一、引言
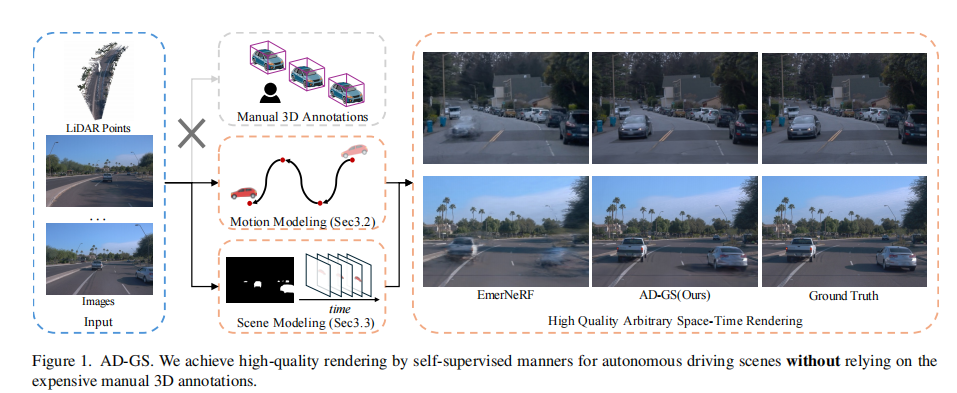
在自动驾驶仿真领域,动态城市驾驶场景的建模与渲染至关重要。高质量的场景渲染能够为自动驾驶算法的训练和测试提供逼真的虚拟环境,然而当前主流方法却面临着两难困境:一方面,依赖人工 3D 标注的方法虽然能实现高质量渲染,但标注成本极高,严重限制了其大规模应用;另一方面,自监督方法虽无需人工标注,但在动态目标运动捕捉的准确性和场景分解的合理性上存在明显不足,常常导致渲染伪影。
为解决这一问题,来自南开大学、伊利诺伊大学厄巴纳 - 香槟分校和南京大学的研究团队提出了 AD-GS(Object-Aware B-Spline Gaussian Splatting),一种基于高斯 splatting 的自监督框架,能够仅通过单条日志数据实现自动驾驶场景的高质量自由视角渲染。
原文链接:https://arxiv.org/pdf/2507.12137
项目主页:https://jiaweixu8.github.io/AD-GS-web/
代码链接:https://github.com/JiaweiXu8/AD-GS
沐小含持续分享前沿算法论文,欢迎关注...
二、核心贡献
AD-GS 的创新点主要体现在三个关键方面,构建了一套完整的自监督自动驾驶场景渲染解决方案:
- 新型运动建模方法:融合可学习 B 样条曲线(包括位置 B 样条曲线和四元数 B 样条曲线)与三角函数,实现了全局运动拟合与局部细节捕捉的统一。与仅使用三角函数的传统方法不同,B 样条曲线通过局部控制点数优化而非全局参数调整,能够精准捕捉目标的细粒度运动。
- 目标感知的场景建模:基于简化的伪 2D 分割,将场景自动分解为目标和背景两部分,在噪声伪标签条件下保持了鲁棒性。其中目标部分采用动态高斯表示,并引入双向时间可见性掩码处理目标的突然出现和消失,背景部分则保持高斯静止,显著提升了渲染精度。
- 正则化机制设计:提出可见性和物理刚性正则化,结合自监督学习有效防止模型出现混沌行为,确保同一目标对应的高斯群在时空维度上保持一致的变形特性。
三、相关工作
3.1 人工辅助的场景渲染
早期自动驾驶场景渲染方法高度依赖人工 3D 标注,例如 NSG 将神经辐射场(NeRF)应用于场景图格式,利用人工标注实现渲染;MARS 则采用模块化设计优化该任务;NeuRAD 和 UniSim 进一步扩展 NeRF 模型,分别用于 LiDAR 传感器建模和安全自动驾驶车辆开发。
为解决动态目标建模问题,OmniRe 结合 SMPL 模型和变形场来建模行人和其他动态实体;ML-NSG 通过多级化 NSG formulation 提升快速移动目标的捕捉能力。随着高斯 splatting 技术的兴起,4DGF 等方法将场景动态性与 NSG 结合,在城市重建中取得显著进展,实现了高质量、低延迟的渲染。但这类方法的共同瓶颈在于人工标注的高成本,难以大规模推广。
3.2 自监督场景渲染
自监督方法旨在仅利用图像和 LiDAR 点云重建场景和目标运动,无需人工标注。PNF 利用伪 3D 标注联合优化目标姿态;SUDS 采用场景分解策略,通过三分支哈希表表示实现 4D 重建;EmerNeRF 借助检测模型的特征监督进行静动态分解;RoDUS 以 2D 分割为指导,提升静动态分离的鲁棒性。
在高斯 splatting 框架下,HUGS 结合 NSG 和伪标签进行重建,采用单轮模型建模运动;PVG 通过三角函数和周期性振动建模高斯变形,验证了该类方法捕捉运动的有效性。然而,现有自监督方法普遍受限于噪声伪标签和局部运动细节捕捉不足的问题,性能难以达到人工辅助方法的水平。
AD-GS 在继承高斯 splatting 高渲染质量优势的基础上,针对现有自监督方法的核心缺陷,从运动建模、场景分解和正则化三个维度进行创新,实现了性能突破。
四、技术细节
4.1 整体框架概述
AD-GS 基于高斯 splatting 构建,该模型采用 3D 高斯集合表示场景,每个高斯定义为 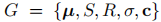 ,分别对应位置、缩放、旋转、不透明度和颜色(通过球谐系数 SH 表示)。通过可微分光栅化技术,高斯集合可根据真实图像进行训练和渲染。
,分别对应位置、缩放、旋转、不透明度和颜色(通过球谐系数 SH 表示)。通过可微分光栅化技术,高斯集合可根据真实图像进行训练和渲染。
AD-GS 的完整流程如图 3 所示:
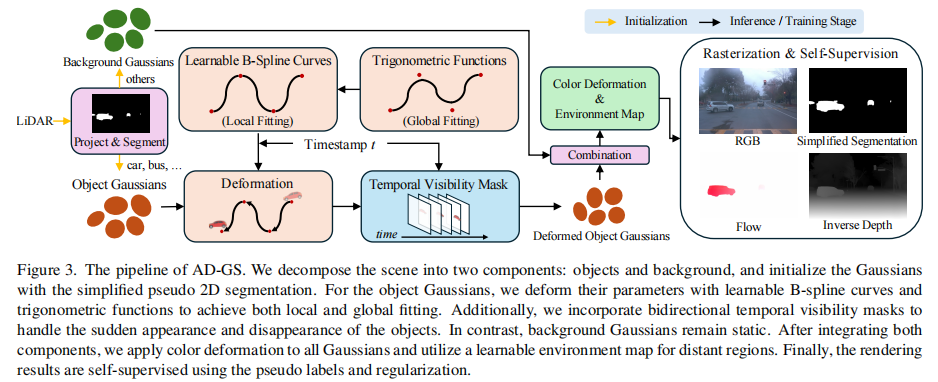
其核心过程包括:
-
高斯投影:利用视图变换矩阵
和投影雅可比矩阵
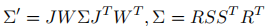
-
像素渲染:通过 α- 混合公式计算相机平面上每个像素的颜色值:
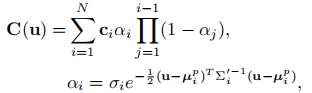
其中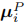 为高斯的投影位置。
为高斯的投影位置。
为适配自动驾驶场景的自监督渲染,AD-GS 将所有高斯分为目标高斯 和背景高斯
,并针对两类高斯设计了不同的建模策略:
- 目标高斯:通过
- 背景高斯:保持位置和旋转固定,仅通过三角函数变形其漫反射 SH 特征
- 全局处理:采用可学习的球形环境图表示天空等远景区域,通过多种自监督损失和正则化确保模型稳定性。
4.2 可学习 B 样条运动曲线
4.2.1 位置 B 样条曲线
样条曲线的核心优势在于局部控制能力,给定
个控制点
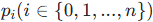 ,可构建
,可构建 连续的
阶 B 样条曲线:
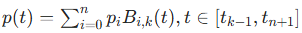
其中 为非递减节点,
为基函数,仅在
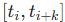 区间非零。为提升计算效率,AD-GS 采用均匀 B 样条的矩阵表示形式
区间非零。为提升计算效率,AD-GS 采用均匀 B 样条的矩阵表示形式

其中 为
可预计算矩阵,具体形式见补充材料。
为同时实现全局运动拟合和局部细节捕捉,AD-GS 将 B 样条曲线与三角函数结合,建模目标高斯的位置变形:
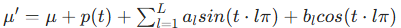
其中 为最大频率,
为可学习参数。图 2 对比了传统方法与 B 样条曲线的拟合特性:传统方法(如 MLP、三角函数)需全局优化所有参数,难以捕捉局部细节;而 B 样条曲线仅优化数据点附近的控制点,实现精准灵活的局部拟合。

4.2.2 四元数 B 样条曲线
由于单位四元数的插值具有非均匀性,标准 B 样条曲线无法有效表示高斯旋转参数的变形。AD-GS 采用 B 样条四元数曲线建模旋转,给定 个可学习单位四元数控制点
,
阶单位四元数 B 样条曲线在每个区间定义为:

其中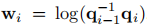 ,
,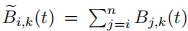 。该曲线专门针对单位四元数设计运算规则,能够精准建模高斯的旋转变形。
。该曲线专门针对单位四元数设计运算规则,能够精准建模高斯的旋转变形。
4.3 目标感知 Splatting 与时间掩码
4.3.1 基于简化 2D 分割的场景分解
AD-GS 摒弃了复杂的实例分割,将场景简化为目标和背景两类:具有时间运动特性的类别(如车辆、行人)归为目标,其余归为背景。利用 SAM(Segment Anything Model)生成的二值分割结果 ,基于 LiDAR 点云的 2D 投影位置初始化目标高斯
和背景高斯
集合。
利用这种初始分解,为优化场景分解结果,通过 α- 混合渲染目标掩码:
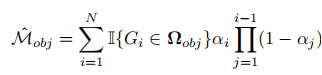
并采用二元交叉熵损失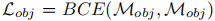 监督掩码渲染结果,通过调整高斯不透明度实现两类高斯的精准分离。
监督掩码渲染结果,通过调整高斯不透明度实现两类高斯的精准分离。
4.3.2 双向时间可见性掩码
为解决移动目标在部分帧中不可见导致的轨迹拟合噪声问题,AD-GS 引入双向时间可见性掩码,对目标高斯的不透明度进行调制:
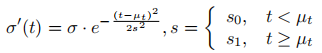
其中 为 LiDAR 点云的固定采集时间戳,
为可学习的双向掩码尺度。为防止掩码过窄,设计扩展正则化损失:
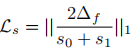
其中 为输入序列的平均帧间隔。
4.4 带正则化的自监督学习
AD-GS 采用多维度自监督损失和正则化机制,确保在无人工标注条件下的高质量重建:
4.4.1 光流监督
利用 CoTracker3 生成伪光流标签,通过预测像素在目标时刻的 3D 位置并投影到目标图像,采用 L1 损失监督:
其中  为预测 3D 位置,
为预测 3D 位置, 为投影函数。仅对目标区域的光流进行监督,以提升效率并降低噪声影响。
4.4.2 逆深度监督
为解决传统深度渲染在无高斯覆盖像素处的计算不稳定性,直接渲染逆深度期望图:
其中 为相机到高斯中心的距离。采用尺度 - 偏移深度损失监督:
其中 为最小化平方误差的最优参数,有效融合稀疏视角的 3D 信息。
4.4.3 可见性和物理刚性正则化
为确保目标高斯的局部刚性,对附近高斯的关键参数(位置 B 样条控制点、三角函数系数、时间掩码尺度)施加方差正则化:

其中 表示通过 KNN 选择的 8 个邻近高斯的参数方差,通过每 10 次迭代更新 KNN 结果平衡效率和性能。
4.4.4 总损失函数
AD-GS 的总损失融合了图像重建损失、掩码损失、光流损失、深度损失、正则化损失等多个组件:
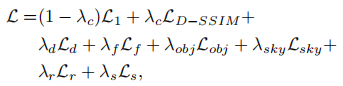
其中 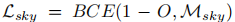 为天空掩码损失(
为天空掩码损失(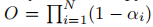 为累积不透明度),
为累积不透明度), 系列为各损失的权重超参数。
五、实验验证
5.1 实验设置
5.1.1 数据集
采用三个主流自动驾驶数据集进行评估:
- KITTI:3 个序列,分辨率 375×1242,双相机采集,分别使用 75%、50%、25% 的图像用于训练;
- Waymo:8 个序列,分辨率 1280×1920,单相机采集,每 4 帧取 1 帧用于测试;
- nuScenes:6 个序列,分辨率 900×1600,三相机采集,60 帧 / 序列,每 4 帧取 1 帧用于测试。
5.1.2 基线模型
- 自监督模型:SUDS、EmerNeRF、PVG、Grid4D;
- 人工辅助模型:StreetGS、ML-NSG、4DGF(用于对比性能上限)。
5.1.3 实现细节
- 超参数设置:λc=0.2,λd=0.1,λf=0.1,λobj=0.1,λsky=0.05,λr=0.5,λs=0.01;
- B 样条参数:阶数 k=6,控制点数量为序列总帧数的 1/3;
- 三角函数频率:K=L=6;
- 训练配置:遵循原始高斯 splatting 的训练调度和致密化策略,单 RTX 3090 GPU 训练。
5.2 对比实验结果
5.2.1 与自监督模型对比
在三个数据集上,AD-GS 均显著优于现有自监督基线模型:
-
KITTI 数据集(表 1):AD-GS 在 KITTI-75% 设置下达到 PSNR=29.16、SSIM=0.920、LPIPS=0.033,大幅超越 PVG(PSNR=27.13)和 Grid4D(PSNR=23.79);

-
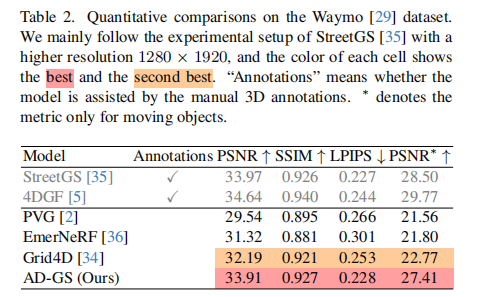
Waymo 数据集(表 2):AD-GS 的 PSNR=33.91,接近人工辅助模型 StreetGS(33.97),移动目标 PSNR∗=27.41,远超 PVG(21.56);
-
nuScenes 数据集(表 3):AD-GS 以 PSNR=31.06、SSIM=0.925、LPIPS=0.164 位居榜首,优于 Grid4D(PSNR=30.29)。
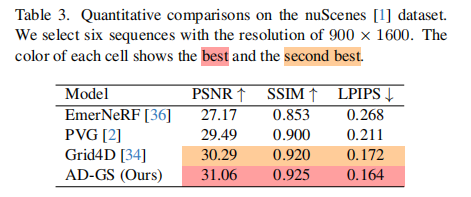
定性结果如图 4-6 所示,AD-GS 在动态目标边缘、细节纹理和背景一致性上表现更优,有效减少了渲染伪影。

5.2.2 与人工辅助模型对比
尽管不依赖人工 3D 标注,AD-GS 在 KITTI 和 Waymo 数据集上的性能已接近甚至部分超过人工辅助模型(表 1、表 2)。在 KITTI-25% 的极稀疏视图设置下,AD-GS 仍优于其他自监督模型,证明了其在数据稀缺场景下的鲁棒性。
5.3 消融实验
5.3.1 损失函数消融
在 KITTI-75% 设置下,逐步添加各损失组件的结果如表 4 所示:

- 仅基础模型(无额外损失):PSNR=26.52;
- 添加目标和天空掩码损失(obj&sky):PSNR 提升至 26.98,场景分解更清晰;
- 新增光流和深度损失(flow&depth):PSNR 达 28.03,补充的运动和 3D 信息提升重建精度;
- 加入正则化损失(reg):PSNR 达到 29.16,有效防止模型混沌,提升结构一致性。
定性结果如图 7 所示,随着损失组件的完善,渲染细节逐渐丰富,伪影减少。

5.3.2 目标建模模块消融
在 Waymo 数据集上对核心模块的消融结果如表 5 所示:
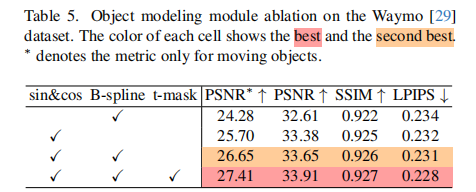
- 仅使用三角函数(sin&cos):PSNR=32.61,PSNR∗=24.28;
- 加入 B 样条曲线(B-spline):PSNR 提升至 33.65,PSNR∗=26.65,局部运动捕捉生效;
- 新增双向时间掩码(t-mask):PSNR=33.91,PSNR∗=27.41,进一步缓解不可见帧的噪声影响。
图 8 和图 9 验证了 B 样条曲线在局部拟合和时间掩码在处理目标突然出现 / 消失场景的有效性,尤其是在目标仅短暂可见的情况下,能够显著减少模糊和伪影。


5.3.3 其他消融实验
-
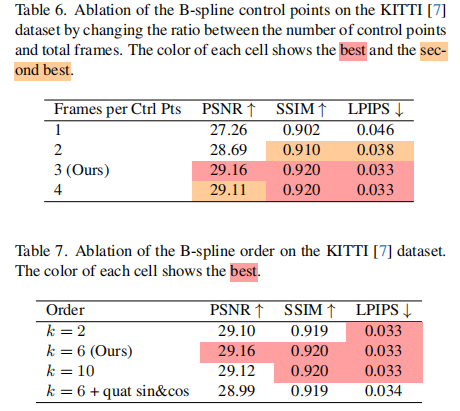
B 样条参数消融:当控制点数量为总帧数的 1/3、阶数 k=6 时性能最优(表 6、表 7),过疏或过密的控制点、过低或过高的阶数都会导致局部拟合能力下降或平滑性不足;
-
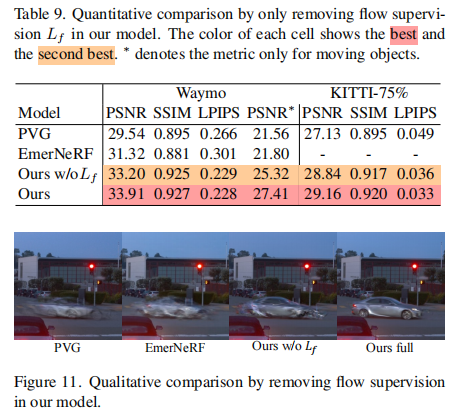
光流监督消融:移除光流损失后,模型在快速移动目标场景的性能明显下降(表 9、图 11),验证了光流监督对运动建模的重要性;
-
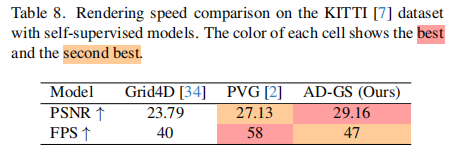
渲染速度:AD-GS 在 KITTI 数据集上达到 47 FPS,虽低于 PVG(58 FPS),但显著优于 Grid4D(40 FPS),在保持高渲染质量的同时兼顾实时性(表 8)。
5.4 局限性分析
AD-GS 仍存在以下不足:
- 面对具有高度复杂运动和结构的目标时,可能出现重建不完整的情况;
- 当目标仅在极短时间内可见(约 10 帧)时,渲染质量会下降;
- 伪标签质量过低时,模型可能产生渲染伪影;
- 性能仍未完全超越依赖人工 3D 标注的先进模型,在极稀疏视图下与标注依赖方法的差距会扩大。

六、总结与展望
AD-GS 通过融合 B 样条曲线与三角函数的运动建模、基于简化 2D 分割的场景分解以及可见性 - 物理刚性正则化,构建了一套高效的自监督自动驾驶场景渲染框架。在 KITTI、Waymo、nuScenes 三大数据集上的实验表明,该方法显著超越现有自监督模型,性能接近人工辅助方法,为低成本、大规模自动驾驶仿真提供了新的解决方案。
未来研究方向可聚焦于:
- 提升复杂动态目标和极短可见性目标的建模能力;
- 优化伪标签生成策略,降低对分割质量的依赖;
- 进一步平衡渲染质量与速度,满足实时仿真需求;
- 探索多模态数据融合(如雷达、IMU),进一步提升模型鲁棒性。