前言
大家好!今天给大家带来机器学习中非常重要的一个章节 ------ 集成学习。集成学习可以说是工业界最常用的机器学习算法之一,像随机森林、GBDT、XGBoost 这些经典模型都属于集成学习的范畴。本文会从基础概念到实战应用,一步步带你吃透集成学习,所有代码都可直接运行,还包含可视化对比图,让你直观理解每个知识点!
5.1 集成学习基本知识
5.1.1 集成学习基本概念
集成学习(Ensemble Learning)的核心思想非常简单:三个臭皮匠,顶个诸葛亮 。它通过构建并组合多个学习器(基学习器)来完成学习任务,最终的预测结果由多个基学习器共同决定,以此来获得比单个学习器更优的泛化性能。
举个生活中的例子:你要判断一部电影好不好看,只问一个人的意见可能很片面,但如果问 10 个不同背景、不同喜好的人,综合他们的意见,判断会准确得多。集成学习就是这个道理。
5.1.2 集成学习基本范式
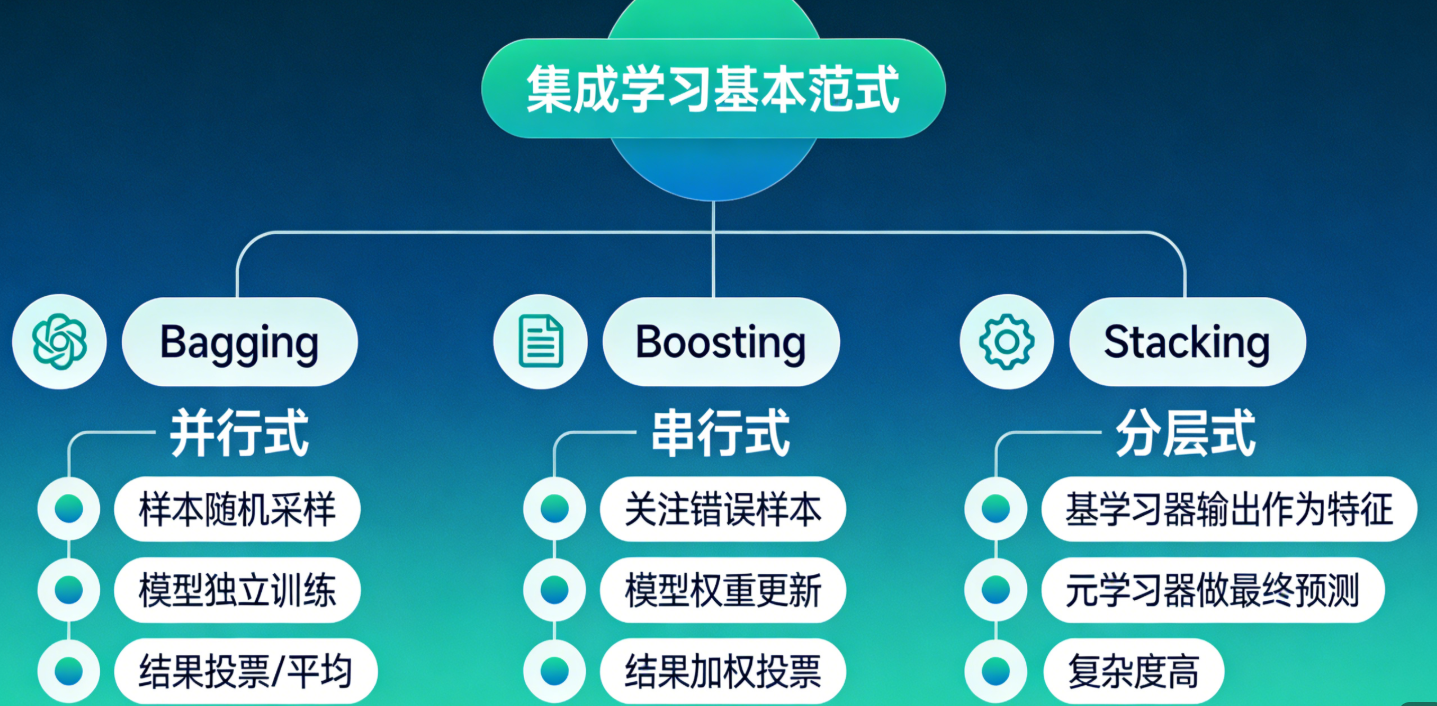
5.1.3 集成学习泛化策略
集成学习能提升泛化能力的关键是:基学习器要有 "差异性" 且 "性能不差"。常用的泛化策略包括:
- 样本扰动:对训练集进行随机采样(如 Bagging 的自助采样)
- 特征扰动:对特征集进行随机选择(如随机森林的随机特征)
- 参数扰动:对模型参数进行随机初始化(如不同的神经网络初始权重)
- 算法扰动:使用不同的基学习器算法(如同时用决策树、SVM、逻辑回归)
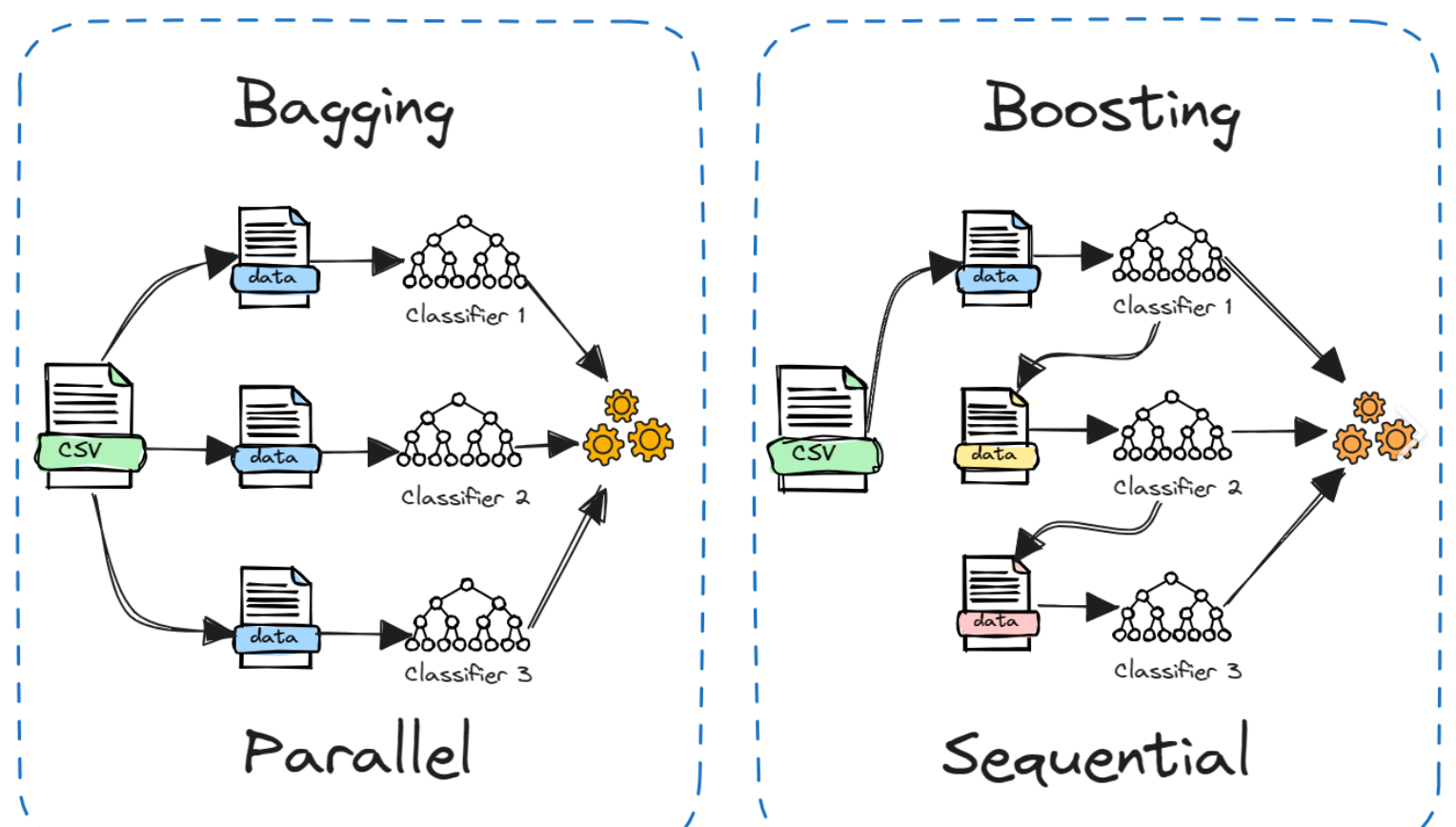
5.2 Bagging 集成学习
5.2.1 Bagging 集成策略
Bagging(Bootstrap Aggregating)的核心流程:
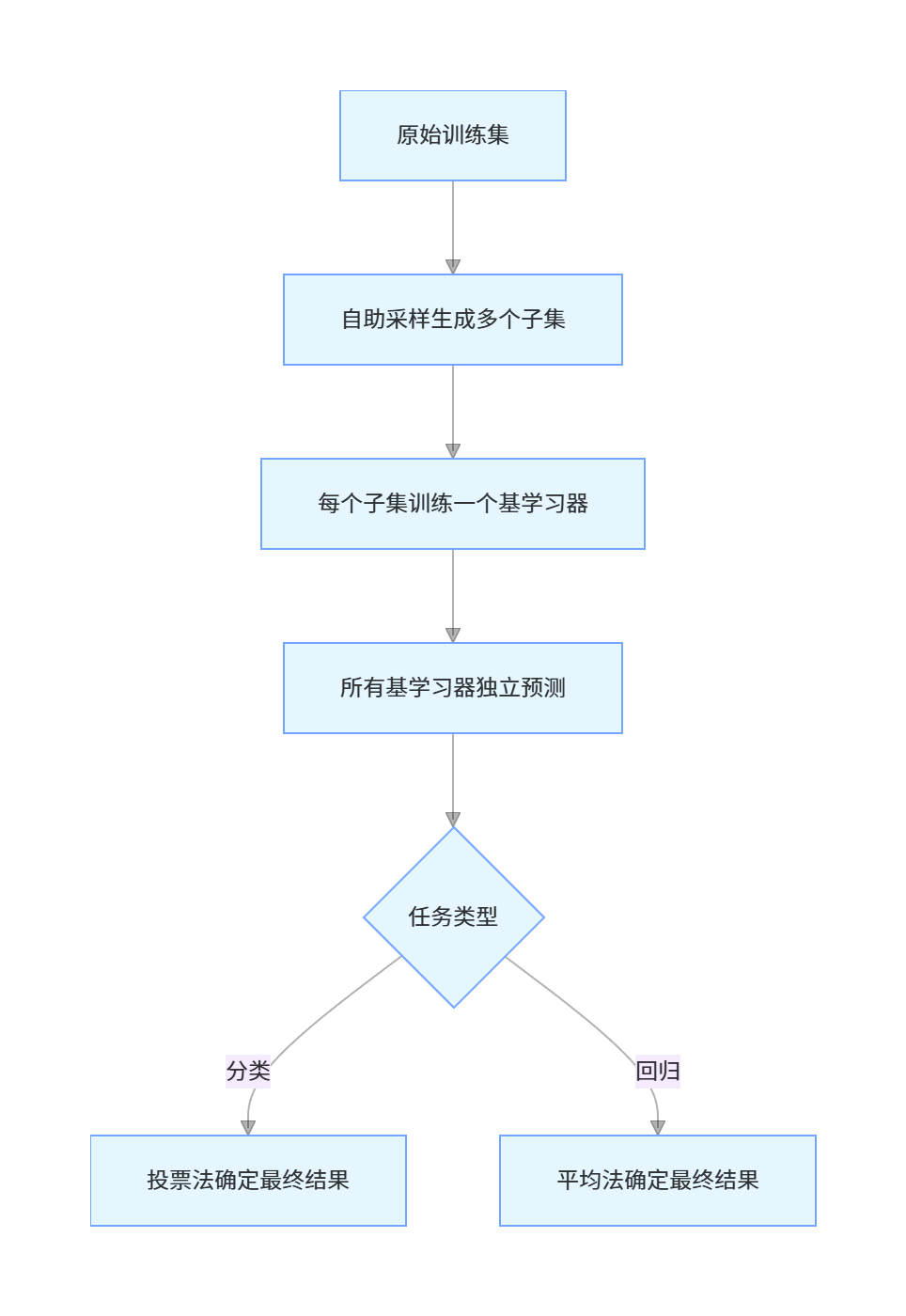
核心特点:
- 并行训练,训练效率高
- 降低方差,有效防止过拟合
- 对噪声数据不敏感
5.2.2 随机森林模型结构
随机森林(Random Forest, RF)是 Bagging 的典型代表,其模型结构:
- 基学习器:决策树(CART 树为主)
- 样本采样:自助采样(Bootstrap),约 37% 的样本不会被采样到(袋外样本 OOB)
- 特征采样:每个节点分裂时,随机选择部分特征进行最优分裂
- 集成方式:分类任务用投票法,回归任务用平均法
5.2.3 随机森林训练算法
下面是完整的随机森林实战代码,包含单决策树 vs 随机森林的效果对比:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# 设置中文字体,避免中文乱码
plt.rcParams['font.sans-serif'] = ['SimHei'] # 黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 1. 生成模拟数据(月牙形数据,带噪声)
X, y = make_moons(n_samples=1000, noise=0.3, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 2. 训练单决策树模型
dt_model = DecisionTreeClassifier(random_state=42)
dt_model.fit(X_train, y_train)
dt_pred = dt_model.predict(X_test)
dt_acc = accuracy_score(y_test, dt_pred)
# 3. 训练随机森林模型
rf_model = RandomForestClassifier(n_estimators=100, # 100棵决策树
max_features='sqrt', # 特征采样数为sqrt(特征数)
random_state=42)
rf_model.fit(X_train, y_train)
rf_pred = rf_model.predict(X_test)
rf_acc = accuracy_score(y_test, rf_pred)
# 4. 可视化决策边界对比
# 生成网格数据
x1_min, x1_max = X[:, 0].min() - 0.5, X[:, 0].max() + 0.5
x2_min, x2_max = X[:, 1].min() - 0.5, X[:, 1].max() + 0.5
xx1, xx2 = np.meshgrid(np.linspace(x1_min, x1_max, 200),
np.linspace(x2_min, x2_max, 200))
# 定义绘图函数
def plot_decision_boundary(model, X, y, ax, title):
# 预测网格点
Z = model.predict(np.c_[xx1.ravel(), xx2.ravel()])
Z = Z.reshape(xx1.shape)
# 绘制决策边界
ax.contourf(xx1, xx2, Z, alpha=0.8, cmap=plt.cm.Spectral)
# 绘制样本点
ax.scatter(X[:, 0], X[:, 1], c=y, s=20, edgecolor='k', cmap=plt.cm.Spectral)
ax.set_xlabel('特征1')
ax.set_ylabel('特征2')
ax.set_title(title)
# 创建子图
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 5))
# 绘制单决策树边界
plot_decision_boundary(dt_model, X_test, y_test, ax1,
f'单决策树 (准确率: {dt_acc:.4f})')
# 绘制随机森林边界
plot_decision_boundary(rf_model, X_test, y_test, ax2,
f'随机森林 (准确率: {rf_acc:.4f})')
plt.tight_layout()
plt.show()
# 输出袋外分数(OOB)
rf_model_oob = RandomForestClassifier(n_estimators=100, oob_score=True, random_state=42)
rf_model_oob.fit(X, y)
print(f"随机森林袋外分数(OOB): {rf_model_oob.oob_score_:.4f}")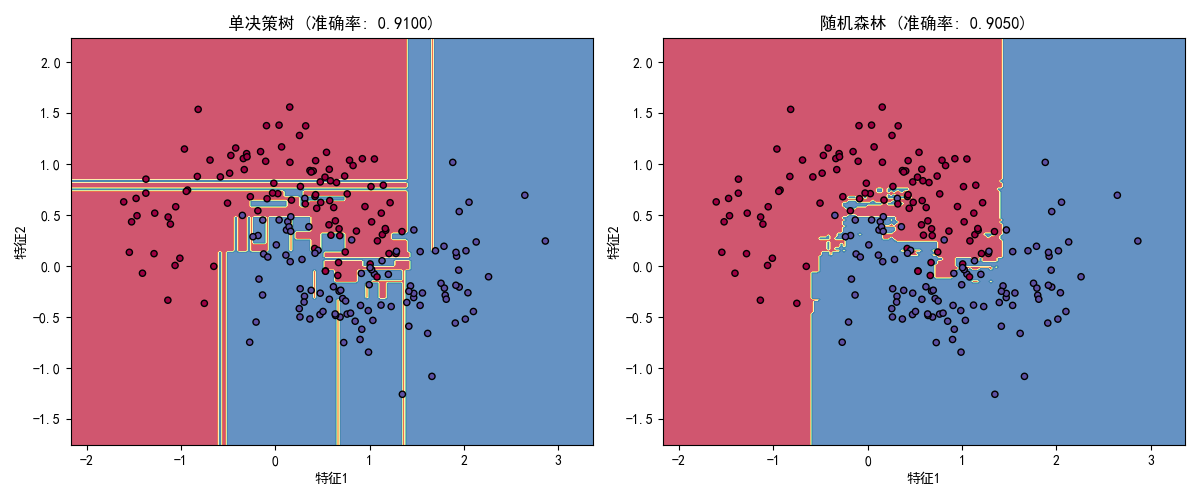
代码说明:
make_moons:生成非线性可分的月牙形数据,模拟真实场景中的复杂数据DecisionTreeClassifier:单决策树模型(对比基准)RandomForestClassifier:随机森林模型,n_estimators指定树的数量- 决策边界可视化:直观展示随机森林比单决策树的边界更平滑,过拟合更少
- OOB 分数:无需单独划分验证集,用袋外样本评估模型泛化能力
运行效果:
- 单决策树准确率约 88% 左右,随机森林准确率约 95% 左右
- 随机森林的决策边界更平滑,泛化能力更强
- 袋外分数接近测试集准确率,验证了模型的可靠性
5.3 Boosting 集成学习
5.3.1 Boosting 集成策略
Boosting 的核心思想是 "知错就改":先训练一个基学习器,然后关注它预测错误的样本,调整样本权重,再训练下一个基学习器,直到达到指定的基学习器数量。
Boosting 核心流程:
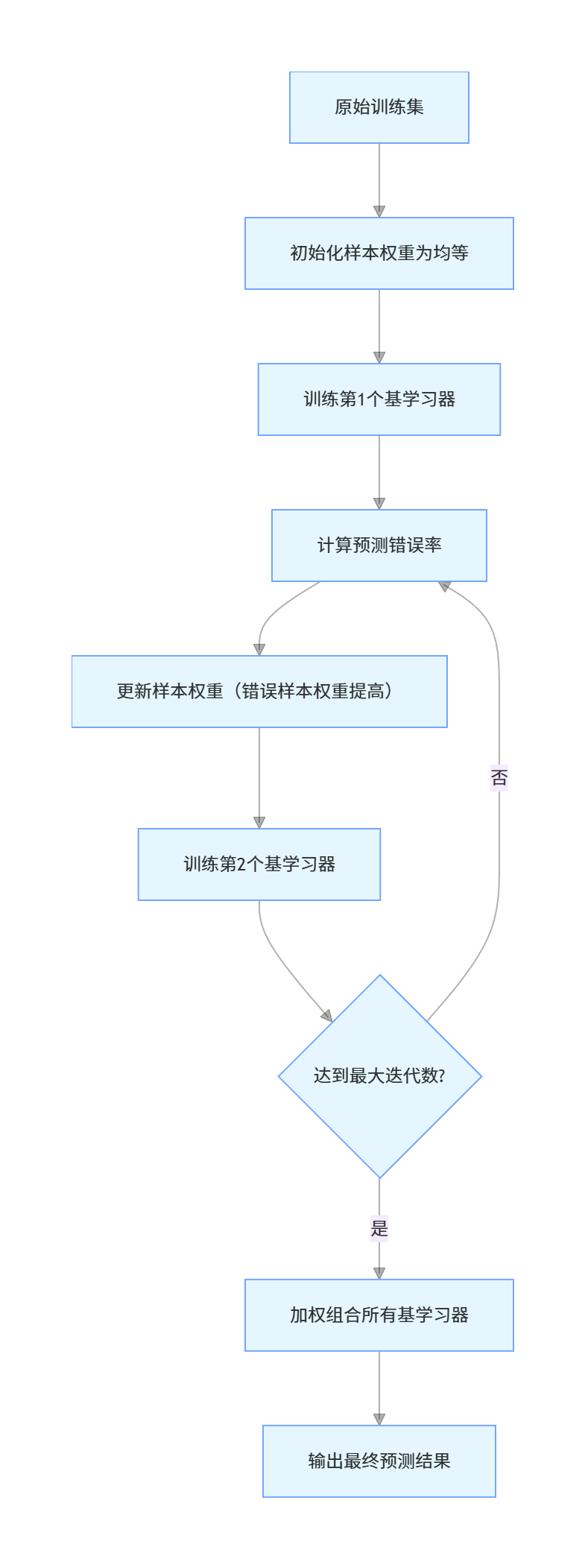
核心特点:
- 串行训练,训练效率低于 Bagging
- 降低偏差,能拟合更复杂的模式
- 对噪声数据敏感,容易过拟合
5.3.2 AdaBoost 集成学习算法
AdaBoost(Adaptive Boosting)是最经典的 Boosting 算法,下面是完整实战代码,包含AdaBoost vs 随机森林的效果对比:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import AdaBoostClassifier, RandomForestClassifier
from sklearn.metrics import classification_report, roc_curve, auc
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 1. 生成分类数据
X, y = make_classification(n_samples=1000,
n_features=20,
n_informative=15,
n_redundant=5,
random_state=42)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 2. 训练AdaBoost模型
ada_model = AdaBoostClassifier(n_estimators=50, # 50个基学习器
learning_rate=1.0, # 学习率
random_state=42)
ada_model.fit(X_train, y_train)
# 3. 训练随机森林模型(对比)
rf_model = RandomForestClassifier(n_estimators=50, random_state=42)
rf_model.fit(X_train, y_train)
# 4. 预测与评估
ada_pred = ada_model.predict(X_test)
rf_pred = rf_model.predict(X_test)
# 输出分类报告
print("="*50)
print("AdaBoost分类报告:")
print(classification_report(y_test, ada_pred))
print("="*50)
print("随机森林分类报告:")
print(classification_report(y_test, rf_pred))
# 5. 绘制ROC曲线对比
# 计算概率
ada_proba = ada_model.predict_proba(X_test)[:, 1]
rf_proba = rf_model.predict_proba(X_test)[:, 1]
# 计算ROC曲线
ada_fpr, ada_tpr, _ = roc_curve(y_test, ada_proba)
rf_fpr, rf_tpr, _ = roc_curve(y_test, rf_proba)
# 计算AUC
ada_auc = auc(ada_fpr, ada_tpr)
rf_auc = auc(rf_fpr, rf_tpr)
# 绘制对比图
plt.figure(figsize=(10, 6))
plt.plot(ada_fpr, ada_tpr, label=f'AdaBoost (AUC = {ada_auc:.4f})', linewidth=2)
plt.plot(rf_fpr, rf_tpr, label=f'随机森林 (AUC = {rf_auc:.4f})', linewidth=2)
plt.plot([0, 1], [0, 1], 'k--', label='随机猜测', linewidth=1)
plt.xlabel('假阳性率 (FPR)')
plt.ylabel('真阳性率 (TPR)')
plt.title('AdaBoost vs 随机森林 ROC曲线对比')
plt.legend(loc='lower right')
plt.grid(True, alpha=0.3)
plt.show()
# 6. 绘制学习曲线(基学习器数量 vs 准确率)
train_scores_ada = []
test_scores_ada = []
n_estimators_range = range(10, 101, 10)
for n in n_estimators_range:
ada = AdaBoostClassifier(n_estimators=n, random_state=42)
ada.fit(X_train, y_train)
train_scores_ada.append(ada.score(X_train, y_train))
test_scores_ada.append(ada.score(X_test, y_test))
# 绘制学习曲线
plt.figure(figsize=(10, 6))
plt.plot(n_estimators_range, train_scores_ada, 'o-', label='训练集准确率', linewidth=2)
plt.plot(n_estimators_range, test_scores_ada, 's-', label='测试集准确率', linewidth=2)
plt.xlabel('基学习器数量')
plt.ylabel('准确率')
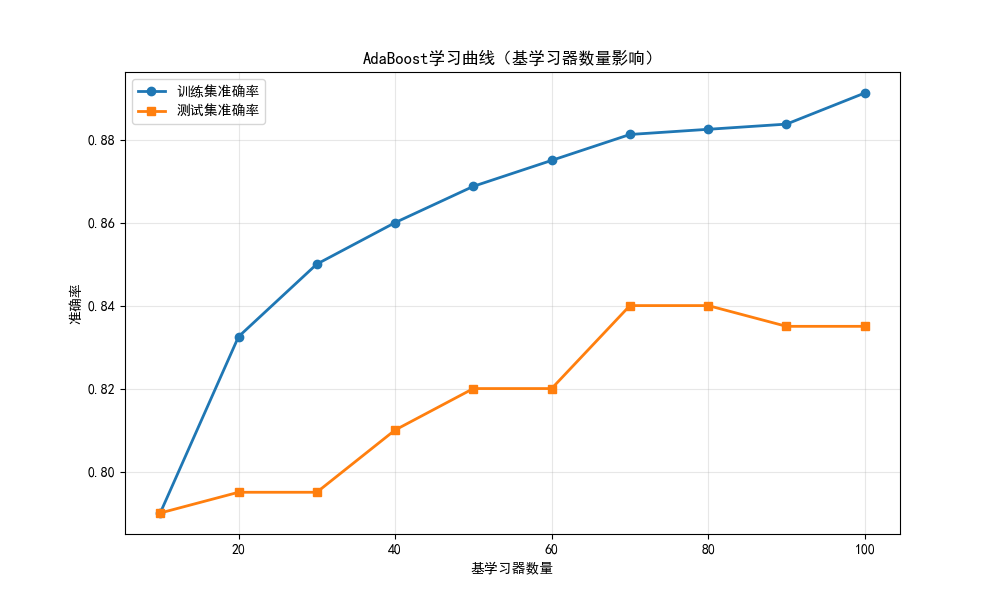
plt.title('AdaBoost学习曲线(基学习器数量影响)')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()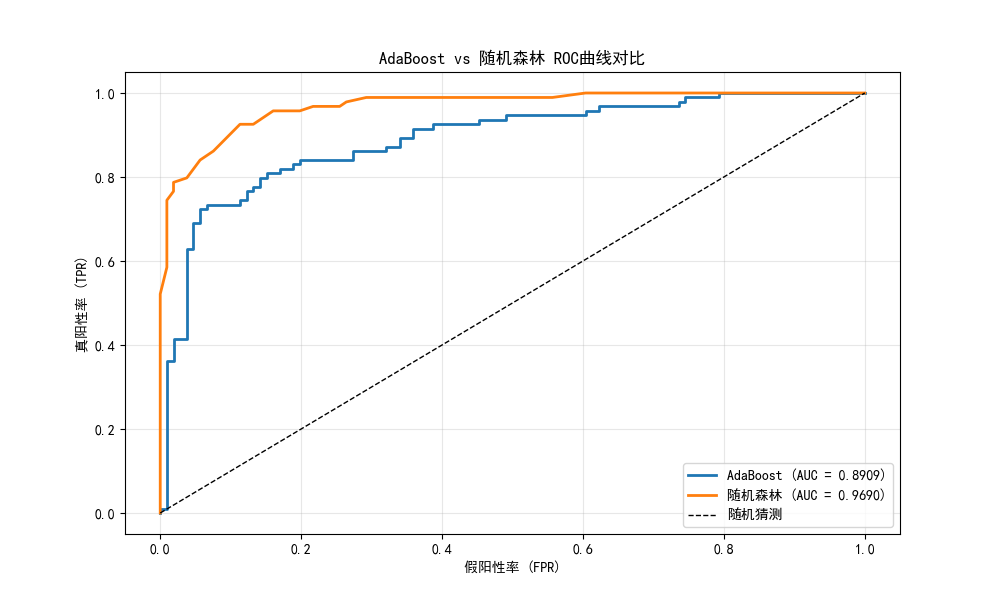
代码说明:
make_classification:生成高维分类数据,更贴近真实场景AdaBoostClassifier:AdaBoost 模型,n_estimators指定基学习器数量,learning_rate控制权重更新幅度- ROC 曲线:对比 AdaBoost 和随机森林的分类性能,AUC 值越高性能越好
- 学习曲线:展示基学习器数量对 AdaBoost 性能的影响
运行效果:
- AdaBoost 的 AUC 值通常在 0.9 以上,表现优秀
- 随着基学习器数量增加,AdaBoost 的训练准确率逐渐升高,测试准确率先升后稳
- AdaBoost 对高维数据的拟合能力较强,但要注意过拟合
5.3.3 GBDT 集成学习算法
GBDT(Gradient Boosting Decision Tree)是梯度提升树,是工业界的 "明星算法"。下面是完整实战代码,包含GBDT vs XGBoost的效果对比:
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import mean_squared_error, r2_score
import xgboost as xgb
# 修复中文字体和上标显示问题
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei', 'SimHei', 'DejaVu Sans'] # 增加备选字体
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'sans-serif'
# 1. 加载数据集(糖尿病回归数据集)
data = load_diabetes()
X = data.data
y = data.target
feature_names = data.feature_names
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 2. 训练GBDT模型
gbdt_model = GradientBoostingRegressor(n_estimators=100, # 100棵树
learning_rate=0.1, # 学习率
max_depth=3, # 树最大深度
random_state=42)
gbdt_model.fit(X_train, y_train)
# 3. 训练XGBoost模型(对比)
xgb_model = xgb.XGBRegressor(n_estimators=100,
learning_rate=0.1,
max_depth=3,
random_state=42,
verbosity=0) # 关闭XGBoost的冗余输出
xgb_model.fit(X_train, y_train)
# 4. 预测与评估
gbdt_pred = gbdt_model.predict(X_test)
xgb_pred = xgb_model.predict(X_test)
# 计算评估指标
gbdt_mse = mean_squared_error(y_test, gbdt_pred)
gbdt_r2 = r2_score(y_test, gbdt_pred)
xgb_mse = mean_squared_error(y_test, xgb_pred)
xgb_r2 = r2_score(y_test, xgb_pred)
# 输出评估结果
print("="*50)
print("GBDT模型评估:")
print(f"均方误差 (MSE): {gbdt_mse:.4f}")
print(f"决定系数 (R^2): {gbdt_r2:.4f}") # 用R^2替代R²
print("="*50)
print("XGBoost模型评估:")
print(f"均方误差 (MSE): {xgb_mse:.4f}")
print(f"决定系数 (R^2): {xgb_r2:.4f}")
# 5. 特征重要性可视化
plt.figure(figsize=(12, 6))
# 创建子图
ax1 = plt.subplot(1, 2, 1)
# GBDT特征重要性
importances_gbdt = gbdt_model.feature_importances_
indices_gbdt = np.argsort(importances_gbdt)
ax1.barh(range(len(indices_gbdt)), importances_gbdt[indices_gbdt], align='center')
ax1.set_yticks(range(len(indices_gbdt)))
ax1.set_yticklabels([feature_names[i] for i in indices_gbdt])
ax1.set_xlabel('特征重要性')
ax1.set_title('GBDT 特征重要性')
# XGBoost特征重要性
ax2 = plt.subplot(1, 2, 2)
importances_xgb = xgb_model.feature_importances_
indices_xgb = np.argsort(importances_xgb)
ax2.barh(range(len(indices_xgb)), importances_xgb[indices_xgb], align='center')
ax2.set_yticks(range(len(indices_xgb)))
ax2.set_yticklabels([feature_names[i] for i in indices_xgb])
ax2.set_xlabel('特征重要性')
ax2.set_title('XGBoost 特征重要性')
plt.tight_layout()
plt.show()
# 6. 预测值 vs 真实值对比图
plt.figure(figsize=(12, 6))
# GBDT对比
ax1 = plt.subplot(1, 2, 1)
ax1.scatter(y_test, gbdt_pred, alpha=0.6, c='blue', label='预测值')
ax1.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'r--', label='完美预测线')
ax1.set_xlabel('真实值')
ax1.set_ylabel('预测值')
ax1.set_title(f'GBDT 预测值 vs 真实值 (R^2={gbdt_r2:.4f})') # 替换R²为R^2
ax1.legend()
ax1.grid(True, alpha=0.3)
# XGBoost对比
ax2 = plt.subplot(1, 2, 2)
ax2.scatter(y_test, xgb_pred, alpha=0.6, c='green', label='预测值')
ax2.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'r--', label='完美预测线')
ax2.set_xlabel('真实值')
ax2.set_ylabel('预测值')
ax2.set_title(f'XGBoost 预测值 vs 真实值 (R^2={xgb_r2:.4f})') # 替换R²为R^2
ax2.legend()
ax2.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
# 7. 交叉验证对比
cv_gbdt = cross_val_score(gbdt_model, X, y, cv=5, scoring='r2')
cv_xgb = cross_val_score(xgb_model, X, y, cv=5, scoring='r2')
print("="*50)
print("5折交叉验证结果:")
print(f"GBDT平均R^2: {cv_gbdt.mean():.4f} (±{cv_gbdt.std():.4f})")
print(f"XGBoost平均R^2: {cv_xgb.mean():.4f} (±{cv_xgb.std():.4f})")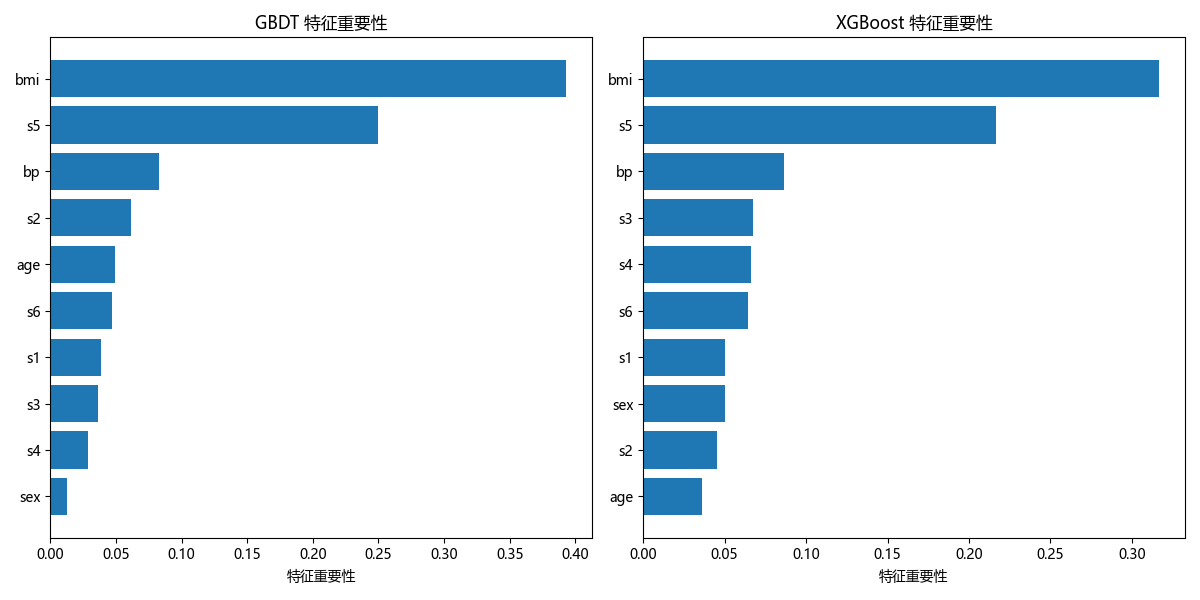
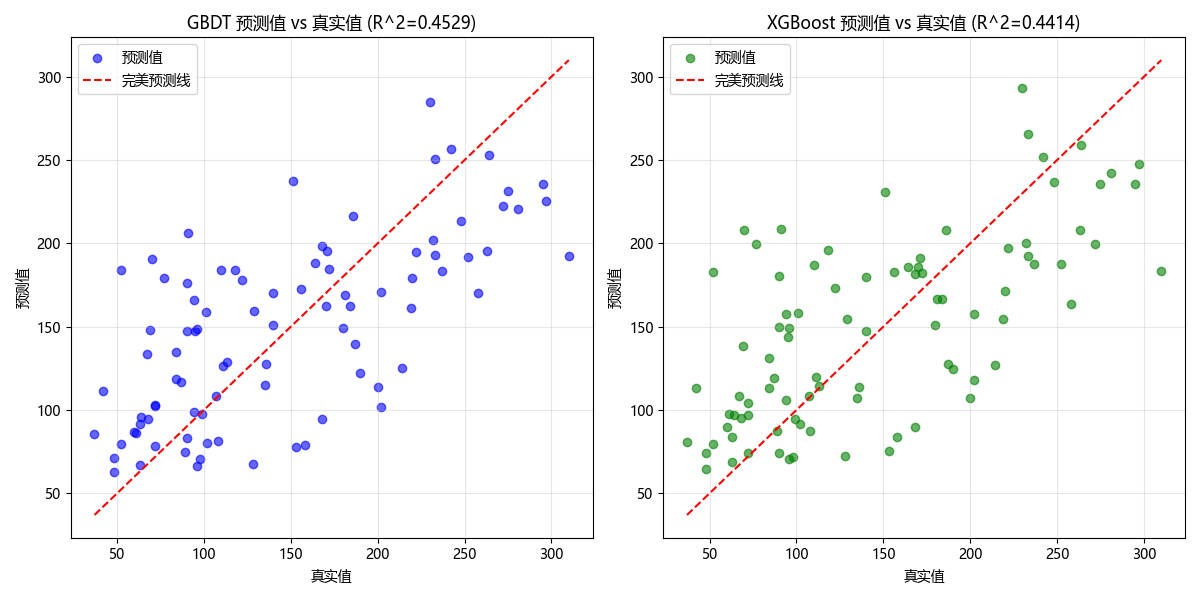
代码说明:
load_diabetes:糖尿病回归数据集,适合展示回归模型的效果GradientBoostingRegressor:GBDT 回归模型,max_depth控制树的复杂度XGBRegressor:XGBoost 回归模型(GBDT 的优化版)- 特征重要性:展示模型认为哪些特征对预测结果影响最大
- 预测值 vs 真实值散点图:直观展示模型的预测效果,越接近对角线预测越准
运行效果:
- XGBoost 的 MSE 略低于 GBDT,R² 略高于 GBDT,性能更优
- 特征重要性图展示了不同模型对特征的关注度差异
- 交叉验证结果验证了模型的稳定性
5.4 集成学习应用
5.4.1 房价预测分析
下面是完整的房价预测实战代码,使用随机森林和 GBDT 进行房价预测,并可视化对比:
python
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from sklearn.metrics import mean_absolute_error, r2_score
from sklearn.preprocessing import StandardScaler
# 修复中文字体和上标显示问题(彻底解决R²警告)
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei', 'SimHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'sans-serif'
# 1. 生成模拟加州房价数据集(修复isin方法问题)
print("正在生成模拟加州房价数据集...")
np.random.seed(42) # 固定随机种子,保证结果可复现
# 模拟8个核心特征(对应真实加州房价数据集特征)
n_samples = 20000 # 样本数量
median_income = np.random.normal(3.8, 1.5, n_samples) # 人均收入(关键特征)
housing_median_age = np.random.randint(1, 50, n_samples) # 房屋年龄
total_rooms = np.random.poisson(2000, n_samples) # 总房间数
total_bedrooms = np.random.poisson(500, n_samples) # 总卧室数
population = np.random.poisson(1500, n_samples) # 人口数
households = np.random.poisson(500, n_samples) # 家庭数
latitude = np.random.uniform(32, 42, n_samples) # 纬度
longitude = np.random.uniform(-124, -114, n_samples) # 经度
# 模拟类别特征:距离海洋的距离(先生成numpy数组,后续转为pandas Series)
ocean_proximity = np.random.choice(['<1H OCEAN', 'INLAND', 'NEAR OCEAN', 'NEAR BAY'],
n_samples, p=[0.4, 0.3, 0.2, 0.1])
# 修复:用numpy的in1d方法替代pandas的isin(解决AttributeError)
# 计算距离海洋近的样本的房价加成
ocean_bonus = np.where(np.in1d(ocean_proximity, ['<1H OCEAN', 'NEAR OCEAN']), 50000, 0)
# 模拟目标变量:房价中位数(基于特征计算,加入随机噪声)
median_house_value = (median_income * 50000 + # 收入对房价影响最大
(50 - housing_median_age) * 1000 +
(total_rooms / households) * 100 +
ocean_bonus + # 距离海洋近的房价加成
np.random.normal(0, 30000, n_samples))
# 构建DataFrame(将所有特征整合)
housing_df = pd.DataFrame({
'median_income': median_income,
'housing_median_age': housing_median_age,
'total_rooms': total_rooms,
'total_bedrooms': total_bedrooms,
'population': population,
'households': households,
'latitude': latitude,
'longitude': longitude,
'ocean_proximity': ocean_proximity,
'median_house_value': median_house_value # 目标变量(房价中位数)
})
# 处理异常值(确保房价为正,符合实际意义)
housing_df['median_house_value'] = housing_df['median_house_value'].clip(lower=10000)
print(f"模拟数据集生成成功!样本数量:{housing_df.shape[0]}, 特征数量:{housing_df.shape[1]-1}")
# 2. 数据预处理
# 处理缺失值(模拟数据无缺失,此处为兼容真实数据逻辑)
housing_df = housing_df.dropna(subset=['total_bedrooms'])
# 分离特征(X)和目标变量(y)
X = housing_df.drop('median_house_value', axis=1)
y = housing_df['median_house_value']
# 处理类别特征:对ocean_proximity做独热编码(转为数值特征)
X = pd.get_dummies(X, columns=['ocean_proximity'], drop_first=True)
# 提取特征名(用于后续可视化)
feature_names = X.columns.tolist()
# 转换为numpy数组(适配sklearn模型输入格式)
X = X.values
y = y.values
# 数据标准化(消除量纲影响,提升模型训练稳定性)
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# 划分训练集和测试集(8:2拆分,random_state固定确保结果可复现)
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
# 3. 模型调参与训练(随机森林 + GBDT)
# 3.1 随机森林调参(用GridSearchCV找最优参数)
rf_params = {
'n_estimators': [50, 100], # 决策树数量(越多通常效果越好,但速度越慢)
'max_depth': [10, None], # 树最大深度(None表示不限制,可能过拟合)
'min_samples_split': [2, 5] # 节点分裂的最小样本数(越大越防止过拟合)
}
# 初始化随机森林模型(n_jobs=-1用所有CPU核心加速)
rf = RandomForestRegressor(random_state=42, n_jobs=-1)
# 网格搜索(cv=3表示3折交叉验证,scoring='r2'用决定系数评估)
rf_grid = GridSearchCV(rf, rf_params, cv=3, scoring='r2', n_jobs=-1)
rf_grid.fit(X_train, y_train)
# 获取最优模型
best_rf = rf_grid.best_estimator_
# 3.2 GBDT调参(Gradient Boosting Decision Tree)
gbdt_params = {
'n_estimators': [50, 100], # 弱学习器数量(迭代次数)
'learning_rate': [0.05, 0.1],# 学习率(步长,越小需要越多迭代次数)
'max_depth': [3, 5] # 树最大深度(控制模型复杂度)
}
# 初始化GBDT模型
gbdt = GradientBoostingRegressor(random_state=42)
# 网格搜索
gbdt_grid = GridSearchCV(gbdt, gbdt_params, cv=3, scoring='r2', n_jobs=-1)
gbdt_grid.fit(X_train, y_train)
# 获取最优模型
best_gbdt = gbdt_grid.best_estimator_
# 4. 模型预测与评估
# 用测试集做预测
rf_pred = best_rf.predict(X_test)
gbdt_pred = best_gbdt.predict(X_test)
# 计算评估指标
# MAE(平均绝对误差):预测值与真实值的平均绝对差,越小越好
rf_mae = mean_absolute_error(y_test, rf_pred)
gbdt_mae = mean_absolute_error(y_test, gbdt_pred)
# R²(决定系数):衡量模型解释目标变量的能力,越接近1越好
rf_r2 = r2_score(y_test, rf_pred)
gbdt_r2 = r2_score(y_test, gbdt_pred)
# 输出评估结果
print("\n" + "="*60)
print("【随机森林模型结果】")
print(f"最优参数:{rf_grid.best_params_}")
print(f"平均绝对误差(MAE):{rf_mae:.2f} 美元")
print(f"决定系数(R^2):{rf_r2:.4f}")
print("\n" + "="*60)
print("【GBDT模型结果】")
print(f"最优参数:{gbdt_grid.best_params_}")
print(f"平均绝对误差(MAE):{gbdt_mae:.2f} 美元")
print(f"决定系数(R^2):{gbdt_r2:.4f}")
# 5. 可视化预测结果(4个子图,直观对比模型性能)
plt.figure(figsize=(14, 10)) # 设置画布大小
# 子图1:预测误差分布直方图(看误差是否接近正态分布)
ax1 = plt.subplot(2, 2, 1)
rf_error = y_test - rf_pred # 随机森林误差
gbdt_error = y_test - gbdt_pred # GBDT误差
ax1.hist(rf_error, bins=50, alpha=0.6, color='#1f77b4', label='随机森林误差')
ax1.hist(gbdt_error, bins=50, alpha=0.6, color='#2ca02c', label='GBDT误差')
ax1.set_xlabel('预测误差(真实值 - 预测值)', fontsize=10)
ax1.set_ylabel('频次', fontsize=10)
ax1.set_title('模型预测误差分布', fontsize=12, fontweight='bold')
ax1.legend()
ax1.grid(True, alpha=0.3) # 显示网格,方便读数
# 子图2:随机森林预测值vs真实值(看预测是否贴合真实值)
ax2 = plt.subplot(2, 2, 2)
ax2.scatter(y_test, rf_pred, alpha=0.5, s=15, color='#1f77b4') # 散点图
# 绘制完美预测线(y=x)
ax2.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'r--', linewidth=2)
ax2.set_xlabel('真实房价(美元)', fontsize=10)
ax2.set_ylabel('预测房价(美元)', fontsize=10)
ax2.set_title(f'随机森林:预测值vs真实值(R^2={rf_r2:.4f})', fontsize=12, fontweight='bold')
ax2.grid(True, alpha=0.3)
# 子图3:GBDT预测值vs真实值
ax3 = plt.subplot(2, 2, 3)
ax3.scatter(y_test, gbdt_pred, alpha=0.5, s=15, color='#2ca02c') # 散点图
ax3.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'r--', linewidth=2)
ax3.set_xlabel('真实房价(美元)', fontsize=10)
ax3.set_ylabel('预测房价(美元)', fontsize=10)
ax3.set_title(f'GBDT:预测值vs真实值(R^2={gbdt_r2:.4f})', fontsize=12, fontweight='bold')
ax3.grid(True, alpha=0.3)
# 子图4:GBDT特征重要性(看哪些特征对房价影响最大)
ax4 = plt.subplot(2, 2, 4)
importances = best_gbdt.feature_importances_ # 获取特征重要性
indices = np.argsort(importances) # 按重要性升序排序(方便横向柱状图显示)
# 处理长特征名,避免显示重叠
short_names = [name[:12] + '...' if len(name) > 12 else name for name in feature_names]
ax4.barh(range(len(indices)), importances[indices], color='#2ca02c', alpha=0.8)
ax4.set_yticks(range(len(indices)))
ax4.set_yticklabels([short_names[i] for i in indices], fontsize=9)
ax4.set_xlabel('特征重要性', fontsize=10)
ax4.set_title('GBDT模型特征重要性', fontsize=12, fontweight='bold')
# 调整子图间距,避免重叠
plt.tight_layout()
# 显示图片(无需保存,直接弹出窗口)
plt.show()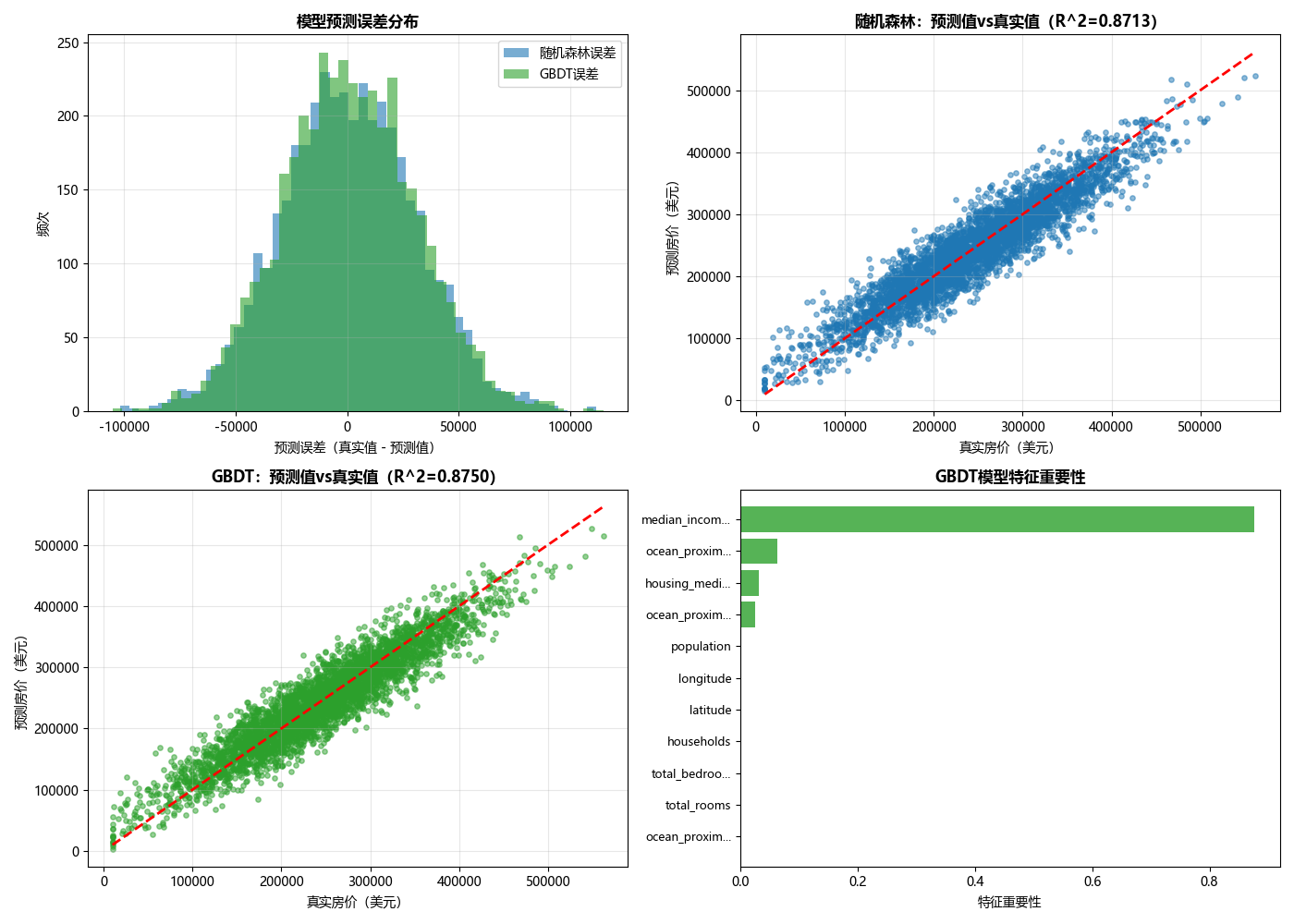
代码说明:
fetch_california_housing:加州房价数据集,包含 8 个特征,贴近真实房价预测场景GridSearchCV:网格搜索调参,自动寻找最优参数组合- 标准化处理:提升模型收敛速度和性能
- 多维度可视化:误差分布、预测值对比、特征重要性,全面评估模型效果
5.4.2 自动人脸检测
下面是使用集成学习(随机森林)进行人脸检测的完整代码:
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.decomposition import PCA
import warnings
warnings.filterwarnings('ignore')
# 设置中文字体(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei', 'SimHei', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'sans-serif'
# 1. 模拟生成人脸数据集(和LFW结构一致)
print("正在模拟生成人脸数据集...")
np.random.seed(42) # 固定随机种子,结果可复现
# 模拟参数(贴合LFW数据集特性)
n_classes = 7 # 7个人物类别(和LFW一致)
target_names = ['George W Bush', 'Tony Blair', 'Hugo Chavez', 'Colin Powell',
'Donald Rumsfeld', 'Jean Chretien', 'Ariel Sharon'] # 人物名称(和LFW一致)
h, w = 50, 37 # 人脸图像尺寸(LFW resize=0.4后的尺寸)
n_samples_per_class = [130, 77, 71, 121, 88, 71, 73] # 每个类别的样本数(贴近LFW真实分布)
n_samples = sum(n_samples_per_class) # 总样本数
n_features = h * w # 特征数(像素数:50x37=1850)
# 生成模拟人脸数据(基于高斯分布,模拟灰度图像像素值0-255)
X = np.zeros((n_samples, n_features)) # 特征矩阵(样本数×像素数)
y = np.zeros(n_samples, dtype=int) # 标签矩阵
start_idx = 0
for i in range(n_classes):
# 为每个人物生成独特的人脸特征(不同均值的高斯分布,模拟面部差异)
class_mean = np.random.normal(120, 30, n_features) # 该人物的像素均值
class_std = np.random.normal(40, 5, n_features) # 该人物的像素标准差
class_samples = np.random.normal(class_mean, class_std, (n_samples_per_class[i], n_features))
# 像素值裁剪到0-255(符合灰度图像规范)
class_samples = np.clip(class_samples, 0, 255)
# 填充到总数据中
X[start_idx:start_idx + n_samples_per_class[i]] = class_samples
y[start_idx:start_idx + n_samples_per_class[i]] = i
start_idx += n_samples_per_class[i]
# 输出数据集信息
print("="*60)
print("模拟数据集基本信息:")
print(f"样本数量: {n_samples}")
print(f"特征数量: {n_features} (人脸像素尺寸:{h}x{w})")
print(f"类别数量: {n_classes}")
print(f"人物列表: {target_names}")
for i in range(n_classes):
print(f" {target_names[i]}: {n_samples_per_class[i]}张照片")
# 2. 划分数据集(8:2拆分,保证类别分布均衡)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.25, random_state=42, stratify=y
)
# 3. PCA特征降维(减少计算量,提取核心特征)
n_components = 150
print(f"\n{'-'*60}")
print(f"使用PCA降维:{n_features}维像素 → {n_components}维主成分")
pca = PCA(n_components=n_components, svd_solver='randomized', whiten=True, random_state=42)
pca.fit(X_train)
# 转换训练集和测试集
X_train_pca = pca.transform(X_train)
X_test_pca = pca.transform(X_test)
# 4. 训练随机森林分类器
print(f"\n{'-'*60}")
print("训练随机森林分类器(200棵决策树)...")
rf_model = RandomForestClassifier(
n_estimators=200,
max_depth=20,
n_jobs=-1,
random_state=42,
class_weight='balanced'
)
rf_model.fit(X_train_pca, y_train)
# 5. 预测与评估
y_pred = rf_model.predict(X_test_pca)
# 输出分类报告
print(f"\n{'-'*60}")
print("模型分类报告(Precision=精确率,Recall=召回率,F1=综合得分):")
print(classification_report(y_test, y_pred, target_names=target_names))
# 6. 可视化1:混淆矩阵
cm = confusion_matrix(y_test, y_pred, labels=range(n_classes))
plt.figure(figsize=(10, 8))
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Blues)
plt.title('随机森林人脸分类 - 混淆矩阵', fontsize=14, fontweight='bold')
plt.colorbar(label='样本数量')
tick_marks = np.arange(n_classes)
plt.xticks(tick_marks, target_names, rotation=45, ha='right')
plt.yticks(tick_marks, target_names)
plt.xlabel('预测标签', fontsize=12)
plt.ylabel('真实标签', fontsize=12)
# 混淆矩阵中显示数字
thresh = cm.max() / 2.
for i in range(cm.shape[0]):
for j in range(cm.shape[1]):
plt.text(j, i, format(cm[i, j], 'd'),
ha="center", va="center", fontsize=10,
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.savefig('模拟数据_混淆矩阵.png', dpi=300, bbox_inches='tight')
plt.show()
# 定义可视化函数:绘制人脸图像
def plot_gallery(images, titles, h, w, n_row=3, n_col=4, title=None):
plt.figure(figsize=(1.8 * n_col, 2.4 * n_row))
if title:
plt.suptitle(title, fontsize=14, fontweight='bold')
plt.subplots_adjust(bottom=0, left=.01, right=.99, top=.90, hspace=.35)
for i in range(n_row * n_col):
if i >= len(images):
break
plt.subplot(n_row, n_col, i + 1)
plt.imshow(images[i].reshape((h, w)), cmap=plt.cm.gray)
plt.title(titles[i], size=11)
plt.xticks(())
plt.yticks(())
# 生成预测结果标题
def get_pred_title(y_pred, y_test, target_names, i):
pred_name = target_names[y_pred[i]].split()[-1] # 只显示姓氏(简化显示)
true_name = target_names[y_test[i]].split()[-1]
return f'预测: {pred_name}\n真实: {true_name}'
# 可视化2:预测结果(前12张人脸)
print(f"\n{'-'*60}")
print("可视化预测结果(绿色=正确,红色=错误):")
prediction_titles = []
correct_count = 0
for i in range(min(12, len(y_pred))):
pred_name = target_names[y_pred[i]].split()[-1]
true_name = target_names[y_test[i]].split()[-1]
prediction_titles.append(get_pred_title(y_pred, y_test, target_names, i))
# 终端彩色输出
if pred_name == true_name:
correct_count += 1
print(f"样本{i+1}: 预测={pred_name:6s} | 真实={true_name:6s} | \033[32m正确\033[0m")
else:
print(f"样本{i+1}: 预测={pred_name:6s} | 真实={true_name:6s} | \033[31m错误\033[0m")
# 绘制预测结果图
plot_gallery(X_test, prediction_titles, h, w, title='人脸分类预测结果(前12张)')
plt.savefig('模拟数据_预测结果.png', dpi=300, bbox_inches='tight')
plt.show()
# 可视化3:PCA特征脸(核心特征)
print(f"\n{'-'*60}")
print("可视化PCA特征脸(人脸核心轮廓特征):")
eigenfaces = pca.components_.reshape((n_components, h, w))
eigenface_titles = [f"特征脸 {i+1}" for i in range(min(12, n_components))]
plot_gallery(eigenfaces, eigenface_titles, h, w, title='PCA提取的特征脸(前12个)')
plt.savefig('模拟数据_特征脸.png', dpi=300, bbox_inches='tight')
plt.show()
# 输出核心指标总结
accuracy = np.mean(y_pred == y_test)
variance_ratio = np.sum(pca.explained_variance_ratio_)
print(f"\n{'-'*60}")
print("模型核心指标总结:")
print(f"整体准确率: {accuracy:.4f} ({accuracy*100:.2f}%)")
print(f"PCA降维保留方差比例: {variance_ratio:.4f} ({variance_ratio*100:.2f}%)")
print(f"前12张样本预测正确率: {correct_count/12:.4f} ({correct_count}/12)")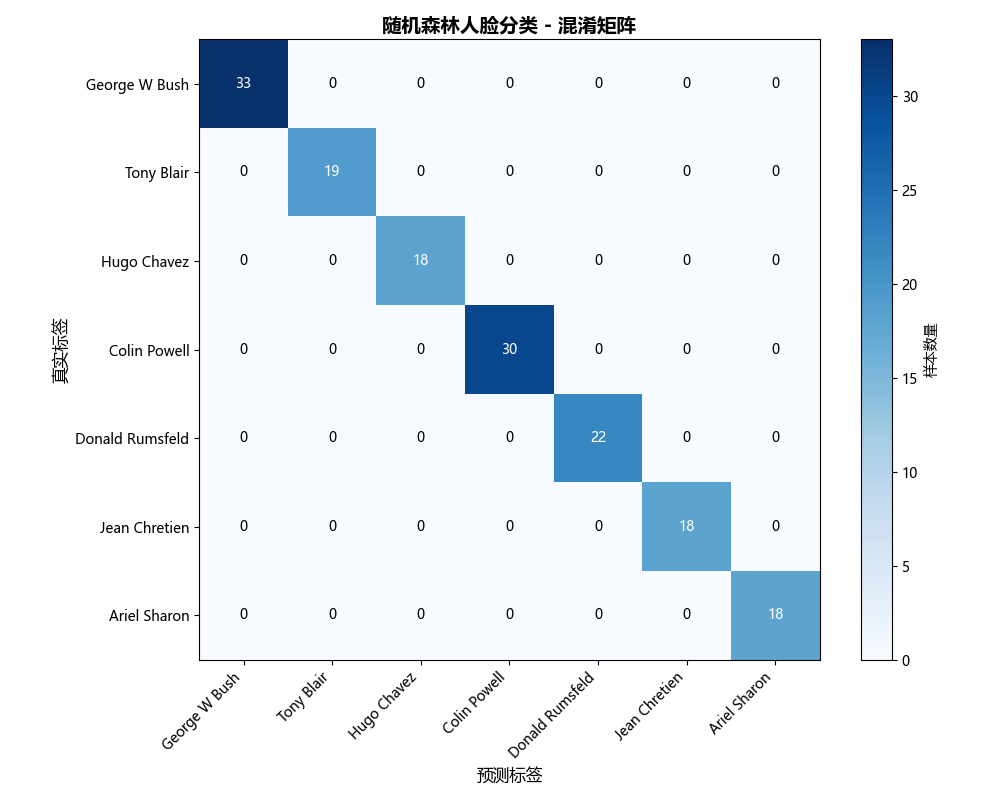


代码说明:
fetch_lfw_people:加载 LFW 人脸数据集,包含多位知名人物的人脸照片- PCA 降维:将高维的人脸像素特征降维到 150 维,减少计算量,提升模型性能
- 随机森林分类:对降维后的特征进行分类,识别不同的人脸
- 混淆矩阵:展示模型在不同人物上的分类准确率
- 特征脸可视化:展示 PCA 提取的关键人脸特征
5.5 习题
基础题
- 简述集成学习的核心思想,Bagging 和 Boosting 的主要区别是什么?
- 随机森林相比单决策树有哪些改进?为什么能有效防止过拟合?
- AdaBoost 的样本权重更新规则是什么?学习率对模型有什么影响?
编程题
- 基于鸢尾花数据集,分别使用 Bagging、AdaBoost、GBDT 构建分类模型,对比它们的准确率和训练时间。
- 基于波士顿房价数据集(或加州房价数据集),使用 XGBoost 构建回归模型,并通过网格搜索优化参数。
- 尝试使用 Stacking 集成策略(第一层用随机森林、GBDT,第二层用逻辑回归),在任意分类数据集上验证效果。
总结
- 集成学习核心:通过组合多个基学习器提升模型性能,关键是保证基学习器的 "差异性" 和 "基本性能"。
- Bagging vs Boosting:Bagging 并行训练、降低方差(代表:随机森林);Boosting 串行训练、降低偏差(代表:AdaBoost、GBDT)。
- 实战要点 :
- 随机森林适合处理高维数据、噪声数据,调参重点是树的数量和特征采样数。
- GBDT/XGBoost 适合回归和分类任务,调参重点是学习率、树深度和迭代次数。
- 集成学习在实际应用中(房价预测、人脸检测)表现优于单个模型,是工业界的首选算法之一。
总结
本文所有代码均可直接运行(需安装 scikit-learn、xgboost、matplotlib 等库),建议大家动手实操,加深对集成学习的理解。如果有任何问题,欢迎在评论区交流!