这一篇是很弱智的笔记,纯粹惩罚没有看官方文档的我
一、问题描述
1、前期准备
我这几天用一个篮球数据集训练了yolo11模型
并根据不断调整yaml部分的网络模型结构,添加了更大尺寸的P2目标检测层来融合篮球这种微小目标,而且也把P2、P3小目标(大尺寸)层的C3k2的repeat重复执行次数从2变到3。。。巴拉巴拉以上看不懂的去看我往期文章
看不懂也没关系当我发疯,总而言之:
在我一番苦心调教下,这个模型已经训练得非常非常优秀,可以看一下各项评估
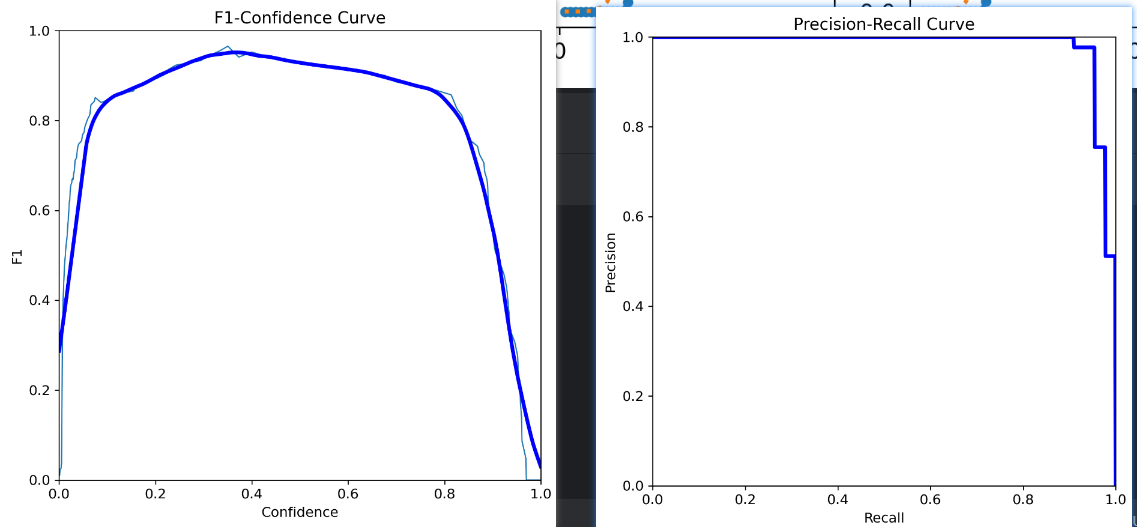
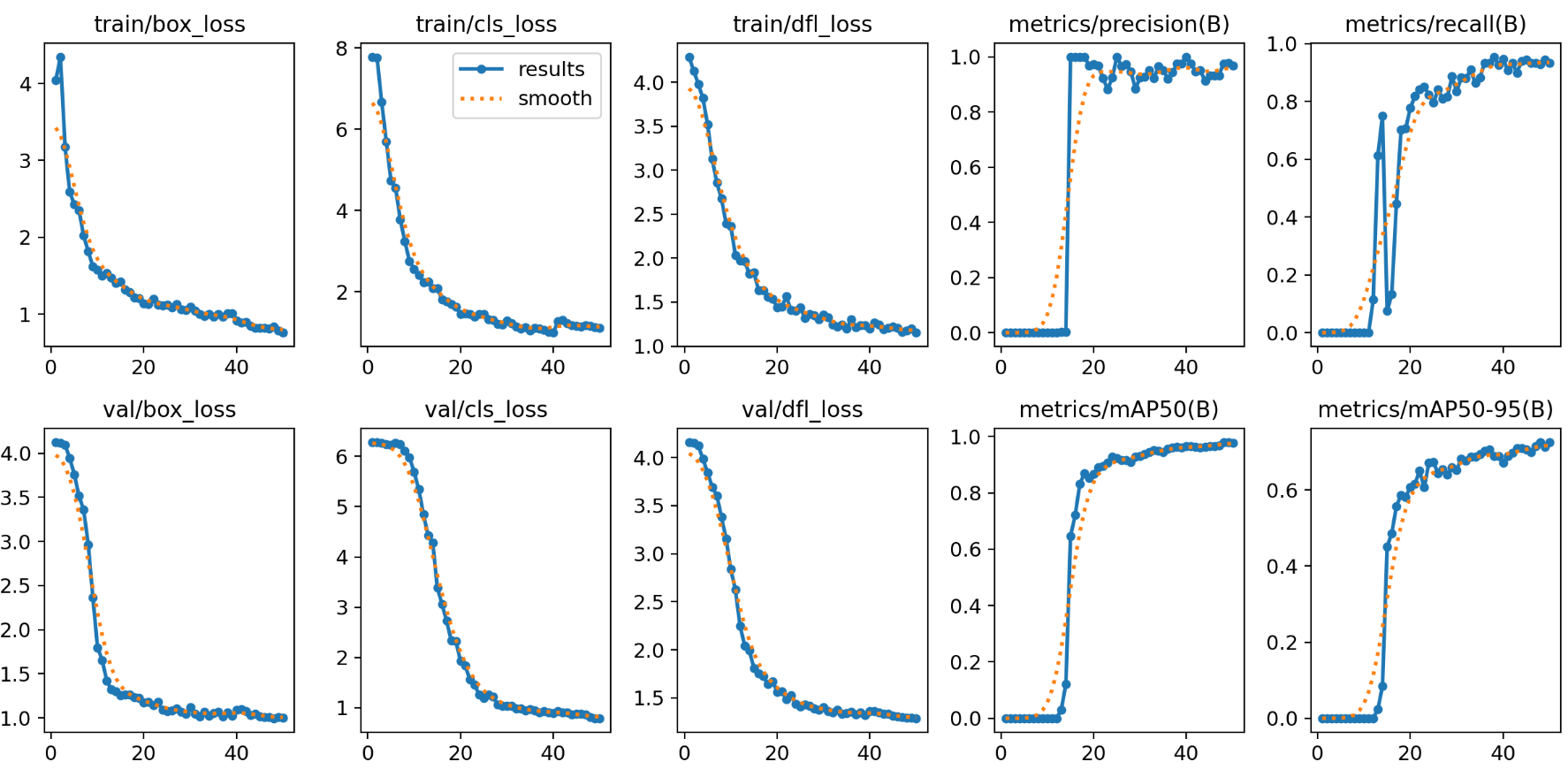
这里说一下,我是纯粹通过调整yaml得网络结构训练成这个效果的,还没加上在train.py那训练的超参数,各个代码如下
【yolo11.yaml】代码
python# Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license # Ultralytics YOLO11 object detection model with P3/8 - P5/32 outputs # Model docs: https://docs.ultralytics.com/models/yolo11 # Task docs: https://docs.ultralytics.com/tasks/detect # Parameters nc: 80 # number of classes scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n' # [depth, width, max_channels] n: [0.50, 0.25, 1024] # summary: 181 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs s: [0.50, 0.50, 1024] # summary: 181 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs m: [0.50, 1.00, 512] # summary: 231 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs l: [1.00, 1.00, 512] # summary: 357 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs x: [1.00, 1.50, 512] # summary: 357 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs # YOLO11n backbone backbone: # [from, repeats, module, args] - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2 - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4 - [-1, 2, C3k2, [256, False, 0.25]] - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8 - [-1, 2, C3k2, [512, False, 0.25]] - [-1, 1, Conv, [512, 3, 2]] # 5-P4/16 - [-1, 2, C3k2, [512, True]] - [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32 - [-1, 2, C3k2, [1024, True]] - [-1, 1, SPPF, [1024, 5]] # 9 - [-1, 2, C2PSA, [1024]] # 10 # YOLO11n head (add P2 for small objects) head: # -------- Top-down: P5 -> P4 -> P3 -------- - [-1, 1, nn.Upsample, [None, 2, "nearest"]] # 11: P5->P4 up - [[-1, 6], 1, Concat, [1]] # 12: cat backbone P4 (layer 6) - [-1, 2, C3k2, [512, False]] # 13: P4/16 - [-1, 1, nn.Upsample, [None, 2, "nearest"]] # 14: P4->P3 up - [[-1, 4], 1, Concat, [1]] # 15: cat backbone P3 (layer 4) - [-1, 3, C3k2, [256, False]] # 16: P3/8 (keep your improved depth) # -------- NEW: Top-down to P2 (for small basketball) -------- - [-1, 1, nn.Upsample, [None, 2, "nearest"]] # 17: P3->P2 up - [[-1, 2], 1, Concat, [1]] # 18: cat backbone P2 (layer 2) <-- you chose #2 - [-1, 3, C3k2, [256, False]] # 19: P2/4 (NEW) # -------- Bottom-up (PAN): P2 -> P3 -> P4 -> P5 -------- - [-1, 1, Conv, [256, 3, 2]] # 20: P2->P3 down - [[-1, 16], 1, Concat, [1]] # 21: cat head P3 (layer 16) - [-1, 2, C3k2, [256, False]] # 22: P3/8 - [-1, 1, Conv, [256, 3, 2]] # 23: P3->P4 down - [[-1, 13], 1, Concat, [1]] # 24: cat head P4 (layer 13) - [-1, 2, C3k2, [512, False]] # 25: P4/16 - [-1, 1, Conv, [512, 3, 2]] # 26: P4->P5 down - [[-1, 10], 1, Concat, [1]] # 27: cat backbone P5 (layer 10) - [-1, 2, C3k2, [1024, True]] # 28: P5/32 # -------- Detect: P2, P3, P4, P5 -------- - [[19, 22, 25, 28], 1, Detect, [nc]] # Detect(P2, P3, P4, P5)【train.py】代码(这些超参数只是为了训练时用充分GPU加速)
pythonimport torch from ultralytics import YOLO if __name__ == '__main__': # 这是为了Windows下开启workers>0 的硬性条件,workers>0就加快速度 torch.multiprocessing.freeze_support() # 解决多进程报错问题 # 直接加载官方YOLO11n预训练模型 model = YOLO(r"F:\我自己的毕设\YOLO_study\basketball\cfg\11\yolo11.yaml").load("yolo11n.pt") results = model.train( data=r"F:\我自己的毕设\YOLO_study\basketball\basketball.yaml", epochs=50, # 训练50轮 imgsz=640, # 输入图片尺寸,放大到1280×1280 device=0, # 使用GPU workers=3, # 开启多进程读取数据 batch=-1, # 自动批量大小调小测试到是24 )
然后我进行了对test测试集里的所有图片批量预测推理
【predict.py批量推测】代码
pythonfrom ultralytics import YOLO import os # 1. 实例化模型 # 确保路径指向正确的 .pt 权重文件 model_path = r'F:\我自己的毕设\YOLO_study\basketball\runs\detect\train4\weights\best.pt' yolo = YOLO(model=model_path) # 2. 指定包含待预测图片的文件夹路径 # 注意:这里填写的是文件夹路径,不是单张图片的路径 source_folder = r'F:\我自己的毕设\YOLO_study\basketball\images\test' # 3. 进行批量预测 # stream=True 表示返回一个生成器,这样处理大量图片或视频时不会占用过多内存 results = yolo(source=source_folder, stream=True, save=True) # 4. 遍历结果进行处理 for result in results: # 这里的 result 是单张图片预测后的结果对象 # 获取原始图片路径 print(f"正在处理图片: {result.path}") # 获取检测到的框 (boxes) # result.boxes 是一个 Boxes 对象,包含了所有检测框的信息 boxes = result.boxes # 示例:打印这张图里检测到了多少个目标 print(f"检测到目标数量: {len(boxes)}") # 示例:获取每个框的坐标和类别 for box in boxes: # box.xyxy 是边界框坐标 (x1, y1, x2, y2) # box.conf 是置信度 # box.cls 是类别ID print(f"坐标: {box.xyxy}, 置信度: {box.conf}, 类别: {box.cls}") # 如果你不想自己写保存代码,YOLO默认会自动把画好框的图保存到 runs/detect/predict 文件夹下
2、出现漏检情况
然后我去观察测试集预测结果,确实非常优秀,大部分篮球都被识别了
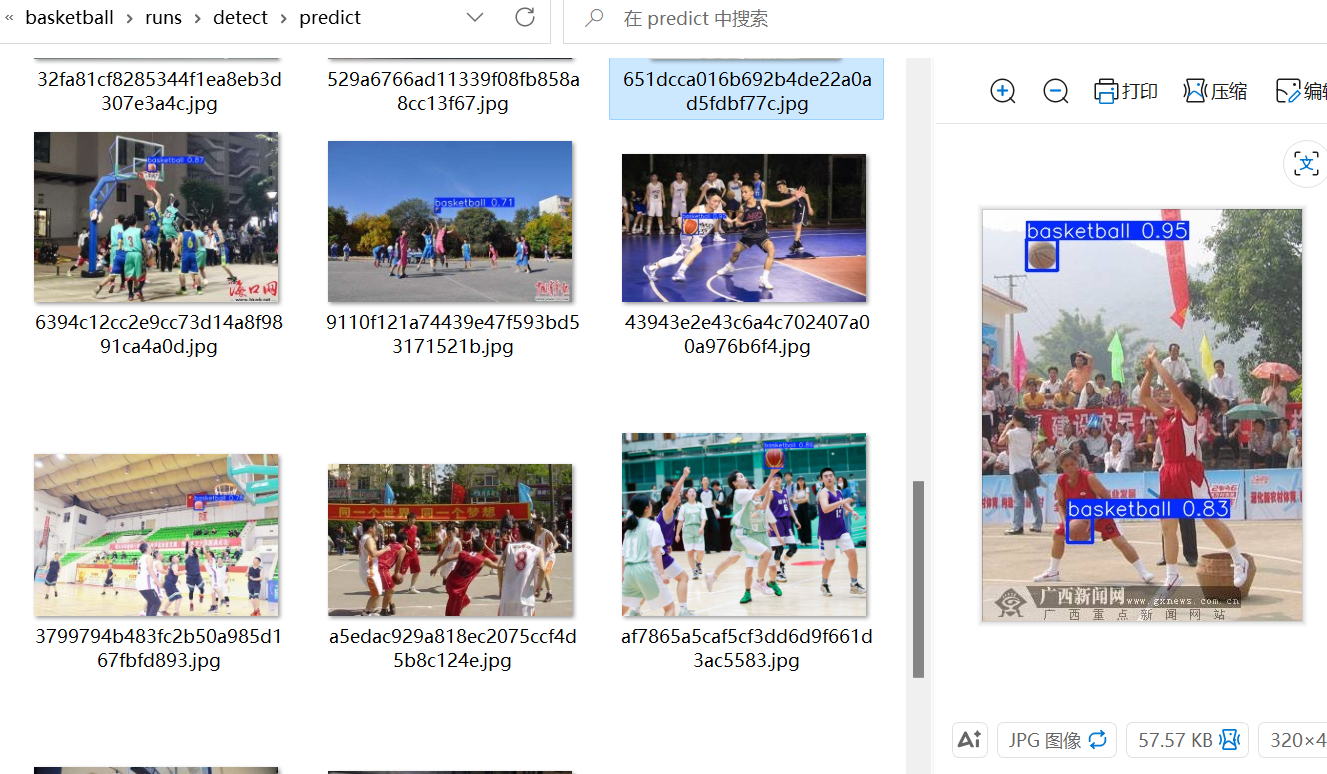
但是有这么几张图片就是识别不出
是因为颜色比较罕见、有点反光、有阴影导致一些特征模糊,反正就是训练集里很少见到的篮球的样子,就好比你见多了正常人,突然来个长得像伪人的人你就不知道它是不是人了

二、解决办法:predict时加强参数
正当我打算再次训练,给训练时加入图像增强、图片放大、甚至打算写一个注意力模块查到head的时候,chatGPT5.2 打断了我


于是我思考了一下,好像上面的情况并非大部分情况,一般正式的球赛都是用红色的球,并在光线正常的情况拍摄,我现在的模型如果已经足够好的情况下,似乎确实不用为了"几颗老鼠屎坏了一锅粥",等会单独为了他们修改反而影响我模型整体效果就完了
于是chatGPT5.2给了我另一个思路:在predict预测的时候加入加强参数
我还不是很理解,我一直以为【imgsz】、【augment】.......这些放大尺寸、数据增强的参数只是train训练的时候才加的,但是大错特错,我根本没去看预测的官方文档,预测也是可以用的!!!!我们可以针对少数漏检、错检的情况,加强数据增强来解决这种"少数难例"。
pythonfrom ultralytics import YOLO # 1. 实例化模型 # 确保路径指向正确的 .pt 权重文件 model_path = r'F:\我自己的毕设\YOLO_study\basketball\runs\detect\train4\weights\best.pt' yolo = YOLO(model=model_path) # 2. 指定包含待预测图片的文件夹路径 # 注意:这里填写的是文件夹路径,不是单张图片的路径 source_folder = r'F:\我自己的毕设\YOLO_study\basketball\images\test' # 3. 进行批量预测 # 取一张刚刚漏检的图片试一下 results = yolo(source=source_folder+r"\529a6766ad11339f08fb858a8cc13f67.jpeg",imgsz=1280, conf=0.15, iou=0.5, augment=True, save=True)
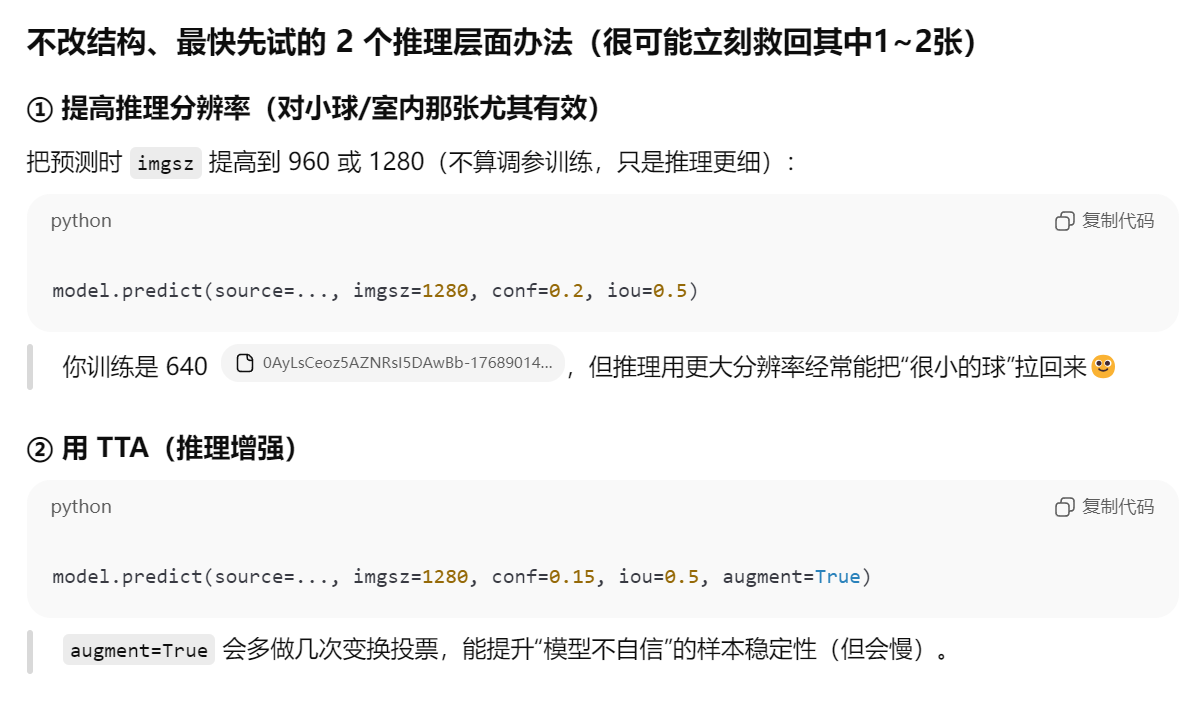
结果效果非常好,马上预测出来了(并不是conf和iou参数起的作用,因为我已经试过了)

三、predict有哪些参数可以解决漏检错检?
可在预测阶段解决漏检错检的参数


不可在预测阶段做,只能靠训练弥补的
