大语言模型的生成能力十分强大,但也同样容易遭到滥用,检测文本是否由模型产生是缓解潜在危害的重要手段。分享一篇发表于 2023 年 ICML 会议的论文,该研究提出了一种用于生成式模型针对输出文本的水印技术。
猴先生:这篇文章首先提出了红绿列表技术(Red-Green List),用于对模型生成的文本添加水印以及检测水印。该技术思路巧妙很有前景,后续有相关研究继续跟进。
1 背景介绍
大语言模型能够撰写文档、生成可执行代码、理解和回答问题,其能力常与人类水平相当。随着这些系统日益普及,其被用于恶意目的的风险也逐渐增加。这些风险包括制造虚假新闻和网络内容,以及在学术写作和编程作业中作弊。此外,大量合成数据使数据集创建工作变得复杂,必须在模型训练前进行检测和排除。
论文专注于语言模型输出的水印技术,这是一种隐藏在文本中的人类难以察觉的特定模式,可通过算法识别文本是否为合成内容。作者提出了一种高效的水印方案,仅需少量标记(最低 25 个标记)即可检测出合成文本,同时将人类文本误判为机器生成的概率极低。

图1 语言模型应用水印前后示例
如图 1 所示,对模型应用论文所提水印方案前后输出的对比。若包含水印的文本由人类撰写,预期应有 9 个"绿色"单词,实际却包含 28 个,随机出现此事件的概率约为 6 × 10 ( − 14 ) 6 \times 10 ^ {(-14)} 6×10(−14) 。水印检测算法可公开允许第三方本地运行,或保持私有通过 API 后台运行。
2 基础知识
语言模型拥有一个包含词元或词元片段(token)的词汇表 V V V,典型词汇表包含 ∣ V ∣ = 50 , 000 |V|=50,000 ∣V∣=50,000 个或更多词元。考虑由 T T T 个词元组成的序列 { s ( t ) } ∈ V T \{s(t)\} \in V^T {s(t)}∈VT。负索引的元素 s ( − N p ) s^{(-N_p)} s(−Np) 至 s ( − 1 ) s^{(-1)} s(−1) 表示长度为 N p N_p Np 的提示词,而 s ( 0 ) s^{(0)} s(0) 至 s ( T ) s^{(T)} s(T) 则是模型响应生成的词元序列。
用于下一个词预测的语言模型可看作为一个函数,通常由神经网络参数化。它接受一个已知的token序列 s ( − N p ) , ⋅ ⋅ ⋅ , s ( − 1 ) s^{(-N_p)},···,s^{(-1)} s(−Np),⋅⋅⋅,s(−1) 作为输入,该序列包含提示词和已生成的前 t − 1 t-1 t−1 个词元。模型输出 ∣ V ∣ |V| ∣V∣ 个逻辑值(logits),对应词汇表中每个词元的倾向程度,随后通过softmax算子转换为词汇表上的离散概率分布。位置 t t t 处的下一个词元通过标准多项式采样,或进行贪心采样从该分布中抽取。
向上述语言模型应用水印技术,需要考虑对低熵序列进行水印处理的难题。举例说明,有如下两个序列,其中加粗部分为提示词:
- The quick brown fox jumps over the lazy dog
- for(i= 0;i<n;i++) sum+=arrayi
这是由人类生成还是语言模型生成?从根本上说很难判断,因为这些序列的熵值(entropy)极低,即开头的几个词元就基本决定了后续词元的走向。
低熵文本为水印技术带来两个难题。首先,对于低熵提示词,人类和模型给出的补全内容即使不完全相同也高度相似,导致无法区分二者。其次,低熵文本难以嵌入水印,因为任何改动都可能产生高困惑度的异常词汇,从而降低文本质量。
猴先生:因此,论文首先提出了硬水印方案,这是红绿列表技术的核心思想。然后,为了应对低熵文本带来的影响,设计了软水印方案以优化水印嵌入。
3 硬水印方案
硬水印方案针对当前词元,在词汇便中生成一个伪随机的红色列表,在列表中的词元禁止作为下一个词元出现。红色列表的生成以前一个词元作为种子,使得后续无需访问完整词元序列即可复现红色列表。算法 1 描述了该方案的伪代码。
算法 1: 硬水印嵌入文本生成算法
- 输入:提示词, s ( − N p ) , ⋅ ⋅ ⋅ , s ( − 1 ) s^{(-N_p)},···,s^{(-1)} s(−Np),⋅⋅⋅,s(−1)
- for t = 0 , 1 , ⋅ ⋅ ⋅ t = 0,1,··· t=0,1,⋅⋅⋅ do
- 应用语言模型到现有的词元序列 s ( − N p ) , ⋅ ⋅ ⋅ , s ( t − 1 ) s^{(-N_p)},···,s^{(t-1)} s(−Np),⋅⋅⋅,s(t−1),获得预测下一个词元的词汇表概率向量 p ( t ) p^{(t)} p(t)。
- 计算词元 s ( t − 1 ) s^{(t-1)} s(t−1) 的哈希值,用它作为某个随机数生成器的种子。
- 使用该种子,随机将词汇表平等划分为"绿列表" G G G 和"红列表" R R R。
- 从集合 G G G 中采样下一个词元 s ( t ) s^{(t)} s(t),禁止出现红列表中的词元。
- end for
虽然生成带水印的文本需要访问语言模型,但检测水印无需此权限。掌握哈希函数和随机数生成器的第三方可为每个词元重新计算红列表,并统计违反红列表规则的次数。检测水印有如下假设。
假设:文本序列是在完全不了解红列表规则的情况下生成的。
由于红列表是随机选定的,自然写作预计会有一半的词元违反红列表规则,而带有水印的模型则不会产生任何违规。自然产生 T T T 个词元而不违反红列表规则的概率仅为 1 / 2 T 1/2^T 1/2T,哪怕对于只有十几个单词的短文本片段,这个概率也很微小。
一种更稳健的检测方法是采用单比例 z z z 检验值来评估零假设。若零假设成立,则绿列表词元数量(记为 ∣ s ∣ G |s|_G ∣s∣G)的期望值为 T / 2 T/2 T/2,方差为 T / 4 T/4 T/4。该检验值的 z z z 统计量为
z = 2 ( ∣ s ∣ G − T / 2 ) / T z=2(|s|_G - T/2)/ \sqrt{T} z=2(∣s∣G−T/2)/T
检验值 z z z 可以看作是水印嵌入的一个量化统计量,值越大则表示嵌入的水印信号越强,水印检测的置信度也越高。例如一段生成词元序列长度 T = 16 T=16 T=16 的文本,当 ∣ s ∣ G = T |s|_G=T ∣s∣G=T 时,即生成的每一个词元都标记水印,则产生 z = 4 z=4 z=4 的检验值。
4 软水印方案
硬水印方案以简单方式处理低熵序列,即直接禁止语言模型生成这类序列。例如在多文本数据集中,"Barack" 几乎必然后接 "Obama",但 "Obama" 可能在红列表中,从而不被选中生成。
更好的做法是采用一种"软性"水印,它仅对不易察觉水印存在的高熵文本生效。只要低熵序列被包裹在具有足够总熵的文本段落中,该段落仍能轻松触发水印检测器。软水印方案的机制是:当存在多个优质候选词时,优先引导模型使用绿列表中的高熵词汇,而对近乎确定的低熵词元几乎不产生影响。
猴先生:这里的高熵和低熵,指的是模型生成下一个词元时,在词汇表中采样的概率分布。概率分布如果集中在单个词元上,则熵值低;概率分布分散在多个词元上,则熵值高。
语言模型的最后一层输出一个对数几率向量 l ( t ) l^{(t)} l(t),这些对数几率通过softmax算子转换为概率向量 p ( t ) p^{(t)} p(t)。
p k ( t ) = e x p ( l k ( t ) ) / ∑ i e x p ( l i ( t ) ) p_k^{(t)}=exp(l_k^{(t)}) / \sum_i exp(l_i^{(t)}) pk(t)=exp(lk(t))/i∑exp(li(t))
软水印方案的措施是对绿列表中词元的逻辑值添加一个正向偏置 δ \delta δ,从而使得绿列表的词元在概率分布上得到一定程度上的增强,但在低熵情况下该增强几乎可忽略。算法 2 描述了该方案的伪代码。
算法 2: 软水印嵌入文本生成算法
- 输入:提示词, s ( − N p ) , ⋅ ⋅ ⋅ , s ( − 1 ) s^{(-N_p)},···,s^{(-1)} s(−Np),⋅⋅⋅,s(−1)
- 绿列表大小, γ ∈ ( 0 , 1 ) \gamma \in (0,1) γ∈(0,1)
- 偏置强度, δ > 0 \delta > 0 δ>0
- for t = 0 , 1 , ⋅ ⋅ ⋅ t = 0,1,··· t=0,1,⋅⋅⋅ do
- 应用语言模型到现有的词元序列 s ( − N p ) , ⋅ ⋅ ⋅ , s ( t − 1 ) s^{(-N_p)},···,s^{(t-1)} s(−Np),⋅⋅⋅,s(t−1),获得预测下一个词元的词汇表逻辑值向量 l ( t ) l^{(t)} l(t)。
- 计算词元 s ( t − 1 ) s^{(t-1)} s(t−1) 的哈希值,用它作为某个随机数生成器的种子。
- 使用该种子,随机将词汇表划分为大小为 γ ∣ V ∣ \gamma |V| γ∣V∣ 的"绿列表" G G G, 和大小为 ( 1 − γ ) ∣ V ∣ (1-\gamma) |V| (1−γ)∣V∣ 的"红列表" R R R。
- 应用偏置 δ \delta δ 到绿列表每个词元对应的逻辑值,并计算修改后的概率分布。
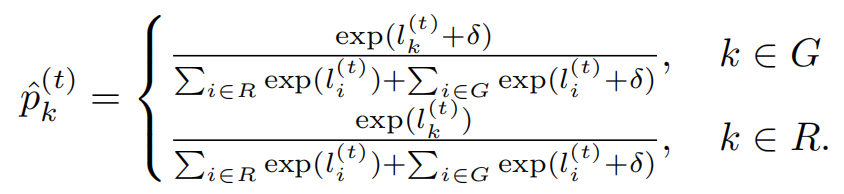
- 使用概率分布 p ^ \hat{p} p^ 从词汇表中采样下一个词元 s ( t ) s^{(t)} s(t)。
- end for
软水印的检测流程与硬水印完全相同。相应的检验值 z z z 定义如下:
z = ( ∣ s ∣ G − γ T ) / T γ ( 1 − γ ) z=(|s|_G - \gamma T) / \sqrt{T \gamma (1 - \gamma)} z=(∣s∣G−γT)/Tγ(1−γ)
对于软水印,检测合成文本的能力取决于序列的熵值:高熵序列只需相对较少的水印标记即可,而低熵序列则需要更多水印标记进行识别。
5 理论分析
文本的熵会影响水印的嵌入检测,导致硬水印方案会明显增大低熵文本的困惑度,即让文本的语义变得不通顺。软水印方案则自适应地调整了水印的嵌入时机,在高熵文本中高概率嵌入,在低熵文本中可忽略嵌入。
因此,论文有必要分析文本的熵与嵌入水印之间的关系,作者采用的是绿列表词元数量的期望作为水印指标。通过定义尖峰熵(spike entropy)来表现词元的分布,是集中于一个或少数几个词元,处于"尖峰"的状态。
定义:给定离散概率向量 p p p 和标量 z z z ,定义 p p p 关于系数 z z z 的尖峰熵为
S ( p , z ) = ∑ k p k 1 + z p k S(p,z)=\sum_{k} \frac{p_k}{1+zp_k} S(p,z)=k∑1+zpkpk
该定义与经典的香农熵类似,用于衡量分布的分散程度。当 p p p 全部概率集中于单一点时,尖峰熵取得最小值 1 1 + z \frac{1}{1+z} 1+z1;当 p p p 的概率均匀分布时,尖峰熵则达到最大值 N N + z \frac{N}{N+z} N+zN。对于较大的 z z z 值:
- 当 p k > 1 / z p_k > 1/z pk>1/z,求和项 p k 1 + z p k ≈ 1 / z \frac{p_k}{1+zp_k} \approx 1/z 1+zpkpk≈1/z;
- 当 p k < 1 / z p_k < 1/z pk<1/z,求和项 p k 1 + z p k ≈ 0 \frac{p_k}{1+zp_k} \approx 0 1+zpkpk≈0。
因此,可将尖峰熵理解为 p p p 中概率大于 1 / z 1/z 1/z 的元素数量的平滑度量。利用该定义,来预测带水印的序列中出现标记为绿色词元的数量。
考虑包含 T T T 个词元的带水印文本序列,每个词元从语言模型根据原始采样概率向量 p ( t ) p^{(t)} p(t) 生成,采样大小为 γ N \gamma N γN 的绿色列表,并在采样每个词元之前通过添加正向偏置 δ \delta δ 提升了其采样概率。
定义 α = e x p ( δ ) \alpha = exp(\delta) α=exp(δ),并用 ∣ s ∣ G |s|_G ∣s∣G 表示序列 s s s 中绿色列表的词元数量。
-
如果随机生成的水印序列平均尖峰熵至少为 S ⋆ S^{\star} S⋆,即
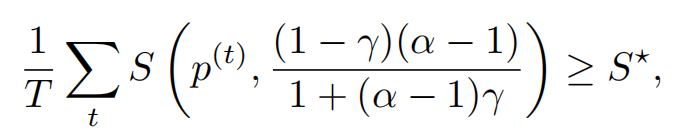
-
那么序列中有绿色列表水印标记的期望数量至少为,
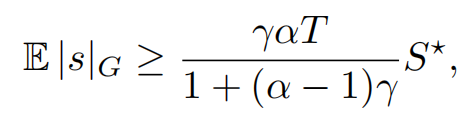
-
同时,绿色词元的数量最多具有方差。
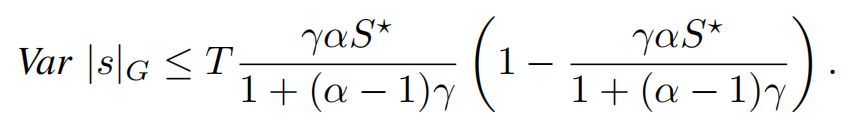
上面的分析展示了文本的熵,与软水印方案嵌入文本绿色词元数量的关系。文本熵值越大,绿色词元数量的期望值下限越大,也就意味着水印的信号强度越高,越容易被检测到。论文做了很多实验来来验证理论分析,更多细节请读者去看原文,这里不再赘述。
值得分享的点是,这篇论文的思路十分简洁并富有启发,而且方案构造与理论分析能够相互对应,使得所提方法很有说服力。我是先看到有文章提到了红绿列表技术,然后追根溯源找到这篇原始论文,看它是如何设计的。
最后,附上文献引用及论文链接:
Kirchenbauer J, Geiping J, Wen Y, et al. A watermark for large language models[C]//International Conference on Machine Learning. PMLR, 2023: 17061-17084.