文章目录
-
- 为什么需要认真做一次时序数据库选型?
- 时序数据库选型时重点关注哪些问题?
- [IoTDB 的场景定位:以工业时序数据为核心](#IoTDB 的场景定位:以工业时序数据为核心)
- 上手流程:先跑通单机闭环,再考虑集群
- [Java 实战:工业设备数据的批量写入与查询](#Java 实战:工业设备数据的批量写入与查询)
- [Python 实战:采集脚本与能耗聚合分析](#Python 实战:采集脚本与能耗聚合分析)
- 常见问题与排查思路
- 总结
为什么需要认真做一次时序数据库选型?
在工业物联网、能源电力、车联网、轨交、制造产线等场景中,系统在早期阶段往往可以依赖通用数据库完成数据落库与基础查询。但随着业务规模扩大,设备数量、测点规模和采样频率持续增长,系统通常会逐步暴露出一系列问题:
- 写入高峰期延迟波动明显,稳定性下降
- 磁盘占用增长过快,长期存储成本失控
- 历史数据查询与趋势分析响应缓慢
- 数据模型固化,扩容和运维复杂度持续上升
回顾这些问题,本质并不在于"数据库性能不足",而在于使用了通用数据库承载典型的时序数据负载。
工业系统中的时序数据通常具备以下特征:
- 持续、高频写入
- 测点规模大、结构相对稳定
- 数据需要长期留存
- 查询以趋势分析、时间窗口聚合为主
在这种背景下,引入专门面向时序场景设计的数据库,几乎是系统演进过程中的必然选择。本文按照真实项目中的选型与验证流程,完整记录一次 IoTDB 从下载安装到跑通写入与查询,再到实际使用中踩坑与排查的全过程。
- IoTDB 官方下载 :https://iotdb.apache.org/zh/Download/
- 企业版官网(Timecho) :https://timecho.com

时序数据库选型时重点关注哪些问题?
在实际项目中,选型最终是否能够落地,往往取决于几个关键问题是否可控,而非功能是否"全面"。结合工业场景经验,重点通常集中在以下三方面。
写入能力与稳定性
工业现场的数据写入不是短时压测行为,而是 7×24 小时持续运行。相比理论峰值写入能力,更值得关注的是:
- 高并发写入场景下延迟是否稳定(尤其是 P95 / P99)
- 是否原生支持批量写入,避免逐条写入带来的性能瓶颈
- 网络抖动、断点回传等情况下,对乱序数据的处理能力
如果写入稳定性不足,后续往往需要通过复杂的缓存与削峰机制弥补,系统整体复杂度会明显上升。
存储效率与长期成本
在工业系统中,存储成本往往在运行半年到一年后开始成为压力点。选型阶段需要重点关注:
- 时序数据压缩率
- 冷热数据管理与长期留存策略
- 扩容后的数据重分布成本
如果同等数据规模下存储增长过快,将直接影响硬件投入和运维复杂度。
查询能力与使用体验
工业系统中常见的查询模式包括:
- 最近一段时间的趋势查询
- 固定时间窗口的聚合统计(如 5 分钟、15 分钟、1 小时)
- 多测点在同一时间轴上的对齐与对比分析
如果系统在写入和存储层面表现良好,但查询能力不足,往往会导致数据被频繁同步到其他系统进行分析,系统链路反而更加复杂。
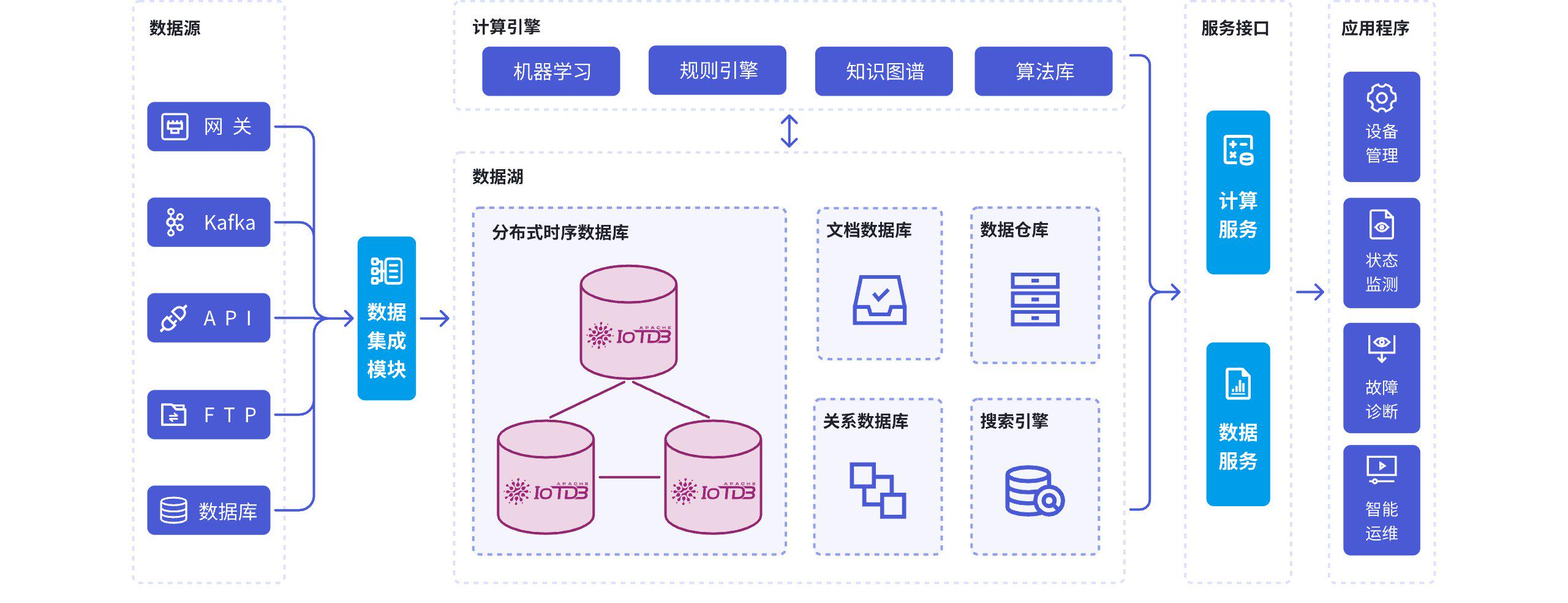
IoTDB 的场景定位:以工业时序数据为核心
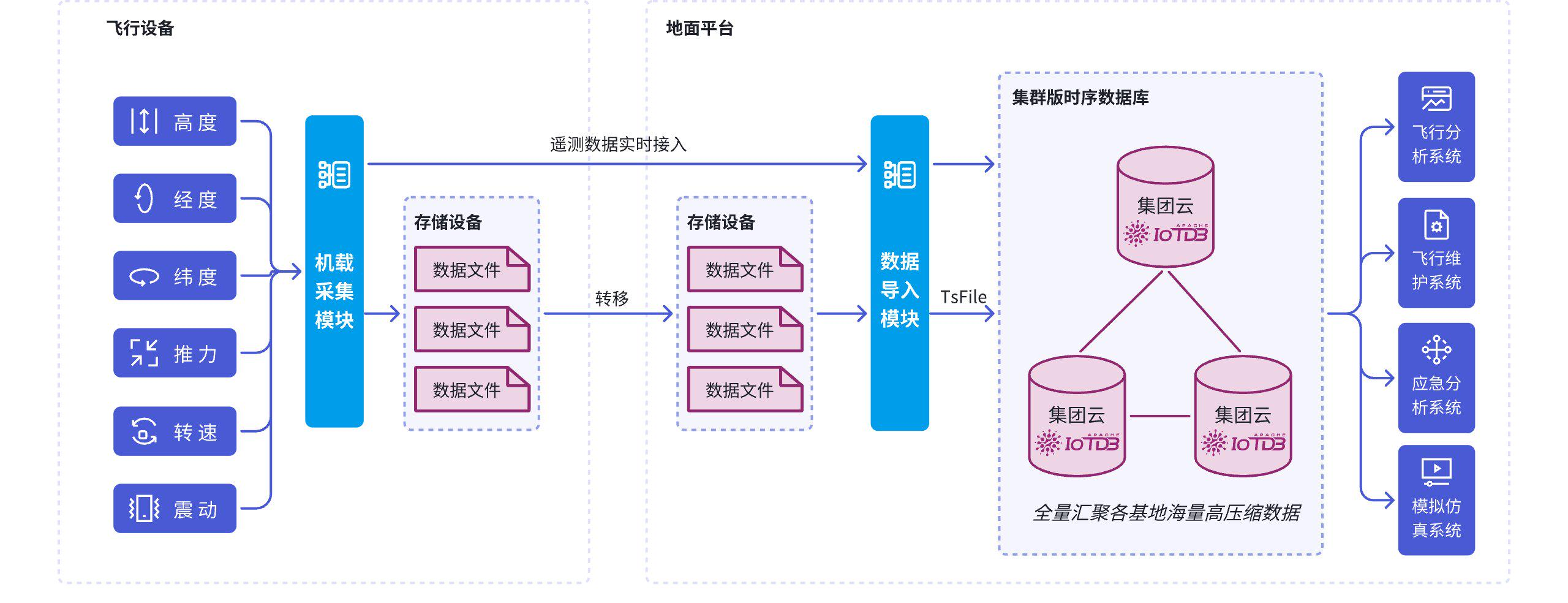
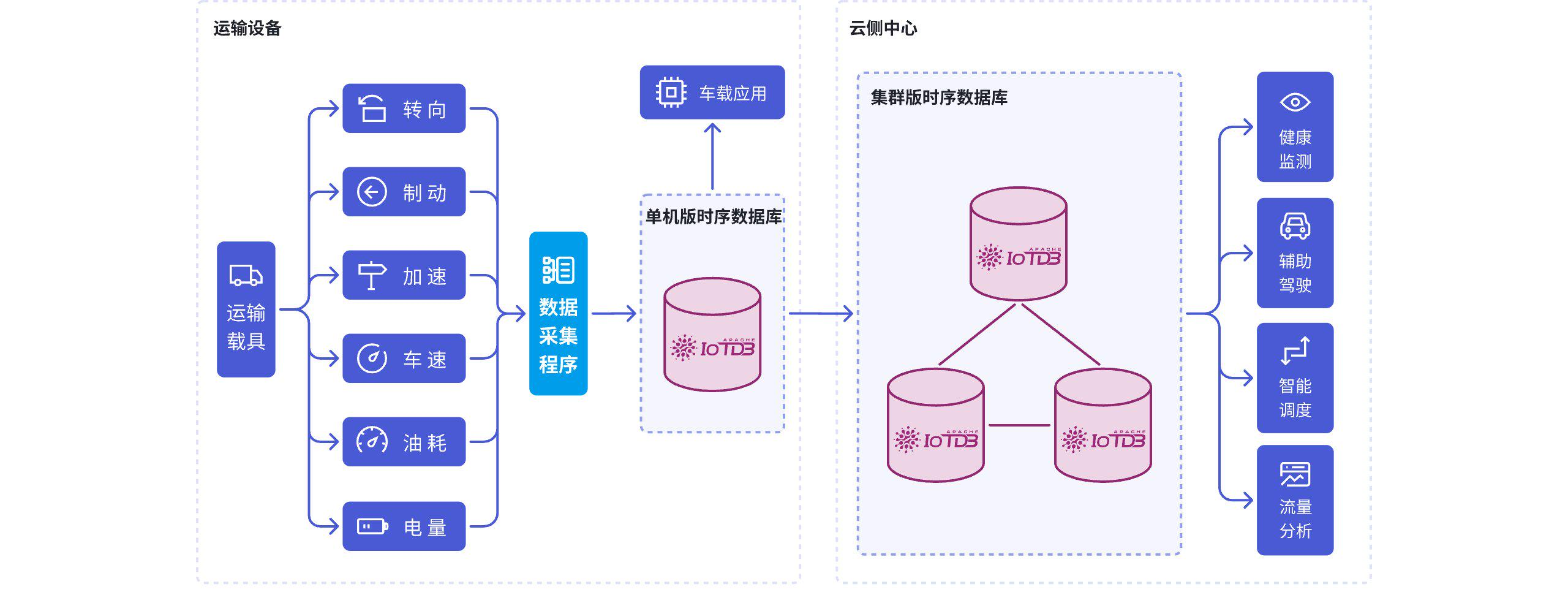
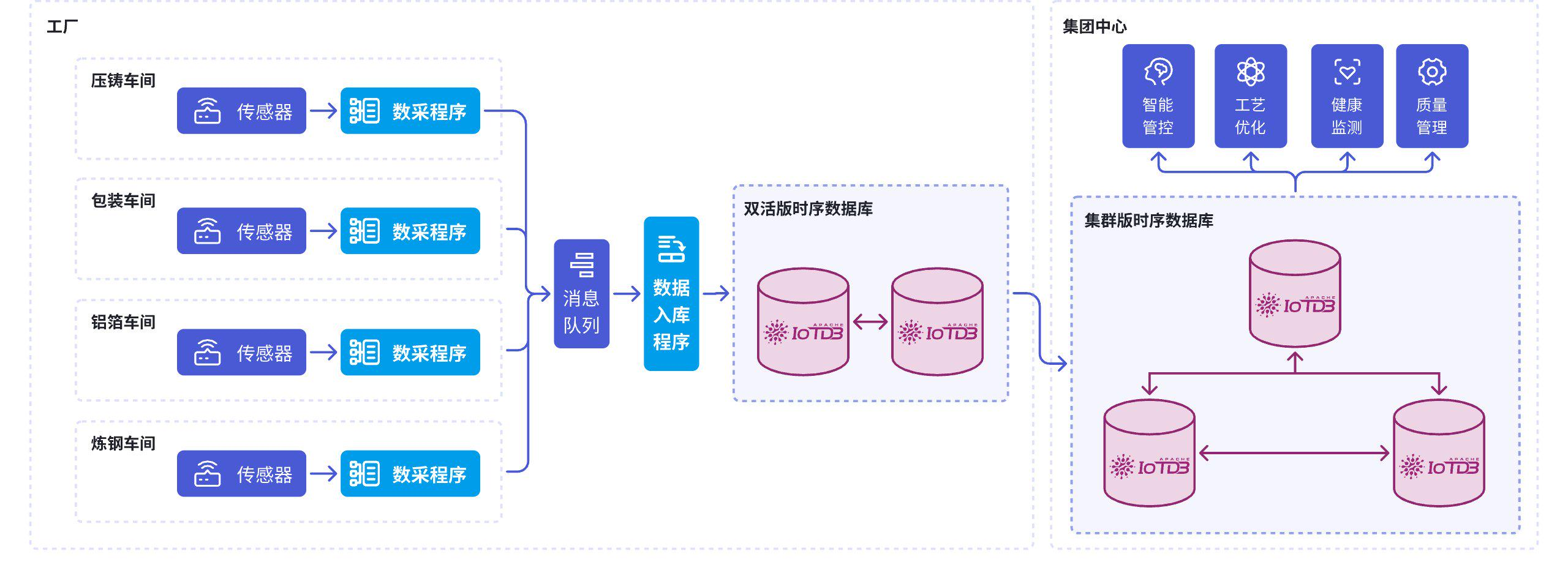
判断一个时序数据库是否适合工业场景,一个直观标准是:其默认设计是否围绕设备与测点数据展开。IoTDB 将能源、电力、交通、制造等行业作为核心应用场景,其数据模型、写入接口与查询能力均围绕设备测点型数据进行设计。
能源电力
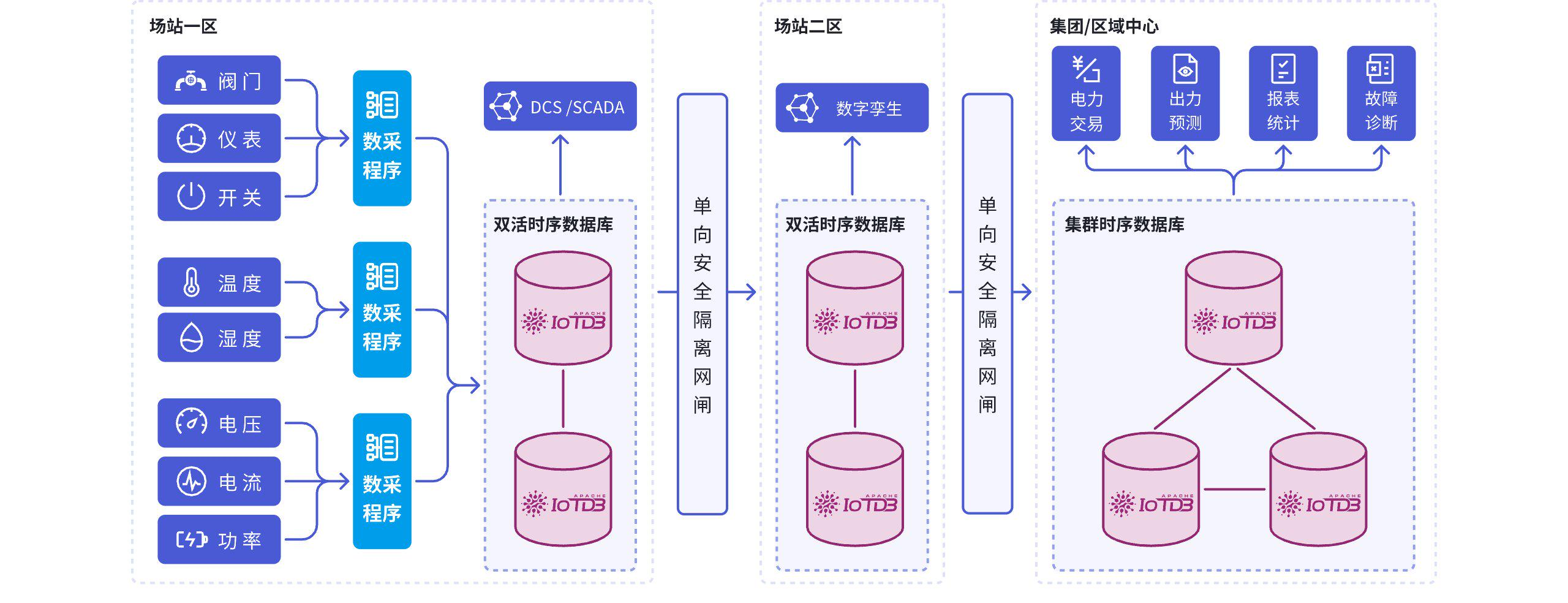
航空航天
交通运输
钢铁冶炼
通用物联网
上手流程:先跑通单机闭环,再考虑集群
在选型验证阶段,建议优先使用 standalone 单机模式。这一阶段的目标并不是验证极限性能,而是确认:
- 数据模型是否符合业务认知
- 写入与查询接口是否顺手
- 基本数据链路是否能够稳定跑通
下载
下载地址:https://iotdb.apache.org/zh/Download/
解压
解压到常规目录即可,避免路径中包含空格或中文字符,尤其是在 Windows 环境下。
启动(Standalone)
- Linux / macOS
bash
./sbin/start-standalone.sh- Windows
bat
.\sbin\start-standalone.bat启动后,首先通过 CLI 连接服务(默认端口 6667,用户 root / root),确认服务端已正常运行。
Java 实战:工业设备数据的批量写入与查询
在真实生产环境中,应避免逐条写入数据。IoTDB 推荐使用 Session + Tablet 进行批量写入。以下示例模拟智能制造车间中设备实时采集与查询验证的完整流程。
java
import org.apache.iotdb.rpc.IoTDBConnectionException;
import org.apache.iotdb.rpc.StatementExecutionException;
import org.apache.iotdb.session.Session;
import org.apache.iotdb.session.SessionDataSet;
import org.apache.iotdb.tsfile.file.metadata.enums.TSDataType;
import org.apache.iotdb.tsfile.write.record.Tablet;
import org.apache.iotdb.tsfile.write.schema.MeasurementSchema;
import java.util.ArrayList;
import java.util.List;
/**
* IoTDB 工业设备数据采集示例
* 场景:智能制造车间设备实时监控
*/
public class IndustrialDataCollection {
public static void main(String[] args)
throws IoTDBConnectionException, StatementExecutionException {
// 1) 连接
Session session = new Session.Builder()
.host("127.0.0.1")
.port(6667)
.username("root")
.password("root")
.build();
session.open(false);
// 2) 工业层级建模:root.工厂.车间.产线.设备
String devicePath = "root.factory01.workshop01.line01.machine01";
List<MeasurementSchema> schemaList = new ArrayList<>();
schemaList.add(new MeasurementSchema("temperature", TSDataType.FLOAT));
schemaList.add(new MeasurementSchema("pressure", TSDataType.FLOAT));
schemaList.add(new MeasurementSchema("speed", TSDataType.INT32));
schemaList.add(new MeasurementSchema("vibration", TSDataType.FLOAT));
schemaList.add(new MeasurementSchema("status", TSDataType.TEXT));
// 3) 批写 Tablet
Tablet tablet = new Tablet(devicePath, schemaList, 1000);
long startTime = System.currentTimeMillis();
for (int i = 0; i < 1000; i++) {
int row = tablet.rowSize++;
tablet.addTimestamp(row, startTime + i * 1000); // 每秒一次
tablet.addValue("temperature", row, 75.5f + (float)(Math.random() * 10));
tablet.addValue("pressure", row, 2.5f + (float)(Math.random() * 0.5));
tablet.addValue("speed", row, 1500 + (int)(Math.random() * 100));
tablet.addValue("vibration", row, 0.05f + (float)(Math.random() * 0.02));
tablet.addValue("status", row, i % 100 == 0 ? "warning" : "normal");
}
session.insertTablet(tablet);
// 4) 查询验证:筛 warning
String querySQL = String.format(
"SELECT temperature, pressure, vibration, status FROM %s " +
"WHERE time >= %d AND status = 'warning'",
devicePath, startTime
);
SessionDataSet dataSet = session.executeQueryStatement(querySQL);
while (dataSet.hasNext()) {
System.out.println(dataSet.next());
}
dataSet.closeOperationHandle();
session.close();
}
}Python 实战:采集脚本与能耗聚合分析
Python 在工业现场常用于采集脚本、边缘网关服务和运维工具。以下示例模拟建筑能耗采集场景,并通过聚合查询验证数据有效性。
python
from iotdb.Session import Session
from iotdb.utils.IoTDBConstants import TSDataType
from iotdb.utils.Tablet import Tablet
import time
import random
# 1) 连接
session = Session("127.0.0.1", "6667", "root", "root")
session.open(False)
# 2) 建模:root.建筑.楼层.监控点
device_id = "root.building01.floor03.energy_meter01"
measurements = ["voltage", "current", "active_power", "reactive_power",
"power_factor", "total_energy"]
data_types = [
TSDataType.FLOAT,
TSDataType.FLOAT,
TSDataType.FLOAT,
TSDataType.FLOAT,
TSDataType.FLOAT,
TSDataType.DOUBLE
]
values, timestamps = [], []
total_energy = 0.0
print("开始采集能耗数据...")
# 3) 模拟 1 小时数据:每 10 秒一次,共 360 条
for i in range(360):
timestamp = int(time.time() * 1000) + i * 10000
voltage = 220.0 + random.uniform(-5, 5)
current = 15.0 + random.uniform(-3, 3)
active_power = (voltage * current * 0.85) / 1000
reactive_power = (voltage * current * 0.53) / 1000
power_factor = 0.85 + random.uniform(-0.05, 0.05)
total_energy += active_power * (10.0 / 3600.0)
timestamps.append(timestamp)
values.append([voltage, current, active_power, reactive_power, power_factor, total_energy])
# 每 100 条批写一次
if (i + 1) % 100 == 0:
tablet = Tablet(device_id, measurements, data_types,
values[-100:], timestamps[-100:])
session.insert_tablet(tablet)
print(f"已写入 {(i + 1)} 条")
# 4) 聚合查询:看平均/峰值
avg_query = f"""
SELECT AVG(active_power) AS avg_power,
MAX(active_power) AS peak_power,
MIN(power_factor) AS min_pf
FROM {device_id}
"""
result = session.execute_statement(avg_query)
while result.has_next():
print(result.next())
session.close()
print("done")常见问题与排查思路
服务启动但无法连接
端口冲突是最常见原因之一,需要依次确认服务进程是否真实存在、端口是否正常监听、启动日志中是否存在异常信息。
客户端连接失败
优先排查:
- 服务端是否正常运行
- 连接地址是否正确(容器与宿主机环境需特别注意)
- 网络或防火墙是否放行端口
写入性能不达预期
在工业场景中,批量写入是基本前提,如果写入性能达不到预期,常见原因包括:
- 使用逐条写入而非批量写入
- 批量大小过小
- 频繁创建和关闭 Session
查询结果为空
查询结果为空常见原因可能是时间戳单位混用(秒 / 毫秒)、路径拼写不一致、查询时间范围未覆盖实际数据,排查时建议先放宽条件验证。
总结
本文从工业物联网与设备测点型系统的实际需求出发,围绕时序数据库选型过程中最核心的几个问题,对 IoTDB 的使用体验进行了完整梳理。从选型关注点、单机模式快速验证,到批量写入、查询方式以及常见问题排查,重点放在"是否符合真实生产使用习惯"和"是否能够稳定跑通业务链路"。
在以设备、测点和时间序列为核心的数据场景中,IoTDB 在数据模型设计、批量写入机制以及时间窗口查询等方面与工业系统的契合度较高,能够覆盖大多数基础采集、监控与分析需求。通过先行跑通单机闭环,再逐步评估扩展与部署方式,可以有效降低选型和落地阶段的试错成本。
- IoTDB 官方下载 :https://iotdb.apache.org/zh/Download/
- 企业版官网(Timecho) :https://timecho.com
