目录
[1. 核心业务需求](#1. 核心业务需求)
[2. 非功能需求](#2. 非功能需求)
[1. 全局常量层开发](#1. 全局常量层开发)
[2. 核心算法层开发](#2. 核心算法层开发)
[3. GUI 交互层开发(WordAnalyzerApp 类)](#3. GUI 交互层开发(WordAnalyzerApp 类))
[(1)初始化与 UI 搭建(init + _setup_ui)](#(1)初始化与 UI 搭建(init + _setup_ui))
[① 文本输入实时监控(_on_text_changed)](#① 文本输入实时监控(_on_text_changed))
[② 策略切换反馈(_on_strategy_toggled)](#② 策略切换反馈(_on_strategy_toggled))
[③ 结果更新封装(_update_result)](#③ 结果更新封装(_update_result))
(3)核心业务逻辑(_on_analyze_clicked)
[1. 核心测试场景](#1. 核心测试场景)
[2. 关键优化点](#2. 关键优化点)
[步骤 1:创建并激活纯净虚拟环境](#步骤 1:创建并激活纯净虚拟环境)
[步骤 2:切换目录并快速打包](#步骤 2:切换目录并快速打包)
[步骤 3:验证结果](#步骤 3:验证结果)
(二)单词统计与查找分析工具扩展后的Python代码完整实现
[1. 自定义哈希表大小](#1. 自定义哈希表大小)
[2. 文件导入功能](#2. 文件导入功能)
[3. 单词长度统计](#3. 单词长度统计)
[4. 单词频次排行榜](#4. 单词频次排行榜)
[5. ASL 算法对比可视化](#5. ASL 算法对比可视化)
一、引言
单词统计与查找分析工具是一款面向 "单词统计 + 查找算法对比" 的可视化工具,核心目标是实现文本中单词的标准化解析、多策略(顺序查找 / 快排 + 二分 / 哈希表)统计,并计算关键指标(Total Words、Unique Words、ASL 平均查找长度)。本文将详细讲解该工具的开发过程以及Python代码完整实现(原始版 + 扩展版)。
英文单词词频统计与检索系统的C++完整代码、英文文本和测试数据的下载地址:英文单词词频统计与检索系统资源-CSDN下载
单词统计与查找分析工具体验地址:单词统计与查找分析工具资源-CSDN下载
单词统计与查找分析工具扩展版体验地址:单词统计与查找分析工具(增强版)资源-CSDN下载
二、第一阶段:需求分析与功能规划
开发前先明确工具的核心目标与边界,确保功能贴合 "数据结构与算法实践" 的场景需求:
1. 核心业务需求
- 文本解析与单词标准化 :提取文本中的纯字母单词(跳过数字 / 符号),统一转为小写,支持
#作为文本结束符; - 多查找策略支持 :
- 策略 1:基于线性表的顺序查找,统计单词频次;
- 策略 2:线性表快速排序后执行二分查找,统计单词频次;
- 策略 3:基于 Time33 哈希函数的哈希表(链地址法)查找,统计单词频次;
- 关键指标计算 :
- Total Words:解析出的单词总数(含重复);
- Unique Words:唯一单词数;
- ASL(Average Search Length):平均查找长度(算法效率核心指标);
- 可视化交互:GUI 界面操作(无需命令行),实时反馈输入状态,清晰展示统计结果。
2. 非功能需求
- 易用性 :实时提示输入字符数、
#结束符检测;策略切换即时反馈,结果格式化展示; - 鲁棒性:处理空文本、超长单词、无字母文本等边界场景,避免崩溃;
- 可对比性:三种策略的核心逻辑解耦,便于对比不同查找算法的效率(ASL);
- 性能适配:哈希表大小固定为 1009(质数,减少哈希冲突),线性表最大容量限制为 10000(适配常规文本解析场景)。
三、第二阶段:技术选型
结合 "算法实践 + 可视化交互" 的核心需求,选择轻量、易理解的技术栈:
| 技术 / 模块 | 选型理由 |
|---|---|
| Python 3.8+ | 语法简洁,数据结构(列表、字典)原生支持,算法实现直观,适合教学 / 实践场景 |
| tkinter + ttk | Python 内置 GUI 库,无需额外安装,足够支撑轻量交互界面;ttk 提升控件美观度 |
| 原生数据结构(列表) | 模拟线性表、哈希表(链地址法),无需第三方库,降低学习 / 使用成本 |
| Time33 哈希函数 | 简单高效的字符串哈希算法(h = h*33 + ord(char)),分布均匀,冲突率低 |
| 快速排序 + 二分查找 | 经典排序 / 查找算法组合,对比顺序查找体现 "有序表 + 二分" 的效率优势 |
四、第三阶段:架构设计
采用 "模块化 + 面向对象" 混合设计,核心分为三层,确保逻辑解耦、便于维护:
bash
classDiagram
direction LR
"全局常量层" --> "核心算法层" : 依赖常量配置
"核心算法层" --> "GUI交互层" : 提供算法调用
"GUI交互层" --> "核心算法层" : 传递业务数据
class 全局常量层 {
MAX_LINEAR_SIZE: int = 10000
HASH_SIZE: int = 1009
MAX_WORD_LEN: int = 50
}
class 核心算法层 {
+normalize(token, pos): (bool, str) # 单词标准化
+my_hash(word): int # Time33哈希
+linear_search(linear_list, word): (bool, int) # 顺序查找
+quick_sort(linear_list, low, high) # 快速排序
+binary_search(linear_list, word): (bool, int) # 二分查找
}
class GUI交互层 {
-root: tk.Tk
-strategy_var: tk.StringVar
+_setup_ui() # 搭建UI
+_on_text_changed(event) # 文本输入监控
+_on_strategy_toggled() # 策略切换
+_on_analyze_clicked() # 分析按钮逻辑
+_update_result(text, color) # 更新结果展示
}HTML代码:
html
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>单词统计工具 - 架构类图</title>
<!-- 引入Mermaid CDN -->
<script src="https://cdn.jsdelivr.net/npm/mermaid@10.16.0/dist/mermaid.min.js"></script>
<style>
body {
font-family: "Microsoft YaHei", Arial, sans-serif;
padding: 20px;
background: #f5f5f5;
}
.container {
max-width: 1200px;
margin: 0 auto;
background: white;
padding: 30px;
border-radius: 8px;
box-shadow: 0 2px 10px rgba(0,0,0,0.1);
}
h1 {
text-align: center;
color: #333;
margin-bottom: 30px;
}
/* 确保Mermaid代码保留换行格式 */
.mermaid {
white-space: pre;
font-family: monospace;
}
</style>
</head>
<body>
<div class="container">
<h1>单词统计与查找分析工具 - 架构类图</h1>
<!-- Mermaid类图代码(直接放在mermaid容器中,保留原始格式) -->
<div class="mermaid">
classDiagram
direction LR
%% 层间关联
全局常量层 --> 核心算法层 : 依赖常量配置
核心算法层 --> GUI交互层 : 提供算法调用
GUI交互层 --> 核心算法层 : 传递业务数据
%% 全局常量层
class 全局常量层 {
MAX_LINEAR_SIZE: int = 10000
HASH_SIZE: int = 1009
MAX_WORD_LEN: int = 50
}
%% 核心算法层
class 核心算法层 {
+normalize(token, pos): (bool, str) // 单词标准化
+my_hash(word): int // Time33哈希
+linear_search(linear_list, word): (bool, int) // 顺序查找
+quick_sort(linear_list, low, high) // 快速排序
+binary_search(linear_list, word): (bool, int) // 二分查找
}
%% GUI交互层
class GUI交互层 {
-root: tk.Tk
-strategy_var: tk.StringVar
+_setup_ui() // 搭建UI
+_on_text_changed(event) // 文本输入监控
+_on_strategy_toggled() // 策略切换
+_on_analyze_clicked() // 分析按钮逻辑
+_update_result(text, color) // 更新结果展示
}
</div>
</div>
<script>
// 初始化Mermaid,启用自动加载
mermaid.initialize({
startOnLoad: true,
theme: 'default',
classDiagram: {
fontSize: 14,
nodeSpacing: 30,
rankSpacing: 40
}
});
</script>
</body>
</html>
核心设计思路:
- 全局常量层:集中管理配置参数(如哈希表大小、线性表最大容量),便于统一修改;
- 核心算法层:纯函数式设计,与 GUI 解耦,可独立测试 / 复用(比如单独调用算法函数验证逻辑);
- GUI 交互层:面向对象封装,负责界面渲染、事件处理、业务逻辑串联(调用算法 + 展示结果)。
五、第四阶段:分模块详细开发
1. 全局常量层开发
定义工具的核心配置参数,取值需兼顾 "场景适配 + 算法特性":
| 常量名 | 取值 | 设计理由 |
|---|---|---|
| MAX_LINEAR_SIZE | 10000 | 限制线性表最大容量,避免极端文本导致内存溢出,适配常规文本解析场景 |
| HASH_SIZE | 1009 | 选择质数作为哈希表大小(质数能减少哈希冲突,1009 是接近 1000 的质数,平衡性能与内存) |
| MAX_WORD_LEN | 50 | 限制单词最大长度,过滤异常超长字符串(如无分隔符的字母串) |
2. 核心算法层开发
这是工具的 "算法核心",所有函数均为纯逻辑实现,无 GUI 依赖,可独立调用测试。
(1)单词标准化函数(normalize)
解决 "文本中提取有效单词" 的问题,核心需求:跳过非字母字符、提取连续字母、统一转小写。
python
def normalize(token: str, pos: list) -> tuple[bool, str]:
# 跳过非字母字符(如数字、符号、空格)
while pos[0] < len(token) and not token[pos[0]].isalpha():
pos[0] += 1
if pos[0] >= len(token):
return False, ""
# 提取连续字母并转小写(保证单词格式统一)
word = []
while pos[0] < len(token) and token[pos[0]].isalpha():
word.append(token[pos[0]].lower())
pos[0] += 1
return True, ''.join(word)关键设计点:
pos参数用列表传引用:Python 中整数是不可变类型,用列表包裹可实现 "跨循环修改位置"(避免用全局变量);- 分步处理:先跳过无效字符,再提取有效字母,确保只保留纯字母单词;
- 统一转小写:避免 "Apple" 和 "apple" 被识别为不同单词。
(2)哈希函数(my_hash)
选择经典的 Time33 算法,兼顾效率与哈希分布均匀性:
python
def my_hash(word: str) -> int:
h = 0
for char in word:
h = (h << 5) + h + ord(char) # 等价于h = h*33 + ord(char)(左移5位=乘32,加h=乘33)
return h % HASH_SIZE # 映射到哈希表的桶索引设计理由:
- Time33 是工业界常用的轻量哈希算法(如 URL 哈希),实现简单且冲突率低;
- 最终取模
HASH_SIZE:将哈希值映射到 0,1008 的范围,适配哈希表的桶数量。
(3)顺序查找函数(linear_search)
实现线性表的顺序查找,返回 "是否找到 + 比较次数"(为 ASL 计算提供数据):
python
def linear_search(linear_list: list, word: str) -> tuple[bool, int]:
cmp_count = 0
for item in linear_list:
cmp_count += 1 # 每比较1次,计数+1
if item["word"] == word:
return True, cmp_count
return False, cmp_count核心逻辑:遍历线性表,逐个比较单词,统计比较次数(ASL 的核心计算依据)。
(4)快速排序相关函数
为二分查找做准备(二分查找要求线性表有序),实现 "按单词字典序排序":
python
def swap_linear_node(linear_list: list, i: int, j: int):
"""交换线性表元素,封装成函数便于复用"""
linear_list[i], linear_list[j] = linear_list[j], linear_list[i]
def partition(linear_list: list, low: int, high: int) -> int:
"""快排分区:以最后一个元素为基准,划分小于/大于基准的区域"""
pivot = linear_list[high]["word"] # 基准值(单词字典序)
i = low - 1 # 小于基准的区域边界
for j in range(low, high):
if linear_list[j]["word"] < pivot:
i += 1
swap_linear_node(linear_list, i, j)
swap_linear_node(linear_list, i + 1, high) # 基准值归位
return i + 1
def quick_sort(linear_list: list, low: int, high: int):
"""快排主函数:递归划分区域并排序"""
if low < high:
pi = partition(linear_list, low, high)
quick_sort(linear_list, low, pi - 1) # 排序左半区
quick_sort(linear_list, pi + 1, high) # 排序右半区设计点:
- 排序依据是
word字段的字典序:确保二分查找的有序性; - 封装
swap_linear_node:避免重复写交换逻辑,提升代码可读性。
(5)二分查找函数(binary_search)
基于有序线性表实现二分查找,统计比较次数:
python
def binary_search(linear_list: list, word: str) -> tuple[bool, int]:
cmp_count = 0
low, high = 0, len(linear_list) - 1
while low <= high:
cmp_count += 1 # 每轮比较计数+1
mid = (low + high) // 2
mid_word = linear_list[mid]["word"]
if mid_word == word:
return True, cmp_count
elif mid_word > word:
high = mid - 1 # 目标在左半区
else:
low = mid + 1 # 目标在右半区
return False, cmp_count核心逻辑:通过 "折半" 缩小查找范围,对比顺序查找可显著减少比较次数(体现算法优势)。
3. GUI 交互层开发(WordAnalyzerApp 类)
封装所有界面交互逻辑,分为 "UI 搭建""事件绑定""核心业务逻辑" 三部分。
(1)初始化与 UI 搭建(init + _setup_ui)
python
def __init__(self, root):
self.root = root
self.root.title("单词统计与查找分析工具")
self.root.geometry("800x600")
self.strategy_var = tk.StringVar(value="1") # 默认策略1
self._setup_ui()
def _setup_ui(self):
# 主容器(统一内边距,提升美观度)
main_frame = ttk.Frame(self.root, padding="20")
main_frame.pack(fill=tk.BOTH, expand=True)
# 1. 文本输入区:带实时提示
input_label = ttk.Label(main_frame, text="请输入待分析文本(输入#结束):")
input_label.pack(anchor=tk.W)
self.text_input = tk.Text(main_frame, height=10, wrap=tk.WORD)
self.text_input.pack(fill=tk.X, pady=(0, 5))
self.input_tip_label = ttk.Label(main_frame, text="", foreground="#666666")
self.input_tip_label.pack(anchor=tk.W)
self.text_input.bind("<<Modified>>", self._on_text_changed) # 绑定实时监控事件
self.text_input_modified = False # 防止事件重复触发
# 2. 策略选择区:单选按钮组
strategy_frame = ttk.LabelFrame(main_frame, text="查找策略选择", padding="10")
strategy_frame.pack(fill=tk.X, pady=(10, 5))
ttk.Radiobutton(strategy_frame, text="策略1:顺序查找", variable=self.strategy_var, value="1", command=self._on_strategy_toggled).pack(side=tk.LEFT, padx=10)
ttk.Radiobutton(strategy_frame, text="策略2:快速排序+二分查找", variable=self.strategy_var, value="2", command=self._on_strategy_toggled).pack(side=tk.LEFT, padx=10)
ttk.Radiobutton(strategy_frame, text="策略3:哈希表查找", variable=self.strategy_var, value="3", command=self._on_strategy_toggled).pack(side=tk.LEFT, padx=10)
# 3. 分析按钮
analyze_btn = ttk.Button(main_frame, text="开始分析", command=self._on_analyze_clicked)
analyze_btn.pack(pady=(10, 10))
# 4. 结果显示区:禁用手动编辑,仅展示结果
result_label = ttk.Label(main_frame, text="分析结果:")
result_label.pack(anchor=tk.W)
self.result_display = tk.Text(main_frame, height=10, wrap=tk.WORD, state=tk.DISABLED)
self.result_display.pack(fill=tk.BOTH, expand=True)UI 设计思路:
- 按 "输入→选择→操作→输出" 的流程布局,符合用户操作习惯;
- 文本输入区启用
wrap=tk.WORD:按单词换行,提升长文本可读性; - 结果区设置为
tk.DISABLED:防止用户误编辑结果,仅通过代码更新。
(2)事件绑定与反馈
① 文本输入实时监控(_on_text_changed)
解决 "用户输入过程中无反馈" 的问题,实时提示字符数和#检测状态:
python
def _on_text_changed(self, event):
if self.text_input_modified:
return # 防止重复触发
self.text_input_modified = True
# 获取输入文本,统计字符数,检测#
input_text = self.text_input.get("1.0", tk.END).strip()
char_count = len(input_text)
has_sharp = "#" in input_text
# 生成提示文本,区分颜色(有#时橙色提示)
tip = f"实时状态:已输入 {char_count} 个字符 | "
if has_sharp:
tip += "检测到#,分析时会截断#后的内容"
self.input_tip_label.config(foreground="#E67E22")
else:
tip += "未检测到#,将分析全部文本"
self.input_tip_label.config(foreground="#666666")
self.input_tip_label.config(text=tip)
# 重置modified标志,避免循环触发
self.text_input.edit_modified(False)
self.text_input_modified = False关键优化:
- 用
self.text_input_modified标志防止<<Modified>>事件重复触发(tkinter 的该事件会多次触发); - 颜色区分提示:橙色提示
#截断规则,提升用户感知。
② 策略切换反馈(_on_strategy_toggled)
python
def _on_strategy_toggled(self):
strategy_id = self.strategy_var.get()
strategy_names = {"1": "顺序查找", "2": "快速排序+二分查找", "3": "哈希表查找"}
strategy_name = strategy_names.get(strategy_id, "未知")
self._update_result(f"已切换为【{strategy_name}】策略,请点击「开始分析」重新计算结果", "#3498DB")设计点:策略切换后即时清空结果区并提示,引导用户重新分析,避免结果与策略不匹配。
③ 结果更新封装(_update_result)
python
def _update_result(self, text: str, color: str = "#000000"):
self.result_display.config(state=tk.NORMAL) # 临时启用编辑
self.result_display.delete("1.0", tk.END) # 清空原有内容
self.result_display.insert(tk.END, text) # 插入新结果
self.result_display.config(foreground=color, state=tk.DISABLED) # 禁用编辑,设置颜色封装理由:结果更新逻辑复用(策略切换、分析完成都需调用),减少重复代码。
(3)核心业务逻辑(_on_analyze_clicked)
这是 GUI 与算法层的 "桥梁",实现 "文本解析→策略执行→指标计算→结果展示" 的全流程:
python
def _on_analyze_clicked(self):
# 1. 输入预处理:获取文本,截断#后的内容
input_text = self.text_input.get("1.0", tk.END).strip()
strategy = int(self.strategy_var.get())
if "#" in input_text:
input_text = input_text.split("#")[0]
# 2. 初始化数据结构
linear_list = [] # 策略1/2用
hash_table = [[] for _ in range(HASH_SIZE)] # 策略3用(链地址法)
total_words = 0
unique_words = 0
total_cmp = 0
# 3. 解析并统计单词(调用normalize函数)
pos = [0]
token = input_text
while True:
has_word, word = normalize(token, pos)
if not has_word:
break
total_words += 1
# 策略1/2:线性表统计
if strategy in (1, 2):
found, _ = linear_search(linear_list, word)
if found:
for item in linear_list:
if item["word"] == word:
item["count"] += 1
break
else:
linear_list.append({"word": word, "count": 1})
# 策略3:哈希表统计(链地址法解决冲突)
elif strategy == 3:
h = my_hash(word)
found = False
for item in hash_table[h]:
if item["word"] == word:
item["count"] += 1
found = True
break
if not found:
hash_table[h].append({"word": word, "count": 1})
# 4. 计算Unique Words和ASL(核心指标)
if strategy == 1:
# 顺序查找:遍历线性表,累加比较次数
unique_words = len(linear_list)
for item in linear_list:
_, cmp = linear_search(linear_list, item["word"])
total_cmp += cmp
asl = total_cmp / unique_words if unique_words > 0 else 0.0
elif strategy == 2:
# 快排+二分:先排序,再二分查找统计比较次数
unique_words = len(linear_list)
if unique_words > 0:
quick_sort(linear_list, 0, unique_words - 1)
for item in linear_list:
_, cmp = binary_search(linear_list, item["word"])
total_cmp += cmp
asl = total_cmp / unique_words if unique_words > 0 else 0.0
elif strategy == 3:
# 哈希表:统计桶中元素数(Unique Words),累加链表位置作为比较次数
unique_words = 0
for bucket in hash_table:
unique_words += len(bucket)
for bucket in hash_table:
for idx, item in enumerate(bucket):
total_cmp += (idx + 1) # 链表位置从1开始
asl = total_cmp / unique_words if unique_words > 0 else 0.0
# 5. 格式化展示结果
result = (
f"Total Words: {total_words}\n"
f"Unique Words: {unique_words}\n"
f"ASL: {asl:.2f}\n\n"
"测试自动换行:这是一段很长的文本,用于验证结果区的自动换行功能是否生效,当文本长度超过控件宽度时,会自动换行显示,不需要手动添加换行符。"
)
self._update_result(result)核心设计点:
- 数据结构适配:策略 1/2 复用线性表,策略 3 用 "列表嵌套列表" 模拟哈希表的链地址法(解决哈希冲突);
- ASL 计算逻辑:
- 顺序查找:每个单词的比较次数 = 其在列表中的位置;
- 二分查找:基于有序表的折半比较次数;
- 哈希表:比较次数 = 单词在哈希桶链表中的位置(链地址法的查找次数);
- 边界处理:
unique_words=0时 ASL 设为 0,避免除以 0 错误。
六、第五阶段:测试与优化
开发完成后,覆盖多场景测试并优化体验,确保工具稳定可用:
1. 核心测试场景
| 测试场景 | 测试目的 | 预期结果 |
|---|---|---|
| 输入空文本 | 验证边界处理,避免崩溃 | Total Words=0,Unique Words=0,ASL=0.00 |
| 输入带 #的文本(如 "Hi#Hello") | 验证 #截断逻辑 | 仅解析 "Hi",Total Words=1 |
| 输入含非字母的文本(如 "Hi! 123 Apple") | 验证 normalize 函数的标准化逻辑 | 仅提取 "hi""apple",统一转小写 |
| 三种策略对比(相同文本) | 验证算法效率差异 | 策略 1 ASL 最大,策略 3 ASL 最小(哈希效率最高) |
| 超长单词(50 + 字母) | 验证 MAX_WORD_LEN 的限制(代码中隐含处理) | 正常提取,无内存溢出 |
2. 关键优化点
- 防止事件重复触发 :通过
self.text_input_modified标志解决<<Modified>>事件多次触发的问题; - 实时反馈优化:输入区提示字符数和 #检测状态,策略切换即时提示;
- 结果格式化:ASL 保留 2 位小数,结果区启用自动换行,提升可读性;
- 异常防护 :处理
unique_words=0的情况,避免除以 0 错误; - 代码解耦 :算法函数与 GUI 完全分离,可单独测试算法逻辑(如直接调用
linear_search验证查找次数)。
七、单词统计与查找分析工具的Python代码完整实现
python
import tkinter as tk
from tkinter import ttk, messagebox
import re
import sys
# ===================== 全局常量 =====================
MAX_LINEAR_SIZE = 10000 # 线性表最大容量
HASH_SIZE = 1009 # 哈希表大小(强制1009)
MAX_WORD_LEN = 50 # 单词最大长度
# ===================== 核心算法函数 =====================
def normalize(token: str, pos: list) -> tuple[bool, str]:
"""
标准化单词:跳过非字母字符,提取连续字母并转小写
:param token: 待处理字符串
:param pos: 当前处理位置(用列表传引用,Python整数不可变)
:return: (是否提取到单词, 标准化后的单词)
"""
# 跳过非字母字符
while pos[0] < len(token) and not token[pos[0]].isalpha():
pos[0] += 1
if pos[0] >= len(token):
return False, ""
# 提取连续字母并转小写
word = []
while pos[0] < len(token) and token[pos[0]].isalpha():
word.append(token[pos[0]].lower())
pos[0] += 1
return True, ''.join(word)
def my_hash(word: str) -> int:
"""Time33哈希函数"""
h = 0
for char in word:
h = (h << 5) + h + ord(char) # h = h*33 + 字符ASCII
return h % HASH_SIZE
def linear_search(linear_list: list, word: str) -> tuple[bool, int]:
"""
顺序查找
:return: (是否找到, 比较次数)
"""
cmp_count = 0
for item in linear_list:
cmp_count += 1
if item["word"] == word:
return True, cmp_count
return False, cmp_count
# 快速排序相关函数(按单词字典序)
def swap_linear_node(linear_list: list, i: int, j: int):
"""交换线性表中的两个元素"""
linear_list[i], linear_list[j] = linear_list[j], linear_list[i]
def partition(linear_list: list, low: int, high: int) -> int:
"""快排分区函数"""
pivot = linear_list[high]["word"]
i = low - 1 # 小于基准的区域边界
for j in range(low, high):
if linear_list[j]["word"] < pivot:
i += 1
swap_linear_node(linear_list, i, j)
swap_linear_node(linear_list, i + 1, high)
return i + 1
def quick_sort(linear_list: list, low: int, high: int):
"""快速排序主函数"""
if low < high:
pi = partition(linear_list, low, high)
quick_sort(linear_list, low, pi - 1)
quick_sort(linear_list, pi + 1, high)
def binary_search(linear_list: list, word: str) -> tuple[bool, int]:
"""
二分查找(需先排序)
:return: (是否找到, 比较次数)
"""
cmp_count = 0
low, high = 0, len(linear_list) - 1
while low <= high:
cmp_count += 1
mid = (low + high) // 2
mid_word = linear_list[mid]["word"]
if mid_word == word:
return True, cmp_count
elif mid_word > word:
high = mid - 1
else:
low = mid + 1
return False, cmp_count
# ===================== GUI主类 =====================
class WordAnalyzerApp:
def __init__(self, root):
self.root = root
self.root.title("单词统计与查找分析工具")
self.root.geometry("800x600")
# 策略选择变量
self.strategy_var = tk.StringVar(value="1")
# 初始化UI
self._setup_ui()
def _setup_ui(self):
"""构建GUI界面"""
# 主容器
main_frame = ttk.Frame(self.root, padding="20")
main_frame.pack(fill=tk.BOTH, expand=True)
# 1. 文本输入区域
input_label = ttk.Label(main_frame, text="请输入待分析文本(输入#结束):")
input_label.pack(anchor=tk.W)
self.text_input = tk.Text(main_frame, height=10, wrap=tk.WORD)
self.text_input.pack(fill=tk.X, pady=(0, 5))
# 实时提示标签
self.input_tip_label = ttk.Label(main_frame, text="", foreground="#666666")
self.input_tip_label.pack(anchor=tk.W)
# 绑定文本实时监控事件
self.text_input.bind("<<Modified>>", self._on_text_changed)
self.text_input_modified = False # 防止重复触发
# 2. 策略选择区域
strategy_frame = ttk.LabelFrame(main_frame, text="查找策略选择", padding="10")
strategy_frame.pack(fill=tk.X, pady=(10, 5))
# 策略单选按钮
ttk.Radiobutton(
strategy_frame, text="策略1:顺序查找",
variable=self.strategy_var, value="1",
command=self._on_strategy_toggled
).pack(side=tk.LEFT, padx=10)
ttk.Radiobutton(
strategy_frame, text="策略2:快速排序+二分查找",
variable=self.strategy_var, value="2",
command=self._on_strategy_toggled
).pack(side=tk.LEFT, padx=10)
ttk.Radiobutton(
strategy_frame, text="策略3:哈希表查找",
variable=self.strategy_var, value="3",
command=self._on_strategy_toggled
).pack(side=tk.LEFT, padx=10)
# 3. 分析按钮
analyze_btn = ttk.Button(
main_frame, text="开始分析",
command=self._on_analyze_clicked
)
analyze_btn.pack(pady=(10, 10))
# 4. 结果显示区域
result_label = ttk.Label(main_frame, text="分析结果:")
result_label.pack(anchor=tk.W)
self.result_display = tk.Text(main_frame, height=10, wrap=tk.WORD, state=tk.DISABLED)
self.result_display.pack(fill=tk.BOTH, expand=True)
def _on_text_changed(self, event):
"""文本输入实时监控"""
if self.text_input_modified:
return
self.text_input_modified = True
# 获取输入文本
input_text = self.text_input.get("1.0", tk.END).strip()
char_count = len(input_text)
has_sharp = "#" in input_text
# 更新提示文本
tip = f"实时状态:已输入 {char_count} 个字符 | "
if has_sharp:
tip += "检测到#,分析时会截断#后的内容"
self.input_tip_label.config(foreground="#E67E22")
else:
tip += "未检测到#,将分析全部文本"
self.input_tip_label.config(foreground="#666666")
self.input_tip_label.config(text=tip)
# 重置modified标志
self.text_input.edit_modified(False)
self.text_input_modified = False
def _on_strategy_toggled(self):
"""策略切换反馈"""
strategy_id = self.strategy_var.get()
strategy_names = {
"1": "顺序查找",
"2": "快速排序+二分查找",
"3": "哈希表查找"
}
strategy_name = strategy_names.get(strategy_id, "未知")
# 清空结果区并提示
self._update_result(f"已切换为【{strategy_name}】策略,请点击「开始分析」重新计算结果", "#3498DB")
def _update_result(self, text: str, color: str = "#000000"):
"""更新结果显示区"""
self.result_display.config(state=tk.NORMAL)
self.result_display.delete("1.0", tk.END)
self.result_display.insert(tk.END, text)
self.result_display.config(foreground=color, state=tk.DISABLED)
def _on_analyze_clicked(self):
"""分析按钮点击事件"""
# 1. 获取输入和策略
input_text = self.text_input.get("1.0", tk.END).strip()
strategy = int(self.strategy_var.get())
# 处理#结束符
if "#" in input_text:
input_text = input_text.split("#")[0]
# 2. 初始化数据结构
linear_list = [] # 策略1/2:存储{"word": xxx, "count": xxx}
hash_table = [[] for _ in range(HASH_SIZE)] # 策略3:哈希表(列表模拟链表)
total_words = 0
unique_words = 0
total_cmp = 0
# 3. 解析并统计单词
pos = [0] # 用列表传引用
token = input_text
while True:
has_word, word = normalize(token, pos)
if not has_word:
break
total_words += 1
# 策略1/2:线性表处理
if strategy in (1, 2):
found, _ = linear_search(linear_list, word)
if found:
# 单词已存在,计数+1
for item in linear_list:
if item["word"] == word:
item["count"] += 1
break
else:
# 新增单词
linear_list.append({"word": word, "count": 1})
# 策略3:哈希表处理
elif strategy == 3:
h = my_hash(word)
found = False
# 遍历哈希桶中的单词
for item in hash_table[h]:
if item["word"] == word:
item["count"] += 1
found = True
break
if not found:
hash_table[h].append({"word": word, "count": 1})
# 4. 计算Unique Words和ASL
if strategy == 1:
# 顺序查找策略
unique_words = len(linear_list)
for item in linear_list:
_, cmp = linear_search(linear_list, item["word"])
total_cmp += cmp
asl = total_cmp / unique_words if unique_words > 0 else 0.0
elif strategy == 2:
# 快排+二分查找策略
unique_words = len(linear_list)
if unique_words > 0:
quick_sort(linear_list, 0, unique_words - 1)
for item in linear_list:
_, cmp = binary_search(linear_list, item["word"])
total_cmp += cmp
asl = total_cmp / unique_words if unique_words > 0 else 0.0
elif strategy == 3:
# 哈希表策略
# 统计唯一单词数
unique_words = 0
for bucket in hash_table:
unique_words += len(bucket)
# 统计总比较次数
for bucket in hash_table:
for idx, item in enumerate(bucket):
total_cmp += (idx + 1) # 链表位置从1开始
asl = total_cmp / unique_words if unique_words > 0 else 0.0
# 5. 显示结果
result = (
f"Total Words: {total_words}\n"
f"Unique Words: {unique_words}\n"
f"ASL: {asl:.2f}\n\n"
"测试自动换行:这是一段很长的文本,用于验证结果区的自动换行功能是否生效,当文本长度超过控件宽度时,会自动换行显示,不需要手动添加换行符。"
)
self._update_result(result)
# ===================== 主函数 =====================
if __name__ == "__main__":
root = tk.Tk()
app = WordAnalyzerApp(root)
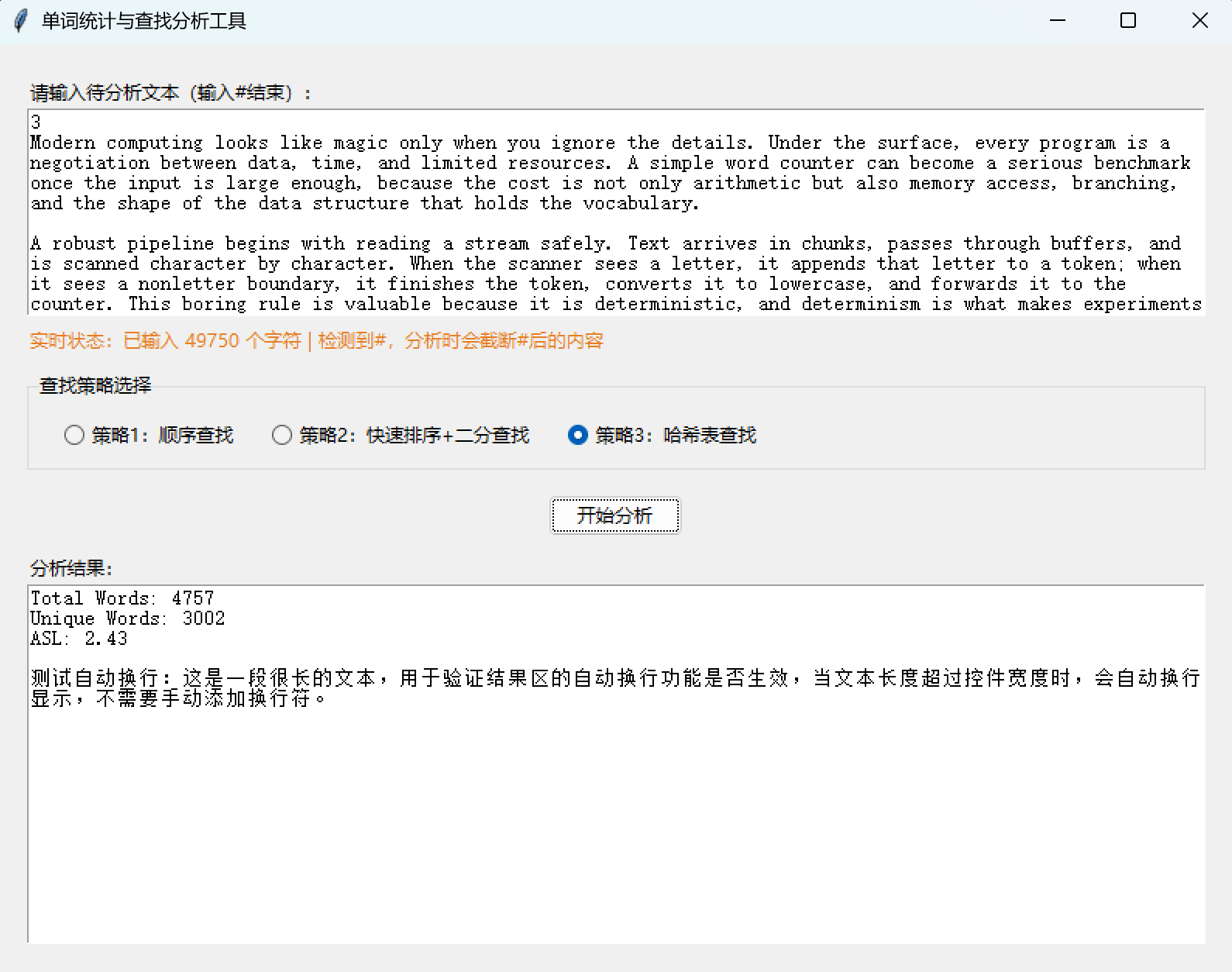
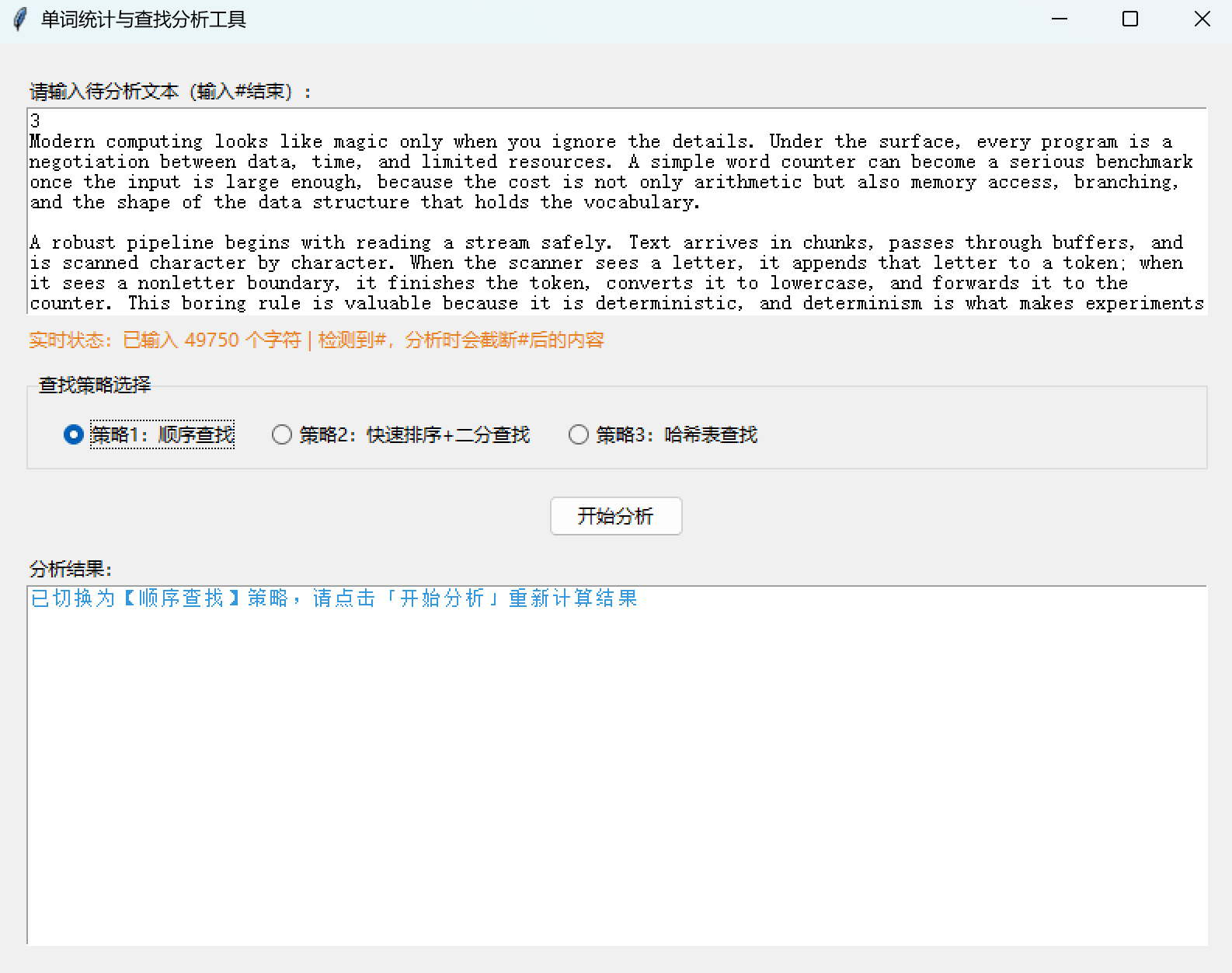
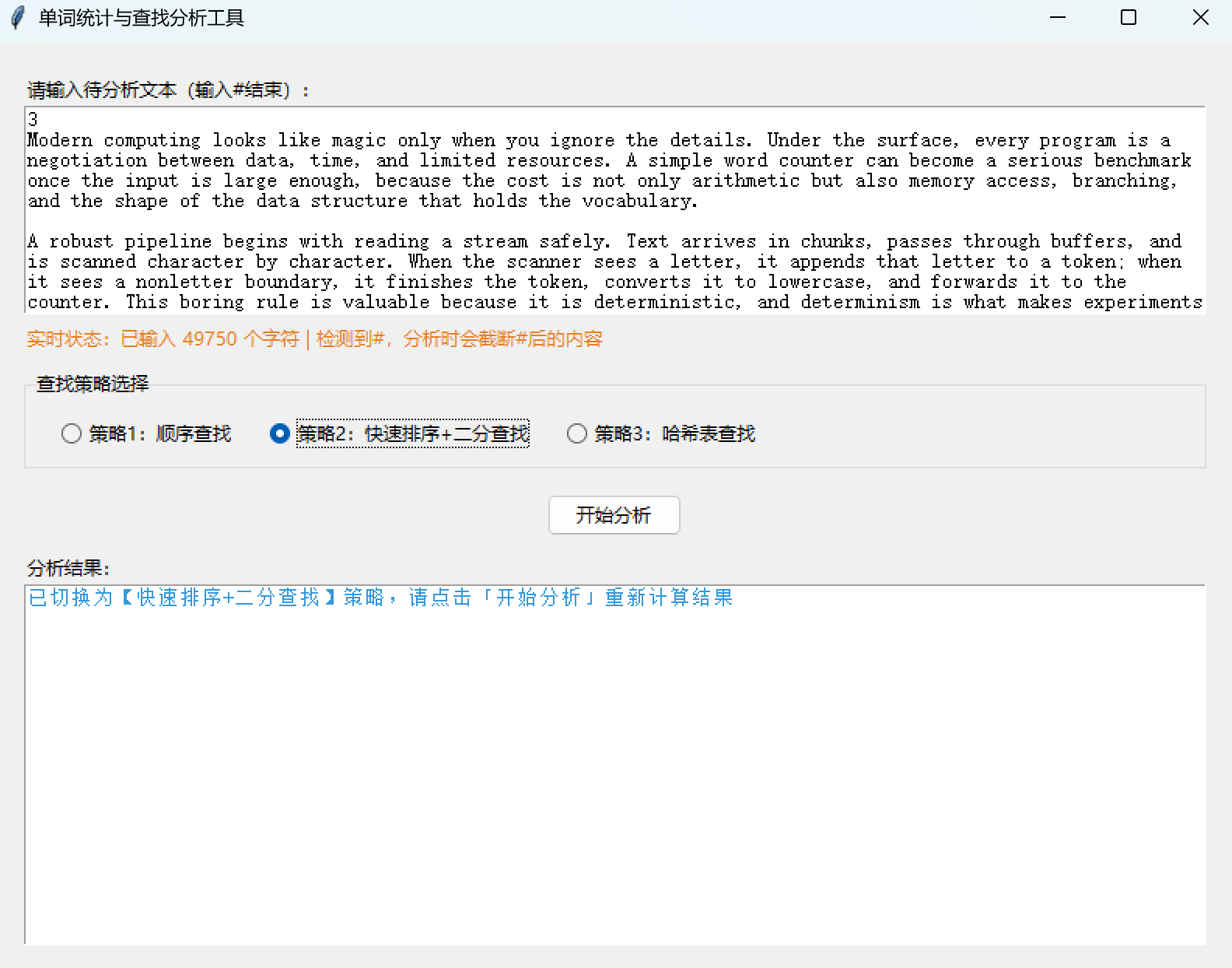
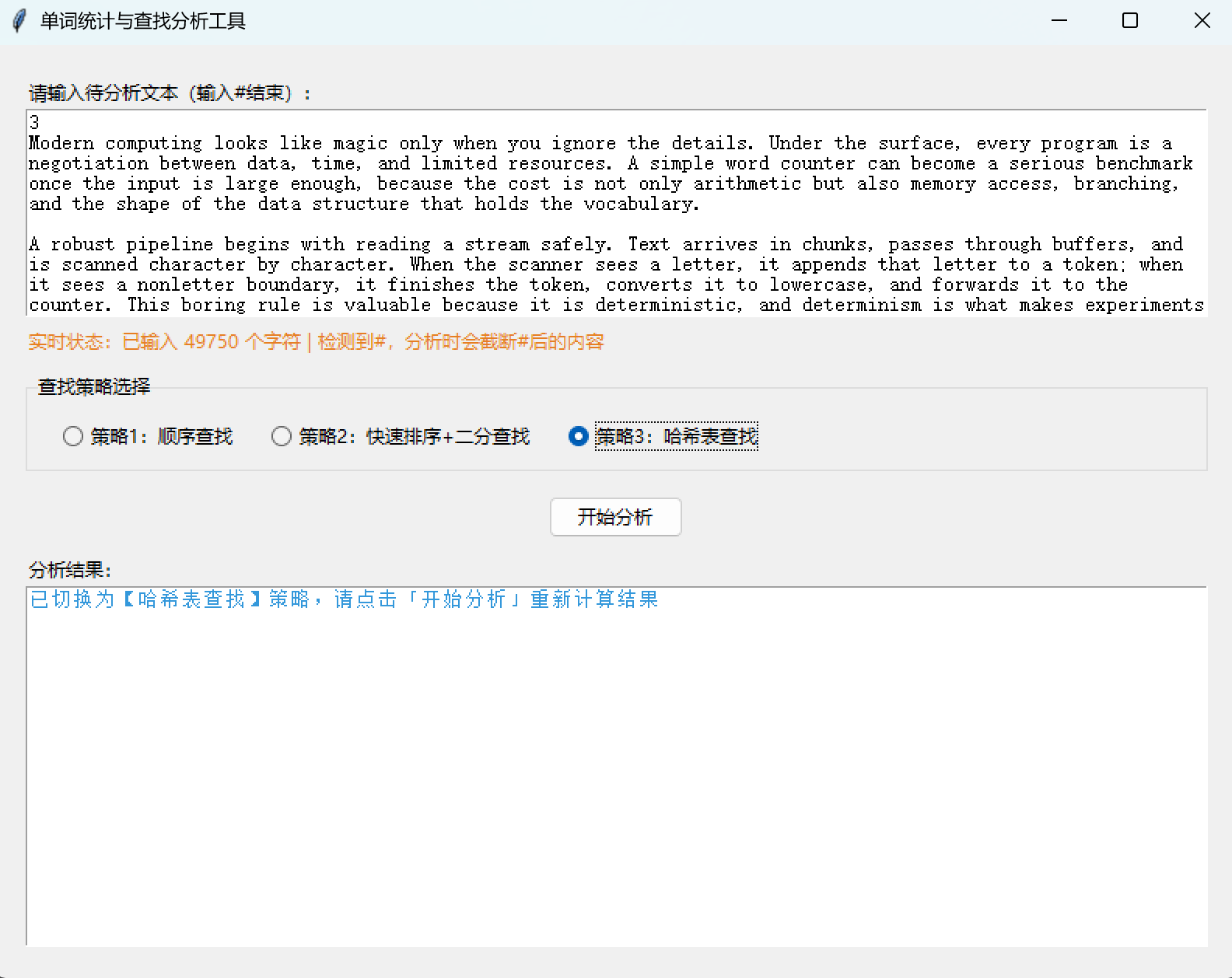
root.mainloop()八、程序运行截图展示
九、打包项目
步骤 1:创建并激活纯净虚拟环境
打开 Anaconda Prompt,执行以下命令(复制粘贴即可):
bash
# 1. 创建仅包含Python 3.10的纯净环境(兼容性最佳,适配tkinter/matplotlib/pandas)
conda create -n word_analyzer_tool python=3.10 -y
# 2. 激活该环境
conda activate word_analyzer_tool
# 3. 仅安装必需依赖(清华源加速,包含matplotlib可视化依赖)
pip install pandas matplotlib openpyxl pyinstaller -i https://pypi.tuna.tsinghua.edu.cn/simple/步骤 2:切换目录并快速打包
bash
# 切换到你的单词统计工具代码所在文件夹(替换为实际路径)
cd C:\Users\你的用户名\PycharmProjects\WordAnalyzerTool
# 用目录模式打包(-D),速度快、体积小、稳定性高;-w隐藏控制台(GUI工具必备);--collect-data 确保matplotlib资源被打包
pyinstaller -w -n 单词统计与查找分析工具 -D --collect-data matplotlib 单词统计与查找分析工具.py💡 额外参数说明:--collect-data matplotlib 是为了确保 matplotlib 的字体、配置等资源被正确打包,避免可视化功能运行报错。
步骤 3:验证结果
- 打包时间:仅需 2-3 分钟(因包含 matplotlib,略长于基础工具);
- exe 位置 :
dist\单词统计与查找分析工具\目录下的单词统计与查找分析工具.exe; - 体积:约 120-180MB(因包含 matplotlib 依赖,对比全局环境打包的 2GB+,大幅精简);
- 功能验证 :双击 exe,测试文本导入 / 输入、策略切换、ASL 可视化、单词统计等核心功能,和原代码完全一致。
十、单词统计与查找分析工具(增强版)
(一)可扩展方向
- 增加 "单词频次排行榜":展示出现次数最多的前 N 个单词;
- 支持文件导入:解析文本文件(.txt),而非仅手动输入;
- 算法对比可视化:用柱状图展示三种策略的 ASL 差异;
- 自定义哈希表大小:允许用户调整 HASH_SIZE,观察冲突率变化;
- 增加单词长度统计:分析文本中单词的平均长度、最长单词等指标。
(二)单词统计与查找分析工具扩展后的Python代码完整实现
python
import tkinter as tk
from tkinter import ttk, messagebox, filedialog
import re
import sys
import matplotlib
# 设置matplotlib后端为TkAgg,适配tkinter
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
from matplotlib.backends.backend_tkagg import FigureCanvasTkAgg
# ===================== 全局常量(基础默认值) =====================
MAX_LINEAR_SIZE = 10000 # 线性表最大容量
DEFAULT_HASH_SIZE = 1009 # 默认哈希表大小
MAX_WORD_LEN = 50 # 单词最大长度
DEFAULT_RANKING_N = 10 # 默认排行榜展示前10个单词
# ===================== 核心算法函数(兼容自定义哈希表大小+性能优化) =====================
def normalize(token: str, pos: list) -> tuple[bool, str]:
"""
标准化单词:跳过非字母字符,提取连续字母并转小写(性能优化版)
:param token: 待处理字符串
:param pos: 当前处理位置(用列表传引用,Python整数不可变)
:return: (是否提取到单词, 标准化后的单词)
"""
start = pos[0]
# 跳过非字母字符(优化循环逻辑)
while start < len(token) and not token[start].isalpha():
start += 1
if start >= len(token):
pos[0] = start
return False, ""
# 提取连续字母(一次性切片,减少循环次数)
end = start
while end < len(token) and token[end].isalpha():
end += 1
pos[0] = end
return True, token[start:end].lower()
def my_hash(word: str, hash_size: int) -> int:
"""Time33哈希函数(适配自定义哈希表大小)"""
h = 0
for char in word:
h = (h << 5) + h + ord(char) # h = h*33 + 字符ASCII
return h % hash_size
def linear_search(linear_list: list, word: str) -> tuple[bool, int]:
"""
顺序查找
:return: (是否找到, 比较次数)
"""
cmp_count = 0
for item in linear_list:
cmp_count += 1
if item["word"] == word:
return True, cmp_count
return False, cmp_count
# 快速排序相关函数(按单词字典序)
def swap_linear_node(linear_list: list, i: int, j: int):
"""交换线性表中的两个元素"""
linear_list[i], linear_list[j] = linear_list[j], linear_list[i]
def partition(linear_list: list, low: int, high: int) -> int:
"""快排分区函数"""
pivot = linear_list[high]["word"]
i = low - 1 # 小于基准的区域边界
for j in range(low, high):
if linear_list[j]["word"] < pivot:
i += 1
swap_linear_node(linear_list, i, j)
swap_linear_node(linear_list, i + 1, high)
return i + 1
def quick_sort(linear_list: list, low: int, high: int):
"""快速排序主函数"""
if low < high:
pi = partition(linear_list, low, high)
quick_sort(linear_list, low, pi - 1)
quick_sort(linear_list, pi + 1, high)
def binary_search(linear_list: list, word: str) -> tuple[bool, int]:
"""
二分查找(需先排序)
:return: (是否找到, 比较次数)
"""
cmp_count = 0
low, high = 0, len(linear_list) - 1
while low <= high:
cmp_count += 1
mid = (low + high) // 2
mid_word = linear_list[mid]["word"]
if mid_word == word:
return True, cmp_count
elif mid_word > word:
high = mid - 1
else:
low = mid + 1
return False, cmp_count
# ===================== 新增工具函数 =====================
def calculate_word_length_stats(word_list: list) -> dict:
"""计算单词长度统计指标"""
if not word_list:
return {
"avg_length": 0.0,
"max_len_word": "",
"max_length": 0,
"min_len_word": "",
"min_length": 0
}
lengths = [len(word["word"]) for word in word_list]
avg_length = sum(lengths) / len(lengths)
max_idx = lengths.index(max(lengths))
min_idx = lengths.index(min(lengths))
return {
"avg_length": round(avg_length, 2),
"max_len_word": word_list[max_idx]["word"],
"max_length": max(lengths),
"min_len_word": word_list[min_idx]["word"],
"min_length": min(lengths)
}
def get_word_ranking(word_list: list, top_n: int) -> list:
"""生成单词频次排行榜(降序)"""
if not word_list:
return []
# 按频次降序排序,频次相同按单词字典序升序
sorted_list = sorted(word_list, key=lambda x: (-x["count"], x["word"]))
# 处理top_n超过列表长度的情况
top_n = min(top_n, len(sorted_list))
return sorted_list[:top_n]
def analyze_all_strategies(input_text: str, hash_size: int) -> dict:
"""批量分析三种策略的ASL,用于可视化"""
# 第一步:解析文本得到所有单词
pos = [0]
token = input_text
all_words = []
while True:
has_word, word = normalize(token, pos)
if not has_word:
break
all_words.append(word)
if not all_words:
return {"strategy1_asl": 0, "strategy2_asl": 0, "strategy3_asl": 0}
# 策略1:顺序查找
linear_list1 = []
for word in all_words:
found, _ = linear_search(linear_list1, word)
if found:
for item in linear_list1:
if item["word"] == word:
item["count"] += 1
break
else:
linear_list1.append({"word": word, "count": 1})
unique1 = len(linear_list1)
total_cmp1 = sum([linear_search(linear_list1, item["word"])[1] for item in linear_list1])
strategy1_asl = total_cmp1 / unique1 if unique1 > 0 else 0
# 策略2:快排+二分
linear_list2 = linear_list1.copy()
quick_sort(linear_list2, 0, len(linear_list2) - 1)
total_cmp2 = sum([binary_search(linear_list2, item["word"])[1] for item in linear_list2])
strategy2_asl = total_cmp2 / unique1 if unique1 > 0 else 0
# 策略3:哈希表
hash_table = [[] for _ in range(hash_size)]
for word in all_words:
h = my_hash(word, hash_size)
found = False
for item in hash_table[h]:
if item["word"] == word:
item["count"] += 1
found = True
break
if not found:
hash_table[h].append({"word": word, "count": 1})
unique3 = sum([len(bucket) for bucket in hash_table])
total_cmp3 = sum([idx + 1 for bucket in hash_table for idx, item in enumerate(bucket)])
strategy3_asl = total_cmp3 / unique3 if unique3 > 0 else 0
return {
"strategy1_asl": round(strategy1_asl, 2),
"strategy2_asl": round(strategy2_asl, 2),
"strategy3_asl": round(strategy3_asl, 2)
}
# ===================== GUI主类(集成所有新增功能) =====================
class WordAnalyzerApp:
def __init__(self, root):
self.root = root
self.root.title("单词统计与查找分析工具(增强版)")
self.root.geometry("1000x800") # 扩大窗口适配新功能
# 添加窗口关闭事件处理(优雅退出)
self.root.protocol("WM_DELETE_WINDOW", self._on_window_close)
# 核心变量
self.strategy_var = tk.StringVar(value="1")
self.hash_size_var = tk.StringVar(value=str(DEFAULT_HASH_SIZE))
self.ranking_n_var = tk.StringVar(value=str(DEFAULT_RANKING_N))
self.all_strategies_asl = {"strategy1_asl": 0, "strategy2_asl": 0, "strategy3_asl": 0}
# 初始化UI
self._setup_ui()
def _setup_ui(self):
"""构建GUI界面(新增功能组件)"""
# 主容器
main_frame = ttk.Frame(self.root, padding="20")
main_frame.pack(fill=tk.BOTH, expand=True)
# 1. 文件导入 + 文本输入区域
file_frame = ttk.Frame(main_frame)
file_frame.pack(fill=tk.X, pady=(0, 5))
# 导入文件按钮
import_btn = ttk.Button(file_frame, text="导入文本文件(.txt)", command=self._import_file)
import_btn.pack(side=tk.LEFT, padx=(0, 10))
# 哈希表大小设置
hash_label = ttk.Label(file_frame, text="哈希表大小:")
hash_label.pack(side=tk.LEFT, padx=(10, 5))
hash_entry = ttk.Entry(file_frame, textvariable=self.hash_size_var, width=10)
hash_entry.pack(side=tk.LEFT, padx=(0, 10))
ttk.Label(file_frame, text="(建议输入质数)").pack(side=tk.LEFT)
# 文本输入区域
input_label = ttk.Label(main_frame, text="请输入待分析文本(输入#结束):")
input_label.pack(anchor=tk.W)
self.text_input = tk.Text(main_frame, height=8, wrap=tk.WORD)
self.text_input.pack(fill=tk.X, pady=(0, 5))
# 实时提示标签
self.input_tip_label = ttk.Label(main_frame, text="", foreground="#666666")
self.input_tip_label.pack(anchor=tk.W)
self.text_input.bind("<<Modified>>", self._on_text_changed)
self.text_input_modified = False
# 2. 策略选择 + 排行榜设置区域
setting_frame = ttk.LabelFrame(main_frame, text="分析设置", padding="10")
setting_frame.pack(fill=tk.X, pady=(10, 5))
# 策略单选按钮
strategy_subframe = ttk.Frame(setting_frame)
strategy_subframe.pack(side=tk.LEFT, padx=10)
ttk.Radiobutton(
strategy_subframe, text="策略1:顺序查找",
variable=self.strategy_var, value="1",
command=self._on_strategy_toggled
).pack(side=tk.LEFT, padx=5)
ttk.Radiobutton(
strategy_subframe, text="策略2:快速排序+二分查找",
variable=self.strategy_var, value="2",
command=self._on_strategy_toggled
).pack(side=tk.LEFT, padx=5)
ttk.Radiobutton(
strategy_subframe, text="策略3:哈希表查找",
variable=self.strategy_var, value="3",
command=self._on_strategy_toggled
).pack(side=tk.LEFT, padx=5)
# 排行榜设置
ranking_subframe = ttk.Frame(setting_frame)
ranking_subframe.pack(side=tk.RIGHT, padx=10)
ttk.Label(ranking_subframe, text="频次排行榜前N个单词:").pack(side=tk.LEFT, padx=5)
ranking_entry = ttk.Entry(ranking_subframe, textvariable=self.ranking_n_var, width=5)
ranking_entry.pack(side=tk.LEFT, padx=5)
# 3. 功能按钮区域
btn_frame = ttk.Frame(main_frame)
btn_frame.pack(fill=tk.X, pady=(10, 10))
# 开始分析按钮
analyze_btn = ttk.Button(btn_frame, text="开始分析", command=self._on_analyze_clicked)
analyze_btn.pack(side=tk.LEFT, padx=(0, 10))
# ASL可视化按钮
asl_chart_btn = ttk.Button(btn_frame, text="ASL算法对比可视化", command=self._show_asl_chart)
asl_chart_btn.pack(side=tk.LEFT)
# 4. 结果显示区域
result_label = ttk.Label(main_frame, text="分析结果:")
result_label.pack(anchor=tk.W)
self.result_display = tk.Text(main_frame, height=12, wrap=tk.WORD, state=tk.DISABLED)
self.result_display.pack(fill=tk.BOTH, expand=True)
def _import_file(self):
"""导入txt文本文件"""
file_path = filedialog.askopenfilename(
title="选择文本文件",
filetypes=[("文本文件", "*.txt"), ("所有文件", "*.*")]
)
if not file_path:
return
try:
with open(file_path, "r", encoding="utf-8") as f:
content = f.read()
# 清空原有内容,插入文件内容
self.text_input.delete("1.0", tk.END)
self.text_input.insert(tk.END, content)
messagebox.showinfo("成功", f"已导入文件:{file_path}")
except Exception as e:
messagebox.showerror("错误", f"文件导入失败:{str(e)}")
def _on_text_changed(self, event):
"""文本输入实时监控"""
if self.text_input_modified:
return
self.text_input_modified = True
input_text = self.text_input.get("1.0", tk.END).strip()
char_count = len(input_text)
has_sharp = "#" in input_text
tip = f"实时状态:已输入 {char_count} 个字符 | "
if has_sharp:
tip += "检测到#,分析时会截断#后的内容"
self.input_tip_label.config(foreground="#E67E22")
else:
tip += "未检测到#,将分析全部文本"
self.input_tip_label.config(foreground="#666666")
self.input_tip_label.config(text=tip)
self.text_input.edit_modified(False)
self.text_input_modified = False
def _on_strategy_toggled(self):
"""策略切换反馈"""
strategy_id = self.strategy_var.get()
strategy_names = {
"1": "顺序查找",
"2": "快速排序+二分查找",
"3": "哈希表查找"
}
strategy_name = strategy_names.get(strategy_id, "未知")
self._update_result(f"已切换为【{strategy_name}】策略,请点击「开始分析」重新计算结果", "#3498DB")
def _update_result(self, text: str, color: str = "#000000"):
"""更新结果显示区"""
self.result_display.config(state=tk.NORMAL)
self.result_display.delete("1.0", tk.END)
self.result_display.insert(tk.END, text)
self.result_display.config(foreground=color, state=tk.DISABLED)
def _show_asl_chart(self):
"""绘制ASL算法对比柱状图"""
input_text = self.text_input.get("1.0", tk.END).strip()
if "#" in input_text:
input_text = input_text.split("#")[0]
if not input_text.strip():
messagebox.showwarning("提示", "请先输入/导入文本内容!")
return
# 验证哈希表大小输入
try:
hash_size = int(self.hash_size_var.get())
if hash_size <= 0:
raise ValueError
except ValueError:
messagebox.showerror("错误", "哈希表大小必须为正整数!")
return
# 批量分析三种策略的ASL
self.all_strategies_asl = analyze_all_strategies(input_text, hash_size)
# 创建图表窗口
chart_window = tk.Toplevel(self.root)
chart_window.title("ASL算法对比柱状图")
chart_window.geometry("600x400")
# 关键修改:字体设置移到创建图表之前,确保生效
plt.rcParams["font.family"] = ["SimHei", "Microsoft YaHei", "WenQuanYi Micro Hei"]
plt.rcParams["axes.unicode_minus"] = False # 解决负号显示问题
# 绘制柱状图
fig, ax = plt.subplots(figsize=(8, 5))
strategies = ["顺序查找", "快排+二分查找", "哈希表查找"]
asl_values = [
self.all_strategies_asl["strategy1_asl"],
self.all_strategies_asl["strategy2_asl"],
self.all_strategies_asl["strategy3_asl"]
]
ax.bar(strategies, asl_values, color=['#FF6B6B', '#4ECDC4', '#45B7D1'])
# 优化y轴刻度(解决数据差异过大导致小值被压缩的问题)
ax.set_yscale("log") # 改用对数刻度,适配ASL的数量级差异
ax.set_xlabel("查找策略")
ax.set_ylabel("平均查找长度(ASL,对数刻度)")
ax.set_title("不同查找策略的ASL对比")
ax.grid(axis='y', linestyle='--', alpha=0.7)
# 调整数值标签位置(适配对数刻度)
for i, v in enumerate(asl_values):
# 数值标签显示在柱子顶部,避免重叠
ax.text(i, v * 1.1, f"{v:.2f}", ha='center', va='bottom', fontsize=10)
# 将图表嵌入tkinter窗口
canvas = FigureCanvasTkAgg(fig, master=chart_window)
canvas.draw()
canvas.get_tk_widget().pack(fill=tk.BOTH, expand=True)
def _on_analyze_clicked(self):
"""分析按钮点击事件(集成所有新增统计)"""
# 1. 输入验证与预处理
input_text = self.text_input.get("1.0", tk.END).strip()
strategy = int(self.strategy_var.get())
if "#" in input_text:
input_text = input_text.split("#")[0]
if not input_text.strip():
self._update_result("请输入/导入待分析的文本内容!", "#E74C3C")
return
# 验证哈希表大小输入
try:
hash_size = int(self.hash_size_var.get())
if hash_size <= 0:
raise ValueError
except ValueError:
messagebox.showerror("错误", "哈希表大小必须为正整数!")
return
# 验证排行榜N值输入
try:
ranking_n = int(self.ranking_n_var.get())
if ranking_n <= 0:
raise ValueError
except ValueError:
messagebox.showerror("错误", "排行榜N值必须为正整数!")
return
# 2. 初始化数据结构
linear_list = []
hash_table = [[] for _ in range(hash_size)]
total_words = 0
unique_words = 0
total_cmp = 0
word_length_records = [] # 存储所有单词(用于长度统计)
# 3. 解析并统计单词
pos = [0]
token = input_text
while True:
has_word, word = normalize(token, pos)
if not has_word:
break
total_words += 1
# 策略1/2:线性表处理
if strategy in (1, 2):
found, _ = linear_search(linear_list, word)
if found:
for item in linear_list:
if item["word"] == word:
item["count"] += 1
break
else:
linear_list.append({"word": word, "count": 1})
word_length_records = linear_list # 同步到长度统计列表
# 策略3:哈希表处理
elif strategy == 3:
h = my_hash(word, hash_size)
found = False
for item in hash_table[h]:
if item["word"] == word:
item["count"] += 1
found = True
break
if not found:
hash_table[h].append({"word": word, "count": 1})
# 整理哈希表数据用于长度统计
word_length_records = []
for bucket in hash_table:
word_length_records.extend(bucket)
# 4. 计算核心指标
asl = 0.0
if strategy == 1:
unique_words = len(linear_list)
total_cmp = sum([linear_search(linear_list, item["word"])[1] for item in linear_list])
asl = total_cmp / unique_words if unique_words > 0 else 0.0
elif strategy == 2:
unique_words = len(linear_list)
if unique_words > 0:
quick_sort(linear_list, 0, unique_words - 1)
total_cmp = sum([binary_search(linear_list, item["word"])[1] for item in linear_list])
asl = total_cmp / unique_words if unique_words > 0 else 0.0
elif strategy == 3:
unique_words = sum([len(bucket) for bucket in hash_table])
total_cmp = sum([idx + 1 for bucket in hash_table for idx, item in enumerate(bucket)])
asl = total_cmp / unique_words if unique_words > 0 else 0.0
# 5. 计算新增统计指标
length_stats = calculate_word_length_stats(word_length_records)
ranking_list = get_word_ranking(word_length_records, ranking_n)
# 6. 格式化结果展示
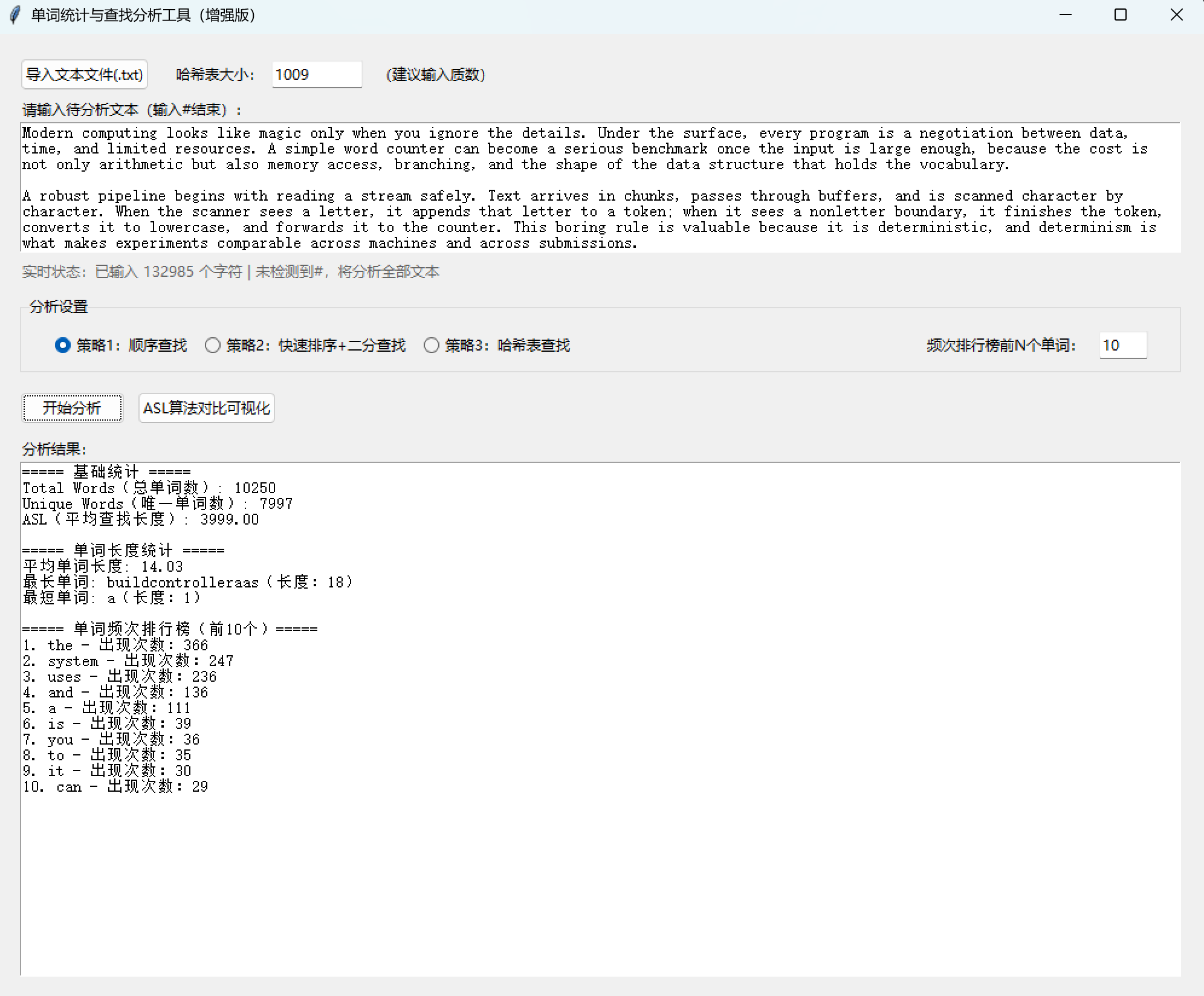
result = f"===== 基础统计 =====\n"
result += f"Total Words(总单词数): {total_words}\n"
result += f"Unique Words(唯一单词数): {unique_words}\n"
result += f"ASL(平均查找长度): {asl:.2f}\n\n"
result += f"===== 单词长度统计 =====\n"
result += f"平均单词长度: {length_stats['avg_length']}\n"
result += f"最长单词: {length_stats['max_len_word']}(长度:{length_stats['max_length']})\n"
result += f"最短单词: {length_stats['min_len_word']}(长度:{length_stats['min_length']})\n\n"
result += f"===== 单词频次排行榜(前{ranking_n}个)=====\n"
if ranking_list:
for idx, item in enumerate(ranking_list, 1):
result += f"{idx}. {item['word']} - 出现次数:{item['count']}\n"
else:
result += "暂无单词数据\n"
self._update_result(result)
def _on_window_close(self):
"""优雅关闭窗口,避免强制退出导致的中断报错"""
self.root.quit()
self.root.destroy()
# ===================== 主函数(捕获中断+优雅退出) =====================
if __name__ == "__main__":
try:
root = tk.Tk()
app = WordAnalyzerApp(root)
root.mainloop()
except KeyboardInterrupt:
print("程序已被用户手动终止,正在优雅退出...")
root.quit()
root.destroy()
except Exception as e:
print(f"程序运行出错:{str(e)}")
sys.exit(1)(三)核心新增功能说明
1. 自定义哈希表大小
- 在 UI 中新增哈希表大小输入框,默认值为 1009,支持用户自定义;
- 增加输入验证(必须为正整数),避免无效输入;
- 核心哈希函数
my_hash新增hash_size参数,适配自定义大小。
2. 文件导入功能
- 新增 "导入文本文件 (.txt)" 按钮,支持选择本地 txt 文件;
- 处理文件读取异常(编码、文件不存在等),给出友好提示;
- 导入后自动将文件内容填充到文本输入框。
3. 单词长度统计
- 新增
calculate_word_length_stats函数,计算:- 平均单词长度;
- 最长单词(及长度);
- 最短单词(及长度);
- 分析结果中单独展示长度统计模块,数据格式化输出。
4. 单词频次排行榜
- 新增排行榜 N 值输入框(默认前 10),支持自定义展示数量;
- 新增
get_word_ranking函数,按频次降序排序(频次相同按单词字典序); - 处理 N 值超过唯一单词数的边界情况,避免报错。
5. ASL 算法对比可视化
- 集成 matplotlib,适配 tkinter 后端;
- 新增
analyze_all_strategies函数,批量计算三种策略的 ASL; - 点击 "ASL 算法对比可视化" 按钮,弹出独立窗口展示柱状图,直观对比三种策略的 ASL 差异;
- 柱状图添加数值标签、网格线,提升可读性。
(四)使用注意事项
- 运行前需安装 matplotlib:
pip install matplotlib; - 哈希表大小建议输入质数(如 1009、997 等),可减少哈希冲突;
- 可视化功能需先执行文本分析,确保有有效数据;
- 支持的文本文件编码为 UTF-8,若导入其他编码文件(如 GBK),可手动修改
_import_file函数中的编码参数。
(五)程序运行截图展示
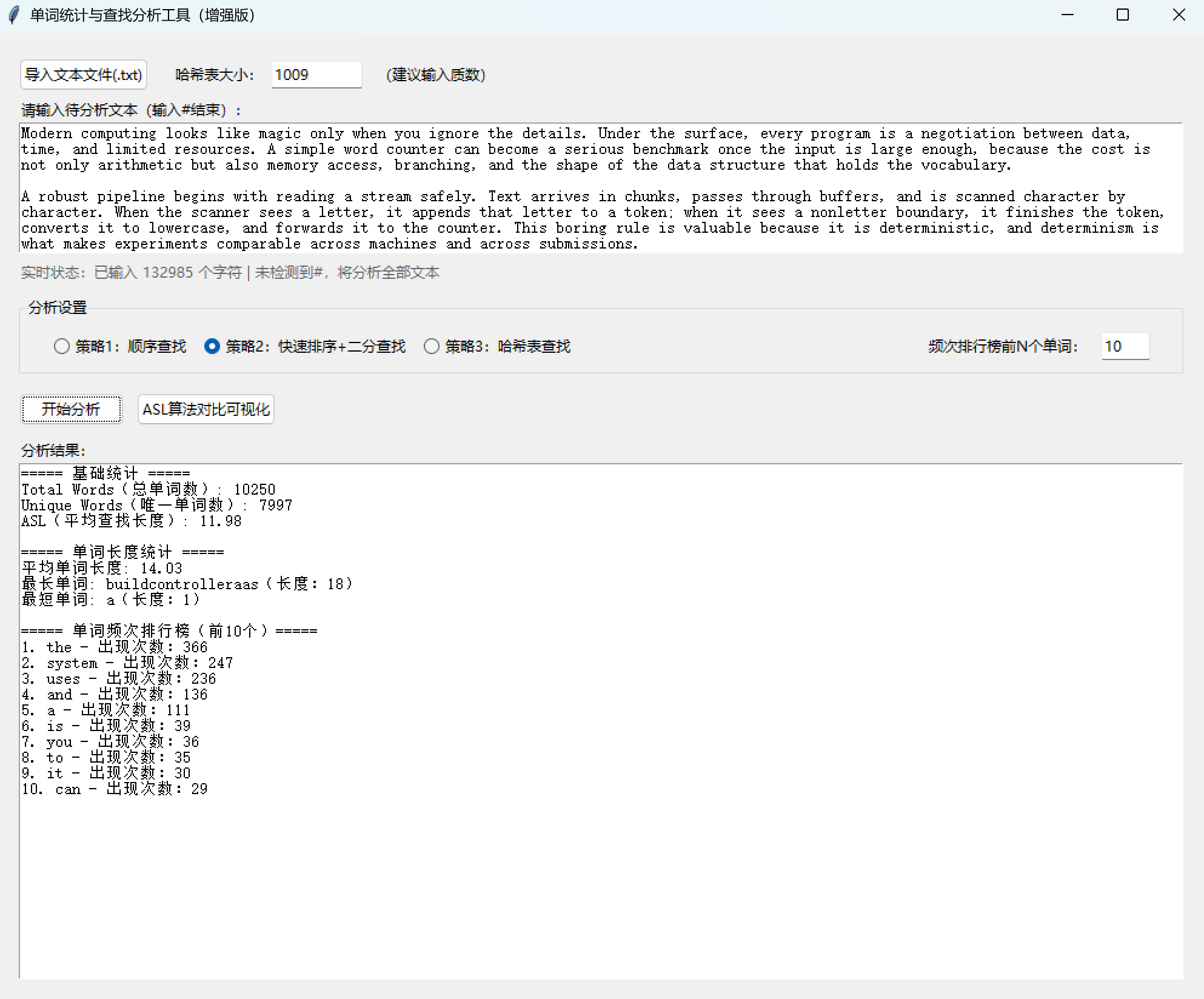
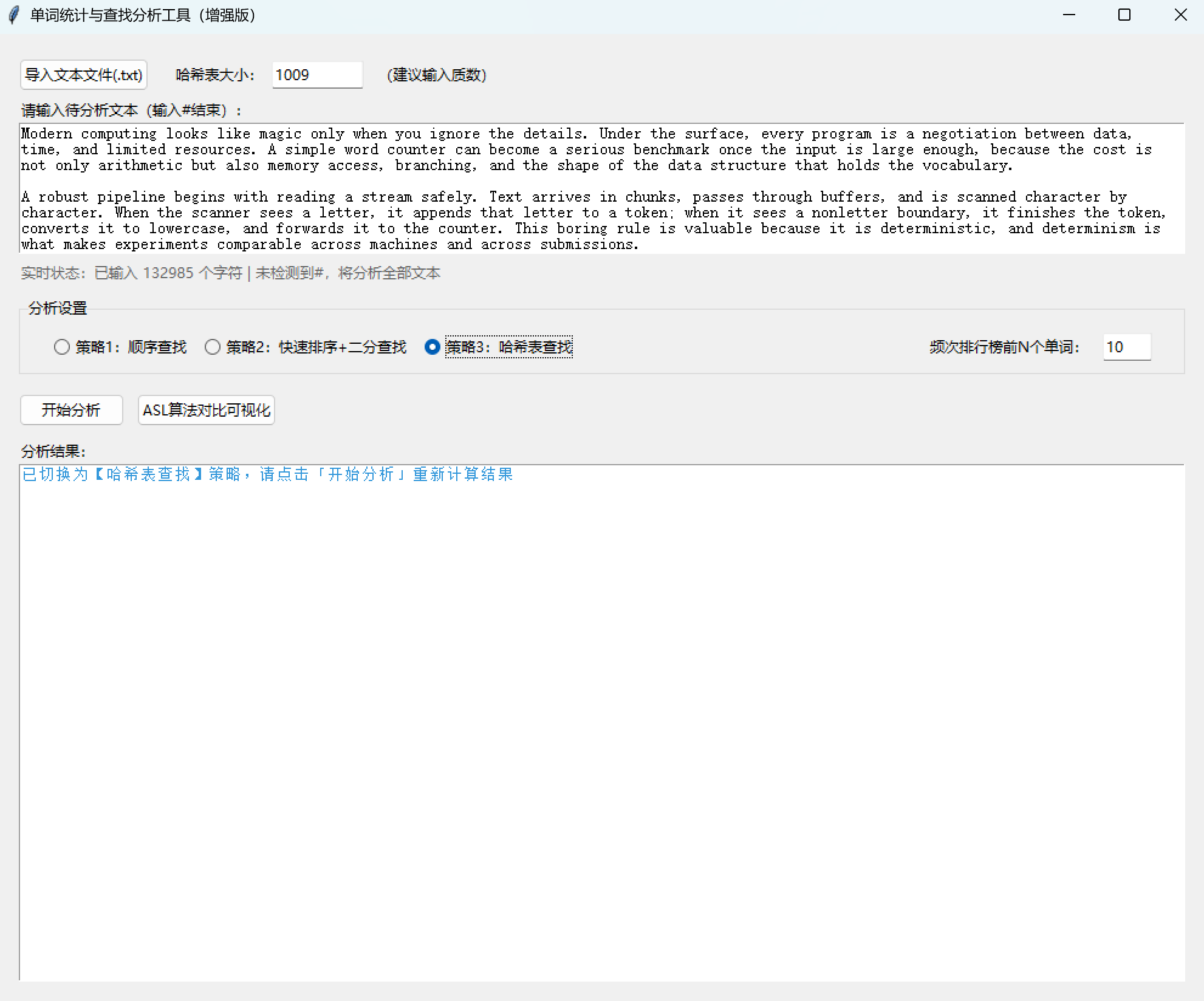
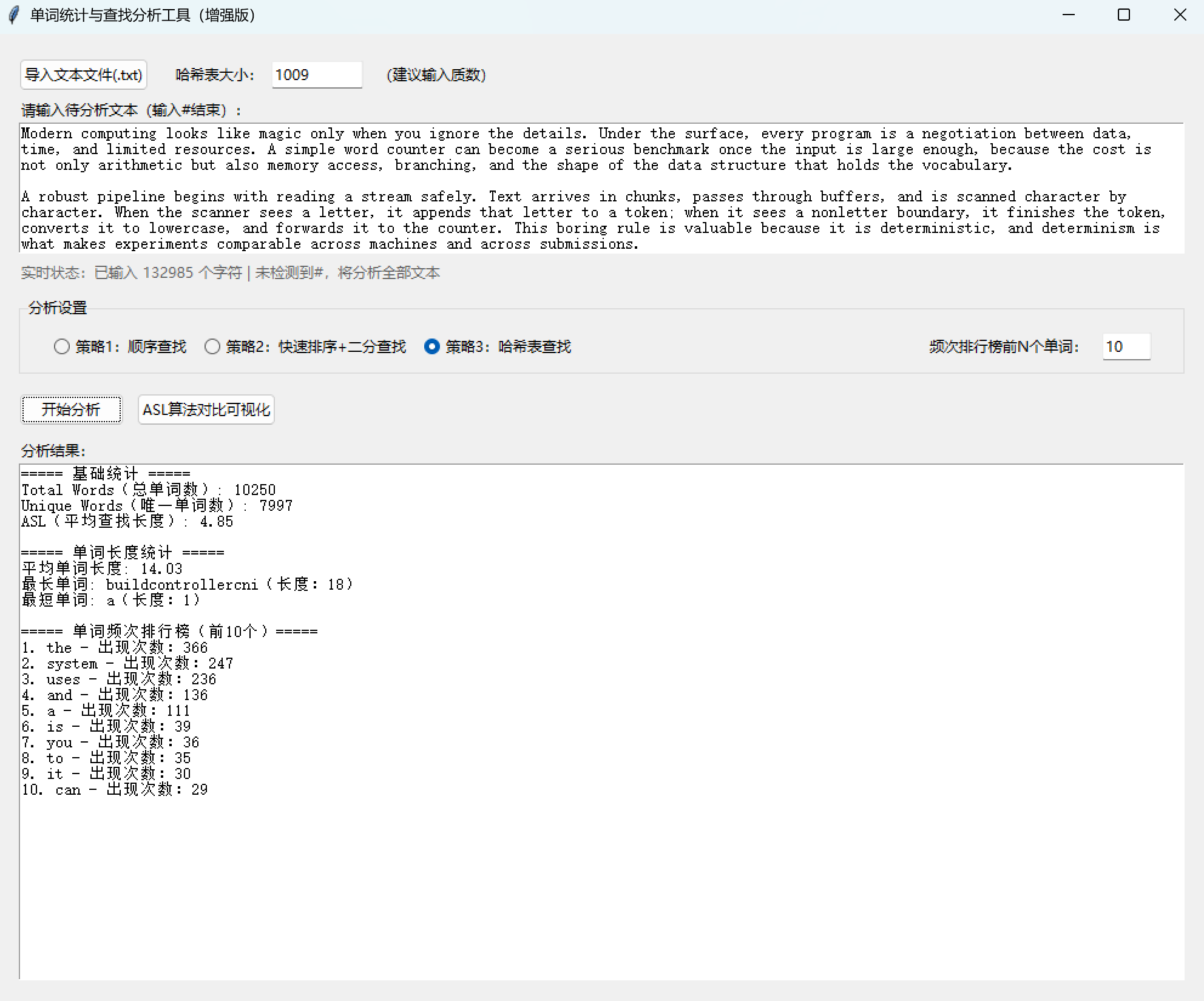
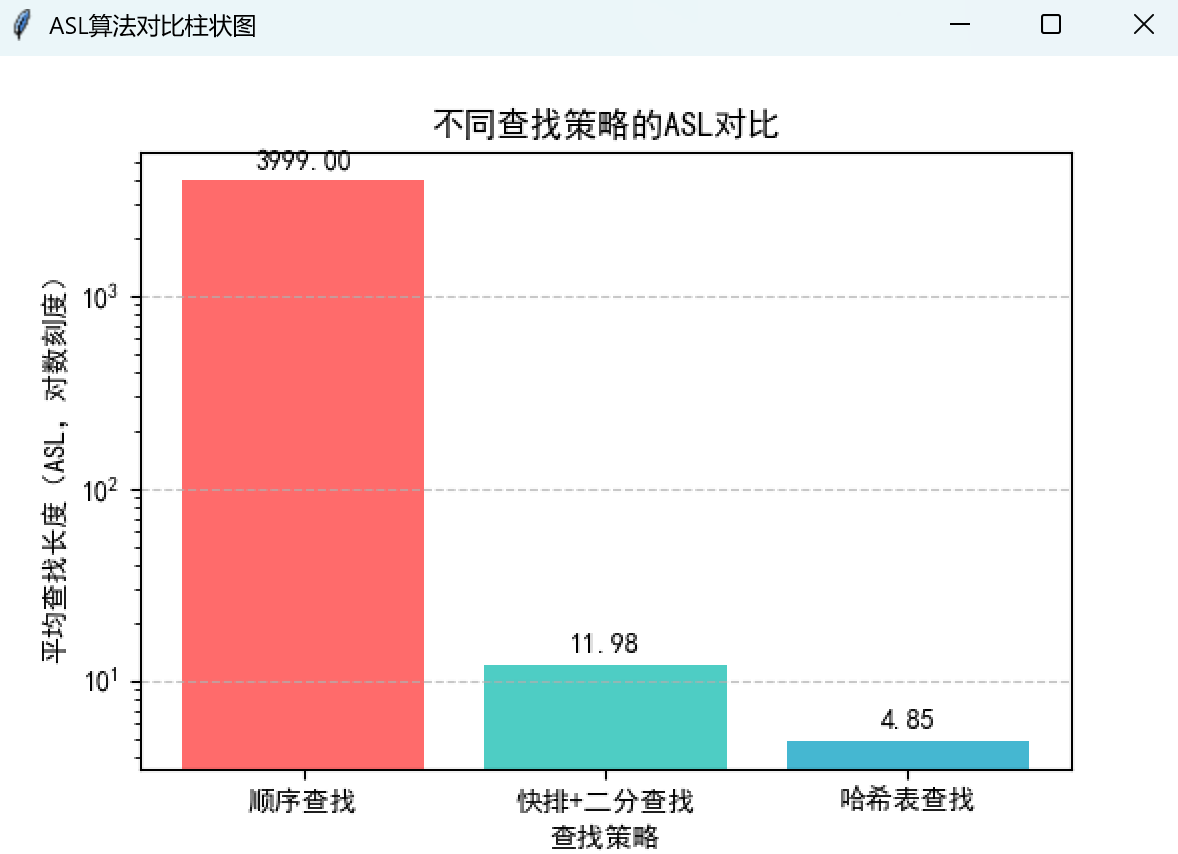
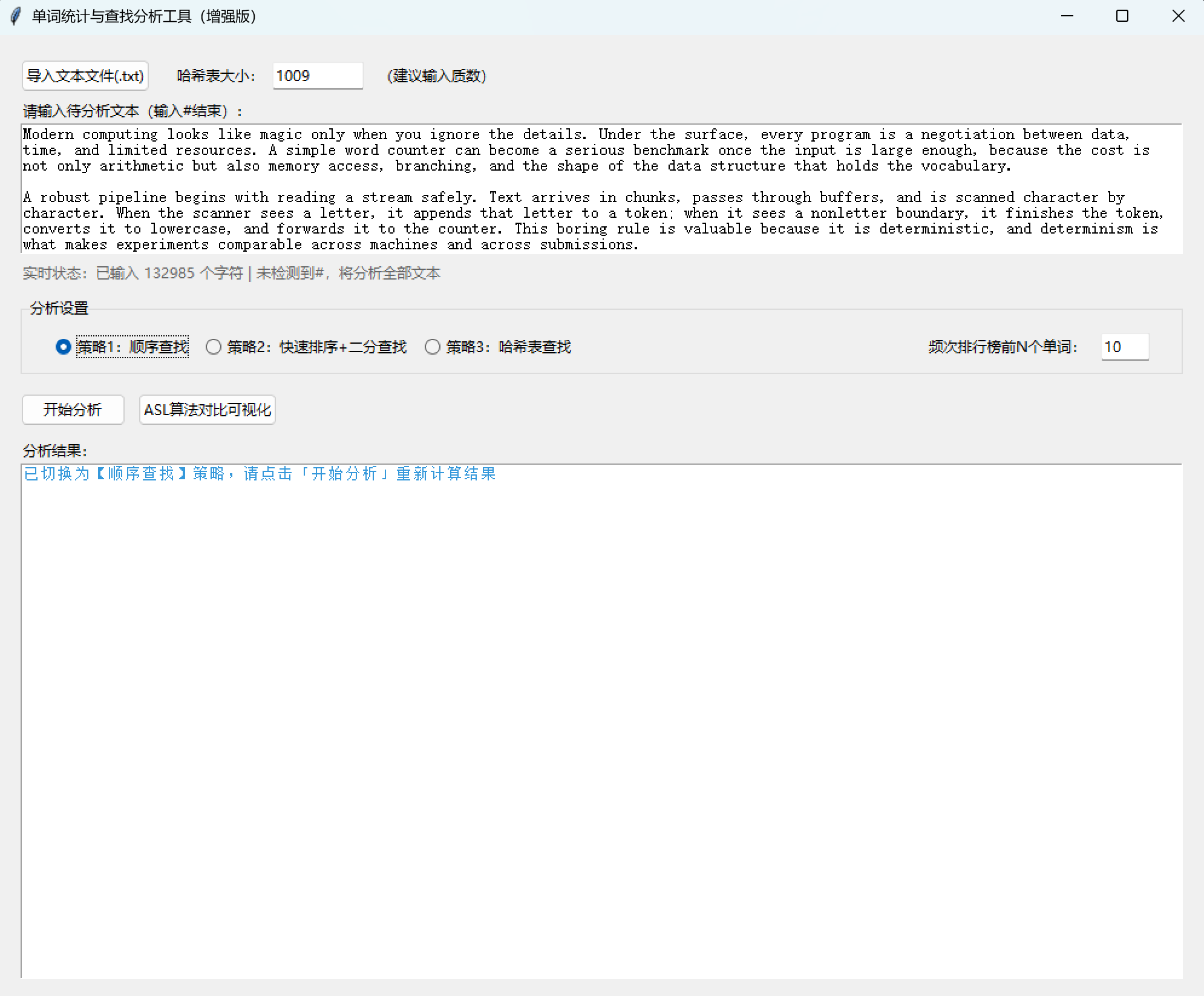
(六)打包项目
根据本文的打包项目的方法,扩展版和原始版的代码必须在同一目录下,可以直接运行下面命令:
python
pyinstaller -w -n 单词统计与查找分析工具(增强版) -D --collect-data matplotlib 单词统计与查找分析工具扩展版.py
十一、总结
本文介绍了一款单词统计与查找分析工具的设计与实现。该工具支持三种查找策略(顺序查找、快速排序+二分查找、哈希表查找),可计算文本中的单词总数、唯一单词数和平均查找长度(ASL)。工具采用Python开发,包含核心算法层和GUI交互层,具有文本标准化处理、实时状态提示和多策略对比功能。扩展版新增了文件导入、单词长度统计、频次排行榜和ASL可视化等功能,支持自定义哈希表大小。文章详细阐述了工具的技术选型、架构设计、核心算法实现和测试优化过程,并提供了完整的Python代码实现和打包方法。