文章目录
特别提醒:唯一需要改动的地方为代码中的api_key,可前往deepseek开放平台获取------ 点击前往
项目介绍
这是一个基于LangGraph框架构建的智能数据分析与可视化系统,它通过多节点自动化工作流实现从原始数据到洞察报告的全流程智能处理,将传统数据分析转化为动态、自适应的AI驱动流程。
该系统采用有向图结构编排数据分析流程,依次执行数据读取与元分析、动态图表生成、报告撰写三个核心节点。其创新性在于动态代码生成能力------系统能根据数据特征自动生成并执行可视化代码,突破固定模板限制,实现真正意义上的自适应分析。最终生成包含图表嵌入的专业分析报告,形成覆盖数据概览、洞察挖掘到结论建议的完整分析闭环。
该项目体现了智能体(Agent)技术在数据分析领域的先进实践,通过LangGraph的流程控制能力,显著提升了数据探索的自动化水平和洞察效率。
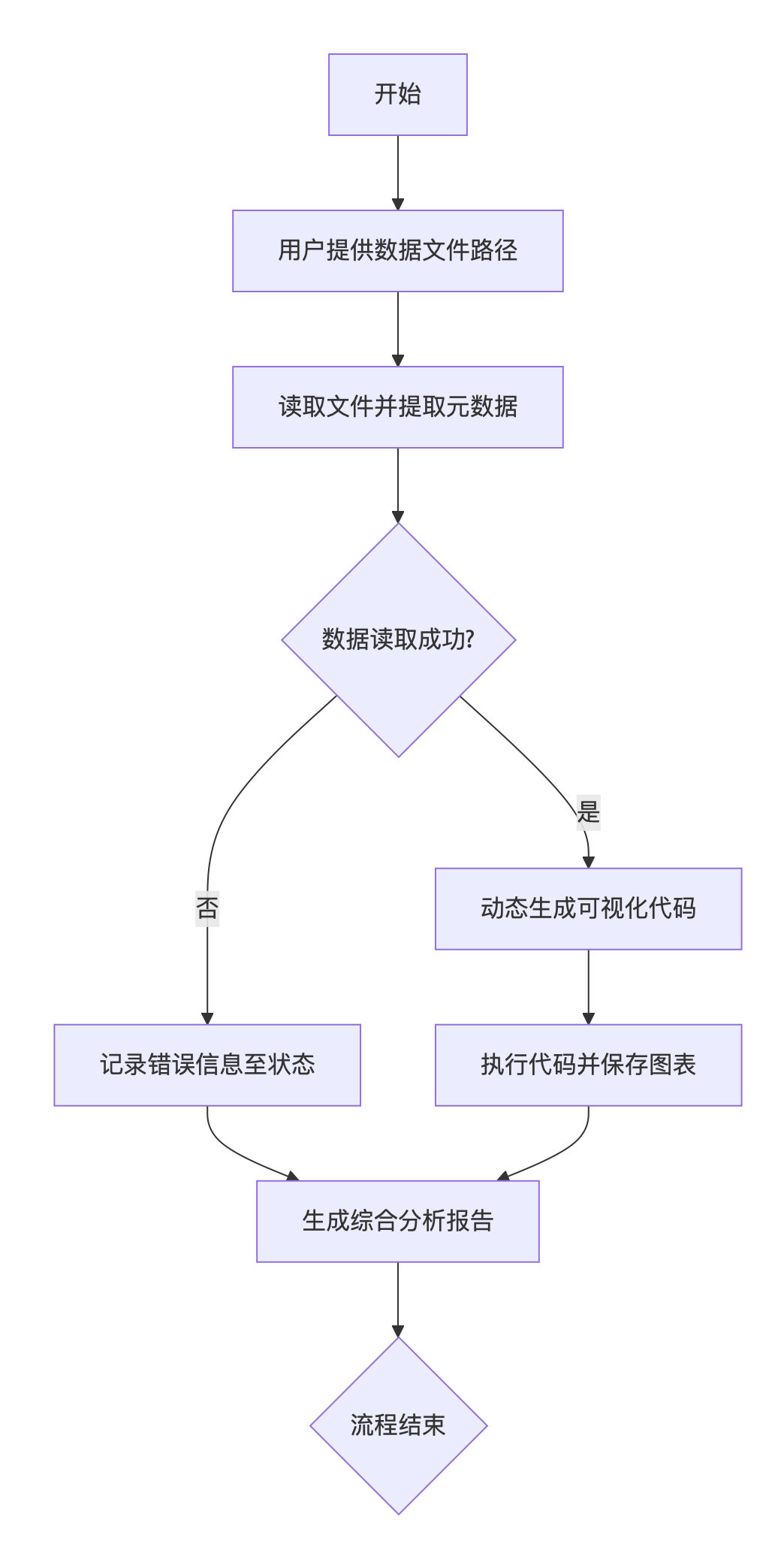
完整代码
data_analysty.py
python
import os
import pandas as pd
import re
from typing import TypedDict, List, Optional
from langgraph.graph import StateGraph, END
from langchain_core.messages import HumanMessage, SystemMessage
from langchain.chat_models import init_chat_model
import matplotlib.pyplot as plt
# 定义状态
class AgentState(TypedDict):
file_path: str
data_summary: str
column_info: str
chart_paths: List[str]
generated_code: str
report: str
error: Optional[str]
# 初始化 LLM
os.environ["DEEPSEEK_API_KEY"] = "换为自己的api_key"
llm = init_chat_model(model='deepseek-chat', model_provider="deepseek")
# 1. 阅读文件内容节点
def read_file_node(state: AgentState):
print("--- 节点 1: 正在读取文件并提取元数据 ---")
file_path = state['file_path']
try:
df = pd.read_csv(file_path)
# 提取列信息和数据类型
col_info = []
for col in df.columns:
col_info.append(f"- {col}: {df[col].dtype} (唯一值数量: {df[col].nunique()})")
summary = f"数据集包含 {len(df)} 行和 {len(df.columns)} 列。\n"
summary += f"数据预览:\n{df.head(3).to_string()}\n"
summary += f"统计摘要:\n{df.describe().to_string()}"
return {
"data_summary": summary,
"column_info": "\n".join(col_info)
}
except Exception as e:
return {"error": f"读取文件失败: {str(e)}"}
# 2. 动态生成绘图代码并执行节点
def dynamic_chart_node(state: AgentState):
print("--- 节点 2: 正在动态生成并执行绘图代码 ---")
if state.get('error'):
return state
summary = state['data_summary']
col_info = state['column_info']
file_path = state['file_path']
prompt = f"""
你是一个高级数据可视化专家。请根据以下数据信息,编写一段 Python 代码来生成 1-2 张最能反映数据特征的图表。
文件路径: '{file_path}' (请直接使用 pd.read_csv('{file_path}') 读取)
数据摘要:
{summary}
列详细信息:
{col_info}
代码要求:
1. 使用 matplotlib 或 seaborn 绘图。
2. 必须将图表保存为文件,文件名请使用 'dynamic_chart_1.png' (如果有第二张,使用 'dynamic_chart_2.png')。
3. 代码中不要包含 plt.show(),只需保存。
4. 确保代码健壮,处理可能的缺失值。
5. 只输出纯 Python 代码,不要包含 Markdown 代码块标记。
"""
messages = [
SystemMessage(content="你是一个只输出 Python 代码的专家。不要解释,不要使用 Markdown 格式。"),
HumanMessage(content=prompt)
]
response = llm.invoke(messages)
code = response.content.strip()
# 清理可能存在的 markdown 标记
code = re.sub(r'^```python\n|^```\n|```$', '', code, flags=re.MULTILINE)
print(f"生成的代码预览:\n{code[:200]}...")
chart_paths = []
try:
# 执行生成的代码
local_vars = {}
exec(code, globals(), local_vars)
# 检查生成的文件
if os.path.exists("../../agent/data_graph_agent/dynamic_chart_1.png"):
chart_paths.append("dynamic_chart_1.png")
if os.path.exists("../../agent/data_graph_agent/dynamic_chart_2.png"):
chart_paths.append("dynamic_chart_2.png")
return {"generated_code": code, "chart_paths": chart_paths}
except Exception as e:
return {"error": f"执行生成的绘图代码失败: {str(e)}\n代码内容:\n{code}"}
# 3. 撰写报告节点
def write_report_node(state: AgentState):
print("--- 节点 3: 正在撰写数据分析报告 ---")
if state.get('error'):
return state
summary = state['data_summary']
charts = state['chart_paths']
code = state['generated_code']
prompt = f"""
你是一个专业的数据分析师。请根据以下数据摘要和生成的图表编写一份深度分析报告。
数据摘要:
{summary}
生成的图表文件: {', '.join(charts)}
绘图逻辑参考代码:
{code}
报告要求:
1. 包含数据概览。
2. 解释为什么选择生成这些图表,以及图表反映了什么业务洞察。
3. 在报告中合适的位置引用图表(使用 Markdown 语法 )。
4. 提供基于数据的结论或建议。
5. 使用中文撰写,保持专业性。
"""
messages = [
SystemMessage(content="你是一个专业的数据分析助手。"),
HumanMessage(content=prompt)
]
response = llm.invoke(messages)
return {"report": response.content}
# 构建工作流
workflow = StateGraph(AgentState)
# 添加节点
workflow.add_node("read_file", read_file_node)
workflow.add_node("dynamic_chart", dynamic_chart_node)
workflow.add_node("write_report", write_report_node)
# 设置入口点
workflow.set_entry_point("read_file")
# 添加边
workflow.add_edge("read_file", "dynamic_chart")
workflow.add_edge("dynamic_chart", "write_report")
workflow.add_edge("write_report", END)
# 编译
app = workflow.compile()
# 运行示例
if __name__ == "__main__":
# 确保有测试数据
test_file = "scores.csv"
if not os.path.exists(test_file):
df_test = pd.DataFrame({
'Month': ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun'],
'Sales': [100, 120, 150, 130, 170, 200],
'Profit': [20, 25, 40, 30, 50, 70]
})
df_test.to_csv(test_file, index=False)
inputs = {"file_path": test_file, "chart_paths": []}
print("开始执行 LangGraph 工作流...")
final_result = app.invoke(inputs)
if final_result.get('report'):
with open("../../agent/data_graph_agent/dynamic_analysis_report.md", "w", encoding="utf-8") as f:
f.write(final_result['report'])
print("\n报告已生成: dynamic_analysis_report.md")
print(f"生成的图表: {', '.join(final_result['chart_paths'])}")
if final_result.get('error'):
print(f"\n发生错误: {final_result['error']}")代码解释
导入模块
- os:提供与操作系统交互的功能,如文件路径操作、环境变量管理。
- re:用于正则表达式操作,支持字符串匹配、搜索和替换等复杂文本处理。
- typing:引入类型注解(如TypedDict, List, Optional),提升代码的可读性和健壮性,方便静态类型检查。
- pandas:是核心的数据处理库,以其高效的DataFrame和Series数据结构著称,支持从多种数据源进行数据清洗、分析和转换等操作。
- langgraph相关组件(StateGraph, END):用于构建基于状态的有向图或工作流,特别适用于创建多步骤的AI代理或复杂的决策流程。
- langchain_core.messages(HumanMessage, SystemMessage):提供了表示对话中不同角色消息(如用户消息、系统消息)的类,是构建对话系统的基石。
- langchain.chat_models(init_chat_model):用于初始化和配置聊天模型(例如大型语言模型),是与AI模型交互的核心工具。
- matplotlib.pyplot:是常用的数据可视化库,用于将数据处理或分析结果生成各种类型的图表和图形。
python
import os
import pandas as pd
import re
from typing import TypedDict, List, Optional
from langgraph.graph import StateGraph, END
from langchain_core.messages import HumanMessage, SystemMessage
from langchain.chat_models import init_chat_model
import matplotlib.pyplot as plt定义状态数据结构
这是LangGraph智能体工作流设计的核心状态类,它定义了数据分析任务在整个自动化流程中流转的记忆。
这个TypedDict类清晰地规划了工作流中七个关键状态字段:
- file_path 记录了原始数据文件的路径,是流程的起点
- data_summary 和 column_info 存储了从数据中提取的概要和元数据
- generated_code 保存了AI动态生成的图表代码
- chart_paths 记录了由代码执行产生的可视化文件
- report 包含了最终生成的分析报告
- error 作为可选字段,专门用于捕获和传递流程中可能出现的错误信息
python
# 定义状态
class AgentState(TypedDict):
file_path: str
data_summary: str
column_info: str
chart_paths: List[str]
generated_code: str
report: str
error: Optional[str]初始化LLM
这段代码是配置大语言模型,记得更换自己的api_key
python
# 初始化 LLM
os.environ["DEEPSEEK_API_KEY"] = "换成自己的api_key"
llm = init_chat_model(model='deepseek-chat', model_provider="deepseek")文件读取节点
这是一个数据分析工作流的入口节点,负责读取原始数据文件并进行初步探索性分析,为后续的数据处理和可视化提供基础。
该节点的核心功能是数据加载与元数据提取。它接收一个包含文件路径的状态字典,使用Pandas库读取CSV文件,并智能地生成两份关键信息:
数据概览:包括数据集规模(行数和列数)、数据预览和统计摘要,让使用者能快速把握数据全貌。
列详细信息:为每一列记录其数据类型和唯一值数量,这对于后续判断合适的分析方法和可视化图表至关重要。
python
# 1. 阅读文件内容节点
def read_file_node(state: AgentState):
print("--- 节点 1: 正在读取文件并提取元数据 ---")
file_path = state['file_path']
try:
df = pd.read_csv(file_path)
# 提取列信息和数据类型
col_info = []
for col in df.columns:
col_info.append(f"- {col}: {df[col].dtype} (唯一值数量: {df[col].nunique()})")
summary = f"数据集包含 {len(df)} 行和 {len(df.columns)} 列。\n"
summary += f"数据预览:\n{df.head(3).to_string()}\n"
summary += f"统计摘要:\n{df.describe().to_string()}"
return {
"data_summary": summary,
"column_info": "\n".join(col_info)
}
except Exception as e:
return {"error": f"读取文件失败: {str(e)}"}动态图表生成节点
这是一个基于大语言模型的动态图表代码生成与执行节点,它通过智能分析数据特征自动生成可视化代码,实现了从数据到图表的全自动化转换。该节点首先利用包含数据摘要和列详细信息的精心设计的提示词,引导LLM扮演数据可视化专家角色,生成符合规范(使用Matplotlib/Seaborn、包含错误处理、直接保存图表文件)的Python代码;接着对LLM输出进行清理以去除可能的Markdown标记,最后通过exec()函数在隔离环境中动态执行生成的代码,并验证图表文件是否成功生成,从而将传统的静态图表制作流程升级为智能化的按需生成模式。
python
# 2. 动态生成绘图代码并执行节点
def dynamic_chart_node(state: AgentState):
print("--- 节点 2: 正在动态生成并执行绘图代码 ---")
if state.get('error'):
return state
summary = state['data_summary']
col_info = state['column_info']
file_path = state['file_path']
prompt = f"""
你是一个高级数据可视化专家。请根据以下数据信息,编写一段 Python 代码来生成 1-2 张最能反映数据特征的图表。
文件路径: '{file_path}' (请直接使用 pd.read_csv('{file_path}') 读取)
数据摘要:
{summary}
列详细信息:
{col_info}
代码要求:
1. 使用 matplotlib 或 seaborn 绘图。
2. 必须将图表保存为文件,文件名请使用 'dynamic_chart_1.png' (如果有第二张,使用 'dynamic_chart_2.png')。
3. 代码中不要包含 plt.show(),只需保存。
4. 确保代码健壮,处理可能的缺失值。
5. 只输出纯 Python 代码,不要包含 Markdown 代码块标记。
"""
messages = [
SystemMessage(content="你是一个只输出 Python 代码的专家。不要解释,不要使用 Markdown 格式。"),
HumanMessage(content=prompt)
]
response = llm.invoke(messages)
code = response.content.strip()
# 清理可能存在的 markdown 标记
code = re.sub(r'^```python\n|^```\n|```$', '', code, flags=re.MULTILINE)
print(f"生成的代码预览:\n{code[:200]}...")
chart_paths = []
try:
# 执行生成的代码
local_vars = {}
exec(code, globals(), local_vars)
# 检查生成的文件
if os.path.exists("../../agent/data_graph_agent/dynamic_chart_1.png"):
chart_paths.append("dynamic_chart_1.png")
if os.path.exists("../../agent/data_graph_agent/dynamic_chart_2.png"):
chart_paths.append("dynamic_chart_2.png")
return {"generated_code": code, "chart_paths": chart_paths}
except Exception as e:
return {"error": f"执行生成的绘图代码失败: {str(e)}\n代码内容:\n{code}"}报告攥写节点
这是一个基于大语言模型的自动化报告生成节点,它在数据分析工作流中扮演最终输出角色,能够智能整合数据摘要、可视化图表和绘图逻辑代码,生成包含数据概览、图表解读、业务洞察和可行性建议的完整中文分析报告
python
# 3. 撰写报告节点
def write_report_node(state: AgentState):
print("--- 节点 3: 正在撰写数据分析报告 ---")
if state.get('error'):
return state
summary = state['data_summary']
charts = state['chart_paths']
code = state['generated_code']
prompt = f"""
你是一个专业的数据分析师。请根据以下数据摘要和生成的图表编写一份深度分析报告。
数据摘要:
{summary}
生成的图表文件: {', '.join(charts)}
绘图逻辑参考代码:
{code}
报告要求:
1. 包含数据概览。
2. 解释为什么选择生成这些图表,以及图表反映了什么业务洞察。
3. 在报告中合适的位置引用图表(使用 Markdown 语法 )。
4. 提供基于数据的结论或建议。
5. 使用中文撰写,保持专业性。
"""
messages = [
SystemMessage(content="你是一个专业的数据分析助手。"),
HumanMessage(content=prompt)
]
response = llm.invoke(messages)
return {"report": response.content}工作流构建
这段代码使用 LangGraph 的 StateGraph构建了一个顺序执行的数据分析工作流,通过定义三个功能节点(读取文件、动态生成图表、撰写报告)并设置线性的边连接,将整个分析流程编排为一个从数据输入到报告输出的自动化管道,最后通过 compile()方法将其编译为可执行的应用实例 。
python
# 构建工作流
workflow = StateGraph(AgentState)
# 添加节点
workflow.add_node("read_file", read_file_node)
workflow.add_node("dynamic_chart", dynamic_chart_node)
workflow.add_node("write_report", write_report_node)
# 设置入口点
workflow.set_entry_point("read_file")
# 添加边
workflow.add_edge("read_file", "dynamic_chart")
workflow.add_edge("dynamic_chart", "write_report")
workflow.add_edge("write_report", END)
# 编译
app = workflow.compile()主程序入口
这段代码是数据分析智能体的主程序执行模块,它首先创建或验证测试数据集,然后调用编译好的LangGraph工作流实例,传入初始状态触发整个自动化分析流程的执行,最终将生成的分析报告保存为Markdown文档并输出结果摘要。
python
# 运行示例
if __name__ == "__main__":
# 确保有测试数据
test_file = "scores.csv"
if not os.path.exists(test_file):
df_test = pd.DataFrame({
'Month': ['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun'],
'Sales': [100, 120, 150, 130, 170, 200],
'Profit': [20, 25, 40, 30, 50, 70]
})
df_test.to_csv(test_file, index=False)
inputs = {"file_path": test_file, "chart_paths": []}
print("开始执行 LangGraph 工作流...")
final_result = app.invoke(inputs)
if final_result.get('report'):
with open("../../agent/data_graph_agent/dynamic_analysis_report.md", "w", encoding="utf-8") as f:
f.write(final_result['report'])
print("\n报告已生成: dynamic_analysis_report.md")
print(f"生成的图表: {', '.join(final_result['chart_paths'])}")
if final_result.get('error'):
print(f"\n发生错误: {final_result['error']}")