SegEarth-OV2相比于SegEarth-OV的主要区别是,将开放词汇的遥感影像语义分割应用到SAR图像上,可同时对光学和SAR影像进行语义分割。
目录
[⭐2.1 空间细节丢失](#⭐2.1 空间细节丢失)
[⭐2.3SAR 模态缺少](#⭐2.3SAR 模态缺少)
[⭐3.1 SimFeatUp:通用特征上采样模块](#⭐3.1 SimFeatUp:通用特征上采样模块)
[⭐3.2Global Bias Alleviation:全局偏差消除](#⭐3.2Global Bias Alleviation:全局偏差消除)
[⭐3.3AlignEarth:跨模态知识蒸馏(SAR 扩展)](#⭐3.3AlignEarth:跨模态知识蒸馏(SAR 扩展))
**题目:**Annotation-Free Open-Vocabulary Segmentation for Remote-Sensing Images
机构: 西安交通大学
论文: paper代码: code
**出处:**CVPR2025

🍂🍂一、研究背景
传统监督学习方法在语义分割任务中存在两个根本性局限:首先,这些方法严重依赖大规模像素级标注数据集(如 Cityscapes、ADE20K 等),而获取这类数据集的标注成本极其高昂。以 Cityscapes 数据集为例,每张精细标注的街景图像平均需要 90 分钟的人工标注时间。其次,这类方法受限于预定义的封闭类别集合,当遇到训练集中未出现过的新类别时,系统完全无法识别。
开放词汇语义分割(Open-Vocabulary Semantic Segmentation,OVSS)通过引入文本描述作为类别指导,实现了对任意类别(包括未见过的类别)的分割能力。这种方法的核心创新在于:
- 摆脱了对像素级标注的依赖,转而利用自然语言描述作为监督信号
- 突破了传统方法固定的类别限制,实现了真正的开放世界识别
典型的实现方案是基于视觉-语言模型(Vision-Language Models,VLMs)的架构,如 CLIP(Contrastive Language-Image Pretraining)。这类模型通过在大规模图像-文本对上进行预训练,建立了视觉特征和语言概念的强关联。在分割任务中,模型可以将输入文本提示(如"道路"、"建筑物")与图像区域进行语义匹配,从而实现零样本的开放词汇分割。
本文的创新点在于建立了面向光学和合成孔径雷达(SAR)双模态数据的统一 OVSS 解决方案。考虑到光学和 SAR 成像机制的显著差异(光学依赖反射光,SAR 依赖微波回波),我们设计了跨模态的特征对齐机制:
- 在特征提取阶段采用双分支架构分别处理不同模态数据
- 通过共享的文本编码器建立统一的语义空间
- 引入模态特定的适配器模块来协调特征分布差异
这一方案不仅保留了传统 OVSS 的开放词汇优势,还特别针对多源遥感数据的特点进行了优化,为遥感图像解译提供了更灵活的解决方案。
🍓🍓二、核心解决问题
⭐2.1 空间细节丢失
SimFeatUp: 通用上采样模块,恢复高分辨率细节,内容保留网络 (CRN) 防止语义漂移 ,早期特征上采样,适配修改后的自注意力,11×11 大核适应遥感尺度变化
⭐2.2全局偏差污染
Global Bias Alleviation: 显式消除 CLS 泄漏,简单减法操作: O_patch - λ × O_cls,无需训练,即插即用
⭐2.3SAR 模态缺少
AlignEarth: 跨模态知识蒸馏 ,利用配对光学-SAR 图像(无需文本标注),全局对比 + 全局蒸馏 + 局部蒸馏三重约束,将光学 VLM 知识迁移到 SAR 编码器
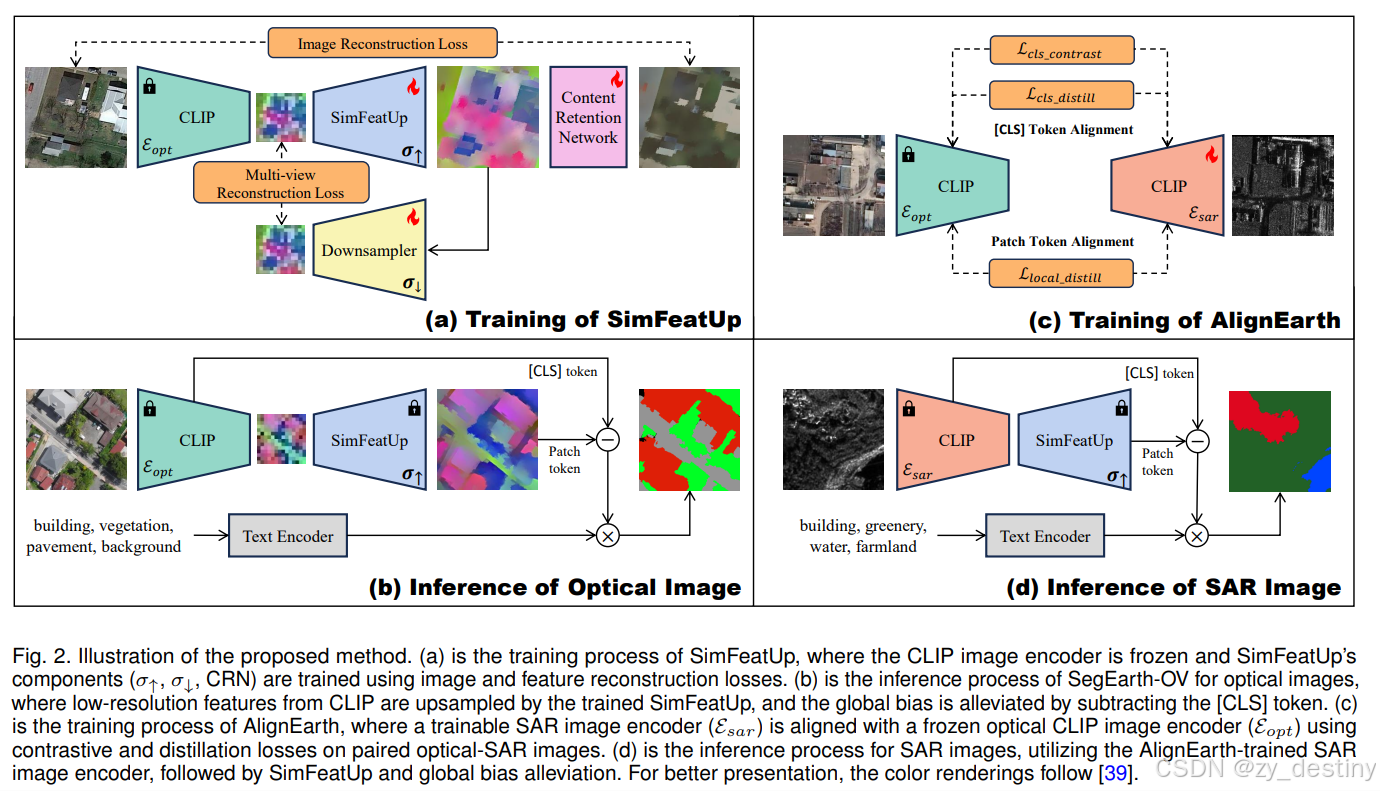
(a)和(b)为原始SegEarth-OV的光学影像训练推理网络结构, (c)和(d)为SegEarth-OV2的SAR影像训练推理网络结构。
🌾🌾三、核心创新点
⭐3.1 SimFeatUp:通用特征上采样模块
|--------------------|--------------------------------------------------------------------------|
| 内容保留网络 (CRN) | 引入图像重建损失 Limg,强制上采样特征能重建原始图像,避免语义漂移 |
| 早期特征上采样 | 使用 CLIP 最后一层 Transformer 的输入特征 X1:hw+1 而非输出特征,避免与 OVSS 修改后的自注意力机制冲突 |
| 大卷积核设计 | 将 JBU 窗口从 7×7 扩展到 11×11,适应遥感目标的大尺度变化 |
| 结构简化 (JBU One) | 将堆叠的 4 个 JBU 模块简化为 1 个共享参数的 JBU 模块,减少 4× 参数量,提升确定性 |
⭐3.2Global Bias Alleviation:全局偏差消除
核心思想: CLIP 的 CLS token 在训练时与文本对齐,但其全局语义会"泄漏"到局部 patch token 中,导致密集预测时局部判别能力下降。
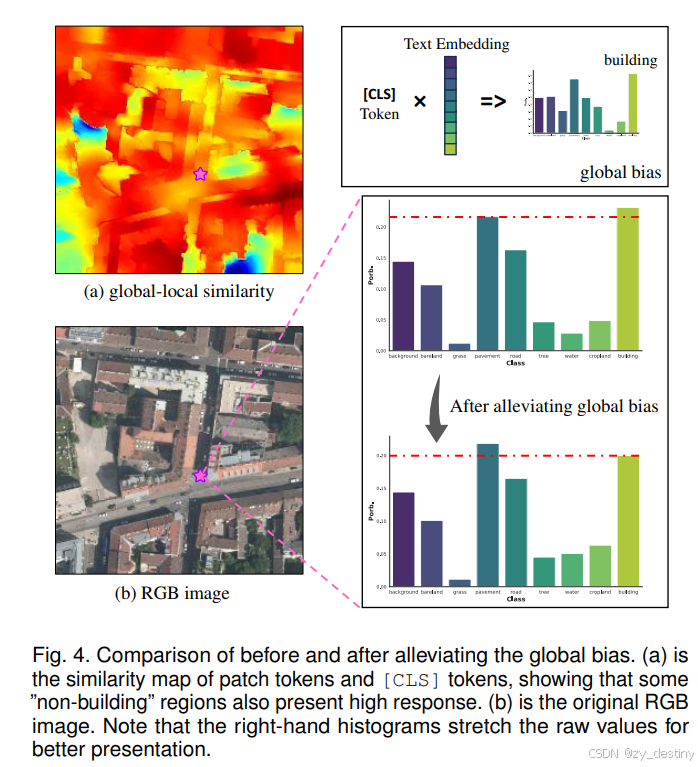
⭐3.3AlignEarth:跨模态知识蒸馏(SAR 扩展)
针对 SAR 图像 缺乏预训练 VLM 的问题,提出从光学 VLM 向 SAR 编码器蒸馏知识:
| 损失类型 | 作用 |
|---|---|
| Global Contrastive Loss (Lcls_contrast) | 对比学习,拉近配对的光学-SAR 图像,推开非配对图像 |
| Global Distillation Loss (Lcls_distill) | 直接约束 SA R CLS token 与光学 CLS token 的余弦相似度 |
| Local Distillation Loss (Llocal_distill) | 将特征图分块 (K×K),块内平均后计算余弦距离,缓解配准误差和散斑噪声影响 |
🍀🍀四、实验结果
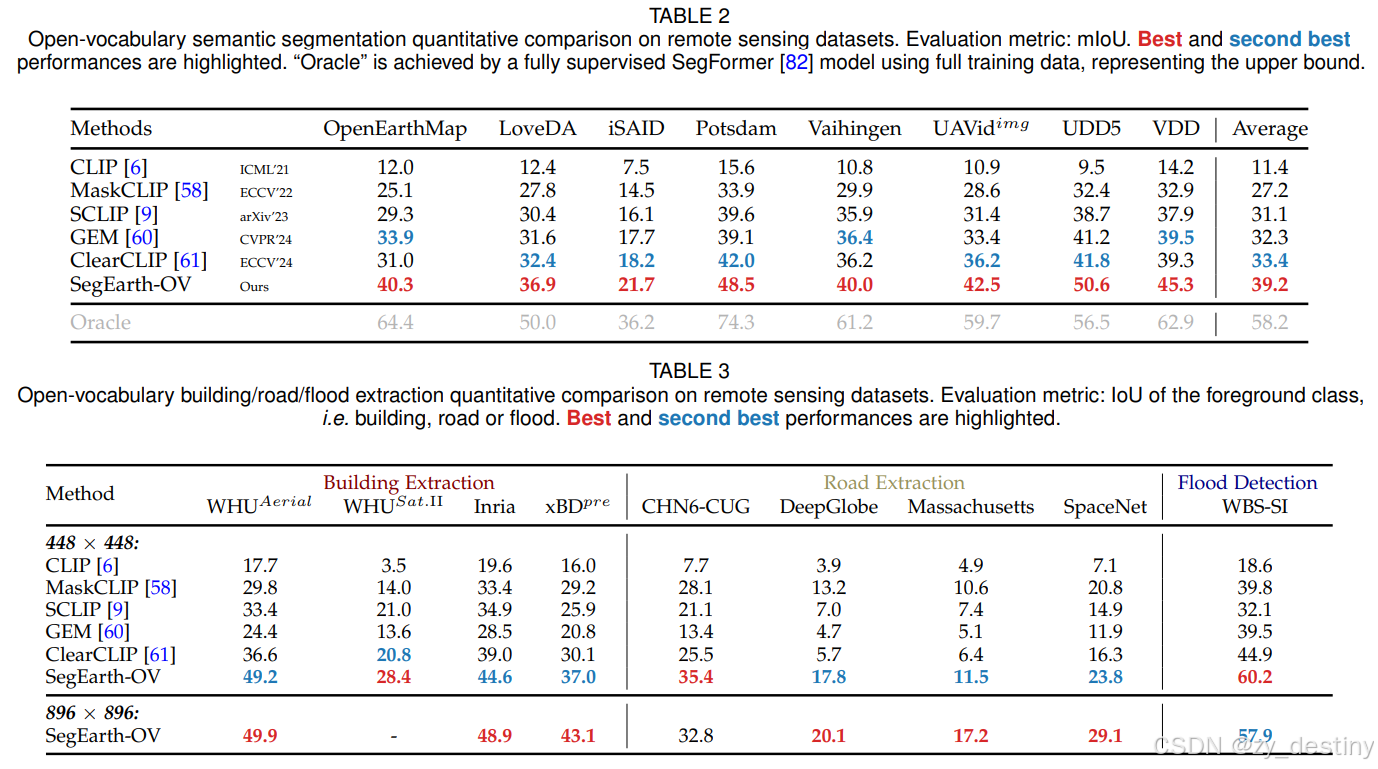
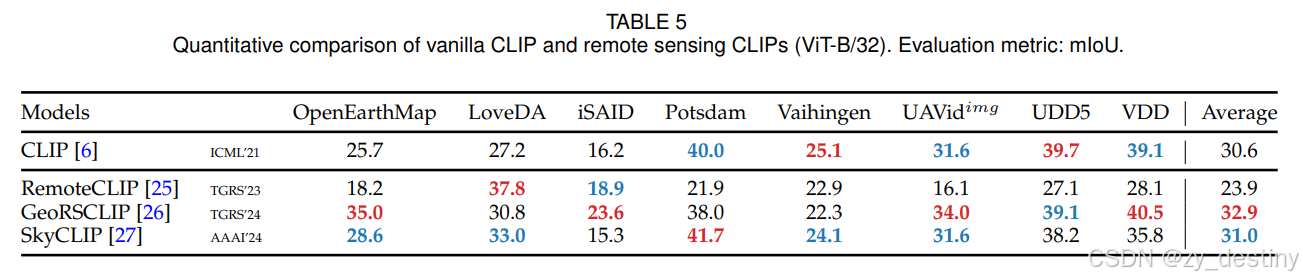
⭐4.1精度对比
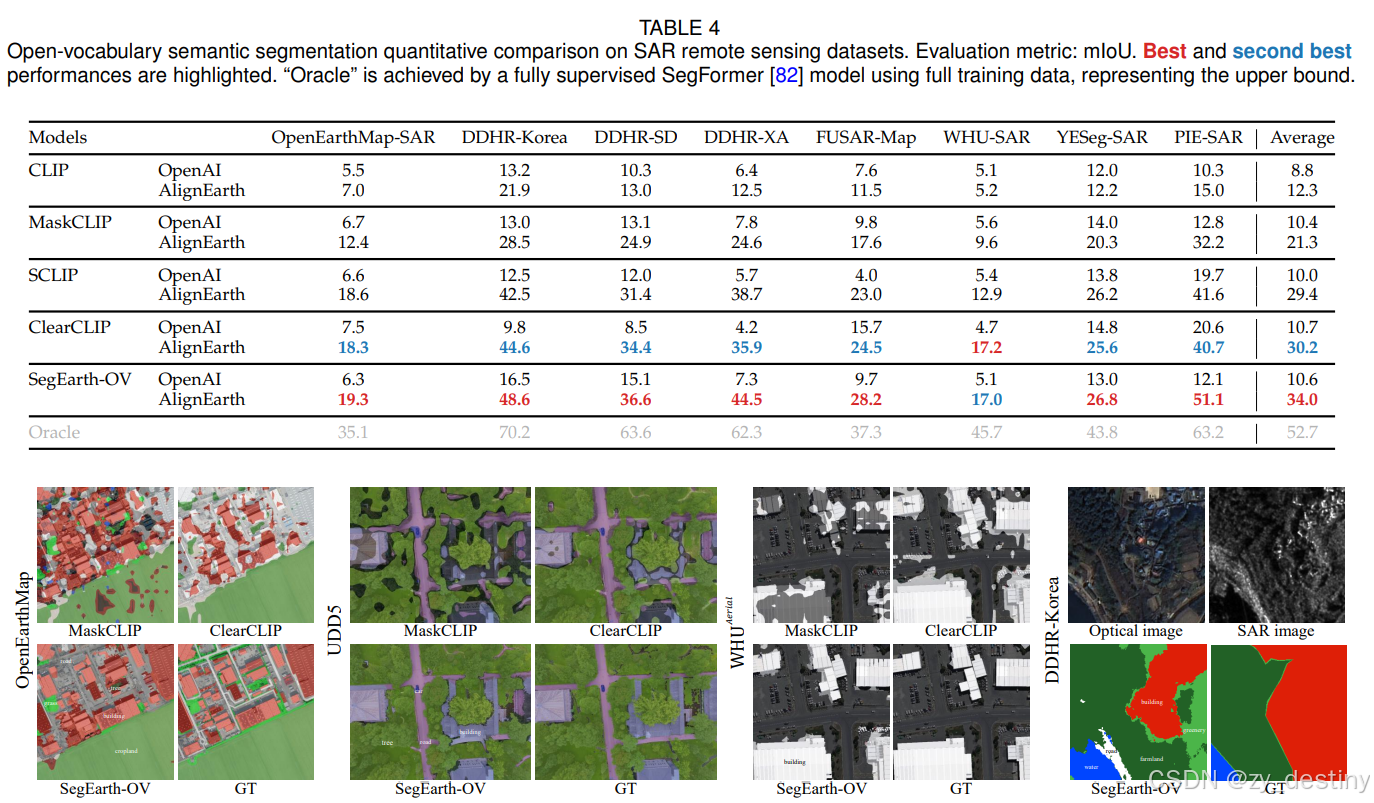
⭐4.2可视化结果

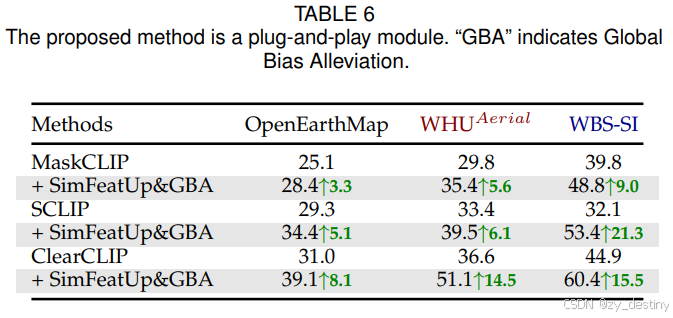
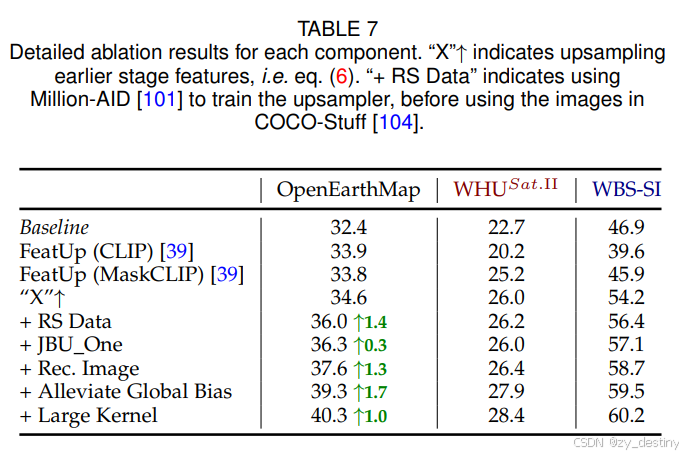
⭐4.3消融实验结果对比
🌷🌷五、代码复现
⭐5.1虚拟环境
bash
Package Version
------------------------ -----------
addict 2.4.0
certifi 2026.1.4
charset-normalizer 3.4.4
contourpy 1.3.0
cycler 0.12.1
einops 0.8.0
et_xmlfile 2.0.0
fairscale 0.4.13
filelock 3.19.1
fonttools 4.60.2
fsspec 2024.3.1
ftfy 6.2.3
hf-xet 1.2.0
huggingface-hub 0.36.0
idna 3.11
importlib_resources 6.5.2
Jinja2 3.1.6
kiwisolver 1.4.7
markdown-it-py 3.0.0
MarkupSafe 3.0.3
matplotlib 3.8.4
mdurl 0.1.2
mmcv 2.1.0
mmengine 0.10.4
mmsegmentation 1.2.2
mpmath 1.3.0
networkx 3.2.1
ninja 1.13.0
numpy 1.24.4
nvidia-cublas-cu12 12.1.3.1
nvidia-cuda-cupti-cu12 12.1.105
nvidia-cuda-nvrtc-cu12 12.1.105
nvidia-cuda-runtime-cu12 12.1.105
nvidia-cudnn-cu12 8.9.2.26
nvidia-cufft-cu12 11.0.2.54
nvidia-curand-cu12 10.3.2.106
nvidia-cusolver-cu12 11.4.5.107
nvidia-cusparse-cu12 12.1.0.106
nvidia-nccl-cu12 2.18.1
nvidia-nvjitlink-cu12 12.9.86
nvidia-nvtx-cu12 12.1.105
opencv-python 4.6.0.66
opencv-python-headless 4.8.0.76
openpyxl 3.1.5
packaging 26.0
pillow 11.3.0
pip 25.2
platformdirs 4.4.0
prettytable 3.16.0
Pygments 2.19.2
pyparsing 3.3.2
python-dateutil 2.9.0.post0
PyYAML 6.0.3
regex 2024.9.11
requests 2.32.5
rich 14.3.1
safetensors 0.4.5
scipy 1.13.1
setuptools 80.9.0
six 1.17.0
sympy 1.14.0
termcolor 3.1.0
timm 1.0.9
tokenizers 0.19.1
tomli 2.4.0
torch 2.1.2
torchvision 0.16.2
tqdm 4.65.2
transformers 4.44.2
triton 2.1.0
typing_extensions 4.15.0
urllib3 2.6.3
wcwidth 0.2.14
wheel 0.45.1
yapf 0.43.0
zipp 3.23.0⭐5.2运行代码
python
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
import argparse
import segearth_segmentor
import custom_datasets
from mmengine.config import Config
from mmengine.runner import Runner
from utils import append_experiment_result
def parse_args():
parser = argparse.ArgumentParser(
description='SegEarth-OV evaluation with MMSeg')
parser.add_argument('--config', default='./configs/cfg_voc20.py')
parser.add_argument('--work-dir', default='./work_logs/')
parser.add_argument(
'--show', action='store_true', help='show prediction results')
parser.add_argument(
'--show-dir',
default='./show_dir/',
help='directory to save visualizaion images')
parser.add_argument(
'--launcher',
choices=['none', 'pytorch', 'slurm', 'mpi'],
default='none',
help='job launcher')
# When using PyTorch version >= 2.0.0, the `torch.distributed.launch`
# will pass the `--local-rank` parameter to `tools/train.py` instead
# of `--local_rank`.
parser.add_argument('--local_rank', '--local-rank', type=int, default=0)
args = parser.parse_args()
if 'LOCAL_RANK' not in os.environ:
os.environ['LOCAL_RANK'] = str(args.local_rank)
return args
def trigger_visualization_hook(cfg, args):
default_hooks = cfg.default_hooks
if 'visualization' in default_hooks:
visualization_hook = default_hooks['visualization']
# Turn on visualization
visualization_hook['draw'] = True
if args.show:
visualization_hook['show'] = True
visualization_hook['wait_time'] = args.wait_time
if args.show_dir:
visualizer = cfg.visualizer
visualizer['save_dir'] = args.show_dir
else:
raise RuntimeError(
'VisualizationHook must be included in default_hooks.'
'refer to usage '
'"visualization=dict(type=\'VisualizationHook\')"')
return cfg
def main():
args = parse_args()
cfg = Config.fromfile(args.config)
cfg.launcher = args.launcher
cfg.work_dir = args.work_dir
# visualization
# trigger_visualization_hook(cfg, args)
runner = Runner.from_cfg(cfg)
results = runner.test()
results.update({'VIT': cfg.model.vit_type,
'CLIP': cfg.model.clip_type,
'MODEL': cfg.model.model_type,
'Dataset': cfg.dataset_type})
if runner.rank == 0:
append_experiment_result('results.xlsx', [results])
if runner.rank == 0:
with open(os.path.join(cfg.work_dir, 'results.txt'), 'a') as f:
f.write(os.path.basename(args.config).split('.')[0] + '\n')
for k, v in results.items():
f.write(k + ': ' + str(v) + '\n')
if __name__ == '__main__':
main()运行以上eval.py文件命令:
bash
python eval.py --config ./configs/cfg_yeseg_sar.pyYESEG-SAR数据的下载地址在:百度网盘
预训练模型的下载地址在:huggingface
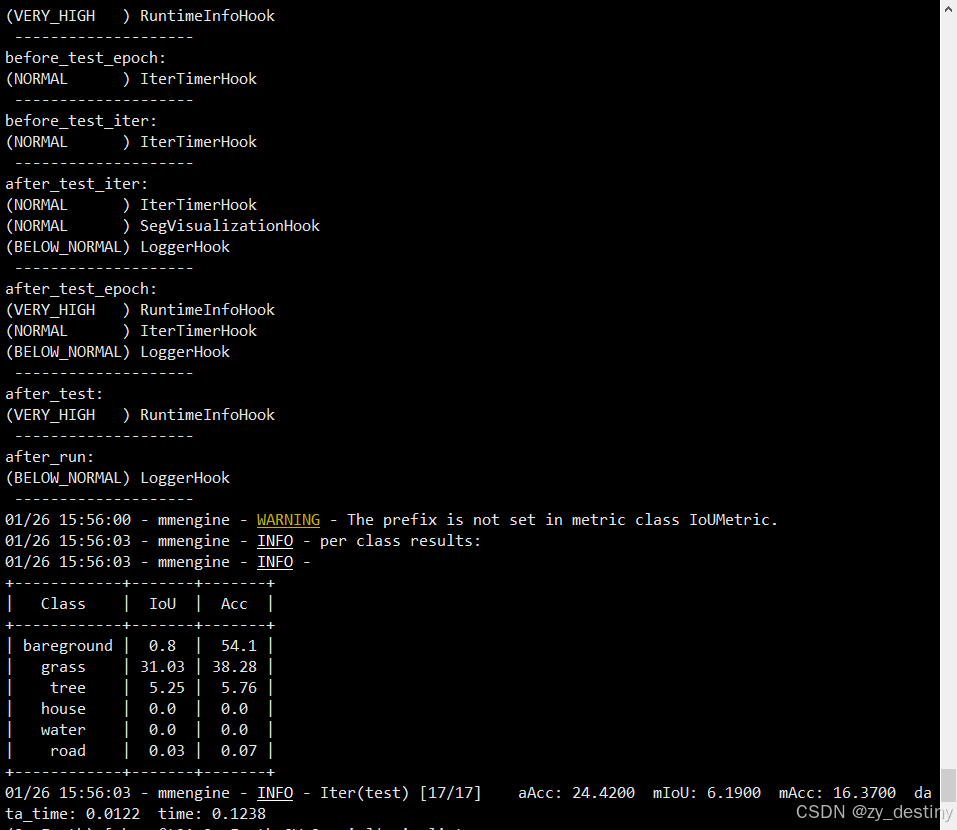
⭐5.3精度结果
bash
+------------+-------+-------+
| Class | IoU | Acc |
+------------+-------+-------+
| bareground | 0.8 | 54.1 |
| grass | 31.03 | 38.28 |
| tree | 5.25 | 5.76 |
| house | 0.0 | 0.0 |
| water | 0.0 | 0.0 |
| road | 0.03 | 0.07 |
+------------+-------+-------+我只测试了17组yeseg-sar数据,结果如下:
中间打印的config的文件内容和HOOK的优先级就不展示了。
⭐5.4推理可视化结果展示



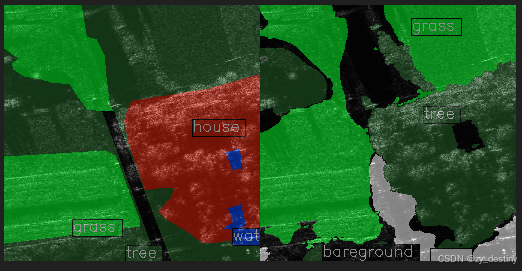
精度和可视化结果看着还不是很好,后面咱们再试试SegEarth-ov3,看看升级后的效果怎么样吧,能否达到想要的智能标注的效果。
整理不易,欢迎一键三连!
送你们一条美丽的--分割线--
🌷🌷🍀🍀🌾🌾🍓🍓🍂🍂🙋🙋🐸🐸🙋🙋💖💖🍌🍌🔔🔔🍉🍉🍭🍭🍋🍋🍇🍇🏆🏆📸📸⛵⛵⭐⭐🍎🍎👍👍🌷