1. Docker部分(快速入门)
1.1 Docker简介
docker本身是一个开源的容器化平台,开发者可以借助docker,将应用程序及其所需依赖打包成一个可移植,可部署的容器。
docker与传统虚拟机的区别?
传统虚拟机是模拟出独立的硬件与系统,并在此基础上创建应用程序。而docker则是在主机系统上建立多个应用和配套环境,把应用和配套环境独立打包为一个单位,这是进程级别的隔离。
1.2. Docker架构
1.2.1 Docker架构大体介绍
docker总体的架构可以分为三部分,分别是:Client、Docker Host、Registry,三部分各司其职。通过docker命令实现总体交互。
1.2.2 Docker Client
Docker Client是Docker的交互客户端,负责与用户进行交互,其交互形式是通过命令行进行交互。例如:
bash
docker build # 构建镜像
docker run # 启动镜像
docker pull # 拉取镜像通过输入不同的命令,Docker Client会向Docker的守护进程发送这些指令,而Docker的守护进程负责进一步的调度,从而实现不同的行为
1.2.3 Docker Host
Docker Host 是安装并运行 Docker 引擎(Docker Daemon,即守护进程)的主机。它负责管理容器、镜像、网络和存储等资源。Docker Host 接收来自 Docker Client 的请求,由其本地的 Docker 守护进程执行相应的操作,例如拉取镜像、创建和运行容器等。简言之,Docker Host 是实际运行和管理 Docker 工作负载的机器。
在 Docker Host 中:
- 镜像(Image) 是一个只读的模板,包含了运行应用程序所需的代码、运行时环境、库、配置文件等。它用于创建容器,本身不运行,是静态的。
- 容器(Container) 是镜像的运行实例。当镜像被启动(如通过
docker run)时,Docker Host 会基于该镜像创建一个可写层,并运行其中的程序,形成一个隔离的、轻量级的运行环境------这就是容器。
因此:镜像是静态的构建产物,容器是镜像的动态运行实例
1.2.4 Docker Registry
Docker Registry 是用于存储和分发 Docker 镜像的服务。它保存了镜像的仓库(Repository),每个仓库可以包含多个镜像版本(通过标签 Tag 区分)。用户可以通过 docker pull 从 Registry 下载镜像,或通过 docker push 将本地构建的镜像上传到 Registry。最常用的公共 Registry 是 Docker Hub,企业也可以搭建私有的 Registry(如使用 Harbor 或官方 registry 镜像)来管理内部镜像。
1.3 Docker的安装
针对Windows用户,如果想要在本机上运行一些中间件,推荐直接下载基于Windows的Linux子系统(即WSL),并下载docker hub,具体的操作可以参考安装 WSL | Microsoft Learn
安装好后,同时在Docker Hub中配置镜像加速源,docker hub -> 设置 -> Docker Engine,设置如下
bash
{
"builder": {
"gc": {
"defaultKeepStorage": "20GB",
"enabled": true
}
},
"experimental": false,
"registry-mirrors": [
"https://docker.1ms.run",
"https://docker.xuanyuan.me"
]
}1.4 Docker的使用
1.4.1 镜像相关命令
- 拉取镜像: docker pull
bash
docker pull nginx # 拉取镜像
docker pull nginx:latest # 等同于上面的命令,不指定版本,默认拉取最新版本镜像- 列出已有镜像:docker images
bash
docker images
# 输出示例
REPOSITORY TAG IMAGE ID CREATED SIZE
nginx latest ca871a86d45a 10 days ago 225MB
confluentinc/cp-kafka latest d20bd62f0182 6 weeks ago 858MB
confluentinc/cp-zookeeper latest 7610a50b13e7 8 months ago 1.75GB- REPOSITORY: 镜像所属仓库名称
- TAG:镜像标签,默认是latest,表示最新版本
- IMAGE ID:镜像ID,镜像的唯一标识
- CREATED:镜像创建时间
- SIZE:镜像大小
- 删除镜像:docker rmi
bash
docker rmi nginx
# 输出示例
Untagged: nginx:latest
Deleted: sha256:ca871a86d45a3ec6864dc45f014b11fe626145569ef0e74deaffc95a3b15b430-
对于latest标签,需要注意的事情
-
latest是一个普通的标签名,默认由镜像构建者打上,并不会保证其所指向该镜像的最新版本
-
在本地使用时,Docker 会使用本地已有的
xxx:latest镜像,不会自动检查远程是否有更新。 -
拉取镜像的时(如
docker pull xxx:latest):才会从远程 Registry 获取当前被标记为latest的那个镜像版本。 -
通常不建议在生产环境中使用latest标签,因为其语义模糊,无法表达具体的版本号,并且可能导致环境不一致、难以回滚等问题。
1.5.1 容器相关命令
- 运行镜像:docker run
bash
docker run -d -p 81:80 nginx- -d 表示后台运行
- -p 端口映射,左边为宿主机开放端口,右边为虚拟容器内部端口,例如上述案例中,宿主机的81端口映射到虚拟容器内部的80端口中
其他的可指定选项
- -P:随机端口映射
- -p:指定端口映射,其有以下几种格式
- ip:hostPort:containerPort 表示ip对应的主机的端口hostPort,与该容器的containerPort进行映射
- ip::containerPort 表示ip对应主机的端口containPort,与该容器的containerPort进行映射
- hostPort:containerPort 表示本机的端口hostPort,与该容器的containerPort进行映射
- containerPort 表示将容器的containerPort端口,随机映射到注解的高端口(等价于-P)
- --net:指定网络模式,该选项有以下可选参数
- --net=bridge: 默认选项,表示连接到默认的网桥
- --net=host: 容器使用宿主机的网络
- --net=container:Name-or-Id: 告诉Docker让新建的容器加入已有的容器的网络配置
- --net=none:不配置该容器的网络,用户可以自定义网络配置
这个命令会启动本地的nginx:latest镜像(不加标签默认是latest),如果本地没有该镜像,会优先从远程仓库中拉取该镜像再进行启动
-
停止容器:docker stop <容器id>
-
启动容器:docker start <容器id>
-
查看容器日志:docker logs <容器id>
-
查看容器其他命令:docker --help
1.5 Docker Compose
1.5.1 简单介绍
Docker Compose 是一个用于定义和运行多容器 Docker 应用的工具。通过一个 docker-compose.yml(或 compose.yaml)文件,用户可以配置应用所需的所有服务(如 Web、数据库、缓存等),然后通过一条命令启动或停止整个应用栈。
1.5.2 基本使用流程
1. 编写docker-compose.yaml文件
version: '3.8'
services:
web:
image: nginx:1.25
ports:
- "8080:80"
volumes:
- ./html:/usr/share/nginx/html
db:
image: mysql:8.0
environment:
MYSQL_ROOT_PASSWORD: example
ports:
- "3306:3306"2. 在该目录下执行命令:
docker compose up:创建并启动所有服务(加-d可后台运行)docker compose down:停止并移除所有容器、网络等资源docker compose ps:查看服务状态docker compose logs:查看日志
💡 注意:新版 Docker Desktop 已内置
docker compose(无空格)子命令(推荐),旧版可能需单独安装docker-compose(带连字符)。
优势:
- 声明式配置:所有依赖、端口、环境变量集中管理;
- 一键启停 :避免手动逐个运行多个
docker run; - 开发/测试友好:快速搭建本地多服务环境。
⚠️ 提示:生产环境中建议结合镜像版本号(如
nginx:1.25而非latest),确保环境一致性。
总结:一般情况下,可以直接借助AI快速生成初版的docker compose配置文件,再根据实际情况进行微调即可
1.6 Dockerfile
1.6.1 简单介绍
Dockerfile 是一个文本文件,包含一系列指令(Instructions),用于自动化构建 Docker 镜像。开发者通过编写 Dockerfile,定义应用运行所需的环境、依赖、代码和启动命令,Docker 会按顺序执行这些指令,生成一个可重复、可移植的镜像。
1.6.2 简单示例
1. 创建文件
# 使用官方 Python 3.11 镜像作为基础镜像
FROM python:3.11-slim
# 设置工作目录
WORKDIR /app
# 将本地 requirements.txt 复制到容器中,这里的 "."代指当前目录
COPY requirements.txt .
# 安装依赖
RUN pip install --no-cache-dir -r requirements.txt
# 复制应用代码到容器,.表示当前的目录
COPY . .
# 暴露容器端口(仅为文档说明,实际运行不依赖此指令)
EXPOSE 8000
# 容器启动时运行的命令,这里会以空格进行分割,相当于运行 python app.py
CMD ["python", "app.py"]核心指令说明:
FROM:指定基础镜像(必须是第一条非注释指令)WORKDIR:设置后续指令的工作目录COPY:将宿主机文件/目录复制到镜像中RUN:在构建时执行命令(如安装软件包)CMD:指定容器启动时默认执行的命令(可被docker run覆盖)EXPOSE:声明容器监听的端口(仅为提示,不自动发布端口)
2. 构建与使用
在Dockerfile的所在目录中执行:
docker build -t my-app:1.0-t 指定镜像名称和标签,. 表示构建上下文为当前目录。
运行构建好的镜像:
docker run -d -p 8000:8000 my-app:1.0💡 最佳实践:
- 使用明确版本的基础镜像 (如
python:3.11而非latest);- 合并
RUN指令减少镜像层数;- 利用
.dockerignore排除无关文件(如node_modules/,.git/);- 遵循最小化原则,只安装必要依赖。
1.6.3 镜像构建------运行
Dockerfile构建的过程,本质上是将该文件内部的不同命令,进行不同程度的封装。
RUN、COPY、ADD、ENV、WORKDIR等指令- 属于 "构建时"操作 ,用于准备应用程序运行所需的环境和文件 (如安装依赖、复制代码、设置路径等)。
- 这些操作的结果被固化到镜像的只读层中,成为镜像的一部分。
CMD、ENTRYPOINT指令- 属于 "运行时"元数据 ,定义了容器启动时默认要执行的命令 (即应用程序本身的入口)。
- 它们不会在构建时执行 ,而是被记录在镜像中,等到
docker run时才真正运行。
📦 所以,整个镜像 = 运行环境(由 RUN/COPY 等构建) + 启动指令(由 CMD/ENTRYPOINT 定义) 。构建完成后,这个镜像就是一个自包含、可移植的"应用包",在任何支持 Docker 的地方运行时,都能复现一致的行为。
1.7 搭建私有docker镜像仓库
1.7.1 构建并启动私有仓库地址
-
在本地目录中,创建一个用于存储镜像仓库的目录,例如/data/docker-registry目录
-
创建一个名为docker-compose.yml的文件,其中定义了私有仓库的配置,示例如下
version: '3'
services:
registry:
image: registry:2
container_name: docker-registry
restart: always
ports:
- "5000:5000" # 暴露端口
volumes:
- /data/docker-registry:/var/lib/registry # 数据卷挂载,持久化
- ./auth:/auth # 挂载包含 htpasswd 文件的目录
environment:
REGISTRY_STORAGE_DELETE_ENABLED: "true" # 允许删除镜像(可选)
REGISTRY_AUTH: htpasswd # 启用 htpasswd 认证
REGISTRY_AUTH_HTPASSWD_PATH: /auth/htpasswd # 指定 htpasswd 文件路径
REGISTRY_AUTH_HTPASSWD_REALM: "Registry Realm" # 可选:认证领域名称 -
在docker-compose.yml文件所在目录下,执行run命令
-d 参数可选,用于后台启动
docker compose up -d
1.7.2 设置私有仓库的账号密码
1, 下载加密包,在 Ubuntu/Debian 中,这个工具包叫 apache2-utils。
sudo apt update
sudo apt install apache2-utils-
创建auth目录,这个目录就是上面docker-compose.yml文件中,指定的密码目录
mkdir -p /data/docker-registry/auth
-
创建一个密码文件并添加用户 'admin',并添加密码
sudo htpasswd -Bc /data/docker-registry/auth/htpasswd admin
1.7.3 登录docker-registry
-
执行以下的命令,并登录账号密码\\
docker login 127.0.0.1:5000
注意:在登录的过程中,可能会遇到这样的问题:
yutao@LAPTOP-884J9O4I:/mnt/d/Program-Project/data/docker-registry$ docker login 127.0.0.1:5000
Username: admin
Password:
Error saving credentials: error storing credentials - err: exit status 1, out: ``
yutao@LAPTOP-884J9O4I:/mnt/d/Program-Project/data/docker-registry$这是因为在 WSL 中运行 docker login 时,Docker 默认会尝试使用一个凭据助手(如 docker-credential-desktop、docker-credential-secretservice 等)来安全地存储凭据。但在 WSL 环境中,这些助手可能不可用或配置不正确,导致保存失败。
我们可以采用以下命令解决,其原理是禁用凭据助手
mkdir -p ~/.docker
cat > ~/.docker/config.json <<EOF
{
"credsStore": "",
"auths": {}
}
EOF随后再次登录,应该就能成功了
1.7.4 推送镜像到私有仓库
-
编辑
/etc/docker/daemon.json(若不存在则创建):sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<EOF
{
"insecure-registries": ["127.0.0.1:5000"]
}
EOF -
然后重启 Docker:
sudo systemctl restart docker
-
拉取一个测试镜像(例如
hello-world或nginx)docker pull nginx:alpine
-
给镜像打上私有 registry 的标签
docker tag nginx:alpine 127.0.0.1:5000/my-nginx:latest
格式:
<registry-host>:<port>/<repo-name>:<tag>
-
推送镜像
docker push 127.0.0.1:5000/my-nginx:latest
-
查看镜像是否推送成功(示例,admin:abc123321替换为自己的账密)
curl --user admin:abc123321 http://127.0.0.1:5000/v2/
yutao@LAPTOP-884J9O4I:/mnt/d/Program-Project/data/docker-registry curl --user admin:abc123321 http://127.0.0.1:5000/v2/ _catalog {"repositories":["my-nginx"]} yutao@LAPTOP-884J9O4I:/mnt/d/Program-Project/data/docker-registry
2. k8s部分
2.1 k8s简介
-
k8s官方文档:Kubernetes 文档 | Kubernetes
-
K8s 就是 Kubernetes 的简称(用数字 8 代替了中间的 8 个字母)。
3. 为什么需要k8s?
在不使用k8s的时候,我们通常会通过docker,将应用封装到虚拟容器内部运行。但是当一个应用需要大量这样的容器时,人工管理会变得十分复杂。而k8s就是用来自动化部署、扩展和管理这些容器化应用的开源平台。
4. k8s的特点?
- 自动化: K8s 可以自动帮你把应用部署到服务器上。
- 自我修复: 如果某个容器崩溃了,K8s 会自动重启它;如果服务器坏了,它会把容器转移到其他健康的服务器上。
- 弹性伸缩: 就像橡皮筋一样,流量大时它自动增加容器数量,流量小时自动减少,帮你省钱又保证服务不卡顿。
5. k8s如何工作(架构是怎样的)?
| 组件名称 | 角色 | 功能描述 |
|---|---|---|
| Master (控制平面) | 集群的大脑 | 负责管理整个集群,决定把容器放在哪里运行,监控状态。 |
| Node (工作节点) | 工人的手脚 | 真正运行容器的地方,负责执行 Master 下达的任务。 |
| Pod | 最小单元 | K8s 管理的最小单位,里面可以包含一个或多个紧密相关的容器。 |
- Pod: K8s 调度的最小单位是 Pod,而不是单个容器。一个Pod中可以装多个容器。
- Deployment: 用来定义你想要运行多少个 Pod,以及它们应该是什么样子的。比如"我要让我的网站一直保持 3 个实例在运行"。
- Service: 为 Pod 提供一个稳定的访问入口(IP 或域名)。因为 Pod 可能会随时挂掉重建,IP 地址会变,但 Service 的地址是不变的,它会自动把流量转发给背后的 Pod(负载均衡)。
6. 云原生与k8s
云原生的目标是什么?
| 维度 | 目标 | 云原生如何实现 |
|---|---|---|
| ✅ 敏捷性(Agility) | 快速响应市场变化,加速创新 | 微服务 + CI/CD + 自动化部署 → 每天发布上百次 |
| ✅ 弹性与效率(Efficiency) | 资源按需使用,成本最优 | 容器化 + K8s 自动扩缩容 → 流量低时自动缩容省成本 |
| ✅ 韧性与安全(Resilience & Security) | 系统稳定、故障自愈、安全内嵌 | 声明式编排 + 自愈机制 + 零信任安全 → 故障秒级恢复 |
因此,云原生是一套设计理念,而k8s则是其中的一种重要的技术实现形式
7. 总结
K8s 就像是一个**"云操作系统"**,它把一堆物理机或虚拟机整合成一个巨大的资源池,你只需要告诉它"我要运行什么应用、需要多少资源",它就会自动帮你搞定部署、扩容、故障恢复等所有复杂的事情。
2.2 Control Plane - Node 架构
K8s v1.20 起,官方已弃用 "Master/Slave" 术语,改用 Control Plane / Node,但"Master-Worker"说法仍广泛使用
1. 控制平面(Control Plane)------ 集群的大脑
部署在 1 个或多个高可用节点上,包含以下关键组件:
| 组件 | 功能说明 |
|---|---|
| kube-apiserver | 🧠 唯一入口:所有操作(kubectl、调度器、控制器等)都必须通过它。提供 RESTful API,负责认证、鉴权、验证和数据存取。 |
| etcd | 💾 数据中心 :分布式键值数据库,存储集群所有状态信息(如 Pod 配置、Service 规则、节点状态)。必须高可用(通常 3 或 5 节点)。 |
| kube-scheduler | 🗺️ 调度器 :监听未调度的 Pod,根据资源需求(CPU/内存)、亲和性、污点容忍等策略,选择最优 Node 来运行 Pod。 |
| kube-controller-manager | 🔁 控制器管家 :运行多个控制器(如 ReplicaSet Controller、Node Controller),确保实际状态 = 用户声明的期望状态(例如 Pod 挂了就自动重建)。 |
| cloud-controller-manager(可选) | ☁️ 云适配器:对接公有云(AWS/Azure/GCP),管理云资源(如负载均衡、路由表)。仅在云环境使用。 |
⚠️ 所有控制平面组件不直接通信,全部通过 kube-apiserver 中转,保证架构清晰、解耦。
2. 工作节点(Node)------ 集群的手脚
每个 Node 上必须运行以下组件:
| 组件 | 功能说明 |
|---|---|
| kubelet | 👷 节点代理 :与 Control Plane 通信,接收指令并管理本机 Pod 的生命周期(创建/启动/监控容器),定期上报节点状态。 |
| kube-proxy | 🌐 网络代理 :维护 Node 上的网络规则,实现 Service 的负载均衡和流量转发(支持 iptables/IPVS 模式),让 Pod 可被访问。 |
| Container Runtime | 📦 容器运行时 :真正运行容器的底层引擎,如 containerd 、CRI-O(Docker 已不再原生支持,需通过 cri-dockerd 适配)。 |
| Pod(逻辑单元) | 🫘 最小部署单位:一个或多个共享网络/存储的容器组合,由 kubelet 管理。 |
3. 典型工作流程(以创建一个 Pod 为例)
- 用户通过
kubectl提交创建 Pod 的请求。 - 请求经
kube-apiserver认证后,写入etcd。 kube-scheduler发现未调度的 Pod,选择一个合适的 Node。- 调度结果写回
etcd,目标 Node 上的kubelet监听到变化。 kubelet调用容器运行时(如 containerd)拉取镜像并启动容器。kube-proxy自动配置 iptables/IPVS 规则,使 Service 能访问该 Pod。
4. 总结
K8s 的 Control Plane - Node 架构,就是通过"一个智能大脑(Control Plane)指挥一群听话的手脚(Nodes)",实现对成千上万容器的自动化、高可靠、弹性化管理。
2.3 手动配置k8s集群
2.3.1 前置准备
- 在配置k8s集群前,需要有三台虚拟机,并分别安装了docker
2. 设置主机名解析
a. 三台虚拟机分别需要设置hostname为k8s-master、k8s-worker-01、k8s-worker-02,方便后续的解析
hostnamectl set-hostname k8s-master
hostnamectl set-hostname k8s-worker-01
hostnamectl set-hostname k8s-worker-02b. 验证:分别输入hostname指令,即可查询当前主机对应的主机名
c. 在每台主机中分别执行如下指令(注意,将对应的ip地址换为真实的虚拟机ip)
cat >> /etc/hosts << EOF
192.168.40.133 k8s-master
192.168.40.132 k8s-worker-01
192.168.40.131 k8s-worker-02
EOFd. 验证:在任意虚拟机中发送如下命令
ping k8s-master
ping k8s-worker-01
ping k8s-worker-02- 其他前置处理
a. 为Kubernetes 准备网络环境,确保 iptables 能正确处理容器网络流量。
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
br_netfilter
EOF-
作用 :让系统开机时自动加载
br_netfilter内核模块。 -
为什么需要?
Kubernetes 使用网桥(bridge)连接 Pod,这个模块能让iptables正确处理桥接流量。cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF -
作用 :开启桥接网络对
iptables的支持。 -
关键参数说明 :
-
net.bridge.bridge-nf-call-iptables = 1:允许 IPv4 流量通过 iptables 过滤。 -
net.bridge.bridge-nf-call-ip6tables = 1:允许 IPv6 流量通过 iptables 过滤。sudo sysctl --system
-
-
作用:立即应用上面的配置(无需重启)。
b. 关闭swap分区
# 1. 立即关闭 swap
sudo swapoff -a
# 2. 永久禁用(注释掉 /etc/fstab 中的 swap 行)
sudo sed -i '/swap/s/^/#/' /etc/fstab什么是swap?
Swap(交换空间) 是 Linux 用硬盘上的一块空间,当作"备用内存"。
- 当 物理内存(RAM)不够用 时,系统会把一部分暂时不用的数据挪到硬盘上的 swap 区,腾出内存给新程序用。
- 它就像"内存的替补",但速度比内存慢很多(因为硬盘比内存慢)。
为什么 Kubernetes 要关掉 swap?
- Kubernetes 需要 精确控制内存分配,而 swap 会让内存使用变得不可预测。
- 如果用了 swap,Pod 可能卡顿、调度异常,甚至导致节点不稳定。
- 所以 K8s 强制要求关闭 swap ,否则
kubeadm init会报错。
2.3.2 安装kubelet、kubeadm、kubectl
kubelet:运行在每个节点上的"代理",负责管理本机的 Pod 和容器(听从控制平面指挥)。kubeadm:用来快速安装和初始化 Kubernetes 集群的工具(比如创建 master 节点、加入 worker 节点)。kubectl:操作集群的命令行工具,你用它来查看 Pod、部署应用、管理资源等。
在所有节点上执行以下命令(以 CentOS/RHEL 为例):
# 1. 配置 Kubernetes 源(用阿里云镜像)
cat <<EOF | sudo tee /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
# 2. 安装三个组件(指定版本可加 -<版本号>,如-1.30.0),这里使用1.27.6,与后续的k8s初始化保持一致的版本
sudo yum install -y kubelet-1.27.6-0 kubeadm-1.27.6-0 kubectl-1.27.6-0
# 3. 启动 kubelet 并设为开机自启
sudo systemctl enable --now kubelet验证(输入一下命令,只要可以输出版本号,就说明没有问题)
# 查看 kubeadm 版本
kubeadm version
# 查看 kubelet 版本
kubelet --version
# 查看 kubectl 版本
kubectl version --client2.3.3 拉取k8s镜像
# 指定国内镜像源(避免超时)
kubeadm config images pull \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.27.6这条命令会自动拉取 Kubernetes 初始化需要的所有镜像(如 kube-apiserver、etcd 等),并重命名成官方格式。所有节点都可运行,但只需在 master 节点执行即可(worker 会按需拉取)。
拉取过程中,可能会出现如下问题:
[root@k8s-master wangyutao]# sudo kubeadm config images pull --image-repository=registry.aliyuncs.com/google_containers
I0111 02:17:51.831285 39801 version.go:256] remote version is much newer: v1.35.0; falling back to: stable-1.28
failed to pull image "registry.aliyuncs.com/google_containers/kube-apiserver:v1.28.15": output: time="2026-01-11T02:17:55-08:00" level=fatal msg="validate service connection: CRI v1 image API is not implemented for endpoint \"unix:///var/run/containerd/containerd.sock\": rpc error: code = Unimplemented desc = unknown service runtime.v1.ImageService"
, error: exit status 1
To see the stack trace of this error execute with --v=5 or higher
[root@k8s-master wangyutao]# 这个错误说明:
kubeadm 无法通过 CRI(容器运行时接口)和 containerd 通信,因为你的 containerd 版本较新,但配置未启用 CRI 插件。
解决方案:
1. 启用 containerd 的 CRI 支持
# 生成默认配置(如果还没有)
containerd config default > /etc/containerd/config.toml-
然后确保
/etc/containerd/config.toml中有这一行(通常默认已启用):[plugins."io.containerd.grpc.v1.cri"]
-
重启 containerd
systemctl restart containerd
-
再试一次拉取镜像
kubeadm config images pull --image-repository=registry.aliyuncs.com/google_containers
验证是否拉取成功
crictl images | grep -E 'kube-apiserver|etcd|coredns|pause|kube-controller-manager|kube-scheduler'验证过程中,可能会遇到这样的报错
[root@k8s-worker-02 wangyutao]# crictl images | grep -E 'kube-apiserver|etcd|coredns|pause|kube-controller-manager|kube-scheduler'
WARN[0000] image connect using default endpoints: [unix:///var/run/dockershim.sock unix:///run/containerd/containerd.sock unix:///run/crio/crio.sock unix:///var/run/cri-dockerd.sock]. As the default settings are now deprecated, you should set the endpoint instead.
E0111 02:58:23.133095 43413 remote_image.go:119] "ListImages with filter from image service failed" err="rpc error: code = Unavailable desc = connection error: desc = \"transport: Error while dialing dial unix /var/run/dockershim.sock: connect: no such file or directory\"" filter="&ImageFilter{Image:&ImageSpec{Image:,Annotations:map[string]string{},},}"
FATA[0000] listing images: rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial unix /var/run/dockershim.sock: connect: no such file or directory" 这个错误是因为
crictl尝试连接到默认的容器运行时端点(如/var/run/dockershim.sock),但找不到这些文件。这是因为 Kubernetes 已经移除了 dockershim 支持,并且你需要指定正确的容器运行时端点。
解决方案:
-
创建或修改 crictl 的配置文件
sudo tee /etc/crictl.yaml <<EOF
runtime-endpoint: unix:///run/containerd/containerd.sock
image-endpoint: unix:///run/containerd/containerd.sock
timeout: 10
debug: false
EOF -
再次验证
crictl images | grep -E 'kube-apiserver|etcd|coredns|pause|kube-controller-manager|kube-scheduler'
-
如果正常,那么输出类似于这样
registry.aliyuncs.com/google_containers/kube-apiserver v1.28.15 3b4e7c6a6b2d3 1.2GB
registry.aliyuncs.com/google_containers/kube-controller-manager v1.28.15 9f8f34c3e32d4 1.1GB
registry.aliyuncs.com/google_containers/kube-scheduler v1.28.15 5f8f34c3e32d4 95MB
registry.aliyuncs.com/google_containers/etcd 3.5.6-0 3b4e7c6a6b2d3 300MB
registry.aliyuncs.com/google_containers/pause 3.6 3b4e7c6a6b2d3 747kB
registry.aliyuncs.com/google_containers/coredns v1.8.6 3b4e7c6a6b2d3 41MB
2.3.4. 初始化k8s节点
-
在主节点机器上,运行如下命令
kubeadm init
--apiserver-advertise-address=192.168.40.133
--control-plane-endpoint=k8s-master
--image-repository=registry.aliyuncs.com/google_containers
--kubernetes-version=v1.27.6
--pod-network-cidr=10.244.0.0/16 -
初始化好后,需要额外做以下事情
启用环境变量(在init的日志输出中会有提示)
export KUBECONFIG=/etc/kubernetes/admin.conf-
为kubectl配置kubeconfig文件,复制 admin.conf 到当前用户的 kube 目录即可
mkdir -p HOME/.kube sudo cp -i /etc/kubernetes/admin.conf HOME/.kube/config
sudo chown (id -u):(id -g) $HOME/.kube/config -
验证集群
查看节点(应该显示 k8s-master 为 Ready)
kubectl get nodes
查看系统 Pod
kubectl get pods -n kube-system
✅ 当 STATUS 为 Ready ,且所有系统 Pod 都 Running,说明集群已就绪!
2.3.5 worker节点加入集群
-
需要在每个worker节点中,执行如下命令(需要以root账户执行)
kubeadm join k8s-master:6443
--token 2gqq4k.sjwepar0hk1ffsog
--discovery-token-ca-cert-hash sha256:8fee861ec4f673fec0dab223c2cdd7facc7cf74339a256e1177787952c52d0d5 -
其中的token、discovery-token-ca-cert-hash,需要从主节点初始化成功的日志中获取,也可以通过以下命令中直接获取到,并对上述的命令进行替换即可
1. 列出当前有效的 token
kubeadm token list
如果没有有效 token(默认 24 小时过期),可以创建一个新 token:
kubeadm token create
2. 获取 discovery-token-ca-cert-hash
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'
3. 也可以通过这个命令一次性获取所有信息
kubeadm token create --print-join-command
输出示例:kubeadm join k8s-master:6443 --token abcd12.efgh34ijkl56mnop --discovery-token-ca-cert-hash sha256:8fee861ec4f673fec0dab223c2cdd7facc7cf74339a256e1177787952c52d0d5
-
检查节点状态。通过以下命令检查节点启动状态
kubectl get pods -n kube-flannel -w
输出示例
[root@k8s-master ~]# kubectl get pods -n kube-flannel -w
NAME READY STATUS RESTARTS AGE
kube-flannel-ds-jwdv8 1/1 Running 0 28m
kube-flannel-ds-qwt7b 1/1 Running 0 28m
kube-flannel-ds-vrvfj 1/1 Running 0 28m- 搭建服务测试
在主节点中,输入一下命令,拉取nginx镜像并搭建pod,测试能否搭建成功
kubectl run test-nginx --image=nginx输出成功示例
kubectl get pods
NAME READY STATUS RESTARTS AGE
test-nginx 1/1 Running 0 11m到这里,k8s集群的搭建就算圆满完成了!
2.4 kubectl命令使用
2.4,1 kubectl简介
kubectl官方文档:命令行工具 (kubectl) | Kubernetes
kubectl(发音为 "cube control" 或 "kube control")是 Kubernetes 官方提供的命令行工具(CLI),用于与 Kubernetes 集群进行交互。它是用户管理、操作和调试 Kubernetes 资源的核心工具。
核心作用
- 与 Kubernetes API Server 通信 :
kubectl通过读取$HOME/.kube/config(即 kubeconfig 文件)中的集群地址、认证信息等,向控制平面发送请求。 - 管理集群资源:可以创建、查看、更新、删除 Pod、Deployment、Service、Namespace 等各种 Kubernetes 对象。
- 调试与监控:支持查看日志、进入容器、检查事件、描述资源状态等。
2.4.2 kubectl常用命令
1. kubectl的命令格式
kubectl [command] [TYPE] [NAME] [flags]command:操作,如get、describe、deleteTYPE:资源类型,如pod、service、deployment(可缩写,如po、svc、deploy)NAME:资源名称(可选)flags:选项,如-n namespace、--kubeconfig等
2. kubectl常用命令总结
查看资源(Get)
kubectl get pods # 查看 Pod
kubectl get nodes # 查看节点
kubectl get svc # 查看 Service
kubectl get deploy # 查看 Deployment
kubectl get ns # 查看命名空间
kubectl get all -n <namespace> # 查看某命名空间下所有资源查看详细信息(Describe)
kubectl describe pod <pod-name> # 查看 Pod 详情(事件、状态等)
kubectl describe node <node-name> # 查看节点详情(资源、污点等)创建/删除资源
kubectl create -f file.yaml # 从 YAML 创建资源
kubectl apply -f file.yaml # 声明式创建或更新资源(推荐)
kubectl delete -f file.yaml # 删除 YAML 中定义的资源
kubectl delete pod <pod-name> # 直接删除某个 Pod日志与进入容器
kubectl logs <pod-name> # 查看 Pod 日志
kubectl logs -f <pod-name> # 实时跟踪日志(类似 tail -f)
kubectl exec -it <pod-name> -- /bin/sh # 进入容器执行 shell端口转发(调试用)
kubectl port-forward svc/<service-name> 8080:8080 -n <ns>
# 将本地 8080 端口转发到集群中某服务的 8080 端口其他实用命令
kubectl top pod # 查看 Pod CPU/内存使用(需 Metrics Server)
kubectl top node # 查看节点资源使用
kubectl explain pod # 查看 Pod 的 API 字段说明
kubectl config view # 查看当前 kubeconfig 配置
kubectl cluster-info # 查看集群基本信息注意事项
- 加
-n <namespace>指定命名空间(默认是default) - 加
--help查看任意命令的帮助,例如:kubectl get pods --help - 使用别名简化:
alias k=kubectl,然后k get pod
2.5 命名空间
k8s命名空间文档:名字空间演练 | Kubernetes
命名空间(Namespace) 是k8s一种逻辑隔离机制,用于将集群中的资源(如 Pod、Service、Deployment 等)分组管理。
- 就像 "文件夹" 一样,把不同项目、团队或环境的资源分开。
- 默认有
default、kube-system、kube-public等命名空间。 - 不同命名空间里的资源名字可以重复 (比如两个 namespace 都可以有叫
web的 Pod)。 - 资源不能直接跨命名空间访问 (需用全名,如
service.namespace.svc.cluster.local)。
命令行查看所有的命名空间
# 三个命令都可以查看所有的namespaces
kubectl get namespace
kubectl get ns
kubectl get namespaces四个默认的命名空间
default:用户创建资源时未指定命名空间,就会放在这里。kube-system:Kubernetes 系统组件(如 kube-apiserver、coredns、kube-proxy)所在的空间。kube-public:公共资源,所有用户(包括未认证的)都可读,通常包含集群信息(如 cluster-info ConfigMap)。kube-node-lease:用于存储节点心跳信息(Node Lease),帮助快速检测节点是否存活。
✅ 这些命名空间在集群初始化时自动创建,不要手动删除或修改。
2.6 Pod
2.6.1 Pod简介
Pod 是 Kubernetes 中最小的部署和调度单元。其特性如下:
- 一个 Pod 可以包含 一个或多个容器(通常是一个主容器,有时加一些辅助容器,叫 Sidecar)。
- 同一个 Pod 里的容器共享网络、存储和生命周期 :它们有相同的 IP 地址、能通过
localhost互相访问,并一起被调度到同一个节点上。 - Pod 是短暂的(ephemeral):一旦被删除,就不会恢复(由控制器如 Deployment 负责重建)。
Pod = 一个或多个紧密协作的容器 + 共享资源 + 最小调度单位。
2.6.2 创建Pod
- 创建Pod示例:运行一个nginx容器
通过命令行方式
kubectl run mynginx --image=nginx:1.14.2- 通过指定的yaml文件创建pod
创建如下文件(例如mynginx-01.yaml)
apiVersion: v1
kind: Pod
metadata:
name: mynginx
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:latest运行命令
kubectl apply -f mynginx-01.yaml2.6.3 Pod其他常用命令
-
查看pod状态
查看状态
kubectl get pods
输出样例
NAME READY STATUS RESTARTS AGE
mynginx 1/1 Running 0 2m45s
test-nginx 1/1 Running 0 64m查看详细状态
kubectl get pods -owide
输出样例
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
mynginx 1/1 Running 0 5m29s 10.244.1.2 k8s-worker-02
test-nginx 1/1 Running 0 67m 10.244.2.2 k8s-worker-01 -
删除pod
kubectl delete pod test-nginx
-
为某个pod生成详细的运行时状态清单
这里会查询到容器运行时候的状态
kubectl get pod mynginx -o yaml
这里会将运行时候的状态导出到nginx-pod.yaml文件中
kubectl get pod mynginx -o yaml > nginx-pod.yaml
.查看该yaml文件
vim nginx-pod.yaml输出样例
# Kubernetes API 版本和资源类型
apiVersion: v1
kind: Pod
# 元数据:描述 Pod 的基本信息(由系统或用户定义)
metadata:
# 系统自动记录的创建时间(通常无需手动指定)
creationTimestamp: "2026-01-12T10:08:45Z"
# 标签,通常由 `kubectl run` 自动生成,用于选择器或分类
labels:
run: mynginx
# Pod 名称(必须)
name: mynginx
# 所属命名空间(默认为 default)
namespace: default
# 资源版本号,Kubernetes 内部用于乐观并发控制(不可修改)
resourceVersion: "15633"
# 全局唯一标识符(UUID),由系统生成
uid: 9a17b40e-5410-4694-8fc3-b820a245ac8c
# spec:声明你希望 Pod 达到的"期望状态"(declarative configuration)
spec:
# 容器列表(至少一个)
containers:
- # 镜像地址(未指定 registry 默认为 docker.io/library/)
image: nginx:1.14.2
# 镜像拉取策略:本地有就不拉(适合测试;生产建议 Always)
imagePullPolicy: IfNotPresent
# 容器名称(必须)
name: mynginx
# 资源限制(空表示无限制,默认 BestEffort QoS)
resources: {}
# 容器终止时写入消息的路径(用于调试退出原因)
terminationMessagePath: /dev/termination-log
# 终止消息的读取方式
terminationMessagePolicy: File
# 挂载 ServiceAccount Token(用于访问 Kubernetes API)
volumeMounts:
- mountPath: /var/run/secrets/kubernetes.io/serviceaccount
name: kube-api-access-7xhx6
readOnly: true
# DNS 策略:使用集群内部 DNS(如 CoreDNS)
dnsPolicy: ClusterFirst
# 是否自动注入服务环境变量(如 MY_SERVICE_HOST)
enableServiceLinks: true
# Pod 被调度到的具体节点(由调度器决定,一般不手动设置)
nodeName: k8s-worker-02
# 抢占策略:可抢占低优先级 Pod(高级调度特性)
preemptionPolicy: PreemptLowerPriority
# 优先级数值(0 表示普通 Pod)
priority: 0
# 容器退出后是否重启(Pod 级别策略)
restartPolicy: Always
# 使用的调度器名称
schedulerName: default-scheduler
# Pod 级别的安全上下文(如 runAsUser、fsGroup 等)
securityContext: {}
# 关联的 ServiceAccount(用于权限控制)
serviceAccount: default
serviceAccountName: default
# Pod 终止前等待的优雅停机时间(秒)
terminationGracePeriodSeconds: 30
# 容忍节点污点(允许在 not-ready 或 unreachable 节点上短暂停留)
tolerations:
- effect: NoExecute
key: node.kubernetes.io/not-ready
operator: Exists
tolerationSeconds: 300
- effect: NoExecute
key: node.kubernetes.io/unreachable
operator: Exists
tolerationSeconds: 300
# 自动挂载的卷:包含 token、ca.crt 和 namespace 信息
volumes:
- name: kube-api-access-7xhx6
projected:
defaultMode: 420 # 权限模式(八进制 644)
sources:
# ServiceAccount Token(用于认证 API Server)
- serviceAccountToken:
expirationSeconds: 3607
path: token
# 集群 CA 证书
- configMap:
items:
- key: ca.crt
path: ca.crt
name: kube-root-ca.crt
# Downward API:将 metadata.namespace 注入文件
- downwardAPI:
items:
- fieldRef:
apiVersion: v1
fieldPath: metadata.namespace
path: namespace
# status:Pod 当前的实际运行状态(只读,由 kubelet 更新)
status:
# Pod 生命周期各阶段的状态条件
conditions:
- lastProbeTime: null
lastTransitionTime: "2026-01-12T10:08:45Z"
status: "True"
type: Initialized # Init 容器已完成
- lastProbeTime: null
lastTransitionTime: "2026-01-12T10:10:01Z"
status: "True"
type: Ready # Pod 已就绪,可接收流量
- lastProbeTime: null
lastTransitionTime: "2026-01-12T10:10:01Z"
status: "True"
type: ContainersReady # 所有容器已就绪
- lastProbeTime: null
lastTransitionTime: "2026-01-12T10:08:45Z"
status: "True"
type: PodScheduled # 已成功调度到节点
# 容器实际运行状态
containerStatuses:
- containerID: containerd://0cb7469f478baa7114bde6e0cec1f2544307f345854bfd8d4fcffdbeb74be856
image: docker.io/library/nginx:1.14.2 # 实际使用的完整镜像名
imageID: docker.io/library/nginx@sha256:f7988fb6c02e0ce69257d9bd9cf37ae20a60f1df7563c3a2a6abe24160306b8d
lastState: {} # 上次终止状态(空表示首次启动)
name: mynginx
ready: true # 容器已通过就绪探针(如有)
restartCount: 0 # 重启次数
started: true # 容器已启动
state:
running:
startedAt: "2026-01-12T10:10:00Z" # 容器启动时间
# 节点 IP(物理机 IP)
hostIP: 192.168.40.131
# Pod 当前生命周期阶段(Pending/Running/Succeeded/Failed/Unknown)
phase: Running
# 分配给 Pod 的集群内部 IP(由 CNI 插件如 Flannel 分配)
podIP: 10.244.1.2
podIPs:
- ip: 10.244.1.2
# 服务质量等级(BestEffort = 无资源限制)
qosClass: BestEffort
# Pod 开始调度的时间
startTime: "2026-01-12T10:08:45Z"2.7 Deployment
2.7.1 Deployment简介
Deployment 是k8s中一种高级控制器对象,用于声明式地管理 Pod 的部署和生命周期,特别适用于无状态应用。其主要功能如下
- 副本管理(Replica Management)
自动维持指定数量的 Pod 副本(例如replicas: 3),如果某个 Pod 挂了,Deployment 会自动重建。 - 滚动更新(Rolling Update)
更新镜像或配置时,逐步替换旧 Pod,保证服务不中断(默认策略)。 - 版本回滚(Rollback)
如果新版本出问题,可一键回退到上一个稳定版本。 - 暂停/恢复更新
支持在更新过程中暂停,方便调试。 - 声明式配置
你只需描述"最终想要什么状态",K8s 会自动让系统向该状态收敛。
底层原理:
- Deployment 不直接管理 Pod ,而是通过 ReplicaSet(RS) 来控制 Pod。
- 每次更新(如改镜像)会创建新的 ReplicaSet,逐步扩新缩旧,实现平滑升级。
2.7.2 Deployment命令使用
- 创建Deployment
命令格式:
# 基础创建
kubectl create deployment <deployment-name> --image=<container-image>命令示例:
# 基础创建示例
kubectl create deployment my-tomcat --image=tomcat:9.0.55
# 新增可选参数(比如暴露端口)
kubectl create deployment my-app --image=nginx --port=80
# 指定副本数量为3
kubectl create deployment my-app --image=nginx --replicas=3-
查看状态
列出所有 Deployment
kubectl get deployments
查看详细信息(包括 Pod 状态、ReplicaSet 等)
kubectl describe deployment my-app
以 YAML 格式输出 Deployment 配置(可用于备份或修改)
kubectl get deployment my-app -o yaml
-
扩容、缩容
将副本数扩缩到 3
kubectl scale deployment my-app --replicas=3
或使用完整资源名
kubectl scale deploy/my-app --replicas=5
-
更新镜像(滚动更新)
更新容器镜像(触发滚动更新)
kubectl set image deployment/my-app nginx=nginx:1.25
查看滚动更新状态
kubectl rollout status deployment/my-app
查看历史版本(用于回滚)
kubectl rollout history deployment/my-app
-
回滚镜像
回滚到上一个版本
kubectl rollout undo deployment/my-app
回滚到指定版本(需先用 history 查看 revision)
kubectl rollout undo deployment/my-app --to-revision=2
-
暴露服务
为 Deployment 创建 ClusterIP Service(集群内访问)
kubectl expose deployment my-app --port=80 --target-port=80
创建 NodePort 类型 Service(外部可通过节点 IP + 端口访问)
kubectl expose deployment my-app --port=80 --type=NodePort
创建 LoadBalancer(云环境适用)
kubectl expose deployment my-app --port=80 --type=LoadBalancer
-
删除Deployment
为 Deployment 创建 ClusterIP Service(集群内访问)
kubectl expose deployment my-app --port=80 --target-port=80
创建 NodePort 类型 Service(外部可通过节点 IP + 端口访问)
kubectl expose deployment my-app --port=80 --type=NodePort
创建 LoadBalancer(云环境适用)
kubectl expose deployment my-app --port=80 --type=LoadBalancer
-
进入 Pod 调试(常配合 Deployment 使用)
获取 Pod 名称
kubectl get pods -l app=my-app
进入容器(假设容器名为 my-app)
kubectl exec -it
-- /bin/bash 查看日志
kubectl logs
kubectl logs -f# 实时跟踪日志 -
编辑 Deployment(在线修改)
编辑 Deployment(在线修改)
-
使用yaml形式(生产推荐)
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-tomcat
spec:
replicas: 2
selector:
matchLabels:
app: tomcat # ← Deployment 通过这个"选择器"找 Pod
template:
metadata:
labels:
app: tomcat # ← 所有新创建的 Pod 都带这个标签
spec:
containers:
- name: tomcat
image: tomcat:9.0.55
2.7.3 注意事项
- Deployment会始终保持pod的期望状态(指定副本数、可运行状态)
- 当pod被删除,ReplicaSet会发现当前 Pod 数量少于期望值,于是自动创建一个新的 Pod 来替代它。 这就是 Kubernetes 的 自愈能力(self-healing)。
- 当pod变多了,会自动删除多余的pod、Deployment(通过其管理的 ReplicaSet)始终以 spec.replicas 字段定义的副本数为"目标状态"。因此,ReplicaSet 会 主动终止(删除)多余的 Pod,直到数量回到期望值。
- Deployment通过标签"管理"Pod,Deployment 创建的每个 Pod 都有相同的标签(比如app=tomcat)。而ReplicaSet(由 Deployment 创建)会持续监控:所有带 app=tomcat 标签的 Pod。注意,如果手动创建一个也带 app: tomcat 的 Pod,它也会被这个 ReplicaSet "接管" ------ 而如果副本数超了,就有可能被删掉。
2.7.4 Deployment拉取镜像失败解决方案
1. 判断使用的是container还是docker
在宿主机上运行
kubectl get nodes -o jsonpath='{.items[*].status.nodeInfo.containerRuntimeVersion}'-
如果是container,则修改container的镜像配置
sudo vi /etc/containerd/config.toml
-
找到 plugins."io.containerd.grpc.v1.cri".registry.mirrors 段落,在其下添加:
[plugins."io.containerd.grpc.v1.cri".registry.mirrors]
[plugins."io.containerd.grpc.v1.cri".registry.mirrors."docker.io"]
endpoint = ["https://docker.1ms.run"]
✅ 注意缩进!它必须是
mirrors的子表。(缩进一般是两个空格)
-
保存并重启 containerd
sudo systemctl restart containerd
-
测试拉取标准镜像
sudo crictl pull nginx
2.8 Service
2.8.1 Service简介
1. 什么是Service?
Service 是 Kubernetes 中实现服务发现 和负载均衡 的核心资源对象。 它的主要作用是:为一组 Pod 提供稳定的网络访问入口(IP + 端口),即使这些 Pod 会频繁地被创建、销毁、更换 IP。
2. 为什么需要Service?
在 Kubernetes 中:
- Pod 是临时的(ephemeral):它们随时可能被删除、重建,IP 地址会变。
- 应用之间不能直接依赖 Pod IP 通信(因为 IP 不稳定)。
- 需要一个"固定入口"来访问一组功能相同的 Pod(比如多个 Tomcat 实例)。
因此Service就会作为一组Pod的"固定入口"
3. Service的核心功能
| 功能 | 说明 |
|---|---|
| ✅ 服务发现 | 其他 Pod 可以通过 Service 名称(如 my-tomcat)访问它,无需知道具体 Pod IP |
| ✅ 负载均衡 | 自动将请求分发到后端多个健康的 Pod |
| ✅ 解耦 | 前端不关心后端有多少个 Pod、IP 是什么,只认 Service |
4. Service 如何工作?
核心就是标签选择器,与Deployment类似,Service 通过 标签选择器(selector) 找到它要代理的 Pod,所以
- Deployment 创建带
app=tomcat标签的 Pod; - Service 通过相同标签找到这些 Pod;
- 请求发到 Service → 自动转发到任意一个健康 Pod。
5. Service的几种类型
| 类型 | 用途 | 访问方式 |
|---|---|---|
| ClusterIP(默认) | 集群内部访问 | 只能在 Kubernetes 集群内通过虚拟 IP 或 DNS 访问 |
| NodePort | 从集群外部访问(测试用) | 通过任意 Node 的 IP + 高端口(如 30000-32767)访问 |
| LoadBalancer | 云厂商集成(生产推荐) | 云平台自动创建外部负载均衡器(如 AWS ELB、阿里云 SLB) |
| ExternalName | 映射外部服务 | 返回 CNAME 记录,用于访问集群外的服务 |
2.8.2. Service常用命令
-
创建不同类型的Service
默认 ClusterIP(集群内访问)
kubectl expose deployment my-tomcat --port=8080
NodePort(外部可通过 http://
: 访问) kubectl expose deployment my-tomcat --port=8080 --type=NodePort
LoadBalancer(云环境)
kubectl expose deployment my-tomcat --port=8080 --type=LoadBalancer
-
测试是否创建成功
查看 Service,找到 PORT(S) 列中的 3xxxx 端口
kubectl get svc my-tomcat
查看工作节点的 IP(通常是内网 IP)
kubectl get nodes -o wide
在宿主机或者同局域网中,测试以下命令
http://<任一节点IP>:<NodePort>-
yaml形式创建
apiVersion: v1
kind: Service
metadata:
name: my-tomcat-service # Service 名称
namespace: default # 可选,默认命名空间
spec:
type: NodePort # Service 类型:NodePort
selector:
app: tomcat # 必须与 Pod 的标签匹配
ports:
- protocol: TCP
port: 8080 # Service 对外暴露的端口(集群内通过此端口访问)
targetPort: 8080 # Pod 中容器实际监听的端口
nodePort: 30080 # 可选:指定 NodePort(范围 30000-32767),若不指定则自动分配
保存为my-tomcat.yaml,然后执行
kubectl apply -f my-tomcat-svc.yaml2.9 Volume存储
2.9.1 Volume 简介
Volume(存储卷) 是 Kubernetes 中用于在 Pod 内部实现数据持久化 和容器间共享数据 的核心机制。与容器生命周期不同,Volume 的生命周期与 Pod 绑定------即使容器重启,Volume 中的数据也不会丢失。
- 为什么需要 Volume?
- 容器内的文件系统是临时的:容器重启后,原有数据会丢失。
- 多个容器运行在同一个 Pod 中时,可能需要共享某些文件(如日志、配置)。
- 某些应用(如数据库)必须将数据写入持久化存储,不能依赖内存或临时磁盘。
因此,Kubernetes 引入 Volume 来解决这些问题。
- Volume 的核心特点
| 特性 | 说明 |
|---|---|
| ✅ 生命周期绑定 Pod | Volume 在 Pod 创建时挂载,在 Pod 删除时销毁(但部分类型如 PV 可独立存在) |
| ✅ 支持多种后端类型 | 包括临时存储、节点本地存储、网络存储、云盘、配置数据等 |
| ✅ 容器间共享 | 同一个 Pod 中的多个容器可挂载同一个 Volume,实现文件共享 |
| ✅ 解耦存储与应用 | 应用无需关心底层存储细节,只需声明挂载点 |
- 常见 Volume 类型
| 类型 | 用途 | 是否持久 |
|---|---|---|
emptyDir |
临时存储,Pod 内容器共享,Pod 删除即清空 | ❌ |
hostPath |
挂载宿主机目录到 Pod(仅单节点测试用) | ⚠️ 半持久(依赖节点) |
configMap / secret |
挂载配置或敏感信息为文件 | ❌(但内容由集群管理) |
persistentVolumeClaim (PVC) |
请求持久化存储(如云硬盘、NFS),生产推荐 | ✅ |
nfs, cephfs, awsElasticBlockStore 等 |
直接使用特定后端存储(不推荐直接使用,建议通过 PVC) | ✅ |
💡 最佳实践 :生产环境中应使用 PersistentVolume (PV) + PersistentVolumeClaim (PVC) 模式,实现存储与 Pod 解耦。
- Volume 如何工作?
-
在 Pod 的
spec.volumes中定义一个或多个 Volume; -
在容器的
volumeMounts中指定挂载路径; -
所有挂载了同一 Volume 的容器可读写相同目录。
volumes:
- name: cache-volume
emptyDir: {}
containers:
- name: app
volumeMounts:
- name: cache-volume
mountPath: /cache
2.9.2 NFS配置
1. 什么是NFS?
NFS(Network File System,网络文件系统)是一种分布式文件系统协议 ,允许你将远程服务器上的目录"挂载"到本地机器上,就像访问本地磁盘一样。
在 Kubernetes(k8s)中,NFS 常被用作一种共享、持久化、多读多写的存储后端,特别适合需要多个 Pod 同时读写同一份数据的场景(比如 WordPress 多副本、日志收集、共享配置等)。
2. NFS在k8s中的作用?
- 持久化存储:Pod 删除后,数据保留在 NFS 服务器上。
- 多 Pod 共享:多个 Pod(甚至跨节点)可同时挂载同一个 NFS 路径。
- 读写支持 :支持
ReadWriteMany(RWX)访问模式(这是很多云盘不支持的!)。 - 成本低:自建 NFS 服务器比云厂商存储便宜,适合私有集群。
- KFS配置
在k8s主节点上运行如下命令
# 安装 NFS 服务器
sudo yum install -y nfs-utils
# 创建共享目录
sudo mkdir -p /nfs/data
sudo chmod -R 777 /nfs/data # 测试用;生产环境建议用更安全的权限
# 配置 /etc/exports
sudo tee /etc/exports <<EOF
/nfs/data *(rw,sync,no_subtree_check,no_root_squash)
EOF
# 启动 rpc 和 nfs 服务
sudo systemctl enable --now rpcbind
sudo systemctl enable --now nfs-server
# 重新加载 exports 配置
sudo exportfs -rav
# 开放防火墙(如果启用了 firewalld)
sudo firewall-cmd --permanent --add-service=nfs
sudo firewall-cmd --permanent --add-service=rpc-bind
sudo firewall-cmd --permanent --add-service=mountd
sudo firewall-cmd --reload在剩下的所有工作节点上运行如下命令
# 安装 nfs 服务(CentOS/RHEL)
sudo dnf install -y nfs-utils验证安装是否成功(在任意工作节点上手动挂载 NFS)
# 创建测试目录
sudo mkdir -p /mnt/nfs-test
# 在其他的节点上挂载 NFS(替换为你的 NFS 服务器 IP 和路径)
sudo mount -t nfs 192.168.10.100:/nfs/data /mnt/nfs-test
# 查看是否挂载成功
df -h | grep nfs
# 输出中包含类似:
192.168.10.100:/nfs/data 100G 5.0G 95G 5% /mnt/nfs-test
# 测试读写
echo "test from node" | sudo tee /mnt/nfs-test/test.txt
cat /mnt/nfs-test/test.txt
# ✅ 能正常写入和读取,说明 NFS 服务端和网络正常。2.9.3 PV & PVC
1. 什么是PV、PVC?
PV(PersistentVolume)和 PVC(PersistentVolumeClaim) 是 Kubernetes 中用于管理持久化存储的两个核心概念,它们将存储的提供 与存储的使用解耦。
PV(PersistentVolume)------ 存储的"供给方"
- 由 集群管理员 创建。
- 代表集群中的一块真实存储资源(如 NFS 目录、云硬盘、Ceph RBD 等)。
- 是 集群级别的资源(不属于某个命名空间)。
- 包含存储的详细信息:大小、访问模式(ReadWriteOnce / ReadWriteMany)、回收策略、后端类型等。
PVC(PersistentVolumeClaim)------ 存储的"需求方"
- 由 应用开发者/用户 创建。
- 是对存储的 申请(claim),声明"我需要多少存储、什么访问模式"。
- 属于 命名空间级别 的资源。
- Kubernetes 会自动将 PVC 与满足条件的 PV 绑定(bind)。
其中,PVC可以被多个Pod引用 ,因此这三者的依赖关系就是NFS -> PV -> PVC -> 多Pod,通过这种关系,实现多系统资源共享(共享一个PVC)
2. 关键配置字段说明
PV 常用字段
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-pv
spec:
capacity:
storage: 20Gi # 存储容量
accessModes: # 访问模式(必选)
- ReadWriteMany # 支持多 Pod 读写(NFS 用这个)
# 其他选项:ReadWriteOnce(单节点读写)、ReadOnlyMany(多节点只读)
persistentVolumeReclaimPolicy: Retain # 回收策略
# Retain:删除 PVC 后保留数据(手动清理)
# Delete:删除 PVC 时自动删除 PV 和底层数据(云盘常用)
nfs: # 存储后端类型(这里是 NFS)
server: 192.168.40.133 # NFS 服务器 IP
path: "/nfs/data" # 共享路径
# 其他后端:awsElasticBlockStore, gcePersistentDisk, cephfs, hostPath 等PVC 常用字段
apiVerson: v1
kind: PersistentVolumeClaim
metadata:
name: my-pvc
namespace: default # 所在命名空间
spec:
accessModes:
- ReadWriteMany # 必须与 PV 的 accessModes 兼容
resources:
requests:
storage: 10Gi # 申请的最小容量(必须 ≤ PV 容量)
# 可选:指定 StorageClass(动态供给时用)
# storageClassName: nfs-storage⚠️ 注意:
- PVC 的
accessModes和storage必须被某个 PV 完全满足才能绑定;- 如果没有匹配的 PV,PVC 会处于
Pending状态。
3. 使用流程(标准四步)
步骤 1:管理员创建 PV(或配置 StorageClass 实现动态供给)
kubectl apply -f pv.yaml步骤 2:开发者创建 PVC
kubectl apply -f pvc.yaml步骤 3:Kubernetes 自动绑定 PV ↔ PVC
kubectl get pv,pvc
# STATUS 应为 Bound步骤 4:Pod 通过 PVC 挂载存储
spec:
containers:
- name: app
image: nginx
volumeMounts:
- name: data
mountPath: /data
volumes:
- name: data
persistentVolumeClaim:
claimName: my-pvc # 引用 PVC 名称2.9.4 Volume 常用示例
-
使用
emptyDir(临时共享)apiVersion: v1
kind: Pod
metadata:
name: shared-pod
spec:
containers:- name: writer
image: alpine
command: ["/bin/sh", "-c"]
args: ["echo 'Hello from writer' > /shared/data.txt && sleep 3600"]
volumeMounts:- name: shared-data
mountPath: /shared
- name: shared-data
- name: reader
image: alpine
command: ["/bin/sh", "-c"]
args: ["cat /shared/data.txt && sleep 3600"]
volumeMounts:- name: shared-data
mountPath: /shared
volumes:
- name: shared-data
- name: shared-data
emptyDir: {}
- name: writer
-
使用
hostPath(仅开发/测试)volumes:
- name: host-log
hostPath:
path: /var/log/myapp
type: DirectoryOrCreate
- name: host-log
⚠️ 注意:
hostPath依赖具体节点,不适合多节点集群或生产环境。
- 使用 PVC(生产推荐)
先创建 PVC:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi再在 Pod 中引用:
volumes:
- name: data-storage
persistentVolumeClaim:
claimName: my-pvc- 使用 NFS(通过 PV + PVC)
假设 NFS 服务器 IP 为
192.168.10.100,共享路径为/nfs/data
步骤 1:创建 PersistentVolume(PV)
# nfs-pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-pv
spec:
capacity:
storage: 20Gi
accessModes:
- ReadWriteMany # NFS 支持多读多写!
persistentVolumeReclaimPolicy: Retain # 删除 PVC 后保留数据
nfs:
server: 192.168.10.100 # 替换为你的 NFS 服务器 IP
path: "/nfs/data" # 共享目录路径步骤 2:创建 PersistentVolumeClaim(PVC)
# nfs-pvc.yaml
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nfs-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 20Gi步骤 3:在应用 Pod 中使用 PVC
# nginx-nfs.yaml
apiVersion: v1
kind: Pod
metadata:
name: nginx-nfs
spec:
containers:
- name: nginx
image: nginx
volumeMounts:
- name: web-content
mountPath: /usr/share/nginx/html
volumes:
- name: web-content
persistentVolumeClaim:
claimName: nfs-pvc应用命令:
kubectl apply -f nfs-pv.yaml
kubectl apply -f nfs-pvc.yaml
kubectl apply -f nginx-nfs.yaml✅ 验证:多个 Pod 挂载同一 PVC 可共享文件,实现跨节点读写。
2.9.5 注意事项
💡 为什么推荐用 PV/PVC 而不是直接在 Pod 中写
nfs:?
- 解耦:Pod 不依赖具体 NFS 地址,便于迁移;
- 复用:多个应用可申请同一类存储;
- 管理:管理员控制存储资源,开发者只需申请(PVC)。
- Volume 不是备份方案:即使使用 PVC,仍需额外做数据备份。
- 不要直接使用云存储插件:应通过 PVC 抽象,提高可移植性。
- Pod 删除 ≠ 数据删除:使用 PVC 时,即使 Pod 被删,数据仍保留在 PV 中(取决于回收策略)。
- 权限问题 :容器内进程用户需有权限读写挂载目录,必要时设置
securityContext。
2.9.6 调试技巧
# 查看 Pod 挂载的 Volume
kubectl describe pod <pod-name>
# 进入容器查看挂载点
kubectl exec -it <pod-name> -- ls /mount-path
# 查看 PVC 状态
kubectl get pvc
kubectl describe pvc my-pvc📌 总结 :Volume 是 Kubernetes 实现"有状态"能力的基础。对于无状态应用可用
emptyDir,对于数据库、文件服务等关键应用,务必使用 PVC + PV 实现真正的持久化存储。
2.10 ConfigMap
2.10.1 ConfigMap简介
1. 什么是ConfigMap
ConfigMap 是 Kubernetes(k8s)中用于存储非敏感配置数据的 API 对象 。它的核心作用是:将应用程序的配置(如环境变量、命令行参数、配置文件)与容器镜像解耦,实现"一次构建镜像,多环境部署"。
2. 为什么需要ConfigMap
在没有 ConfigMap 时,我们可能:
- 把配置写死在代码或镜像里 → 换环境就要重新构建镜像
- 用
env在 Pod 中硬编码 → 难维护、不安全
有了 ConfigMap:
- 配置独立于镜像;
- 同一个镜像可在 dev/test/prod 环境通过不同 ConfigMap 运行
- 修改配置无需重建镜像(部分场景支持热更新)
- ConfigMap 能存什么?
- 键值对(key-value) :如
database_url: mysql://... - 完整配置文件内容 :如
nginx.conf、app.properties - 命令行参数片段
- 非敏感数据 (⚠️ 敏感信息请用 Secret)
🔒 注意:ConfigMap 不加密,不要存密码、密钥!
2.10.2 ConfigMap创建
方法 1:从字面量创建(适合少量 key-value)
kubectl create configmap app-config \
--from-literal=log_level=info \
--from-literal=api_url=https://api.example.com方法 2:从文件创建(适合配置文件)
# 将 nginx.conf 文件内容存入 ConfigMap
kubectl create configmap nginx-config --from-file=nginx.conf方法 3:从 YAML 文件定义(推荐,可版本控制)
# app-config.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: app-config
data:
log_level: "info"
api_url: "https://api.example.com"
app.properties: |
server.port=8080
feature.enabled=true2.10.3 ConfigMap使用
方式 1:作为环境变量
env:
- name: LOG_LEVEL
valueFrom:
configMapKeyRef:
name: app-config
key: log_level方式 2:作为容器启动命令参数
args: ["--log-level", "$(LOG_LEVEL)"]
env:
- name: LOG_LEVEL
valueFrom:
configMapKeyRef:
name: app-config
key: log_level方式 3:挂载为 Volume(适合配置文件)
volumes:
- name: config-volume
configMap:
name: app-config
volumeMounts:
- name: config-volume
mountPath: /etc/config # 文件会出现在此目录下挂载后:
/etc/config/log_level内容是info/etc/config/app.properties是完整配置文件
热更新支持吗?
- 作为环境变量 :❌ Pod 创建时注入,修改 ConfigMap 不会更新已运行的 Pod
- 挂载为 Volume :✅ 支持热更新(Kubelet 默认每 1 分钟同步一次)
💡 提示:若需立即生效,可滚动重启 Pod:
kubectl rollout restart deployment/my-app
因此:ConfigMap 是 Kubernetes 的"配置中心",把非敏感配置从容器镜像中抽离出来,实现灵活、安全、可维护的应用部署。
2.11 Secret
2.11.1 Secret简介
1. 什么是Secret?
Secret 是 Kubernetes(k8s)中用于存储和管理敏感信息的 API 对象,比如密码、令牌(token)、SSH 密钥、TLS 证书等。
- 核心目标:避免将敏感数据硬编码在容器镜像、Pod 配置或代码中,从而提升安全性。
3. 与ConfigMap对比
| 特性 | Secret | ConfigMap |
|---|---|---|
| 存储内容 | 敏感数据(密码、密钥、证书等) | 非敏感配置(日志级别、URL、配置文件等) |
| 存储方式 | Base64 编码(不是加密!) | 明文存储 |
| 安全性 | 更高(可配合 RBAC、加密 at rest) | 无特殊保护 |
| 使用场景 | 数据库密码、API Key、私钥 | 应用配置、环境开关 |
⚠️ 注意:Secret 默认只是 Base64 编码,不是加密!
要真正加密,需启用 etcd 静态加密(Encryption at Rest)。
4. Secret 能存什么?
- 数据库用户名/密码
- OAuth 访问令牌(Access Token)
- Docker Registry 凭据(
imagePullSecrets) - TLS 证书和私钥(用于 HTTPS)
- SSH 私钥
- 任意需要保密的字符串
2.11.2 Secret创建
方法 1:从字面量创建(自动 Base64 编码)
kubectl create secret generic db-secret \
--from-literal=username=admin \
--from-literal=password='S3cr3tP@ss!'方法 2:从文件创建(适合证书、密钥文件)
kubectl create secret generic tls-secret \
--from-file=tls.crt=./server.crt \
--from-file=tls.key=./server.key方法 3:通过 YAML 手动定义(需自己 Base64 编码)'
# db-secret.yaml
apiVersion: v1
kind: Secret
metadata:
name: db-secret
type: Opaque
data:
username: YWRtaW4= # echo -n "admin" | base64
password: UzNjcjN0UEBzcwEh # echo -n "S3cr3tP@ss!" | base64💡
type: Opaque表示通用 Secret(最常用)
2.11.3 在Pod中使用Secret
1. 方式 1:作为环境变量(谨慎使用)
env:
- name: DB_PASSWORD
valueFrom:
secretKeyRef:
name: db-secret
key: password风险 :环境变量可能被
ps、日志、调试工具泄露。仅用于兼容旧应用。
方式 2:挂载为 Volume(✅ 推荐!)
volumes:
- name: secret-volume
secret:
secretName: db-secret
volumeMounts:
- name: secret-volume
mountPath: /etc/secrets
readOnly: true挂载后:
/etc/secrets/username文件内容是admin/etc/secrets/password文件内容是S3cr3tP@ss!- 文件权限默认为
644,可通过defaultMode修改(如0400)
方式 3:拉取私有镜像(imagePullSecrets)
spec:
imagePullSecrets:
- name: regcred # 这是一个 docker-registry 类型的 Secret
containers:
- name: my-app
image: private-registry/my-app:latest创建命令:
kubectl create secret docker-registry regcred \ --docker-server=my-registry.com \ --docker-username=user \ --docker-password=pass
总结:Secret 是 Kubernetes 专门用来安全传递敏感信息的机制,通过 Volume 挂载方式使用最安全,配合 RBAC 和 etcd 加密可满足生产安全要求。
2.12 Ingress
2.12.1 Ingress简介
1. Ingress是什么?
Ingress 是 Kubernetes 中管理外部访问集群内服务(Service)的 API 对象,主要用于 HTTP/HTTPS 流量的路由。
2. Ingress的核心作用?
将同一个公网 IP 和端口(如 80/443)的请求,根据 域名 或 路径 转发到不同的后端 Service
shop.example.com→ 电商服务blog.example.com→ 博客服务example.com/api/→ API 服务
3. 注意事项
- Ingress 本身不生效 ,需要部署 Ingress Controller(如 Nginx、Traefik、ALB)来实现实际流量转发。
- 只支持 L7(应用层) ,不支持 TCP/UDP(那些用 Service 的
NodePort或LoadBalancer)。
2.12.2 Ingress配置
1. 安装 Helm(只需要在master节点安装即可)
# 下载 Helm 二进制文件(最新稳定版)
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/main/scripts/get-helm-3
# 给脚本执行权限
chmod +x get_helm.sh
# 运行安装脚本
sudo ./get_helm.sh2. 验证安装
helm version
# ✅ 正常输出类似:
version.BuildInfo{Version:"v3.14.0", GitCommit:"...", GitTreeState:"clean", GoVersion:"go1.21.5"}3. 部署 Ingress Controller(在master节点操作,以 Nginx 为例)
# 添加官方仓库(可选)
helm repo add ingress-nginx https://kubernetes.github.io/ingress-nginx
# 安装(Helm 方式)
helm install ingress-nginx ingress-nginx/ingress-nginx \
--namespace ingress-nginx --create-namespace等待几分钟,直到 Pod 和 LoadBalancer IP 就绪,执行以下命令验证
kubectl get pods -n ingress-nginx
kubectl get svc -n ingress-nginx # 查看 EXTERNAL-IP✅ 此时,Ingress Controller 已监听 80/443 端口,准备接收流量。
2.12.3 路由规则配置
-
首先确保有对应的Deployment和Service运行,假设部署的服务名为my-app
my-app.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-app
spec:
replicas: 2
selector:
matchLabels:
app: my-app
template:
metadata:
labels:
app: my-app
spec:
containers:
- name: nginx
image: nginx:alpine
ports:
- containerPort: 80apiVersion: v1
kind: Service
metadata:
name: my-app-svc
spec:
selector:
app: my-app
ports:
- protocol: TCP
port: 80
targetPort: 80
随后执行 kubectl apply -f my-app.yaml 进行部署
✅ 确保
my-app-svc在 default 命名空间(或其他命名空间)中可访问。
- 创建Ingress资源
假设我们需要通过myapp.local进行访问
# ingress-my-app.yaml
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: my-app-ingress
spec:
rules:
- host: myapp.local
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: my-app-svc
port:
number: 80随后通过kubectl apply -f ingress-my-app.yaml 进行启用
-
随后在本机修改 /etc/hosts文件,添加
<你的-master-node-IP> myapp.local
接着通过 curl http://myapp.local 验证是否成功
2.13 k8s网络模型
2.13.1 k8s网络中的通信类型
k8s网络中的主要通信类型有这四个
- 同一Pod内的容器间通信
- 各个Pod彼此间通信
- Pod和Service间的通信
- 集群外部流量和Servie之间的通信
2.13.2 k8s网络模型的核心要求
Kubernetes 对网络模型提出了以下基本要求,以支持上述通信类型:
- 所有 Pod 之间可直接通信
无论是否在同一节点上,Pod 之间都应能通过 IP 地址直接访问,无需 NAT(网络地址转换)。 - 所有节点与 Pod 之间可双向通信
节点可以访问任意 Pod,Pod 也可以访问任意节点,且通信路径对称。 - 每个 Pod 拥有唯一的 IP 地址
Pod 的 IP 在集群范围内是唯一的,生命周期内保持不变(直到被删除重建)。 - Service 提供稳定的虚拟 IP 和 DNS 名称
Service 为一组 Pod 提供统一入口,即使后端 Pod 变化,Service 的 IP 和域名保持不变。
为实现这些要求,Kubernetes 本身不实现网络功能 ,而是依赖 CNI(Container Network Interface)插件,如 Flannel、Calico、Cilium 等。这些插件负责:
- 为 Pod 分配 IP
- 建立跨节点的网络隧道或路由
- 实现 Service 的负载均衡(通常结合 kube-proxy)
💡 简单来说:Kubernetes 定义"要什么",CNI 插件决定"怎么做"。
2.13.4 k8s各层网络模型
1. 同一 Pod 内的容器间通信
-
通信形式 :通过 localhost(127.0.0.1) 直接通信。
-
端口暴露 :
- 容器共享同一个 网络命名空间(Network Namespace),因此共享 IP 和端口空间。
- 一个容器监听
8080,另一个容器可通过localhost:8080访问。
-
是否需要端口声明:不需要 Service 或暴露端口;只需在容器内正常监听即可。
-
✅ 示例:
containers: - name: app image: nginx ports: [{ containerPort: 80 }] - name: sidecar image: curl command: ["curl", "http://localhost"] # 可直接访问 nginx
额外解释 :上述示例是 Sidecar(边车)模式 的 Pod 配置示例,主要有两个容器,主容器使用
镜像nginx和辅助容器使用镜像curl。辅助容器可以配合检查主容器的健康状态、日志情况等信息。
2. Pod 与 Pod 之间的通信
- 通信形式 :通过 Pod IP + 容器端口 直接通信(跨节点也一样)。
- 端口暴露 :
- 每个 Pod 有唯一集群 IP(如
10.244.1.5)。 - 目标 Pod 的容器必须在
containerPort上监听(但该字段仅为文档说明,不强制暴露)。
- 每个 Pod 有唯一集群 IP(如
- 依赖组件:CNI 插件(如 Flannel)负责打通 Pod 跨节点路由。
- ❌ 不能直接从集群外访问 Pod IP(除非使用 HostNetwork 或特殊路由)。
- ✅ 示例:Pod A (
10.244.1.5) 中运行nginx:80→ Pod B 可直接curl http://10.244.1.5
3. Pod 与 Service 之间的通信
-
通信形式 :通过 Service 的 ClusterIP + Port 访问。
-
端口暴露 (Service 定义中的关键字段):
spec: ports: - port: 80 # Service 对外暴露的端口(其他 Pod 访问时用) targetPort: 8080 # 转发到后端 Pod 的实际端口 protocol: TCPport:Service 的虚拟端口(集群内通过<ClusterIP>:port访问)targetPort:后端 Pod 容器实际监听的端口
-
实现机制 :
kube-proxy在每个节点上维护 iptables/ipvs 规则,将流量 DNAT 到后端 Pod。- DNS(CoreDNS)将 Service 名称解析为 ClusterIP。
-
✅ 示例:
my-app-svc.default.svc.cluster.local:80→ 被解析为10.96.123.45:80→ 转发到某个 Pod 的8080端口。
4. 集群外部 ↔ Service 的通信
有三种主要方式,对应不同端口暴露策略:
| 方式 | 端口暴露形式 | 通信入口 | 适用场景 |
|---|---|---|---|
| NodePort | 在每个节点的 固定高端口(30000--32767) 上监听 | http://<任意NodeIP>:<NodePort> |
测试、裸金属集群 |
| LoadBalancer | 云厂商创建外部 LB,分配公网 IP | http://<EXTERNAL-IP> |
公有云环境 |
| Ingress | 复用 80/443 端口,基于 HTTP Host/Path 路由 | http://myapp.example.com |
生产 Web 应用 |
- Ingress 特别说明 :
- Ingress Controller 本身是一个 Pod + Service(通常为 NodePort 或 LoadBalancer)
- 外部流量 → NodePort/LoadBalancer → Ingress Controller Pod → 根据规则转发到后端 Service
5. 总结:
| 通信层级 | 源 → 目标 | 使用地址 | 端口类型 | 是否需 CNI | 是否需 kube-proxy |
|---|---|---|---|---|---|
| 容器 ↔ 容器(同 Pod) | localhost | 127.0.0.1 | 容器端口 | ❌ | ❌ |
| Pod ↔ Pod | Pod IP | Pod IP | 容器端口 | ✅ | ❌ |
| Pod ↔ Service | ClusterIP | Service IP | Service.port | ✅ | ✅ |
| 外部 ↔ Service | NodeIP / EXTERNAL-IP | 节点 IP / 公网 IP | NodePort / 80,443 | ✅ | ✅(间接) |
2.14 k8s的工作流程
Kubernetes 采用 声明式 API + 控制循环 的架构,其基本工作流程如下:
- 用户提交期望状态
用户通过kubectl或 YAML 文件向 API Server 提交资源定义(如 Deployment、Service 等),声明"希望系统达到什么状态"(例如:运行 3 个 Nginx Pod)。 - API Server 接收并验证请求
- 所有操作必须经过 API Server(集群唯一入口)。
- API Server 进行身份认证、授权和合法性校验。
- 持久化到 etcd
验证通过后,API Server 将资源对象的期望状态 写入 etcd(分布式键值数据库),作为集群的"唯一真相源"。 - 控制器(Controller)监听变化
- Controller Manager 中的各类控制器(如 Deployment Controller、ReplicaSet Controller)持续监听 etcd 中的资源变化。
- 一旦发现实际状态 ≠ 期望状态(如 Pod 数量不足),控制器会创建/删除资源以"调和(Reconcile)"差异。
- 调度器(Scheduler)分配节点
- 对于新创建的 Pod,Scheduler 根据资源需求、节点标签、亲和性等策略,选择一个合适的 Worker 节点。
- 调度结果写回 etcd。
- Kubelet 执行容器启动
- 目标节点上的 Kubelet(节点代理)从 API Server 获取分配给本节点的 Pod 信息。
- Kubelet 调用容器运行时(如 containerd 或 Docker)拉取镜像、创建并启动容器。
- 持续监控与自愈
- Kubelet 持续上报 Pod 状态到 API Server。
- 控制器不断比对"实际状态" vs "期望状态",自动修复异常(如重启崩溃的 Pod、补充缺失副本)。
- 服务发现与访问(可选)
- kube-proxy 在每个节点上维护网络规则,实现 Service 的负载均衡。
- 外部流量可通过 Ingress、NodePort 或 LoadBalancer 访问应用。
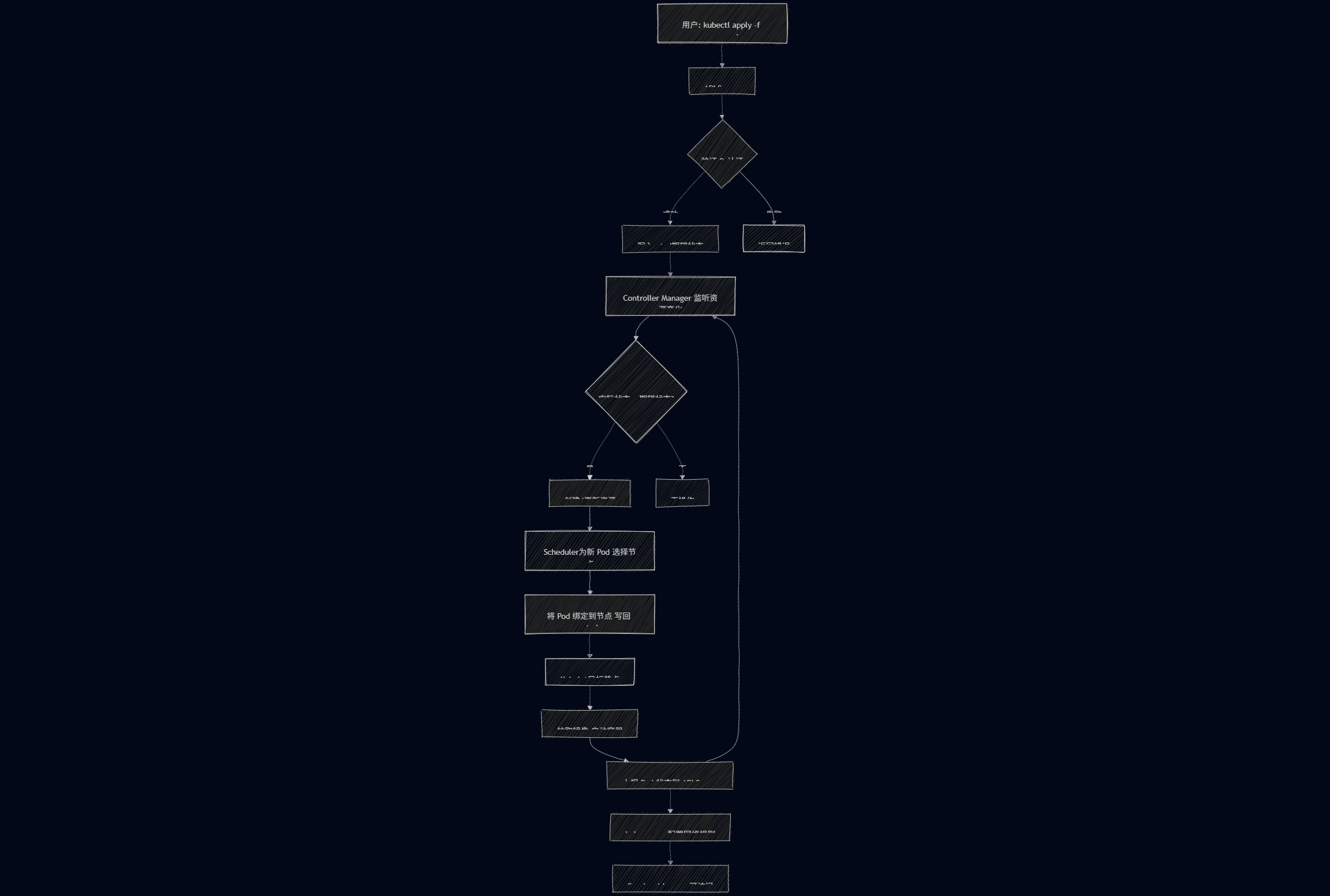
🔄 总结一句话:
用户声明"要什么" → Kubernetes 自动确保"是什么"始终等于"要什么"。
3. 结语
通过本文的系统梳理,我们从 Docker 容器技术的基础概念、核心命令、镜像构建与私有仓库搭建,逐步深入到 Kubernetes 的集群部署、资源管理、网络通信与存储机制。Docker 为我们提供了轻量、可移植的应用封装能力,而 Kubernetes 则在此基础上实现了大规模容器化应用的自动化部署、弹性伸缩与自愈管理。二者相辅相成,共同构成了现代云原生应用的基石。
掌握这些知识,不仅意味着你能够高效地打包和运行单个服务,更具备了在生产环境中构建高可用、可扩展、易维护的分布式系统的能力。技术之路永无止境,但每一步扎实的实践,都是通向云原生世界的坚实阶梯。愿你在容器与编排的世界中,持续探索,不断进阶