提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- [1. 初识](#1. 初识)
-
- [1.1 单体架构](#1.1 单体架构)
- [1.2 应⽤数据分离架构](#1.2 应⽤数据分离架构)
- [1.3 应⽤服务集群架构](#1.3 应⽤服务集群架构)
-
- [1.4 负载均衡](#1.4 负载均衡)
- [1.5 读写分离 / 主从分离架构](#1.5 读写分离 / 主从分离架构)
- [1.6 引⼊缓存⸺冷热分离架构](#1.6 引⼊缓存⸺冷热分离架构)
- [1.7 数据库分库分表](#1.7 数据库分库分表)
- [1.8 引入微服务](#1.8 引入微服务)
- [1.9 其他概念](#1.9 其他概念)
- [2. 特性介绍](#2. 特性介绍)
- [3. 应用场景](#3. 应用场景)
- [4. redis安装](#4. redis安装)
- [5. 通用命令](#5. 通用命令)
-
- [5.1 get和set](#5.1 get和set)
- [5.2 keys](#5.2 keys)
- [5.3 生产环境](#5.3 生产环境)
- [5.4 exists](#5.4 exists)
- [5.5 del](#5.5 del)
- [5.6 expire](#5.6 expire)
- [5.7 ttl](#5.7 ttl)
- [5.8 redis的过期策略:面试题](#5.8 redis的过期策略:面试题)
- [5.9 定时器实现原理](#5.9 定时器实现原理)
- [5.10 type](#5.10 type)
- 总结
前言
1. 初识
Redis:内存中存储数据,分布式系统中更优,单体系统的话,就在这个系统里面定义变量存储不是更好吗
分布式系统共享变量?------》进程间通信-------》Redis
Redis可以作为数据库来使用,缺点就是存储空间比较小
Redis与MYSQL结合:热点数据存储到Redis中,全部数据存储到MySQL
这样就可以又大又快了
存储空间大,访问速度快
Redis可以做消息中间件,但是一般做缓存
分布式系统
1.1 单体架构
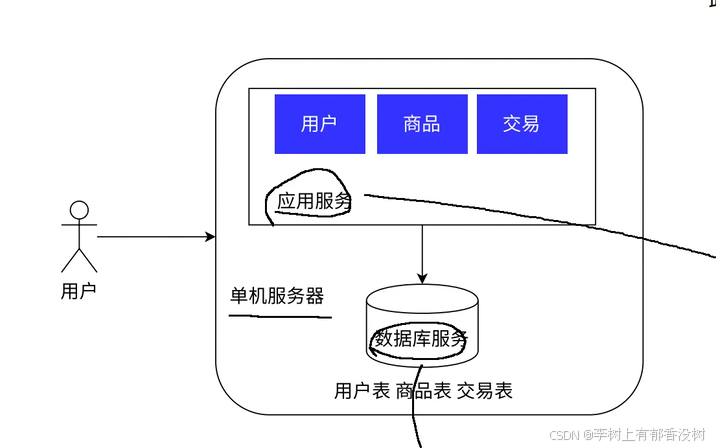
这里的数据库服务其实是一个客户端服务器结构的程序
为什么要分布式,一台主机顶不住了,如果用户量和访问量很多的话,其实这个是无奈之举
1.2 应⽤数据分离架构
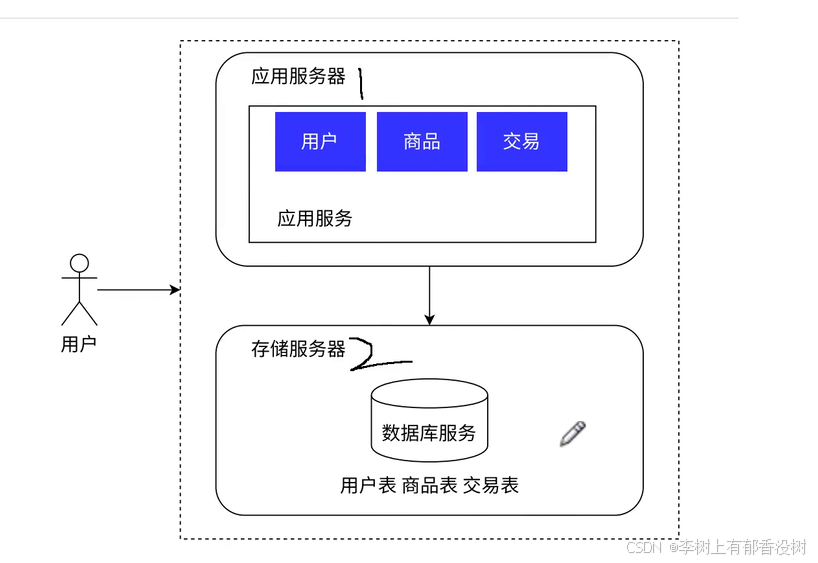
意思就是数据库和应用分别部署到两个主机上
如果部署到一台主机上,意思就是同样的硬件资源,需要给两个人用
分别部署的话,就是自己用自己的硬件资源,自己的CPU
应用服务器:需要大的CPU的主机
数据库服务器:需要大的硬盘的主机
1.3 应⽤服务集群架构
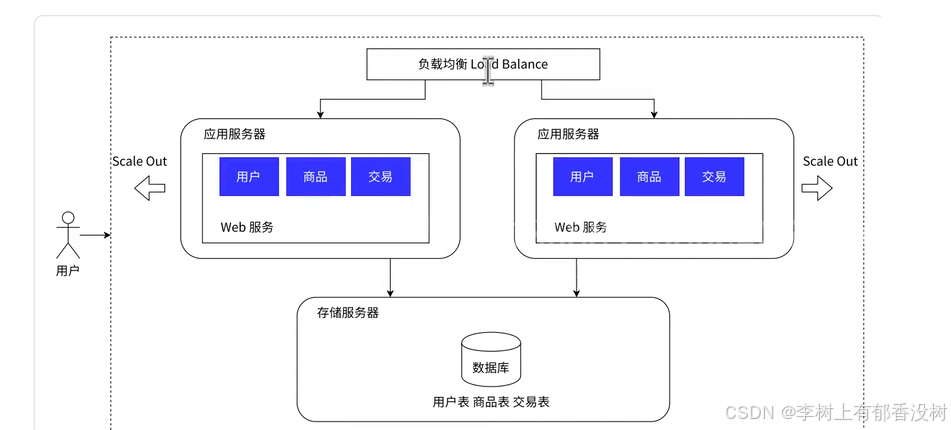
应用可能比较吃CPU和内存,把请求分摊处理,一人处理一点
1.4 负载均衡
负载均衡软件:Nginx、HAProxy、LVS、F5 等
负载均衡器只是分配请求,所以可以处理很多请求,已经处理一个请求的分配要不了多少资源,不像应用服务器
如果一个负载均衡器不行了---》可以设置多个负载均衡器
1.5 读写分离 / 主从分离架构
开源(引入更多节点)+节流(优化代码)
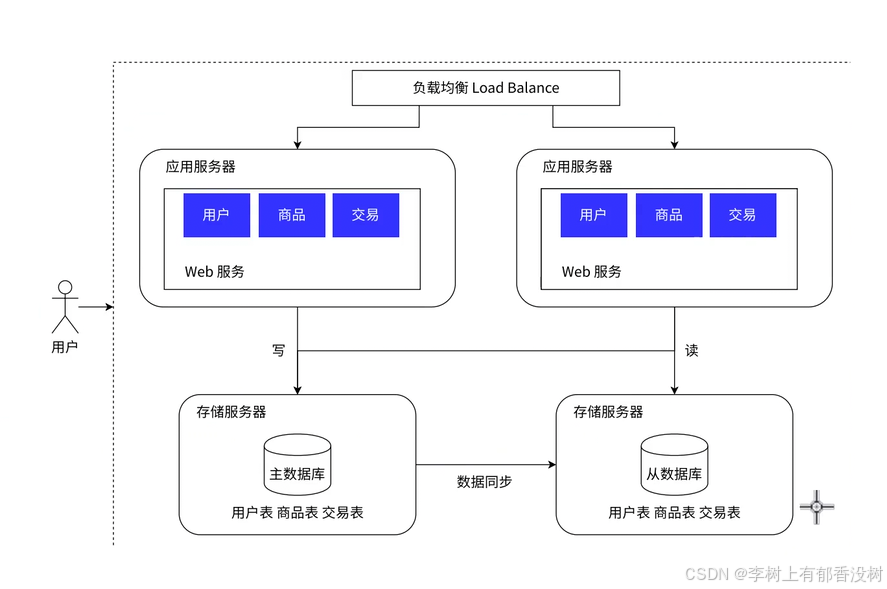
主master
从slave
主一般一个
从一般多个
一主多从
1.6 引⼊缓存⸺冷热分离架构
是因为数据库响应速度太慢了
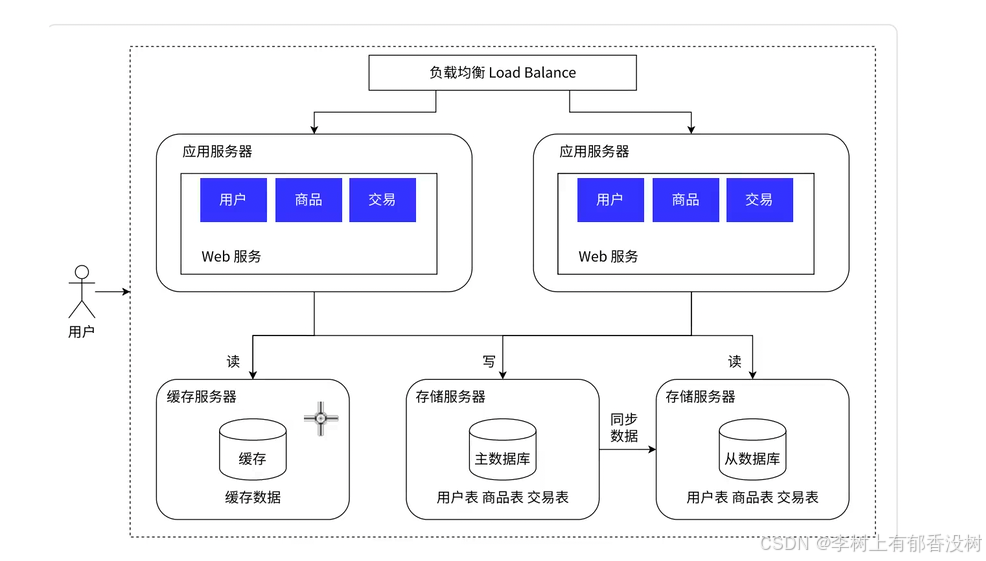
缓存的数据是热点数据
二八原则:20%的数据能够支持80%的访问量
数据库存储的仍然是全量数据
1.7 数据库分库分表
就是一台服务器存不下数据了怎么办---》就需要多台主机来存储
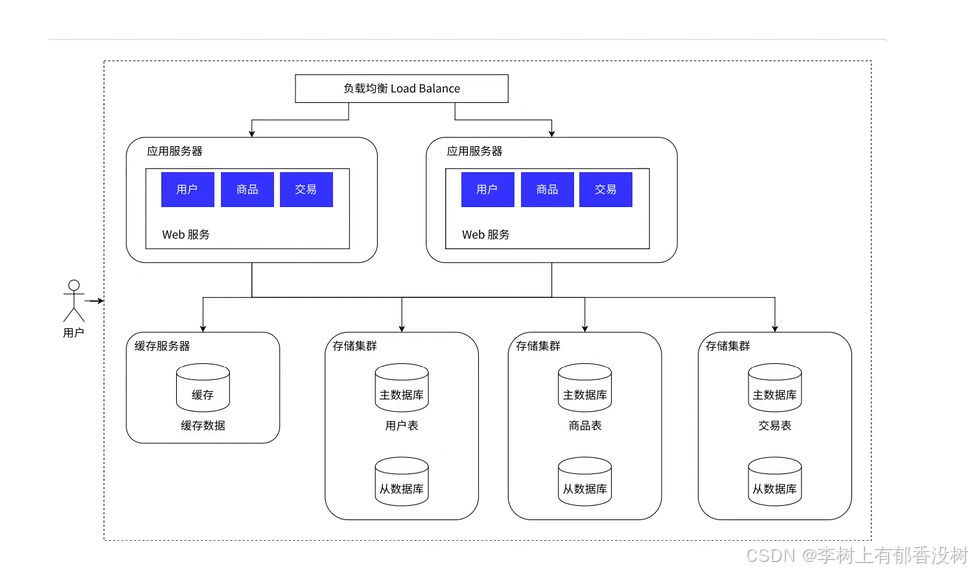
本来一个数据库服务器有多个数据库database
但是现在一个数据库服务器就存储一个数据库或者一部分数据库了
如果一个表太大了,存不下--》分表,把一个表分为五个表,然后每个数据库存一个表
1.8 引入微服务
就是一个应用服务器只负责一个业务
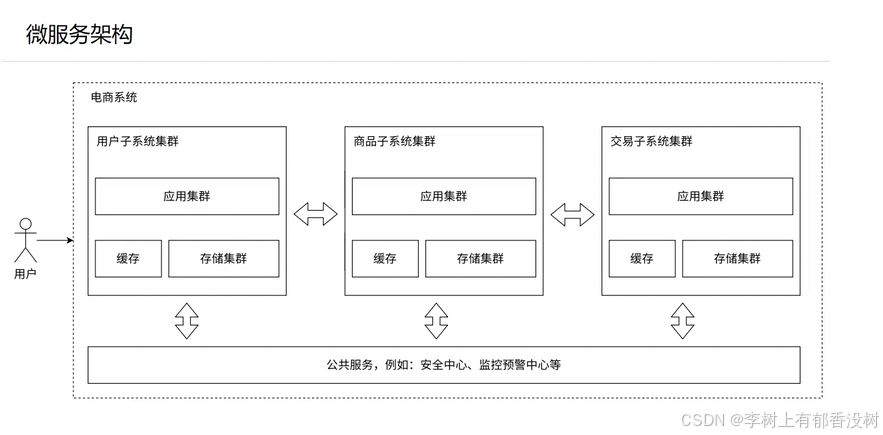
优点:有利于人员的分配,有利于功能的复用,可以给不同的服务进行部署不同的机器(垃圾服务配置垃圾机器)
但是缺点就是
- 系统的性能下降
因为网络通信比硬盘访问还要慢---》需要的设备要求高 - 系统复杂程度提高,可用性有影响---》服务器多了,出现的问题就变多了---》需要丰富的监控报警,以及配套的运维人员
1.9 其他概念
一个应用,就是一个或一组服务器程序
一个应用里面有很多的功能,每个独立的功能就是一个模块或者组件
分布式:多个主机或者多个服务器,物理上的多个主机
集群:多个主机或者多个服务器,逻辑上的多个主机
主从:
中间件:和业务无关的服务(功能更通用的服务)
比如数据库,缓存,消息队列
可用性:系统整体可用时间 / 总的事件
越大越好
响应时间衡量服务器的额性能,越小越好
吞吐量与并发:衡量系统处理请求的能力
2. 特性介绍
MySQL:通过表得到方式来存储:关系型数据库
Redis是通过键值对的方式来存储组织数据,非关系型数据库:不是按照表的形式来存储
key是String,value是数据结构
redis会把数据存储到硬盘中,这样redis重启,数据也就恢复了
可以部署多个redis,每个redis存储数据的一部分
redis可以弄主从,从节点是主节点的备份,主节点挂了,从节点就变为主节点了
为什么redis快
因为数据在内存中
redis的核心功能都是比较简单的逻辑:都是操作内存的数据结构
redis使用了io多路复用的方式,epoll,使用一个线程来管理很多个socket
redis使用得到是单线程模型--》减少了线程之间的竞争开销
redis是用C语言开发的
多线程提高效率得到前提,这是一个cpu密集型任务,使用多个线程可以充分利用cpu多核资源
redis的核心任务是操作内存的数据结构,不会吃cpu,单核就很快了,多核没有什么提升,而且多核还要加锁
吞吐量大,访问要快:redis
3. 应用场景
redis做数据库:存储全量数据
redis做缓存:存热点数据
redis存储用户身份信息,session
redis可以作为消息队列服务器:基于这个可以实现
redis不能做的事情:存储大规模数据
4. redis安装
java
su切换到root用户
java
docker pull redis:5.0.7
java
netstat -anp | grep redisredis不用配置密码,为什么呢,因为非常安全,因为我们的数据不值钱,所以非常安全,因为缓存数据,不可能缓存密码那种的
进入容器
java
docker exec 容器名 -it bash
redis-cli可进入redis客户端,链接到redis
Ctrl+c就可以退出
要么就是exit
要么就是ctrl+D
Mysql和redis都是客户端-服务器 结构的程序
可以有多个客户端,服务器只有一个
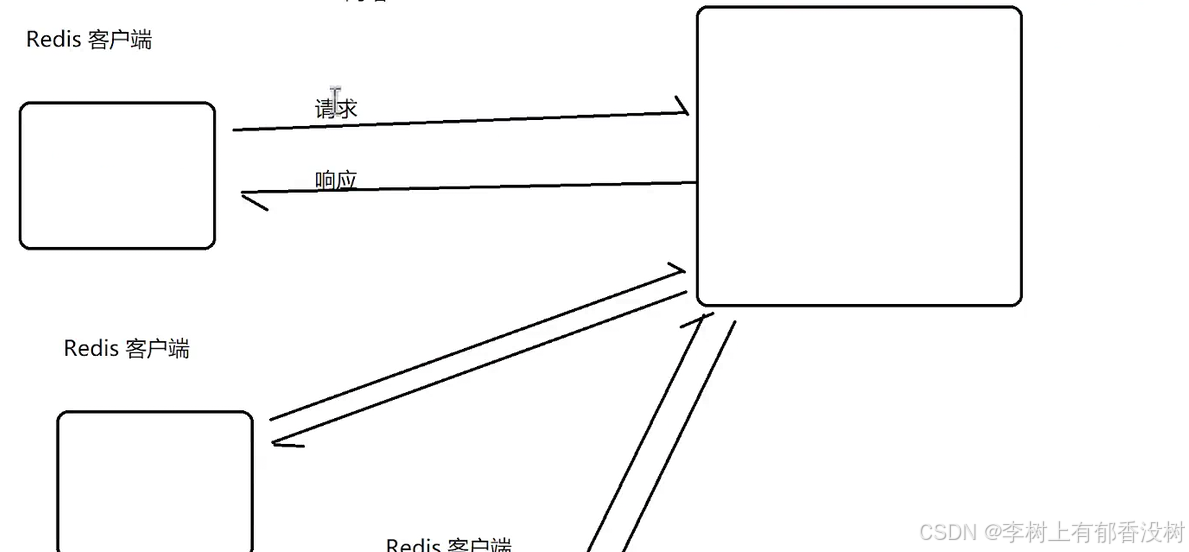
redis客户端
第一个是自带的:redis-cli
第二个是链接外地的
redis-cli -h 127.0.0.1 -p 6379
第三种就是图形化界面的客户端
第四种就是基于redis的api自行开发客户端(最重要)
存储用户点赞数:可以用redis来存,因为是分布式的
java
auth 密码如果redis-cli的时候没有指定密码,那么进入redis的时候在指定密码也是可以的
5. 通用命令
5.1 get和set
java
set key valuekey和value都必须是字符串,写数字也是当做字符串
java
127.0.0.1:6379> set key1 value1
OK
127.0.0.1:6379> set key2 1111
OK
127.0.0.1:6379> set "key2" "1111"
OK这样也是可以的,加不加字符串都是一样的
redis中不区分大小写的
java
get key1
set的时候没有加引号,get的时候还是有引号的
如果key不存在,会返回nil
其实就是null
5.2 keys
返回所有满⾜样式(pattern)的 key
key固定就是字符串,value有很多类型(字符串,哈希表,列表,集合,有序集合)
java
keys patternpattern是通配符的格式
就是获取什么类型的key
java
h?llo 匹配 hello , hallo 和 hxllo
• h*llo 匹配 hllo 和 heeeello
• h[ae]llo 匹配 hello 和 hallo 但不匹配 hillo
• h[^e1]llo 匹配 hallo , hbllo , ... 但不匹配 hello
• h[a-b]llo 匹配 hallo 和 hbllo问号就是匹配任意的一个字符
星号就是匹配0个或者任意字符
abe表示只能选a或者选e或者b
第四个表示排除e和1的任意一个字符,可以排除多个
第五个表示匹配a到b的任意一个,左右都是闭区间
keys的时间复杂度是o(N)
所以一般静止使用
java
keys *这个就是获取所有的key
redis是一个单线程服务,所哟ksys *的时间太长,可能就会阻塞其他的服务调用redis
5.3 生产环境
办公环境:WIndows,台式机,笔记本
开发环境:可能和办公环境就是一样的
测试环境:测试工程师使用
线上环境(生产环境,前面三个环境都是线下环境):外界用户可以访问到
5.4 exists
这个的作用就是判断一个key是否存在
java
EXISTS key [key ...]时间复杂度:O(1):因为组织这些key就是按照哈希表来组织
返回值:key 存在的个数。
java
127.0.0.1:6379> exists key1 key2
(integer) 2
bash
127.0.0.1:6379> exists key1
(integer) 1redis是一个客户端服务器的程序,客户端和服务器之间通过网络来进行通信
所以一次全部判断更好,效率更高
多个exists的话,就会进行多次网络通信
5.5 del
删除指定的 key
可以一次删除一个或者多个key
bash
DEL key [key ...]时间复杂度:O(1)
返回值:删除掉的 key 的个数。
bash
127.0.0.1:6379> del key1
(integer) 1
127.0.0.1:6379> keys *
1) "key2"redis中是作为缓存的,存的只是热点数据,所以这里的删除不是危险操作
如果redis就是作为数据库---》删除key的话就是危险操作了
redis作为mq的话,这里的误删数据就要具体问题具体分析了
5.6 expire
给key奢姿过期时间的
为指定的 key 添加秒级的过期时间(Time To Live TTL)
返回值:1 表⽰设置成功。0 表⽰设置失败
设置时间----》比如手机验证码,五分钟内有效
基于redis还可以实现分布式锁,为了避免不能出现解锁的情况,可以给锁设置过期时间,过期时间到了就自动释放锁了
bash
EXPIRE key seconds
bash
pexpire这个是设置毫秒
bash
127.0.0.1:6379> set hello 3
OK
127.0.0.1:6379> expire hello 10
(integer) 1注意设置key的过期时间,key必须是存在的
5.7 ttl
获取指定 key 的过期时间,秒级
返回值:剩余过期时间。-1 表⽰没有关联过期时间,-2 表⽰ key 不存在。
EXPIRE 和 TTL 命令都有对应的⽀持毫秒为单位的版本:PEXPIRE 和 PTTL
bash
127.0.0.1:6379> set hello 3
OK
127.0.0.1:6379> expire hello 10
(integer) 1
127.0.0.1:6379> ttl hello
(integer) 6
bash
127.0.0.1:6379> ttl hello
(integer) -25.8 redis的过期策略:面试题
redis怎么知道哪些key过期了,哪些key已经过期了要被删除,哪些key还没过期
直接遍历所有的key----》不好
redis整体的策略:定期删除,惰性删除
惰性删除:就是使用的时候再去判断有没有过期,要不要删除,过期了就删除,返回空值nil
定期删除:每隔一段时间去扫描key,看有没有过期,但是每次遍历很慢-----》每次抽取一部分来验证过期时间,看有没有过期
为什么要抽取一部分呢,因为是单线程的,所以不能扫描全部,导致太慢,不然其他请求就阻塞了,和keys *是一样的道理
但是虽然这样----》也可能会有一些过期的key没有被删除
redis还提供一些内存淘汰策略
为什么redis不采取定时器来删除呢,有过期时间,然后定时器来删除---》可能是:定时器---》要引入多线程,,,,,但是redis最初就是设定了单线程的
5.9 定时器实现原理
定时器就是某个时间到达之后,执行指定对的任务:比如删除key
- 基于优先级队列/堆:按照指定的优先级,先出,我们可以把过期时间短的放在堆顶,这样就可以优先删除,这样就可以实现定时器了,所以堆顶就是最早要过期的元素,所以分配一个线程,取检查堆顶元素,取判断看他有没有过期,但是线程在扫描的时候,也不能一直while循环一直查询,可以根据当前时刻和队首元素的过期时间,设置一个休眠或者等待时间,当时间到了,就可以唤醒这个线程了,这样就OK了,如果出现了新的任务---》时间更短--->可以唤醒线程,重新等待
第二种就是可以根据时间轮来实现定时器,把时间划分为很多小段,
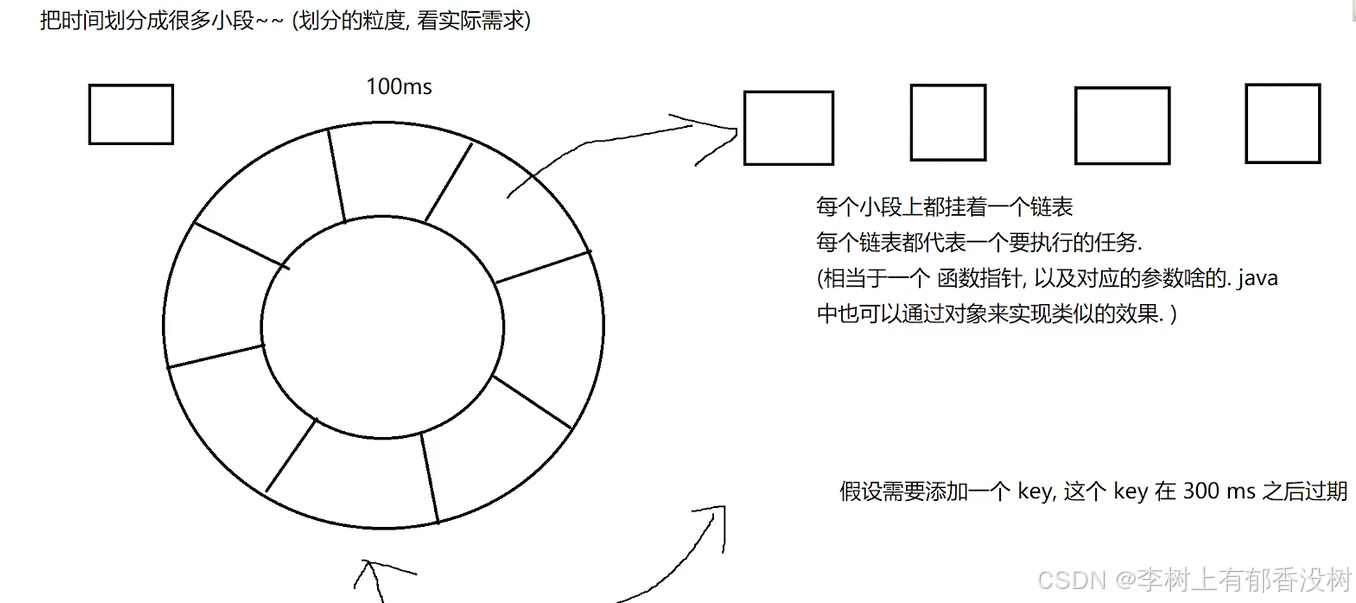

注意redis是没有用到定时器对的
5.10 type
返回 key 对应的数据类型
返回值: none , string , list , set , zset , hash and stream .。
stream 是作为消息队列的时候
bash
127.0.0.1:6379> keys *
1) "key2"
127.0.0.1:6379> set key1 111
OK
127.0.0.1:6379> type key1
string
127.0.0.1:6379> lpush key2 111 222 333
(error) WRONGTYPE Operation against a key holding the wrong kind of value
127.0.0.1:6379> lpush key3 111 222 333
(integer) 3
127.0.0.1:6379> type key3
list
127.0.0.1:6379> lpush就是相当于链表的头插
bash
127.0.0.1:6379> sadd key4 11 22 33
(integer) 3
127.0.0.1:6379> type key4
set
127.0.0.1:6379>
bash
127.0.0.1:6379> hset key5 field1 value1
(integer) 1
127.0.0.1:6379> type key5
hash
127.0.0.1:6379> 不同类型操作方式不一样
总结
当前redis支持十个数据类型,但是我们经常用的是五个,string,list,set,hash,Zset