第二篇 实践篇
目录
[第二篇 实践篇](#第二篇 实践篇)
[3 使用自己的数据进行深度学习遥感地物分类](#3 使用自己的数据进行深度学习遥感地物分类)
[3.3.4 制作数据集](#3.3.4 制作数据集)
[3.4.2 UNET代码实现](#3.4.2 UNET代码实现)
3 使用自己的数据进行深度学习遥感地物分类
使用自己的数据进行深度学习遥感地物分类相较于使用公开数据集进行深度学习遥感地物分类,在数据预处理方面多了许多处理与操作 ,因为要制作自己的专用数据集,需要进行标注打标签、矢量栅格转化与分块等操作,以及我们应用模型时,是在大图上进行应用,还需要一些较为复杂的操作。
3.1代码整体介绍
preprocessings 数据预处理工具
datasets 数据存放位置
dataloaders 数据的dataloader
models 模型
evaluations 评价指标类
utils 用来储存实验过程的常用工具与函数
environment.yml conda环境配置文件,供大家配置环境参考
================================================================
前边都是常用工具代码,不太常改,x_experiments是进行实验经常需要修改的
x_experiments 实验代码、记录、与结果详细目录如下
3.2问题定义与数据收集
3.2.1问题定义
在应用创新中,我们首先需要明确的是自己的研究对象是什么,如湿地、红树林、水体、矿物、岩性、植被、冰雪、建成区、耕地等等,根据自己的研究方向,明确一种或者多种对象进行研究。此处,假设我们的研究方向是土地利用分类,研究对象如下:
|----|-------|
| 1 | 工业区 |
| 2 | 水田 |
| 3 | 灌溉田 |
| 4 | 旱地 |
| 5 | 花园地 |
| 6 | 乔木林 |
| 7 | 灌木林 |
| 8 | 公园 |
| 9 | 天然草地 |
| 10 | 人工草地 |
| 11 | 河流 |
| 12 | 城市住宅区 |
| 13 | 湖泊 |
| 14 | 池塘 |
| 15 | 鱼塘 |
| 16 | 雪 |
| 17 | 裸地 |
| 18 | 乡村住宅 |
| 19 | 体育场 |
| 20 | 广场 |
| 21 | 道路 |
| 22 | 立交桥 |
| 23 | 火车站 |
| 24 | 机场 |
所以我们要将以上地物要素标记出来,并制作数据集训练模型,然后将训练好的模型应用到其他数据上。
3.2.2数据收集
进行土地利用分类一般使用分辨率较高的数据,如GF数据等等,这些高分辨率数据的获取一般比较困难,需要购买或者高校教师账号才能获取。当然也有专门研究30米或者500米等较低分辨率下土地利用分类的研究。
此处我们使用FBPS 数据为例,FBPS 数据是由"Enabling Country-Scale Land Cover Mapping with
Meter-Resolution Satellite Imagery"该研究提出,该数据提供了一系列GF2整景的遥感影像以及其标签,虽然该数据集中提供了标签,但是本教程会拿出一景影像进行标记与演示。
https://x-ytong.github.io/project/Five-Billion-Pixels.html
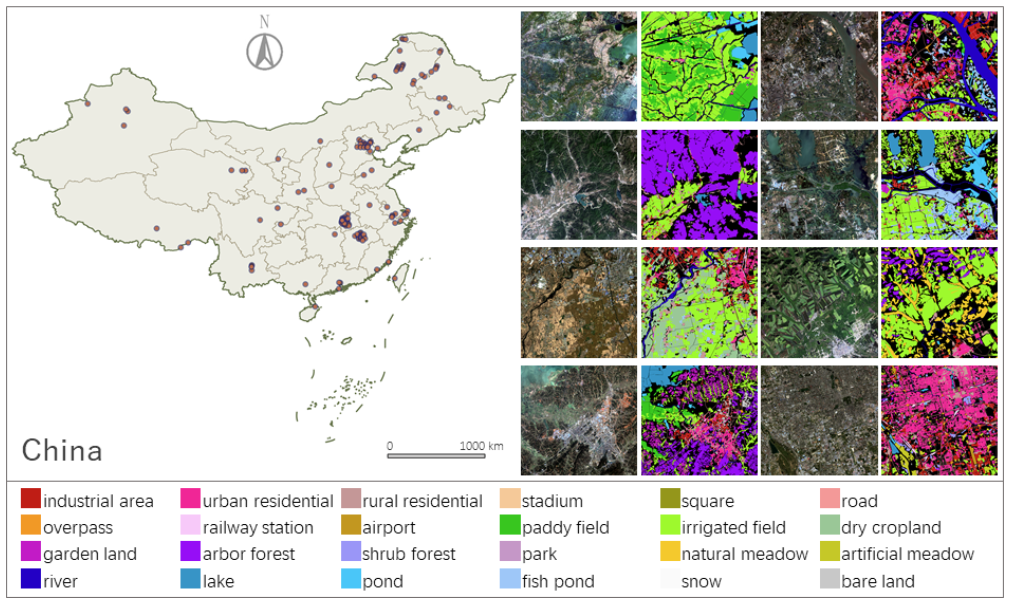

数据目录如图所示,具体数据内容可以参见readme中的介绍,非常详细。
我们在这主要使用的是Image_16bit_BGRNir文件夹中的遥感影像(tif)和Coordinate_files文件夹中的空间信息(rpb)
@article{FBP2023,
title={Enabling country-scale land cover mapping with meter-resolution satellite imagery},
author={Tong, Xin-Yi and Xia, Gui-Song and Zhu, Xiao Xiang},
journal={ISPRS Journal of Photogrammetry and Remote Sensing},
volume={196},
pages={178-196},
year={2023}
}
3.3数据预处理
3.3.1使用rpb文件进行正射校正并赋予空间信息
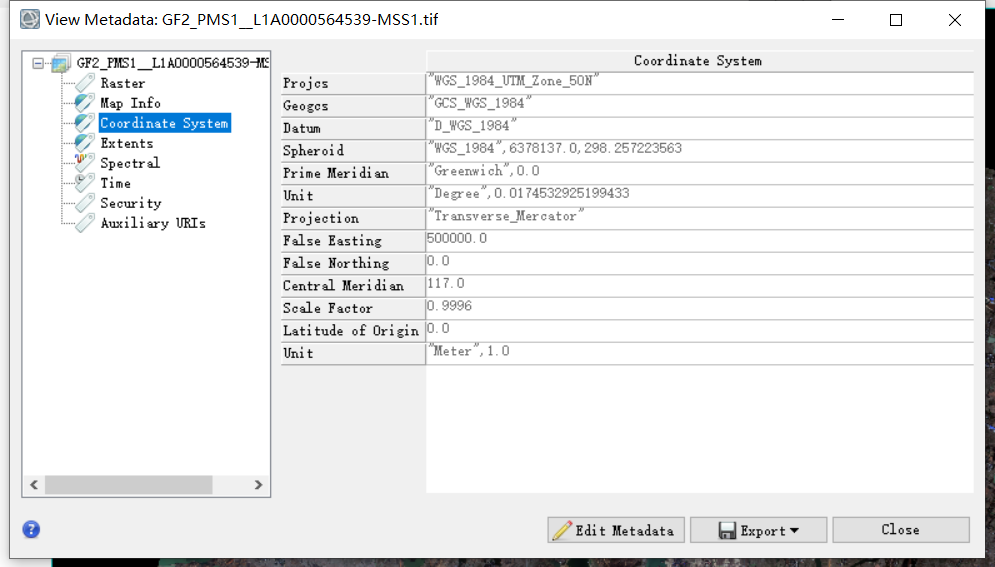
使用ENVI打开刚下载的FBPS 数据中的Image_16bit_BGRNir中的tif影像,是没有空间信息的,详细信息如下:
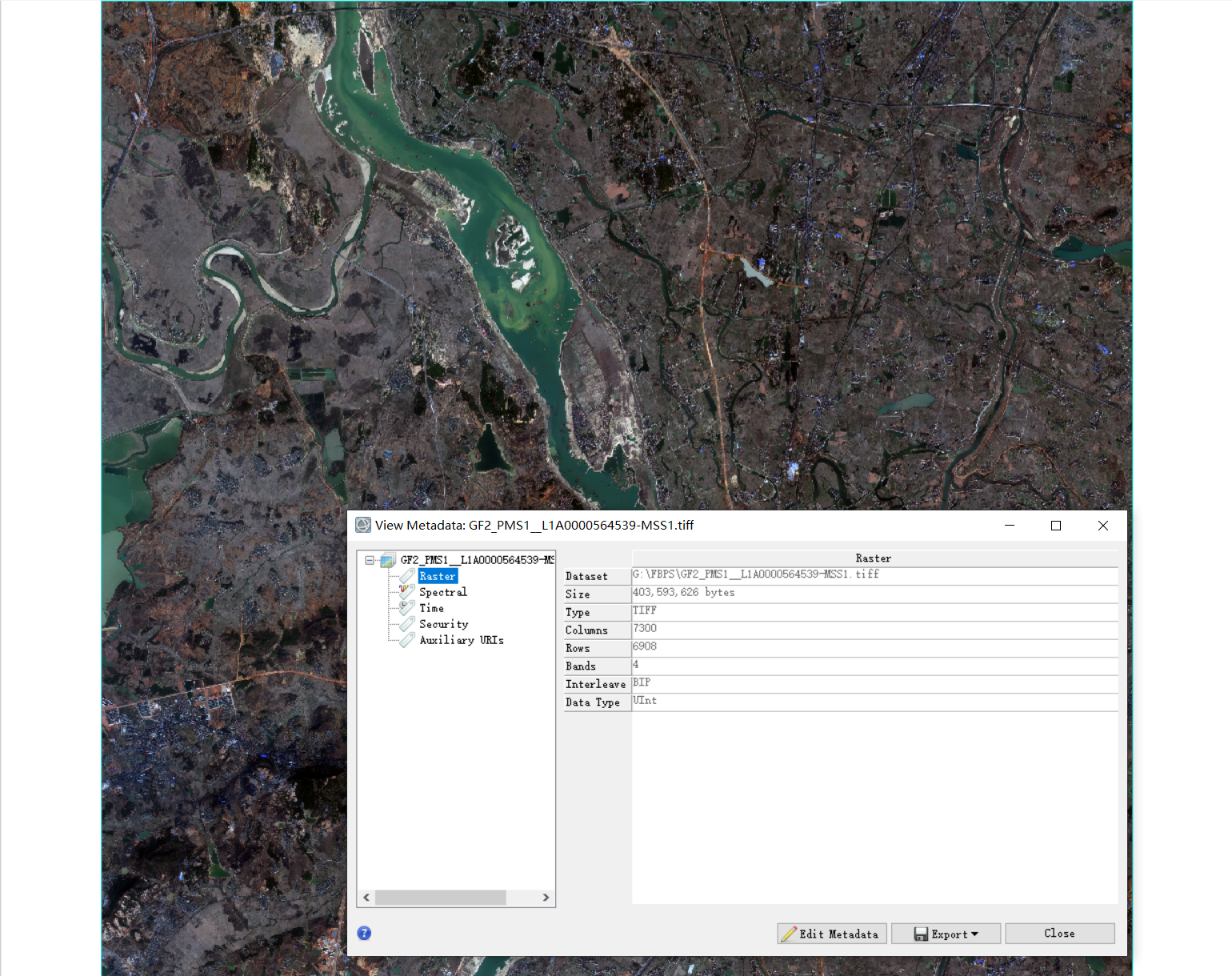
但是有了空间信息才能较为方便的在ENVI或者arcgis等GIS软件中对遥感或者地理数据进行处理。
第一步,我们将Coordinate_files文件夹中的空间信息(rpb)文件全部拷入Image_16bit_BGRNir文件夹中,从新用ENVI打开tif,这次会发现影像的元数据中多了空间信息,界面中也出现了指北针。
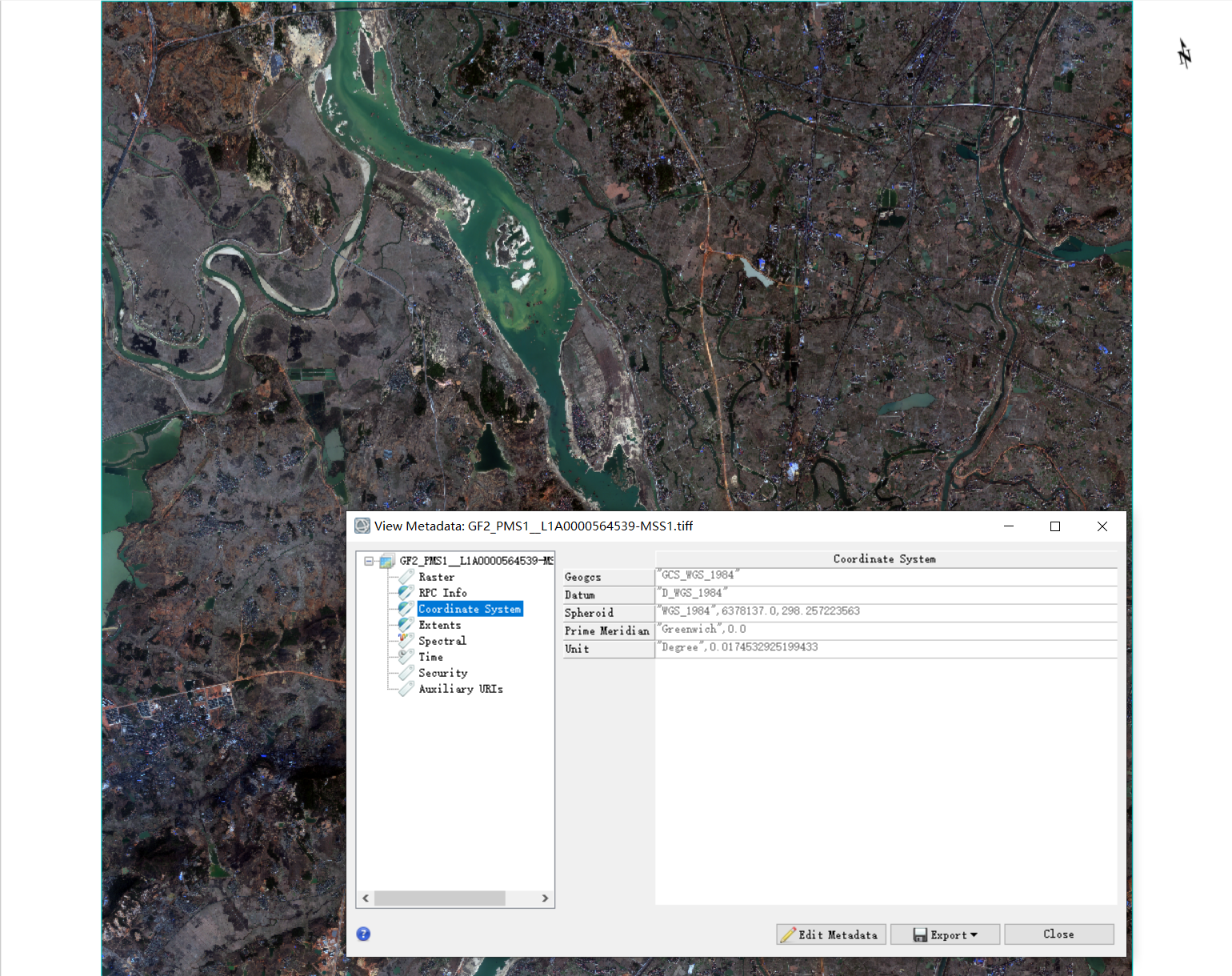
这是因为,envi在打开tif时,可以根据文件名去寻找对应的rpb文件,读取并加载里面的空间信息。但是这时这些信息是临时的,没有写入tif。
第二步,基于这些RPC信息进行正射校正,在这个过程中地理空间信息会被写入tif。
点击Toolbox→Geometric Correction→Orthorectification→RPC Orthorectification Workflow,打开正射校正流程化工具;
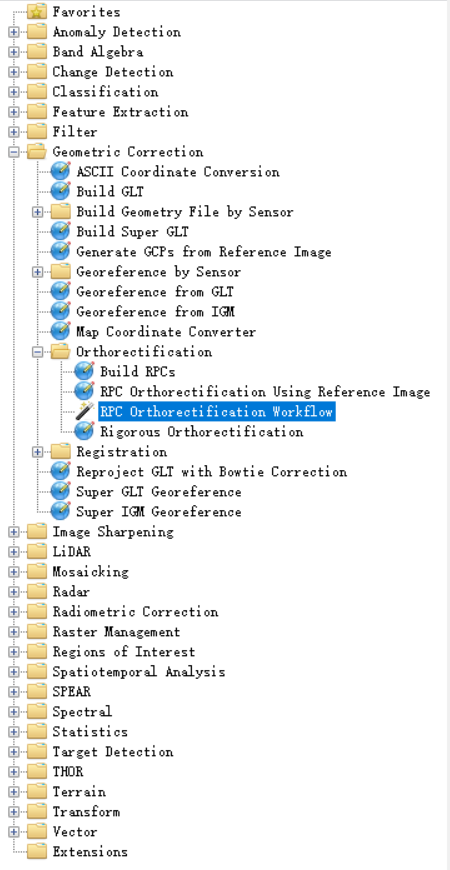
在File Selection面板中,Input File选择tif,DEM File会默认选择全球分辨率为900米的DEM数据,我们这里保持默认,点击Next;
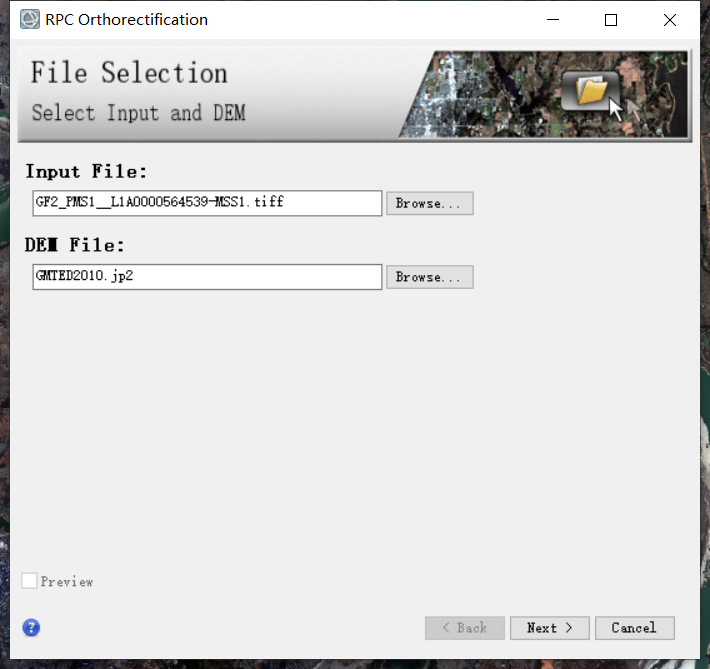
切换到Export选项卡,选择输出文件格式,设置输出路径及文件名,其他选项卡保持默认即可,点击Finish;
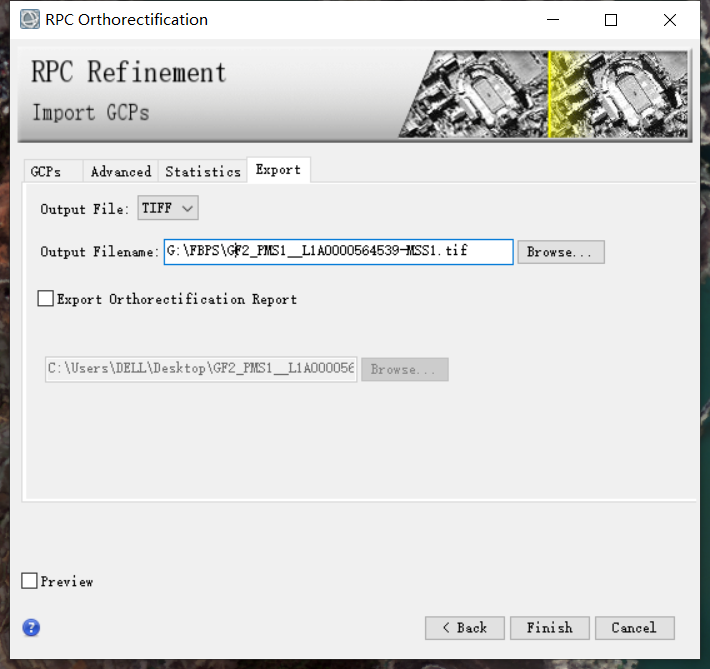
重新打开envi,打开保存出的tif,发现影像变斜,这就是完成的校正并赋予了空间信息。

3.3.2制作目标shp文件
这一步及其费时费力,也是及其关键的一步,有了大量高质量的数据才能训练出优秀的模型。
这一步有时不需要,有些课题组有前期的积累具有对应的shp文件,或者可以从一些开源的网站上获取到一些shp,加以处理后得到自己所需要的shp,如openstreetmap此类网站。
请见xy 用户:geedownload
或者xy 搜索 深度学习遥感地物分类-以建筑分割和多地物分割为例
很久之后,我们便得到了一景影像对应的label shp了,标注起来太费力了,这里就用一景影像进行演示了。

3.3.3目标shp转tif
现在,我们得到了目标shp(label.shp),但是在训练模型时,往往需要的是栅格数据,需要将目标shp矢量转成tif栅格数据。
请见xy 用户:geedownload
或者xy 搜索 深度学习遥感地物分类-以建筑分割和多地物分割为例
3.3.4 制作数据集
请见xy 用户:geedownload
或者xy 搜索 深度学习遥感地物分类-以建筑分割和多地物分割为例
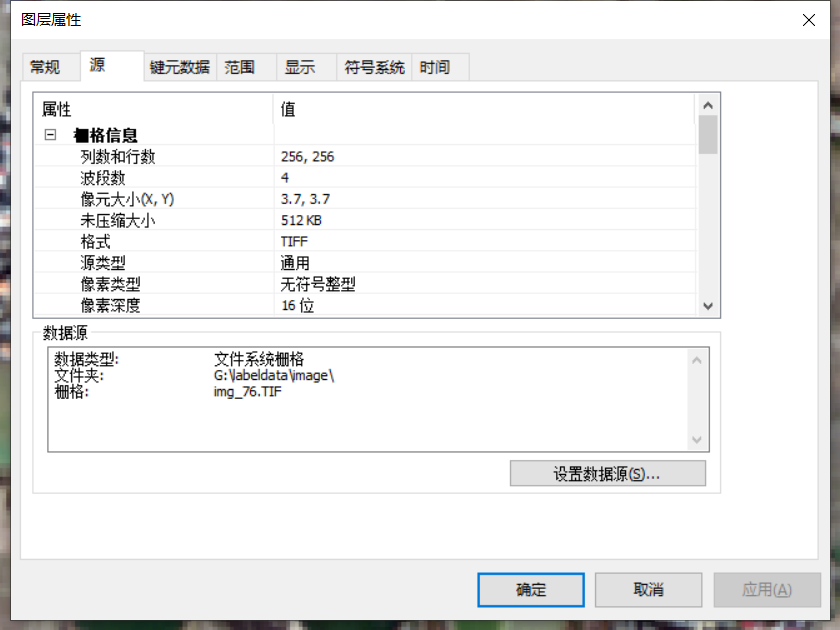
4.打开一对可以对应的tif,如img_76.TIF
image中的img_76.TIF,如下图

label中的img_76.TIF,如下图
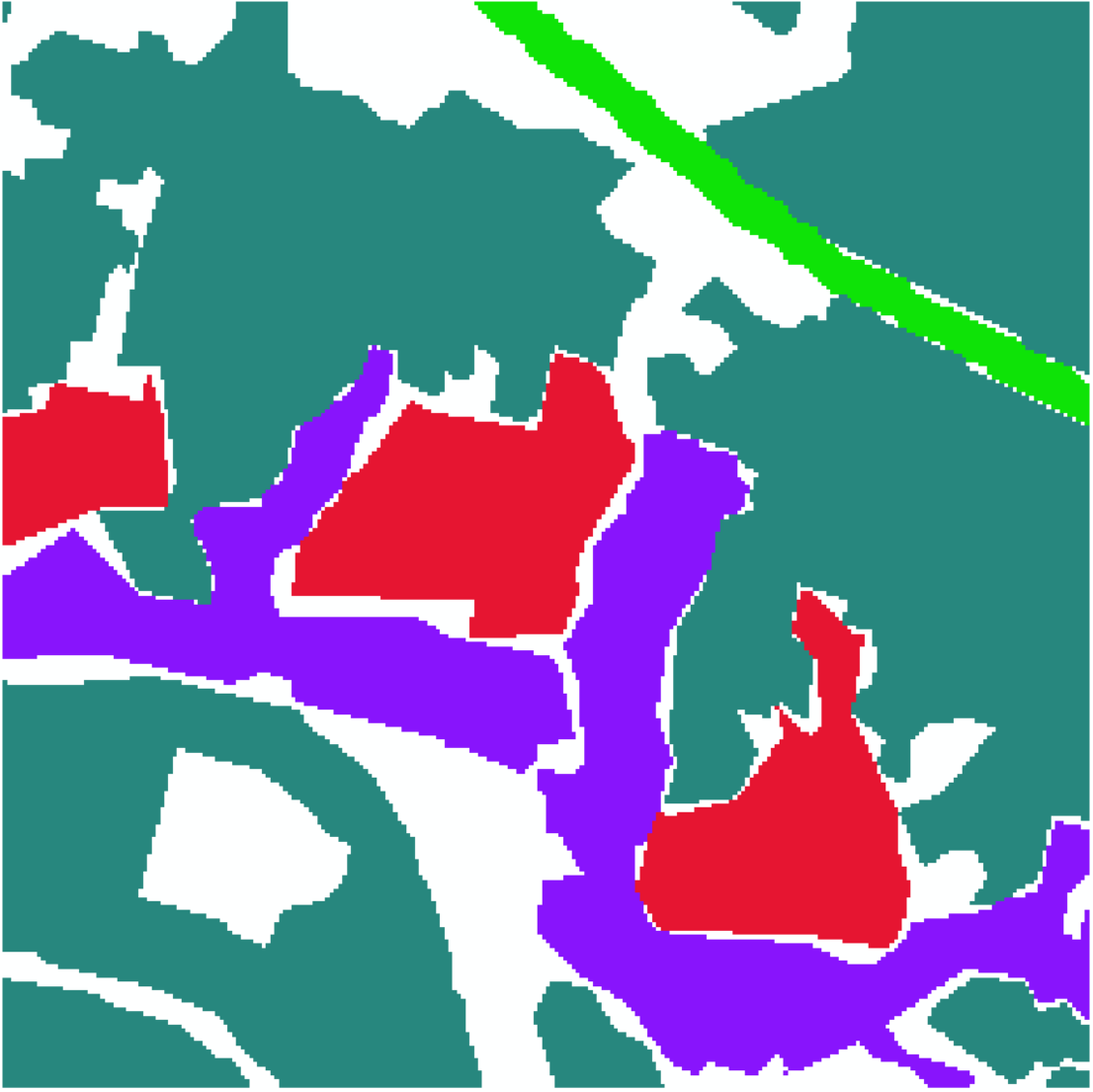
它们空间一致,分辨率一致,行列数一致,这就是我们想要的数据对了。
5.把可以成对的影像对筛选出来,并按照6:2:2的比例划分为训练数据,验证数据和测试数据。
首先,在G盘labeldata中新建一个datasets文件夹用来存放数据集,datasets内部目录树如下:
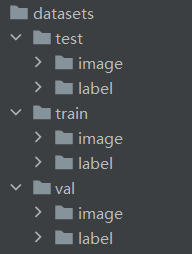
接下来,编写代码,来实现筛选以及按比例划分,代码如下
import os
import shutil
import random
# 定义数据集的目录
image_dir = '../image'
label_dir = '../label'
datasets_dir = '../datasets'
# 创建训练集、验证集和测试集的目录
train_dir = os.path.join(datasets_dir, 'train')
val_dir = os.path.join(datasets_dir, 'val')
test_dir = os.path.join(datasets_dir, 'test')
os.makedirs(train_dir, exist_ok=True)
os.makedirs(val_dir, exist_ok=True)
os.makedirs(test_dir, exist_ok=True)
# 读取影像和标签文件
image_files = [f for f in os.listdir(image_dir) if f.endswith('.TIF')]
label_files = [f for f in os.listdir(label_dir) if f.endswith('.TIF')]
# 将文件名和路径配对
file_pairs = set(image_files) & set(label_files)
# 随机打乱文件对
file_pairs = list(file_pairs)
random.shuffle(file_pairs)
# 计算划分比例
total_files = len(file_pairs)
train_size = int(total_files * 0.6)
val_size = int(total_files * 0.2)
test_size = total_files - train_size - val_size
# 划分数据集
train_files = file_pairs[:train_size]
val_files = file_pairs[train_size:train_size + val_size]
test_files = file_pairs[train_size + val_size:]
# 移动文件到对应的目录
for file in train_files:
shutil.move(os.path.join(image_dir, file), os.path.join(train_dir, 'image', file))
shutil.move(os.path.join(label_dir, file), os.path.join(train_dir, 'label', file))
for file in val_files:
shutil.move(os.path.join(image_dir, file), os.path.join(val_dir, 'image', file))
shutil.move(os.path.join(label_dir, file), os.path.join(val_dir, 'label', file))
for file in test_files:
shutil.move(os.path.join(image_dir, file), os.path.join(test_dir, 'image', file))
shutil.move(os.path.join(label_dir, file), os.path.join(test_dir, 'label', file))执行完代码后就得到了一个自己的深度学习数据集。
3.3.5构建RSDataset与RSDataLoader
PyTorch 的 Dataset 类是用于表示数据集的一个抽象基类。它定义了如何从数据源加载和访问数据。Dataset 类是 PyTorch 数据处理管道中的一个重要组成部分,通常与 DataLoader 类一起使用,以实现高效的数据加载和批处理。
Dataset 主要功能
- 数据加载 :
Dataset类提供了一种标准化的方式来加载数据。你可以自定义数据加载逻辑,包括读取文件、预处理数据等。 - 数据访问:通过索引访问数据,使得数据可以被逐个或批量地访问。
- 数据预处理:可以在数据加载时进行预处理操作,如图像缩放、归一化等。
要使用 Dataset 类,你需要继承它并实现两个主要的方法:
__len__:返回数据集的大小(即数据样本的数量)。__getitem__:根据给定的索引返回一个数据样本。
Dataset 类通常与 DataLoader 类一起使用,以实现批量加载、数据打乱、多线程加载等功能。
构建RSDataset来加载我们自己的数据集,代码如下:
import numpy as np
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import os
import skimage.io as io
def get_filename(path, filetype):
# 获取指定路径下指定文件类型的文件名列表
name = []
final_name = []
for root, dirs, files in os.walk(path):
for i in files:
if filetype in i[-4:]:
name.append(i.replace(filetype, ''))
final_name = [item + filetype for item in name]
return final_name
class RSDataset(Dataset):
# 定义自定义数据集类
def __init__(self, image_folder, label_folder, xishu=1):
self.image_folder = image_folder # 图像文件夹路径
self.label_folder = label_folder # 标签文件夹路径
# 获取图像和标签文件名列表
self.filenames = get_filename(self.image_folder, filetype='TIF')
# 将文件名列表重复xishu次,因为我们数据太少了,这样方便训练
self.filenames = self.filenames * xishu
self.images_path = [self.image_folder + i for i in self.filenames]
self.labels_path = [self.label_folder + i for i in self.filenames]
def __len__(self):
# 返回数据集的长度,即图像文件的数量
return len(self.images_path)
# 请见xy 用户:geedownload
# 或者xy 搜索 深度学习遥感地物分类-以建筑分割和多地物分割为例
if __name__ == "__main__":
image_path=r'../datasets/train/image/'
label_path=r'../datasets/train/label/'
dataset = RSDataset(image_path, label_path)
# img,label=dataset[50]
rsdata_loader = DataLoader(dataset, batch_size=8, shuffle=True, num_workers=8, pin_memory=True, drop_last=True)
print(len(rsdata_loader.dataset))输出为:357,为data/train/image或data/train/label中图片的数量
3.4选择合适的模型架构
这里我们选用UNet做为主要模型,模型代码来源于网络,供学习参考。
3.4.1UNET模型介绍
UNET是一种卷积神经网络(CNN)架构,最初被设计用于生物医学图像分割任务。它采用了一种独特的"U"形结构,使得网络能够精确地定位图像中的目标对象,并对其进行分割。
UNET的工作原理基于编码器(下采样)和解码器(上采样)的结构。编码器通过卷积层和池化层逐渐减小图像的尺寸,同时提取特征;解码器则通过转置卷积层(或上采样)逐步恢复图像尺寸,并合并来自编码器的特征,以生成最终的分割图像。
下图为UNET模型的示意图,图中的特征大小由输入图片,卷积步长以及是否采用padding等决定,此处仅做示意作用,具体模型请参考代码与详细模型结构图。
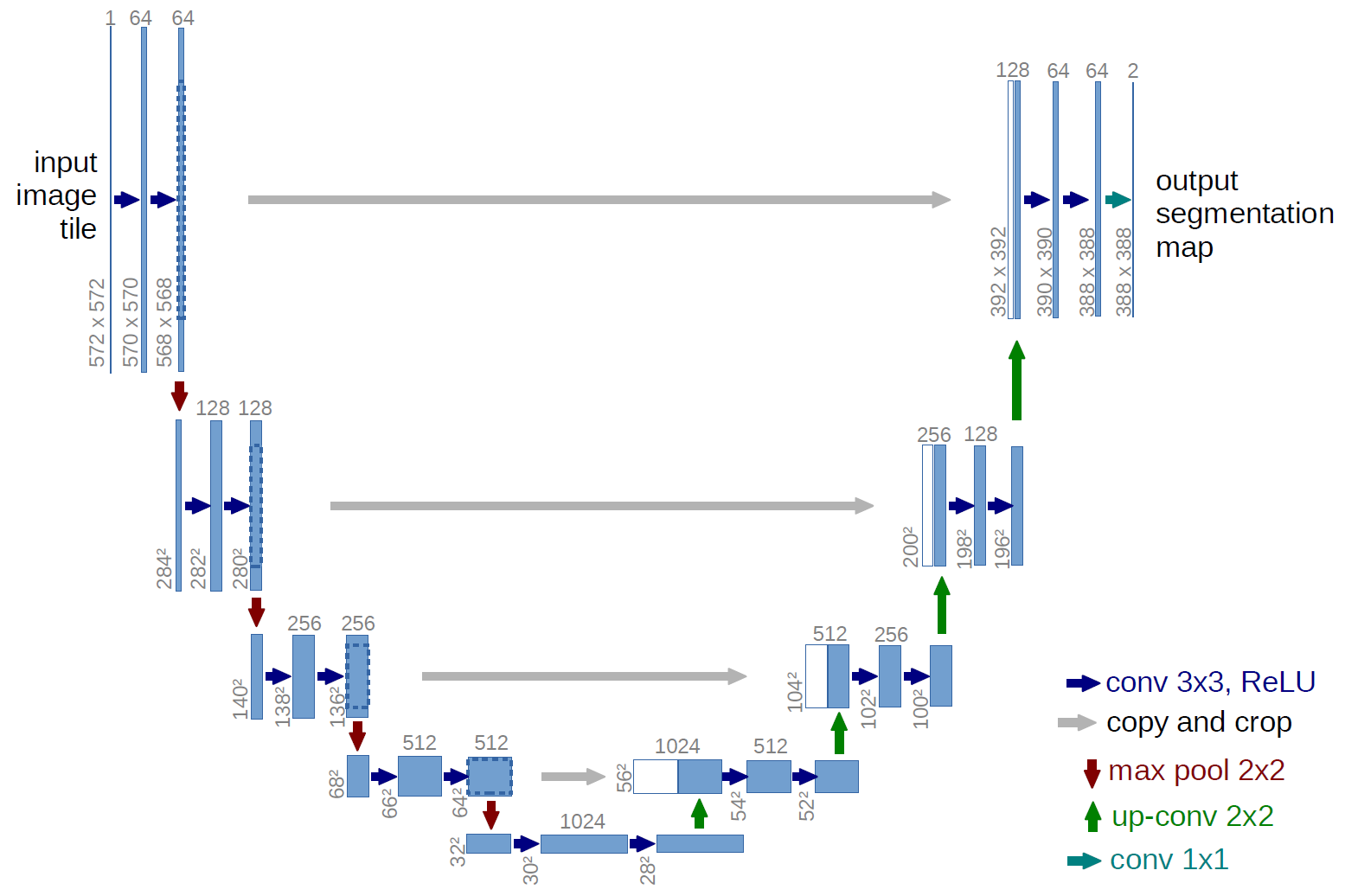
3.4.2 UNET代码实现
""" Parts of the U-Net model """
import torch
import torch.nn as nn
import torch.nn.functional as F
class DoubleConv(nn.Module):
"""(convolution => [BN] => ReLU) * 2"""
def __init__(self, in_channels, out_channels, mid_channels=None):
super().__init__()
if not mid_channels:
mid_channels = out_channels
self.double_conv = nn.Sequential(
nn.Conv2d(in_channels, mid_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
nn.Conv2d(mid_channels, out_channels, kernel_size=3, padding=1),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
return self.double_conv(x)
class Down(nn.Module):
"""Downscaling with maxpool then double conv"""
def __init__(self, in_channels, out_channels):
super().__init__()
self.maxpool_conv = nn.Sequential(
nn.MaxPool2d(2),
DoubleConv(in_channels, out_channels)
)
def forward(self, x):
return self.maxpool_conv(x)
class Up(nn.Module):
"""Upscaling then double conv"""
def __init__(self, in_channels, out_channels, bilinear=True):
super().__init__()
# if bilinear, use the normal convolutions to reduce the number of channels
if bilinear:
self.up = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.conv = DoubleConv(in_channels, out_channels, in_channels // 2)
else:
self.up = nn.ConvTranspose2d(in_channels , in_channels // 2, kernel_size=2, stride=2)
self.conv = DoubleConv(in_channels, out_channels)
def forward(self, x1, x2):
x1 = self.up(x1)
# input is CHW
diffY = x2.size()[2] - x1.size()[2]
diffX = x2.size()[3] - x1.size()[3]
x1 = F.pad(x1, [diffX // 2, diffX - diffX // 2,
diffY // 2, diffY - diffY // 2])
# if you have padding issues, see
# https://github.com/HaiyongJiang/U-Net-Pytorch-Unstructured-Buggy/commit/0e854509c2cea854e247a9c615f175f76fbb2e3a
# https://github.com/xiaopeng-liao/Pytorch-UNet/commit/8ebac70e633bac59fc22bb5195e513d5832fb3bd
x = torch.cat([x2, x1], dim=1)
return self.conv(x)
class OutConv(nn.Module):
def __init__(self, in_channels, out_channels):
super(OutConv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size=1)
def forward(self, x):
return self.conv(x)
""" Full assembly of the parts to form the complete network """
import torch.nn.functional as F
from models.unet.unet_parts import *
class UNet(nn.Module):
def __init__(self, n_channels, n_classes, bilinear=True):
super(UNet, self).__init__()
self.n_channels = n_channels
self.n_classes = n_classes
self.bilinear = bilinear
self.inc = DoubleConv(n_channels, 64) # (convolution => [BN] => ReLU) * 2
self.down1 = Down(64, 128) # Downscaling with maxpool(2) then double conv
self.down2 = Down(128, 256)
self.down3 = Down(256, 512)
factor = 2 if bilinear else 1
self.down4 = Down(512, 1024 // factor)
self.up1 = Up(1024, 512 // factor, bilinear)
self.up2 = Up(512, 256 // factor, bilinear)
self.up3 = Up(256, 128 // factor, bilinear)
self.up4 = Up(128, 64, bilinear)
self.outc1 = OutConv(64, 32)
self.outc2 = OutConv(32, 16)
self.outc3 = OutConv(16, 8)
self.outc4 = OutConv(8, n_classes)
def forward(self, x):
x1 = self.inc(x)
x2 = self.down1(x1)
x3 = self.down2(x2)
x4 = self.down3(x3)
x5 = self.down4(x4)
x = self.up1(x5, x4)
x = self.up2(x, x3)
x = self.up3(x, x2)
x = self.up4(x, x1)
logits = self.outc1(x)
logits = self.outc2(logits)
logits = self.outc3(logits)
logits = self.outc4(logits)
return logits
if __name__ == "__main__":
model = UNet(n_channels=4, n_classes=24)
# 创建一个示例网络
import netron
import onnx
print(model)
model.eval()
input = torch.rand(1, 4, 256, 256)
output = model(input)
print(output.size())
torch.onnx.export(model=model, args=input, f='model.onnx', input_names=['image'], output_names=['feature_map'])
onnx.save(onnx.shape_inference.infer_shapes(onnx.load("model.onnx")), "model.onnx")
netron.start("model.onnx")输出的网络结构为:
UNet(
(inc): DoubleConv(
(double_conv): Sequential(
(0): Conv2d(4, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
(down1): Down(
(maxpool_conv): Sequential(
(0): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(1): DoubleConv(
(double_conv): Sequential(
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
)
)
(down2): Down(
(maxpool_conv): Sequential(
(0): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(1): DoubleConv(
(double_conv): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
)
)
(down3): Down(
(maxpool_conv): Sequential(
(0): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(1): DoubleConv(
(double_conv): Sequential(
(0): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
)
)
(down4): Down(
(maxpool_conv): Sequential(
(0): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(1): DoubleConv(
(double_conv): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
)
)
(up1): Up(
(up): Upsample(scale_factor=2.0, mode='bilinear')
(conv): DoubleConv(
(double_conv): Sequential(
(0): Conv2d(1024, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(512, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
)
(up2): Up(
(up): Upsample(scale_factor=2.0, mode='bilinear')
(conv): DoubleConv(
(double_conv): Sequential(
(0): Conv2d(512, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
)
(up3): Up(
(up): Upsample(scale_factor=2.0, mode='bilinear')
(conv): DoubleConv(
(double_conv): Sequential(
(0): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
)
(up4): Up(
(up): Upsample(scale_factor=2.0, mode='bilinear')
(conv): DoubleConv(
(double_conv): Sequential(
(0): Conv2d(128, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
)
(outc1): OutConv(
(conv): Conv2d(64, 32, kernel_size=(1, 1), stride=(1, 1))
)
(outc2): OutConv(
(conv): Conv2d(32, 16, kernel_size=(1, 1), stride=(1, 1))
)
(outc3): OutConv(
(conv): Conv2d(16, 8, kernel_size=(1, 1), stride=(1, 1))
)
(outc4): OutConv(
(conv): Conv2d(8, 24, kernel_size=(1, 1), stride=(1, 1))
)
)
torch.Size([1, 24, 256, 256])
此图是模型的具体结构,并模拟了输入一张256*256大小的4通道图像,输出24分类结果的数据流。
3.5模型训练与评估
模型的训练与评估一般是交叉进行的,用训练集训练一轮或者多轮,用验证集进行一次评估。边训练边评估,可以实时监测模型的效果与训练过程,防止过拟合,并不断调整超参数,使得模型优化到理想的效果。
在训练前,还需要设置一些超参数,如学习率、lr调度器模式、损失函数的动量、训练的epoch数、训练输入的batch大小等等,具体设置见代码。
import os
import torch
import argparse
from dataloaders import data_loader
from torch.utils.data import DataLoader
from models.unet.unet_model import UNet
from evaluations.metrics import EvaluatorMC
from utils.lr_scheduler import LR_Scheduler
from utils.saver import Saver
from utils.summaries import TensorboardSummary
from utils.replicate import patch_replication_callback
from utils.utils import AverageMeter
from tqdm import tqdm
import time
import torch.nn as nn
torch.backends.cudnn.benchmark = True
class Trainer(object):
def __init__(self, args):
# 实验记录
self.args = args
self.saver = Saver(args) # 创建模型保存文件夹
self.saver.save_experiment_config() # 保存args参数
self.summary = TensorboardSummary(self.saver.experiment_dir) # 在保存路径下建立tensorboard可视化日志
self.writer = self.summary.create_summary() # 定义SummaryWriter
# 训练集
self.train_dataset = data_loader.RSDataset(args.input_dir_train, args.label_dir_train,xishu=10)
self.train_loader = DataLoader(self.train_dataset, batch_size=args.batch_size, shuffle=True, num_workers=8,pin_memory=True, drop_last=True)
# 验证集
self.val_dataset = data_loader.RSDataset(args.input_dir_val, args.label_dir_val)
self.val_loader = DataLoader(self.val_dataset, batch_size=args.batch_size,shuffle=False, num_workers=4, pin_memory=True, drop_last=False)
# 定义网络
self.model = UNet(n_channels=4, n_classes=24)
train_params = self.model.parameters()
# 定义优化器
self.optimizer = torch.optim.SGD(train_params, momentum=args.momentum,weight_decay=args.weight_decay, nesterov=args.nesterov,lr= self.args.lr)
# 定义损失函数
self.critersion = nn.CrossEntropyLoss().cuda()
# 定义评价指标
self.evaluator = EvaluatorMC(num_classes=24)
# 学习率衰减函数
self.scheduler = LR_Scheduler(args.lr_scheduler, args.lr, args.epochs, len(self.train_loader))
# 是否使用GPU
if args.cuda:
self.model = torch.nn.DataParallel(self.model, device_ids=self.args.gpu_ids)
patch_replication_callback(self.model)
self.model = self.model.cuda()
# 混合梯度下降
self.scaler = torch.cuda.amp.GradScaler()
# 加载预训练模型
self.best_pred = 0.0
if args.resume is not None:
if not os.path.isfile(args.resume):
raise RuntimeError("=> no checkpoint found at '{}'" .format(args.resume))
checkpoint = torch.load(args.resume)
args.start_epoch = checkpoint['epoch']
if args.cuda:
self.model.load_state_dict(checkpoint['state_dict'])
else:
self.model.load_state_dict(checkpoint['state_dict'],)
if not args.ft:
self.optimizer.load_state_dict(checkpoint['optimizer'])
self.best_pred = checkpoint['best_pred']
print("=> loaded checkpoint '{}' (epoch {})".format(args.resume, checkpoint['epoch']))
if args.ft:
args.start_epoch = 0
# 请见xy 用户:geedownload
# 或者xy 搜索 深度学习遥感地物分类-以建筑分割和多地物分割为例
def main():
# 创建一个参数解析器
parser = argparse.ArgumentParser(description="mydata数据实验")
# 优化器参数
parser.add_argument('--lr', type=float, default=0.001, metavar='LR',
help='学习率 (默认: auto)')
parser.add_argument('--lr-scheduler', type=str, default='poly',
choices=['poly', 'step', 'cos'],
help='lr调度器模式: (默认: poly)')
parser.add_argument('--momentum', type=float, default=0.9,
metavar='M', help='动量 (默认: 0.9)')
parser.add_argument('--weight-decay', type=float, default=5e-4,
metavar='M', help='权重衰减 (默认: 5e-4)')
parser.add_argument('--nesterov', action='store_true', default=False,
help='是否使用Nesterov (默认: False)')
# 随机种子,GPU,参数保存
parser.add_argument('--no-cuda', action='store_true', default=False,
help='禁用CUDA训练')
parser.add_argument('--gpu-ids', type=str, default='0',
help='使用哪个GPU进行训练,必须是整数列表 (默认=0)')
parser.add_argument('--seed', type=int, default=1, metavar='S',
help='随机种子 (默认: 1)')
parser.add_argument('--ft', action='store_true', default=False, # False
help='在不同的数据集上进行微调')
# 训练参数配置
parser.add_argument('--epochs', type=int, default=100, metavar='N',
help='训练的epoch数 (默认: auto)')
parser.add_argument('--start_epoch', type=int, default=0,
metavar='N', help='开始epochs (默认:0)')
parser.add_argument('--batch-size', type=int, default=64,
metavar='N', help='训练输入的batch大小 (默认: auto)')
parser.add_argument('--resume', type=str, default=None,
help='如果需要,将模型权重文件的路径放入其中')
parser.add_argument('--expname', type=str, default='mydata',
help='设置检查点名称')
parser.add_argument("--input_dir_train", default=r'../../datasets/train/image/', type=str)
parser.add_argument("--label_dir_train", default=r'../../datasets/train/label/', type=str)
parser.add_argument("--input_dir_val", default=r'../../datasets/val/image/', type=str)
parser.add_argument("--label_dir_val", default=r'../../datasets/val/label/', type=str)
# 解析参数
args = parser.parse_args()
# 检查CUDA是否可用
args.cuda = not args.no_cuda and torch.cuda.is_available()
# 如果使用CUDA,解析GPU ID
if args.cuda:
try:
args.gpu_ids = [int(s) for s in args.gpu_ids.split(',')]
except ValueError:
raise ValueError('Argument --gpu_ids must be a comma-separated list of integers only')
# 设置随机种子
torch.manual_seed(args.seed)
# 创建训练器
trainer = Trainer(args)
# 打印参数
print(args)
# 打印开始和总epoch数
print('Starting Epoch:', trainer.args.start_epoch)
print('Total Epoches:', trainer.args.epochs)
# 遍历每个epoch
for epoch in range(trainer.args.start_epoch, trainer.args.epochs):
# 训练
trainer.training(epoch)
# 验证
trainer.validation(epoch)
# 关闭writer
trainer.writer.close()
if __name__ == "__main__":
main()本代码训练10轮,保存模型一轮,输出与模型保存在run对应的目录下。
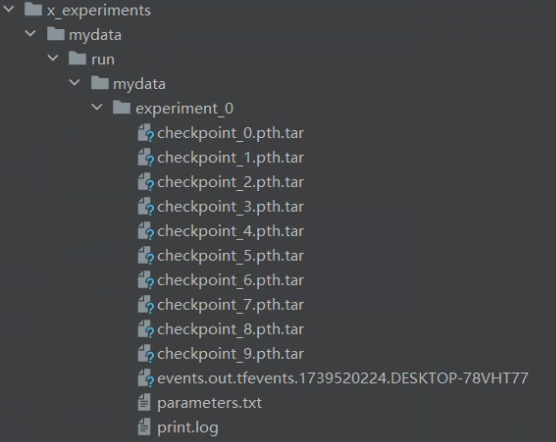
其中print.log中存放了训练过程中的输出。
Using poly LR Scheduler!
Namespace(batch_size=64, cuda=True, epochs=100, expname='mydata', ft=False, gpu_ids=[0], input_dir_train='../../datasets/train/image/', input_dir_val='../../datasets/val/image/', label_dir_train='../../datasets/train/label/', label_dir_val='../../datasets/val/label/', lr=0.001, lr_scheduler='poly', momentum=0.9, nesterov=False, no_cuda=False, resume=None, seed=1, start_epoch=0, weight_decay=0.0005)
Starting Epoch: 0
Total Epoches: 100
=>Epoches 0, learning rate = 0.001000, previous best = 0.000000
[Epoch: 0, numImages: 3520, time: 0.89]
Loss: 166.432019
Validation:
[Epoch: 0]
accuracy:0.3723, Miou:0.0268, FWiou:0.3626
=>Epoches 1, learning rate = 0.000991, previous best = 0.000000
[Epoch: 1, numImages: 3520, time: 0.75]
Loss: 126.690249
Validation:
[Epoch: 1]
accuracy:0.9138, Miou:0.0609, FWiou:0.8350
=>Epoches 2, learning rate = 0.000982, previous best = 0.000000
[Epoch: 2, numImages: 3520, time: 0.76]
Loss: 79.845032
Validation:
[Epoch: 2]
accuracy:0.8872, Miou:0.0555, FWiou:0.7872
=>Epoches 3, learning rate = 0.000973, previous best = 0.000000
[Epoch: 3, numImages: 3520, time: 0.76]
Loss: 65.936344
Validation:
[Epoch: 3]
accuracy:0.9297, Miou:0.0581, FWiou:0.8643
=>Epoches 4, learning rate = 0.000964, previous best = 0.000000
[Epoch: 4, numImages: 3520, time: 0.75]
Loss: 57.989609
Validation:
[Epoch: 4]
accuracy:0.9126, Miou:0.0592, FWiou:0.8415
=>Epoches 5, learning rate = 0.000955, previous best = 0.000000
[Epoch: 5, numImages: 3520, time: 0.75]
Loss: 51.435939
Validation:
[Epoch: 5]
accuracy:0.9461, Miou:0.2392, FWiou:0.9001
=>Epoches 6, learning rate = 0.000946, previous best = 0.000000
[Epoch: 6, numImages: 3520, time: 0.76]
Loss: 45.419788
Validation:
[Epoch: 6]
accuracy:0.8363, Miou:0.2304, FWiou:0.7496
=>Epoches 7, learning rate = 0.000937, previous best = 0.000000
[Epoch: 7, numImages: 3520, time: 0.76]
Loss: 40.720757
Validation:
[Epoch: 7]
accuracy:0.8289, Miou:0.2056, FWiou:0.7351
=>Epoches 8, learning rate = 0.000928, previous best = 0.000000
[Epoch: 8, numImages: 3520, time: 0.75]
Loss: 38.601218
Validation:
[Epoch: 8]
accuracy:0.9185, Miou:0.2677, FWiou:0.8514
=>Epoches 9, learning rate = 0.000919, previous best = 0.000000
[Epoch: 9, numImages: 3520, time: 0.75]
Loss: 34.592023
Validation:
[Epoch: 9]
accuracy:0.8990, Miou:0.2517, FWiou:0.8181
=>Epoches 10, learning rate = 0.000910, previous best = 0.000000
[Epoch: 10, numImages: 3520, time: 0.75]
Loss: 32.118557
Validation:
[Epoch: 10]
accuracy:0.8788, Miou:0.2268, FWiou:0.80143.6模型测试
由于训练集和验证集都参与了模型的训练,需要使用从未参与过训练与优化的测试集进行精度验证,该精度才能较为真实的代表模型的效果。
我们选择验证精度最优的模型或者训练次数最多的模型进行测试,代码如下
import os
import torch
import numpy as np
from models.unet.unet_model import UNet
from evaluations.metrics import EvaluatorMC
from utils.replicate import patch_replication_callback
from osgeo import gdal
def main():
# 加载权重文件路径
weights_path = "./run/mydata/experiment_0/checkpoint_9.pth.tar"
# 加载测试图像文件夹路径
image_folder = "../../datasets/test/image/"
# 加载测试标签文件夹路径
label_folder = "../../datasets/test/label/"
# 加载预测结果保存文件夹路径
pre_folder = "../../datasets/test/pre/"
# 检查路径是否存在
assert os.path.exists(weights_path), f"weights {weights_path} not found."
assert os.path.exists(image_folder), f"image {image_folder} not found."
assert os.path.exists(label_folder), f"image {label_folder} not found."
assert os.path.exists(pre_folder), f"image {pre_folder} not found."
# 获取文件名列表
filenames = get_filename(image_folder, filetype='TIF')
# 获取图像路径列表
images_path = [image_folder + i for i in filenames]
# 获取标签路径列表
labels_path = [label_folder + i for i in filenames]
# 获取预测结果保存路径列表
pre_path = [pre_folder + i for i in filenames]
# 创建模型
model = UNet(n_channels=4, n_classes=24)
# 将模型设置为多GPU模式
model = torch.nn.DataParallel(model, device_ids=[0])
# 将模型复制到所有GPU上
patch_replication_callback(model)
# 将模型移动到GPU上
model = model.cuda()
# 加载权重
checkpoint = torch.load(weights_path,weights_only=True)
model.load_state_dict(checkpoint['state_dict'])
# 将模型设置为评估模式
model.eval()
# 创建评估器
evaluator = EvaluatorMC(num_classes=24)
# 在不计算梯度的情况下进行预测
with torch.no_grad():
# 重置评估器
evaluator.reset()
# 遍历所有图像
for idx in range(len(images_path)):
# 加载图像
im_proj, im_geotrans, im_width, im_height, image = readimg(images_path[idx])
image = image/1.0
# 加载标签
label = readimg(labels_path[idx])[4]
label[(label < 1) | (label > 24)] = 0 # 将背景标签置为0
# 图像标准化
mean = [380.4740078, 258.59853866, 216.03595979, 176.54910684]
std = [38.86907341, 35.75741774, 44.72163728, 47.94977936]
for i in range(image.shape[0]):
image[i] = (image[i] - mean[i]) / std[i]
# 转换为PyTorch张量
image = torch.from_numpy(image).float()
image = torch.unsqueeze(image, dim=0)
image = image.cuda()
label = torch.from_numpy(label).long()
# 使用模型进行预测
output = model(image)
# 对输出进行softmax处理
output = torch.nn.Softmax(dim=1)(output)
# 获取每个像素的最大概率类别
output = torch.argmax(output, dim=1)
# 将预测结果转换为numpy数组
prediction = output.cpu().numpy().astype(np.int8)
# 将预测结果保存为图像文件
prediction = prediction.squeeze(0)
writeimg(pre_path[idx], im_proj, im_geotrans, prediction)
# 将标签和预测结果添加到评估器中
evaluator.add_batch(label.numpy(), output.cpu().numpy())
# 计算评估指标
accuracy, Miou, FWiou = evaluator.cal()
# 打印评估指标
print("accuracy:{:.4f}, Miou:{:.4f}, FWiou:{:.4f}".format(accuracy, Miou, FWiou))
if __name__ == '__main__':
main()此处我们使用了迭代次数最多的模型,对测试集进行预测并计算精度,精度指标如下。
accuracy:0.9062, Miou:0.3750, FWiou:0.8418
精度还是比较可以的。
3.7模型应用
既然是应用创新,模型通过分块小图训练和验证后,需要应用在原始遥感影像上,但是遥感影像往往几个G甚至十几G,因为显存的限制,如果一下放入模型进行预测往往是不太现实的,需要经过分割、预测、拼接、赋予空间信息等一系列操作,具体代码如下:
import numpy as np
from tqdm import tqdm
from torch.backends import cudnn
import os
import torch
from models.unet.unet_model import UNet
from utils.replicate import patch_replication_callback
from osgeo import gdal
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
cudnn.enabled = True
CropSize=1000
RepetitionRate=0.1
classbands = 24
inputimg=r'../../datasets/data/GF2_PMS1__L1A0000564539-MSS1.tif'
outputimg=r'../../datasets/data/GF2_PMS1__L1A0000564539-MSS1_pre.tif'
weights_path = "./run/mydata/experiment_0/checkpoint_9.pth.tar"
#定义相关函数
def get_filename(path, filetype):
name = []
final_name = []
for root, dirs, files in os.walk(path):
for i in files:
if filetype in i[-4:]:
name.append(i.replace(filetype, '')) #生成不带'.shp'后缀的文件名组成的列表
final_name = [item + filetype for item in name] #生成'.shp'后缀的文件名组成的列表
return final_name #输出由有filetype后缀的文件名组成的列表
# 创建模型
model = UNet(n_channels=4, n_classes=24)
# 将模型设置为多GPU模式
model = torch.nn.DataParallel(model, device_ids=[0])
# 将模型复制到所有GPU上
patch_replication_callback(model)
# 将模型移动到GPU上
model = model.cuda()
# 加载权重
checkpoint = torch.load(weights_path,weights_only=True)
model.load_state_dict(checkpoint['state_dict'])
# 将模型设置为评估模式
model.eval()
# 将大图裁剪为一系列小图
img_list,num=TifCrop(inputimg, CropSize=CropSize, RepetitionRate=RepetitionRate)
product_list=[]
# 对每一张小图进行预测
for i in tqdm(range(num)):
image=img_list[i]
image = image / 1.0
mean = [380.4740078, 258.59853866, 216.03595979, 176.54910684]
std = [38.86907341, 35.75741774, 44.72163728, 47.94977936]
for i in range(image.shape[0]):
image[i] = (image[i] - mean[i]) / std[i]
# 转换为PyTorch张量
image = torch.from_numpy(image).float()
image = torch.unsqueeze(image, dim=0)
image = image.cuda()
# 使用模型进行预测
output = model(image)
# 对输出进行softmax处理
output = torch.nn.Softmax(dim=1)(output)
# # 获取每个像素的最大概率类别
# output = torch.argmax(output, dim=1)
# 将预测结果转换为numpy数组
prediction = output.cpu().detach().numpy()
# 将预测结果加入product_list
prediction = prediction.squeeze(0)
product_list.append(prediction)
TifStitch(inputimg, product_list, outputimg, RepetitionRate, classbands)
遥感影像

预测结果
请见xy 用户:geedownload
或者xy 搜索 深度学习遥感地物分类-以建筑分割和多地物分割为例