前言:
在移动端视觉任务中,轻量化卷积神经网络(CNNs)一直占据主导地位,其空间归纳偏置使其能以较少参数学习有效表征。但 CNN 的局限性也十分明显 ------ 仅能进行局部特征处理,难以捕捉全局依赖关系。而以自注意力为核心的视觉 Transformer(ViT)虽能学习全局表征,却存在模型笨重、 latency 高、训练复杂等问题,难以适配移动端资源约束。
2022 年 ICLR 会议上,Apple 团队提出的 MobileViT 给出了破局之道:将 CNN 的局部特征提取能力与 ViT 的全局依赖建模优势相结合,打造出轻量化、通用型、移动端友好的视觉模型。本文将深入解析 MobileViT 的核心设计、技术创新与实测性能,看看它如何成为移动端视觉任务的新标杆。
论文链接 :https://arxiv.org/pdf/2110.02178.pdf
代码链接:https://github.com/apple/ml-cvnets
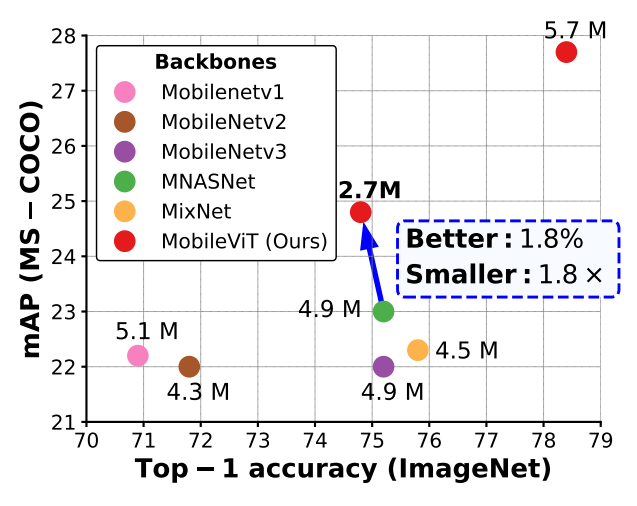
图1:与轻量级卷积神经网络模型相比,MobileVIT 在任务级泛化性能方面表现更优。表中列出了在 MS-COCO 数据集上使用不同特征提取器(MobileNetv1(Howard 等人,2017 年)、MobileNetv2(Sandler 等人,2018 年)、MobileNetv3(Howard 等人,2019 年)、MNASNet(Tan 等人,2019 年)、MixNet(Tan 和 Le,2019b)以及 MobileViT(我们的模型))的 SSDLite 网络的网络参数。
一、核心痛点:为什么需要 MobileViT?
在 MobileViT 出现之前,移动端视觉模型面临着 "二选一" 的困境:
-
轻量化 CNN 的短板:MobileNet 系列、ShuffleNet等模型虽高效,但依赖局部卷积操作,缺乏全局特征建模能力,在复杂视觉任务(如细粒度分类、密集检测)中性能受限。
-
ViT 的移动端适配难题:标准 ViT 需将图像拆分为非重叠 patch,通过多头自注意力学习全局关系,但存在三大问题:
(1)缺乏图像特有的归纳偏置,需更多参数才能达到 CNN 级性能(如 DeIT 在 5-6M 参数下比 MobileNetv3 准确率低 3%);
(2)训练复杂,依赖大量数据增强和 L2 正则化防止过拟合;
(3)推理 latency 高,内存访问效率低,难以在移动设备上实时运行。
此外,现有混合模型(如 ViT-C、CvT)虽尝试融合卷积与 Transformer,但仍存在模型过重、对数据增强敏感等问题。MobileViT 的核心目标就是:在保持轻量化的同时,兼顾局部特征提取与全局依赖建模,且具备简单训练流程和低 latency 特性。
二、核心创新:MobileViT 的三大关键设计
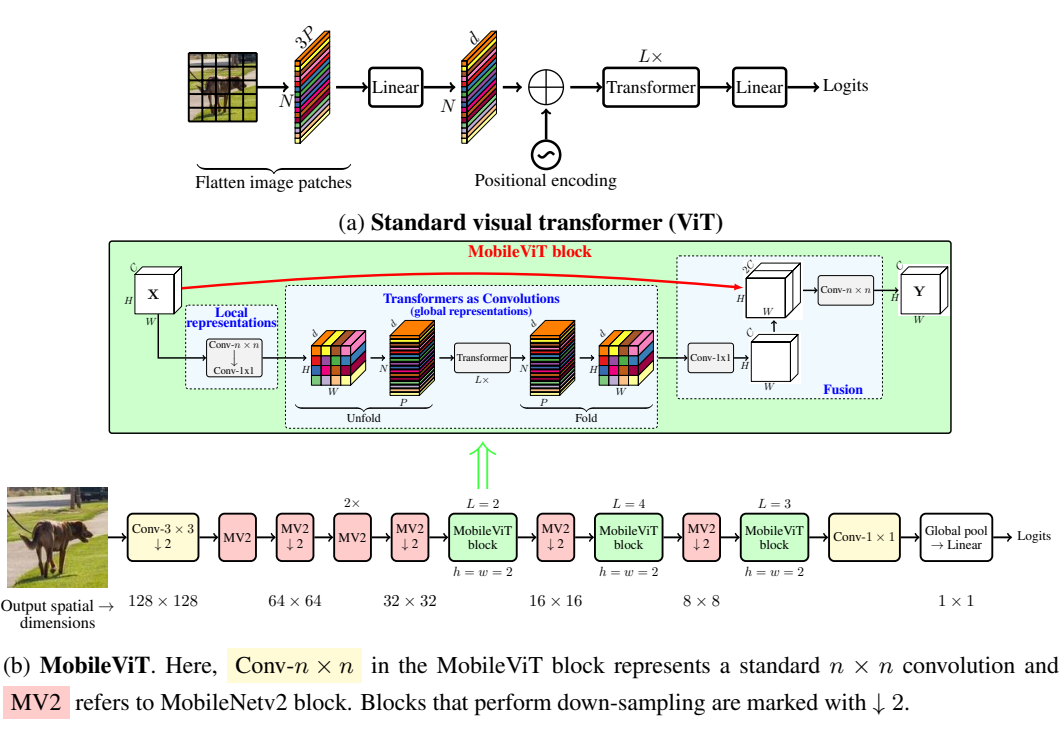
图2:Visual transformers对比MobileViT
2.1. 核心模块:MobileViT Block(Transformer 即卷积)
MobileViT 的灵魂在于其创新的网络块设计,核心思路是将 Transformer 作为 "全局卷积" 来使用,既保留 CNN 的空间归纳偏置,又获得 ViT 的全局建模能力。其流程如下:
- 局部特征提取 :对输入张量先应用 3×3 标准卷积(编码局部空间信息),再通过 1×1 卷积投影到高维空间(维度 d>C),得到局部特征图XLX_LXL;
- 全局特征建模 :将 XLX_LXL 拆分为 N 个非重叠的扁平 patch(尺寸 h×w,且 h,w≤卷积核大小 n),对每个位置的 patch序列应用 Transformer 层,建模跨 patch 的全局依赖,得到全局特征 XGX_GXG;
- 特征融合:将全局特征折叠回原始空间维度,通过 1×1 卷积投影到低维空间,与原始输入通过跳跃连接拼接,最后用 3×3卷积融合局部与全局特征。
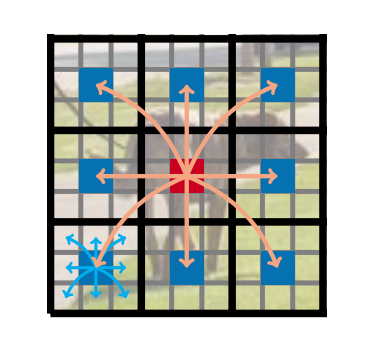
图3:在 MobileViT 块中,每个像素都能看到其他每个像素。在此示例中,红色像素利用转换器关注蓝色像素(即其他图像块中对应位置的像素)。由于蓝色像素已经通过卷积操作编码了关于相邻像素的信息,因此这使得红色像素能够对图像中的所有像素进行编码。在这里,黑色和灰色网格中的每个单元分别代表一个图像块和一个像素。
关键设计亮点:
- 不同于标准 ViT 丢失像素空间顺序,MobileViT 既保留 patch 顺序,又维持每个 patch 内的像素空间关系;
- 有效感受野达到整个图像尺寸(H×W),每个像素能捕捉全局信息(如图 3 所示,红色像素通过 Transformer 关注其他 patch的对应位置,再结合卷积的局部信息);
- 结构上与卷积操作同源(均包含 "展开 - 处理 - 折叠" 三步),天然适配移动端的卷积优化算子。
2.2. 轻量化架构设计
MobileViT 遵循 "浅而窄" 的设计哲学,避免了标准 ViT 的深度堆叠:
- 整体架构:输入层→3×3 步幅卷积→MobileNetv2 的 MV2 块(负责下采样)→MobileViT 块(负责全局建模)→1×1卷积→全局池化→分类头;
- 参数控制 :
(1)Transformer 层仅使用 2-4 层(标准 ViT 需 12 层),隐藏层维度 d 控制在 96-144(标准 ViT为 192);
(2) MV2 块仅用于下采样,采用较小的扩张系数(XXS 版本为 2,XS/S 版本为 4),避免冗余参数;
(3) 激活函数使用Swish,在轻量化模型中平衡性能与计算成本。
2.3. 多尺度采样器:提升训练效率与泛化能力
为解决 ViT 多尺度适配难题,MobileViT 提出动态批次大小的多尺度采样器,核心优势:
- 训练时随机采样不同空间分辨率(如 160×160、256×256、320×320),并根据分辨率动态调整批次大小(分辨率越小,批次越大);
- 无需微调即可学习多尺度表征,避免了标准 ViT 的位置编码插值问题;
- 减少 14% 训练时间,同时提升 0.5% 准确率,泛化 gap 接近零(训练误差与验证误差差异小)。
相比传统固定分辨率训练,该采样器让模型在不同输入尺寸下的鲁棒性显著提升,且对 CNN 模型(如 MobileNetv2)同样有效,证明其通用性。
三、性能实测:MobileViT 到底有多强?
3.1. 图像分类:碾压同量级 CNN 与 ViT
在 ImageNet-1k 数据集上,MobileViT 以更少参数实现更高准确率:
-
与轻量化 CNN 对比(2.3M 参数量):MobileViT-XS 准确率 74.8%,比 MobileNetv2(69.8%)高5%,比 MobileNetv3(67.4%)高 7.4%;
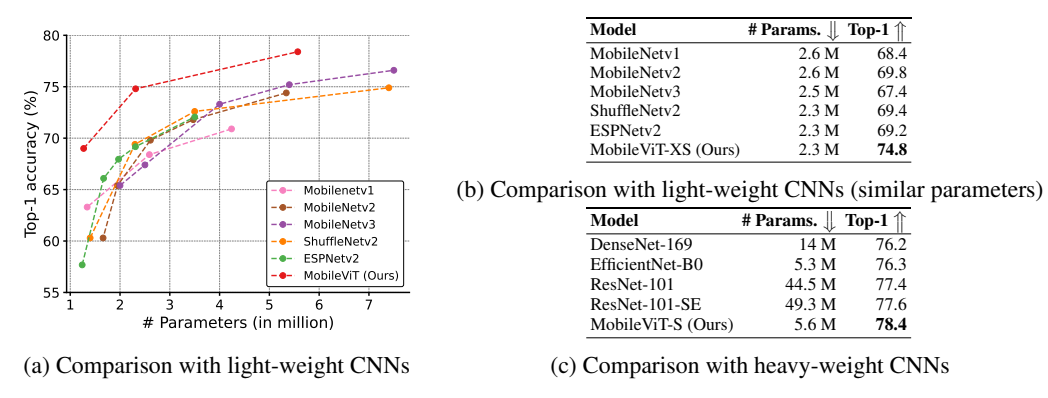
图4:MobileVIT 与 CNNs 在 ImageNet-1k 验证集上的对比。所有模型均使用基础数据增强。
-
与重量级 CNN 对比:5.6M 参数量的 MobileViT-S,准确率超过 14M 参数量的 DenseNet-169(76.2%)和5.3M 参数量的 EfficientNet-B0(76.3%)。
-
与 ViT 变体对比(5.6M 参数量):MobileViT-S 准确率 78.4%,比 DeIT(72.2%)高 6.2%,比PiT(73.0%)高 5.4%;
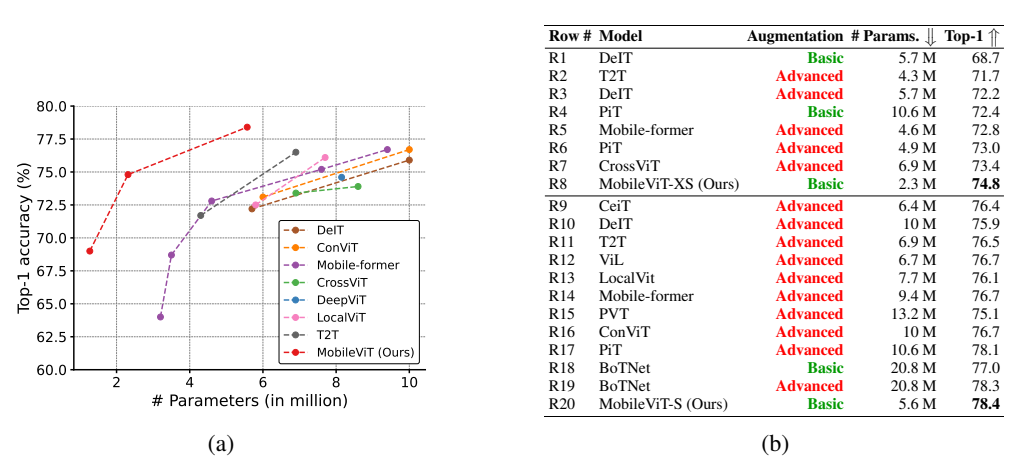
图5:MobileViT 与 ViTs 在 ImageNet-1k 验证集上的对比。这里,基础表示 ResNet 风格的数据增强,而高级表示基础数据增强方法与多种增强方法的组合(例如,MixUp(Zhang 等人,2018 年)、RandAugmentation(Cubuk 等人,2019 年)和 CutMix(Zhong 等人,2020 年))。
关键优势:MobileViT 仅需基础数据增强(随机裁剪 + 水平翻转),无需 MixUp、CutMix 等复杂策略,训练流程简化 50%(300 轮 vs MobileNetv3 的 600 轮)。
3.2. 通用骨干网络:检测与分割任务表现亮眼
MobileViT 不仅适用于分类,更能作为通用骨干网络迁移到下游任务:
-
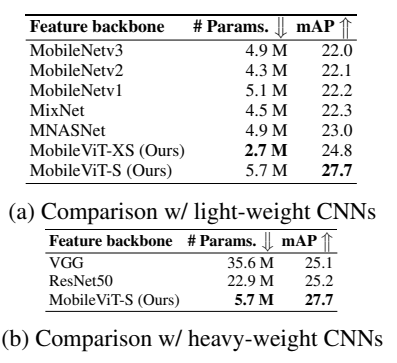
目标检测(MS-COCO):
(1)SSDLite+MobileViT-XS(2.7M 参)mAP 达 24.8%,比 MNASNet 骨干(4.9M 参,23.0%)高 1.8%,模型体积缩小 1.8 倍;
(2)MobileViT-S(5.7M 参)mAP 达 27.7%,超过 VGG16(35.6M 参,25.1%)和 ResNet50(22.9M 参,25.2%)。
-
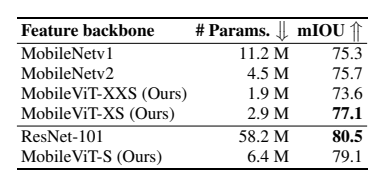
语义分割(PASCAL VOC):
(1)DeepLabv3+MobileViT-XS(2.9M 参)mIOU 达 77.1%,比 MobileNetv2 骨干(4.5M 参,75.7%)高 1.4%;
(2)MobileViT-S(6.4M 参)mIOU 达 79.1%,接近 ResNet-101(58.2M 参,80.5%),参数减少 9 倍。
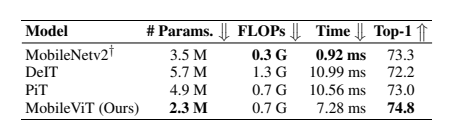
3.3. 移动端 latency:实时性达标
在 iPhone 12 上的实测结果显示,其中,绿色区域内的点表示这些模型能够实时运行,MobileViT 完全满足移动端实时性要求( latency <33ms):
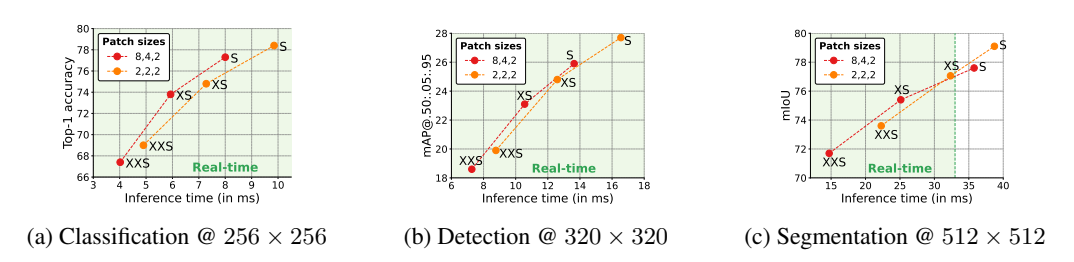
相比同性能 的ViT 模型,MobileViT-XS latency 比 DeIT 低 34%(7.28ms vs 10.99ms),比 PiT 低 31%(7.28ms vs 10.56ms)。虽比 MobileNetv2(0.92ms)略高,但准确率提升 1.5%,且随着移动端 Transformer 优化算子的普及, latency 仍有下降空间。
四、核心启示:MobileViT 的设计哲学
MobileViT 的成功并非偶然,其设计思路对移动端视觉模型极具启发:
- 归纳偏置的平衡:通过 "卷积 + Transformer" 的同源结构,既保留 CNN 的空间归纳偏置(降低训练难度),又引入 ViT的全局建模能力(提升性能上限);
- 效率优先的极简设计:避免过度复杂的模块堆叠,仅通过核心块创新和采样策略优化,在参数、计算量、 latency 间找到最佳平衡点;
- 通用型优于任务专用:不针对特定任务设计,而是通过强表征能力适配分类、检测、分割等多种任务,降低移动端模型开发成本。
五、总结
MobileViT 首次实现了 "轻量化 CNN 的效率 + ViT 的性能" 的完美结合,其核心创新在于将 Transformer 重构为 "全局卷积",让模型同时具备局部特征提取与全局依赖建模能力。实测证明,MobileViT 在图像分类、目标检测、语义分割等任务中均超越同量级 CNN 和 ViT 模型,且训练简单、 latency 低,完全适配移动端资源约束。
随着移动端 AI 算力的提升和 Transformer 优化技术的发展,MobileViT 的设计思路将成为移动端视觉模型的重要方向。目前其源码已开源,开发者可直接用于移动应用开发,或基于其设计哲学进一步优化模型。
对于移动端 AI 从业者而言,MobileViT 的出现意味着:无需在 "性能" 与 "效率" 间妥协,通用型轻量化视觉模型已成为现实。未来,随着多模态任务和边缘计算的普及,这种 "CNN+Transformer" 的混合架构将在更多场景中发挥作用。