目录
[1. 语言与库限制](#1. 语言与库限制)
[2. 各策略ASL计算方法](#2. 各策略ASL计算方法)
[3. 比较次数统计口径](#3. 比较次数统计口径)
[4. Normalize函数](#4. Normalize函数)
[5. Time33哈希函数](#5. Time33哈希函数)
[6. 关键注意事项](#6. 关键注意事项)
[7. 常见问题](#7. 常见问题)
[1. 单词标准化函数 Normalize(题目强制要求)](#1. 单词标准化函数 Normalize(题目强制要求))
[2. Time33 哈希函数 myHash(题目强制要求,重命名避免关键字冲突)](#2. Time33 哈希函数 myHash(题目强制要求,重命名避免关键字冲突))
[1. 线性表节点(策略 1/2 专用)](#1. 线性表节点(策略 1/2 专用))
[2. 哈希表节点(策略 3 专用,链地址法解决冲突)](#2. 哈希表节点(策略 3 专用,链地址法解决冲突))
[3. 哈希表结构体(策略 3 专用)](#3. 哈希表结构体(策略 3 专用))
[(四)查找 / 排序算法(策略 1/2 核心)](#(四)查找 / 排序算法(策略 1/2 核心))
[1. 策略 1:顺序查找 linearSearch](#1. 策略 1:顺序查找 linearSearch)
[2. 策略 2:快速排序(手写,按字典序)](#2. 策略 2:快速排序(手写,按字典序))
[(1)交换节点函数 swapLinearNode](#(1)交换节点函数 swapLinearNode)
[(2)快排分区函数 partition](#(2)快排分区函数 partition)
[(3)快排主函数 quickSort](#(3)快排主函数 quickSort)
[3. 策略 2:二分查找 binarySearch](#3. 策略 2:二分查找 binarySearch)
[1. 初始化阶段](#1. 初始化阶段)
[2. 读取并处理输入文本](#2. 读取并处理输入文本)
[3. 计算 Unique Words 和 ASL(平均查找长度)](#3. 计算 Unique Words 和 ASL(平均查找长度))
[4. 输出结果 + 内存释放](#4. 输出结果 + 内存释放)
一、题目描述
- 本题要求实现一个英文单词词频统计与检索系统,使用三种不同的数据结构策略存储和检索单词,并计算每种策略的平均查找长度(ASL),以对比它们的查找效率。
本文的C++完整代码、英文文本和测试数据的下载地址:英文单词词频统计与检索系统资源-CSDN下载
你需要根据输入的策略编号,使用对应的数据结构完成词频统计:
- 策略1:线性表 + 顺序查找
- 策略2:线性表 + 快速排序 + 二分查找
- 策略3:哈希表(链地址法,链表法解决冲突)
输入格式
第一行 :一个整数 S(1 ≤ S ≤ 3),表示使用的策略编号。
第二行起 :英文文本内容,读取直到遇到字符 #(遇到 # 立刻结束,# 不参与分词/统计,# 之后内容忽略)。
分词与规范化规则:
- 定义:由连续的英文字母(A-Z, a-z)构成的序列视为一个单词。
- 分隔符:任何非英文字母字符(空格、标点、数字、换行符等)均视为分隔符。
- 结束标记 :字符
#仅用于结束输入;读取过程中遇到#立刻停止读取。#不作为分隔符参与分词,可以单独占一行表示输入结束。
输出格式
程序输出三行信息:
bash
Total Words: X
Unique Words: Y
ASL: Z.ZZ- Total Words:文本中所有单词的总数(含重复)
- Unique Words:去重后的单词总数
- ASL:平均查找长度(保留2位小数)
ASL(Average Search Length,平均查找长度):
定义:在数据存储结构构建完成后,查找其中任意一个不同单词所需的平均比较次数。
计算公式 :
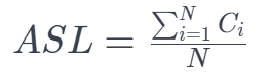
其中:
- N = 不同词数(Unique Words)
= 查找第 i 个不同单词所需的比较次数
重要说明:
- ⚠️ ASL统计的是查找成功时的比较次数(假设要查的单词一定存在)
- ⚠️ 计算时不考虑词频权重,即每个不同单词被查找的概率相等(等概率假设)
- ⚠️ 插入/构建过程中的比较次数不计入ASL,ASL只反映"数据结构建好后的查找性能"
输入样例1
bash
3
The quick brown fox jumps over the lazy dog.
Quick brown foxes jump over lazy dogs!
The fox and the dog are friends.
#输出样例1
bash
Total Words: 23
Unique Words: 14
ASL: 1.00输入样例2
bash
2
Software engineering requires careful testing.
Testing software ensures quality software.
Quality engineering practices matter greatly.
Data-driven decisions improve software quality.
#输出样例2
bash
Total Words: 21
Unique Words: 14
ASL: 3.21提示
1. 语言与库限制
- 语言:C++
- 允许 :
std::string(用于读取输入与 normalize),C/C++基础库(<iostream><string><cstring><cctype>等) - 禁止 :STL容器(
vectormapsetunordered_map等)和库排序函数(必须手写数据结构和排序算法)
2. 各策略ASL计算方法
通用计算流程(三种策略统一)
步骤1:构建阶段
- 读取文本,根据策略构建相应的数据结构
- 统计总词数(Total Words)和不同词数(Unique Words)
- ⚠️ 此阶段的比较次数不计入ASL
步骤2:ASL统计阶段
- 遍历数据结构中的每个不同单词
- 对每个不同单词,重新模拟一次查找过程
- 记录每次查找的比较次数
- 计算
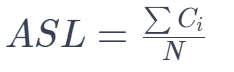
3. 比较次数统计口径
| 策略 | 比较次数定义 | 计算方式 |
|---|---|---|
| 策略1 | 查找第i个词需要i次比较 | 对每个词执行顺序查找累加 |
| 策略2 | 每访问mid并比较记1次 | 对每个词执行二分查找累加 |
| 策略3 | 从链表头到命中节点的节点数 | 遍历哈希表,累加节点位置 |
⚠️ 统一原则:所有策略都基于"等概率查找假设",即每个不同单词被查询的概率相同。
4. Normalize函数
cpp
// 单词规范化函数(使用此标准实现)
// 功能:从token的pos位置开始提取下一个单词(仅字母,转小写)
// 参数:token-输入串,pos-当前位置(会被更新),word-输出单词
// 返回:1=成功提取单词,0=token处理完毕
int Normalize(const char *token, int &pos, char *word) {
// 跳过非字母字符
while (token[pos] && !isalpha(token[pos]))
pos++;
if (!token[pos])
return 0; // token结束
// 提取连续字母并转小写
int len = 0;
while (token[pos] && isalpha(token[pos])) {
word[len++] = tolower(token[pos++]);
}
word[len] = '\0';
return 1;
}5. Time33哈希函数
cpp
unsigned int hash(const char *str) {
unsigned int h = 0;
while (*str) {
h = (h << 5) + h + *str; // h = h*33 + c
str++;
}
return h % HASH_SIZE; // HASH_SIZE必须为1009
}链表节点定义参考:
cpp
struct HashNode {
char word[50]; // 单词
int count; // 词频
HashNode* next; // 指向下一个节点(链表法)
};
struct HashTable {
HashNode* buckets[1009]; // 哈希表大小固定为1009
int unique_count; // 不同词数
};6. 关键注意事项
- 策略2排序:必须按照单词的字典序(Lexicographical Order)排序。
- 规则:从第一个字符开始逐位比较 ASCII 码。
- 如果首字符相同,则比较第二个字符,依此类推。
- 示例:
apple<apply(e<y),cat<catch(短串排前面)。 - 必须严格满足此顺序,否则二分查找结果不正确。
- 策略3哈希表:数组大小 M 必须为 1009。
- 策略3链地址法:使用链表解决哈希冲突,链表节点需要动态分配(使用
new),且必须使用头插法。 - 所有策略基于等概率查找假设计算ASL
- ASL必须保留2位小数
- normalize后为空的token应跳过,不计入总词数
7. 常见问题
Q1: 为什么建议使用提供的Normalize函数?
A: 为保证评测一致性。如果normalize实现略有差异(如空串处理方式不同),会导致词频统计结果不同,影响PTA评测准确性。
Q2: 我可以自己实现normalize吗?
A: 可以,但必须完全符合上述规范。建议直接使用提供的标准实现,避免因实现差异导致测试失败。
Q3: Normalize后变成空串怎么办?
A: 提供的Normalize函数会自动跳过非字母字符。如果token完全由非字母字符组成(如"123"),Normalize会返回0表示处理完毕,此时不应计入总词数。
Q4: 测试样例中的分词结果是什么?
A: 示例:
"Test,World!"→"test"和"world"(两个单词)"Data-Structure"→"data"和"structure"(两个单词)"User's"→"user"和"s"(两个单词)"123"→ 空串(跳过,不计数)
Q5: 策略2必须用快速排序吗?可以用其他排序算法吗?
A: 可以使用其他O(N log N)的排序算法(如归并排序、堆排序),但禁止使用:
- 库函数(std::sort等)
- O(N²)的排序(冒泡、选择、插入排序在大数据量下会比较慢)
快速排序是最常用的选择,建议掌握。
Q6: 如何验证我的ASL计算是否正确?
A: 三步验证法:
- 小规模手工验证:用3个单词测试,手工计算ASL对比
- 理论公式验证:
- 策略1:ASL应该精确等于(N+1)/2
- 策略2:ASL应该接近log₂(N+1)-1(误差<15%)
- 策略3:ASL应该接近1+α/2(α=N/1009,误差<25%)
二、英文单词词频统计与检索系统的C++代码完整实现
cpp
#include <iostream>
#include <cstring>
#include <cctype>
#include <string>
using namespace std;
// 全局常量定义(严格遵循题目要求)
const int MAX_LINEAR_SIZE = 10000; // 线性表最大容量(足够处理常规输入)
const int HASH_SIZE = 1009; // 哈希表大小(题目强制要求1009)
const int MAX_WORD_LEN = 50; // 单词最大长度
// ===================== 题目要求的标准化函数 =====================
int Normalize(const char *token, int &pos, char *word) {
// 跳过所有非字母字符
while (token[pos] && !isalpha(token[pos]))
pos++;
if (!token[pos]) // 字符串处理完毕
return 0;
// 提取连续字母并转换为小写
int len = 0;
while (token[pos] && isalpha(token[pos])) {
word[len++] = tolower(token[pos++]);
}
word[len] = '\0'; // 字符串结束符
return 1;
}
// ===================== 题目要求的Time33哈希函数(修改1:重命名为myHash) =====================
unsigned int myHash(const char *str) { // 原函数名hash → myHash
unsigned int h = 0;
while (*str) {
h = (h << 5) + h + *str; // 等价于 h = h*33 + 当前字符ASCII
str++;
}
return h % HASH_SIZE; // 模1009得到哈希桶索引
}
// ===================== 数据结构定义 =====================
// 策略1/2的线性表节点(存储单词+词频)
struct LinearNode {
char word[MAX_WORD_LEN];
int count;
};
// 策略3的哈希表节点(链地址法)
struct HashNode {
char word[MAX_WORD_LEN];
int count;
HashNode* next;
// 构造函数:初始化单词,词频默认1,指针置空
HashNode(const char* w) : count(1), next(nullptr) {
strcpy(word, w);
}
};
// 策略3的哈希表结构体
struct HashTable {
HashNode* buckets[HASH_SIZE]; // 哈希桶数组
int unique_count; // 不同单词数
// 构造函数:初始化桶为空,不同词数为0
HashTable() : unique_count(0) {
memset(buckets, 0, sizeof(buckets));
}
};
// ===================== 策略1:顺序查找函数 =====================
// 返回值:是否找到目标单词;输出参数cmp_count:查找的比较次数
bool linearSearch(LinearNode* list, int size, const char* word, int& cmp_count) {
cmp_count = 0;
for (int i = 0; i < size; i++) {
cmp_count++; // 每一次比较计数+1
if (strcmp(list[i].word, word) == 0) {
return true;
}
}
return false;
}
// ===================== 策略2:快速排序(手写,字典序) =====================
// 交换两个线性表节点
void swapLinearNode(LinearNode& a, LinearNode& b) {
LinearNode temp = a;
a = b;
b = temp;
}
// 快速排序分区函数(按单词字典序)
int partition(LinearNode* list, int low, int high) {
char pivot[MAX_WORD_LEN];
strcpy(pivot, list[high].word); // 选最后一个元素作为基准
int i = low - 1; // 小于基准的区域边界
for (int j = low; j < high; j++) {
// 字典序:list[j].word < pivot 则交换
if (strcmp(list[j].word, pivot) < 0) {
i++;
swapLinearNode(list[i], list[j]);
}
}
swapLinearNode(list[i+1], list[high]); // 基准归位
return i + 1;
}
// 快速排序主函数
void quickSort(LinearNode* list, int low, int high) {
if (low < high) {
int pi = partition(list, low, high);
quickSort(list, low, pi - 1); // 递归排序左半区
quickSort(list, pi + 1, high); // 递归排序右半区
}
}
// ===================== 策略2:二分查找函数 =====================
// 返回值:是否找到目标单词;输出参数cmp_count:查找的比较次数
bool binarySearch(LinearNode* list, int size, const char* word, int& cmp_count) {
cmp_count = 0;
int low = 0, high = size - 1;
while (low <= high) {
cmp_count++; // 每一次比较mid位置计数+1
int mid = (low + high) / 2;
int cmp_res = strcmp(list[mid].word, word);
if (cmp_res == 0) {
return true; // 找到目标
} else if (cmp_res > 0) {
high = mid - 1; // 目标在左半区
} else {
low = mid + 1; // 目标在右半区
}
}
return false;
}
// ===================== 主函数(核心逻辑) =====================
int main() {
int strategy;
cin >> strategy;
cin.ignore(); // 忽略输入策略后的换行符
// 初始化各策略的存储结构
LinearNode linearList[MAX_LINEAR_SIZE] = {0}; // 策略1/2的线性表
int linearSize = 0; // 线性表当前有效长度
HashTable hashTable; // 策略3的哈希表
int totalWords = 0; // 总词数(含重复)
// ===================== 读取输入文本(直到#) =====================
string line;
while (getline(cin, line)) {
// 检查是否包含结束符#,截断#后的内容
size_t sharpPos = line.find('#');
bool isEnd = (sharpPos != string::npos);
if (isEnd) {
line = line.substr(0, sharpPos);
}
// 处理当前行的所有单词
const char* token = line.c_str();
int pos = 0;
char word[MAX_WORD_LEN];
while (Normalize(token, pos, word)) {
totalWords++; // 总词数+1
// ===================== 策略1/2:构建线性表 =====================
if (strategy == 1 || strategy == 2) {
int cmp;
bool found = linearSearch(linearList, linearSize, word, cmp);
if (found) {
// 单词已存在,词频+1
for (int i = 0; i < linearSize; i++) {
if (strcmp(linearList[i].word, word) == 0) {
linearList[i].count++;
break;
}
}
} else {
// 单词不存在,添加到线性表尾部
strcpy(linearList[linearSize].word, word);
linearList[linearSize].count = 1;
linearSize++;
}
}
// ===================== 策略3:构建哈希表 =====================
else if (strategy == 3) {
unsigned int idx = myHash(word); // 修改2:调用重命名后的myHash
HashNode* p = hashTable.buckets[idx];
bool found = false;
// 遍历链表查找单词
while (p != nullptr) {
if (strcmp(p->word, word) == 0) {
p->count++;
found = true;
break;
}
p = p->next;
}
// 单词不存在,头插法添加新节点
if (!found) {
HashNode* newNode = new HashNode(word);
newNode->next = hashTable.buckets[idx];
hashTable.buckets[idx] = newNode;
hashTable.unique_count++;
}
}
// 遇到#则终止所有输入处理
if (isEnd) {
goto endInput;
}
}
// 行内包含#,终止循环
if (isEnd) {
break;
}
}
endInput: // 输入结束标记
// ===================== 计算Unique Words和ASL =====================
int uniqueWords = 0;
double ASL = 0.0;
int totalCmp = 0; // 所有不同单词的查找比较次数总和
if (strategy == 1) {
// 策略1:线性表+顺序查找
uniqueWords = linearSize;
for (int i = 0; i < linearSize; i++) {
int cmp;
linearSearch(linearList, linearSize, linearList[i].word, cmp);
totalCmp += cmp;
}
ASL = (double)totalCmp / uniqueWords;
}
else if (strategy == 2) {
// 策略2:快速排序+二分查找
uniqueWords = linearSize;
quickSort(linearList, 0, linearSize - 1); // 先排序
for (int i = 0; i < linearSize; i++) {
int cmp;
binarySearch(linearList, linearSize, linearList[i].word, cmp);
totalCmp += cmp;
}
ASL = (double)totalCmp / uniqueWords;
}
else if (strategy == 3) {
// 策略3:哈希表(链地址法)
uniqueWords = hashTable.unique_count;
// 遍历所有哈希桶,统计每个节点的查找次数(链表位置)
for (int i = 0; i < HASH_SIZE; i++) {
HashNode* p = hashTable.buckets[i];
int pos = 1; // 链表中位置(头节点为1次比较)
while (p != nullptr) {
totalCmp += pos;
pos++;
p = p->next;
}
}
ASL = (double)totalCmp / uniqueWords;
}
// ===================== 输出结果(严格按格式) =====================
printf("Total Words: %d\n", totalWords);
printf("Unique Words: %d\n", uniqueWords);
printf("ASL: %.2f\n", ASL);
// ===================== 释放哈希表内存(防止内存泄漏) =====================
if (strategy == 3) {
for (int i = 0; i < HASH_SIZE; i++) {
HashNode* p = hashTable.buckets[i];
while (p != nullptr) {
HashNode* temp = p;
p = p->next;
delete temp;
}
hashTable.buckets[i] = nullptr;
}
}
return 0;
}三、C++代码详细解释
- 读取文本输入(以
#为结束符),将文本中的单词标准化(提取连续字母、转为小写); - 支持三种不同的查找 / 统计策略,统计文本的总词数 、不同单词数(Unique Words) 和平均查找长度(ASL);
- 输出统计结果,并针对哈希表策略做内存释放,避免内存泄漏。
(一)全局常量定义(满足题目强制要求)
cpp
const int MAX_LINEAR_SIZE = 10000; // 线性表最大容量(适配常规文本输入)
const int HASH_SIZE = 1009; // 哈希表桶数(题目强制要求1009)
const int MAX_WORD_LEN = 50; // 单个单词最大长度(避免字符串越界)- 常量命名全大写 + 下划线,符合 C++ 工程规范;
HASH_SIZE=1009是题目强制要求(1009 是质数,能减少哈希冲突);MAX_LINEAR_SIZE足够大,避免线性表溢出。
(二)核心工具函数
1. 单词标准化函数 Normalize(题目强制要求)
cpp
int Normalize(const char *token, int &pos, char *word) {
// 跳过所有非字母字符(比如标点、数字、空格)
while (token[pos] && !isalpha(token[pos]))
pos++;
if (!token[pos]) // 字符串处理完毕,无单词可提取
return 0;
// 提取连续字母并转为小写
int len = 0;
while (token[pos] && isalpha(token[pos])) {
word[len++] = tolower(token[pos++]);
}
word[len] = '\0'; // 手动添加字符串结束符(C风格字符串必需)
return 1;
}- 功能:从输入字符串中提取 "纯字母单词",并标准化为小写;
- 参数说明 :
token:待处理的原始字符串(比如一行文本);pos:当前处理位置(引用传参,因为要修改全局位置);word:输出参数,存储标准化后的单词;
- 返回值 :
1表示提取到有效单词,0表示无单词可提取; - 关键逻辑:先跳过非字母字符 → 提取连续字母并转小写 → 补全字符串结束符。
2. Time33 哈希函数 myHash(题目强制要求,重命名避免关键字冲突)
cpp
unsigned int myHash(const char *str) { // 原函数名hash→myHash(hash是C++关键字)
unsigned int h = 0;
while (*str) {
h = (h << 5) + h + *str; // 等价于 h = h*33 + 当前字符ASCII(Time33核心)
str++;
}
return h % HASH_SIZE; // 模1009得到哈希桶索引(保证索引在0~1008之间)
}- 功能 :将字符串映射为
0~1008的整数(哈希索引); - Time33 算法原理 :通过
h = h*33 + 字符ASCII计算哈希值,位运算h<<5 +h是h*33的优化(左移 5 位 =×32,加 h=×33); - 为什么模 1009:题目强制要求,且 1009 是质数,能最大化减少哈希冲突。
(三)数据结构定义
1. 线性表节点(策略 1/2 专用)
cpp
struct LinearNode {
char word[MAX_WORD_LEN]; // 存储标准化后的单词
int count; // 单词出现次数(词频)
};- 用于策略 1(顺序查找)和策略 2(排序 + 二分查找),线性表由
LinearNode数组实现。
2. 哈希表节点(策略 3 专用,链地址法解决冲突)
cpp
struct HashNode {
char word[MAX_WORD_LEN];
int count;
HashNode* next; // 链表指针(链地址法核心)
// 构造函数:初始化单词,词频默认1,指针置空
HashNode(const char* w) : count(1), next(nullptr) {
strcpy(word, w); // 拷贝单词到节点
}
};- 链地址法:每个哈希桶对应一个链表,冲突的单词存入同一链表;
- 构造函数简化节点创建,避免手动初始化。
3. 哈希表结构体(策略 3 专用)
cpp
struct HashTable {
HashNode* buckets[HASH_SIZE]; // 哈希桶数组(1009个桶)
int unique_count; // 不同单词总数(避免重复统计)
// 构造函数:初始化桶为空,不同词数为0
HashTable() : unique_count(0) {
memset(buckets, 0, sizeof(buckets)); // 所有桶指针置空
}
};buckets:每个元素是HashNode*,指向对应桶的链表头;unique_count:记录哈希表中不同单词的数量(简化后续统计)。
(四)查找 / 排序算法(策略 1/2 核心)
1. 策略 1:顺序查找 linearSearch
cpp
bool linearSearch(LinearNode* list, int size, const char* word, int& cmp_count) {
cmp_count = 0;
for (int i = 0; i < size; i++) {
cmp_count++; // 每一次字符串比较,计数+1(统计查找次数)
if (strcmp(list[i].word, word) == 0) {
return true; // 找到目标单词
}
}
return false; // 未找到
}- 功能:遍历线性表,查找目标单词;
- 参数说明 :
list:线性表数组;size:线性表有效长度;word:目标单词;cmp_count:输出参数,记录查找过程中的比较次数;
- 返回值 :
true找到,false未找到; - 关键 :
strcmp是 C 风格字符串比较函数,返回 0 表示两个字符串相等。
2. 策略 2:快速排序(手写,按字典序)
(1)交换节点函数 swapLinearNode
cpp
void swapLinearNode(LinearNode& a, LinearNode& b) {
LinearNode temp = a;
a = b;
b = temp;
}- 交换两个线性表节点的所有数据(单词 + 词频)。
(2)快排分区函数 partition
cpp
int partition(LinearNode* list, int low, int high) {
char pivot[MAX_WORD_LEN];
strcpy(pivot, list[high].word); // 选最后一个元素作为基准
int i = low - 1; // 小于基准的区域边界
for (int j = low; j < high; j++) {
// 字典序比较:list[j].word < pivot 则交换
if (strcmp(list[j].word, pivot) < 0) {
i++;
swapLinearNode(list[i], list[j]);
}
}
swapLinearNode(list[i+1], list[high]); // 基准元素归位
return i + 1; // 返回基准元素的索引
}- 核心逻辑:以最后一个元素为基准,将线性表划分为 "小于基准" 和 "大于基准" 两部分;
- 字典序判断 :
strcmp(a, b) < 0表示a的字典序小于b。
(3)快排主函数 quickSort
cpp
void quickSort(LinearNode* list, int low, int high) {
if (low < high) {
int pi = partition(list, low, high);
quickSort(list, low, pi - 1); // 递归排序左半区
quickSort(list, pi + 1, high); // 递归排序右半区
}
}- 递归实现快速排序,最终线性表按单词字典序升序排列。
3. 策略 2:二分查找 binarySearch
cpp
bool binarySearch(LinearNode* list, int size, const char* word, int& cmp_count) {
cmp_count = 0;
int low = 0, high = size - 1;
while (low <= high) {
cmp_count++; // 每一次折半比较,计数+1
int mid = (low + high) / 2;
int cmp_res = strcmp(list[mid].word, word);
if (cmp_res == 0) {
return true; // 找到目标
} else if (cmp_res > 0) {
high = mid - 1; // 目标在左半区
} else {
low = mid + 1; // 目标在右半区
}
}
return false; // 未找到
}- 前提:线性表必须已按字典序排序;
- 核心逻辑:折半缩小查找范围,每次比较后排除一半元素,效率远高于顺序查找。
(五)主函数(核心执行流程)
1. 初始化阶段
cpp
int strategy;
cin >> strategy;
cin.ignore(); // 忽略输入策略后的换行符(避免干扰后续文本读取)
// 初始化存储结构
LinearNode linearList[MAX_LINEAR_SIZE] = {0}; // 策略1/2的线性表
int linearSize = 0; // 线性表当前有效长度
HashTable hashTable; // 策略3的哈希表
int totalWords = 0; // 总词数(含重复)- 输入策略(1/2/3),
cin.ignore()处理换行符是关键(否则getline会读取空行); - 初始化线性表、哈希表、统计变量。
2. 读取并处理输入文本
cpp
string line;
while (getline(cin, line)) {
// 检查是否包含结束符#,截断#后的内容
size_t sharpPos = line.find('#');
bool isEnd = (sharpPos != string::npos);
if (isEnd) {
line = line.substr(0, sharpPos);
}
// 处理当前行的所有单词
const char* token = line.c_str();
int pos = 0;
char word[MAX_WORD_LEN];
while (Normalize(token, pos, word)) {
totalWords++; // 总词数+1
// 策略1/2:线性表处理
if (strategy == 1 || strategy == 2) {
int cmp;
bool found = linearSearch(linearList, linearSize, word, cmp);
if (found) {
// 单词已存在,词频+1
for (int i = 0; i < linearSize; i++) {
if (strcmp(linearList[i].word, word) == 0) {
linearList[i].count++;
break;
}
}
} else {
// 单词不存在,添加到线性表尾部
strcpy(linearList[linearSize].word, word);
linearList[linearSize].count = 1;
linearSize++;
}
}
// 策略3:哈希表处理
else if (strategy == 3) {
unsigned int idx = myHash(word);
HashNode* p = hashTable.buckets[idx];
bool found = false;
// 遍历链表查找单词
while (p != nullptr) {
if (strcmp(p->word, word) == 0) {
p->count++;
found = true;
break;
}
p = p->next;
}
// 单词不存在,头插法添加新节点
if (!found) {
HashNode* newNode = new HashNode(word);
newNode->next = hashTable.buckets[idx];
hashTable.buckets[idx] = newNode;
hashTable.unique_count++;
}
}
// 遇到#则终止所有输入处理
if (isEnd) {
goto endInput;
}
}
// 行内包含#,终止循环
if (isEnd) {
break;
}
}
endInput: // 输入结束标记- 核心逻辑 :
- 逐行读取文本,遇到
#则截断并终止输入; - 调用
Normalize提取标准化单词,每提取一个单词,总词数totalWords+1; - 按策略处理单词:
- 策略 1/2 :用
linearSearch查找单词 → 存在则词频 + 1 → 不存在则添加到线性表尾部; - 策略 3 :计算哈希索引 → 遍历对应桶的链表查找单词 → 存在则词频 + 1 → 不存在则头插法添加新节点(头插法效率更高),并更新
unique_count。
- 策略 1/2 :用
- 逐行读取文本,遇到
3. 计算 Unique Words 和 ASL(平均查找长度)
cpp
int uniqueWords = 0;
double ASL = 0.0;
int totalCmp = 0; // 所有不同单词的查找比较次数总和
if (strategy == 1) {
// 策略1:顺序查找
uniqueWords = linearSize;
for (int i = 0; i < linearSize; i++) {
int cmp;
linearSearch(linearList, linearSize, linearList[i].word, cmp);
totalCmp += cmp;
}
ASL = (double)totalCmp / uniqueWords;
}
else if (strategy == 2) {
// 策略2:快速排序+二分查找
uniqueWords = linearSize;
quickSort(linearList, 0, linearSize - 1); // 先排序
for (int i = 0; i < linearSize; i++) {
int cmp;
binarySearch(linearList, linearSize, linearList[i].word, cmp);
totalCmp += cmp;
}
ASL = (double)totalCmp / uniqueWords;
}
else if (strategy == 3) {
// 策略3:哈希表
uniqueWords = hashTable.unique_count;
// 遍历所有哈希桶,统计每个节点的查找次数(链表位置)
for (int i = 0; i < HASH_SIZE; i++) {
HashNode* p = hashTable.buckets[i];
int pos = 1; // 链表中位置(头节点为1次比较)
while (p != nullptr) {
totalCmp += pos;
pos++;
p = p->next;
}
}
ASL = (double)totalCmp / uniqueWords;
}- Unique Words(不同单词数) :
- 策略 1/2:等于线性表的有效长度
linearSize; - 策略 3:等于哈希表的
unique_count(插入时已统计);
- 策略 1/2:等于线性表的有效长度
- ASL(平均查找长度) :
ASL = 所有不同单词的查找比较次数总和 / 不同单词数;- 策略 1:对每个单词做顺序查找,累加比较次数;
- 策略 2:先排序,再对每个单词做二分查找,累加比较次数;
- 策略 3:哈希表的 ASL 统计逻辑是 "链表中第 n 个节点需要 n 次比较"(头节点 1 次,第二个 2 次...)。
4. 输出结果 + 内存释放
cpp
// 输出结果(严格按格式)
printf("Total Words: %d\n", totalWords);
printf("Unique Words: %d\n", uniqueWords);
printf("ASL: %.2f\n", ASL);
// 释放哈希表内存(防止内存泄漏)
if (strategy == 3) {
for (int i = 0; i < HASH_SIZE; i++) {
HashNode* p = hashTable.buckets[i];
while (p != nullptr) {
HashNode* temp = p;
p = p->next;
delete temp;
}
hashTable.buckets[i] = nullptr;
}
}- 输出格式严格:
Total Words、Unique Words、ASL保留两位小数; - 策略 3 必须释放哈希表节点内存(否则会造成内存泄漏):遍历每个桶的链表,逐个
delete节点。
(六)关键细节与注意事项
- C 风格字符串处理 :全程使用
strcpy(拷贝)、strcmp(比较),且手动补全\0,避免字符串越界; - 内存管理 :策略 3 的哈希表节点是动态分配的(
new HashNode),必须手动delete释放; - 引用传参 :
Normalize的pos、linearSearch/binarySearch的cmp_count用引用传参,确保修改能作用到外部变量; - 结束符处理 :
#可能出现在行中间,需截断并立即终止输入(goto endInput); - 哈希冲突解决:策略 3 用链地址法(每个桶对应链表),是哈希表冲突解决的经典方案。
(七)核心知识点总结
| 模块 | 核心知识点 |
|---|---|
| 字符串处理 | C 风格字符串、strcpy/strcmp、tolower/isalpha |
| 查找算法 | 顺序查找、二分查找(前提:有序) |
| 排序算法 | 快速排序(手写、字典序) |
| 哈希表 | Time33 哈希函数、链地址法解决冲突、质数桶数减少冲突 |
| 性能分析 | 平均查找长度(ASL)的计算逻辑 |
| 内存管理 | 动态分配 / 释放节点(避免内存泄漏) |
四、总结
本文实现了一个英文单词词频统计与检索系统,支持三种数据结构策略:线性表顺序查找、线性表快速排序后二分查找、哈希表链地址法。系统读取输入文本直到遇到#结束,对单词进行标准化处理(转为小写、提取连续字母),统计总词数和不同词数,并计算各策略的平均查找长度(ASL)。关键实现包括手写快速排序、二分查找和哈希表冲突处理,最终输出统计结果并确保内存安全释放。该系统有效对比了不同数据结构的查找效率差异。