选题意义背景
蔬菜是人类日常饮食中不可或缺的重要组成部分,富含维生素、矿物质和膳食纤维,对维持人体健康具有重要意义。随着全球人口的增长和生活水平的提高,对蔬菜的需求量不断增加。同时,蔬菜产业也是农业生产中的重要支柱产业,在保障粮食安全、增加农民收入、促进农村经济发展等方面发挥着重要作用。因此,提高蔬菜产量和质量,保障蔬菜生产的可持续发展,对于满足人民日益增长的美好生活需要和推动农业现代化具有重要意义。菜病害是影响蔬菜产量和质量的主要因素之一。据统计,全球每年因蔬菜病害造成的产量损失可达%~40%,严重影响了蔬菜生产的经济效益和可持续发展。传统的蔬菜病害检测方法主要依靠人工观察和经验判断,这种方法存在诸多局限性。首先,人工检测效率低下,难以满足大规模蔬菜生产的需求;其次,检测结果受检测人员经验和主观因素的影响较大,容易出现误判和漏判;此外,传统检测方法往往只能在病害发生后期进行识别,难以实现病害的早期预警和防治,导致病害扩散和损失扩大。
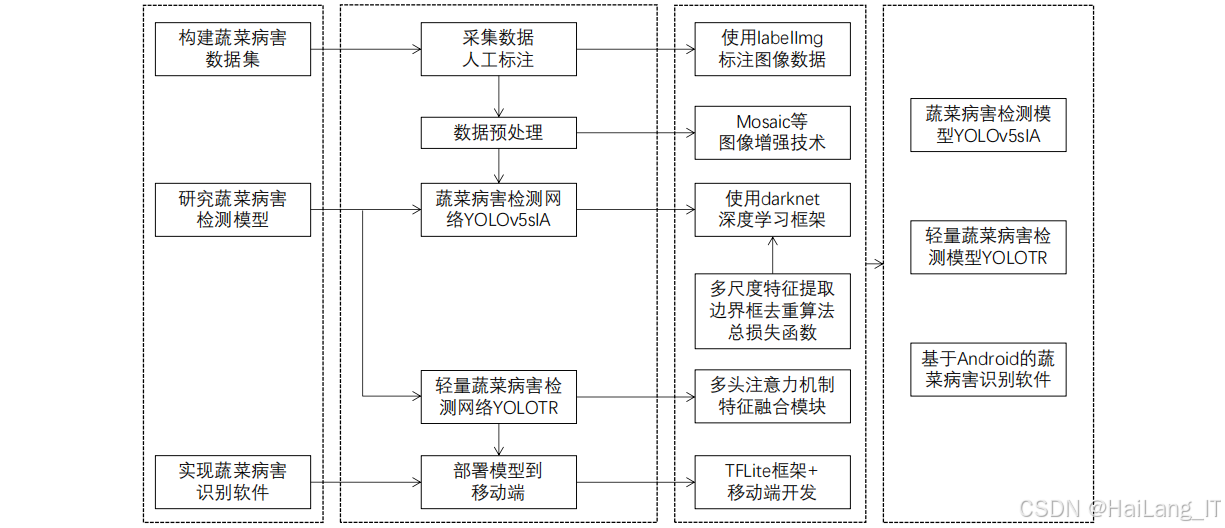
随着深度学习技术的快速发展,基于深度学习的图像识别技术在农业领域的应用越来越广泛。深度学习技术能够自动从大量图像数据中学习特征,具有较强的特征提取和模式识别能力,为蔬菜病害检测提供了新的技术手段。与传统方法相比,基于深度学习的蔬菜病害检测方法具有检测效率高、准确率高、客观性强等优点,能够实现病害的早期预警和实时检测,对于提高蔬菜病害防治的及时性和有效性具有重要意义。
数据集构建
数据收集与整理
数据集的构建是深度学习研究的基础,高质量的数据集对于提高模型的性能至关重要。蔬菜病害数据集的构建主要包括数据收集和数据整理两个阶段。在数据收集阶段,通过多种渠道获取蔬菜病害图像,包括实地拍摄和网络资源收集。实地拍摄主要在蔬菜种植基地和农田中进行,获取真实自然环境下的蔬菜病害图像;网络资源收集主要从农业相关网站、学术论文和公开数据集中获取蔬菜病害图像。在数据整理阶段,对收集到的图像进行筛选和分类,去除模糊、重复和无关的图像,确保数据集的质量和有效性。

VOC格式标注
数据标注是数据集构建的重要环节,准确的标注信息对于模型的训练和评估具有重要意义。本研究采用VOC格式进行数据标注,VOC格式是目标检测领域常用的数据集格式之一,包含图像信息和标注信息两部分。图像信息包括图像文件名、图像尺寸等;标注信息包括目标类别、目标边界框坐标等。在标注过程中,使用专业的标注工具LabelImg进行手动标注,确保标注信息的准确性和一致性。标注完成后,将标注信息保存为XML格式文件,与对应的图像文件一起组成完整的数据集。
数据增强方法
数据增强是提高模型泛化能力和鲁棒性的重要手段,能够通过对原始数据进行变换生成新的数据样本,增加数据集的多样性和规模。本研究采用多种数据增强方法,包括亮度/对比度调整、旋转/平移等几何变换、Mosaic增强等。亮度/对比度调整通过随机调整图像的亮度和对比度,模拟不同光照条件下的蔬菜图像;旋转/平移等几何变换通过随机旋转、平移、缩放和翻转图像,模拟不同角度和位置的蔬菜图像;Mosaic增强通过将四张不同的图像拼接成一张新的图像,增加图像的复杂度和多样性。通过这些数据增强方法,能够有效提高模型对不同环境条件和病害形态的适应能力。

功能模块介绍
数据采集与预处理模块
数据采集与预处理模块是蔬菜病害检测系统的基础模块,负责获取和处理蔬菜病害图像数据。该模块主要包括图像采集、图像预处理和数据标注三个部分。图像采集部分通过相机、手机等设备获取蔬菜图像;图像预处理部分对采集到的图像进行调整大小、归一化、去噪等处理,提高图像质量;数据标注部分使用专业的标注工具对图像中的病害区域进行标注,生成标注信息。该模块的设计旨在提供高质量的训练数据,为后续的模型训练和检测提供基础。
病害识别与检测模块
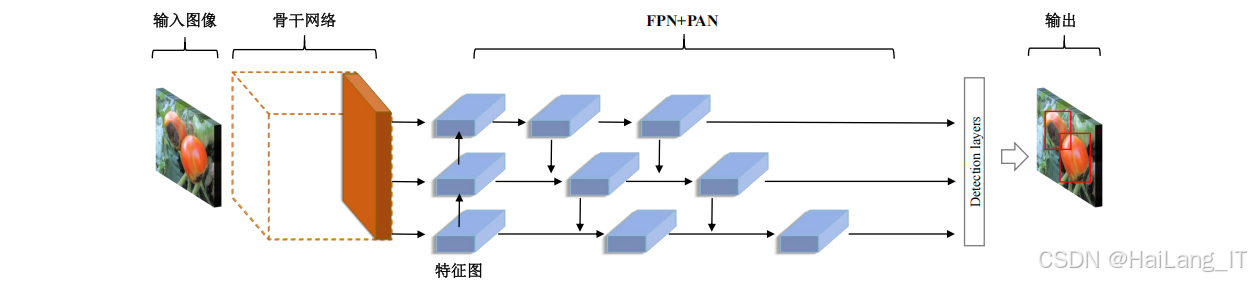
病害识别与检测模块是蔬菜病害检测系统的核心模块,负责对输入的蔬菜图像进行病害识别和检测。该模块采用深度学习技术,基于YOLOv5网络模型进行改进,融合了多尺度特征提取模块和Transformer编码器,提高了模型的检测精度和效率。该模块主要包括模型训练和检测推理两个部分。模型训练部分使用标注好的数据集对模型进行训练,优化模型参数;检测推理部分使用训练好的模型对输入图像进行推理,输出病害的类别和位置信息。
结果展示与防治建议模块
结果展示与防治建议模块是蔬菜病害检测系统的输出模块,负责展示检测结果和提供防治建议。该模块主要包括结果可视化和防治建议生成两个部分。结果可视化部分将检测结果以图像的形式展示给用户,包括病害的边界框、类别和置信度等信息;防治建议生成部分根据检测到的病害类别,提供相应的防治措施和建议,帮助用户及时采取有效的防治措施。该模块的设计旨在提高用户体验,为用户提供便捷的病害检测和防治服务。
相关代码介绍
数据集构建
在基于深度学习的蔬菜病害检测方法研究中,数据集构建是基础而关键的一步。高质量的数据集能够有效提升模型的训练效果和检测性能。通过继承PyTorch的Dataset类,创建一个自定义的蔬菜病害数据集类VegetableDiseaseDataset。该类能够根据图像路径和标签路径,自动加载图像和对应的标注信息。在初始化方法中,指定图像路径、标签路径和数据增强方式,确保数据集的灵活性和可扩展性。在__getitem__方法中,实现了图像和标注的加载与处理逻辑。通过OpenCV读取图像,并将其转换为RGB格式,确保颜色信息的准确性。然后,解析XML格式的标注文件,提取病害的类别和边界框信息,并将边界框坐标转换为YOLO格式,以便模型训练。应用数据增强操作对图像和标注进行同步变换。数据增强是提高模型泛化能力的重要手段,通过随机调整图像的亮度、对比度、旋转角度等,模拟不同环境条件下的蔬菜图像,增加数据集的多样性和规模。本代码使用albumentations库实现数据增强,支持多种变换操作,如调整大小、随机亮度对比度、随机旋转、水平翻转、垂直翻转和模糊等。
python
import os
import cv
import xml.etree.ElementTree as ET
import numpy as np
import albumentations as A
from albumentations.pytorch import ToTensorV2
from torch.utils.data import Dataset
class VegetableDiseaseDataset(Dataset):
def __init__(self, img_dir, ann_dir, transform=None):
self.img_dir = img_dir
self.ann_dir = ann_dir
self.transform = transform
self.img_list = os.listdir(img_dir)
self.classes = ['番茄叶霉病', '番茄早疫病', '番茄晚疫病', '黄瓜霜霉病', '黄瓜白粉病', '黄瓜角斑病', '茄子褐纹病', '茄子黄萎病', '茄子绵疫病']
def __len__(self):
return len(self.img_list)
def __getitem__(self, idx):
# 加载图像
img_name = self.img_list[idx]
img_path = os.path.join(self.img_dir, img_name)
image = cv2.imread(img_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 加载标注
ann_name = img_name.replace('.jpg', '.xml')
ann_path = os.path.join(self.ann_dir, ann_name)
tree = ET.parse(ann_path)
root = tree.getroot()
boxes = []
labels = []
# 解析标注信息
for obj in root.findall('object'):
# 获取类别
class_name = obj.find('name').text
class_idx = self.classes.index(class_name)
labels.append(class_idx)
# 获取边界框
bndbox = obj.find('bndbox')
xmin = int(bndbox.find('xmin').text)
ymin = int(bndbox.find('ymin').text)
xmax = int(bndbox.find('xmax').text)
ymax = int(bndbox.find('ymax').text)
# 转换为YOLO格式
height, width = image.shape[:2]
x_center = (xmin + xmax) / 2 / width
y_center = (ymin + ymax) / 2 / height
w = (xmax - xmin) / width
h = (ymax - ymin) / height
boxes.append([x_center, y_center, w, h])
# 转换为numpy数组
boxes = np.array(boxes, dtype=np.float32)
labels = np.array(labels, dtype=np.int64)
# 数据增强
if self.transform is not None:
transformed = self.transform(image=image, bboxes=boxes, class_labels=labels)
image = transformed['image']
boxes = transformed['bboxes']
labels = transformed['class_labels']
# 转换为torch张量
boxes = np.array(boxes, dtype=np.float32)
labels = np.array(labels, dtype=np.int64)
return image, boxes, labels
# 定义数据增强
transform = ACompose([
A.Resize(640, 640),
A.RandomBrightnessContrast(p=0.5),
A.RandomRotate90(p=0.5),
A.HorizontalFlip(p=0.5),
A.VerticalFlip(p=0.5),
A.Blur(p=0.2),
ToTensorV2()
], bbox_params=A.BboxParams(format='yolo', label_fields=['class_labels']))模型定义
模型的设计和定义是深度学习研究的核心内容,直接影响着检测系统的性能。本研究在YOLOv的基础上,融合了Inception模块,提出了一种融合多尺度特征的蔬菜病害识别网络。定义了Inception模块,该模块是一种经典的多尺度特征提取模块,包含四个并行的特征提取分支。这四个分支分别使用1x1、3x3、5x5卷积和池化操作,能够同时提取不同尺度的特征信息。通过将不同分支的特征进行融合,Inception模块能够增强网络的多尺度特征表示能力,提高模型对不同大小病害的检测精度。定义了增强型YOLOv5模型EnhancedYOLOv5,该模型在YOLOv5的基础上,将瓶颈部分的网络层替换为Inception模块。YOLOv5是一种高效的目标检测网络,具有检测速度快、精度高的优点。通过融合Inception模块,增强型YOLOv5模型能够进一步提高对不同尺度病害的检测能力,特别是小尺度病害的检测精度。考虑了多尺度特征融合和特征提取效率,通过合理的网络结构设计,确保模型在保持较高检测精度的同时,具有较快的检测速度,能够满足实时检测的需求。
python
import torch
import torch.nn as nn
from yolov5.models.yolo import Model
class InceptionModule(nn.Module):
def __init__(self, in_channels, out_channels):
super(InceptionModule, self).__init__()
# 1x1卷积分支
self.branch1x1 = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
# 3x3卷积分支
self.branch3x3 = nn.Sequential(
nn.Conv2d(in_channels, out_channels//2, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_channels//2),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels//2, out_channels, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
# 5x5卷积分支
self.branch5x5 = nn.Sequential(
nn.Conv2d(in_channels, out_channels//2, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_channels//2),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels//2, out_channels, kernel_size=5, stride=1, padding=2, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
# 池化分支
self.branch_pool = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1),
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch3x3 = self.branch3x3(x)
branch5x5 = self.branch5x5(x)
branch_pool = self.branch_pool(x)
# 融合不同分支的特征
outputs = torch.cat([branch1x1, branch3x3, branch5x5, branch_pool], dim=1)
return outputs
class EnhancedYOLOv5(nn.Module):
def __init__(self, cfg='yolov5s.yaml'):
super(EnhancedYOLOv5, self).__init__()
# 加载基础YOLOv5模型
self.yolov5 = Model(cfg)
# 在瓶颈部分嵌入Inception模块
self.inception = InceptionModule(in_channels=1024, out_channels=256)
# 替换YOLOv5的部分层
self.yolov5.model[-3][-1] = self.inception
def forward(self, x):
return self.yolov5(x)检测推理代码
检测推理是深度学习模型应用的重要环节,负责将训练好的模型应用于实际数据,实现病害的自动检测。本研究实现了一个完整的检测推理流程,包括模型加载、图像预处理、推理、后处理和结果可视化等功能。定义了一个VegetableDiseaseDetector类,该类封装了检测推理的全部功能,提供了简洁易用的接口。在初始化方法中,加载训练好的模型并设置相关参数,如置信度阈值和IOU阈值等,确保检测结果的准确性和可靠性。实现了图像预处理功能,对输入图像进行调整大小、归一化和转换为Tensor等操作,确保图像格式符合模型的输入要求。预处理过程是模型推理的重要前置步骤,直接影响着模型的推理结果。,实现了推理和后处理功能。推理过程使用模型对预处理后的图像进行预测,输出检测结果;后处理过程对模型输出进行解析,筛选置信度大于阈值的检测框,进行坐标转换和非极大值抑制,实现了结果可视化功能,将检测结果绘制在原始图像上,包括边界框和类别信息,便于直观地展示检测结果。通过这个完整的检测推理流程,能够方便地使用训练好的模型进行蔬菜病害检测。
python
import torch
import cv
import numpy as np
import os
class VegetableDiseaseDetector:
def __init__(self, model_path, classes, conf_threshold=0.5, iou_threshold=0.5):
# 加载模型
self.model = torch.load(model_path)
self.model.eval()
# 设置设备
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.model.to(self.device)
# 类别名称
self.classes = classes
# 阈值设置
self.conf_threshold = conf_threshold
self.iou_threshold = iou_threshold
def preprocess(self, image):
# 调整图像大小
image = cv2.resize(image, (640, 640))
# 归一化
image = image / 255.0
# 转换为Tensor
image = torch.from_numpy(image).permute(2, 0, 1).float()
image = image.unsqueeze(0)
# 移动到设备
image = image.to(self.device)
return image
def detect(self, image_path):
# 读取图像
image = cv2.imread(image_path)
original_image = image.copy()
# 预处理
input_image = self.preprocess(image)
# 推理
with torch.no_grad():
outputs = self.model(input_image)
# 后处理
results = self.postprocess(outputs, original_image.shape[:2])
# 可视化结果
self.visualize(results, original_image)
return results, original_image
def postprocess(self, outputs, image_shape):
results = []
# 解析输出
for output in outputs:
boxes = output[:, :4]
confidences = output[:, 4]
class_probs = output[:, 5:]
# 筛选置信度大于阈值的框
mask = confidences > self.conf_threshold
boxes = boxes[mask]
confidences = confidences[mask]
class_probs = class_probs[mask]
# 获取类别
class_ids = torch.argmax(class_probs, dim=1)
# 坐标转换
boxes = self.scale_boxes(boxes, (640, 640), image_shape)
# 非极大值抑制
indices = self.nms(boxes, confidences, self.iou_threshold)
# 保存结果
for i in indices:
result = {
'class_id': class_ids[i].item(),
'class_name': self.classes[class_ids[i].item()],
'confidence': confidences[i].item(),
'bbox': boxes[i].tolist()
}
results.append(result)
return results
def scale_boxes(self, boxes, input_shape, output_shape):
# 坐标转换
scale_h = output_shape[0] / input_shape[0]
scale_w = output_shape[1] / input_shape[1]
boxes[:, 0] *= scale_w
boxes[:, 2] *= scale_w
boxes[:, 1] *= scale_h
boxes[:, 3] *= scale_h
return boxes
def nms(self, boxes, scores, iou_threshold):
# 非极大值抑制
indices = []
# 按置信度排序
sorted_indices = torch.argsort(scores, descending=True)
while len(sorted_indices) > 0:
# 选择置信度最高的框
current = sorted_indices[0]
indices.append(current)
# 计算与其他框的IOU
ious = self.iou(boxes[current], boxes[sorted_indices[1:]])
# 筛选IOU小于阈值的框
mask = ious < iou_threshold
sorted_indices = sorted_indices[1:][mask]
return indices
def iou(self, box1, box2):
# 计算IOU
x1 = max(box1[0], box2[:, 0])
y1 = max(box1[1], box2[:, 1])
x2 = min(box1[2], box2[:, 2])
y2 = min(box1[3], box2[:, 3])
# 计算交集面积
intersection = torch.clamp(x2 - x1, min=0) * torch.clamp(y2 - y1, min=0)
# 计算并集面积
area1 = (box1[2] - box1[0]) * (box1[3] - box1[1])
area2 = (box2[:, 2] - box2[:, 0]) * (box2[:, 3] - box2[:, 1])
union = area1 + area2 - intersection
# 计算IOU
iou = intersection / union
return iou
def visualize(self, results, image):
# 可视化检测结果
for result in results:
bbox = result['bbox']
class_name = result['class_name']
confidence = result['confidence']
# 绘制边界框
cv2.rectangle(image, (int(bbox[0]), int(bbox[1])), (int(bbox[2]), int(bbox[3])), (0, 255, 0), 2)
# 绘制类别和置信度
label = f'{class_name}: {confidence:.2f}'
cv2.putText(image, label, (int(bbox[0]), int(bbox[1]) - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)
# 使用示例
classes = ['番茄叶霉病', '番茄早疫病', '番茄晚疫病', '黄瓜霜霉病', '黄瓜白粉病', '黄瓜角斑病', '茄子褐纹病', '茄子黄萎病', '茄子绵疫病']
detector = VegetableDiseaseDetector('enhanced_yolovpth', classes)
results, image = detector.detect('test.jpg')
cv2.imwrite('result.jpg', image)重难点和创新点
复杂自然背景下的病害检测是蔬菜病害检测系统研发的主要难点之一。实际种植环境中的蔬菜图像往往包含复杂的背景信息,如土壤、杂草、其他植物等,这些背景信息会干扰病害特征的提取和识别。为了解决这个问题,研究团队构建了包含真实自然背景的多尺度蔬菜病害数据集,并在模型设计中引入了多尺度特征提取和融合机制,提高模型对复杂背景的适应能力。
不同尺度病害的有效检测是另一个难点。蔬菜病害的大小和形态各异,有的病害区域较大,有的病害区域较小,特别是一些早期病害,症状不明显,区域较小,难以被传统方法有效检测。为了提高对不同尺度病害的检测能力,研究团队在YOLOv的基础上融合了Inception模块,该模块能够同时提取不同尺度的特征信息,增强网络对小尺度病害的关注和检测能力。同时,采用了FPN和PAN结构进行多尺度特征融合,充分利用不同层次的特征信息。
模型的轻量化和实时性也是一个重要问题。传统的深度学习模型参数量大、计算复杂度高,难以部署到移动端或嵌入式设备上进行实时检测。为了解决这个问题,研究团队引入了Transformer编码器,构建了轻量型蔬菜病害识别网络。该网络通过引入自注意力机制和多头注意力机制,提高了特征提取效率,同时采用了轻量化模块和解耦检测头,减少了模型参数量和计算量,实现了模型的轻量化和实时性。
相关文献
1 Redmon J, Divvala S, Girshick R, et al. You Only Look Once: Unified, Real-Time Object DetectionC//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 779-788.
2 Bochkovskiy A, Wang C Y, Liao H Y M. YOLOv4: Optimal Speed and Accuracy of Object DetectionJ. arXiv preprint arXiv:2004.10934, 2020.
3 Ultralytics. YOLOv5EB/OL. https://github.com/ultralytics/yolov5, 2023.
4 Szegedy C, Liu W, Jia Y, et al. Going deeper with convolutionsC//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 1-9.
5 Vaswani A, Shazeer N, Parmar N, et al. Attention is all you needC//Advances in neural information processing systems. 2017: 5998-6008.
6 Lin T Y, Dollár P, Girshick R, et al. Feature pyramid networks for object detectionC//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 2117-2125.
7 Liu S, Qi L, Qin H, et al. Path aggregation network for instance segmentationC//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 8759-8768.
8 He K, Zhang X, Ren S, et al. Deep residual learning for image recognitionC//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.