在本教程中,我们将从零开始,使用 Ollama 本地大模型(Qwen2.5:7B) + LangChain + Neo4j 图数据库,构建一个完整的中文知识图谱系统。整个流程包括:
- 本地部署 Ollama 和 Neo4j(通过 Docker)
- 编写自定义 Prompt 提取结构化三元组
- 将结果写入 Neo4j 并可视化
所有组件均运行在本地,无需联网调用 API,适合隐私敏感或离线场景。
🔧 一、环境准备
1. 安装 Docker(如未安装)
bash
# Ubuntu / Debian
sudo apt update && sudo apt install docker.io -y
sudo systemctl start docker
sudo usermod -aG docker $USER # 将当前用户加入 docker 组(需重新登录)
# macOS / Windows:请安装 Docker Desktop2. 启动 Ollama(使用 Docker)
bash
docker run -d \
--gpus=all \ # 如有 NVIDIA GPU 可加速(非必需)
-p 11434:11434 \
--name ollama \
-v ollama:/root/.ollama \
ollama/ollama⚠️ 若无 GPU,去掉
--gpus=all即可。
然后拉取 Qwen2.5:7B 模型(首次运行会自动下载):
bash
docker exec -it ollama ollama pull qwen2.5:7b验证是否成功:
bash
curl http://localhost:11434/api/generate -d '{
"model": "qwen2.5:7b",
"prompt": "你好"
}'3. 启动 Neo4j(使用 Docker)
bash
docker run -d \
--name neo4j \
-p 7474:7474 \
-p 7687:7687 \
-v neo4j_data:/data \
-v neo4j_logs:/logs \
-e NEO4J_AUTH=neo4j/your_password \
neo4j:5.18✅ 请将
your_password替换为你自己的密码(例如neo4j123),后续代码中需保持一致。
访问 http://localhost:7474(或你的服务器 IP),用用户名 neo4j 和设置的密码登录。
📦 二、Python 环境依赖
创建虚拟环境并安装依赖:
bash
python -m venv kg-env
source kg-env/bin/activate # Windows: kg-env\Scripts\activate
pip install langchain-ollama \
langchain-experimental \
langchain-core \
neo4j \
graphviz💡 注意:
graphviz是 Python 包,还需安装系统级 Graphviz:
- Ubuntu:
sudo apt install graphviz- macOS:
brew install graphviz- Windows: 从 https://graphviz.org/download/ 安装并加入 PATH
🧩 三、完整 Python 脚本:构建中文知识图谱
将以下代码保存为 build_kg.py:
python
from langchain_ollama import ChatOllama
from langchain_experimental.graph_transformers import LLMGraphTransformer
from langchain_core.documents import Document
from langchain_core.prompts import ChatPromptTemplate
from neo4j import GraphDatabase
import time
from graphviz import Digraph
# 1. LLM 配置(指向本地 Ollama)
llm = ChatOllama(
model="qwen2.5:7b",
temperature=0,
base_url="http://192.168.31.161:11434" # ← 改为你的服务器 IP 或 localhost
)
# 2. 自定义中文 Prompt(严格约束实体与关系类型)
custom_prompt = ChatPromptTemplate.from_messages([
("system", """你是一名专业的中文知识图谱构建专家,请严格根据以下文本内容提取结构化的实体与关系。
【提取规则】
1. 实体类型仅限以下四类:
- Person:人物(如 马化腾、张一鸣)
- Organization:组织或公司(如 腾讯、字节跳动、中国科学院)
- Location:地理位置(如 北京、广东省深圳市、长三角)
- Product:产品或技术(如 微信、抖音、鸿蒙系统)
2. 关系类型仅限以下六种:
- FOUNDED:A 创立了 B(例:马化腾 --FOUNDED--> 腾讯)
- BORN_IN:A 出生于 B(例:雷军 --BORN_IN--> 湖北仙桃)
- HEADQUARTERED_IN:A 总部位于 B(例:阿里巴巴 --HEADQUARTERED_IN--> 杭州市)
- DEVELOPED:A 开发了 B(例:张小龙 --DEVELOPED--> 微信)
- CEO_OF:A 担任 B 的 CEO(仅当明确提及"CEO"、"首席执行官"等职务时使用)
- COMMITTED_TO:A 致力于 B(如企业使命、战略方向,需原文明确表述)
3. 重要原则:
- 所有实体名称必须使用原文中的完整表述,不得缩写或改写(如"腾讯公司"不能简化为"腾讯"除非原文如此)。
- 仅提取文本中**明确陈述**的事实,禁止推理、联想或补充常识。
- 若文本未提及某类信息(如出生地、CEO),则不生成对应关系。
- 不输出任何解释、说明或额外文本,仅返回符合格式的三元组。
请基于以下输入文本进行提取:
"""),
("human", "{input}")
])
# 3. 图转换器
llm_transformer = LLMGraphTransformer(
llm=llm,
prompt=custom_prompt,
allowed_nodes=["Person", "Organization", "Location", "Product"],
allowed_relationships=["CEO_OF", "BORN_IN", "FOUNDED", "HEADQUARTERED_IN", "COMMITTED_TO", "DEVELOPED"]
)
# 4. 输入文档(中文示例)
documents = [
Document(page_content="""
马化腾(Pony Ma)是腾讯公司(Tencent)的创始人兼董事会主席,他出生于中国广东省汕头市。
腾讯是一家全球领先的互联网科技公司,总部位于中国广东省深圳市。
马化腾还主导了微信(WeChat)的开发,微信是中国最流行的即时通讯与社交平台。
"""),
]
print("🚀 开始提取知识图谱...")
graph_documents = []
for i, doc in enumerate(documents):
print(f"\n📄 正在处理第 {i+1}/{len(documents)} 个文档...")
start_time = time.time()
graph_doc = llm_transformer.convert_to_graph_documents([doc])
graph_documents.extend(graph_doc)
print(f"✅ 处理完成,耗时 {time.time() - start_time:.2f} 秒")
print("🔍 提取的节点:")
for node in graph_doc[0].nodes:
print(f"- {node.id} ({node.type})")
print("\n🔗 提取的关系:")
for rel in graph_doc[0].relationships:
print(f"- {rel.source.id} --[{rel.type}]--> {rel.target.id}")
# 5. 连接 Neo4j(替换为你的实际密码)
URI = "bolt://192.168.31.161:7687" # ← 改为你的 Neo4j 地址
USERNAME = "neo4j"
PASSWORD = "your_password" # ← 必须与 Docker 启动时一致
driver = GraphDatabase.driver(URI, auth=(USERNAME, PASSWORD))
def create_graph(tx, graph_doc):
# 清空旧数据(可选)
tx.run("MATCH (n) DETACH DELETE n")
# 创建节点
for node in graph_doc.nodes:
tx.run("MERGE (n:`%s` {id: $id})" % node.type, id=node.id)
# 创建关系
for rel in graph_doc.relationships:
tx.run("""
MATCH (source {id: $source_id})
MATCH (target {id: $target_id})
MERGE (source)-[r:%s]->(target)
""" % rel.type, source_id=rel.source.id, target_id=rel.target.id)
print("\n💾 正在写入 Neo4j...")
try:
with driver.session() as session:
for graph_doc in graph_documents:
session.execute_write(create_graph, graph_doc)
print("✅ 写入成功!打开浏览器查看图谱:http://192.168.31.161:7474")
except Exception as e:
print(f"❌ 写入失败:{e}")
print("请检查:Neo4j 是否运行?密码是否正确?网络是否通?")
# 6. 从 Neo4j 读取并导出为图片
def fetch_graph_from_neo4j(tx):
result = tx.run("""
MATCH (a)-[r]->(b)
RETURN a.id AS a, labels(a)[0] AS a_type,
type(r) AS rel,
b.id AS b, labels(b)[0] AS b_type
""")
return list(result)
def save_neo4j_graph_as_image(records, filename="knowledge_graph"):
dot = Digraph(format="png", graph_attr={"rankdir": "LR"})
for r in records:
dot.node(r["a"], f"{r['a']}\n({r['a_type']})")
dot.node(r["b"], f"{r['b']}\n({r['b_type']})")
dot.edge(r["a"], r["b"], label=r["rel"])
path = dot.render(filename, cleanup=True)
print(f"🖼️ 图谱已保存为:{path}.png")
# 导出图片
with driver.session() as session:
records = session.execute_read(fetch_graph_from_neo4j)
if records:
save_neo4j_graph_as_image(records)
else:
print("⚠️ Neo4j 中无数据,跳过图片导出")
driver.close()
print("\n🎉 全部完成!")
print("👉 在 Neo4j 浏览器中运行以下 Cypher 查询查看图形:")
print("MATCH (n)-[r]->(m) RETURN n, r, m")▶️ 四、运行脚本
bash
python build_kg.py预期输出:
开始提取知识图谱...
正在处理第 1/1 个文档...
处理完成,耗时 62.47 秒
提取的节点:
- 马化腾 (Person)
- 腾讯公司 (Organization)
- 中国广东省汕头市 (Location)
- 中国广东省深圳市 (Location)
- 微信 (Product)
提取的关系:
- 马化腾 --[FOUNDED]--> 腾讯公司
- 马化腾 --[BORN_IN]--> 中国广东省汕头市
- 腾讯公司 --[HEADQUARTERED_IN]--> 中国广东省深圳市
- 马化腾 --[DEVELOPED]--> 微信
正在手动写入 Neo4j(无APOC问题)...
写入成功!现在浏览器里一定能看到完整图谱了
全部完成!去浏览器 http://192.168.31.161:7474 运行以下查询查看图形:
MATCH (n)-[r]->(m) RETURN n,r,m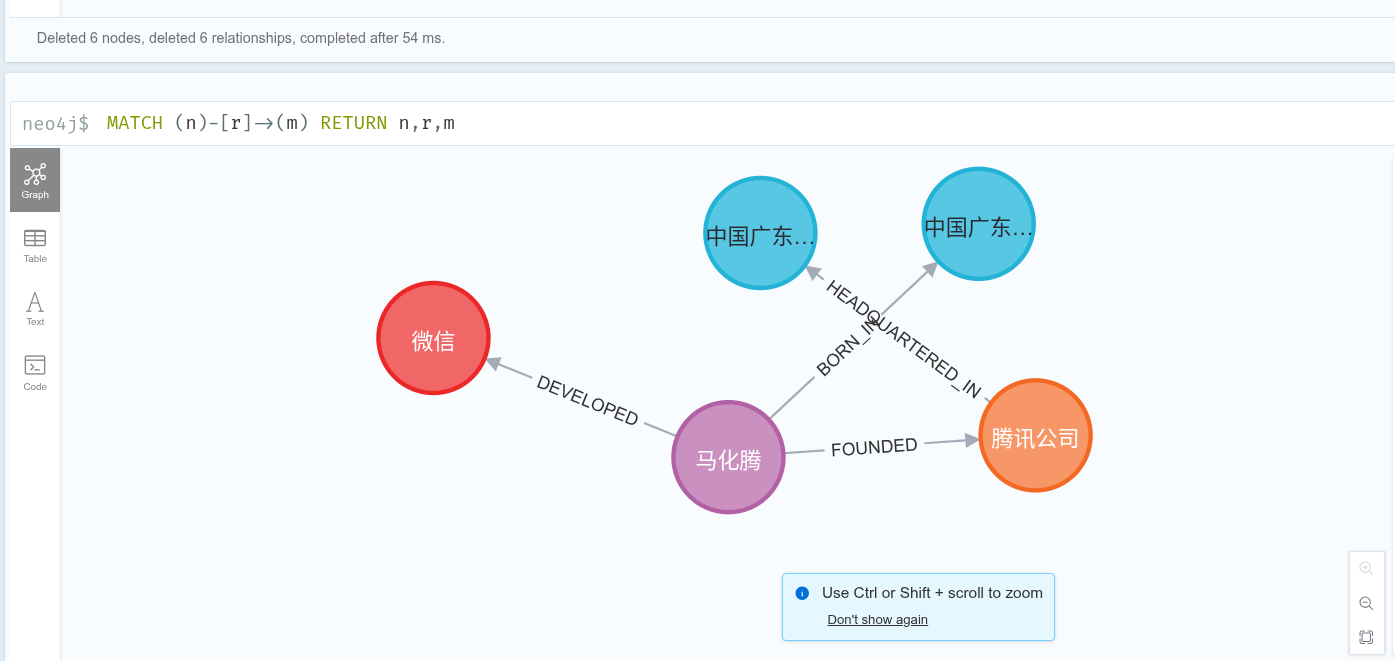
同时,在 Neo4j 浏览器中执行:
cypher
MATCH (n)-[r]->(m) RETURN n, r, m即可看到交互式图谱!
✅ 五、常见问题排查
| 问题 | 解决方案 |
|---|---|
Connection refused |
检查 Ollama/Neo4j 是否在运行:docker ps |
Authentication failed |
确认 NEO4J_AUTH 密码与代码中一致 |
| 提取结果为空 | 检查 Prompt 是否适配中文;尝试 temperature=0.1 |
| Graphviz 报错 | 安装系统级 Graphviz(非仅 pip 包) |
| IP 地址不对 | 将 192.168.31.161 改为 localhost(本地测试) |
🌟 六、扩展建议
- 增加更多文档批量处理
- 添加实体消歧(如"马化腾" vs "Pony Ma")
- 使用
unstructured库解析 PDF/Word - 部署为 FastAPI 服务提供 KG 查询接口
📚 结语
通过本教程,你已经掌握了如何利用 开源大模型 + 图数据库 构建端到端的中文知识图谱系统。整个流程完全本地化,安全可控,适合企业内网或科研场景。