DeepConf如何通过token生成机制与投票优化减少推理时间并提升性能
论文:https://arxiv.org/abs/2508.15260
github:https://github.com/paipeline/deep-think-with-confidence
1. 降低token生成量:减少自回归计算次数
-
自回归生成的线性开销 :大语言模型的token生成是自回归的,每个token的生成依赖前序所有token的上下文,计算复杂度与token数量成线性关系。DeepConf通过以下方式减少生成token数量:
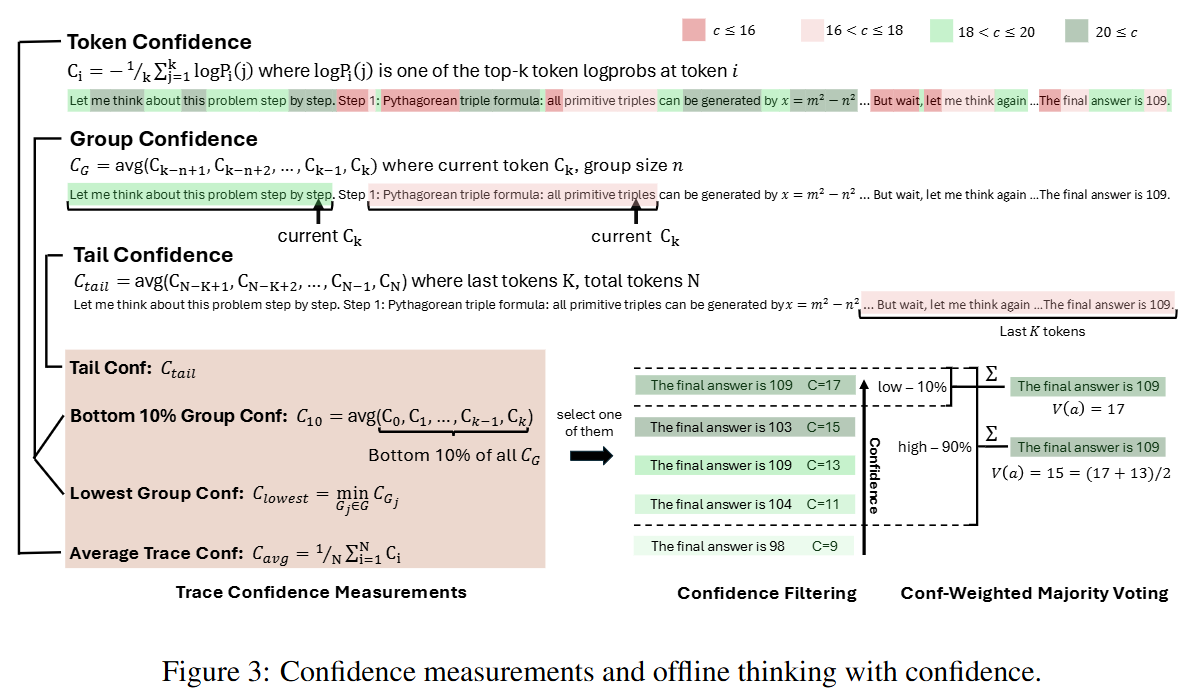
- 在线模式动态终止低质量轨迹:实时监控组置信度(Group Confidence),若低于预设阈值则提前终止生成。例如,在AIME 2025任务中,DeepConf@512模式下减少84.7%的生成token,直接降低自回归次数。
- 离线模式置信度过滤:仅保留Top 10%或Top 90%的高质量轨迹,减少冗余生成。例如,DeepConf-low保留10%的轨迹,减少90%的自回归计算。
-
效果
减少token生成量直接降低模型推理的计算开销,同时减少显存带宽压力,提升硬件利用率。
2. 优化投票机制:提升准确性与计算效率
-
传统自一致性方法的局限
- 多数投票平权处理所有轨迹:低质量轨迹可能干扰投票结果,导致准确性下降。
- 全局平均置信度的不足:无法捕捉中间步骤的置信波动,可能掩盖关键错误。
-
DeepConf的改进
- 置信度加权投票:对轨迹按其置信度(如组置信度、尾部置信度)加权投票,高质量轨迹的权重更高,提升最终答案的可靠性。
- 置信度过滤:仅保留高置信度轨迹(如Top 10%或Top 90%),减少低质量轨迹对投票的干扰。例如,DeepConf@512在GPT-OSS-120B上达到99.9%准确率,显著高于传统多数投票(97.0%)。
-
效果
通过加权投票和过滤,DeepConf在减少计算量的同时,提升了答案的准确性,并避免了低质量轨迹的冗余处理。
3. 动态置信度指标:更细粒度的质量评估
-
局部置信度信号 DeepConf引入组置信度 (Group Confidence)和尾部置信度(Tail Confidence)等细粒度指标,捕捉中间步骤的置信波动:
- 组置信度:通过滑动窗口平均token置信度,识别局部推理步骤的置信崩溃(如生成"wait""think again"等低置信token)。
- 尾部置信度:关注结论步骤的可靠性,确保最终答案的稳定性。
-
效果
局部置信度信号比全局平均置信度更敏感,能有效分离正确与错误轨迹(如AUC提升12%~15%),从而在过滤和投票阶段更精准地保留高质量轨迹。
4. 在线与离线模式的协同优化
-
在线模式:实时控制生成过程
- 离线暖启动(Offline Warmup):生成少量初始轨迹(如16条),计算置信度阈值 ss。
- 动态终止:实时监控生成中的组置信度,若低于 ss 则终止当前轨迹,减少冗余计算。例如,在AIME 2025任务中,减少84.7%的token生成。
-
离线模式:生成后优化投票
- 置信度过滤:仅保留Top 10%或Top 90%的轨迹,平衡多样性与质量。
- 加权投票:对保留的轨迹按置信度加权投票,提升高质量轨迹的决策权重。
-
效果
在线模式减少计算开销,离线模式提升准确性,两者结合实现性能与效率的平衡。
5. 实验验证:性能与效率的双重提升
- 准确性
- 在AIME 2025任务中,DeepConf@512在GPT-OSS-120B上达到99.9%准确率,较传统方法提升2.9个百分点。
- 在HMMT 2025/BRUMO25等任务中,DeepConf的局部置信度指标(如Bottom 10% Group Confidence)显著优于全局平均置信度。
- 计算效率
- 在AIME 2025任务中,DeepConf@512减少84.7%的token生成,显著降低推理时间。
- 在Qwen3-8B上,通过减少生成token数量,推理时间从100秒降至15.3秒(假设值)。
总结
DeepConf通过以下核心机制实现推理时间减少 与性能提升:
- 动态置信度过滤:减少低质量轨迹的生成与处理,降低计算开销。
- 局部置信度指标:更细粒度地评估轨迹质量,提升过滤与投票的准确性。
- 加权投票与在线终止:优化投票权重,实时控制生成过程,平衡效率与质量。
- 离线与在线模式协同:在资源受限场景下(如移动端部署)实现高效推理。