CATNet 论文地址:Learning to Aggregate Multi-Scale Context for Instance Segmentation in Remote Sensing Images.
代码 GitHub 地址:Context Aggregation Network.
算法介绍
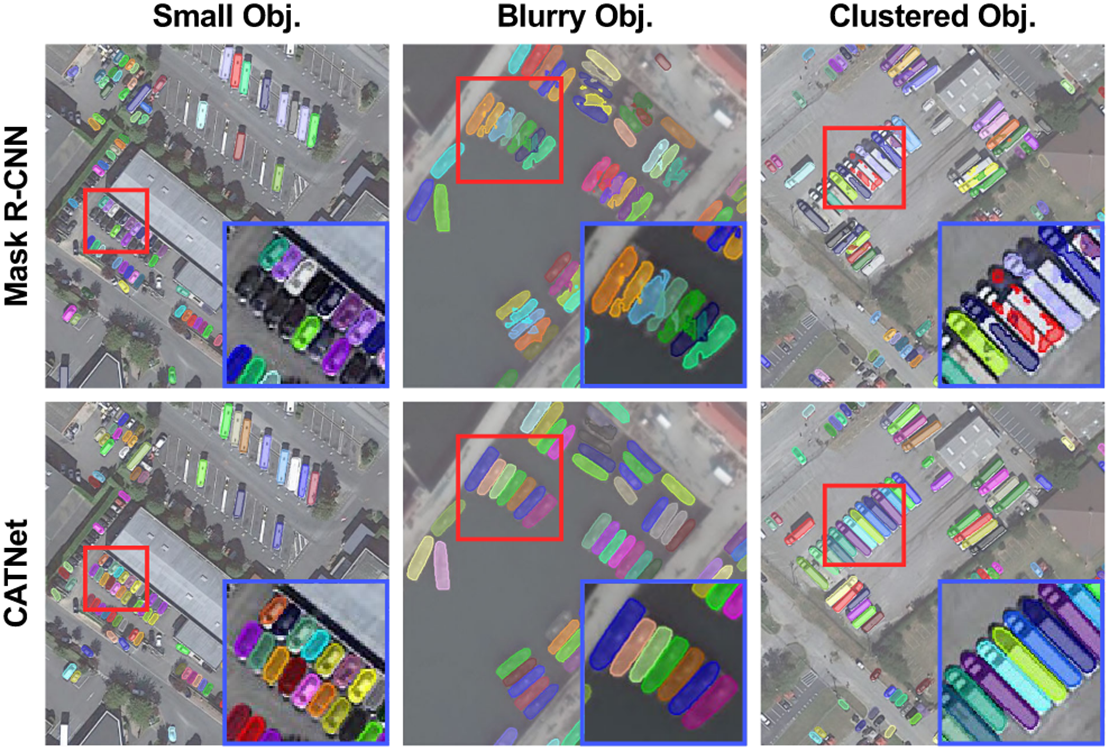
文章指出之前的上下文学习只在空间层面,核心思想是图像的上下文应该包括特征、空间和实例三个方面,因此对应地提出了三个轻量级即插即用模块组成 CATNet 学习上下文,分别是DenseFPN、SCP(Spatial Context Pyramid) 和 HRoIE(hierarchical region of interest extractor)。通过这三个模块,CATNet 可以通过相同或相似类(飞机和直升机),或者相似语义类(船和港口)辅助学习,最终结果如下:
CATNet 的架构如图,(a), (b), © 分别就是上述的三个模块。
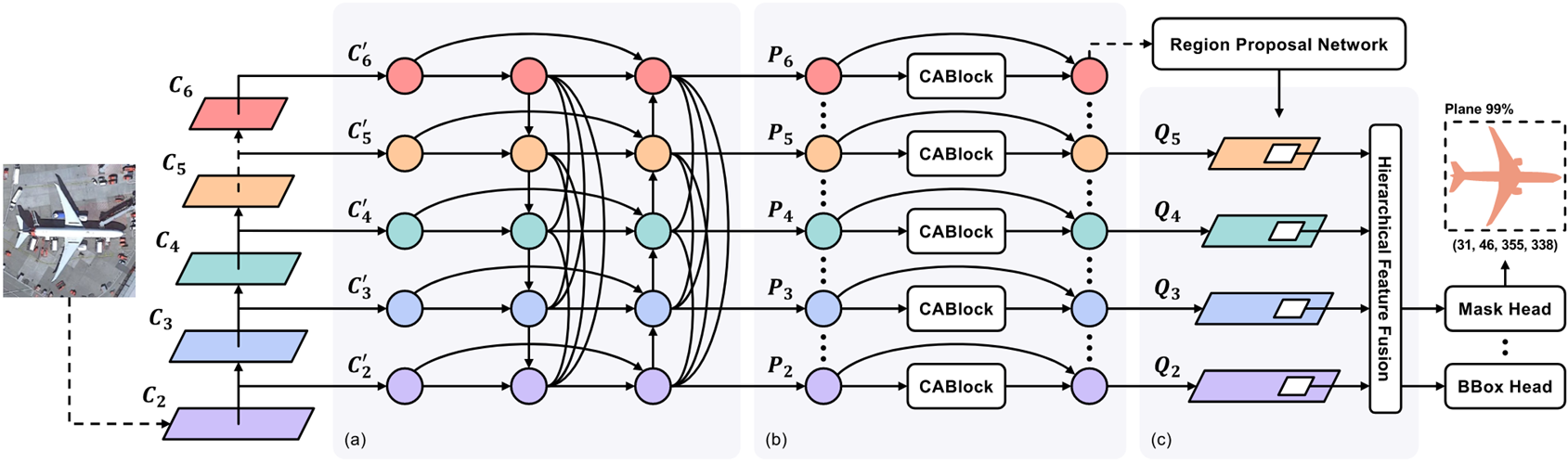
下面是三个模块的内容。
DenseFPN
C2 ~ C6 是骨干网络(如 ResNet50)每个阶段的卷积输出,用 C 2 ′ C_2' C2′ ~ C 6 ′ C_6' C6′ 这些 1 x 1 卷积将前面的输出统一下采样到通道数为256,然后通过残差连接 + cross-level 密集连接 + 特征重加权进行上下文学习,具体模块内容如下:
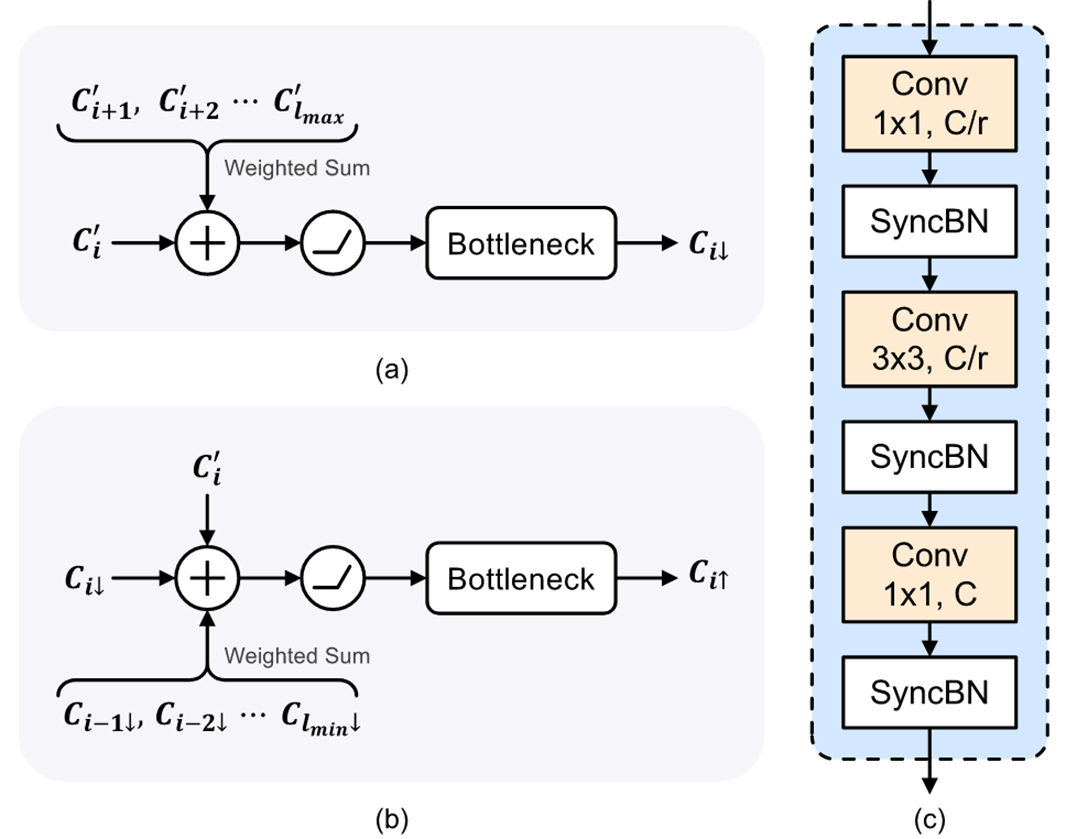
SCP
从整个特征图中聚合特征学习,并使用自适应权重将它们组合到每个像素中。SCP 可以借助全局上其他相同类或相同语义的目标进行学习,其模块如下:
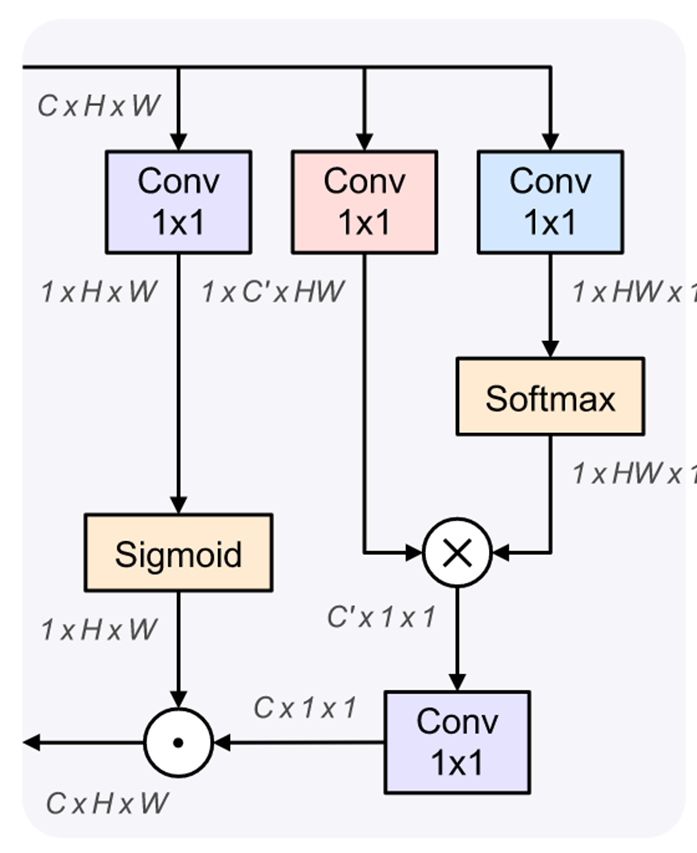
其中 sigmoid 的输出由于是 (0, 1),所以可以被视为应该从全局上下文中聚合的信息的比率,例如当这里不需要其他全局信息时,学到的 sigmoid 应该是 0,越需要则越大。
HRoIE
最后通过提议框的上下文学习来融合特征,模块如下:
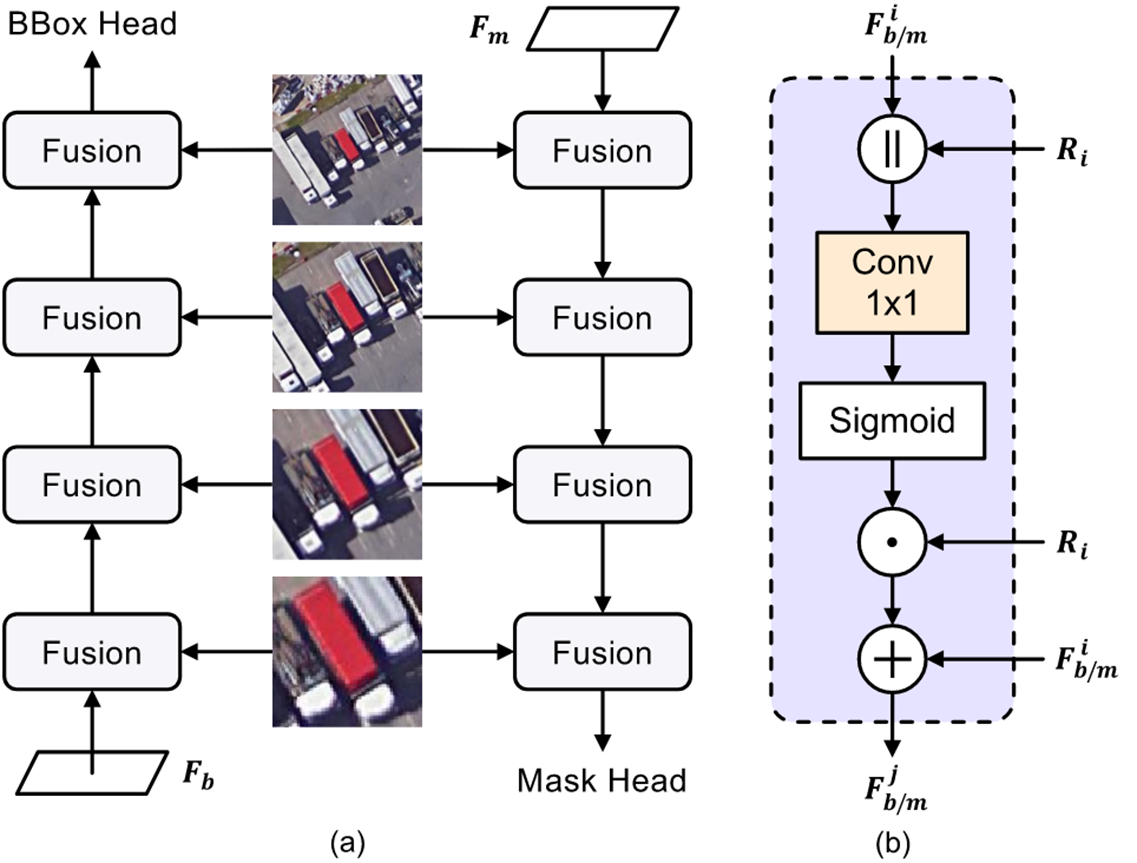
其中 Ri 是通过 RPN 生成的提议框,F 是特征图。
环境配置
我在直接使用开源代码中的 requirements.txt 时下载的 cuda 版本并不是需要的 11.8,因此手动地下载列出来的环境。
其中 mmcv 我下载的是 2.0.1 版本。pytorch 是 2.0.1,但是在下载 torchvision 0.15.0 时说版本不匹配,需要 pytorch 2.0.0,我下载了 torchvision 0.15.1,成功了,但是它竟然自己把 pytorch 版本降到了 2.0.0+cu117,但是我需要 cuda 11.8,所以又得重新安装一次 pytorch 2.0.1,然后就好了。
是不是可以一开始就不按 README 推荐的安装,直接安 pytorch 2.0.0 应该也没问题吧?
配置完成后输入 export PYTHONPATH=$PWD:$PYTHONPATH 导入 python 路径。
使用 mim train mmdet ./configs/vhr/cat_mask_rcnn_r50_aug_6x_vhr.py --gpus 2 --launcher pytorch 训练。
遇到了显存溢出的报错,准备调整一下 batch_size,但是这个用 MMDet 组织的代码跟以前纯 pytorch 的结构完全不同。
在两个地方分别找到了 batch_size。一个是 CATNet/configs/datasets/vhr.py 中的 train_dataloader 中有 batch_size=2,另一个地方是 CATNet/configs/schedules/schedule_3x.py 中有 auto_scale_lr = dict(base_batch_size=8)。
根据 ChatGPT 的回答,auto_scale_lr 是用来根据实际的全局批次大小调整学习率的,公式为 a d j u s t e d _ l r = o r i g i n a l _ l r × a c t u a l _ b a t c h _ s i z e b a s e _ b a t c h _ s i z e . adjusted\_lr = original\_lr \times \frac{actual\_batch\_size}{base\_batch\_size}. adjusted_lr=original_lr×base_batch_sizeactual_batch_size.
其中 a c t u a l _ b a t c h _ s i z e = b a t c h _ s i z e × n u m _ g p u s actual\_batch\_size = batch\_size \times num\_gpus actual_batch_size=batch_size×num_gpus,例如我的 batch_size 是 2,使用 2 个 GPU,调整后的学习率就是原学习率是一半。
下载 NWPU VHR-10 数据集以及在它上面预训练的模型进行测试。
使用 mim test mmdet ./configs/vhr/cat_mask_rcnn_r50_aug_6x_vhr.py --checkpoint ./weights/cat_mask_rcnn_r50_aug_6x_vhr-599b2304.pth --gpus 2 --launcher pytorch 测试模型,遇到报错 FormatCode() got an unexpected keyword argument 'verify',只需要把 yapf 的版本从 0.43.2 降到 0.40.0 即可。
复现
使用一张自制图像测试
由于 VHR 数据集也是 COCO 格式,所以用之前复现 RefSegFormer 时自制的那张照片和注释进行复现。
- 在
CATNet/data下创建 test 文件夹,仿照 vhr 分别创建 annotations 和 image 文件夹并将自制的放进去。 - 在
CATNet/configs下创建文件夹 test,并将 vhr 的两个文件复制过来后缀名改为 test。 - 把
CATNet/configs/test/cat_mask_rcnn_r50_6x_test.py的检测头数从 10 改为 1,_base_部分 vhr 改为 test。 - 修改
CATNet/configs/test/cat_mask_rcnn_r50_aug_6x_test.py的_base_部分。 - 在
CATNet/configs/_base_/datasets里创建 test.py,修改 dataset_type、data_root 和 图像高宽 batch_size。 - 在
CATNet/datasets下创建 test.py,修改类名为 TestDataset,修改类信息为'classes': ('road')。 - 在
CATNet/datasets/__init__.py中添加 TestDataset,否则会报错TestDataset is not in the dataset registry。
使用 mim train mmdet ./configs/test/cat_mask_rcnn_r50_6x_test.py --gpus 1 --launcher pytorch 训练。
在训练后发现什么都检测不到,测试时会报错 ERROR:The testing results of the whole dataset is empty,这个错误看样子也是因为没有检测结果而引出的。因此通过调参,提高学习率,降低 nms 阈值等。
下面是调参时需要更改的部分:
- 在
CATNet/configs/_base_/models/下创建模型的 py 文件,例如仿照cat_mask_rcnn_r50_fpn.py,并调整其中的模型参数(如 num 阈值等)。 - 在
CATNet/configs/_base_/schedules/下创建schedule_3x_test.py,仿照schedule_3x.py,调整其中的训练参数(如学习率等)。 - 把
CATNet/configs/test/cat_mask_rcnn_r50_6x_test.py的_base_部分修改为更改后的路径文件名。
使用 mim test mmdet ./work_dirs/cat_mask_rcnn_r50_6x_test/cat_mask_rcnn_r50_6x_test.py --checkpoint ./work_dirs/cat_mask_rcnn_r50_6x_test/epoch_80.pth --gpus 1 --launcher pytorch 测试。
注意这里的
cat_mask_rcnn_r50_6x_test.py和 训练时的不一样,这个路径在work_dirs里,是自动生成的,它在训练的配置文件的基础上添加了可视化等其他配置。
要得到可视化结果,也需要在训练后的 cat_mask_rcnn_r50_6x_test.py 中找到 default_hooks,在 visualization=dict(type='DetVisualizationHook', _scope_='mmdet') 中加上 draw=True 即可。
使用 Moroccan 数据集复现
先把 Moroccan 进行划分,前 189 张作为验证集,其余作为训练集,生成对应的 json 文件,与图片一起放到 CATNet/data/Moroccan 下。
结果发现 Acc 很高,有接近 100%,但 mAP 很低,只有 0.07 左右。分析原因和解决方法如下:
- 背景区域占据大量像素,且类别只有一种,这种情况更应该使用 IoU 而不是 mAP 作为指标。
- 查看了一些可视化结果,发现有不少假阳性输出,可以降低 NMS 阈值试试,因为背景很大所以通常 NMS 进行比较的两个框都有很大重叠,如果 NMS 阈值设置的高的话可能不会被去除,造成多框问题。
使用 RLD 数据集复现
原数据集是 YOLO 格式的,标注内容为 class x1 y1 x2 y2 x3 y3 x4 y4。有若干个场景,并没有划分训练集和验证集。
我选取 15% 用于验证,其余用于训练。由于每个场景都是由远到近的顺序,因此需要平均抽取每张验证图像。
假设每个场景的图像数是 N,用于验证的就是 15 % N 15\%N 15%N,为了平均抽取,每隔 N 15 % N ≈ 7 \frac{N}{15\%N}\approx7 15%NN≈7 张图像抽一张作为验证集,这样分布更加均匀,而不至于训练集都是近跑道的图像。
实际做的时候我选择了每 8 张抽一张,并且方便起见没有为每个场景单独划分。下面是代码:
python
import os
import shutil
# 图像文件夹和标注文件夹路径
image_dir = r'F:\Datasets\runway\RunwayLandingDataset\images'
label_dir = r'F:\Datasets\runway\RunwayLandingDataset\labels'
# 验证集的目标文件夹
val_image_dir = r'F:\Datasets\runway\RunwayLandingDataset\val\images'
val_label_dir = r'F:\Datasets\runway\RunwayLandingDataset\val\labels'
# 创建验证集的文件夹(如果不存在)
os.makedirs(val_image_dir, exist_ok=True)
os.makedirs(val_label_dir, exist_ok=True)
# 获取图像文件列表(假设图像和标注文件的命名一致,只是扩展名不同)
image_files = sorted(os.listdir(image_dir)) # 例如: ['00000.jpg', '00001.jpg', ...]
label_files = sorted(os.listdir(label_dir)) # 例如: ['00000.txt', '00001.txt', ...]
# 确保图像和标签文件一一对应
assert len(image_files) == len(label_files), "图像文件和标签文件数量不匹配!"
# 选择每7张图像/标注抽取一张
for i in range(7, len(image_files), 8): # 从第8张开始,每隔8张选择一张
# 获取图像和标注文件的完整路径
image_file = image_files[i]
label_file = label_files[i]
# 确保文件名匹配(图像名和标签名应该相同)
assert image_file.replace('.jpg', '.txt') == label_file, f"{image_file} 和 {label_file} 名称不匹配!"
# 目标路径
target_image_path = os.path.join(val_image_dir, image_file)
target_label_path = os.path.join(val_label_dir, label_file)
# 移动图像和标签文件
shutil.move(os.path.join(image_dir, image_file), target_image_path)
shutil.move(os.path.join(label_dir, label_file), target_label_path)
print(f"已移动: {image_file} 和 {label_file} 到验证集。")
print("验证集抽取完成!")YOLO 转 COCO 格式
最终一共 12239 张图像中有 1529 张作为验证集。然后使用下面的脚本分别将其转换为 COCO 格式。
python
import os
import json
from PIL import Image
yolo_label_dir = r'F:\Datasets\runway\RunwayLandingDataset\labels' # 存放YOLO标签的文件夹
image_dir = r'F:\Datasets\runway\RunwayLandingDataset\images' # 存放图像的文件夹
# COCO格式的数据结构
coco_data = {
"images": [],
"annotations": [],
"categories": [{"id": 0, "name": "runway"}] # 这里假设只有一类标注
}
# 用于生成图像 ID 和标注 ID 的计数器
image_id = 0
annotation_id = 0
# 遍历 YOLO 标签文件夹中的标签文件
for filename in os.listdir(yolo_label_dir):
if filename.endswith('.txt'):
# 获取图像的文件名
image_name = filename.replace('.txt', '.jpg')
# 获取图像的实际尺寸(宽度和高度)
image_path = os.path.join(image_dir, image_name)
with Image.open(image_path) as img:
image_width, image_height = img.size
# 添加图像信息到COCO格式
coco_data['images'].append({
"id": image_id,
"file_name": image_name,
"height": image_height,
"width": image_width
})
# 读取 YOLO 格式的标签文件
with open(os.path.join(yolo_label_dir, filename), 'r') as f:
yolo_labels = f.readlines()
# 处理每一个标签
for label in yolo_labels:
parts = label.strip().split()
category_id = int(parts[0]) # 类别ID
x_center, y_center, w, h = map(float, parts[1:])
# 计算实际的像素坐标 (左上角和右下角)
x1 = (x_center - w / 2) * image_width
y1 = (y_center - h / 2) * image_height
x2 = (x_center + w / 2) * image_width
y2 = (y_center + h / 2) * image_height
# 计算多边形的 segmentation,YOLO 只是矩形,我们这里直接用边框的四个点来构造一个矩形的多边形
segmentation = [[x1, y1, x2, y1, x2, y2, x1, y2]]
# 计算区域面积
area = (x2 - x1) * (y2 - y1)
# 添加标注到COCO格式
coco_data['annotations'].append({
"id": annotation_id,
"image_id": image_id,
"category_id": category_id,
"segmentation": segmentation,
"area": area,
"bbox": [x1, y1, x2 - x1, y2 - y1],
"iscrowd": 0
})
annotation_id += 1
# 增加图像 ID
image_id += 1
# 保存为 COCO 格式的 JSON 文件
with open('instances.json', 'w') as f:
json.dump(coco_data, f, indent=4)
print("转换完成!")但是在转换到 01521 号图像的时候出现了错误,发现它的标注像这样 0 0.19107315891472867 0.7659345391903531 0.19864341085271317 0.7659345391903531 0.006056201550387596 0.9521963824289406,缺少了第四个点的坐标,将这张图像及其标注删除即可。
注意这样转换后也会造成一个图像中的多个标注放到 json 中不同的 annotation 字段中,这会影响训练的效果,通过 \[robust-ref-seg 复现过程]中的代码将其合并即可。
可视化
通过下面的代码可视化 json 标注以验证转换结果。
python
import json
import matplotlib.pyplot as plt
from PIL import Image
import matplotlib.patches as patches
import os
# 加载 COCO 格式的 JSON 文件
with open(r'F:\Datasets\runway\RunwayLandingDataset\val\instances.json', 'r') as f:
coco_data = json.load(f)
# 获取标注信息
annotations = coco_data['annotations']
images = coco_data['images']
categories = coco_data['categories']
# 创建类别 ID 到类别名称的映射
category_map = {category['id']: category['name'] for category in categories}
# 创建一个图像 id 到图像文件路径的映射
image_map = {image['id']: image['file_name'] for image in images}
# 选择一张图像的 ID,这里可以通过图像 ID 获取图像路径
image_id = 1 # 举例:图像 ID = 1
image_path = os.path.join(r'F:\Datasets\runway\RunwayLandingDataset\val\images', image_map[image_id])
# 加载图像
image = Image.open(image_path)
# 创建一个绘图对象
fig, ax = plt.subplots(1, figsize=(12, 9))
# 显示图像
ax.imshow(image)
# 遍历所有标注,选择属于这张图像的标注
for annotation in annotations:
if annotation['image_id'] == image_id:
# 获取边界框
bbox = annotation['bbox']
x, y, w, h = bbox
# 绘制边界框
rect = patches.Rectangle((x, y), w, h, linewidth=2, edgecolor='r', facecolor='none')
ax.add_patch(rect)
# 绘制类别名称
category_name = category_map[annotation['category_id']]
ax.text(x, y - 10, category_name, color='red', fontsize=12, bbox=dict(facecolor='white', alpha=0.7))
# 如果有多边形分割,绘制分割
if 'segmentation' in annotation:
for polygon in annotation['segmentation']:
polygon = [(polygon[i], polygon[i+1]) for i in range(0, len(polygon), 2)] # 转换为 (x, y) 点
poly = patches.Polygon(polygon, closed=True, linewidth=2, edgecolor='blue', facecolor='none')
ax.add_patch(poly)
# 显示带有标注的图像
plt.axis('off')
plt.show()