Adaptive Model Pruning and Personalization for Federated Learning Over Wireless Networks
Adaptive Federated Pruning in Hierarchical Wireless Networks
这两篇文章都在探讨了在无线网络环境下,如何通过自适应模型剪枝(Adaptive Model Pruning)技术来优化联邦学习(FL)的性能。两篇文章都采用了剪枝技术和 Karush-Kuhn-Tucker (KKT) 条件进行资源优化。
Adaptive Model Pruning and Personalization for Federated Learning Over Wireless Networks
-
background:通信与计算瓶颈;数据异构(Non-IID)
-
模型:两层网络(设备-服务器)
-
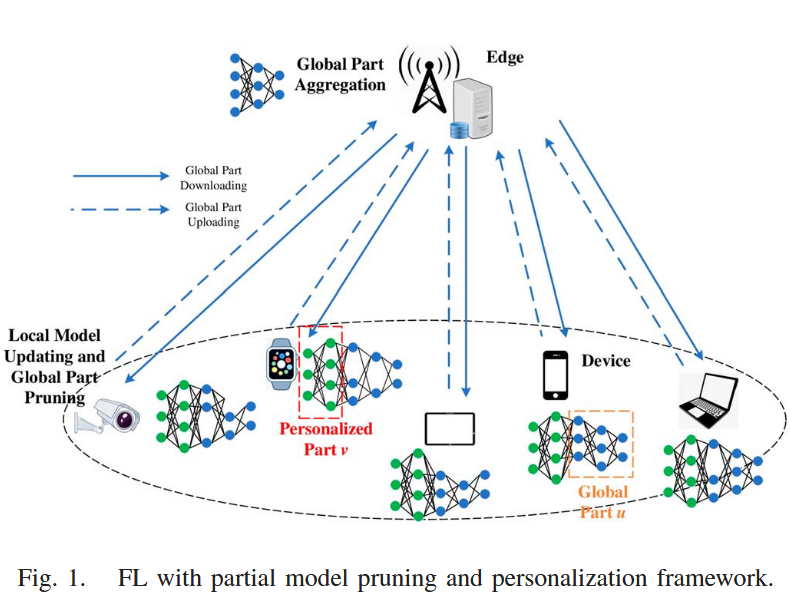
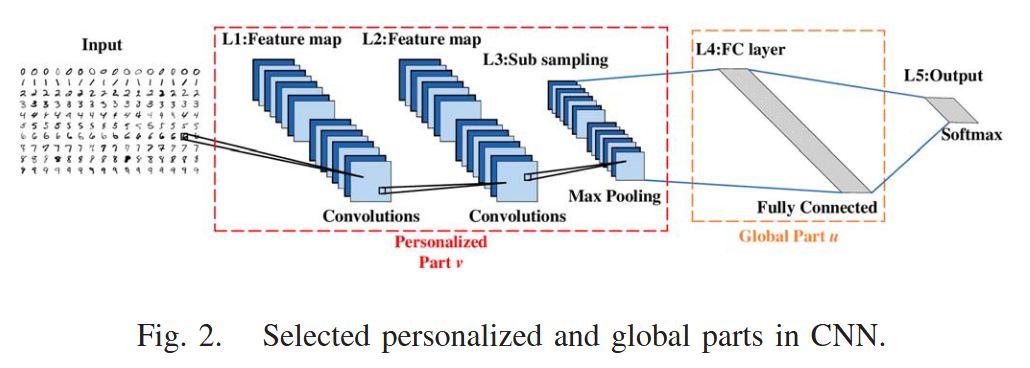
contribution:(1)模型拆分(Model Splitting):把模型拆分为全局部分和个性化部分。全局部分通常是模型的前几层(特征提取器),负责学习通用的数据表示。这部分在设备和服务器之间同步。个性化部分通常是模型的最后几层(分类器),负责适配本地特定任务。这部分永远留在本地,不参与上传和聚合;(2)部分剪枝(Partial Pruning):基于权值的量级对全局部分进行剪枝,剔除数值较小的参数;(3)自适应优化:系统可以根据当前的信道质量(CSI)和设备的实时剩余算力,瞬间计算出最合适的剪枝程度。(4)论文对该框架的收敛性进行了严格的数学证明,给出了梯度范数上界的理论保证。
-
接近底层为personalized part,接近顶层为global part。这一点的设定和我想的不太一样,大部分时候深度学习中还是认为靠近输入的是global特征,靠近输出的作为personalized part。不过有些研究认为,不同设备的原始数据输入(比如不同相机的滤镜、不同地区的口音)差异巨大,所以应该让最开始的几层个性化,而中间的逻辑部分全局共享。
-
看一下仿真图
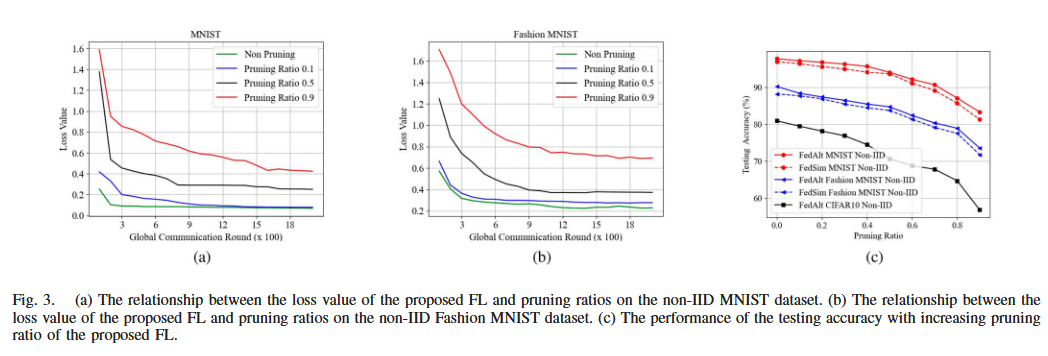
(a)(b) 损失随通信轮数变化:剪枝比越大,收敛越慢、最终损失越高
© 测试精度随剪枝比变化:单调下降,复杂数据更敏感;FedAlt 略优于 FedSim(FedAlt交替更新个性化部分与共享部分与 FedSim同时更新

Proposed FL:同时做 partial personalization + global part pruning,并且联合优化剪枝比与带宽分配;
Equal Resource Pruning:也做个性化+剪枝,但带宽平均分给所有设备(因此不最优);
Partial Personalization in 16:只个性化、不剪枝,因此需要上传完整 global part
Partial Pruning in 25:只剪枝、不个性化(剪枝主要在全连接层),并上传剪枝后的模型
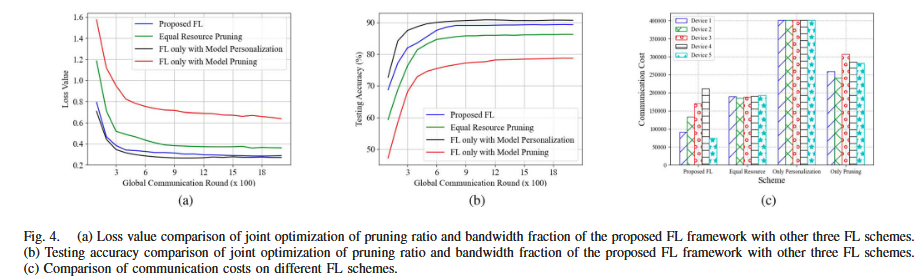
Proposed FL 的loss 更低、accuracy 更高,至少优于 Equal Resource Pruning 与 FL only with model pruning。同时,Proposed FL 的学习性能与仅做部分个性化的方案非常接近。这意味着:个性化带来对数据异质性的适配,而剪枝+带宽联合分配在不显著牺牲精度的前提下,改善了时延/通信负担。
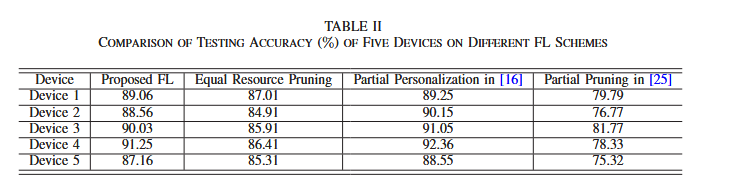
Proposed FL 接近个性化最优、显著优于剪枝类基线
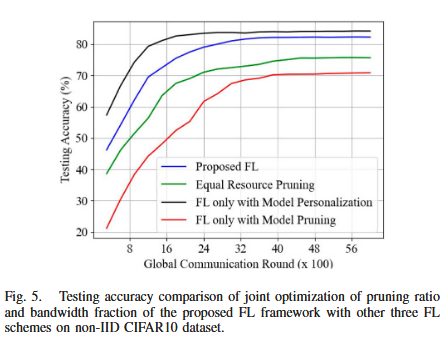
用 AlexNet 与 non-IID CIFAR10 进一步验证鲁棒性,并指出 Fig.5 中 Proposed FL 的性能接近仅个性化,且优于均分资源剪枝与仅剪枝。这说明联合优化策略并非仅对简单模型/数据分布有效,而是对更复杂网络与更强 non-IID 场景仍具稳定收益。
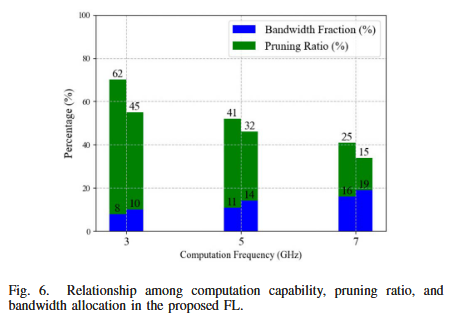
在相同算力下,若分配到更多带宽,将选择更小剪枝比以保证更快收敛与更高精度;对于算力更强的设备,系统倾向于分配更多带宽并选择更小剪枝比,以同时满足时延约束并提升收敛速度。
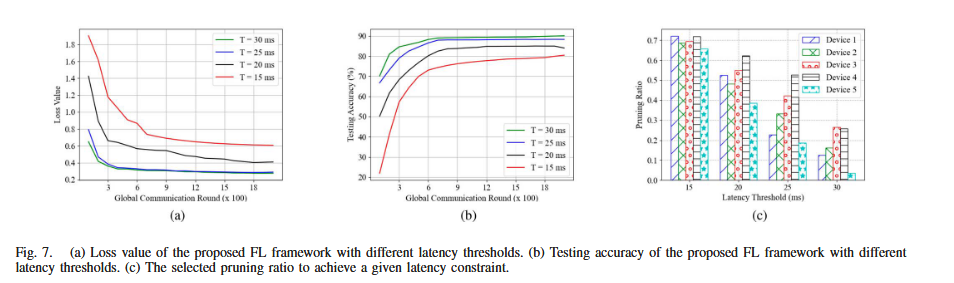
(a) Loss 曲线:时延门限越严格,收敛越慢、稳态 loss 越高(提高剪枝比会在每轮引入更大误差,从而不利于收敛)
(b) Accuracy 曲线:时延门限越严格,测试精度上限越低
© 剪枝比选择:门限越小 ⇒ 被迫选择更大的剪枝比;并且呈现设备差异
- 我主要看一下文章的思路和方法,理论证明部分在此忽略。