文章目录
- 引言
- 错误纠正
- Memory
- SAA的Memory机制
-
- SAA的Memory机制的架构
- 维护短期记忆
- 维护长期记忆
-
- 长期记忆的检索过程
-
- [1. 存入阶段(写入/索引)](#1. 存入阶段(写入/索引))
- [2. 检索阶段(读取/召回)](#2. 检索阶段(读取/召回))
- SAA的长期记忆存储
- SAA的长期记忆管理
- 总结
引言
我相信大家在平时一定使用过网页对话chatbot,国产的有deepseek、Qwen等,国外的有ChatGPT、Gemini、Grok等。在我们使用的期间,我们会发现这些chatbot会记住我们这次对话的上下文,甚至之前的对话的某些信息,如果你们对为什么LLM能记住我们的信息感兴趣,那么接着往下看吧!
错误纠正
很多人不了解大模型或者不了解大模型应用开发的,就常常认为大模型底层就是会有记忆机制的,即内置Memory。这种想法是错误的,大模型底层并没有记忆机制,而是stateless(无状态)。
1.基础大模型(如 Qwen)的行为(LLM)
- 默认情况下,大语言模型(包括 Qwen 系列)是无状态的:每次请求都是独立的,模型不会自动记住你之前的对话内容。
- 如果你在一次对话中发送多轮消息(例如通过 API 的
messages字段传入历史),那是由调用方(即你的应用)负责维护对话历史,而不是模型自己存储。
2.Memory 机制是应用层的功能
- "Memory"通常是指在构建智能体(Agent)或对话系统时,为了实现上下文记忆、长期记忆、用户偏好记录等功能而额外引入的模块。
- 例如,在 LangChain、LlamaIndex 或阿里云百炼平台中,开发者可以配置短期记忆(如最近几轮对话)或长期记忆(如向量数据库存储的历史信息),并在每次生成回复前将相关记忆注入 prompt。
- 这种 Memory 管理是由应用框架或开发者代码实现的,不是模型原生能力。
Memory
那么像chatbot这些大模型应用,是如何维持记忆呢?那么维护记忆万一超过了模型能承受的上下文,怎么办?
要了解这些问题,我们首先得搞懂,什么是Memory。
Memory分为短期记忆和长期记忆,接下来我们分别说说,尽量简单易懂。
短期Memory
短期记忆(Short-term Memory)
-
定义 :指在单次对话会话(session)中保留的上下文信息。
-
典型实现:将用户与系统单次会话中的最近几轮的对话历史(prompt + response)作为上下文,一起输入给大模型。
-
特点:
- 仅在当前会话有效;
- 会话结束后通常被丢弃(除非主动保存);
- 受限于模型的上下文长度(如 Qwen-Max 支持 32768 tokens);
- 是实现多轮对话连贯性的基础。
-
例子:
用户:我叫小明。 助手:你好,小明! 用户:我今年多大? → 助手能回答,是因为"我叫小明"这句还在短期记忆(即对话历史)中
短期记忆一般大模型应用都会自动开启的,但是每个应用对短期记忆的策略都会不一样,所以体验上也不一样。
长期Memory
长期记忆(Long-term Memory)
-
定义 :跨越多个会话、持久化存储的用户信息或交互历史。
-
典型实现:
- 将关键信息(如用户偏好、身份、历史任务)提取后存入数据库或向量库;
- 下次对话时通过检索(Retrieval)机制召回相关内容,并注入到 prompt 中。
-
特点:
- 需要显式设计(如使用向量数据库 + embedding 检索);
- 不是所有系统都默认开启;
- 涉及隐私和数据安全,通常需用户授权;
- 属于高级功能,常见于智能体(Agent)或个性化助手。
-
例子:
上周用户说:"我喜欢喝美式咖啡。" 一周后再次对话,系统说:"今天还想来一杯美式吗?" → 这说明系统通过长期记忆记住了偏好。
以Gemini为例子,你可以在这里添加想让Gemini记住你的相关信息,或者在某次对话中直接prompt让其记住也是可以的。这样就是长期Memory,每次Gemini都会在某些情景下触发相关的长期记忆,策略不同,输出也会不同
SAA的Memory机制
ok,现在回归正题,来讲讲SAA的Memory机制,如果还有想有更深的了解的兄弟可以先去看看这两篇文章,再回来应该能更好的理解
1.Spring AI vs Spring AI Alibaba
https://juejin.cn/post/7596181746062508059
2.逃出结构化思维:从向量,向量数据库到RAG
https://juejin.cn/post/7587074669818134554
SAA本质上是一个AI应用开发框架,可以开发agent,multi-agent和工作流等等,那么必然需要使用底层LLM,然而我们前面已经说过了LLM实际上是无状态的,那么LLM应用的相关记忆必定是由我们上层应用来开发和管理的。
即如果你使用的是 Qwen 的 API(如 dashscope) ,你需要自己维护对话历史并作为输入传入。
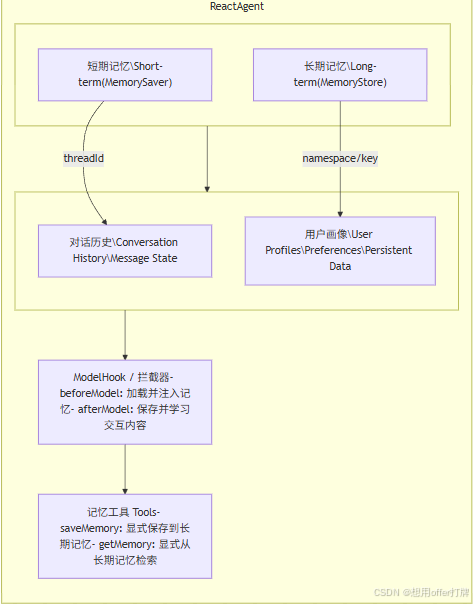
SAA的Memory机制的架构
下面是SAA实现两种Memory的架构图,其中左下角的箭头(指向ModelHook)应该放置到中间的,画错了就将就看吧
维护短期记忆
如何添加短期记忆
在 Spring AI Alibaba 中,要向 Agent 添加短期记忆(会话级持久化),你需要在创建 Agent 时指定 checkpointer
java
import com.alibaba.cloud.ai.graph.checkpoint.savers.RedisSaver;
import org.redisson.api.RedissonClient;
// 配置 Redis checkpointer
RedisSaver redisSaver = new RedisSaver(redissonClient);
ReactAgent agent = ReactAgent.builder()
.name("my_agent")
.model(chatModel)
.tools(getUserInfoTool)
.saver(redisSaver)
.build();
// 使用 thread_id 维护对话上下文
RunnableConfig config = RunnableConfig.builder()
.threadId("1") // threadId 指定会话 ID
.build();
agent.call("你好!我叫 Bob。", config);扩展短期记忆
我们还可以修改和管理记忆。
默认情况下,Agent 使用状态通过 messages 键管理短期记忆,特别是对话历史。
你可以通过在工具或 Hook 中访问和修改状态来扩展记忆功能
java
import com.alibaba.cloud.ai.graph.agent.hook.ModelHook;
import com.alibaba.cloud.ai.graph.agent.hook.HookPosition;
import com.alibaba.cloud.ai.graph.OverAllState;
import com.alibaba.cloud.ai.graph.RunnableConfig;
import org.springframework.ai.chat.messages.Message;
import java.util.List;
import java.util.Map;
import java.util.Optional;
import java.util.concurrent.CompletableFuture;
// 在 Hook 中访问和修改状态
public class CustomMemoryHook extends ModelHook {
@Override
public String getName() {
return "custom_memory";
}
@Override
public HookPosition[] getHookPositions() {
return new HookPosition[]{HookPosition.BEFORE_MODEL};
}
@Override
public CompletableFuture<Map<String, Object>> beforeModel(OverAllState state, RunnableConfig config) {
// 访问消息历史
Optional<Object> messagesOpt = state.value("messages");
if (messagesOpt.isPresent()) {
List<Message> messages = (List<Message>) messagesOpt.get();
// 处理消息...
}
// 添加自定义状态
return CompletableFuture.completedFuture(Map.of(
"user_id", "user_123",
"preferences", Map.of("theme", "dark")
));
}
@Override
public CompletableFuture<Map<String, Object>> afterModel(OverAllState state, RunnableConfig config) {
return CompletableFuture.completedFuture(Map.of());
}
}管理短期记忆
一个会话中,如果用户一直对话,整个会话的上下文就会越来越长,最后就会超过该大模型所能承受的上下文限制。
保留所有对话历史是实现短期记忆最常见的形式。但较长的对话对历史可能会导致大模型 LLM 上下文窗口超限,导致上下文丢失或报错。
即使你在使用的大模型上下文长度足够大,大多数模型在处理较长上下文时的表现仍然很差。因为很多模型会被过时或偏离主题的内容"分散注意力"。同时,过长的上下文,还会带来响应时间变长、Token 成本增加等问题。
在 Spring AI ALibaba 中,ReactAgent 使用 messages 记录和传递上下文,其中包括指令(SystemMessage)和输入(UserMessage)。在 ReactAgent 中,消息(Message)在用户输入和模型响应之间交替,导致消息列表随着时间的推移变得越来越长。由于上下文窗口有限,许多应用程序可以从使用技术来移除或"忘记"过时信息中受益,即 "上下文工程"。
作为后端,我们通常采取以下几种策略来模拟"记忆":
- Sliding Window(滑动窗口): 只保留最近的 N N N 轮对话,丢弃最早的记录。
- Summary Memory(摘要记忆): 当对话过长时,调用大模型对之前的对话做一个简短总结,后续只带上这个
Summary。 - Vector Database(向量数据库/RAG): 将历史对话存入向量库(如 Milvus, Pinecone)。当用户提问时,通过语义搜索检索出最相关的历史片段(Top-K),塞进 Context 传给模型。
维护长期记忆
长期记忆的检索过程
对于后端开发人员来说,长期记忆的检索过程其实就是一个标准的 "语义检索 + RAG (Retrieval-Augmented Generation)" 工作流。
你可以把它类比为:全文搜索(Elasticsearch)的升级版 。不同于关键词匹配,它是基于"意思"来匹配。
整个过程可以分为 "存入" 和 "检索" 两个阶段:
1. 存入阶段(写入/索引)
当一段对话结束或产生新的知识时:
- 切片 (Chunking) :将长文本切分成合适的大小(例如 512 tokens)。
- 向量化 (Embedding) :调用 Embedding 模型(如 OpenAI 的
text-embedding-3-small)将文本转为高维向量(如 1536 维的浮点数数组)。 - 入库 :将向量和原始文本、Metadata(如
user_id,timestamp)存入向量数据库(Redis Vector Search, Milvus, 或 Pinecone)。
2. 检索阶段(读取/召回)
当用户提出一个新问题,系统需要"回想起"以前的事情:
-
Step A: 问题向量化
将用户的提问(Query)同样通过 Embedding 模型转为一个向量 V q u e r y V_{query} Vquery。
-
Step B: 向量空间搜索 (ANN Search)
在数据库中寻找与 V q u e r y V_{query} Vquery 距离最近(相似度最高)的 K K K 个向量。通常使用余弦相似度 (Cosine Similarity) 计算:
similarity = A ⋅ B ∥ A ∥ ∥ B ∥ \text{similarity} = \frac{A \cdot B}{\|A\| \|B\|} similarity=∥A∥∥B∥A⋅B
-
Step C: 召回与过滤
数据库返回最匹配的原始文本片段。作为后端,你通常会在这里根据 user_id 做 Metadata Filter,确保 A 用户的提问不会检索到 B 用户的记忆。
-
Step D: 上下文注入 (Context Injection)
将检索出来的"记忆片段"拼接到当前的 Prompt 中。
SAA的长期记忆存储
Spring AI Alibaba 将长期记忆以 JSON 文档的形式存储在 Store 中。
每个记忆都在自定义的 namespace(类似于文件夹)下组织,并使用唯一的 key(类似于文件名)。命名空间通常包含用户或组织 ID 或其他标签,以便更容易地组织信息。
这种结构支持记忆的层次化组织。通过内容过滤器支持跨命名空间搜索。
java
import com.alibaba.cloud.ai.graph.store.stores.MemoryStore;
import com.alibaba.cloud.ai.graph.store.StoreItem;
import java.util.*;
// MemoryStore 将数据保存到内存字典中。在生产环境中请使用基于数据库的存储实现
MemoryStore store = new MemoryStore();
String userId = "my-user";
String applicationContext = "chitchat";
List<String> namespace = List.of(userId, applicationContext);
// 保存记忆
Map<String, Object> memoryData = new HashMap<>();
memoryData.put("rules", List.of(
"用户喜欢简短直接的语言",
"用户只说中文和Java"
));
memoryData.put("my-key", "my-value");
StoreItem item = StoreItem.of(namespace, "a-memory", memoryData);
store.putItem(item);
// 通过ID获取记忆
Optional<StoreItem> retrievedItem = store.getItem(namespace, "a-memory");
// 在此命名空间内搜索记忆,通过内容等价性过滤,按向量相似度排序
List<StoreItem> items = store.searchItems(
namespace,
Map.of("my-key", "my-value")
);SAA的长期记忆管理
SAA还可以进行对长期记忆的管理,我们可以使用 ModelHook 在模型调用前后自动加载和保存长期记忆。
同时,我们也可以在tool里面进行读取和写入长期记忆。
长期记忆的写入和召回等核心流程就如上面说到的一样,这里由于篇幅就不详细赘述。
总结
本文讨论了Memory的概念,两种不同记忆机制的区别以及SAA如何处理不同记忆。
但是大模型应用开发Memory是门学问,也不可能一文能讲清楚所有场景该怎么做,比如短期记忆和长期记忆混合该怎么使用,那就等着读者去探索了。
如果你感觉这篇入门文章给你带来了不错的体感,那就给我点赞+收藏+关注吧❤️