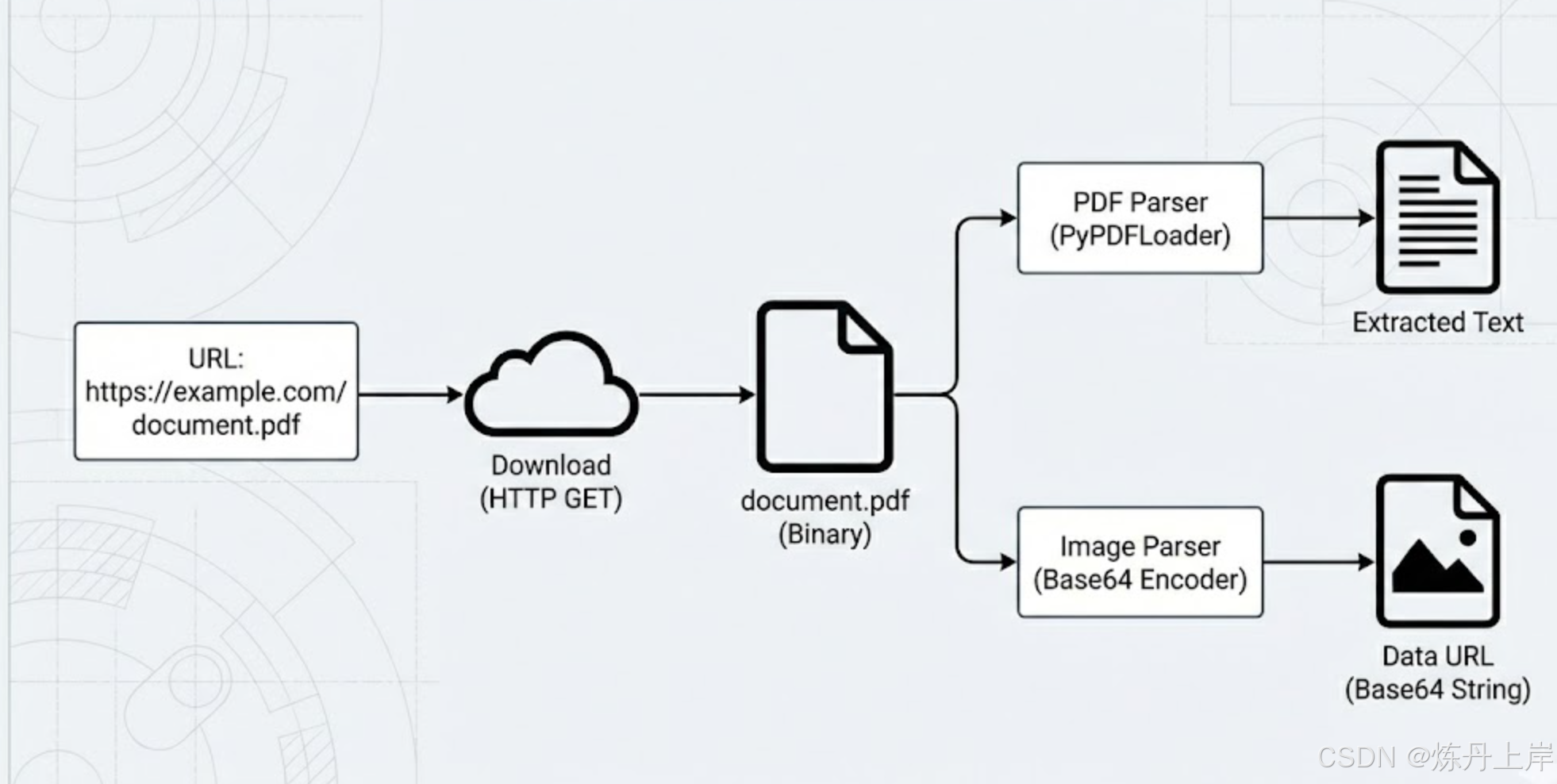
在构建 AI 助手、智能文档问答、企业知识库等应用时,"用户上传文件"看似简单,实际上背后是一条非常标准的工程流水线:
URL → 下载二进制 → 识别类型 → 调用解析器 → 输出文本/Base64 → 注入上下文 → 模型推理 → 流式返回
这篇文章会用"工程视角"把整套流程拆开讲清楚,并解释每一步为什么必不可少,尤其适合做 RAG / 文档问答 / 多模态助手 的同学。
1. 先回答四个核心问题(最容易混淆的点)
Q1:文件"下载"下载的到底是什么?
✅ 下载的是完整的二进制内容(raw bytes)
无论是 PDF、Excel、Word 还是 PPT,本质上都是一段结构化的二进制数据流。HTTP 请求返回的内容通常就是 resp.content 这种 bytes。
在 HTTPX 里,异步请求拿到的 response 就是标准的
AsyncClient.get()返回值。 (HTTPX 中文文档)
Q2:都下载下来了,为啥还要识别文件类型?
✅ 因为必须选对解析器(Parser)
模型不能"直接读 bytes",你必须先知道这是 PDF 还是 XLSX,才能决定:
- 用 PDF 的解析器(提取段落、页码)
- 用 Excel 的解析器(转成表格文本)
- 用 Word 的解析器(提取正文结构)
- 用 图片的解析器(转 Base64 或走视觉模型)
Q3:都下载下来了,为啥还要做内容解析?
✅ 这是整个流程的核心:二进制 → 可理解语义
AI 模型能理解的是 "文本 token" 或 "图像输入(多模态)" ,而不是原始二进制文件。
所以必须把文件转换成统一的可消费格式:
- PDF → 纯文本(按页/按段)
- Excel → 表格文本(CSV风格、或key-value风格)
- Word → 文本流
- 图片 →
data:image/...;base64,...或直接交给视觉模型
Q4:解析输出是不是"纯文本"?
✅ 大部分是,但图片是例外
- 文档类 (PDF/Word/Excel):返回 纯文本字符串
- 图片类 (PNG/JPG/WebP...):常见做法是返回 Data URL(Base64)
Data URL 的标准来自 RFC 2397:允许把小型数据以内联方式嵌进 URL 字符串里。 (RFC Editor)
2. 全链路流程拆解(从用户请求到模型回答)
下面我们按真实工程架构,把每个阶段串起来。
阶段1:用户发起请求
用户可能是上传本地文件,也可能是给一个外链 URL,例如:
json
{
"message": "分析这个PDF文档的内容",
"files": ["https://example.com/document.pdf"],
"user_id": "user123"
}你的系统要做的第一件事不是"交给模型",而是进入输入预处理环节。
阶段2:输入预处理(handle_input)
这一层一般做两件事:上下文初始化 + 文件任务拆分。
2.1 基础校验与上下文准备
- 校验
user_id - 创建或获取
thread_id - 选择模型(后面可能会切换)
- 记录日志、trace id 等
2.2 提取文件引用并并行处理
多文件通常会做并行 I/O:
python
file_refs = ["https://example.com/document.pdf"]
files_tasks = [_process_single_file(url) for url in file_refs]
files_list = await asyncio.gather(*files_tasks)并行的意义非常直接:下载与解析都是 I/O 密集型任务,并发收益巨大。
阶段3:单文件处理(_process_single_file)
这是最关键的"文件落地 + 解析转换"环节。
3.1 URL 校验
通常只允许 HTTP/HTTPS,避免本地路径穿透、协议滥用等安全问题:
python
if not file_ref.startswith(("http://", "https://")):
raise ValueError("仅支持http/https直链")3.2 文件下载(二进制落地)
文件下载的典型方式:
- 使用
httpx.AsyncClient - 支持 redirect
- 设置超时
- 拿
resp.content写入临时文件
HTTPX 提供了
AsyncClient的标准异步模式,非常适合 FastAPI / Sanic 这种 async Web 服务。 (HTTPX 中文文档)
伪代码:
python
async with httpx.AsyncClient(follow_redirects=True, timeout=60) as client:
resp = await client.get(url)
resp.raise_for_status()
tmp = tempfile.NamedTemporaryFile(delete=False, suffix=".pdf")
tmp.write(resp.content) # bytes
tmp.close()- ✅ 此时得到的是:"完整的二进制文件"
- ❌ 但这仍然不是模型能理解的东西。
3.3 文件类型识别(决定解析路线)
识别方式很多,最常见是用后缀名(也可以用 MIME sniff / magic number):
python
suffix = Path(prepared.name).suffix.lower()
is_image = suffix in {".png", ".jpg", ".jpeg", ".gif", ".webp", ".bmp", ".svg"}工程上建议:
- 后缀名用于快速路由
- MIME 用于二次确认
- magic number 用于防伪装(高安全要求场景)
3.4 内容解析:二进制 → 文本 / Base64
这一步是核心。
方案A:图片 → Base64 Data URL
把图片 bytes 做 Base64 编码:
python
data = prepared.path.read_bytes()
encoded = base64.b64encode(data).decode("utf-8")
parsed = f"data:{mime};base64,{encoded}"为什么要 Data URL?
- 可以把图片内容作为"字符串参数"传递
- 避免模型侧再去访问外链(通常模型不允许随意外网访问)
- 遵循 RFC 2397 标准格式 (RFC Editor)
方案B:文档(PDF/Word/Excel) → 提取文本
典型做法是调用统一的 parse_document_tool():
python
parsed = await parse_document_tool(str(prepared.path))3.5 临时文件清理
下载文件落地到磁盘非常常见(尤其是解析库需要 path),但必须做资源回收:
python
finally:
if prepared.is_temp:
prepared.path.unlink(missing_ok=True)阶段4:解析器(parse_document_tool)如何选型
解析器就是"把文件转成文字"的工具层。
一般形式如下:
python
suffix = path.suffix.lower()
if suffix == ".pdf":
text = _extract_pdf_text(path)
elif suffix == ".xlsx":
text = _extract_excel_text(path)
elif suffix == ".docx":
text = _extract_docx_text(path)
# ...4.1 PDF 解析:PyPDFLoader 的典型模式
一个非常常用的方案是 LangChain 的 PyPDFLoader:
- 默认按页拆分(每页一个 Document)
- metadata 里保留 page number
- 支持 single mode(整篇变成一个文本流)
官方文档明确说明:
PyPDFLoader会按页加载并生成带页码的 Document。 (LangChain 文档)
4.2 Excel 解析:表格转文本的关键点
Excel 本质是二维表结构,解析策略常见有两种:
- CSV 风格(适合简单表格)
- 结构化 Key-Value (适合表头复杂/多sheet)
目标只有一个:让模型读懂表格的行列含义。
阶段5:模型自动切换(文本 vs 多模态)
如果检测到文件里有图片,很多系统会直接切换到视觉模型:
python
if any(f.get("is_image") for f in files_list):
selected_model = "Vision-Model"原因很直接 :
文本模型无法理解图片像素,多模态模型可以直接"看图"。
阶段6:构建给模型的消息(Message Building)
文档类输入
文档类通常用普通文本消息 + 文件解析内容注入:
python
HumanMessage(
content="分析这个PDF文档的内容",
additional_kwargs={"files": files_list}
)图片类输入(多模态 parts)
多模态模型一般要求 parts:
python
parts = [
{"type": "text", "text": "分析这张图片"},
{"type": "image_url", "image_url": {"url": "data:image/png;base64,..."}}
]阶段7:中间件增强(把文件内容"塞进上下文")
7.1 file_context_middleware:注入文本
常见做法是把解析后的文本拼进 SystemMessage:
"已解析的用户文件(务必优先基于这些内容回答)..."
这样模型即使没有文件系统权限,也能"看到文件内容"。
7.2 vision_model_switching_middleware:自动切模型
图片存在则切换视觉模型,让推理链路自然进入多模态。
阶段8:模型推理
- 文档:模型在文本上下文里做推理/总结/问答
- 图片:视觉模型读取 Base64 图像并完成理解
阶段9:流式返回(Streaming & SSE)
很多 AI 产品为了体验,会边生成边返回,即"流式输出"。
**SSE(Server-Sent Events)**是最常见方案:服务端单向推送文本流,非常适合大模型逐 token 输出。 (掘金)
并且 OpenAI 的 Responses API(stream=true)也是通过 SSE 发事件流,例如 response.output_text.delta 这种增量事件。 (OpenAI 平台)
典型事件包括:
response.file.parsed(文件解析完成)response.output.delta(模型输出增量)response.completed(结束)
3. 为什么这套设计几乎是"行业标准"?
✅ 1)为什么必须下载?
- 模型通常不能直接访问公网 URL(安全与权限问题)
- 需要统一存储、统一解析
- 方便做缓存、审计、脱敏
✅ 2)为什么必须识别类型?
- 决定解析器(解析逻辑完全不同)
- 决定是否需要视觉模型
- 避免"拿 PDF 走 Excel 解析器"的灾难
✅ 3)为什么必须解析成文本?
因为模型的入口是:
- 文本 token
- 或多模态图像输入
"二进制文件"对模型来说就是随机噪音。
✅ 4)为什么用临时文件而不是全放内存?
- 大文件内存风险高
- 解析库通常要求 path
- 临时文件可控,可清理,可复用
✅ 5)为什么并行处理?
- 多文件下载/解析属于 I/O 密集任务
async并发提升吞吐量- 体验明显更快
4. 一张数据流图总结全流程
*.pdf
*.png
用户URL
HTTP下载
二进制文件
PDF解析器
图片解析器
文档内容(文本)
Data URL(Base64)
系统提示词注入
模型推理
SSE流式输出
最终回答
5. 工程实践中的注意事项(踩坑预警)
- 文件大小控制:图片建议限制在 1MB~几MB,否则 Base64 会膨胀
- 解析截断策略 :文档很长时要设置
max_chars,避免上下文爆炸 - 扫描版 PDF :PyPDFLoader 可能抽不到字(需要 OCR 或
hi_res模式) - 异常兜底:下载失败、解析失败要给用户友好提示
- 安全:只允许 http/https,生产环境最好校验 MIME + 文件头防伪装
结语
这套流程的核心思想其实就一句话:
文件只是载体,模型真正需要的是"可理解的语义表示"。
当你把"下载二进制 → 解析成文本/图像表示 → 注入上下文"这条链路搭稳之后,无论你做的是企业知识库、合同审阅、PDF 问答还是多模态助手,都可以直接复用这套架构。
参考资料: