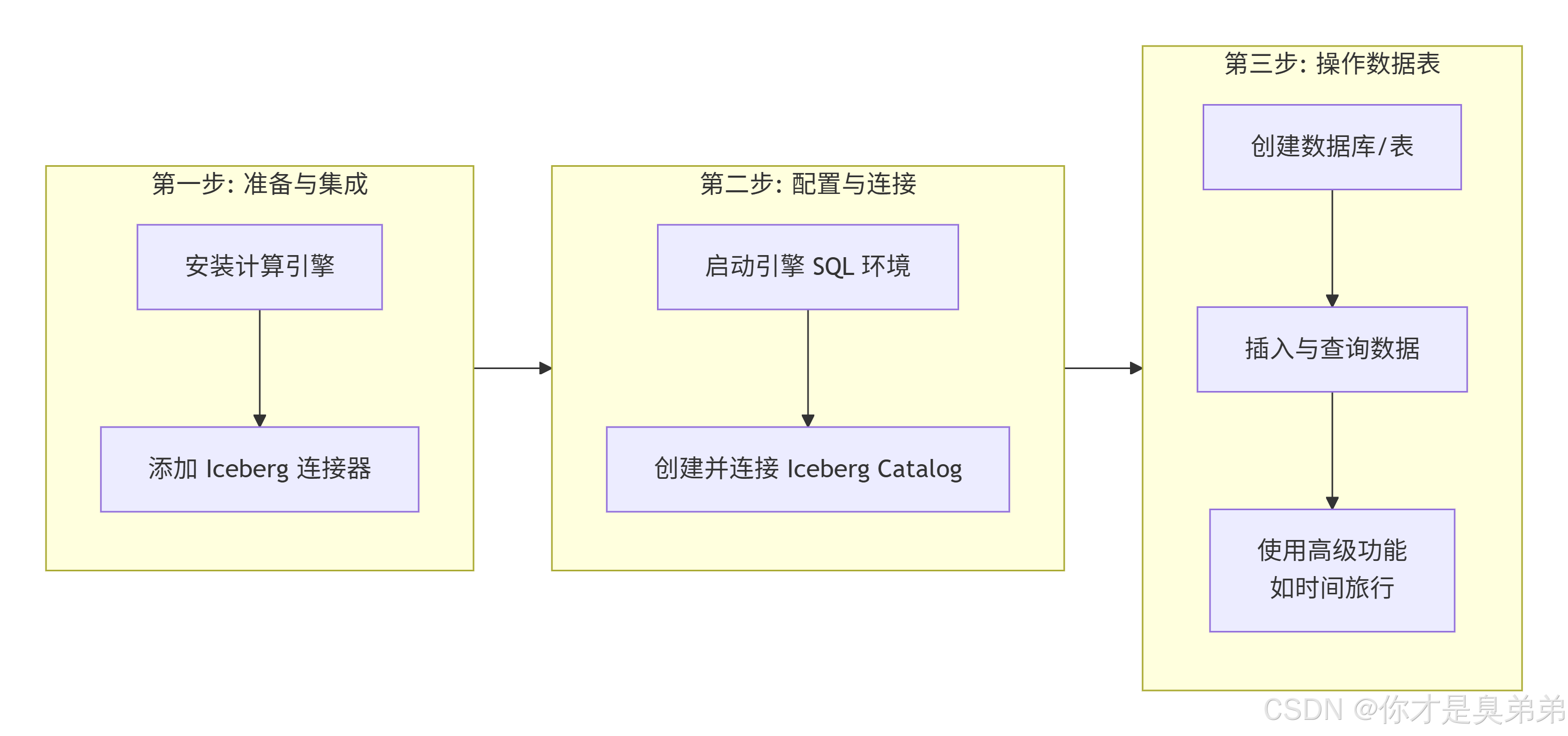
1、使用 Iceberg 的核心流程
2、下载 Apache Flink引擎
注意:推荐Linux 版本 Windows版本bin 当中是.sh的执行脚本(如果安装到windows可能还需要借助如:Cygwin 或 Windows Subsystem for Linux (WSL) 启动运行.sh脚本)
官网下载: https://flink.apache.org/zh/downloads/#apache-flink-downloads
3、下载 Apache Iceberg
注意:Apache Iceberg 是一个数据湖解决方案,而它作为Jar包(库)的形式,正是其现代架构设计的精髓所在。
官网下载: Apache Iceberg 官方仓库
🏗️ 核心概念区分:数据湖 ≠ 独立服务
首先要明确,"数据湖"是一种数据存储和管理的架构理念 ,其核心是在低成本存储(如HDFS、S3)上集中存放海量的原始数据,并提供统一的访问、治理和分析能力。
实现这种理念的技术组件有很多,而Iceberg的定位是其中的**"表格式"** 层。你可以这样理解现代数据湖的通用架构:
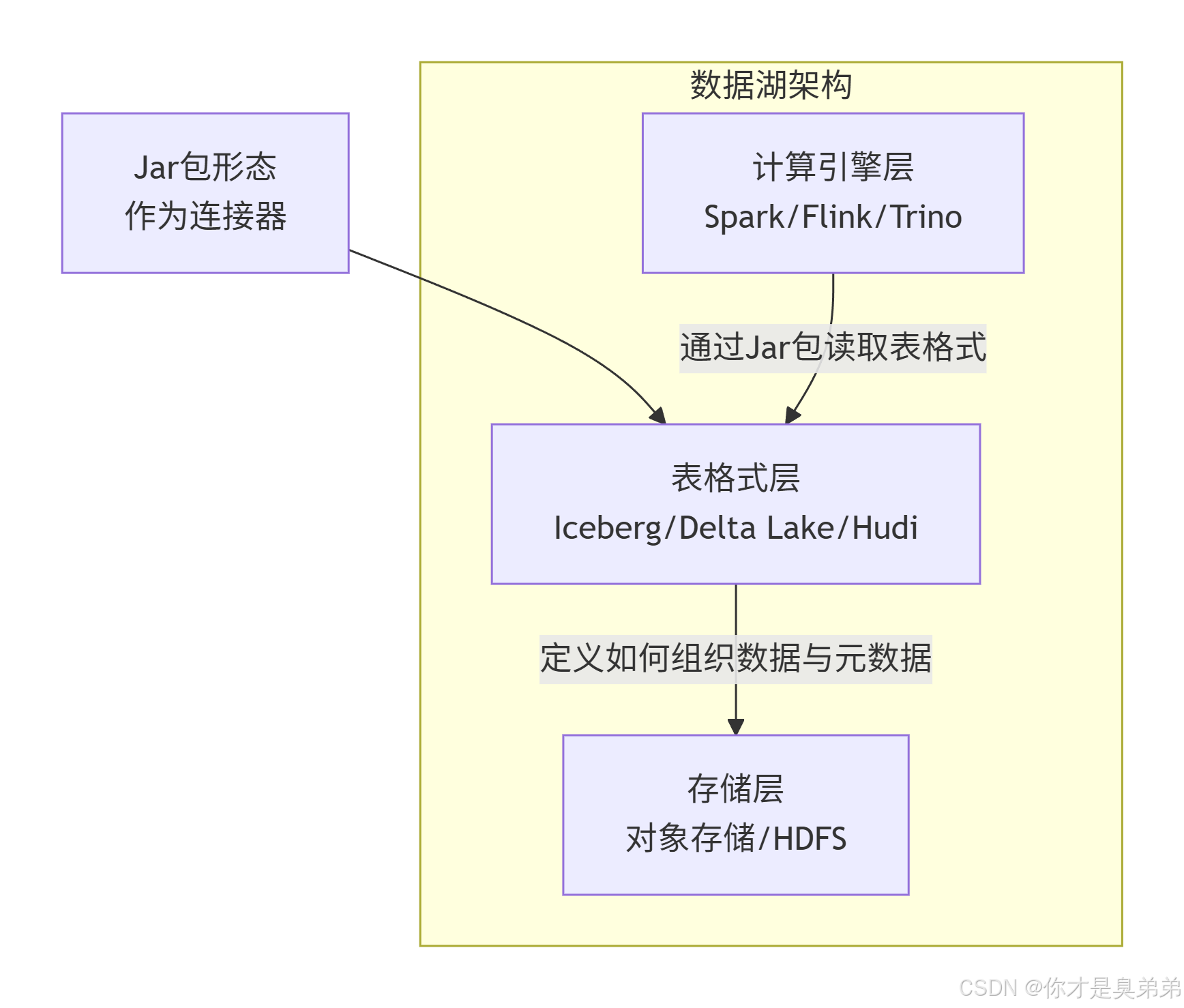
如上图所示,Iceberg的核心作用是为存储层上的文件定义一套严谨的"表"的格式规范。这套规范告诉计算引擎:
-
数据在哪里:如何找到表对应的数据文件。
-
数据什么样:表的schema、分区信息。
-
数据的状态:有哪些历史快照,保证读写一致性。
📦 为什么以Jar包形式交付?
这正是Iceberg设计的先进性。它不需要像传统数据库(MySQL)或某些服务(HBase)那样启动一个常驻的"主节点"或"服务进程"。具体优势对比如下:
| 特性 | 传统有状态服务 (如Hive Metastore) | Apache Iceberg (库模式) |
|---|---|---|
| 架构 | 中心化的独立服务,存在单点瓶颈和故障风险。 | 去中心化的嵌入式库,无单点故障。 |
| 元数据存储 | 集中存储在独立的数据库(如MySQL)中。 | 以文件形式与数据本身一起存储在对象存储(如S3)中。 |
| 扩展性 | 受限于中心服务的性能,扩展复杂。 | 计算引擎可直接读取存储,随计算引擎线性扩展。 |
| 部署与集成 | 需要额外部署、配置和维护服务。 | 以Jar包嵌入计算引擎,开箱即用,极其轻量。 |
🔄 它如何工作?一个查询流程对比
假设你要查询一张表:
-
传统方式(如Hive):
-
计算引擎连接并询问 Hive Metastore服务 :"
sales表在哪里?什么结构?" -
Metastore服务从自己的数据库中查询并返回信息。
-
引擎根据信息去存储系统 读取数据文件。
过程涉及两个外部服务,任何一个出问题都导致查询失败。
-
-
Iceberg方式:
-
计算引擎(如Spark)加载了
iceberg-spark-runtime.jar。 -
引擎通过Jar包内的逻辑,直接去对象存储的指定路径 读取Iceberg的元数据文件(如
metadata.json)。 -
引擎解析元数据文件,获知所有数据文件位置,然后直接读取。
过程仅涉及计算引擎和对象存储,路径更短,更稳定可靠。
-
✅ Jar包形态的优势
所以,Iceberg作为Jar包,恰恰实现了 "让数据自己说话" 的目标。它的所有元数据都以文件形式安静地躺在你的对象存储里,任何支持Iceberg格式的计算引擎,只要引入对应的Jar包,就能直接理解并处理这些数据。
这种设计为你带来了:
-
免运维:无需部署和管理另一个高可用服务。
-
开放性:多引擎(Spark, Flink, Trino, Presto, Hive...)通过各自Jar包平等接入,没有厂商锁定。
-
可靠性:元数据与数据共存亡,存储可靠即元数据可靠。
-
高性能:去中心化设计避免了中心服务的性能瓶颈。
因此,当你将 iceberg-flink-runtime-xxx.jar 放入Flink的 lib 目录时,你并不是在安装一个"湖",而是在给Flink这个"渔船"安装一套最先进的 "声纳和导航系统"(表格式支持) ,让它能直接去广阔的数据海洋(对象存储)中,精准、高效地捕鱼(处理数据)。
4、使用 Apache Flink引擎操作 Apache Iceberg
✅ 方式一:通过 Flink SQL 使用 (适用于流批一体)
假设你已经按照之前的建议,准备好了 Flink 1.17 和 Iceberg 1.7.2+ 的环境。
-
启动 Flink SQL Client :
确保已将
iceberg-flink-runtime-1.17-1.7.2.jar等依赖放入 Flink 的lib/目录,然后启动 SQL 客户端。 -
创建并连接 Iceberg Catalog :
Catalog 是 Iceberg 管理表的入口,你需要告诉 Flink 表的元数据和数据存储在哪里。
sql-- 创建一个名为iceberg_catalog的Catalog,数据存储在本地路径 CREATE CATALOG iceberg_catalog WITH ( 'type'='iceberg', 'catalog-type'='hadoop', 'warehouse'='file:///tmp/iceberg/warehouse' ); -- 使用这个Catalog USE CATALOG iceberg_catalog; -
操作数据表 :
连接后,你就可以像使用普通数据库一样操作 Iceberg 表了。
sql-- 创建数据库和表 CREATE DATABASE my_db; USE my_db; CREATE TABLE user_events ( user_id BIGINT, event_time TIMESTAMP(6), event_name STRING ) PARTITIONED BY (user_id); -- 插入数据 INSERT INTO user_events VALUES (1, TIMESTAMP '2026-01-01 10:00:00', 'login'), (2, TIMESTAMP '2026-01-01 10:01:00', 'purchase'); -- 查询数据 SELECT * FROM user_events; -- 使用时间旅行,查询1小时前的数据快照 SELECT * FROM user_events /*+ OPTIONS('snapshot-id'='123456789') */; -- 或按时间查询 SELECT * FROM user_events FOR SYSTEM_TIME AS OF TIMESTAMP '2026-01-01 09:00:00';✅ 方式二:通过 Spark SQL 使用 (适用于批处理与分析)
如果你使用 Spark,流程也类似。
-
启动 Spark Shell 并集成 Iceberg:
spark-sql --packages org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.8.1 -
在 Spark SQL 中配置并使用 Catalog:
sql-- 配置Spark使用Iceberg Catalog CREATE DATABASE iceberg_catalog.my_db; USE iceberg_catalog.my_db; -- 建表、插入、查询等操作与Flink SQL语法高度相似 CREATE TABLE ...💡 关键使用技巧与提示
-
关于 Catalog :除了上述的
hadoop类型(用于HDFS或本地文件),生产环境常用hive(连接Hive Metastore)或rest(连接REST服务)类型的 Catalog 来实现元数据共享。 -
关于存储路径 :
warehouse路径如果是云存储,写法类似's3://my-bucket/iceberg/warehouse',并需配置访问密钥。 -
关于表格式版本 :创建表时,可以通过
'format-version'='2'属性指定格式。V2 是当前最稳定、支持最广的版本,除非有明确需求,否则建议使用 V2。 -
核心特性实践 :除了基本增删改查,务必尝试 时间旅行 、增量查询 (如
SELECT * FROM table.inc)和表管理 (如ALTER TABLE ...)等核心功能。