原理:
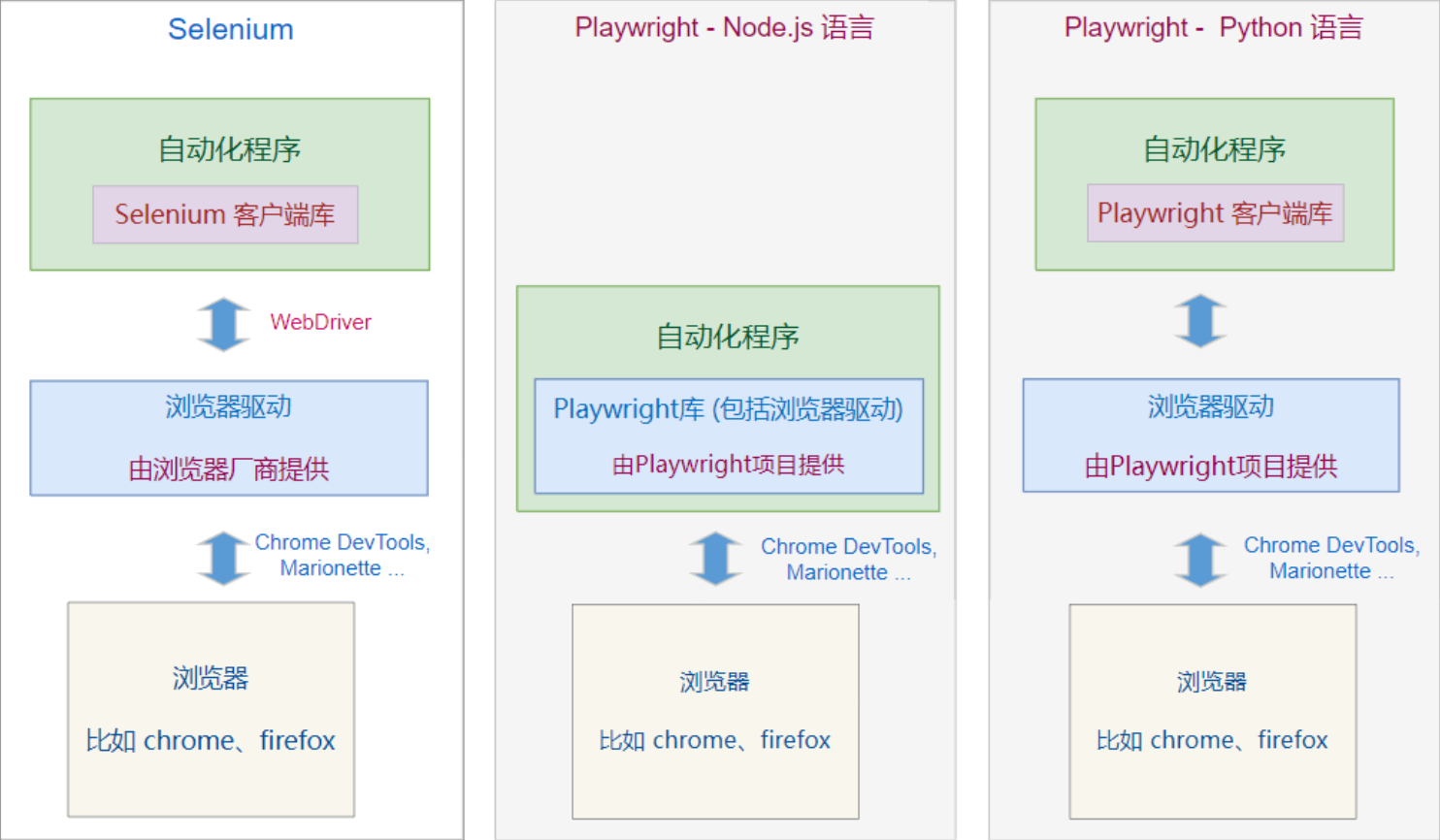
Playwright 是微软开发的 Web应用 的 自动化测试框架 。
它和另外一个 web自动化框架 Selenium 有 什么区别呢?
区别一:
Selenium 只提供了 Web 自动化功能, 如果你要做自动化测试,需要结合其它自动化测试框架
而 Playwright 是面向自动化测试的,除了Web自动化功能,它也包含了自动化测试的功能框架;
安装过程跳过,直接进入基础代码
我这里使用的环境是vscode的虚拟环境、python3.14.2
基础代码:
导入playwright库:
python
from playwright.sync_api import sync_playwright.start()会返回一个playwright进程
python
# 启动 playwright driver 进程
p = sync_playwright().start()
python
# 启动浏览器,返回 Browser 类型对象
browser = p.chromium.launch(headless=False)headless=False 取消无头模式,该模式下我们可以直接看到程序打开的浏览器
headless=True 开启无头模式,我们程序打开的浏览器被隐藏
python
# 创建新页面,返回 Page 类型对象
page = browser.new_page()
page.goto("https://www.byhy.net/cdn2/files/selenium/stock1.html")
print(page.title()) # 打印网页标题栏page用来接收新页面的参数,可以通过page来对新页面进行操作
python
# 输入通讯,点击查询。这是定位与操作,是自动化重点,后文详细讲解
page.locator('#kw').fill('通讯') # 输入通讯
page.locator('#go').click() # 点击查询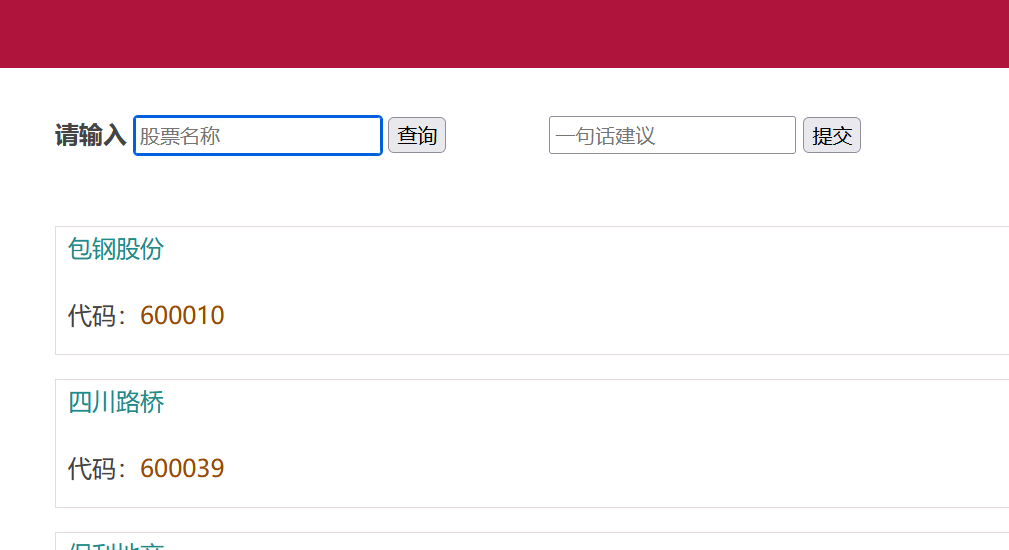
.locator() 定位到#kw搜索框,fill() 输入通讯
python
# 打印所有搜索内容
lcs = page.locator(".result-item").all()
for lc in lcs:
print(lc.inner_text())
python
# 关闭浏览器
browser.close()
python
# 关闭 playwright driver 进程
p.stop()完整代码和结果:
python
from playwright.sync_api import sync_playwright
input('1....')
# 启动 playwright driver 进程
p = sync_playwright().start()
input('2....')
# 启动浏览器,返回 Browser 类型对象
browser = p.chromium.launch(headless=False)
# 创建新页面,返回 Page 类型对象
page = browser.new_page()
page.goto("https://www.byhy.net/cdn2/files/selenium/stock1.html")
print(page.title()) # 打印网页标题栏
# 输入通讯,点击查询。这是定位与操作,是自动化重点,后文详细讲解
page.locator('#kw').fill('通讯') # 输入通讯
page.locator('#go').click() # 点击查询
# 打印所有搜索内容
lcs = page.locator(".result-item").all()
for lc in lcs:
print(lc.inner_text())
input('3....')
# 关闭浏览器
browser.close()
input('4....')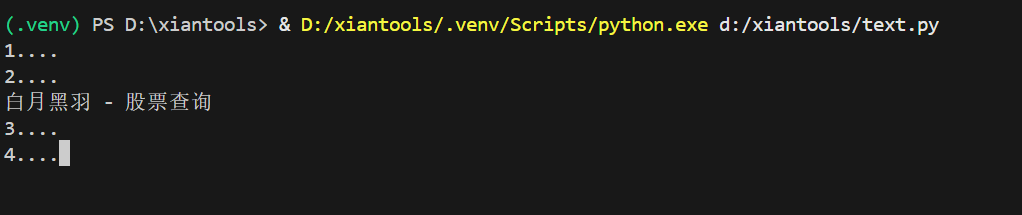
以上代码没有正确输出打印的结果,是因为程序来不及加载信息,我们需要给程序几秒等待的时间
界面等待:
python
page.wait_for_timeout(2000)加入等待时间后就正常打印出抓取的信息了:
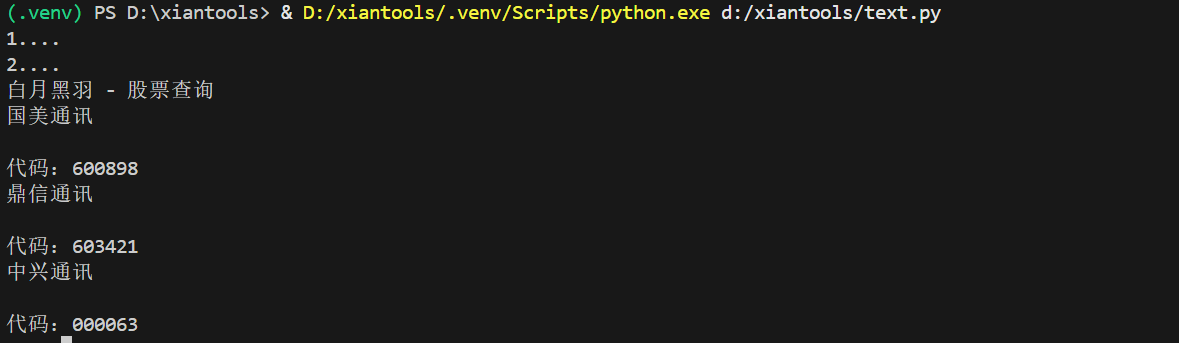
自动化代码助手:
该助手主要记录我们对浏览器的操作,定位、文本框输入、输入网站等...
不能过彻底代替我们实现我们想要的功能,例如:无法完成数据的抓取
python
# 运行代码
playwright codegen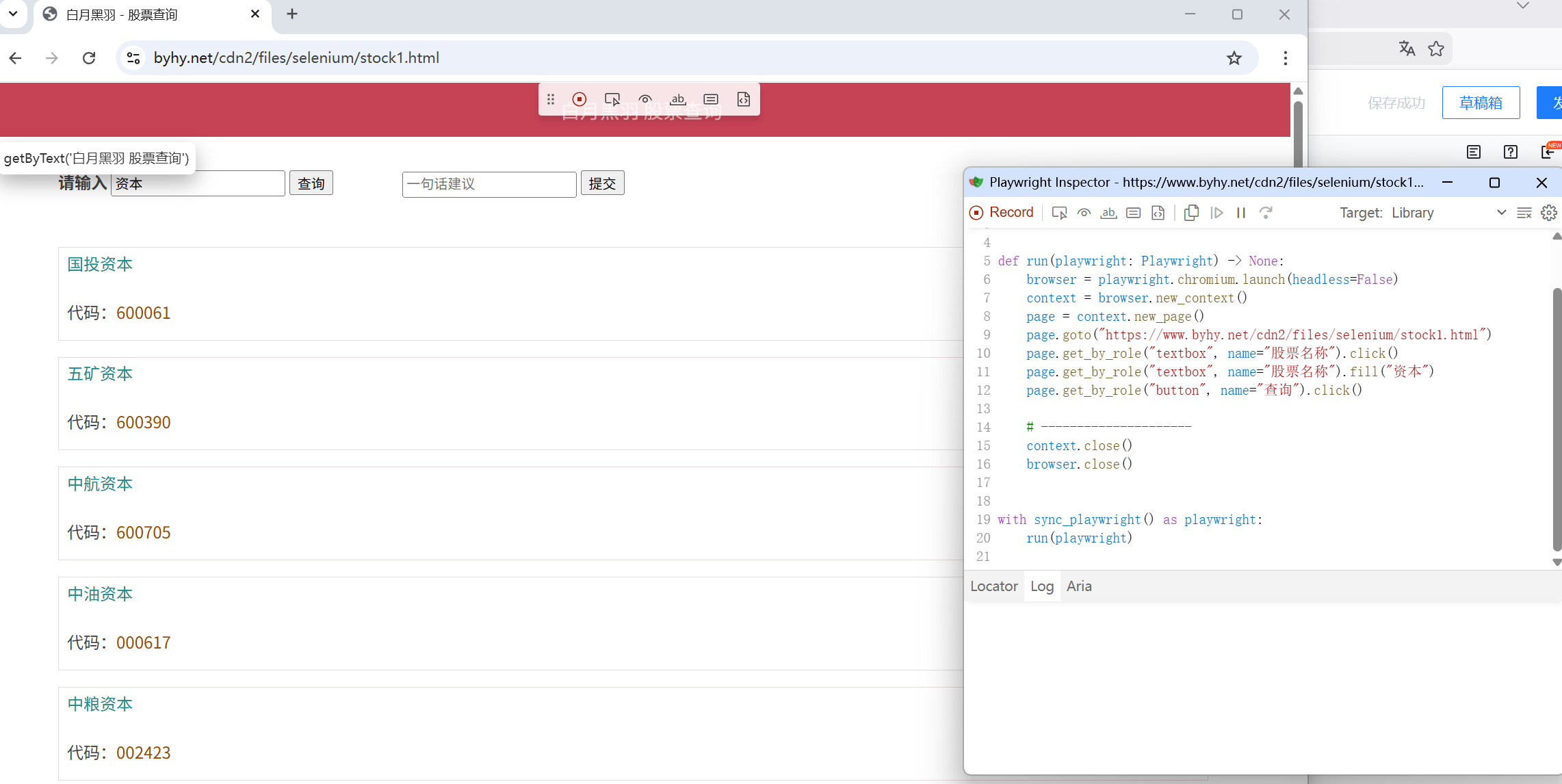
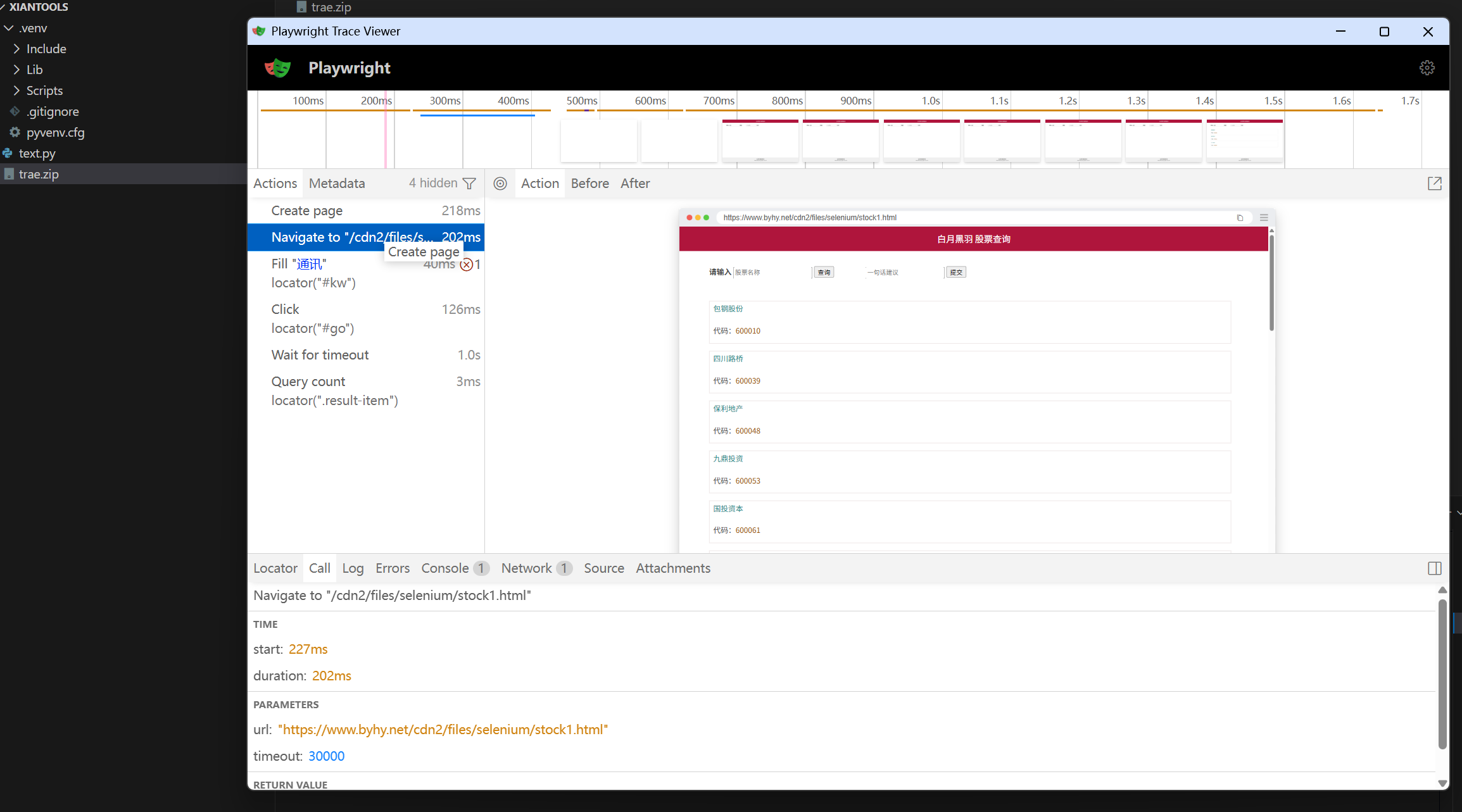
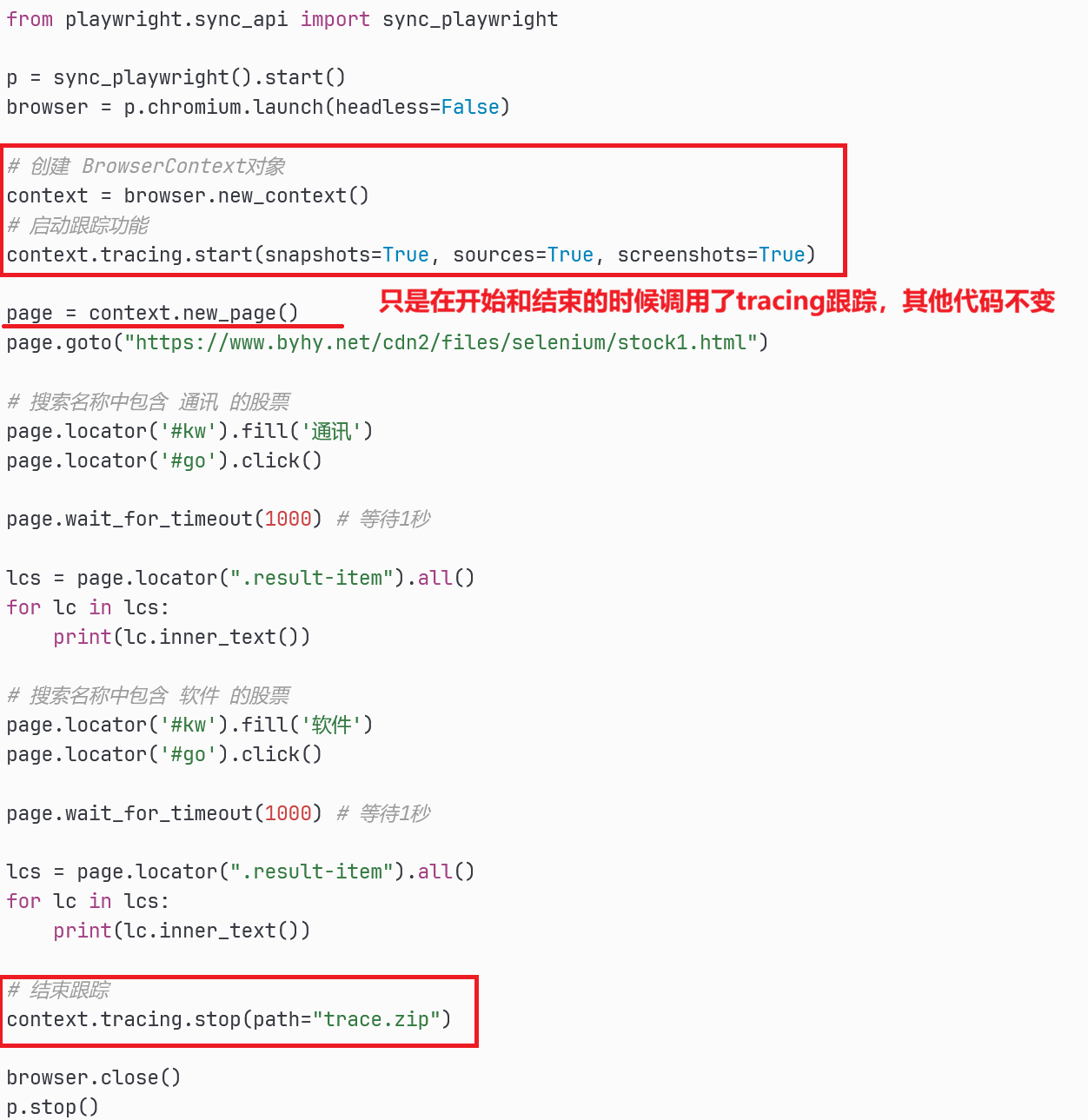
跟踪功能🏷️
Playwright 有个特色功能: 跟踪(tracing)
启用跟踪功能后, 可以在执行自动化后,通过记录的跟踪数据文件, 回看自动化过程中的每个细节。
下面的的代码进行了自动化搜索股票,并打开跟踪功能,保存 跟踪数据文件 为 trace.zip
执行完以后,我们发现,当前工作目录下面多了 trace.zip 这个跟踪数据文件。
怎么查看这个跟踪文件呢?有2种方法:
-
直接访问 trace.playwright.dev 这个网站,上传 跟踪文件
-
执行命令
playwright show-trace trace.zip -