Liang, D., Zhou, X., Xu, W., Zhu, X., Zou, Z., Ye, X., Tan, X., & Bai, X. (2024). PointMamba: A Simple State Space Model for Point Cloud Analysis. NeurIPS.
博主导读 :
在点云分析的武林中,Transformer 家族(如 Point-MAE, PointGPT)凭借着强大的"全局注意力"心法,坐稳了 SOTA 的盟主宝座。但它们有一个致命的软肋:太重了! 自注意力机制 O ( N 2 ) O(N^2) O(N2) 的复杂度,就像是一个体重 300 斤的大力士,虽然力大无穷,但遇到大规模场景(N 变大)时,显存直接爆炸,速度慢如蜗牛。
这时候,隔壁 NLP 领域杀出了一匹黑马------Mamba 。它号称拥有 Transformer 的全局视野,却只有 RNN 的线性复杂度 O ( N ) O(N) O(N)。点云圈的侠客们一看,眼睛都直了:这不就是我们梦寐以求的"凌波微步"吗?
PointMamba 就是那个率先打通任督二脉的高手。它没有设计复杂的网络结构,而是用最朴素的 Hilbert 曲线 ,把无序的点云变成有序的序列,直接喂给原生的 Mamba。
结果令人咋舌:不仅精度超越了 Point-MAE,在大规模点云下,显存占用降低了 25 倍,速度提升了 30 倍! 简单的招式,往往最致命。
论文:PointMamba: A Simple State Space Model for Point Cloud Analysis
1. 痛点:天下苦 O ( N 2 ) O(N^2) O(N2) 久矣
在 PointMamba 问世之前,点云领域面临着一个巨大的"算力黑洞":
- Transformer 的富贵病 :Attention 机制虽然好,但它需要计算所有点对之间的关系。随着点数 N N N 增加,计算量和显存呈二次方爆炸。这对于自动驾驶、大场景扫描等动辄几万个点的任务来说,简直是灾难。
- Mamba 的水土不服 :Mamba 在文本领域(1D 序列)杀疯了,但它是**单向建模(Causal)**的。而点云是 3D 的、无序的。如果你直接把点云随机排成一排喂给 Mamba,前面的点看不到后面的点,且随机的顺序会破坏空间结构,效果甚至不如 MLP。
PointMamba 的灵魂拷问 :
能不能既享受 Mamba 的线性复杂度 ,又解决点云的无序性问题?
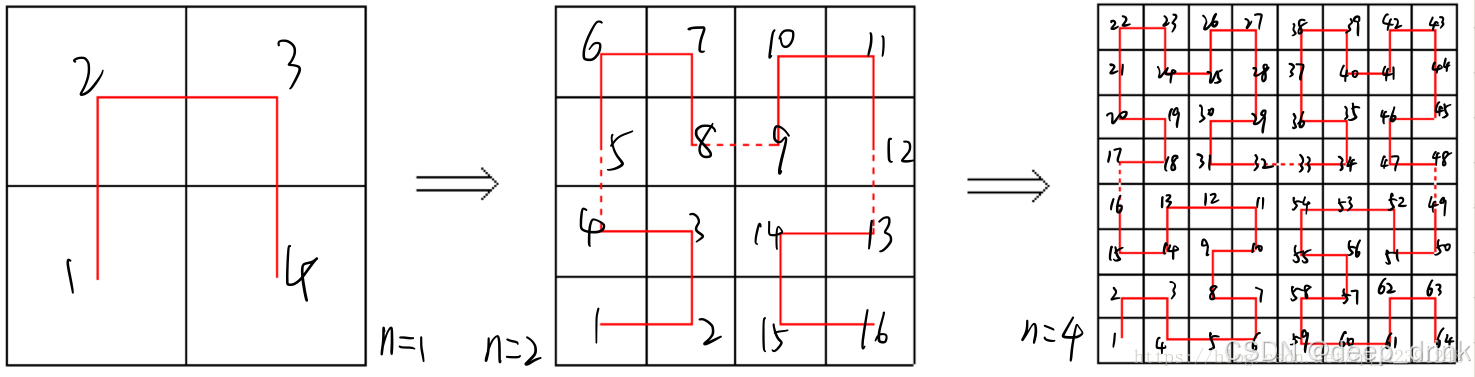
2. 核心大招:空间填充曲线 (Space-Filling Curve) 🧩
作者意识到,既然 Mamba 需要"有序"的序列,那我们就人为地制造一个**"最有道理"的顺序**。
PointMamba 的核心逻辑极其简单,可以概括为:FPS 采样 -> Hilbert 排序 -> Mamba 编码。
-
为什么要用 Hilbert 曲线?
- 干啥:把 3D 空间里的点,连成一条不中断的线。
- 优势 :局部性保持(Locality Preserving)。在 3D 空间中挨得近的两个点,映射到 Hilbert 1D 序列上,它们的索引(Index)通常也是挨着的。这完美契合了 Mamba 这种类似 RNN 的"扫描"特性。
-
双向扫描 (Dual Scanning):
- 问题:只用一种排序还是有偏见的。
- 解决 :作者用了两种曲线:Hilbert 和 Trans-Hilbert(希尔伯特曲线的转置)。
- 效果:就像从两个不同的角度去"阅读"这个点云,左右互搏,信息互补。
-
顺序指示器 (Order Indicator):
- 干啥:告诉 Mamba 当前读的是哪种序列。
- 做法 : Z = T o k e n ⊙ γ + β Z = Token \odot \gamma + \beta Z=Token⊙γ+β。给特征加一个可学习的"时间戳"。虽然只有区区 1.5k 参数,但去掉了它,精度直接掉 2 个点!
加上公式后: E A 和 E B E_A和E_B EA和EB是mamba得到的特征
对于 Hilbert 序列: Z A = E A × 标签 1 + 偏移 1 Z_A = E_A \times \text{标签}_1 + \text{偏移}_1 ZA=EA×标签1+偏移1
对于 Trans-Hilbert 序列: Z B = E B × 标签 2 + 偏移 2 Z_B = E_B \times \text{标签}_2 + \text{偏移}_2 ZB=EB×标签2+偏移2
对于每个点得到两组特征,进行拼接。
3. 炼丹实录:简单即是美 (Simple is Best) 🔥
这篇论文最"反内卷"的地方在于它的网络设计。PointMamba 没有使用任何花哨的分层结构(Hierarchical)或复杂的注意力头。
3.1 架构:拒绝花哨
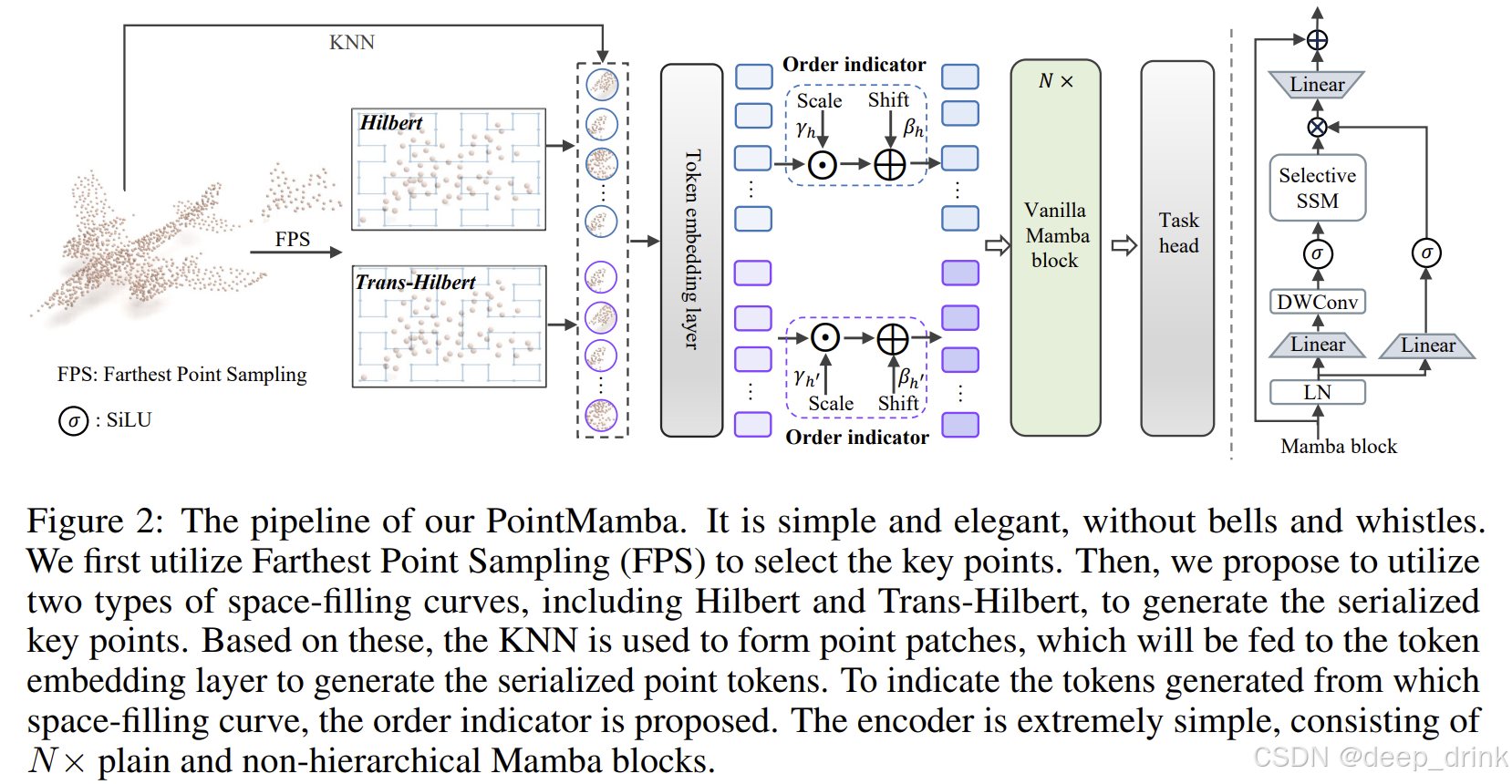
- 传统做法:像 PointNet++ 那样做多层 Downsampling(下采样),或者像 Point Transformer 那样堆复杂的 Attention Block。
- PointMamba 做法 :Vanilla Mamba (原味 Mamba) 。
- 直接堆叠 N N N 个标准的 Mamba Block,不做分层,不搞特殊设计。
- 这种"直筒子"结构,配合 O ( N ) O(N) O(N) 的复杂度,让推理速度起飞。
3.2 排序策略大比拼:随机 vs. Hilbert
作者做了一个非常硬核的消融实验,证明了"怎么排队"比"怎么卷积"更重要:
- Random (随机排序):SOTA 守门员水平。证明了 Mamba 确实怕乱序。
- Hilbert Only:精度提升明显。
- Hilbert + Trans-Hilbert :王者水平 (94.32%)。双视角扫描带来了质变。
3.3 预训练:蒙眼还原
作者还顺手搞了个 Masked Modeling(掩码预训练)。
- 玩法:随机选一种排序,遮住 60% 的点,让 Mamba 猜被遮住的点在哪里。
- 结论:即使是单向模型,也能通过这种方式学到强大的 3D 上下文信息。
4. 实验结果:降维打击 📊
作者拿着这个架构简单的 PointMamba,去挑战那些设计精密的 Transformer 巨兽。结果非常打脸:
4.1 精度:登顶 SOTA
在最难的 ScanObjectNN (PB-T50-RS) 数据集上:
- PointMamba : 89.31%
- PointGPT-S: 89.17%
- Point-MAE: 85.18%
PointMamba 在没用 Transformer 的情况下,干掉了 Transformer 的巅峰之作。
4.2 效率:这才是真正的"降维打击"
这才是本文的高光时刻:
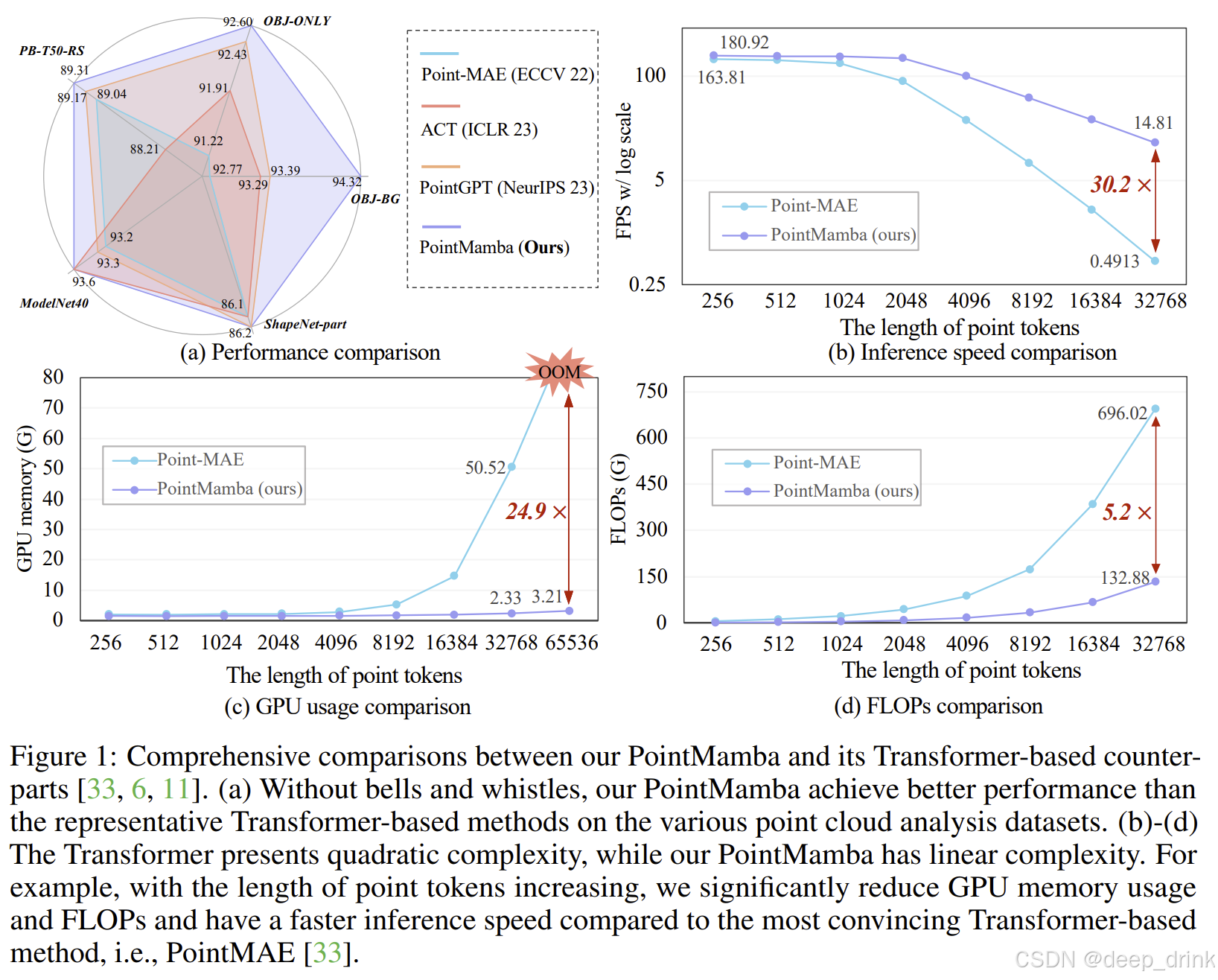
- 当点数增加到 32K 时:
- 显存占用 :PointMamba 只有 Point-MAE 的 1/25(24.9x)。
- 推理速度 :PointMamba 比 Point-MAE 快了 30 倍(30.2x)。
- 计算量 (FLOPs) :降低了 5 倍。
这意味着什么? 意味着在同样的显卡上,Transformer 只能跑几千个点,而 PointMamba 可以轻松跑几万甚至几十万个点的超大场景,而且是实时处理!
5. 总结 (Conclusion)
PointMamba 给火热的 3D Vision 泼了一盆冷水,也指了一条明路:
- 数据结构 > 网络结构:与其在网络层级里疯狂堆算子,不如想想怎么把数据组织好(Hilbert Serialization)。把 3D 变成 1D,降维攻击最为致命。
- Transformer 不是唯一解:SSM(状态空间模型)证明了它在 3D 领域完全可以替代 Attention,而且快得多。
- 极简主义的胜利:不需要分层,不需要复杂的几何算子,只要顺序对,Vanilla Mamba 就能教做人。
📚 参考文献
1 Liang, D., Zhou, X., Xu, W., Zhu, X., Zou, Z., Ye, X., Tan, X., & Bai, X. (2024). PointMamba: A Simple State Space Model for Point Cloud Analysis. NeurIPS.
💬 互动话题:
- 关于 Mamba 的未来:你觉得 Mamba 会像 Transformer 取代 RNN 一样,在 3D 领域全面取代 Transformer 吗?还是说这只是昙花一现?
- 关于排序:除了 Hilbert 曲线,你还能想到什么把 3D 点云变 1D 序列的好方法?(PTv3里面有很多排序)
📚 附录:点云网络系列导航
🔥 欢迎订阅专栏 :【点云特征分析_顶会论文代码硬核拆解】持续更新中...
本文为 CSDN 专栏【点云特征分析_顶会论文代码硬核拆解】原创内容,转载请注明出处。