前提:所有操作基于联想电脑的Windows系统,其他电脑或linux等系统可以简单看一下,借鉴一下我的类似操作
一、问题
这两天我在个人联想电脑训练一个超大量的数据集,就是DOTA遥感影像数据图片,而且我还手动对图像进行切割增强,因此我的数据集光训练集就达到了1万多张,还包括我在切割图片时脚本文件生成的npy文件(记录了哪些图片是从一张图割下来的,什么位置割开的)
然后,我什么数据增强参数、学习率这些参数都没调,也没调yaml网络模型结构,就是简简单单试一下训练。。。炸了,我已经采用了:
- 【workers】多线程
- 【device=0】用GPU训练
- 【epochs=50】只练50轮
- 【batch=15】手动测试出的最大效率批量投喂
结果训练了一天一夜。。。。。
然后我又去网上看,尝试了三招:
- 【cache=ture】数据提前调入缓存
- 【cache="disk"】数据提前调入内存
- 【val=False】取消每一轮都用验证集验证训练效果
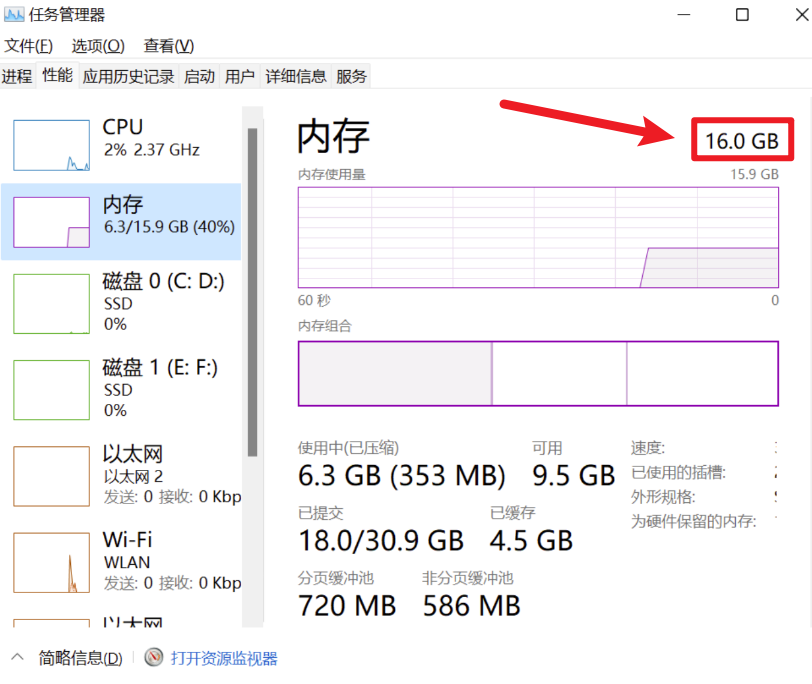
结果又更慢了!原因是我打开【任务管理器】打开【性能】
- 我的内存只有16GB,cache=True反而容易把内存顶满然后更慢、甚至崩
- 尤其这种 DOTA 数据量、再加上增强缓存,很容易把内存吃爆,Windows 一旦开始大量分页(用硬盘当内存),训练会"突然巨慢"。
- 这里附上各位电脑CPU性能对应要不要开cache这个操作:
- 而且关于【val=False】不做验证,也会让训练不稳定
所以我的代码改成了:
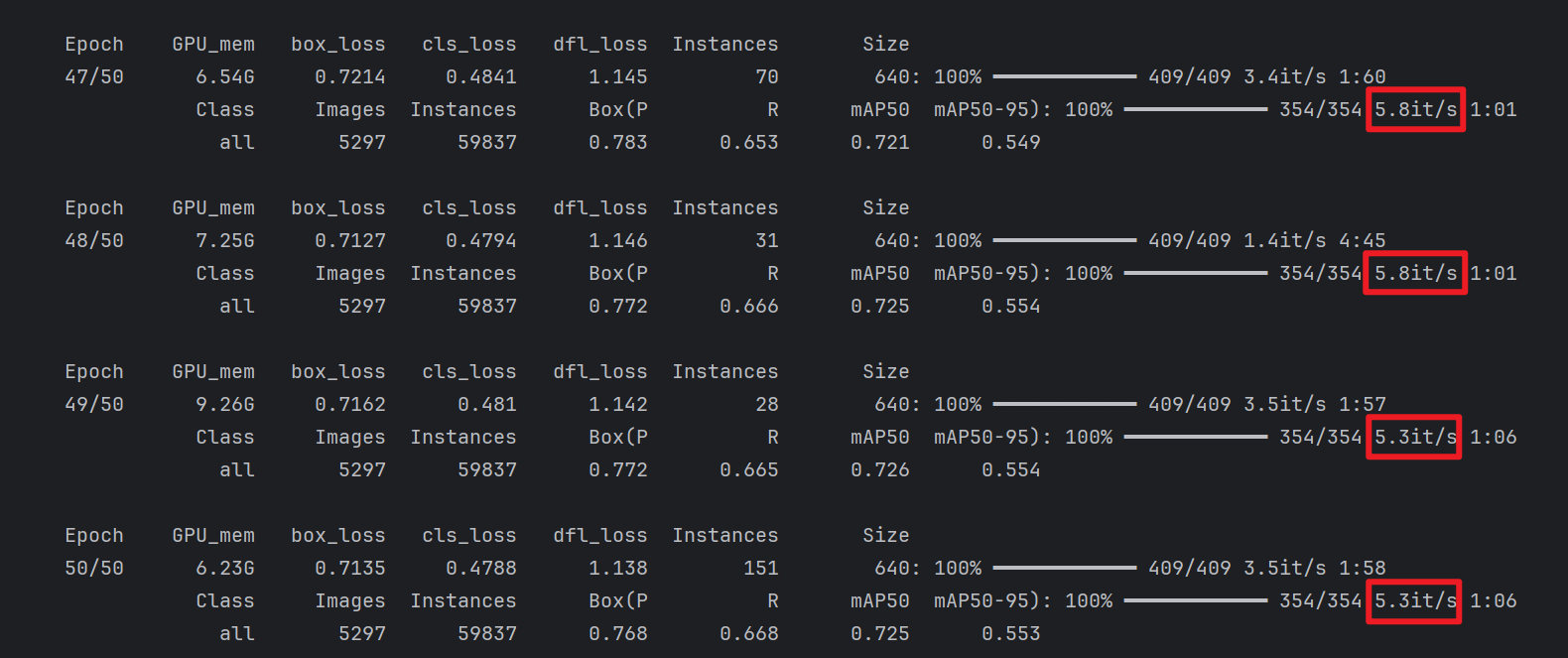
pythonimport torch from ultralytics import YOLO if __name__ == '__main__': # 这是为了Windows下开启workers>0 的硬性条件,workers>0就加快速度 torch.multiprocessing.freeze_support() # 解决多进程报错问题 # 直接加载官方YOLO11n预训练模型 # model = YOLO(r"F:\我自己的毕设\YOLO_study\DOTA\my_yaml\11\my_yolo11-obb.yaml").load("yolo11n-obb.pt") model = YOLO("yolo11n-obb.pt") results = model.train( data=r"F:\我自己的毕设\YOLO_study\DOTA\DOTA.yaml", epochs=50, imgsz=640, device=0, workers=4, # ❗Windows 不要太多 cache=False, # ❗立刻关掉 disk cache batch=15, val=True # ❗打开验证(反而更稳定) )虽然有一点改进,然并卵,依旧慢到世界爆炸!!等训练完我国已经完成全面建成富强民主文明和谐的社会主义现代化强国了


二、隐秘的解决方式1
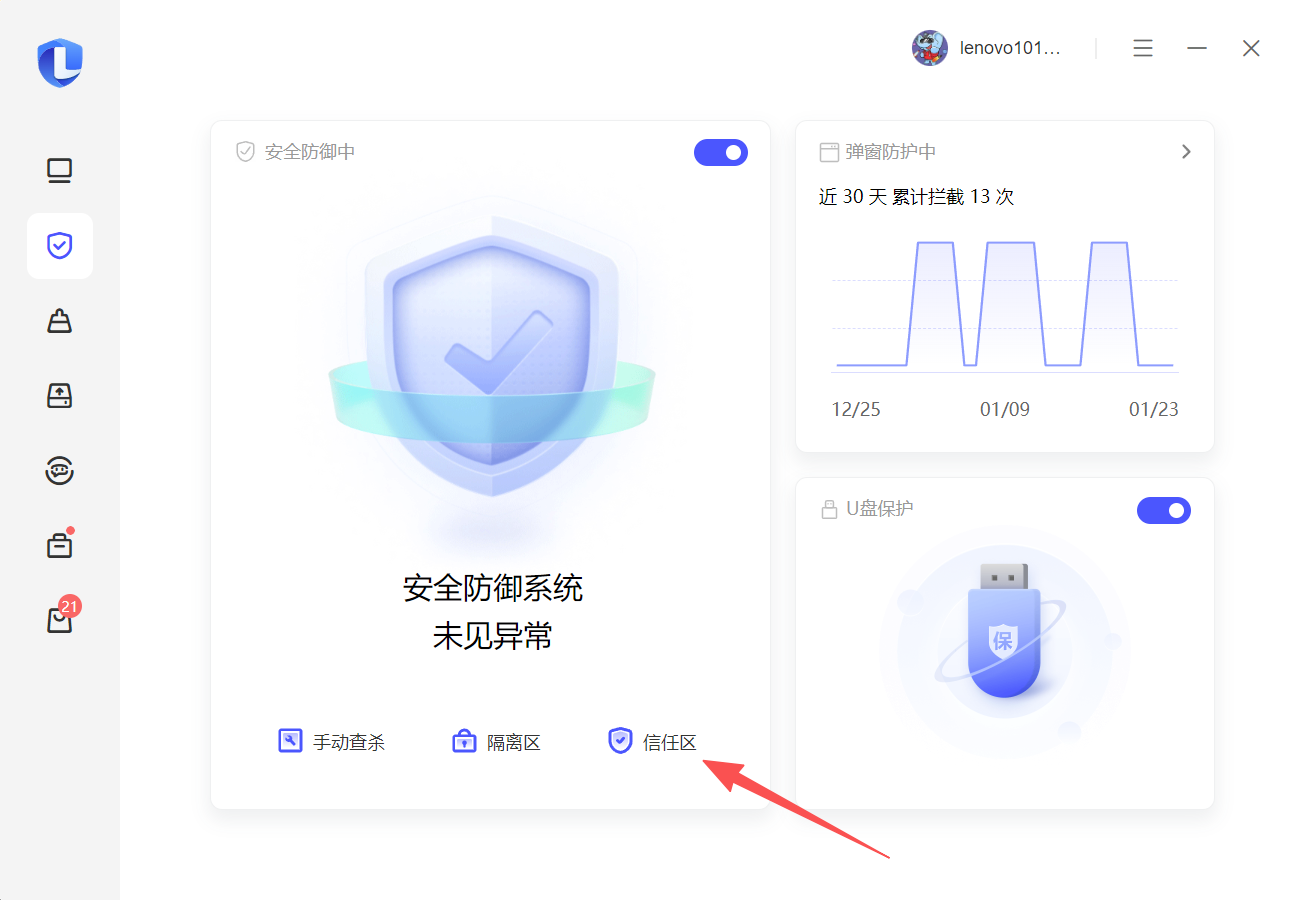
那么接下来我将分享一个应该很多大佬都知道但是没分享出来的解决办法:给你的数据集文件夹添加安全防护白名单信任
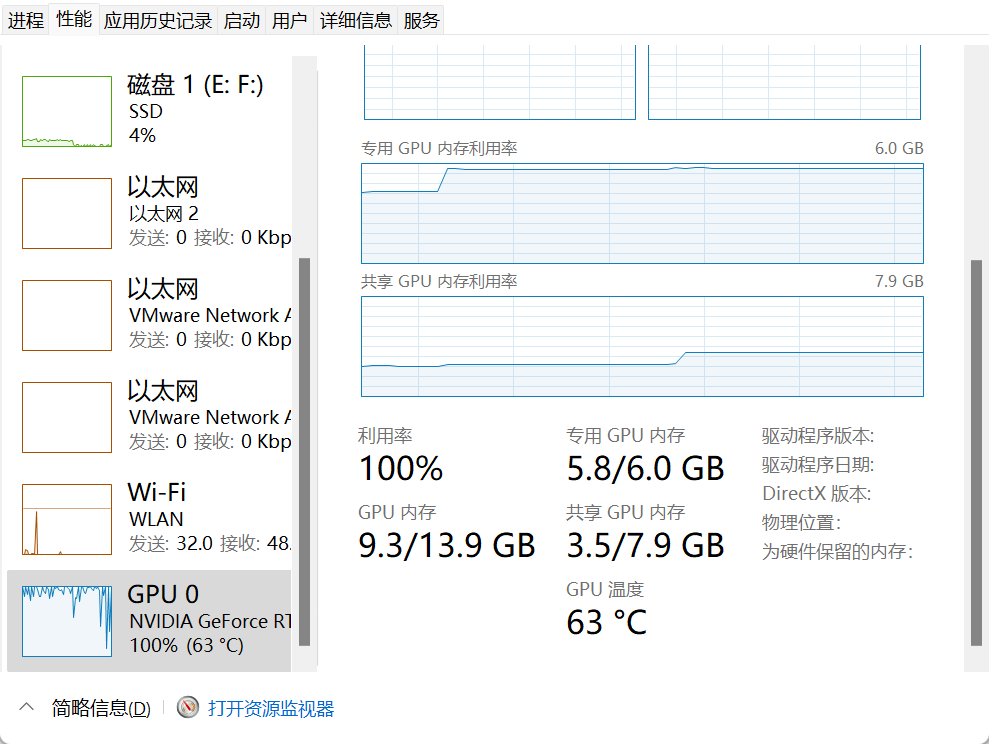
各位可以打开自己的【任务管理器】--->【性能】,找到【GPU】然后拉到底
如果发现你的GPU那利用率不停的跳,一会很低一会很高,像这样:
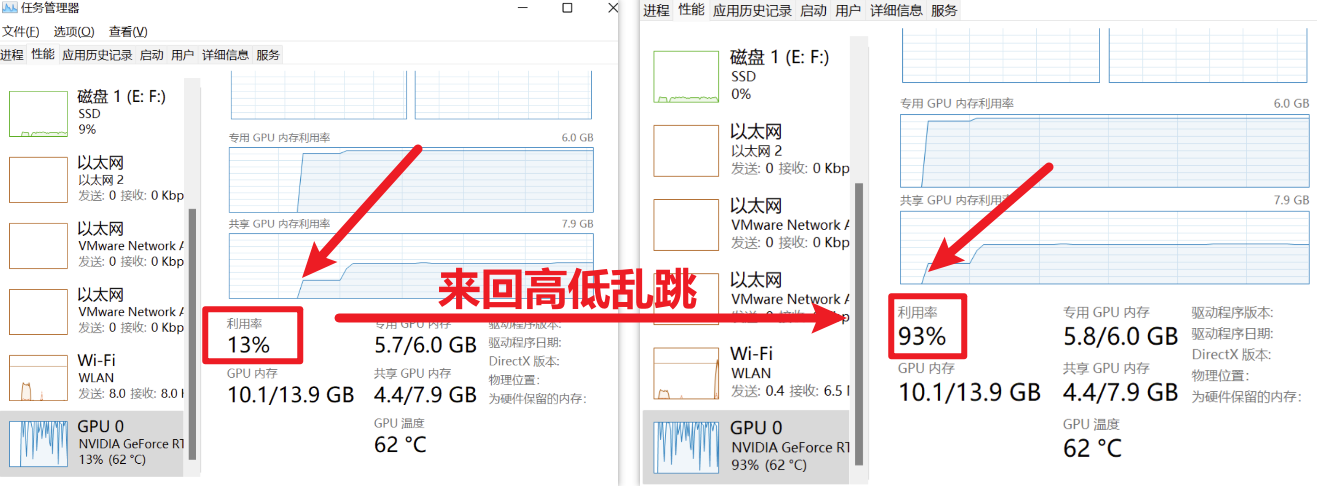
原因如下:GPU在等电脑安全卫士扫描这些文件有没有病毒

那么针对我的电脑情况,是联想自带了一个【联系电脑管家】来保护电脑
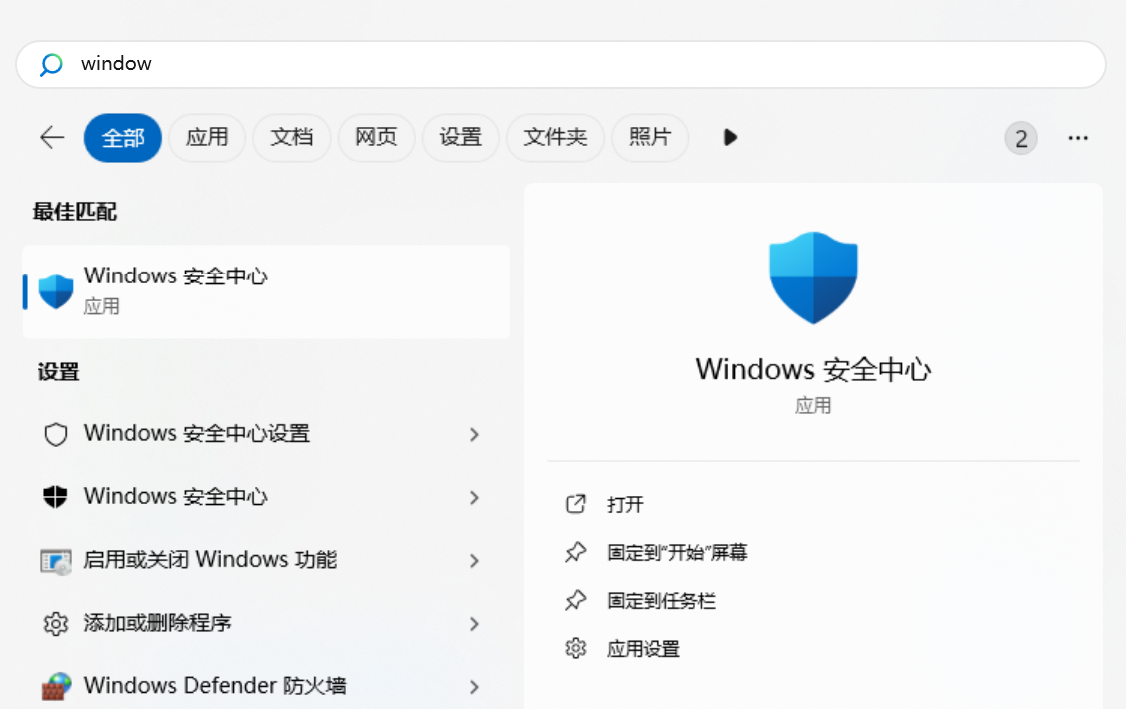
搜索【windows安全中心】然后点进去
点【打开应用】
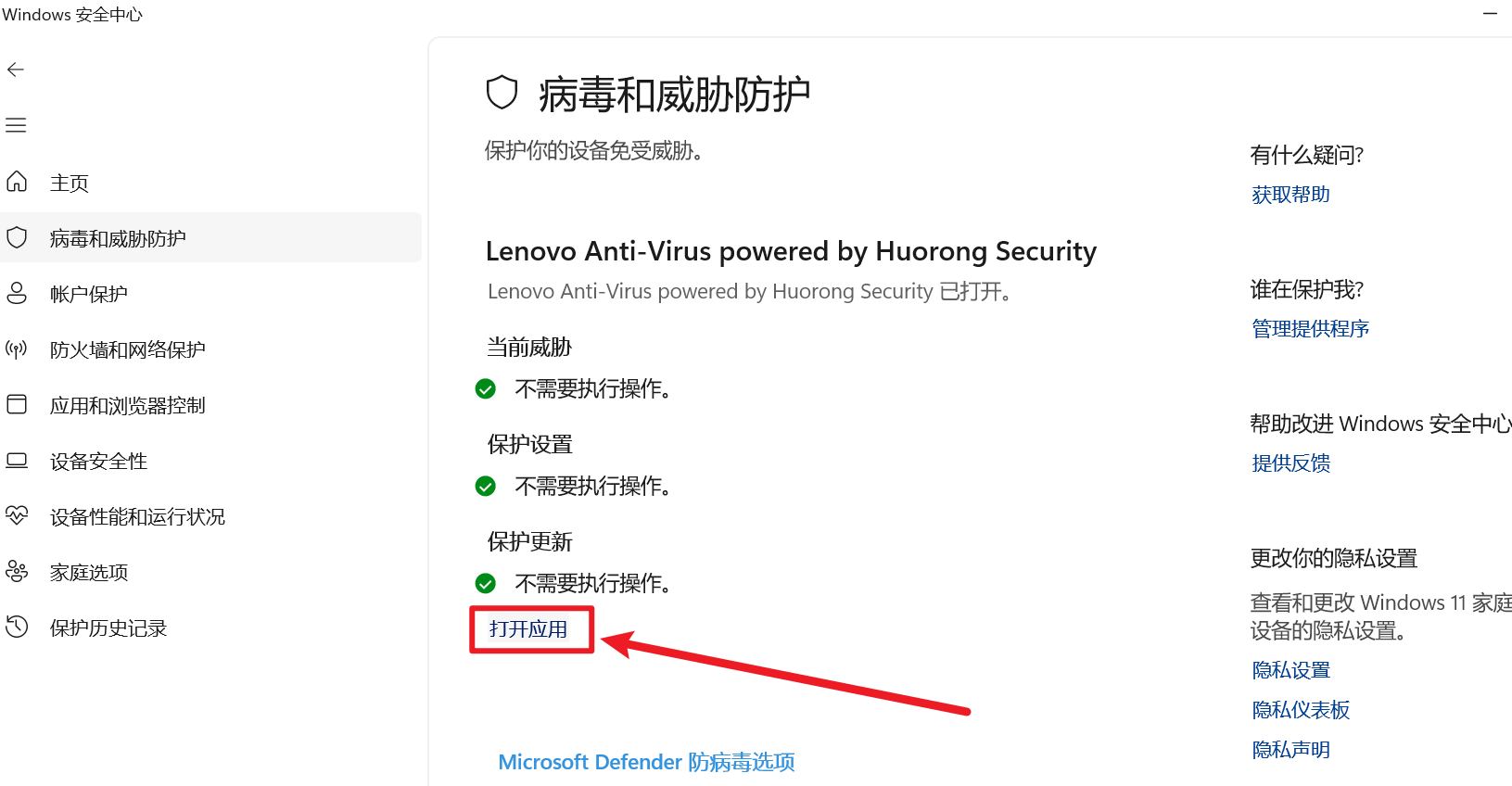
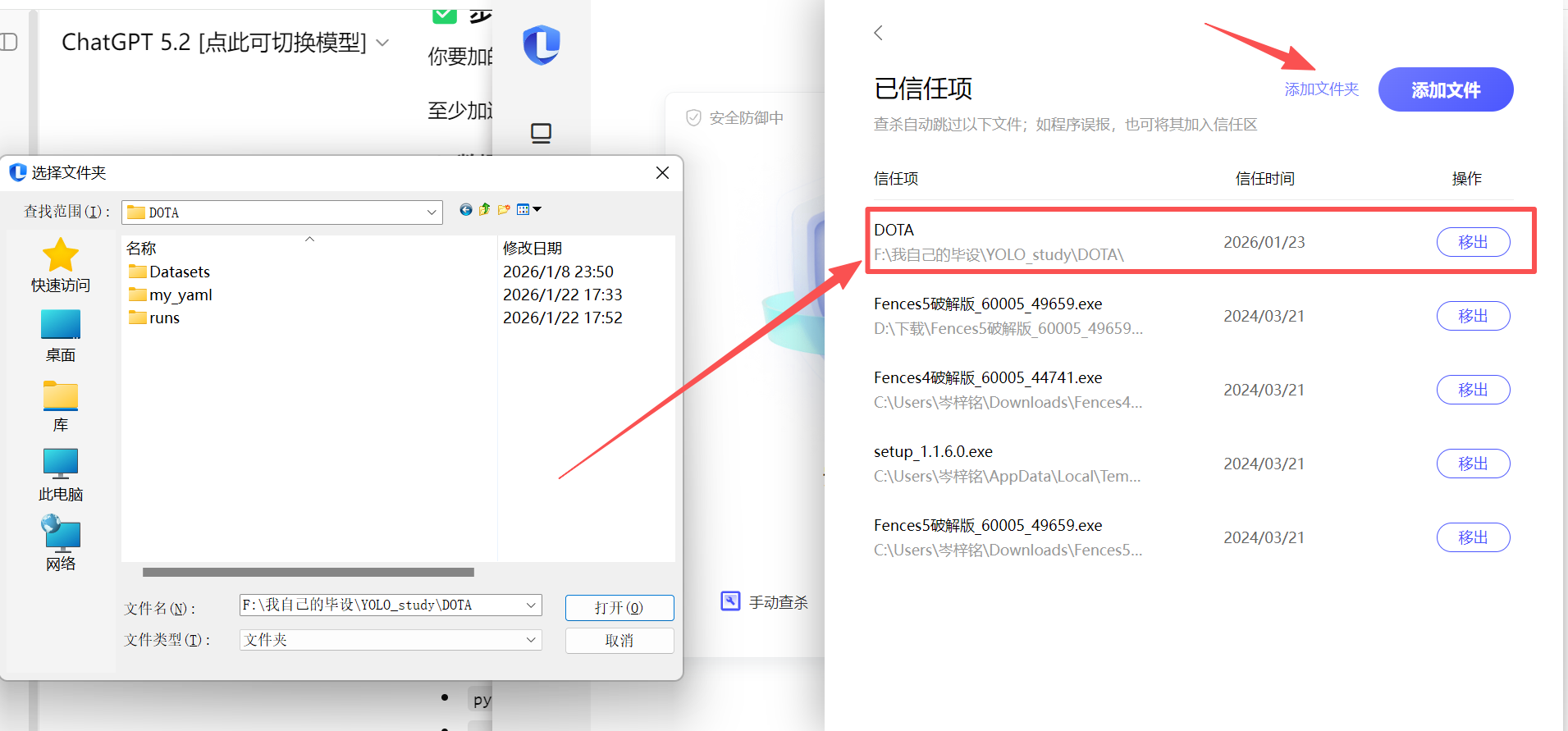
然后就会打开【联系电脑管家】,如果界面跟我一样,就按如下操作复制
把你要包含训练的所有文件的目录,整个添加进去
然后你就会发现【任务管理器 / 性能 / GPU】那已经稳定了,会有一点波动,但基本维持在70%~90%,已经是很高的利用率了
另外很少情况下偶尔还是会跳到13%这么低,是因为




三、隐秘的解决方式2
我知道看到这里会有人要骂我了
两个参数加快:
- 【val=False】取消每一轮都验证,不跑验证集数据
- 【plots=False】取消生成图表
关于【val=False】
但是这样你可能会看不到每一轮训练完的模型,对于【验证集考试】的效果,不知道模型是不是过拟合化了,那么我的建议是你可以看自己选择,选择训练5轮停下,单独用best.pt做一次验证,当然嫌麻烦也可以不做


关于【plots=False】
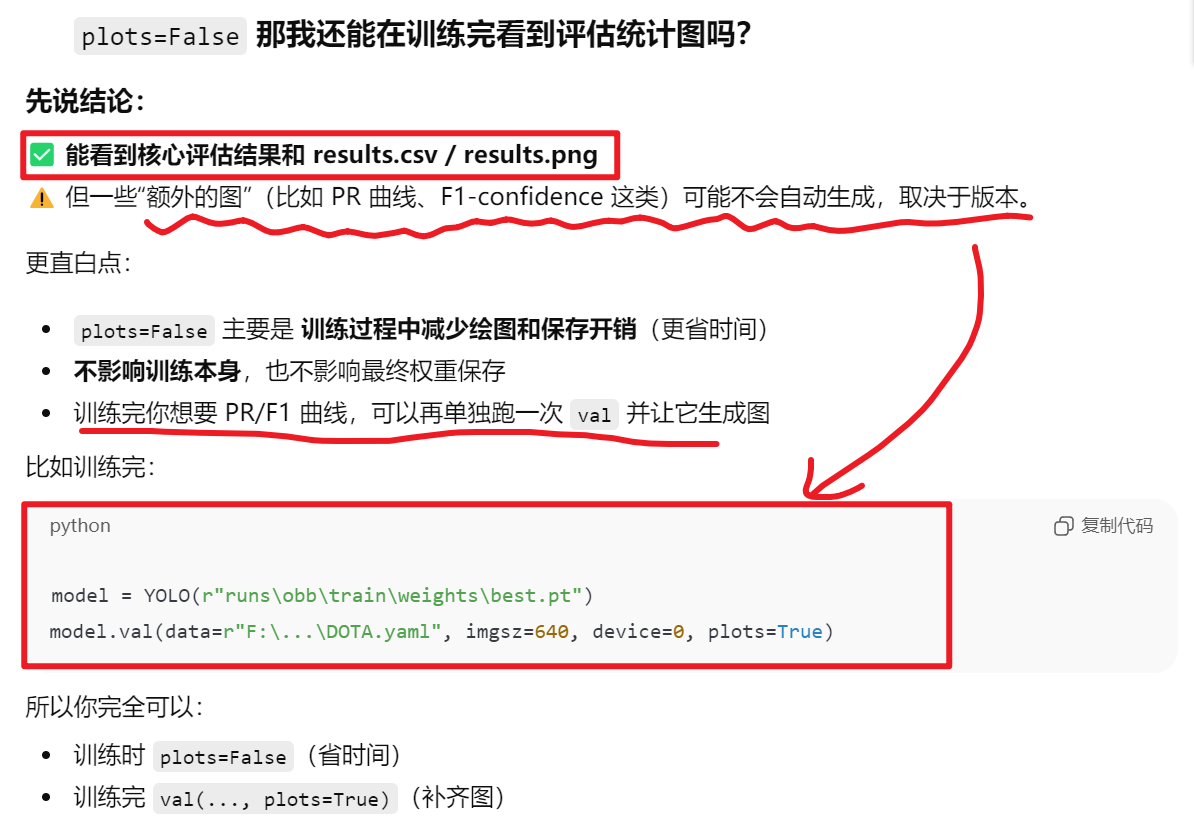
四、隐秘的解决方式2
在你的项目目录开一个终端,输入下面的命令并同时用下面命令执行train.py运行
pythonset PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True python train.py # 执行train.py代码