一、研究背景
扩散生成模型的发展历程中,核心设计逐渐偏离了"直接预测干净图像"这一经典去噪目标。早期扩散模型虽以去噪为初衷,但后续关键进展(如ε-预测、v-预测)转向了预测噪声或含噪量,这类预测目标需在高维空间中保留全部噪声信息,导致模型对网络容量要求极高,且严重依赖预训练 latent 空间、额外损失函数等辅助组件,难以实现自包含的建模框架。
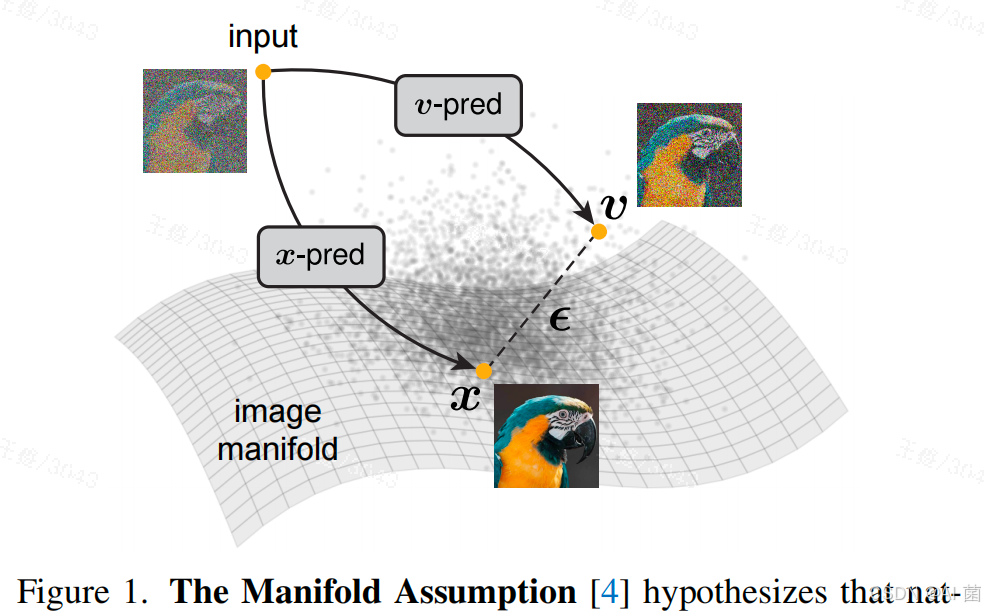
同时,机器学习领域的流形假设指出,自然数据(如图像)本质上分布在低维流形上,而噪声和含噪量(如流速v)则分布于整个高维空间。现有扩散模型在像素级等高维空间建模时,常受维度灾难困扰,需通过密集卷积、小补丁分割、额外跳跃连接等复杂设计缓解问题,却牺牲了模型的简洁性和通用性。因此,回归"直接预测干净数据"的核心思路,构建简洁、自包含的高维数据生成模型成为研究痛点。
二、核心工作
提出一种名为"Just Image Transformers(JiT)"的生成模型,核心是让神经网络直接预测干净图像(x-预测),而非噪声或含噪量。该模型基于纯视觉Transformer(ViT)架构,无需预训练、无额外损失函数、无tokenizer等辅助组件,通过大尺寸图像补丁(16×16、32×32等)直接处理像素数据,实现高维空间(256×256、512×512甚至1024×1024分辨率)的高效生成。
核心创新在于验证了:在流形假设下,低容量网络可通过聚焦低维流形上的干净数据信息,过滤高维噪声,从而在高维像素空间中超越传统ε-预测、v-预测模型的性能,打破"高维建模需高容量网络"的固有认知。
三、研究方法
1. 预测目标选择
明确采用x-预测(直接输出干净图像),并基于流-扩散统一框架推导了x-预测与ε-预测、v-预测的数学关联:通过噪声调度公式(z_t = tx + (1-t)\epsilon)和流速定义(v = x - \epsilon),可由x-预测结果间接推导得到ε和v,确保模型兼容扩散模型的ODE采样流程。
2. 模型架构设计
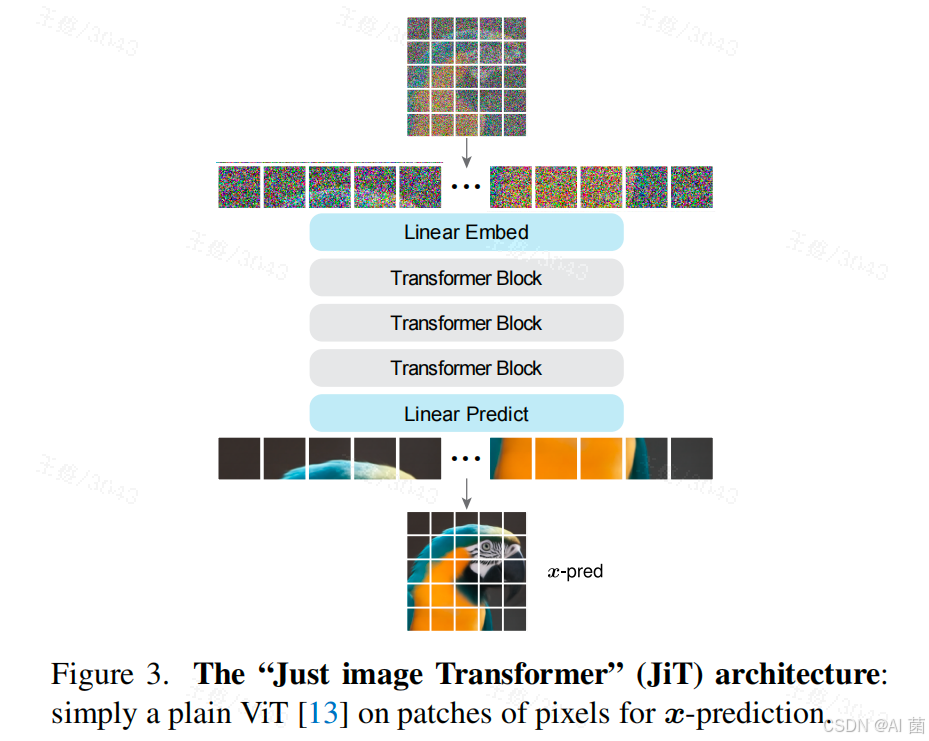
- 基础架构:遵循"Transformer on Patches"理念,将图像分割为非重叠大补丁(如256×256图像用16×16补丁,512×512图像用32×32补丁),经线性嵌入、位置编码后输入Transformer块,最终通过线性层输出重构补丁。
- 优化增强:融入通用Transformer改进组件(SwiGLU激活、RMSNorm归一化、RoPE位置编码等),采用adaLN-Zero实现时间和类别条件建模,部分模型引入瓶颈嵌入层(降低补丁维度)提升性能。
- 损失函数:采用v-损失作为优化目标,通过(v_\theta = (x_\theta - z_t)/(1-t))将x-预测结果转换为流速预测值,避免直接优化x-损失的权重失衡问题。
3. 训练与采样流程
- 训练:采用logit-正态分布采样时间步t,生成含噪样本(z_t),模型输出干净图像预测值(x_\theta),通过转换公式计算(v_\theta)并与真实流速v计算L2损失。
- 采样:基于Heun数值解法求解ODE方程(dz_t/dt = v_\theta(z_t, t)),从纯噪声(z_0)迭代到t=1得到干净图像,支持50步高效采样。
四、实验设计
1. 数据集与评估指标
- 数据集:ImageNet(1000类),测试分辨率涵盖64×64、256×256、512×512、1024×1024。
- 评估指标:主要采用FID-50K(生成图像与真实数据的分布相似度),辅助使用Inception Score(IS)、精度-召回率(Precision-Recall)。
2. 实验变量设置
- 模型变量:补丁大小(4×4、16×16、32×32、64×64)、网络规模(B/L/H/G四档,对应不同深度和隐藏维度)、瓶颈嵌入维度(16~1024)、噪声调度参数(μ值调整噪声水平)。
- 对比变量:预测目标(x-预测、ε-预测、v-预测)、损失函数(x-损失、ε-损失、v-损失)、是否使用预训练/额外损失/预处理器。
3. 对照实验设计
- 核心对比:相同架构下x-预测与ε-预测、v-预测在不同分辨率和补丁维度下的性能差异。
- 消融实验:噪声水平调整、瓶颈维度影响、网络容量缩放、额外损失(如分类损失)的作用。
- 扩展性实验:跨分辨率生成(256×256与512×512模型互转)、与现有SOTA模型(如DiT、SiD2、PixNerd)的算力-性能对比。

五、实验分析
1. 核心假设验证
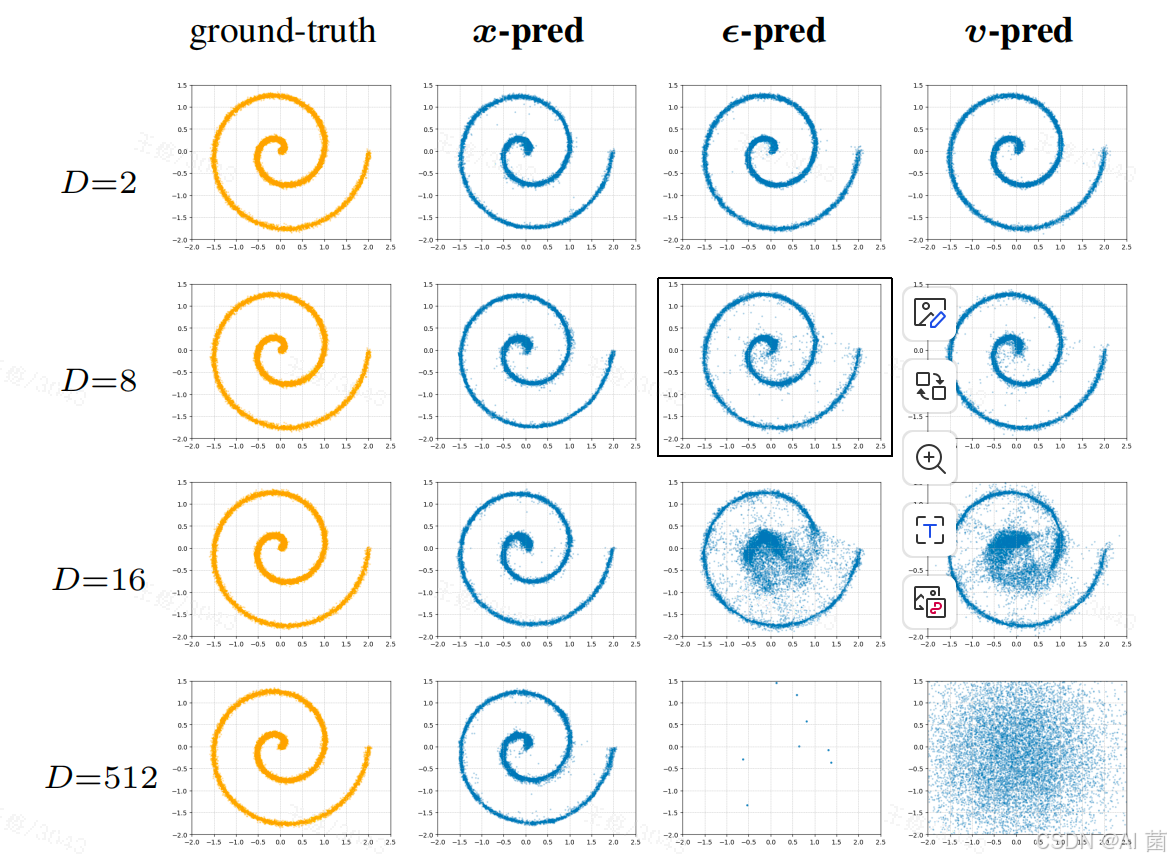
玩具实验(低维流形嵌入高维空间)表明,当观测维度D(如512)远大于数据固有维度d(如2)时,仅x-预测能稳定生成合理结果,而ε-预测、v-预测会因无法处理高维噪声信息而彻底失效,验证了流形假设下x-预测的本质优势。
2. 关键参数影响
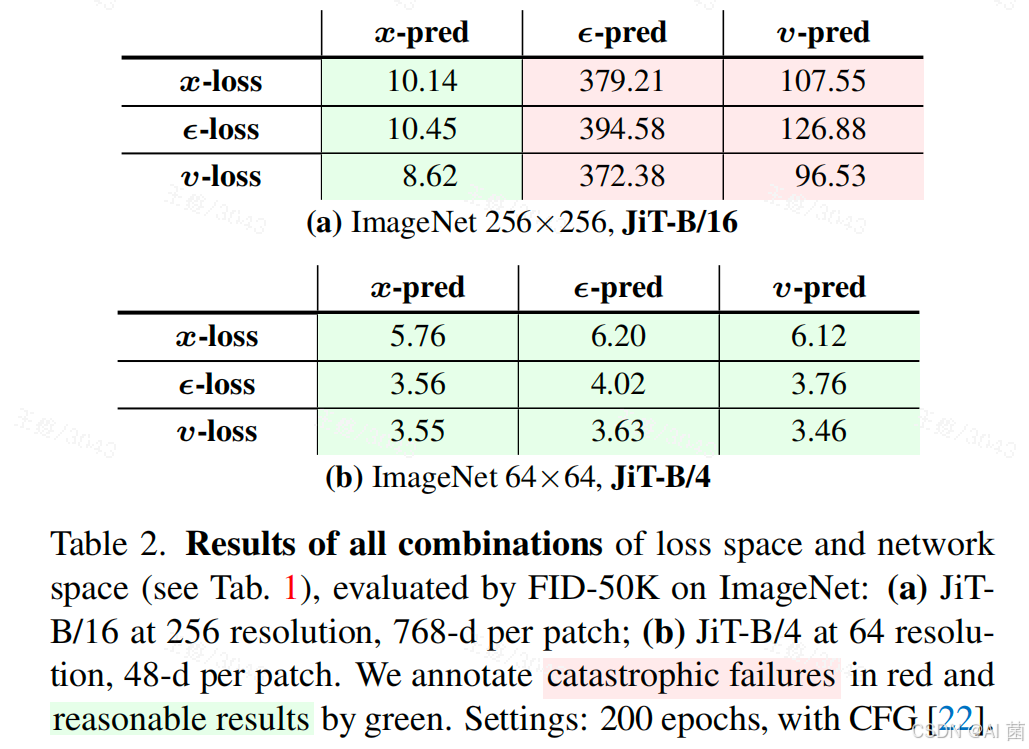
- 预测目标:在256×256分辨率(768维/补丁)下,x-预测的FID仅为8.62,而ε-预测、v-预测的FID均超过370,灾难性失效;低分辨率(64×64,48维/补丁)下三者差异缩小,证明高维场景中x-预测的必要性。
- 瓶颈嵌入:瓶颈维度在32~512范围内可提升性能(FID降低约1.3),即使瓶颈维度低至16,模型仍能保持合理性能,说明低维流形信息可通过瓶颈结构有效保留。
- 噪声水平:适当提高噪声水平(μ=-0.8)对x-预测有益,但无法挽救ε-预测、v-预测的失效问题。
3. 性能与扩展性
- 高分辨率生成:JiT-B/32在512×512分辨率下FID为4.64,JiT-B/64在1024×1024分辨率下FID为4.82,且模型参数和算力与低分辨率版本相当,突破高维建模的算力瓶颈。
- 模型缩放:随着网络规模从B扩大到G,256×256分辨率下FID从4.37降至1.82,512×512分辨率下从4.64降至1.78,显示出良好的缩放性。
- 对比SOTA:与现有像素级扩散模型(如ADM-G、SiD2)相比,JiT以更低算力(25Gflops vs 1120Gflops)实现相当或更优性能,且无需预训练组件,简洁性显著提升。
4. 辅助实验结论
- 预处理器:EDM风格的预处理器无法改善高维场景性能,甚至导致灾难性失效,证明偏离x-预测的设计不可行。
- 额外损失:添加分类损失可使FID小幅下降(如JiT-L/16从2.79降至2.50),但论文为保持极简设计未采用。
- 跨分辨率能力:512×512模型下采样至256×256的FID(1.84)接近原生256×256模型(1.82),但256×256模型上采样至512×512性能退化明显,说明高分辨率建模需匹配对应补丁尺寸。
六、总结
论文回归扩散模型"去噪"本质,基于流形假设提出JiT模型,通过直接预测干净图像(x-预测)和纯Transformer架构,实现了高维像素空间的简洁、自包含生成。核心贡献在于:
1)验证了x-预测在高维建模中的本质优势,打破传统ε-预测、v-预测的主导地位;
2)提出无需预训练、无额外损失的极简架构,兼容大尺寸补丁和高分辨率生成 ;
3)证明低容量网络可通过聚焦低维流形信息应对维度灾难,为跨领域(如蛋白质、分子、气象数据)高维自然数据建模提供通用框架。
未来方向可进一步探索额外损失函数与JiT的结合,以及在更多高维非图像领域的扩展应用,持续推进"Diffusion + Transformer"范式的通用性和性能边界。