
🎬 个人主页 :MSTcheng · CSDN
🌱 代码仓库 :MSTcheng · Gitee
🔥 精选专栏 : 《C语言》
《数据结构》
《算法学习》
《C++由浅入深》
💬座右铭: 路虽远行则将至,事虽难做则必成!
前言:在上一篇文章中我们向大家介绍了
unordered_set和unordered_map并且使用两种方式来实现了哈希表,本篇文章我们就使用哈希表作为底层自己封装一个unordered_set和unordered_map。
文章目录
一、源码及框架分析

通过源码可以看到,结构上hash_map和hash_set跟map和set的完全类似,复⽤同⼀个hashtable实现key和key/value结构,hash_set传给hash_table的是两个key,hash_map传给hash_table的是pair<const key, value>。
需要注意的是源码里面跟map/set源码类似,命名风格比较乱,这里比map和set还乱,hash_set模板参数居然用的Value命名,hash_map用的是Key和T命名。但是我们自己实现的时候底层数据类型就使用T类型。
二、unordered_map和unordered_set封装
与之前红黑树封装map和set一样,使用哈希表封装unordered_map/set也遵循五个步骤:
- 实现哈希表(链地址法实现)
- 封装
unordered_map/set的框架,解决KeyOfT (注意我们自己实现第二个模板参数就使用的是)- 实现普通迭代器
(iterator)以及const迭代器(const_iterator)- 实现
Key不支持修改- 实现
map的operator[]
2.1封装unordered_map/set的框架,解决KeyOfT的问题
1、结点的结构:
cpp
template<class T>
struct HashNode
{
T _data;
HashNode<T>* _next;
//默认构造
HashNode(const T& data)
:_data(data)
,_next(nullptr)
{}
};哈希表中每一个位置存的是一个结构体,结构体中存储了数据
_data,和指向下一个结点的指针_next。
有了上一次模拟实现的经验,这一次我们就直接给出代码,不熟悉的可以看---> 【C++】如何仅仅使用一颗红黑树来封装map和set?(超详细!)
1、在unordered_set.h中:
cpp
#include"HashTable.h"
#pragma once
namespace my_uset
{
//HashFunc就是支持负数取模或者string取模的仿函数
template<class k, class Hash = HashFunc<k>>
class unordered_set
{
public:
struct SetKeyOfT
{
const k& operator()(const k& key)
{
return key;
}
};
private:
HashTable<k, k, SetKeyOfT, Hash> _t;
};
};2、在unordered_map.h中:
cpp
#include"HashTable.h"
#pragma once
namespace my_umap
{
template<class k, class v, class Hash = HashFunc<k>>
class unordered_map
{
public:
struct MapKeyOfT
{
const k& operator()(const pair<k, v>& kv)
{
return kv.first;
}
};
private:
HashTable<k, pair<k, v>, MapKeyOfT, Hash> _t;
};
};接着就将仿函数套到哈希表中: 3、在HashTable.h中
cpp
template<class k, class T,class KeyOfT ,class Hash>
class HashTable
{
typedef HashNode<T> Node;
public:
//默认构造
HashTable()
:_tables(11, nullptr)//底层容器选用的是vector 所以_tables(11,nullptr)
, _n(0) //是给哈希表开11个空间 并且使用空指针初始化的意思
{
}
bool Insert(const T& data)
{
//===================
//封装第一步 套一层仿函数kot
//===================
KeyOfT kot;
if (Find(kot(data)))
return false;
Hash hs;
//法二 将旧表的节点直接拿下来挂到新表对应的位置 而不是拷贝
if (_n == _tables.size())
{
vector<Node*> newtables(_tables.size() * 2);
//遍历旧表 将旧表的节点移动到新表
for (size_t i = 0;i < _tables.size();i++)
{
Node* cur = _tables[i];
//遍历每一个位置的哈希桶
while (cur)
{
//根据新表的大小重新计算映射位置
size_t Hashi = hs(kot(cur->_data)) % _tables.size();
Node* next = cur->_next;
cur->_next = newtables[Hashi];
newtables[Hashi] = cur;
cur = next;
}
}
//旧表全部遍历完后 与新表交换内部指针_start _finish _endofstorage
_tables.swap(newtables);
}
//通过余数找到要映射的位置
size_t Hashi = hs(kot(data)) % _tables.size();
Node* NewNode = new Node(data);//根据kv开一个节点的空间
//将新节点与哈希表链接
NewNode->_next = _tables[Hashi];
_tables[Hashi] = NewNode;
_n++;
return true;
}
Node* Find(const k& key)
{
//===================
//封装第一步 套一层仿函数kot
//===================
KeyOfT kot;
Hash hs;
size_t Hashi = hs(key) % _tables.size();
Node* cur = _tables[Hashi];
while (cur)
{
if (kot(cur->_data) == key)
{
//隐式类型转化构造迭代器
return cur;
}
cur = cur->_next;
}
return nullptr;
}
bool Erase(const k& key)
{
//===================
//封装第一步 套一层仿函数kot
//===================
KeyOfT kot;
Hash hs;
size_t Hashi = hs(key) % _tables.size();
Node* cur = _tables[Hashi];
Node* prev = nullptr;//删除需要一个前置指针
while (cur)
{
if (kot(cur->_data) == key)
{
if (prev == nullptr)
{
//说明要删除的节点就是第一个节点 即cur就是哈希桶的第一个节点
_tables[Hashi] = cur->_next;
}
else
{
prev->_next = cur->_next;
}
delete cur;
return true;
}
prev = cur;
cur = cur->_next;
}
return false;
}
private:
vector<Node*> _tables;
size_t _n;//有效数据个数
};2.2实现普通迭代器(iterator)和const迭代器(const_iterator)
iterator实现的大框架跟list的iterator思路是⼀致的,用一个类型封装结点的指针,再通过重载运算符实现,迭代器像指针一样访问的行为 ,要注意的是哈希表的迭代器是单向迭代器。- 这里的难点是
operator++的实现。iterator中有⼀个指向结点的指针,如果当前桶下⾯还有结点,则结点的指针指向下⼀个结点即可。如果当前桶⾛完了,则需要想办法计算找到下⼀个桶。这⾥的难点是反⽽是结构设计的问题,源码实现的迭代器iterator中除了有结点的指针,还有哈希表对象的指针,这样当前桶走完了,要计算下⼀个桶就相对容易多了,用key值计算出当前桶位置,依次往后找下⼀个不为空的桶即可
实际上就是两个指针哈希表指针HT*和链表指针Node*,一个指针去遍历哈希表,一个指针去遍历每个位置中的结点。
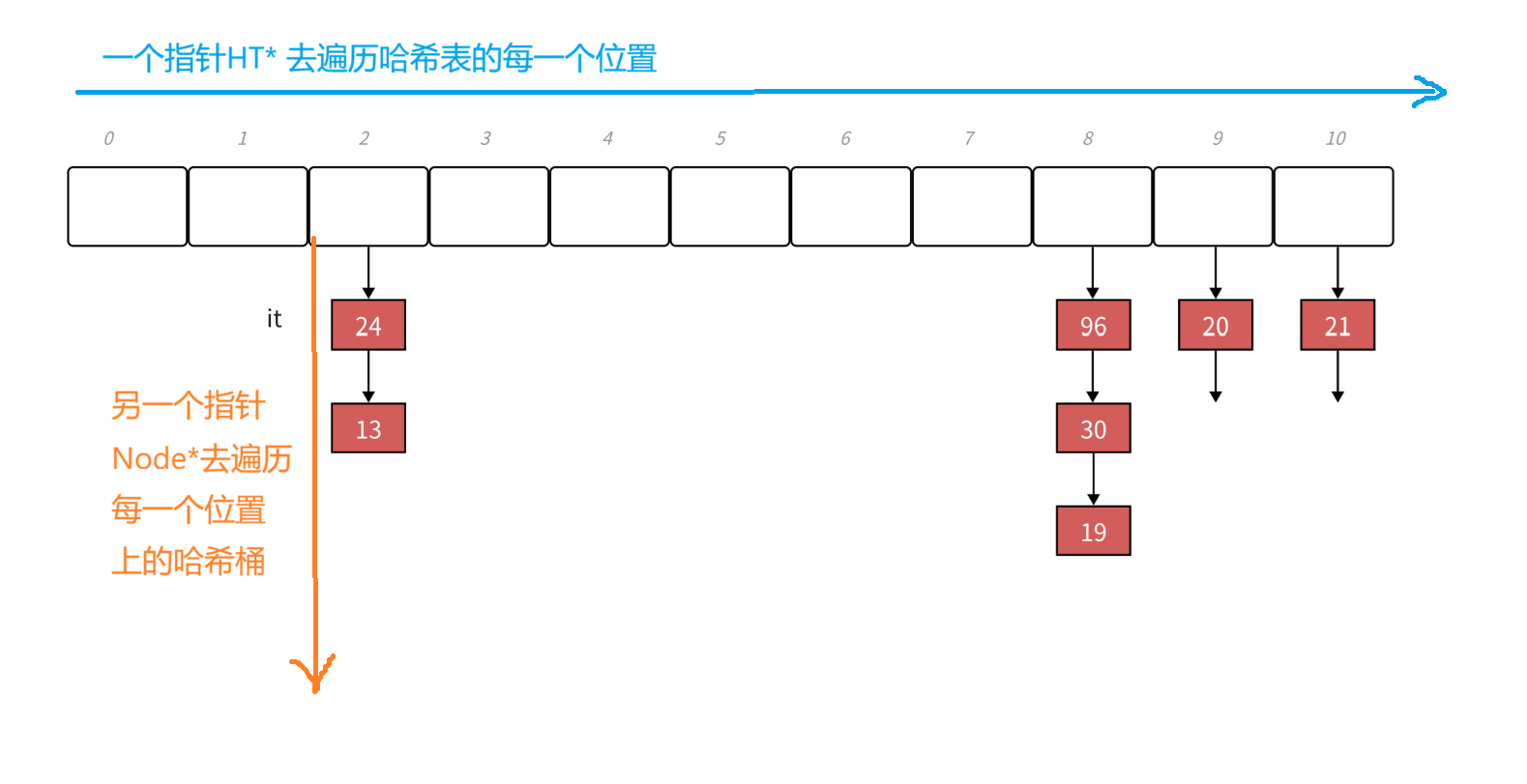
1、在HashTable.h中:
cpp
//前置声明 迭代器使用了HashTable 但是编译器向上找找不到所以要前置声明
template<class K, class T, class KeyOfT, class Hash>
class HashTable;
//迭代器 的封装
template<class k,class T,class Ref,class Ptr,class KeyOfT,class Hash>
struct HTIterator
{
typedef HashNode<T> Node;
typedef HashTable<k, T, KeyOfT, Hash> HT;//多定义一个哈希表类型 因为要定义一个哈希表类型的指针来遍历哈希表
typedef HTIterator<k, T, Ref, Ptr, KeyOfT, Hash> Self;//Self是迭代器类型
Node* _node;
const HT* _ht; //注意这里要加上const!!! 这是遍历哈希表的指针
HTIterator(Node* node,const HT* ht)
:_node(node)//每一个位置对于的桶里面的指针
,_ht(ht)//哈希表的指针 哈希表是一个vector 这是一个vector的指针
{}
//Ref由哈希表迭代器传参来决定 Ref为T&
Ref operator*()
{
return _node->_data;
}
//Ptr也由哈希表迭代器传参来决定 Ptr为T*
Ptr operator->()
{
return &_node->_data;
}
//加加返回迭代器类型 迭代器类型太长了 所以重命名为Self
Self& operator++() //迭代器++是有两个指针来进行++的,一个是外层遍历vector的那个指针
{ //一个是遍历每个桶的结点的指针
if (_node->_next)
{
//如果桶中还有结点那么就继续往下遍历
_node = _node->_next;
}
else
{
//当前桶为空需要去寻找下一个桶的第一个结点
size_t hashi = Hash()(KeyOfT()(_node->_data))% _ht->_tables.size();
++hashi;
while (hashi != _ht->_tables.size())
{
//如果下一个桶不是哈希表的最后一个位置 且该位置不为空那就继续往下遍历桶中的链表
if (_ht->_tables[hashi])
{
_node = _ht->_tables[hashi];
break;
}
hashi++;
}
//跳出循环 说明最后一个位置的桶已经遍历结束 迭代器器将走到end
if (hashi == _ht->_tables.size())
{
_node = nullptr;
}
}
return *this;
}
bool operator!=(const Self& s) const
{
return _node != s._node;
}
bool operator==(const Self& s) const
{
return _node == s._node;
}
};
template<class k, class T,class KeyOfT ,class Hash>
class HashTable
{
//友元声明 因为iterator中使用了HashTable的私有成员
template<class K, class T, class Ref, class Ptr, class KeyOfT, class Hash>
friend struct HTIterator;
typedef HashNode<T> Node;
public:
typedef HTIterator<k, T, T&, T*, KeyOfT, Hash> Iterator;
typedef HTIterator<k, T, const T&,const T*, KeyOfT, Hash> ConstIterator;
Iterator Begin()
{
for (size_t i = 0;i < _tables.size();i++)
{
//哪一个位置的结点不为空 就将该位置和该结点去构造迭代器
if (_tables[i])
{
return Iterator(_tables[i], this);
}
}
//所有位置上的桶均为空就走到End
return End();
}
Iterator End()
{
return Iterator(nullptr, this);
}
//const迭代器
ConstIterator Begin() const
{
for (size_t i = 0; i < _tables.size(); i++)
{
if (_tables[i])
{
return ConstIterator(_tables[i], this);
}
}
return End();
}
ConstIterator End() const
{
return ConstIterator(nullptr, this);
}
//......
private:
vector<Node*> _tables;
size_t _n;//有效数据个数
};2、在unordered_set中:
cpp
namespace my_set
{
template<class k, class Hash = HashFunc<k>>
class unordered_set
{
public:
struct SetKeyOfT
{
const k& operator()(const k& key)
{
return key;
}
};
typedef typename HashTable<k, const k, SetKeyOfT, Hash>::Iterator iterator;
typedef typename HashTable<k, const k, SetKeyOfT, Hash>::ConstIterator const_iterator;
iterator begin()
{
return _t.Begin();
}
iterator end()
{
return _t.End();
}
const_iterator begin() const
{
return _t.Begin();
}
const_iterator end() const
{
return _t.End();
}
private:
HashTable<k, k, SetKeyOfT, Hash> _t;
};
};3、在unordered_map中:
cpp
namespace my_map
{
template<class k, class v, class Hash = HashFunc<k>>
class unordered_map
{
public:
struct MapKeyOfT
{
const k& operator()(const pair<k, v>& kv)
{
return kv.first;
}
};
typedef typename HashTable<k, pair< k, v>, MapKeyOfT, Hash>::Iterator iterator;
typedef typename HashTable<k, pair< k, v>, MapKeyOfT, Hash>::ConstIterator const_iterator;
iterator begin()
{
return _t.Begin();
}
iterator end()
{
return _t.End();
}
const_iterator begin() const
{
return _t.Begin();
}
const_iterator end() const
{
return _t.End();
}
private:
HashTable<k, pair<k, v>, MapKeyOfT, Hash> _t;
};
};2.3实现unordered_map和unordered_set中Key不支持修改
想要实现
unordered_map中Key不能被修改,那么我们在将哈希表实例化成unordered_map传参的时候就因该限制,pair里的key不能被修改,所以我们直接加上const即可,下面看代码:
1、在unordered_set.h中:
cpp
namespace my_set
{
template<class k, class Hash = HashFunc<k>>
class unordered_set
{
public:
struct SetKeyOfT
{
//......
};
typedef typename HashTable<k, const k, SetKeyOfT, Hash>::Iterator iterator;
typedef typename HashTable<k, const k, SetKeyOfT, Hash>::ConstIterator const_iterator;
//迭代器部分略......
private:
//将第二个模板参数加上const修饰
HashTable<k, const k, SetKeyOfT, Hash> _t;
};
};2、在unordered_map.h中:
cpp
namespace my_map
{
template<class k, class v, class Hash = HashFunc<k>>
class unordered_map
{
public:
struct MapKeyOfT
{
//......
};
//下面的k加上了const迭代器这里也需要加上,不然就会出现权限问题
typedef typename HashTable<k, pair< const k, v>, MapKeyOfT, Hash>::Iterator iterator;
typedef typename HashTable<k, pair< const k, v>, MapKeyOfT, Hash>::ConstIterator const_iterator;
//迭代器部分略......
private:
//map保证key不能修改 所以给k加上const
HashTable<k, pair<const k, v>, MapKeyOfT, Hash> _t;
};
};2.42.4实现map的operator\[\]
与前面红黑树封装的
map和set一样,unoredered_map的方括号底层实际上是调用插入来实现的,因为插入的返回值是一个pair<iterator,bool>刚好有查找和修改的功能,所以我们只需要修改一下插入函数,然后底层调用插入函数即可。 下面来看代码:
1、在HashTable.h中:
cpp
pair<Iterator,bool> Insert(const T& data)
{
KeyOfT kot;
auto it = Find(kot(data));
if (it!=End())
return {it,false};
Hash hs;
//法二 将旧表的节点直接拿下来挂到新表对应的位置 而不是拷贝
if (_n == _tables.size())
{
vector<Node*> newtables(_tables.size() * 2);
//遍历旧表 将旧表的节点移动到新表
for (size_t i = 0;i < _tables.size();i++)
{
Node* cur = _tables[i];
//遍历每一个位置的哈希桶
while (cur)
{
//根据新表的大小重新计算映射位置
size_t Hashi = hs(kot(cur->_data)) % _tables.size();
Node* next = cur->_next;
cur->_next = newtables[Hashi];
newtables[Hashi] = cur;
cur = next;
}
}
//旧表全部遍历完后 与新表交换内部指针_start _finish _endofstorage
_tables.swap(newtables);
}
//通过余数找到要映射的位置
size_t Hashi = hs(kot(data)) % _tables.size();
Node* NewNode = new Node(data);//根据kv开一个节点的空间
//将新节点与哈希表链接
NewNode->_next = _tables[Hashi];
_tables[Hashi] = NewNode;
_n++;
return {Iterator(NewNode,this),true};
}修改完成后接下来我们就可以在
unordered_map.h中去调用这个插入函数:
cpp
v& operator[](const k& key)
{
pair<iterator, bool> ret = insert({ key,v() });
return ret.first->second;
}三、完整代码&测试代码
1、由于篇幅问题,想要获得完整代码的友友们请到我的代码仓库获取:->获取完整代码请点击
2、测试代码:
cpp
void Func(const my_set::unordered_set<int>& s)
{
auto it1 = s.begin();
while (it1 != s.end())
{
// *it1 = 1;
cout << *it1 << " ";
++it1;
}
cout << endl;
}
void test_uset1()
{
my_set::unordered_set<int> s1;
s1.insert(45);
s1.insert(5);
s1.insert(13);
s1.insert(45);
s1.insert(452);
s1.insert(4513);
s1.insert(333);
s1.insert(123);
auto it1 = s1.begin();
while (it1 != s1.end())
{
//*it1 = 1;
cout << *it1 << " ";
++it1;
}
cout << endl;
}
cpp
void test_umap()
{
my_map::unordered_map<string, string> dict;
dict.insert({ "insert", "插入" });
dict.insert({ "sort", "排序" });
dict.insert({ "test", "测试" });
for (auto& [k, v] : dict)
{
// k += 'x';
cout << k << ":" << v << endl;
}
dict["string"] = "字符串";
dict["key"];
dict["key"] = "关键字";
dict["for"];
for (auto& [k, v] : dict)
{
cout << k << ":" << v << endl;
}
}
四、总结
由于哈希表的封装与红黑树的封装类似,所以就不再过多的赘述了,如果有什么问题可以点击我的代码仓库去看源码,博客的代码也有可能笔误还请多多包含,!相信只要按照上面的步骤你也能封装出一个属于你自己的
unoredered_map/set!
html
MSTcheng 始终坚持用直观图解 + 实战代码,把复杂技术拆解得明明白白!
👁️ 【关注】 看普通程序员如何用实用派思路搞定复杂需求
👍 【点赞】 给 "不搞虚的" 技术分享多份认可
🔖 【收藏】 把这些 "好用又好懂" 的干货技巧存进你的知识库
💬 【评论】 来唠唠 ------ 你踩过最 "离谱" 的技术坑是啥?
🔄 【转发】把实用技术干货分享给身边有需要的程序员伙伴
技术从无唯一解,让我们一起用最接地气的方式,写出最扎实的代码! 🚀💻能够看到这里的小伙伴已经打败95%的人了超棒的,为你点赞,休息一下吧!
