什么是词向量
在自然语言处理(Natural Language Processing,NLP)任务中,文本是最基础也是最核心的数据形式。然而,计算机并不能像人类一样直接理解文字的含义,它只能对数字进行计算和建模。因此,如何将文本信息转化为数值形式,成为机器学习处理文本数据的首要问题。
词向量(Word Embedding)正是在这一背景下提出的一种重要表示方法
主流词向量模型
一、词袋模型
词袋模型(Bag of Words)是最早也是最基础的文本向量化方法之一。该方法将文本看作词语的集合,仅统计每个词在文档中出现的次数,而不考虑词语的顺序和语义关系。在词袋模型中,每个文档可以表示为一个高维向量,向量的每一维对应词表中的一个词,其取值表示该词在文档中的出现频率。
词袋模型实现简单、计算效率高,但其缺点也较为明显:一方面向量维度较高且稀疏,另一方面无法刻画词语之间的语义相似性,因此在复杂语义任务中的表现有限。
Python 示例代码:
python
from sklearn.feature_extraction.text import CountVectorizer
texts = [
"这家餐厅的菜很好吃",
"服务态度非常好",
"这家店的菜太难吃了"
]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(texts)
print("词表:", vectorizer.get_feature_names_out())
print("向量表示:\n", X.toarray())二、TF-IDF 模型
TF-IDF(Term Frequency--Inverse Document Frequency)是一种在词袋模型基础上引入权重机制的文本表示方法。其核心思想是:一个词在当前文档中出现得越频繁,同时在整个语料库中出现得越少,则该词对文档的区分能力越强。
与传统词频统计相比,TF-IDF 能有效降低"的、了、是"等高频但区分度较低词语的权重,从而突出文本中的关键词信息。因此,TF-IDF 被广泛应用于文本分类、信息检索和情感分析等任务中。
Python 示例代码:
python
from sklearn.feature_extraction.text import TfidfVectorizer
texts = [
"这家餐厅的菜很好吃",
"服务态度非常好",
"这家店的菜太难吃了"
]
tfidf = TfidfVectorizer()
X = tfidf.fit_transform(texts)
print("词表:", tfidf.get_feature_names_out())
print("TF-IDF 向量:\n", X.toarray())TF-IDF 在保证模型简单性的同时,显著提升了文本特征的区分能力,是传统机器学习情感分析中最常用的向量化方法。
三、Word2Vec
Word2Vec 是一种基于神经网络的词向量模型,其核心思想是通过上下文信息学习词语的语义表示。与传统基于词频的表示方法不同,Word2Vec 能够将词语映射为低维、稠密的向量,并使语义相近的词在向量空间中距离更近。
Word2Vec 主要包含两种训练模型:CBOW(通过上下文预测中心词)和 Skip-gram(通过中心词预测上下文)。该模型在捕捉词语语义相似性方面表现突出,是现代自然语言处理的重要基础方法之一。
Python 示例代码(gensim):
python
from gensim.models import Word2Vec
sentences = [
["这家", "餐厅", "的", "菜", "很好吃"],
["服务", "态度", "非常", "好"],
["这家", "店", "的", "菜", "太", "难吃", "了"]
]
model = Word2Vec(
sentences,
vector_size=100,
window=5,
min_count=1,
workers=4
)查看某个词的词向量
python
print(model.wv["好"])计算相似词
python
print(model.wv.most_similar("好"))四、GloVe
GloVe(Global Vectors for Word Representation)是一种结合全局词频统计信息的词向量模型。与 Word2Vec 侧重局部上下文不同,GloVe 利用整个语料库中词与词的共现关系进行建模,从而学习词语的向量表示。
在实际应用中,GloVe 常以预训练词向量的形式使用,能够在多种自然语言处理任务中取得稳定效果。
词向量转化的小例子
下面通过一个简单示例,演示如何使用 CountVectorizer 将文本转化为词袋向量表示。
python
from sklearn.feature_extraction.text import CountVectorizer
texts=["dog cat fish","dog cat cat","fish bird", 'bird']
cont = []
#实例化一个模型
cv = CountVectorizer(max_features=6,ngram_range=(1,3)) #,统计每篇文章中每个词出现的频率次数
#训练此模型
cv_fit=cv.fit_transform(texts)#每个词在这篇文章中出现的次数
print(cv_fit)
# 打印出模型的全部词库
print(cv.get_feature_names())
#打印出每个语句的词向量
print(cv_fit.toarray())
# #打印出所有数据求和结果
# print(cv_fit.toarray().sum(axis=0))#输出结果
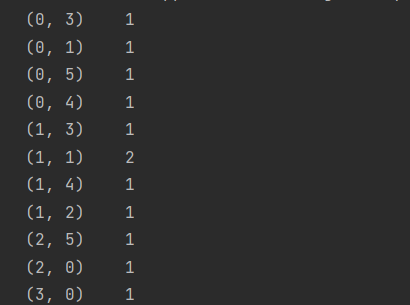
- 示例数据说明
python
texts = ["dog cat fish", "dog cat cat", "fish bird", "bird"]该示例中包含 4 条英文文本,每条文本可以看作一条简单的"评论"或"文档"。
这些文本由少量词语组成,适合用于演示词袋模型的基本原理。
- CountVectorizer 的作用
python
cv = CountVectorizer(max_features=6, ngram_range=(1, 3))CountVectorizer 是 scikit-learn 中用于构建**词袋模型(Bag of Words)**的工具,其核心功能是:
建立词表(Vocabulary)
统计每个词或词组在文档中出现的次数
将文本转换为数值向量
参数说明:
max_features=6
表示只保留词频最高的前 6 个特征(词或词组),用于控制向量维度,防止特征过多。
ngram_range=(1, 3)
表示同时考虑:
1-gram(单词,如 dog)
2-gram(连续两个词,如 dog cat)
3-gram(连续三个词,如 dog cat fish)
这使得模型不仅能捕捉单个词,还能捕捉局部的词序信息。
- 模型训练与文本转换
python
cv_fit = cv.fit_transform(texts)该语句完成了两个步骤:
fit:从所有文本中学习词表(统计词频并筛选特征)
transform:将每条文本转换为词频向量
返回的 cv_fit 是一个稀疏矩阵,用于高效存储高维文本特征。
- 查看稀疏矩阵结果
python
print(cv_fit)输出结果为稀疏矩阵格式,只显示非零元素的位置和值,表示:
行索引:文本编号
列索引:词表中特征的索引
值:该特征在文本中出现的次数
这种表示方式可以节省大量内存,适合大规模文本数据。
- 查看模型词表
python
print(cv.get_feature_names())该语句用于输出模型最终保留的所有特征,即词袋模型的词表。
由于设置了 ngram_range=(1,3),词表中不仅包含单个词,还可能包含多个连续词组成的短语。例如:
单词:dog、cat
二元词组:dog cat
三元词组:dog cat fish
- 查看每条文本的词向量表示
python
print(cv_fit.toarray())该语句将稀疏矩阵转换为普通的二维数组,方便观察。
每一行表示一条文本
每一列对应词表中的一个特征
数值表示该特征在对应文本中出现的次数
例如,如果某一列对应特征 cat,那么数值为 2 表示该文本中 cat 出现了两次。
项目案例
为了训练一个能够自动判断评论情感倾向(好评或差评)的模型,本文选取苏宁易购商品评论数据作为实验数据来源。相关评论数据通过网络爬虫方式获取,并根据情感极性分为优质评价(好评)和差评两类,为后续的文本向量化和模型训练提供数据基础。
1. 数据读取与初步整理
实验中分别使用两个文本文件存储不同情感类别的评论数据,其中:
优质评价.txt:存储正向情感评论(好评)
差评.txt:存储负向情感评论(差评)
使用 Pandas 对文本数据进行读取,代码如下:
python
import pandas as pd
cp_content = pd.read_table(r".\差评.txt",encoding='gbk')
yzpj_content = pd.read_table(r".\优质评价.txt",encoding='gbk')中文评论的分词处理(jieba)
在中文文本处理中,词语之间不存在天然的空格分隔,因此在进行词向量构建之前,必须先对评论文本进行分词操作。本文采用 jieba 分词库对苏宁易购评论数据进行分词处理。
jieba 提供了两种常用分词接口:
jieba.cut():返回生成器,适合大规模数据
jieba.lcut():直接返回列表,使用更加方便
本实验中采用 jieba.lcut() 方法。
差评文本分词
python
import jieba
import pandas as pd
cp_segments = []提取差评文本内容
python
contents = cp_content['content'].values.tolist()对每条评论进行分词
python
for text in contents:
words = jieba.lcut(text)
if len(words) > 1: # 过滤分词结果过短的评论
cp_segments.append(words)将分词结果保存为 DataFrame
python
cp_fc_results = pd.DataFrame({'content': cp_segments})
cp_fc_results.to_excel('cp_fc_results.xlsx', index=False)好评文本分词
python
yzpj_segments = []提取好评文本内容
python
contents = yzpj_content['content'].values.tolist()
for text in contents:
words = jieba.lcut(text)
if len(words) > 1:
yzpj_segments.append(words)保存分词结果
python
yzpj_fc_results = pd.DataFrame({'content': yzpj_segments})
yzpj_fc_results.to_excel('yzpj_fc_results.xlsx', index=False)至此,好评与差评的分词结果已分别存储,为后续文本清洗和特征提取做好准备。
停用词去除
分词完成后,文本中仍然包含大量无实际语义价值的词语,如"的""了""是"等。这类词被称为停用词,若不加处理,会对模型训练产生干扰,因此需要将其移除。
导入停用词表
python
stopwords_df = pd.read_csv(
r'./StopwordsCN.txt',
encoding='utf8',
engine='python'
)
stopwords = stopwords_df['stopword'].values.tolist()定义去停用词函数
python
def remove_stopwords(texts, stopwords):
cleaned_texts = []
for text in texts:
clean_words = [word for word in text if word not in stopwords]
cleaned_texts.append(clean_words)
return cleaned_texts差评去停用词
python
cp_contents = cp_fc_results['content'].values.tolist()
cp_clean = remove_stopwords(cp_contents, stopwords)好评去停用词
python
yzpj_contents = yzpj_fc_results['content'].values.tolist()
yzpj_clean = remove_stopwords(yzpj_contents, stopwords)基于朴素贝叶斯的情感分类模型
构建训练数据集
为实现监督学习,需要为评论数据添加情感标签:
差评:1
好评:0
python
cp_train = pd.DataFrame({
'segments_clean': cp_clean,
'label': 1
})
yzpj_train = pd.DataFrame({
'segments_clean': yzpj_clean,
'label': 0
})
pj_train = pd.concat([cp_train, yzpj_train], axis=0)
pj_train.to_excel('pj_train.xlsx', index=False)划分训练集与测试集
python
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(
pj_train['segments_clean'].values,
pj_train['label'].values,
random_state=0
)文本向量化(CountVectorizer)
由于 CountVectorizer 接受的是字符串形式输入,因此需要先将分词列表重新拼接成字符串。
python
train_texts = [' '.join(words) for words in x_train]
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(
max_features=4000,
lowercase=False,
ngram_range=(1, 3)
)
vectorizer.fit(train_texts)训练朴素贝叶斯模型
python
from sklearn.naive_bayes import MultinomialNB
from sklearn import metrics
classifier = MultinomialNB(alpha=0.1)
classifier.fit(vectorizer.transform(train_texts), y_train)训练集评估
python
train_pred = classifier.predict(vectorizer.transform(train_texts))
print(metrics.classification_report(y_train, train_pred))测试集评估
python
test_texts = [' '.join(words) for words in x_test]
test_pred = classifier.predict(vectorizer.transform(test_texts))
print(metrics.classification_report(y_test, test_pred))模型交互测试
训练完成后,可以通过命令行输入文本,实时测试模型的情感预测效果。
python
while True:
text = input('请输入一段评价(输入 exit 退出):')
if text == 'exit':
break
words = jieba.lcut(text)
words_clean = [w for w in words if w not in stopwords]
text_vec = vectorizer.transform([' '.join(words_clean)])
result = classifier.predict(text_vec)
if result[0] == 1:
print("预测结果:差评")
else:
print("预测结果:优质评价")