两种状态](#6.4.1 线程的两种状态)
- [6.4.2 pthread_detach](#6.4.2 pthread_detach)
- [6.4.3 pthread_detach vs pthread_join 核心对比](#6.4.3 pthread_detach vs pthread_join 核心对比)
- [6.5 demo:主线程分离新线程](#6.5 demo:主线程分离新线程)
- [7. 多线程 demo](#7. 多线程 demo)
- [8. 线程 ID 与线程库底层原理](#8. 线程 ID 与线程库底层原理)
-
- [8.1 pthread 库的本质](#8.1 pthread 库的本质)
- [8.2 线程在库中的管理方式](#8.2 线程在库中的管理方式)
- [8.3 TCB 是如何组织的?](#8.3 TCB 是如何组织的?)
核心视角:先见见线程 → 再补充线程相关知识 → 最后引入线程相关接口
1. 线程初体验
1.1 demo
cpp
#include<iostream>
#include<string>
#include<pthread.h>
#include<unistd.h>
void* threadrun(void* args)
{
std::string name = (const char*)args;
while (true)
{
std::cout << "我是新线程:name:" << name << std::endl;
sleep(1);
}
return nullptr;
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, threadrun, (void*)"thread - 1");
while (true)
{
std::cout << "我是主线程..." << std::endl;
sleep(1);
}
return 0;
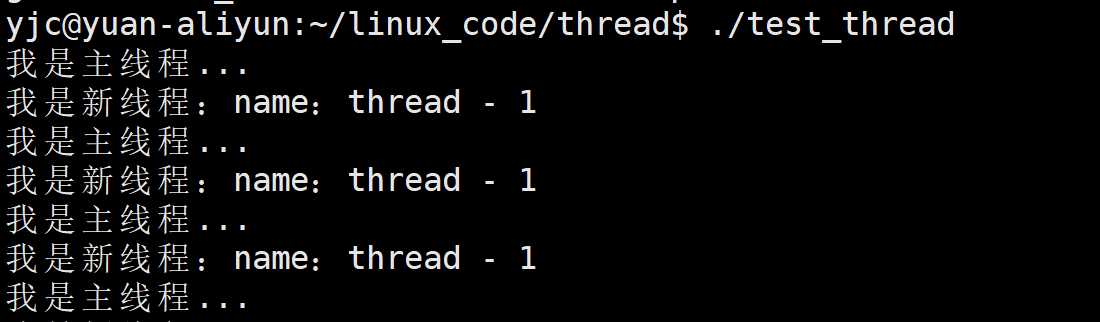
}1.2 实验结果
1.3 实验现象与结论分析
1. 同一个进程,多个执行流
从运行结果可以看到:
- 程序只有一个
- 却能看到两个"同时在跑"的执行逻辑
这说明:
同一个进程内部,存在多个执行流,也就是多个线程。

2. 用 ps 观察线程
使用命令:
bash
ps -aL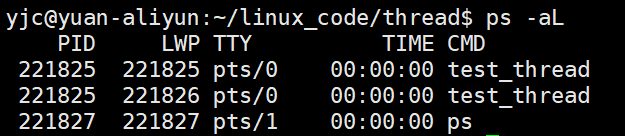
可以看到:
- 两个线程的 pid 是一样的
- 说明它们属于 同一个进程
同时注意几个字段:
- lwp(light weight process)
说明线程在 Linux 中是轻量级进程
第一个 lwp 一般是主线程 - tty
表示线程运行所在的终端
3. 信号是针对进程的
再注意一个很重要的现象:
- 信号是发送给 进程 的
- 使用
kill -9杀掉进程 - 不管多少线程,都会一起退出
4. pthread 需要额外链接库
编译时如果不加 -lpthread 会直接失败:
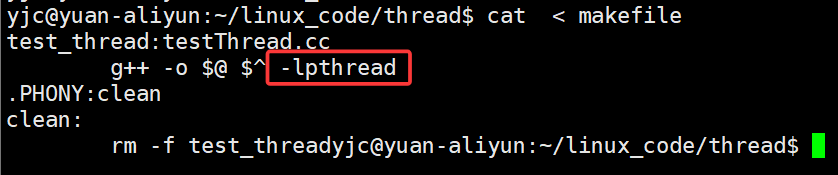
这也从侧面说明:
线程并不是内核直接提供给用户的能力,而是通过库来完成的。
5. 抽象进程 PCB 结构
我们可以抽象出一个简化版的 PCB:
c
task_struct
{
pid_t pid;
pid_t lwp;
}从这里可以推导出几个关键点:
-
进程在创建时就有
lwp -
单线程进程:
lwp == pid -
创建新线程时:
pid不变lwp增加
-
CPU 在调度时,是以 lwp 作为执行流的唯一标识
1.4 一些重要补充
1. 调度时间片
调度时,时间片是分配给 不同执行流(lwp) 的,
而不是"只按进程分"。
2. 线程的健壮性问题
一个非常关键但容易被忽略的点:
只要一个线程崩溃,整个进程都会崩溃
原因也不复杂:
- 信号是针对进程的
- 所有线程共享地址空间
所以线程模型下,对代码健壮性要求更高。
3. 多线程打印混乱的原因
多个线程同时向显示器打印时,经常会出现输出混杂:
- 向显示器打印,本质是 向文件写数据
- 显示器属于 共享资源
- 没有加保护,就会出现 原子性问题
2. 为什么要引入 pthread 库?
Q:为什么要引入 pthread?不能像以前一样直接用系统调用吗?
A:
在 Linux 中,其实 并不存在"线程"这个概念 。
Linux 内核只认:
- 进程
- 轻量级进程(LWP)
Linux 提供的系统调用只有:
vforkclone
问题就来了:
- 用户视角:我要线程
- 内核视角:我只有进程 / LWP
👉 这中间明显存在一层"鸿沟"。
于是操作系统在 用户层 引入了 pthread 库:
- 在库中封装
clone - 对用户提供"线程"的抽象接口
因此:
- Linux 的线程实现是在 用户层
- pthread 是 原生线程库
- 与 Linux 强绑定,但不属于内核
2.1 POSIX 线程库(pthread)
在 Linux 下,与线程相关的接口并不是零散存在的,而是构成了一个完整的线程库体系。
- 与线程有关的函数,几乎都以
pthread_开头 - 使用时需要包含头文件:
c
#include <pthread.h>- 编译时需要显式链接线程库:
bash
-lpthread这一步如果忘了,基本就是"编译器直接不给你面子"。
3. 线程创建:pthread_create
pthread_create 是 POSIX 线程库中用于创建新线程的核心接口,也是所有多线程程序的起点。
它的作用可以简单理解为:
在当前进程中,启动一个新的执行流,让它从指定函数开始跑。
3.1 函数原型
c
#include <pthread.h>
int pthread_create(pthread_t *thread,
const pthread_attr_t *attr,
void *(*start_routine) (void *),
void *arg);3.2 参数详解
| 参数名 | 含义 |
|---|---|
thread |
输出型参数,用于保存新创建线程的 ID |
attr |
线程属性,一般传 NULL,表示使用默认属性 |
start_routine |
线程入口函数,本质是一个回调 |
arg |
传给线程入口函数的参数 |
这里需要注意的是:
- 线程入口函数的函数签名是固定的
- 必须是:
void* func(void*)
3.3 返回值
- 成功:返回
0 - 失败:返回非 0 错误码
(注意:不会设置 errno)
4. 线程等待:pthread_join
线程创建好后,新线程要被主线程等待。如果不等待会出现类似僵尸进程的问题,本质就是内存泄漏。
pthread 库中的 pthread_join 函数,它是多线程编程中用于等待指定线程结束并回收其资源 的核心函数,也是保证线程执行顺序、避免资源泄漏的关键。
pthread_join 可以理解为"主线程(或调用线程)主动等待目标线程完成工作",调用后当前线程会阻塞,直到目标线程退出,同时回收该线程的资源(避免产生"僵尸线程"),还能获取目标线程的退出返回值。
4.1 函数原型
c
#include <pthread.h>
int pthread_join(pthread_t thread, void **retval);
4.2 参数说明
| 参数名 | 含义 |
|---|---|
thread |
要等待的目标线程的 ID(即 pthread_create 输出的 pthread_t 变量) |
retval |
输出参数,指向 void* 类型的指针,用于接收目标线程的退出返回值 : - 若不需要获取返回值,传 NULL; - 若目标线程通过 pthread_exit(ret) 退出,*retval 会被设为 ret。 |
如果你不关心线程返回值,可以直接传 NULL。
4.3 返回值
- 成功:返回
0; - 失败:返回非0错误码,常见错误如:
EINVAL:目标线程是"分离状态"(无法 join);ESRCH:指定的线程 ID 不存在;EDEADLK:检测到死锁(比如线程等待自身)。
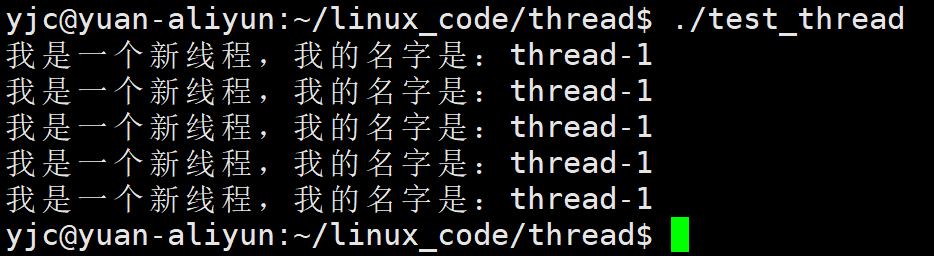
4.4 demo
cpp
#include<iostream>
#include<string>
#include<pthread.h>
#include<unistd.h>
void * routine(void * args)
{
std::string name = static_cast<const char*>(args);
int cnt = 5;
while (cnt--)
{
std::cout << "我是一个新线程,我的名字是:"<<name <<std::endl;
sleep(1);
}
return nullptr;
}
int main()
{
pthread_t tid;
int n = pthread_create(&tid, nullptr, routine, (void*)"thread-1");
(void)n;
pthread_join(tid, nullptr);
return 0;
}
static_cast<const char*>用于将
void*转换为只读字符指针,这是 C++ 下比较规范的写法。
实验结果
5. 关于线程 ID(pthread_t)
先来看一个 demo。
5.1 demo
cpp
#include<iostream>
#include<string>
#include<pthread.h>
#include<unistd.h>
void showtid(pthread_t &tid)
{
printf("tid: 0x%lx\n", tid);
}
std::string FormatId(const pthread_t &tid)
{
char id[64];
snprintf(id, sizeof(id), "0x%lx", tid);
return id;
}
void *routine(void *args)
{
std::string name = static_cast<const char *>(args);
pthread_t tid = pthread_self();
int cnt = 5;
while (cnt--)
{
std::cout << "我是一个新线程: 我的名字是: "
<< name
<< " 我的Id是: "
<< FormatId(tid)
<< std::endl;
sleep(1);
}
return nullptr;
}
int main()
{
pthread_t tid;
int n = pthread_create(&tid, nullptr, routine, (void*)"thread-1");
(void)n;
showtid(tid);
int cnt = 5;
while (cnt--)
{
std::cout << "我是main线程: 我的名字是: main thread"
<< " 我的Id是: "
<< FormatId(pthread_self())
<< std::endl;
sleep(1);
}
pthread_join(tid, nullptr);
return 0;
}5.2 实验结果
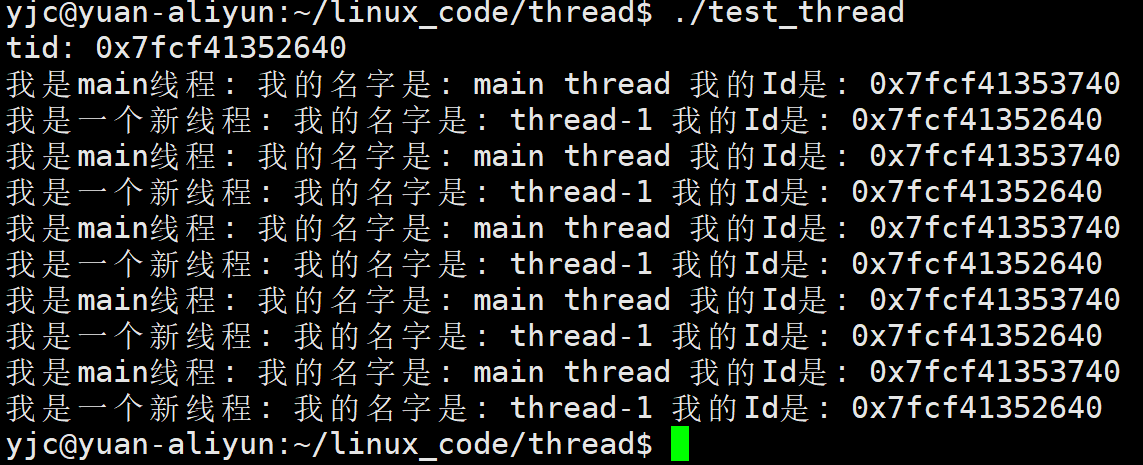
5.3 实验结论
-
线程 ID 很长,而且明显不是 lwp
- 这是刻意设计的
- pthread 已经封装了轻量级进程,就没有必要再暴露lwp给用户
- 所以lwp 对用户是透明的
-
新线程和主线程:
- 共享代码区
- 都可以调用
FormatId - 说明地址空间是共享的
同时也说明:
👉
FormatId是一个 可重入函数 -
main函数结束:- 主线程结束
- 一般也代表进程结束
-
线程入口函数结束:
- 对应线程结束
5.4 关于 pthread_self
pthread_self 函数,它是 POSIX 线程库中用于获取当前线程自身 ID 的核心函数,在调试、日志记录、线程身份识别等场景中非常常用。
pthread_self 的作用是返回调用该函数的线程 的唯一标识符(线程 ID),这个 ID 是 pthread_t 类型,与 pthread_create 创建线程时输出的 ID 一致,可用于线程的身份校验、日志标记等。
1. 函数原型
c
#include <pthread.h>
pthread_t pthread_self(void);2. 核心特点
- 参数:无参数,直接返回当前线程的 ID;
- 返回值 :当前线程的
pthread_t类型 ID; - 注意 :
pthread_t不一定是整数类型(不同系统实现不同,比如可能是结构体),因此打印时建议转换为unsigned long类型,保证兼容性。
6. 线程终止问题
线程的终止方式主要有以下几种:
-
线程入口函数 return
- 等价于
pthread_exit
- 等价于
-
不能使用
exit()exit()是进程级别的- 任意线程调用都会导致整个进程退出
-
使用
pthread_exit() -
使用
pthread_cancel()- 返回值是
PTHREAD_CANCELED(-1)
- 返回值是
6.1 pthread_exit
pthread_exit 是 pthread 库提供的线程退出函数,作用是主动终止当前调用该函数的线程,并可以向等待该线程的其他线程返回一个退出状态(返回值)。
简单类比:如果说 main 函数里的 return 是终止整个进程,那么 pthread_exit 就是专门终止单个线程的"return"。
函数原型
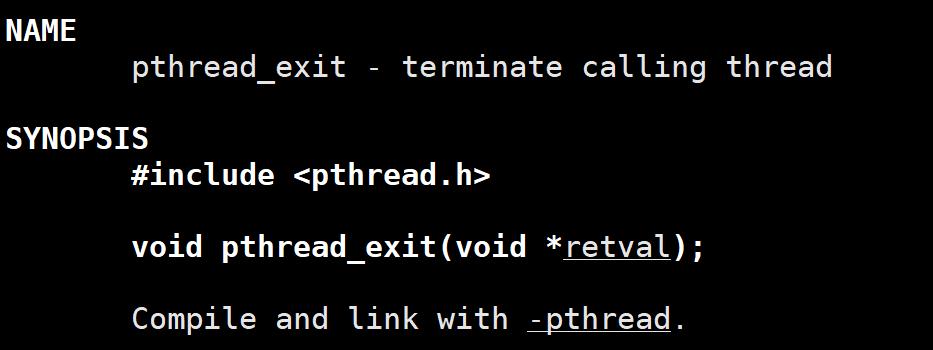
c
#include <pthread.h>
void pthread_exit(void *retval);- 参数
retval:线程的退出状态(返回值),是一个void*类型的指针,可以指向任意数据(比如整数、结构体等),其他线程可以通过pthread_join获取这个值。 - 返回值:无返回值(函数执行后线程直接终止,不会回到调用处)。
6.2 线程退出的几种方式对比
线程终止的常见方式有 3 种,pthread_exit 是最可控的一种:
| 方式 | 特点 | 适用场景 |
|---|---|---|
pthread_exit |
主动退出,可返回状态,仅终止当前线程 | 需要明确控制线程退出、返回结果 |
| 线程函数执行完毕(return) | 隐式退出,return 的值等价于 pthread_exit 的 retval |
简单场景,线程完成任务后自然结束 |
pthread_cancel |
其他线程强制终止当前线程 | 需紧急终止线程(如异常场景) |
6.3 pthread_cancel
c
#include <pthread.h>
int pthread_cancel(pthread_t thread);- 用于取消(终止)指定线程
- 是一种 异步取消机制
- 不一定立刻生效,受取消点影响
6.4 非阻塞 join:线程分离(detach)
需求场景
如果主线程不想再关心新线程, 新线程结束后希望它自己释放资源,怎么办?
答案是:
👉 把线程设置成分离态(detached)
6.4.1 线程的两种状态
-
joinable(默认)
- 需要
pthread_join
- 需要
-
detached
- 自动回收资源
- 无法再 join
6.4.2 pthread_detach
线程分离:可以主线程分离新线程,也可以新线程分离主线程。分离的线程,依旧在进程的地址空间中,进程的所有资源,被分离的线程依旧可以访问资源,可以操作,只是主线程不再等待新线程。
pthread_detach 的核心作用是:将指定的线程标记为分离态(detached) ,线程终止后,其占用的系统资源(如线程 ID、退出状态等)会被操作系统自动回收 ,无需其他线程调用 pthread_join 等待。
先明确线程的两种状态,这是理解 pthread_detach 的基础:
- 可结合态(joinable,默认) :线程终止后,资源不会自动释放,必须由其他线程调用
pthread_join获取其退出状态,否则会产生"僵尸线程"(类似进程的僵尸进程),导致资源泄漏。 - 分离态(detached) :线程终止后,资源立即被系统回收,无法再调用
pthread_join获取其退出状态(调用会失败)。
简单类比:如果说 pthread_join 是"手动回收线程资源",那么 pthread_detach 就是"设置线程为自动回收模式"。
函数原型
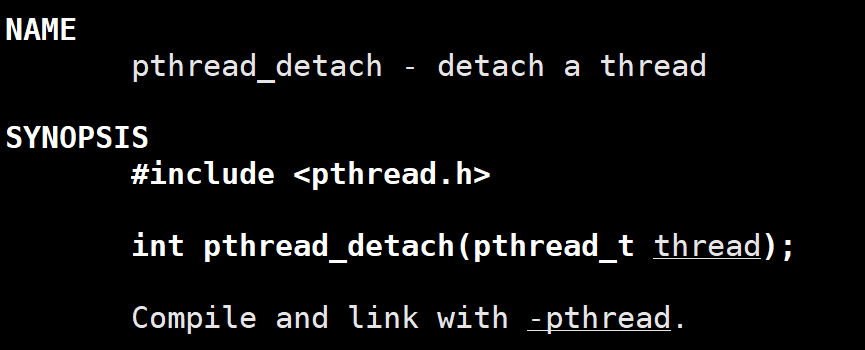
c
#include <pthread.h>
int pthread_detach(pthread_t thread);- 参数
thread:要设置为分离态的目标线程 ID。 - 返回值 :成功返回
0;失败返回非 0 的错误码(如ESRCH表示目标线程不存在,EINVAL表示线程已处于分离态)。
6.4.3 pthread_detach vs pthread_join 核心对比
| 特性 | pthread_detach |
pthread_join |
|---|---|---|
| 核心作用 | 设置线程为分离态,自动回收资源 | 等待线程终止,手动回收资源 |
| 是否阻塞 | 非阻塞(调用后立即返回) | 阻塞(直到目标线程终止) |
| 能否获取退出状态 | 不能 | 能(通过第二个参数) |
| 适用场景 | 无需关注线程退出状态的后台任务 | 需要获取线程执行结果的场景 |
6.5 demo:主线程分离新线程
cpp
#include <iostream>
#include <string>
#include <pthread.h>
#include <unistd.h>
#include <cstdio>
#include<cstring>
void *rotine(void *args)
{
std::string name = static_cast<const char *>(args);
int cnt = 10;
while (cnt--)
{
std::cout << "新线程name:" << name << std::endl;
sleep(1);
}
return (void *)10;
}
int main()
{
pthread_t tid;
pthread_create(&tid, nullptr, rotine, (void *)"thread-1");
pthread_detach(tid);
std::cout << "新线程被分离" << std::endl;
int cnt = 5;
while (cnt--)
{
std::cout << "main线程name:" << std::endl;
sleep(1);
}
int n = pthread_join(tid, nullptr);
if(n != 0)
{
std::cout << "pthread_join error: " << strerror(n) << std::endl;
}
else
{
std::cout << "pthread_join success"<< std::endl;
}
return 0;
}实验结果
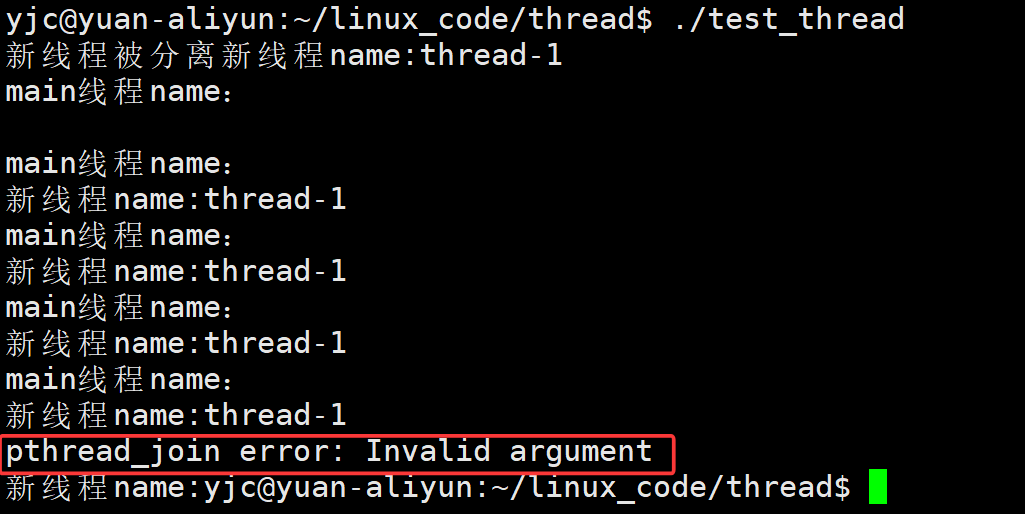
可以看到:
- join 失败
- 原因是线程已经被分离
结论很明确:
被分离的线程,不需要也不能再 join
7. 多线程 demo
cpp
#include <iostream>
#include <string>
#include <pthread.h>
#include <unistd.h>
#include <cstdio>
#include <cstring>
#include <vector>
// 多线程
int num = 10;
void *routine(void *args)
{
std::string name = static_cast<const char *>(args);
int cnt = 5;
while (cnt--)
{
std::cout << "新线程name:" << name << std::endl;
sleep(1);
}
return nullptr;
}
int main()
{
std::vector<pthread_t> tids;
for (int i = 0; i < num; i++)
{
pthread_t tid;
char id[64];
snprintf(id, sizeof(id), "thread-%d", i);
int n = pthread_create(&tid, nullptr, routine, id);
if (n == 0)
tids.push_back(tid);
else
continue;
sleep(1);
}
for (int i = 0; i < num; i++)
{
int n = pthread_join(tids[i], nullptr);
if (n == 0)
std::cout << "等待新线程成功" << std::endl;
else
std::cout << "等待失败" << std::endl;
}
return 0;
}实验结果:
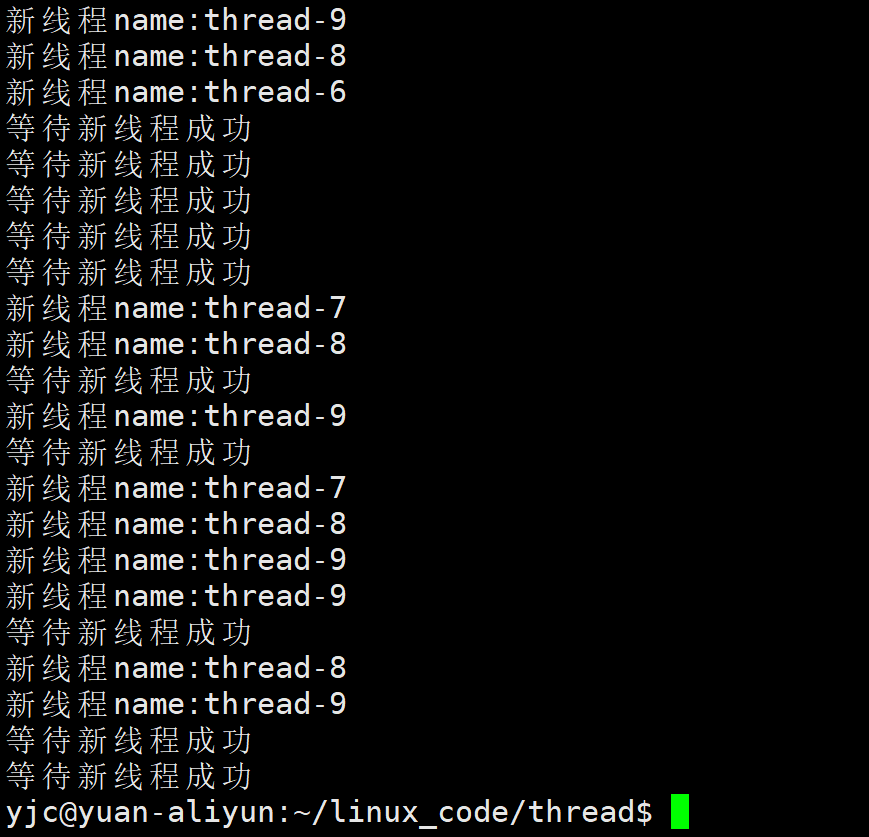
可以看到:
-
成功创建多个线程
-
创建过程中:
- 有的线程被新建
- 有的已经退出
8. 线程 ID 与线程库底层原理
在讨论线程 ID 之前,先对齐一下颗粒度(好装...今天学的新词)。
Linux 下没有真正意义上的线程,
而是用 轻量级进程(LWP)模拟线程 。
操作系统提供的系统调用接口,不会直接提供线程相关接口。为了抹平用户和操作系统的鸿沟,在用户层就封装轻量级进程,形成原生线程库。
8.1 pthread 库的本质
- 可执行程序是 ELF
- pthread 库本身也是 ELF
可执行程序在加载到内存形成进程时,要进行动态链接和动态地址重定向。同时动态库也应该加载到内存,并且映射到当前进程的地址空间中。
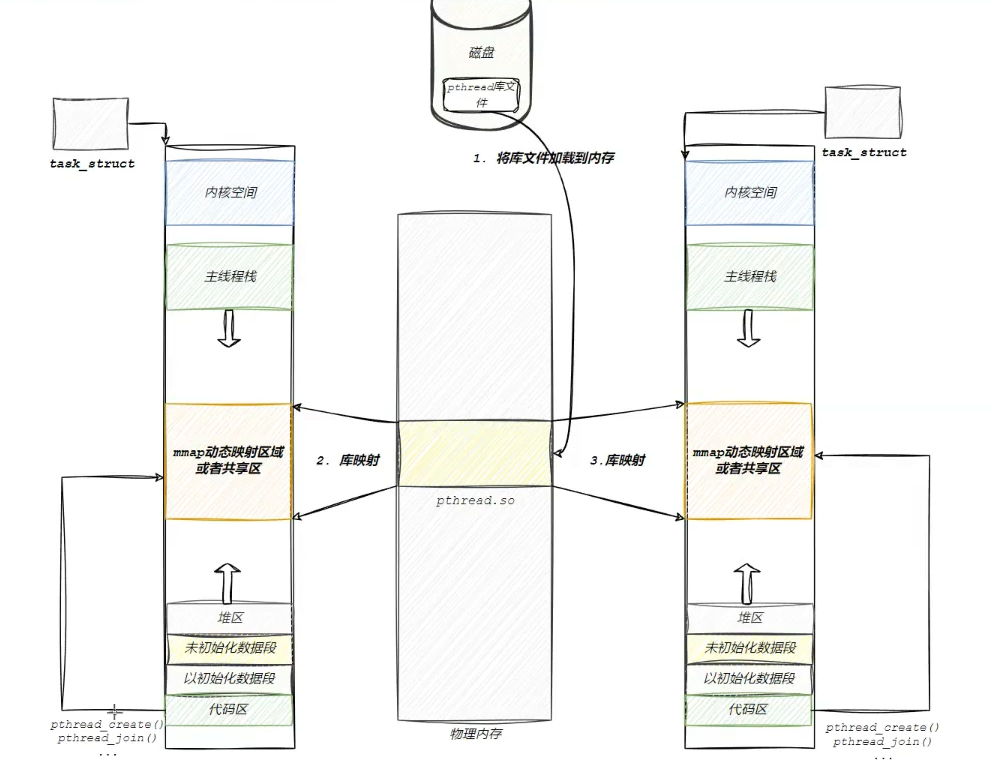
结论:
进程自己的代码区,可以直接访问线程库内部的数据和函数
8.2 线程在库中的管理方式
线程的概念是库中维护的,在库的内部就一定会存在多个被创建好的线程,库就要管理这些线程。管理的方法是:先描述再组织。
所以再库中就一定有类似于struct tcb{}的东西,包含线程相关的属性。
有点小逆天,在库里面怎么能管理线程那?其实本质上是因为我们调用pthread_creat()函数的时候,系统就帮我们创建了tcb对象。而且我还要告诉你的是:在tcb中,是不需要写优先级,时间片,上下文这些信息的。因为这些调度信息是内核的事儿,被写在lwp中。
线程的概念是在库中维护的,因此:
- 库中一定存在类似
struct tcb {}的结构 - 用于保存线程相关属性
注意一个很反直觉但很关键的点:
TCB 中不需要调度信息
比如优先级、时间片、上下文
因为这些信息属于 内核 ,
写在 lwp 里。
8.3 TCB 是如何组织的?
ok,上面通过tcb已经将线程描述好了,现在的问题是如何将多个线程组织起来呢?
当调用 pthread_create 时:
-
在线程库中:
- 创建 TCB
- 分配线程栈
-
在内核中:
- 通过
clone创建 LWP - 绑定线程栈和入口函数
- 通过
线程库用数组等结构管理这些 TCB。
👉 用户拿到的 pthread_t,本质上就是 TCB 的虚拟地址。
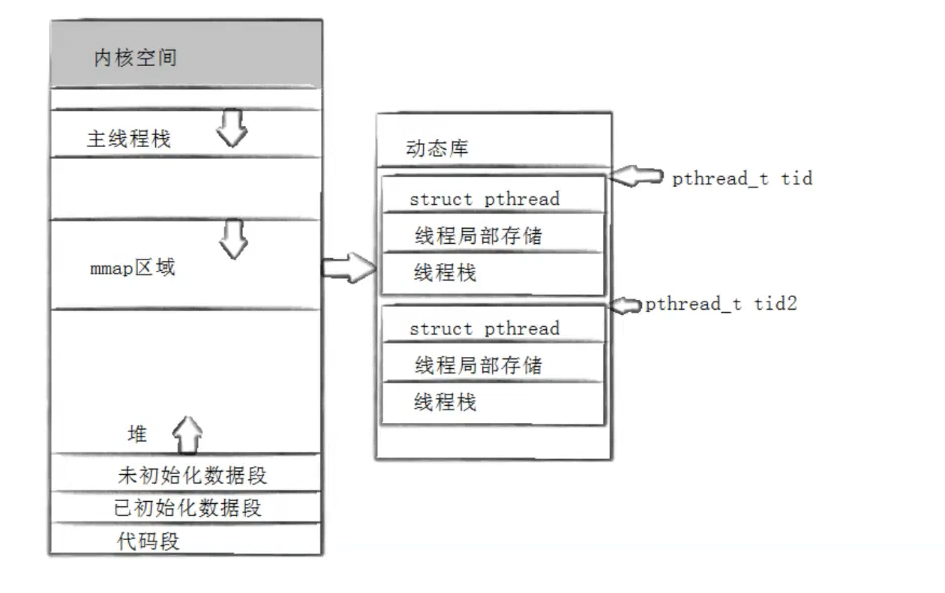
mmap就是共享区,其中映射了pthread库。每当我们调用pthread_creat函数,就会在库中创建对应的tcb和线程栈。动态库用数组管理这些tcb。而用户拿到的tid就是在线程库中,对应的管理块儿的虚拟地址!太妙了这里。
在tcb中存在属性void* ret,当线程的代码执行结束,我们手动返回一个值,实际上就是将返回值写入ret属性中。
并且,虽然线程的代码执行完了,但是tcb等资源依旧存在,所以必须要用pthread_join等待,我们也就理解了pthread_join函数参数必须要传入tid,并且通过第二个参数带出返回值。
继续考虑一个问题,线程是在库中有tcb也在内核中有lwp的,所以库和内核要联动管理线程。当我们调用pthread_creat函数的时候,既要在库中创建线程控制管理块,也要在内核中创建轻量级进程(这里就要调用系统调用了,并且要告诉内核执行什么方法:系统调用的方法是clone,线程对应的栈在哪里:线程栈的地址)通过pthread_creat就将内核和库对线程的管理联动起来了。
完