在 C 语言编程中,我们每天都在编写.c源代码文件,然后通过编译器执行一系列命令,最终得到可以运行的程序。但你是否好奇过,一行行人类可读的代码,究竟是如何被计算机识别并执行的?这背后离不开 "翻译环境" 和 "运行环境" 的协同工作,其中编译和链接更是核心环节。今天,我们就来一步步拆解这个过程,揭开从源代码到可执行程序的神秘面纱。
一、先明确两个核心环境
ANSI C 标准规定,C 语言的实现必然包含两个关键环境,它们共同支撑着程序从 "编写" 到 "运行" 的全流程:
- 翻译环境 :核心任务是将我们编写的源代码(
.c文件)转换为计算机能直接执行的机器指令(二进制指令)。这个过程就是我们常说的 "编译 + 链接"。 - 运行环境:当翻译环境生成可执行程序后,运行环境负责实际执行这些程序,完成具体的功能逻辑。
二、翻译环境:编译 + 链接的完整流程
翻译环境的工作可拆解为 "编译" 和 "链接" 两大步骤,而编译又进一步分为预处理、编译、汇编三个阶段。一个多文件的 C 项目,最终能生成可执行程序,正是依赖这一系列流程的协作。
(一)编译的三个阶段:从.c到.o(目标文件)
编译的核心是将源代码逐步处理为机器指令的 "半成品"------ 目标文件(Windows 下后缀为.obj,Linux 下为.o)。每个.c文件会单独经过编译流程,生成对应的目标文件。
1. 预处理(预编译):生成.i文件
预处理阶段主要处理源代码中以#开头的预编译指令,最终将.c文件转换为.i后缀的文件。
- 关键命令 (gcc 环境):
gcc -E test.c -o test.i - 核心处理规则 :
- 删除所有
#define,并展开所有宏定义(比如#define MAX 100,会把代码中所有MAX替换为 100); - 处理条件编译指令(
#if、#ifdef、#elif、#else、#endif),根据条件保留或删除对应的代码块; - 处理
#include指令,将头文件(如stdio.h)的内容完整插入到指令所在位置(递归处理,头文件中包含的其他头文件也会被插入); - 删除所有注释(// 单行注释和 /* */ 多行注释都会被清空);
- 添加行号和文件名标识,方便后续编译阶段生成调试信息;
- 保留
#pragma编译器指令(后续编译器会根据该指令进行特殊处理)。
- 删除所有
预处理后的.i文件不再有宏定义和注释 ,且包含了所有需要的头文件内容**。如果不确定宏是否展开、头文件是否正确包含,查看.i文件是最直接的方式。**
2. 编译:生成.s汇编文件
编译阶段是整个流程中最复杂的一步,它将预处理后的.i文件通过词法分析、语法分析、语义分析和优化 ,最终生成汇编代码文件(.s后缀)。
- 关键命令 (gcc 环境):
gcc -S test.i -o test.s - 核心流程 :
- 词法分析:将代码中的字符分割为一系列 "记号",包括关键字(如
int、return)、标识符(如变量名a、函数名Add)、字面量(如10、2022)、特殊字符(如+、=、[])。例如代码array[index] = (index+4)*(2+6);会被拆分为 16 个记号; - 语法分析:将词法分析得到的记号组合成语法树,语法树以表达式为节点,确保代码符合 C 语言的语法规则;
- 语义分析:检查代码的 "逻辑合理性",比如变量类型是否匹配、函数参数个数是否正确、类型转换是否合法等(静态语义分析),若有错误会在此阶段报错;
- 优化:对代码进行优化(如常量折叠、循环优化等),提升最终程序的执行效率。
- 词法分析:将代码中的字符分割为一系列 "记号",包括关键字(如
3. 汇编:生成.o目标文件
汇编阶段将编译生成的汇编代码(.s文件)转换为机器指令,最终生成目标文件(.o或.obj)。
- 关键命令 (gcc 环境):
gcc -c test.s -o test.o - 核心逻辑 :汇编器会根据 "汇编指令 - 机器指令" 对照表,将每一条汇编语句直接翻译为对应的机器指令(几乎是一一对应),且不进行指令优化。此时生成的目标文件已经是二进制文件,但还不能直接运行 ------ 因为它可能依赖其他文件中的函数或变量。
预处理深度解析:13 个核心技术点:
1. 预定义符号
C 语言内置了多个预定义符号,可直接使用,均在预处理期间处理:
__FILE__:当前编译的源文件名(字符串);__LINE__:当前代码行号(整数);__DATE__:文件编译日期(格式:MMM DD YYYY);__TIME__:文件编译时间(格式:HH:MM:SS);__STDC__:若编译器遵循 ANSI C,值为 1,否则未定义。
例子:
cpp
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
int main()
{
printf("%s\n", __FILE__);
printf("%s\n", __DATE__);
printf("%s\n", __TIME__);
printf("%d\n", __LINE__);
return 0;
}
2. #define定义常量
基本语法 :#define name stuff
cpp
#define DEBUG_PRINT printf("file:%s\tline:%d\tdate:%s\ttime:%s\n", __FILE__,__LINE__,__DATE__,__TIME__)
#define max 10000
#define str "hello world"
#include<stdio.h>
int main()
{
int m = max;
printf("%d\n", m); // 输出宏定义的数值
printf("%s\n", str); // 输出宏定义的字符串
DEBUG_PRINT; // 直接调用宏(宏本身是完整的printf语句)
return 0;
}
注意 :定义常量时不要加;,否则可能导致语法错误
3. #define定义宏
宏允许将参数替换到文本中,语法 :#define name(parameter-list) stuff(参数列表左括号需与 name 紧邻,否则会被解析为 stuff 的一部分)。
示例:计算一个数的平方
cpp
#define SQRT(a) ((a) * (a))
#include<stdio.h>
int main()
{
int a = 10;
int ret = SQRT(a); // 调用宏定义的函数
printf("%d\n", ret);
// 额外测试:传入表达式,验证防陷阱效果
int b = 5;
int ret2 = SQRT(b + 1); // 预期结果:(5+1)*(5+1)=36
printf("b+1 = %d, (b+1)的平方 = %d\n", b + 1, ret2);
return 0;
}
主要宏的运算符优先级问题
4. 带有副作用的宏参数
副作用指表达式求值时产生的永久性效果(如x++、x--)。若宏参数在宏体中多次出现,副作用可能导致不可预测结果。
cpp
#define MAX(X,Y) ((X)>(Y)?(X):(Y)) // 定义宏定义的条件运算符
#include<stdio.h>
int main()
{
int a = 3;
int b = 5;
int m = MAX(a++, b++);
//int m=((a++) > (b++) ? (a++) : (b++))
printf("%d\n", m);
printf("%d\n", a);
printf("%d\n", b);
return 0;
}
带自增 / 自减(++/--)等副作用的参数传入宏时,会因参数被多次求值(比较阶段 + 赋值阶段)导致结果不可预测;
避免方法:
cpp
#define MAX(X,Y) ((X)>(Y)?(X):(Y))
#include<stdio.h>
int main()
{
int a = 3;
int b = 5;
// 先自增,再传参(手动规避副作用)
int a_val = a++;
int b_val = b++;
int m = MAX(a_val, b_val);
printf("%d\n", m); // 输出5
printf("%d\n", a); // 输出4
printf("%d\n", b); // 输出6
return 0;
}5. 宏替换的规则
- 调用宏时,先检查参数是否 包含
#define定义的符号,若有则先替换; - 将替换文本插入到原位置,宏参数被对应值替换;
- 再次扫描结果文件,重复上述过程(宏不可递归,字符串常量中的内容不被搜索)。
6. 宏与函数的对比
宏和函数各有优劣,适用于不同场景,具体对比如下:
| 属性 | #define 定义宏 | 函数 |
|---|---|---|
| 代码长度 | 每次使用均插入代码,可能增加程序长度 | 代码仅存一份,调用时跳转 |
| 执行速度 | 更快(无调用 / 返回开销) | 较慢(存在函数调用和返回开销) |
| 运算符优先级 | 需加括号避免不可预期结果 | 表达式求值结果传递,可预测 |
| 带有副作用的参数 | 可能产生不可预期结果 | 仅传参时求值一次,易控制 |
| 参数类型 | 类型无关,支持任意合法操作的类型 | 类型相关,不同类型需不同函数 |
| 调试 | 无法调试(预处理阶段已替换) | 可逐语句调试 |
| 递归 | 不支持 | 支持 |
宏的独特优势 :参数可包**含类型,**函数无法实现:
cpp
#define Malloc(n,type) (type*)malloc(n*sizeof(type));
#include<stdio.h>
int main()
{
int *ptr=Malloc(5,int);//作用是分配5个int类型的内存空间,并返回指向这块内存的指针;
*ptr=10;
printf("%d\n",ptr[0]);
return 0;
}7.1 #运算符:字符串化
将宏参数转换为字符串字面量,仅用于带参数的宏替换列表中。
cpp
#define PRINT(n) printf("the value of "#n" is %d", n)
#include<stdio.h>
int main()
{
int a = 10;
printf("the value of a is %d\n", a);
PRINT(a); // 替换为:printf("the value of ""a"" is %d", a);
// 输出:the value of a is 10
return 0;
}
7.2 ##运算符:记号粘合
将两边的符号合成一个合法标识符,可用于动态创建函数名、变量名等。
示例 :生成不同类型的最大值函数(type##_max是 "记号粘合" 操作,会将宏参数type和字符串_max拼接成一个新的合法标识符:)
cpp
#include<stdio.h>
// ## 运算符:将"type"和"_max"粘合为合法标识符(如int_max、float_max)
#define GENERIC_MAX(type) \
type type##_max(type x, type y) { \
return (x > y ? x : y); \
}
// 生成int类型的max函数:展开后为 int int_max(int x, int y) { ... }
GENERIC_MAX(int)
// 生成float类型的max函数:展开后为 float float_max(float x, float y) { ... }
GENERIC_MAX(float)
// 生成double类型的max函数
GENERIC_MAX(double)
// 生成char类型的max函数(比较ASCII值)
GENERIC_MAX(char)
int main()
{
// 使用生成的函数
int m = int_max(2, 3);
float fm = float_max(3.5f, 4.5f);
double dm = double_max(2.56, 8.99);
char cm = char_max('a', 'z');
// 输出结果验证
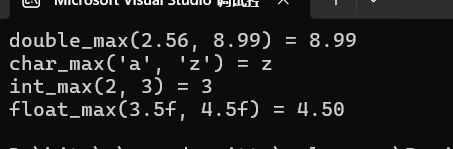
printf("double_max(2.56, 8.99) = %.2f\n", dm); // 输出8.99
printf("char_max('a', 'z') = %c\n", cm); // 输出z
printf("int_max(2, 3) = %d\n", m);
printf("float_max(3.5f, 4.5f) = %.2f\n", fm);
return 0;
}
8. 命名约定
为区分宏和函数,建议:
- 宏名全部大写(如
MAX、SQUARE); - 函数名不要全部大写(如
int_max、add)。
9. #undef:移除宏定义
用于删除已有的宏定义,若需重新定义某个符号,需先移除旧定义:
10. 命令行定义
许多编译器支持在命令行中定义符号,用于编译程序的不同版本(如调整数组大小)。
cpp
#include <stdio.h>
// 定义数组大小(可根据需要修改数值)
#define ARRAY_SIZE 10
int main() {
int array[ARRAY_SIZE];
for(int i=0; i<ARRAY_SIZE; i++)
array[i] = i;
for(int i=0; i<ARRAY_SIZE; i++)
printf("%d ", array[i]);
return 0;
}11. 条件编译
通过条件编译指令,可选择性编译代码(如保留调试代码),常见指令如下:
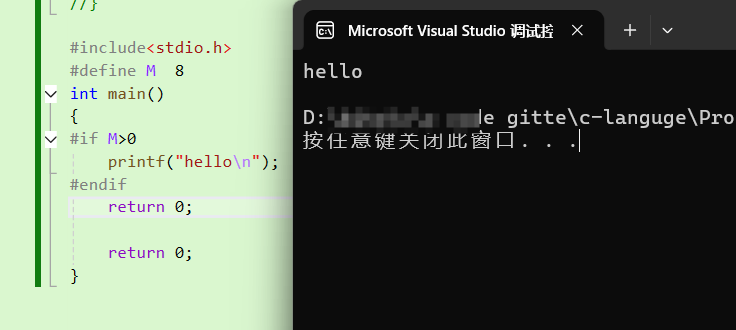
1基本格式:
cpp
#if 常量表达式
// 代码块
#endif例子:(改变M的大小控制是否执行printf语句)
2多分支格式:
cpp
#if 常量表达式
// 代码块1
#elif 常量表达式
// 代码块2
#else
// 代码块3
#endif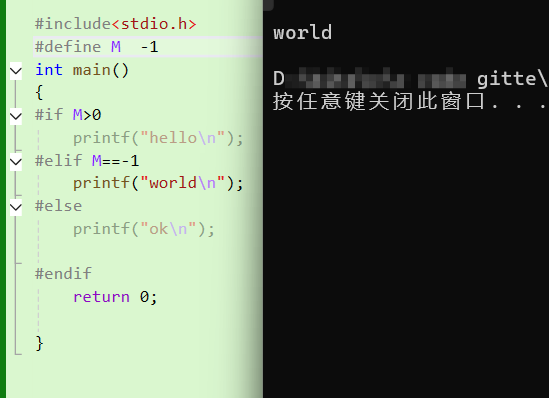
3判断符号是否定义:
cpp
#if defined(symbol) // 等价于#ifdef symbol
// 代码块
#endif
#if !defined(symbol) // 等价于#ifndef symbol
// 代码块
#endif
cpp
#include <stdio.h>
// 定义测试宏
#define DEBUG 1
// #undef DEBUG // 取消注释可关闭DEBUG宏
int main() {
// 1. #if defined(symbol) 等价于 #ifdef symbol
#if defined(DEBUG)
printf("DEBUG宏已定义 → 开启调试模式\n");
#endif
// 等价写法
#ifdef DEBUG
printf("(等价#ifdef)DEBUG宏已定义\n");
#endif
// 2. #if !defined(symbol) 等价于 #ifndef symbol
#if !defined(RELEASE)
printf("RELEASE宏未定义 → 未启用发布模式\n");
#endif
// 等价写法
#ifndef RELEASE
printf("(等价#ifndef)RELEASE宏未定义\n");
#endif
return 0;
}12.1 包含方式及区别
| 包含方式 | 查找策略 | 适用场景 |
|---|---|---|
#include "filename" |
先在源文件所在目录查找,未找到则去标准路径查找 | 本地头文件(自定义) |
#include <filename.h> |
直接去标准路径查找 | 库文件(如 stdio.h) |
注意 :库文件也可使用""包含,但查找效率低,且无法区分文件类型,不推荐。
12.2 避免头文件重复包含
头文件被多次包含会导致代码冗余、编译效率降低(如test.c多次包含test.h,test.h内容会被重复拷贝)。解决方案:
1条件编译方式(兼容性好):
cpp
#ifndef __TEST_H__ // 若未定义__TEST_H__
#define __TEST_H__ // 定义__TEST_H__
// 头文件内容(函数声明、结构体定义等)
#endif // __TEST_H__2#pragma once方式(简洁,部分编译器支持):
cpp
#pragma once
// 头文件内容13. 其他预处理指令
#error:编译时输出错误信息,终止编译;#line:修改当前行号和文件名标识;#pragma:编译器特定指令(如**#pragma pack()用于调整结构体对齐方式**)。
(二)链接:生成可执行程序(.exe或 Linux 下无后缀)
一个 C 项目通常会有多个.c文件(比如test.c和add.c),每个文件单独编译生成目标文件后,需要通过链接器将所有目标文件和 "链接库" 整合,最终生成可执行程序。
- 链接库 :包括支持程序运行的 "运行时库"(如
printf函数所在的标准库)和第三方库(如开源的算法库); - 核心任务:解决多文件、多模块之间的依赖问题,具体包括地址分配、符号决议和重定位;
- 举个例子 :
test.c中声明了外部函数Add和全局变量g_val(通过extern关键字),并在main函数中调用;add.c中定义了g_val = 2022和Add函数(实现两数相加);- 编译阶段,
test.c生成test.o时,编译器并不知道Add和g_val的实际地址,只能暂时搁置; - 链接阶段,链接器会在
add.o中查找Add函数和g_val变量的地址,然后修正test.o中所有引用它们的指令,将目标地址替换为实际地址 ------ 这个过程就是 "重定位"。
经过链接后,所有目标文件的机器指令被整合,依赖的函数和变量地址被正确填充,最终生成可在操作系统中运行的程序。
三、运行环境:可执行程序的执行流程
当翻译环境生成可执行程序后,运行环境会负责执行它,具体步骤如下:
- 程序载入内存:在操作系统环境中(如 Windows、Linux),由操作系统将可执行程序载入内存;如果是嵌入式等独立环境,可能需要手工安排或置入只读内存。
- 调用 main 函数 :程序执行的入口是
main函数,操作系统会启动执行流,首先调用main函数。 - 执行程序代码 :
- 此时会使用 "运行时堆栈(stack)",存储函数的局部变量、函数参数和返回地址;
- 同时可以使用静态内存(
static修饰的变量),静态内存中的变量在程序整个执行过程中会一直保留其值,不会随函数调用结束而销毁。
- 程序终止 :正常情况下,
main函数执行完毕后程序终止;也可能因异常(如数组越界、除零错误)导致程序意外终止。
总结
C 语言程序从源代码到可执行程序的过程,是 "翻译环境" 和 "运行环境" 共同作用的结果。其中翻译环境的 "预处理→编译→汇编→链接" 是核心,每一步都有明确的目标和任务:预处理处理宏和头文件,编译将代码转为汇编,汇编将汇编转为机器指令,链接解决多文件依赖并生成可执行程序。理解这个流程,不仅能帮助我们更好地排查编译和链接错误(如 "未定义引用""宏定义失效"),还能为后续深入学习计算机系统(如目标文件格式、内存布局)打下基础。如果想进一步探究底层细节,推荐阅读《程序员的自我修养》一书。