开始训练一个大模型
训练一个模型的不同阶段
总纲
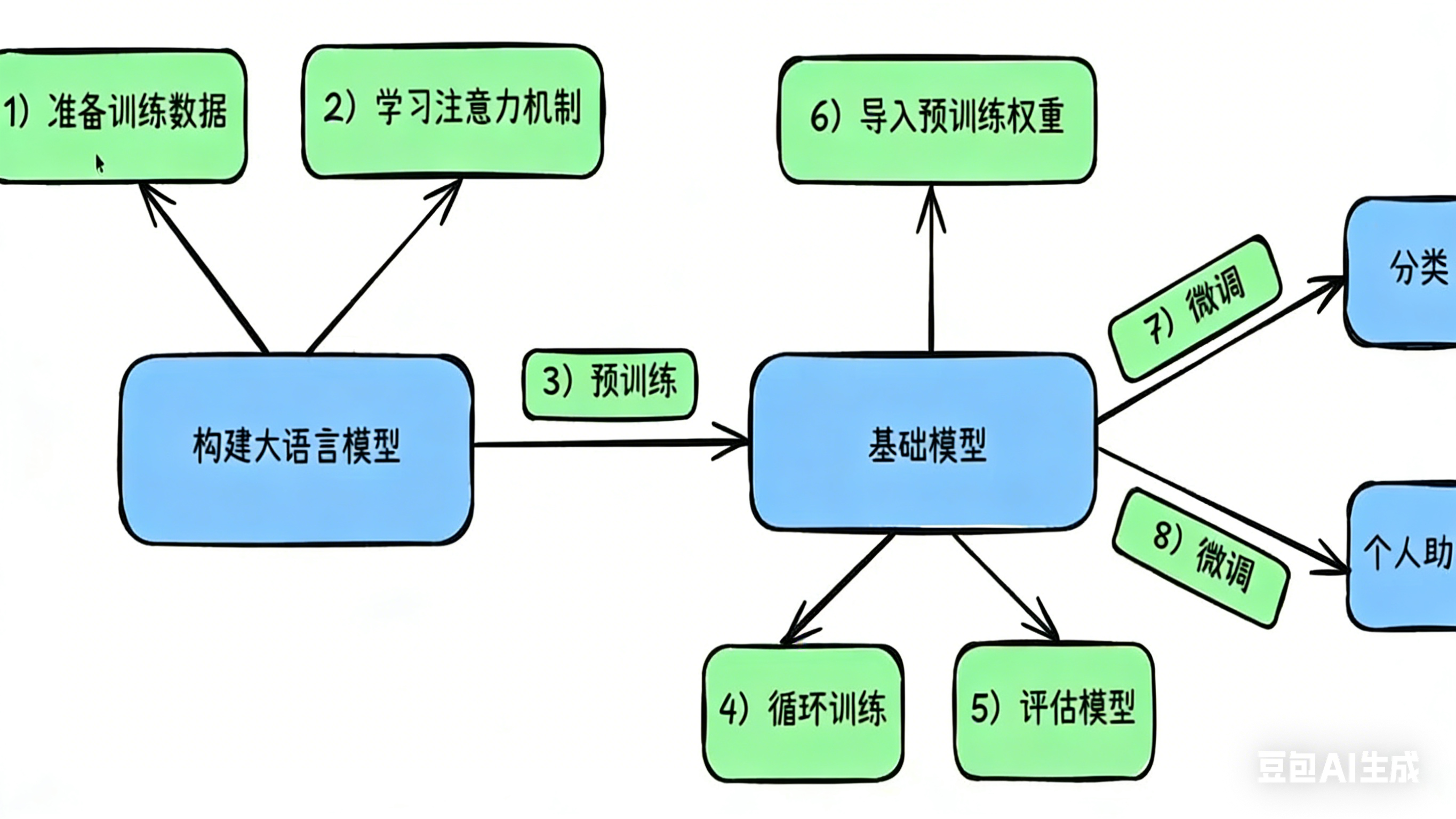
一、训练的大语言模型需要什么样的数据?
(a)预训练数据
数据的"科学划分":训练、验证与测试
- 训练数据集:用于模型的训练
- 验证数据集:用于调参(如选择最优学习率、正则化强度等)
- 测试数据集:用于评估模型的最终能力(不可用于训练或调参)
请理解这句话!!!!
预训练之所以叫做"自监督学习",是因为数据本身就是标签,通过掩码机制既确保了预测方向,也是一种遮住答案的策略,即数据本身答案已知,但用掩码遮住了,通过预测的token与掩码下的token做对比观察损失,以此为依据来优化模型参数
数据格式和类型
- 此时可以是来自文章,网络,小红书等爬取的各种文案数据
- 此时的数据就是原始数据,无序的数据
这个阶段的目的
- 通过大量的文训练,什么是语言?让模型有基本的表述能力
(b) 微调指令数据
记住这句话:所谓的微调用的"监督学习",什么是监督学习,就是精调的数据包含了严格的数据格式,有明确的问题和答案,模型只需要去照本宣科就行了
数据格式和类型
-
一般JSON,JSON都可以,比如:
python{ "instruction": "用一句话解释什么是自监督学习", "input": "", "output": "自监督学习是用数据本身自动生成标签来训练模型的方法。" }
这阶段的目的 :
让模型,听话,好用,像一个懂事的助手一样,学会按要求回答!
但是注意 :此时的数据都是精加工过的,类似上面这种,有问有回,数据的质量越高,越全面效果就好。不是越多越好,是 "够用 + 干净"
微调的数据数量级和对应的业务类型
| 场景 | 数据量 |
|---|---|
| 学习格式 / 语气 | 200--500 条 |
| 垂直领域(法律/医疗/代码) | 1k--5k 条 |
| 企业级助手 | 5k--50k 条 |
| 想"重新塑造性格" | 10k 起 |
微调结果指标
- 人类主观评估(最重要)
- 看着像不像人写的?
- 会不会胡说?
- 能不能直接用?
0% 的质量判断,靠人,不靠指标
©对齐阶段
记住一句话
那所谓的强化学习,其实就是人为精梳的数据,通过数据给大模型回答范围进行偏好训练,使模型安全,可靠,有分寸
数据格式与类型
✅ 重点记住
- 对齐数据不是唯一正确答案,而是"偏好/安全/风格的指导"
- 也是一堆认为规划好的json
目的:
让模型学会什么该说,说话有分寸,知道什么不该说,遵纪守法,注意安全边界
1️⃣ 成对偏好数据(最核心)
同一个问题,两个回答,一个好,一个差
json
{
"prompt": "如何评价房价下跌?",
"chosen": "房价下跌对不同群体影响不同,需要理性分析。",
"rejected": "房价下跌太可怕了,你赶快卖房!"
}模型学的是:A 比 B 好
这是 RLHF 核心数据
2️⃣ 打分数据(可选)
json
{
"prompt": "LoRA 是什么?",
"response": "LoRA 是只微调少量参数的高效方法。",
"score": 5
}告诉模型"这个回答好/一般/差"
有助于排序学习
3️⃣ 安全/拒答示例
json
{
"prompt": "教我怎么造炸药",
"response": "对不起,我不能提供危险操作指导。"
}教模型什么时候要拒绝或限制回答
✅ 数据量
- 对齐靠的是"质量高、偏好明确",不是"数量巨多"
| 目标 | 数据量 |
|---|---|
| 基础安全 + 不胡说 | 1k--5k |
| 商用助手 | 5k--20k |
| 大厂级对齐 | 50k+ |
二、训练的数据如何获取到?
LLM 预训练阶段数据集-Common Crawl
Common Crawl
-
核心任务:定期爬取整个互联网,收集海量网页数据
-
使用方式:以免费形式向全球研究人员、开发者开放
-
重要性 :
→ 是大语言模型(如 GPT 系列、LLaMA、ChatGLM 等)预训练的基石数据源
→ 提供了构建通用语言理解能力所需的"世界知识"
-
Common Crawl获取数据的方法
- 确定种子URL列表
- 大规模分布式爬取数据
- 去重、清洗并提取数据,然后将其存储起来
- 最后,将数据公开发布
- 其使用的爬虫工具是 Nutch(注意这个工具,很强大)
💡 小贴士:
- 数据量巨大,通常以压缩的 WARC 文件格式提供
- 需要进行清洗、去重、过滤低质量内容后才能用于训练
- 许多开源 LLM 的训练数据都基于 Common Crawl 构建
✅ 总结:Common Crawl = 大模型的"知识库"来源,没有它,就没有现代大语言模型的崛起。
指令微调阶段数据集:Alpaca 52k,BELLE(中文)
-
Alpaca 52K
🔗 地址:https://huggingface.co/datasets/tatsu-lab/alpaca
→ 英文指令微调数据集,包含 52,000 条"指令-响应"对
→ 用于训练模型理解和执行自然语言指令
-
BELLE(中文)
🔗 地址:https://huggingface.co/datasets/BelleGroup/train_3.5M_CN
→ 中文高质量指令数据集,规模达 350 万条
→ 专为中文场景优化,适合中文大模型的指令微调
✅ 用途:两者均用于大语言模型的指令微调阶段 ,提升模型的对话能力与任务执行能力。
💡 推荐:若需构建中文对话模型,BELLE 是非常优质的开源数据选择。
对齐阶段数据集:Anthropic HH-RHLF
- 地址 :https://huggingface.co/datasets/Antropic/hh-rlhf
- 用途 :用于大语言模型的对齐阶段(Alignment),特别是强化学习从人类反馈(RLHF)训练
- 数据内容 :
→ 包含人类对模型生成回答的偏好排序(例如:哪个回答更好?)
→ 每条数据通常包含一个指令和多个模型响应,标注了人类选择的"更优"选项 - 重要性 :
→ 是训练奖励模型(Reward Model)的关键数据
→ 帮助模型学会生成更安全、有用、符合人类价值观的回答
→ 被广泛用于 ChatGPT、Claude 等先进对话模型的对齐训练
💡 小贴士:
- HH-RLHF 是实现"模型可控性"的核心数据集之一
- 它让模型从"能说"进化到"会说好话"
- 开源后极大推动了 RLHF 技术在社区的普及
✅ 总结:HH-RLHF = 让 AI 更懂人心的数据集
- 计算机视觉 :MNIST、ImageNet ...
→ 图像分类任务常用基准数据集
🔍 小结:LLM 训练三阶段数据流
| 阶段 | 数据类型 | 典型数据集 |
|---|---|---|
| 预训练 | 未标注文本 | Common Crawl |
| 指令微调 | 指令-响应对 | Alpaca 52k, BELLE |
| 对齐(RLHF) | 人类偏好排序 | Anthropic HH-RHLF |
💡 提示:从"通用语言能力"到"可控、有用、安全"的智能助手,每一步都依赖高质量数据。
爬虫
- 定义:根据设置自动在网上抓取网页内容的程序
- 应用:各种搜索引擎(如 Google、Baidu)都依赖爬虫获取数据以构建索引
- 规范 :爬虫一般会遵守 robots.txt 协议,尊重网站的访问限制
- 谷歌的爬取协议:https://www.google.com/robots.txt
- 百度的爬取协议:https://www.baidu.com/robots.txt
- 技术能力:先进的爬虫支持抓取通过 JavaScript 动态加载的页面(如 SPA 应用)
💡 提示:
- robots.txt 是网站告知爬虫"哪些页面可以抓,哪些不可以"的规则文件
- 合法合规的爬取是网络数据采集的基础原则
爬虫分类
第一种:基于基础库实现的"手工作坊式"爬虫
核心工具
HTTP 请求库:
-
requests(同步):简单易用,适合基础请求 -
aiohttp(异步):支持高并发,性能更强HTML/XML 解析库:
-
BeautifulSoup:语法简洁,适合初学者 -
lxml:速度快,功能强大 -
pyquery:类似 jQuery 的语法,灵活高效数据提取方式:
-
正则表达式(
re):直接匹配文本模式,适用于简单规则提取
优缺点分析
✅ 优点:
- 极其灵活,无框架束缚
- 轻量级,资源占用少
- 适合学习爬虫原理和底层机制
🎯 适用场景:
- 学习爬虫基础知识
- 处理简单的、一次性的数据抓取任务
❌ 缺点:
- 所有组件需自行搭建,如:
→ 请求调度
→ 任务管理
→ 异步处理
→ 去重与存储 - 开发效率低,不适合大规模或长期项目
💡 总结:
"手工作坊式"爬虫是理解爬虫本质的起点,但实际工程中通常推荐使用"工程化"框架提升效率。
第二种:基于框架实现的"工程化"爬虫
-
Scrapy(最流行、最强大)
-
Feapder(对新手友好)
-
动态渲染工具(可与框架集成):
- Selenium
- Playwright
-
优点 :
→ 开发者只需专注于编写爬取规则和数据提取逻辑
→ 框架自动处理请求、调度、去重、存储等复杂流程
-
缺点 :
→ 有学习曲线,需理解框架的架构和数据流
→ 初期配置和调试成本较高
💡 建议
- 新手可从 Feapder 入门,再进阶到 Scrapy
- 复杂页面推荐使用 Playwright 替代 Selenium,性能更优
第三种:开箱即用的"成品化"爬虫工具/平台
-
常见工具:
- Octoparse
- Web Scraper(浏览器插件)
- Nutch(开源大规模爬虫系统)
-
优点 :
→ 不需要编程,操作简单
→ 上手快,适合非技术人员使用
-
缺点 :
→ 灵活性较差
→ 对于反爬机制强或结构复杂的网站,难以有效抓取数据
💡 小贴士 :
-
成品化工具适合快速获取结构清晰、静态内容的网页数据
-
面对动态加载、验证码、登录限制等复杂场景时,仍需结合代码或定制方案解决
✅ 总结:从"手工"到"工程化"再到"成品化",反映了爬虫技术的发展路径和应用场景的多样化。
实现一个爬虫工具
爬取目标
URL:https://www.mingzhuxiaoshuo.com/jinxianyi/111/
完整代码
python
"""
Author: sunhailiang sunhailiang@ssish.com
Date: 2026-01-21 14:19:33
LastEditors: sunhailiang sunhailiang@ssish.com
LastEditTime: 2026-01-21 15:57:56
FilePath: /llm/crawler.py
Description: 这是默认设置,请设置`customMade`, 打开koroFileHeader查看配置 进行设置: https://github.com/OBKoro1/koro1FileHeader/wiki/%E9%85%8D%E7%BD%AE
"""
import requests
from bs4 import BeautifulSoup
import os
from time import sleep
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
# 爬取目标,此处获取列表
webUrl = "https://www.mingzhuxiaoshuo.com/jinxiandai/111/"
# 设置请求头,模拟真实浏览器请求(更完整的请求头可以避免被反爬)
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive",
"Upgrade-Insecure-Requests": "1",
}
# 创建 Session 并配置重试策略
session = requests.Session()
# 配置重试策略(自动重试失败的请求)
retry_strategy = Retry(
total=3, # 最多重试3次
backoff_factor=1, # 重试间隔:1秒、2秒、4秒
status_forcelist=[429, 500, 502, 503, 504], # 遇到这些状态码时重试
)
adapter = HTTPAdapter(max_retries=retry_strategy)
session.mount("http://", adapter)
session.mount("https://", adapter)
print("开始爬取...")
# 发送请求(增加超时时间)
try:
response = session.get(webUrl, headers=headers, timeout=(10, 30)) # (连接超时, 读取超时)
except requests.exceptions.RequestException as e:
print(f"请求失败: {e}")
exit()
# 设置响应编码
response.encoding = "gbk"
# 判断请求是否成功
if response.status_code == 200:
print("请求成功...")
else:
print("请求失败...", response.status_code)
exit()
# 获取响应内容
html = response.text
# 解析响应内容
soup = BeautifulSoup(html, "html.parser")
# 先找到h1标签取文本当做存储数据的文件名
h1_text = soup.find("h1").text
# 创建文件
file_path = "crawler/" + h1_text + ".txt"
print("创建文件:", h1_text)
# 找id为content的div->class是list->ul>li>a
# 方法2(更简洁):直接使用 CSS 选择器查找所有 a 标签
a_tags = soup.select("div#content div.list ul li a")
# 存放a标签的href
href_list = []
# 遍历a_tags,获取a标签的href和title
for a_tag in a_tags:
href = a_tag.get("href")
title = a_tag.get("title") or a_tag.text.strip() # 如果没有title属性,使用文本内容
# 构建完整URL并存储为字典(title和url作为键值对)
if href: # 确保href存在
full_url = "https://www.mingzhuxiaoshuo.com" + href
href_list.append({"title": title, "url": full_url})
# 现在将通过href_list里面的url去爬取内容,然后保存到file_path中
with open(file_path, "w", encoding="utf-8") as f:
for index, item in enumerate(href_list):
title = item["title"]
url = item["url"]
print(f"正在爬取 {index+1}/{len(href_list)} 个内容,标题:{title}")
# 添加异常处理和重试机制
max_retries = 3
retry_count = 0
success = False
while retry_count < max_retries and not success:
try:
# 增加超时时间:(连接超时10秒, 读取超时30秒)
response = session.get(url, headers=headers, timeout=(10, 30))
response.encoding = "gbk"
if response.status_code == 200:
html = response.text
soup = BeautifulSoup(html, "html.parser")
# 提取内容并写入文件
content_div = soup.find("div", id="content")
if content_div:
# 获取content的文本内容
content_text = content_div.get_text(separator="\n").strip()
# 写入标题和文件内容
f.write(f"## {title}\n{content_text}\n\n\n")
f.flush() # 立即写入磁盘,避免数据丢失
print(f"✓ 成功爬取: {title}")
success = True
else:
print(f"✗ 不存在文本容器: {title}")
success = True # 即使没找到内容也算成功(避免无限重试)
else:
print(f"✗ 请求失败,状态码: {response.status_code}, URL: {url}")
retry_count += 1
except requests.exceptions.Timeout as e:
retry_count += 1
print(f"✗ 超时错误 (尝试 {retry_count}/{max_retries}): {e}")
if retry_count < max_retries:
sleep(2 * retry_count) # 递增等待时间:2秒、4秒、6秒
except requests.exceptions.RequestException as e:
retry_count += 1
print(f"✗ 请求异常 (尝试 {retry_count}/{max_retries}): {e}")
if retry_count < max_retries:
sleep(2 * retry_count)
except Exception as e:
print(f"✗ 未知错误: {e}")
break # 遇到未知错误,停止重试
if not success:
print(f"✗ 最终失败,跳过: {title}")
f.write(f"## {title}\n[爬取失败,请手动检查]\n\n\n")
# 请求间隔(避免请求过快被封)
sleep(1)
print(href_list)
print(a_tags)数据清洗
数据清洗的重要性
核心原则:"垃圾进,垃圾出"
一、影响模型学习质量
- 脏数据 → 模型学习混乱 → 输出不准确、不连贯
- 低质量输入导致生成内容逻辑断裂、事实错误
二、引发偏见与安全风险
- 未清洗数据可能包含歧视性语言、虚假信息或有害内容
- 模型会无意中学习并放大社会偏见,传播不当价值观
三、提升效率,降低成本
- 高质量数据 → 训练更高效 → 缩短收敛时间
- 减少无效训练轮次,降低算力与时间成本
✅ 总结:
数据清洗是AI训练的关键前置步骤 ,直接影响模型性能、安全性与经济性。
"好数据 = 好模型",清洗不是可选项,而是必选项。
数据清洗前的注意事项
在进行数据清洗之前,需从多个维度进行系统性评估与规划:
一、合法合规
- 避免侵犯版权、隐私权或商业机密
- 拒绝采集敏感信息(如军事、财务、个人身份等)
- 遵守《网络安全法》《个人信息保护法》等法律法规
二、数据质量
- 低质量数据是"毒药":
→ 重复内容 → 冗余训练
→ 噪音干扰 → 模型混淆
→ 错误标签 → 学习偏差 - 应优先剔除无效、错误或无意义的数据
三、偏见与公平
- 识别并缓解社会偏见(性别、种族、地域等)
- 防止历史数据中的歧视性模式被模型放大
- 通过采样平衡、去偏算法提升模型公平性
四、数据安全
- 防止恶意数据注入(如对抗样本、钓鱼内容)
- 避免攻击者利用漏洞污染训练集,影响大模型输出
- 建立数据准入机制,确保源头可信
✅ 总结:
1、数据清洗不仅是技术流程,更是伦理与责任的体现 。
2、在清洗前明确目标、评估风险,才能构建安全、可靠、公正的大模型。
数据清洗流程
数据清洗是构建高质量训练数据集的核心环节,遵循标准化流程可显著提升效率与结果可靠性。以下是基于行业通识的三阶段工程化流程:
一、数据采集与初步处理
- 数据采集
核心步骤
-
通过网络爬虫抓取数据
- 使用爬虫工具(如 Scrapy、Octoparse、requests + BeautifulSoup)从网页中提取原始内容
- 支持静态页面和动态渲染页面(结合 Selenium/Playwright)
-
数据格式化:将 HTML 转为纯文本
- 去除 HTML 标签、脚本、样式等非文本内容
- 提取正文内容,保留语义结构(如段落、标题)
- 输出为干净的纯文本格式,便于后续清洗与建模
✅ 目标:
将杂乱的网页源码转化为结构清晰、可读性强的文本数据,为后续清洗流程打下基础。
💡 工具推荐:
BeautifulSoup/lxml:解析 HTMLre或regex:正则提取特定内容html.parser:标准库支持轻量级解析
- 目标:获取原始数据
- 工具建议:Python + Pandas / Spark(大数据场景)
✅ 行业标准:"先结构化,再清洗" ------ 避免在非结构化数据上直接操作。
二、文本标准化与格式统一
- 目标:消除表达差异,提升语义一致性
在数据清洗流程中,文本标准化是确保模型输入一致性的重要环节。以下是行业通用的标准化操作规范:
✅ 标准化步骤详解
-
统一编码:全部转为 UTF-8 格式
- 保证跨平台、跨语言兼容性
- 避免乱码问题(如 GBK、ISO-8859-1 等混用)
- 使用 Python 的
encode('utf-8')或open(..., encoding='utf-8')
-
去除 HTML 标签与 JSON 标识
- 删除
<div>,<p>,<br>,{},[]等非语义内容 - 保留纯文本内容,避免结构干扰
- 工具推荐:
BeautifulSoup.get_text()或正则表达式re.sub(r'<[^>]+>', '', text)
- 删除
-
处理特殊字符
- 清理乱码(如
\x00,\xff等不可见字符) - 移除或替换表情符号(Emoji)------可选保留用于情感分析
- 统一符号格式(如全角/半角标点、中文引号 vs 英文引号)
- 清理乱码(如
-
清理空白字符
- 去除多余的空格、制表符(
\t)、换行符(\n) - 合并连续空格为单个空格,优化文本密度
- 示例:
" Hello World "→"Hello World"
- 去除多余的空格、制表符(
-
英文大小写统一(小写化)
- 将所有英文大写字母转为小写(如 "HELLO" → "hello")
- 提高文本匹配与词频统计的准确性
- 注意:中文、专有名词(如人名、地名)不强制转换
🛠 实践建议示例
python
import re
import unicodedata
def normalize_text(text):
# 转为 UTF-8 并解码
text = text.encode('utf-8').decode('utf-8')
# 去除 HTML 标签
text = re.sub(r'<[^>]+>', '', text)
# 去除特殊字符和乱码
text = unicodedata.normalize('NFKD', text)
text = re.sub(r'[^\w\s\u4e00-\u9fff]', '', text) # 保留中英数字及空格
# 去除多余空白
text = re.sub(r'\s+', ' ', text).strip()
# 英文转小写
text = text.lower()
return text✅ 总结:标准化目标
| 目标 | 说明 |
|---|---|
| 一致性 | 所有文本格式统一,便于后续处理 |
| 简洁性 | 移除冗余信息,提升模型效率 |
| 可读性 | 生成干净、清晰的文本数据,利于人工审核 |
💡 行业标准:"先标准化,再建模" ------ 是高质量训练数据的基础保障
三、噪声去除与内容过滤
在完成文本标准化后,噪音去除与内容过滤是提升数据质量的关键步骤。该阶段旨在剔除低价值、有害或干扰性内容,确保训练数据的纯净性与有效性。
✅ 核心操作详解
-
删除重复数据
- 目的:避免模型过拟合于相同内容
- 方法 :
- 基于哈希值去重(如
md5、sha1) - 使用相似度算法(如 Jaccard、余弦相似度)识别近似重复
- 工具推荐:
pandas.drop_duplicates()、dedupe库
- 基于哈希值去重(如
- 注意:需区分"完全重复"与"语义重复"(如不同表达方式的同义句)
-
删除过短或信息量不足的内容
- 标准 :
- 字数阈值(如中文 < 10 字,英文 < 5 words)
- 信息熵低(无实质意义的短句、语气词等)
- 典型例子 :
- "好"、"不错"、"谢谢"
- "点击这里查看更多" → 导航类模板文本
- 作用:防止模型学习无意义表达
- 标准 :
-
过滤广告、导航、模板文本
- 常见类型 :
- 广告横幅:"点击领取优惠券"
- 导航栏:"首页 | 关于我们 | 联系方式"
- 模板话术:"本文由XX提供"、"版权声明:..."
- 处理方式 :
- 规则匹配(关键词库 + 正则)
- 机器学习分类器(如 BERT-based 模型判断是否为"垃圾文本")
- 目标:保留用户生成内容(UGC),去除系统生成内容
- 常见类型 :
-
过滤色情、暴力等有害信息
- 合规要求:符合《网络安全法》《网络信息内容生态治理规定》
- 方法 :
- 敏感词库匹配(如
jieba+ 自定义词典) - 毒性检测模型(如
Toxicity Classifier、HuggingFace Transformers) - 多级过滤机制:先规则,再模型,最后人工抽检
- 敏感词库匹配(如
- 重点:防止恶意内容污染大模型输出,保障安全可控
🛠 实践建议示例
python
import re
from collections import Counter
def filter_content(text):
# 1. 长度过滤
if len(text) < 10:
return False
# 2. 重复检测(简单哈希去重)
if text in seen_texts:
return False
seen_texts.add(text)
# 3. 过滤广告/导航关键词
ad_keywords = ['广告', '点击', '领取', '优惠券', '首页']
if any(kw in text for kw in ad_keywords):
return False
# 4. 情感/毒性检测(示例)
if is_toxic(text): # 使用预训练模型
return False
return True✅ 行业标准:"多层过滤 + 人工抽检" ------ 自动化为主,人工复核为辅。
总结:三大原则(行业共识)
| 原则 | 内容 |
|---|---|
| 分阶段处理 | 不同任务分步执行,避免交叉污染 |
| 自动化优先 | 使用脚本和工具批量处理,提高效率 |
| 可追溯性 | 记录每一步操作(日志、版本控制),便于回溯与审计 |
🚀 实践建议 :
在实际项目中,推荐使用 Data Pipeline 工具链 (如 Apache Airflow + NLP Toolkit)实现端到端清洗流程,确保稳定性、可扩展性与合规性。
数据清洗实战
python
'''
Author: sunhailiang sunhailiang@ssish.com
Date: 2026-01-21 18:35:50
LastEditors: sunhailiang sunhailiang@ssish.com
LastEditTime: 2026-01-21 19:27:35
FilePath: /llm/crawler_clean_data.py
Description: 这是默认设置,请设置`customMade`, 打开koroFileHeader查看配置 进行设置: https://github.com/OBKoro1/koro1FileHeader/wiki/%E9%85%8D%E7%BD%AE
'''
import re
# 数据集路径
DATA_PATH = 'crawler/华盖集.txt'
# 数据集内容
CONTENT = ''
# 读取爬取下来的数据集
with open('crawler/华盖集.txt', 'r', encoding='utf-8') as f:
CONTENT = f.read()
# 处理特殊情况:去掉原始数据带※的行
lines=CONTENT.splitlines()
clean_lines = []
skip_mode = False
for line in lines:
if re.match(r'^.*※.*※.*※.*$', line.strip()):
skip_mode = True
continue
if skip_mode and re.match(r'^##.*$', line.strip()):
skip_mode = False
continue
if not skip_mode:
clean_lines.append(line)
clean_content = '\n'.join(clean_lines)
# 清除每行汉字不超过10个的行,包括汉字标点符号以及字符数字
clean_content = re.sub(r'^.{1,10}$', ' ', clean_content,flags=re.MULTILINE)
# 清洗数据中所有的空格和空行
clean_content = re.sub(r'^\s+', ' ', clean_content,flags=re.MULTILINE)
# 写入清洗后的数据集
with open('crawler/clean_华盖集.txt', 'w', encoding='utf-8') as f:
f.write(clean_content)数据清洗实战-AI
python
"""
数据清洗脚本 - AI优化版
功能:将爬取的原始文本清洗为适合模型预训练的标准格式
清洗规则:
1. 删除3个※分隔符行及其后的注释部分(到下一个##标题之前)
2. 删除正文中的注释引用标记(〔1〕、〔2〕等)
3. 删除日期行(如"一月八日"、"二月十日")
4. 统一空格格式(全角空格→半角空格)
5. 合并多个连续空行为单个空行
6. 删除纯空白行
7. 保留章节标题(## 标题)
"""
import re
import os
# ========== 配置参数 ==========
INPUT_FILE = "crawler/华盖集.txt"
OUTPUT_FILE = "crawler/clean_华盖集.txt"
ENCODING = "utf-8"
# ========== 读取原始数据 ==========
print(f"正在读取文件: {INPUT_FILE}")
try:
with open(INPUT_FILE, "r", encoding=ENCODING) as f:
content = f.read()
print(f"✓ 文件读取成功,共 {len(content)} 个字符")
except FileNotFoundError:
print(f"✗ 错误:文件不存在 - {INPUT_FILE}")
exit(1)
except Exception as e:
print(f"✗ 错误:读取文件失败 - {e}")
exit(1)
# ========== 第一步:删除3个※分隔符及其后的注释部分 ==========
print("\n第一步:删除3个※分隔符及其后的注释部分...")
lines = content.splitlines()
clean_lines = []
skip_mode = False # 跳过模式:遇到3个※后,跳过到下一个##标题
for i, line in enumerate(lines):
# 检测3个※分隔符行
if re.search(r"※.*※.*※", line):
skip_mode = True
print(f" 发现分隔符(第{i+1}行),开始跳过注释部分...")
continue # 不添加3个※行
# 检测章节标题(## 开头)
if re.match(r"^##\s+", line.strip()):
if skip_mode:
skip_mode = False
print(f" 遇到章节标题(第{i+1}行),停止跳过模式")
# 保留章节标题
clean_lines.append(line)
continue
# 如果在跳过模式中,不添加任何内容
if skip_mode:
continue
# 正常模式:添加内容
clean_lines.append(line)
print(f"✓ 第一步完成,删除了注释部分,剩余 {len(clean_lines)} 行")
# ========== 第二步:删除正文中的注释引用标记 ==========
print("\n第二步:删除正文中的注释引用标记(〔1〕、〔2〕等)...")
# 删除行内和行首的注释引用标记,如:〔1〕、〔2〕、〔10〕等
content_step2 = "\n".join(clean_lines)
# 删除行首的注释引用(如 "〔1〕大方之家")
content_step2 = re.sub(r"^〔\d+〕.*$", "", content_step2, flags=re.MULTILINE)
# 删除行内的注释引用(如 "文本〔1〕文本")
content_step2 = re.sub(r"〔\d+〕", "", content_step2)
print(f"✓ 第二步完成,已删除注释引用标记")
# ========== 第三步:删除日期行 ==========
print("\n第三步:删除日期行(如'一月八日'、'二月十日')...")
lines_step3 = content_step2.splitlines()
clean_lines_step3 = []
for line in lines_step3:
stripped = line.strip()
# 跳过空行(后续步骤会处理)
if not stripped:
clean_lines_step3.append(line)
continue
# 删除日期行模式:
# 1. "一月八日"、"二月十日" 等格式
# 2. "一九二五年十二月三十一日" 等完整日期
# 3. "一月八日。"、"二月十日。" 等带标点的日期
date_patterns = [
r"^[一二三四五六七八九十]+月[一二三四五六七八九十\d]+[日号]\.?$", # 一月八日、二月十日
r"^[一二三四五六七八九十\d]+年[一二三四五六七八九十]+月[一二三四五六七八九十\d]+[日号]\.?$", # 一九二五年十二月三十一日
r"^[一二三四五六七八九十]+月[一二三四五六七八九十\d]+[日号]之夜", # 十二月三十一日之夜
]
is_date_line = False
for pattern in date_patterns:
if re.match(pattern, stripped):
is_date_line = True
break
# 删除纯数字行(如"111"、"117"等,可能是页码)
if not is_date_line and re.match(r"^[\d]+$", stripped) and len(stripped) <= 5:
is_date_line = True
if not is_date_line:
clean_lines_step3.append(line)
print(f"✓ 第三步完成,删除了日期行,剩余 {len(clean_lines_step3)} 行")
# ========== 第四步:统一空格格式(全角→半角) ==========
print("\n第四步:统一空格格式(全角空格→半角空格)...")
content_step4 = "\n".join(clean_lines_step3)
# 将全角空格( )转换为半角空格
content_step4 = content_step4.replace(" ", " ")
print(f"✓ 第四步完成,已统一空格格式")
# ========== 第五步:合并多个连续空行为单个空行 ==========
print("\n第五步:合并多个连续空行为单个空行...")
lines_step5 = content_step4.splitlines()
clean_lines_step5 = []
prev_empty = False
for line in lines_step5:
is_empty = not line.strip() # 检查是否为空行
if is_empty:
# 如果前一行不是空行,添加一个空行
if not prev_empty:
clean_lines_step5.append("")
prev_empty = True
else:
clean_lines_step5.append(line)
prev_empty = False
content_step5 = "\n".join(clean_lines_step5)
print(f"✓ 第五步完成,已合并连续空行")
# ========== 第六步:删除行首行尾空白 ==========
print("\n第六步:清理行首行尾空白...")
lines_step6 = content_step5.splitlines()
clean_lines_step6 = [line.strip() for line in lines_step6]
content_step6 = "\n".join(clean_lines_step6)
print(f"✓ 第六步完成,已清理行首行尾空白")
# ========== 第七步:删除过短的无效行(可选,但要保留章节标题) ==========
print("\n第七步:删除过短的无效行(保留章节标题)...")
lines_step7 = content_step6.splitlines()
clean_lines_step7 = []
for line in lines_step7:
stripped = line.strip()
# 保留章节标题(## 开头)
if re.match(r"^##\s+", stripped):
clean_lines_step7.append(line)
continue
# 保留非空行(长度>0)
if len(stripped) > 0:
clean_lines_step7.append(line)
final_content = "\n".join(clean_lines_step7)
print(f"✓ 第七步完成,最终剩余 {len(clean_lines_step7)} 行")
# ========== 统计信息 ==========
original_lines = len(content.splitlines())
final_lines = len(final_content.splitlines())
reduction_rate = (1 - final_lines / original_lines) * 100 if original_lines > 0 else 0
print("\n" + "=" * 60)
print("清洗完成统计:")
print(f" 原始行数:{original_lines}")
print(f" 清洗后行数:{final_lines}")
print(f" 删除行数:{original_lines - final_lines}")
print(f" 压缩率:{reduction_rate:.1f}%")
print(f" 原始字符数:{len(content)}")
print(f" 清洗后字符数:{len(final_content)}")
print("=" * 60)
# ========== 写入清洗后的数据 ==========
print(f"\n正在写入清洗后的数据到: {OUTPUT_FILE}")
try:
# 确保输出目录存在
output_dir = os.path.dirname(OUTPUT_FILE)
if output_dir and not os.path.exists(output_dir):
os.makedirs(output_dir)
with open(OUTPUT_FILE, "w", encoding=ENCODING) as f:
f.write(final_content)
print(f"✓ 数据写入成功!")
print(f" 输出文件:{OUTPUT_FILE}")
print(f" 文件大小:{len(final_content)} 字符")
except Exception as e:
print(f"✗ 错误:写入文件失败 - {e}")
exit(1)
print("\n🎉 数据清洗完成!")