【声明】本博客所有内容均为个人业余时间创作,所述技术案例均来自公开开源项目(如Github,Apache基金会),不涉及任何企业机密或未公开技术,如有侵权请联系删除
背景
上篇 blog
【Ubuntu】【Hugo】搭建私人博客:元信息&翻译(三)
分析完了 translation_list.html 剩余内容,并接着分析了 search.html,接下来继续分析
搭建私人博客
接着分析 <input> 输入框内容

aria-label="search":无障碍访问,告诉屏幕阅读器这是搜索框 ,屏幕阅读器是视障人士(比如盲人)用的软件,它会把网页内容用语音方式读出来给他们听,而aria-label就是直接给元素起个语音名字,让盲人或视障用户通过读屏软件知道这里是个搜索框,可以提升网站的无障碍访问能力,这里 ARIA 全称 Accessible Rich Internet Applications,这个 HTML 属性专门用来增强网页对辅助技术的友好度type="search":告诉浏览器,这是个搜索框类型,这样浏览器可以提供更好的移动端支持,并且语义更清晰, 对人,对机器都友好,可以让站点更专业,更好用autocomplete="off":禁用浏览器自动填充历史,避免干扰搜索建议maxlength="64":限制最多输入 64 个字符
OK,下面是 <searchResults>

可以看到,这是一个空的无序列表 <ul>,初始时没有内容,当用户在 <input> 中输入关键词时,JavaScript 脚本会动态生成 <li> 列表项插入到这里,显示匹配的搜索结果(一般是文章标题),这里的 aria-label 同样是为了无障碍支持
OK,搜索页面的整体布局就已经分析完了,下面先来看一下其效果
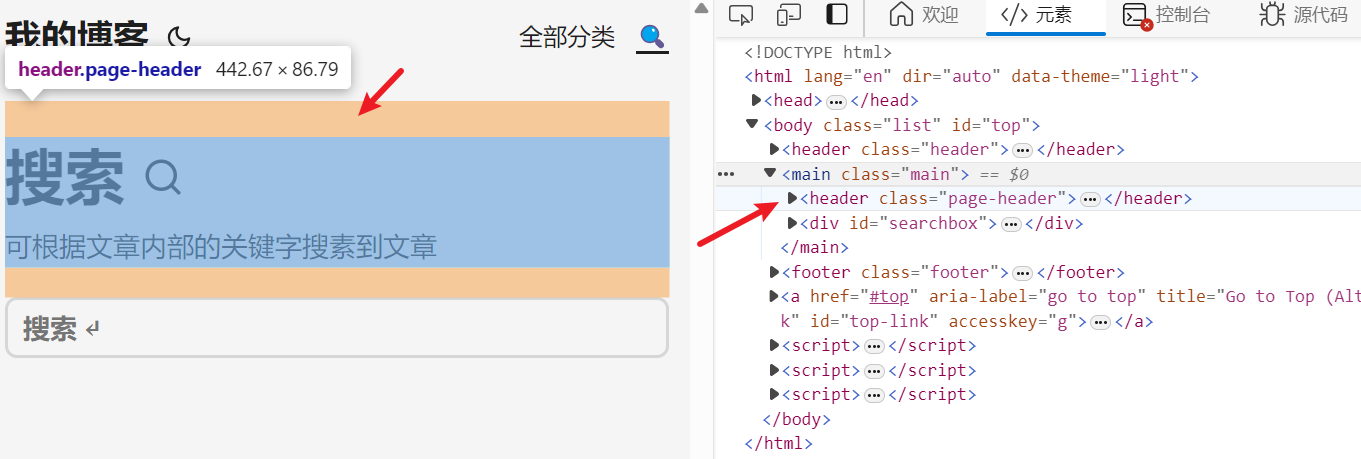
<header>布局如下
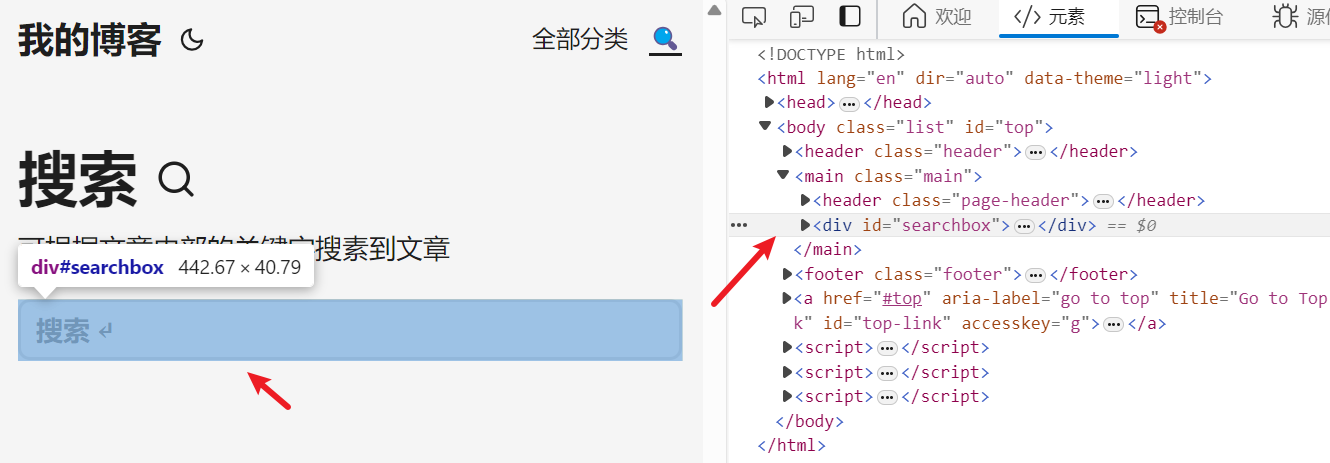
<searchbox>布局如下
OK,介绍完搜索页面的布局,下面来看搜索功能的实现,Hugo PaperMod 的搜索实现在 assets/js/fastsearch.js
注意,这里的 fastsearch.js 是一个纯前端搜索脚本,运行在用户浏览器中,不涉及任何服务器/后端逻辑,其整个搜索功能完全可以离线使用,非常适合 Hugo 这样的纯静态托管站点
初始化变量
下面来看其详细实现,首先是第一部分:初始化变量
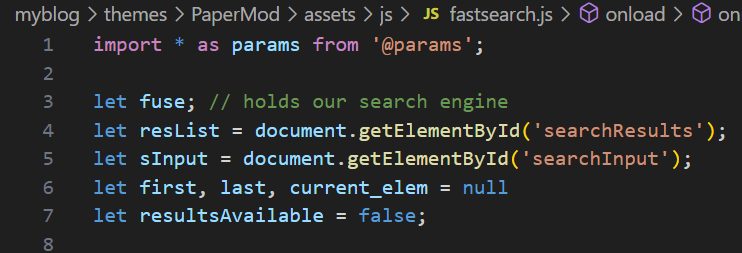
import * as params...:从 Hugo 构建系统导入配置参数fuse:使用的模糊搜索方法,这个变量用来存搜索引擎,fuse 实例,引擎实现就是下面的fuse.basic.min.js
resList = ...('searchResults'):这里就是上面布局介绍的搜索结果下拉列表<ul>sInput=...('searchInput'):同样是上面介绍的搜索输入框<input>first,last,current_elem:用于键盘导航resultsAvailable:标志位,用来标记是否有搜索结果
这些都是全局变量,后面会用到
加载搜索数据
OK,下面来看第二部分:加载搜索数据
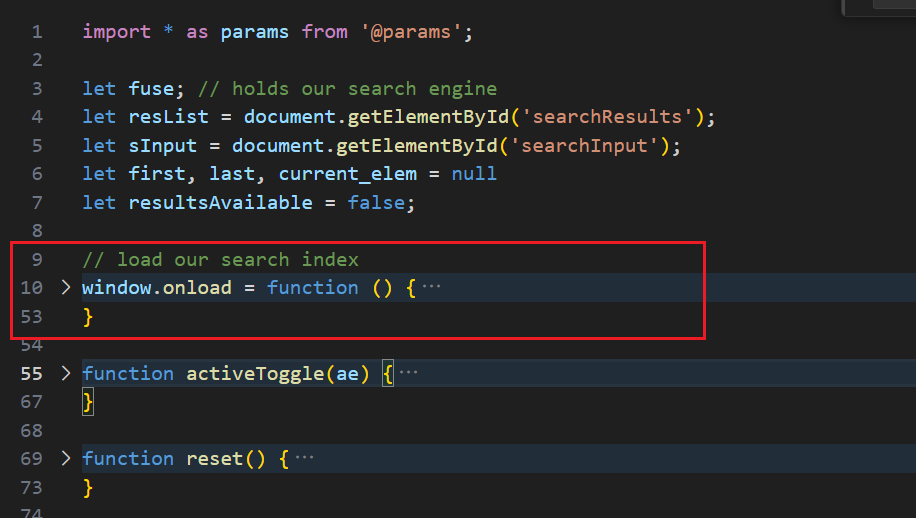
第二部分这里是整个前端搜索功能的核心初始化部分,负责在页面加载完成后,执行下面几个关键步骤:
- 从远端服务器获取搜索索引数据,这里是索引数据是
index.json(后面介绍) - 用
fuse.basic.min.js构建一个模糊搜索引擎 - 可以通过配置(比如 Hugo 配置文件的
hugo.toml的params)来自定义搜索行为
以确保在页面完全加载后,可以异步加载搜索所需的全文索引数据
注意,这里的 window.onload 指的是用户浏览器中当前网页加载完成,也就是搜索页面在用户浏览器中加载完成 ,举个例子(不是搜索页面的)
- 用户在浏览器地址栏输入某篇文章的地址,比如
https://myblog.com/posts/article并回车后 - 浏览器开始下载
article/index.html,并解析 HTML 内容,加载 CSS,图片,JS 等资源 - 当所有资源(包括图片,脚本)都加载完毕后,浏览器触发
window.onload事件,这是用户实际看到页面的时刻,此时 JavaScript 脚本开始运行
这个动作是在用户访问某篇文章页面时,由用户的浏览器执行的
OK,本篇先到这里,如有疑问,欢迎评论区留言讨论,祝各位功力大涨,技术更上一层楼!!!更多内容见下篇 blog
【Ubuntu】【Hugo】搭建私人博客:搜索功能(AJAX请求)