set
基本介绍
set是一个集合,集合就是把一些有关系的数据放在一起。
- 集合中的元素是无序的,这里的无需代表着顺序不重要,变换一下顺序,集合还是原本的集合。
- 集合中的元素是不能重复的。
- 和list类似,集合中的每个元素都是string类型,虽然说是string类型,那我们可以使用json格式存储一些结构化数据。
基本命令
sadd,smembers和sismember
sadd:用于在集合中添加数据,返回值表示成功添加了几个元素,因为集合中的元素是不能重复的,所以不一定所有的元素都会被添加进去。
bash
sadd key member1[member2....]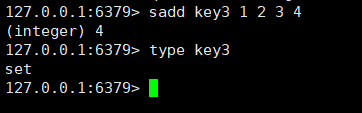
smembers:可以获取一个集合中的所有元素。
bash
smembers key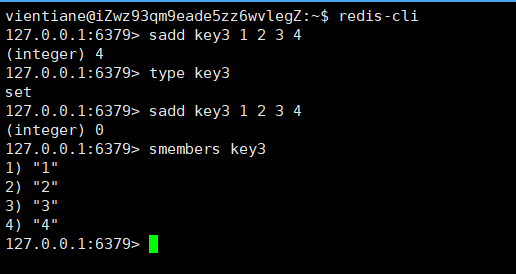
sismember:判断一个元素是否在集合里。
bash
sismember key member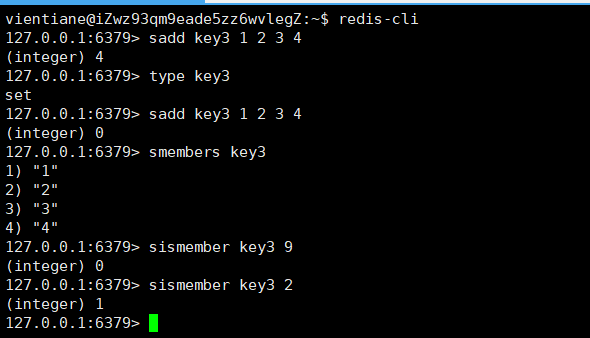
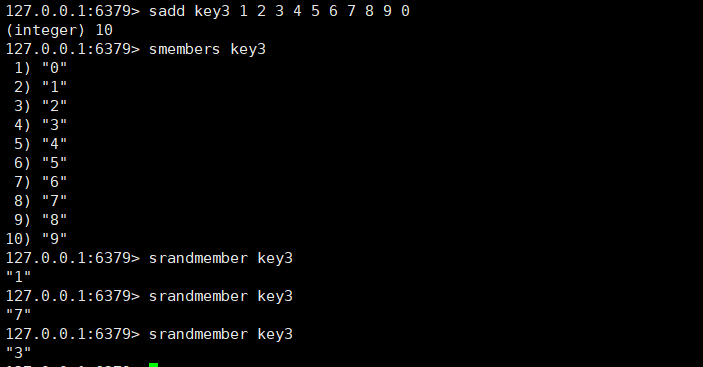
spop和srandmember
spop:spop删除元素的时候是随机删除,count不写的时候代表只删除一个,如果count有指定的话,写几个就删除几个,除非集合元素没有比count大。
bash
spop key [count]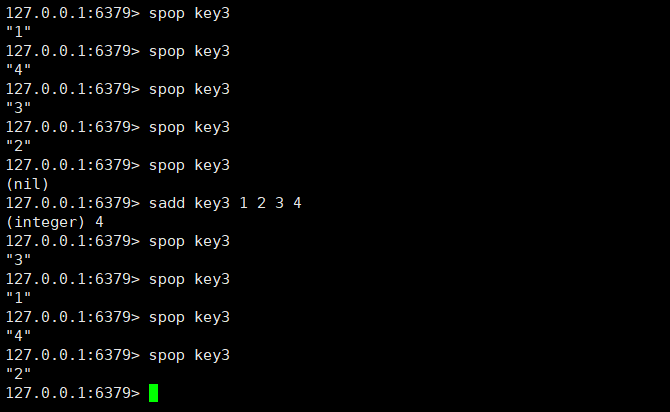
srandmember :可以获得其中一个随机的元素。
smove和srem
smove :这个指令是将一个元素从一个集合移动到另外一个集合。
集合有一个特性就是不能重复,如果要将一个元素从a集合移动到b集合,而b集合中已经存在这个元素了,那么在执行指令的时候,a集合中这个元素就消失了,而b集合中元素不会发生改变。
如果我们要移动的元素在source不存在的时候,会返回0,表示移动失败。
bash
smove source destination member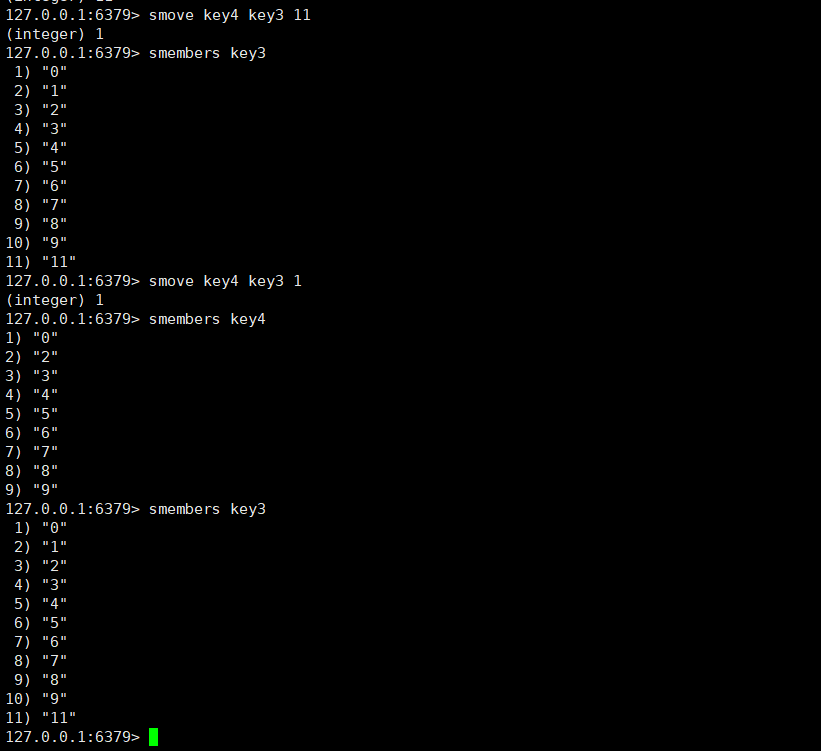
srem:可以对集合中的元素进行删除,返回值表示删除成功的元素个数。
bash
srem key member [member1 .....]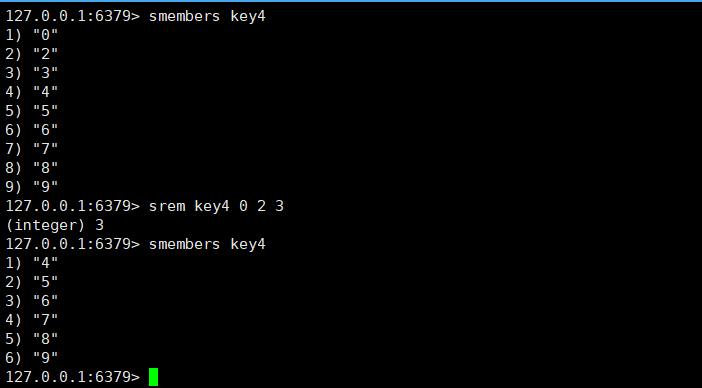
sinter和sinterstore
用于求交集,并集和补集。
sinter:用于求一个集合或者多个集合的交集,时间复杂度为O(M*N)。
bash
sinter key1 [key2 ...]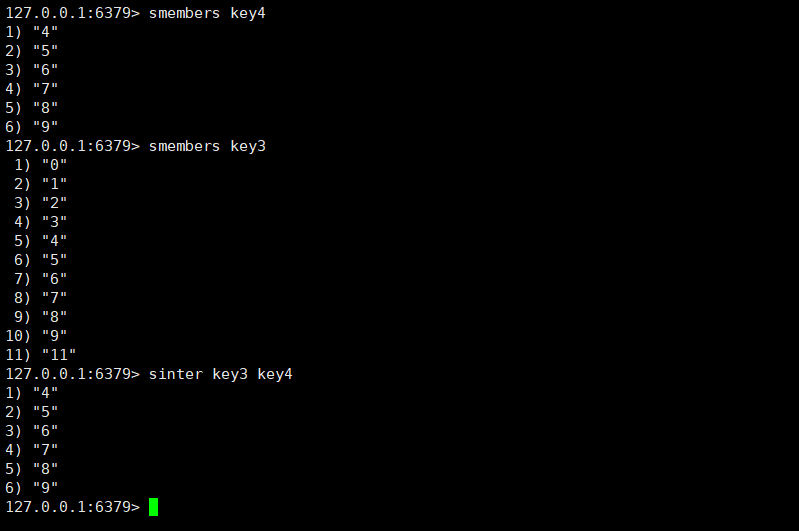
sinterstore:功能类似于sinter,但不再是以返回值的方式告诉我们了,而是可以存储到destination里。
bash
sinterstore destination key1 [key2....]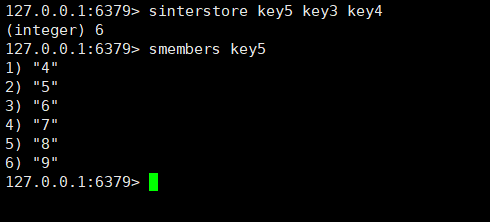
sunion,sunionstore,sdiff,sdiffstore
sunion:这个命令返回的是并集的数据。
bash
sunion key1 [key2....]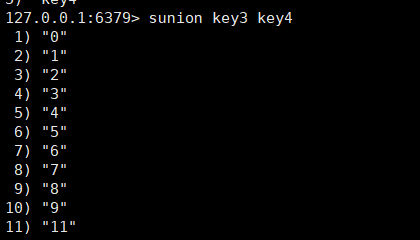
sunionstore:功能类似于sunion,但不再是以返回值的方式告诉我们了,而是可以存储到destination里。
bash
sunionstore destination key1[key2...]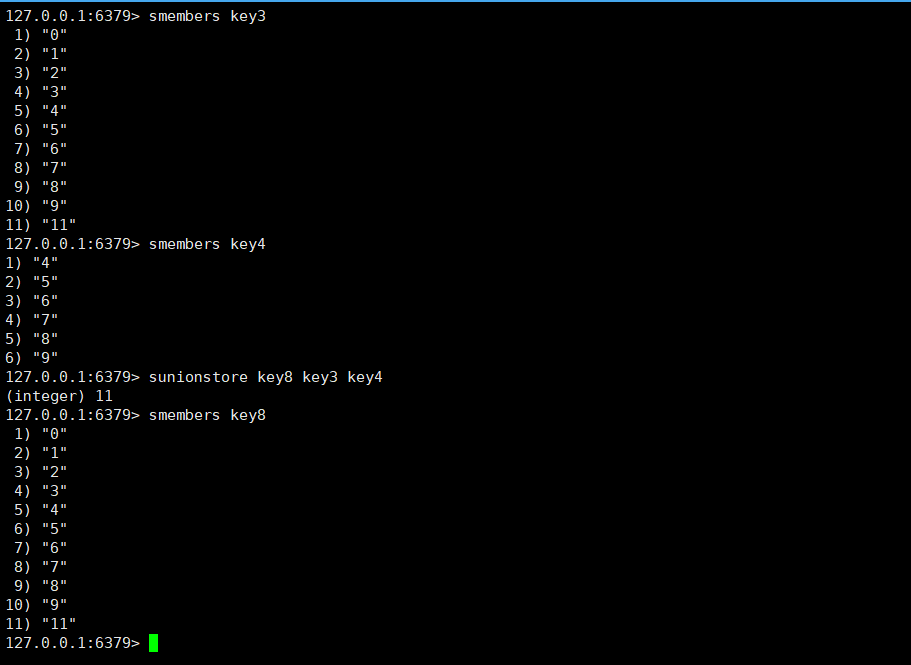
sdiff:这个命令返回的是集合的差集。
bash
sdiff key1 [key2...]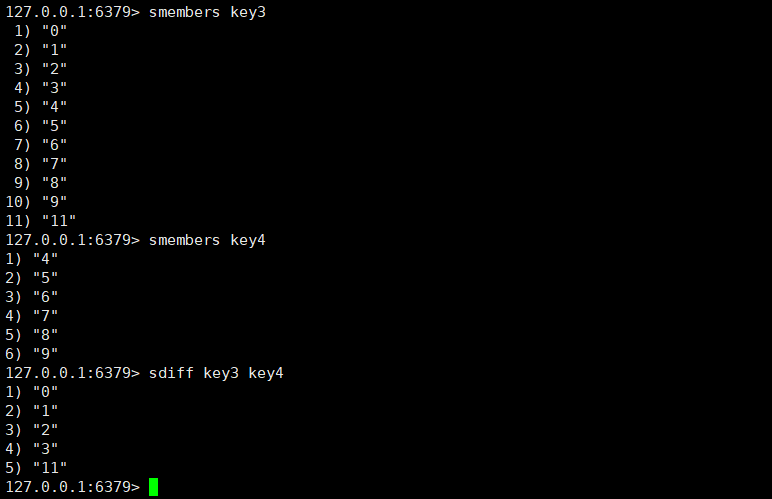
sdiffstore:功能类似于sdiff,但不再是以返回值的方式告诉我们了,而是可以存储到destination里。
bash
sdiffstore destination key1[key2....]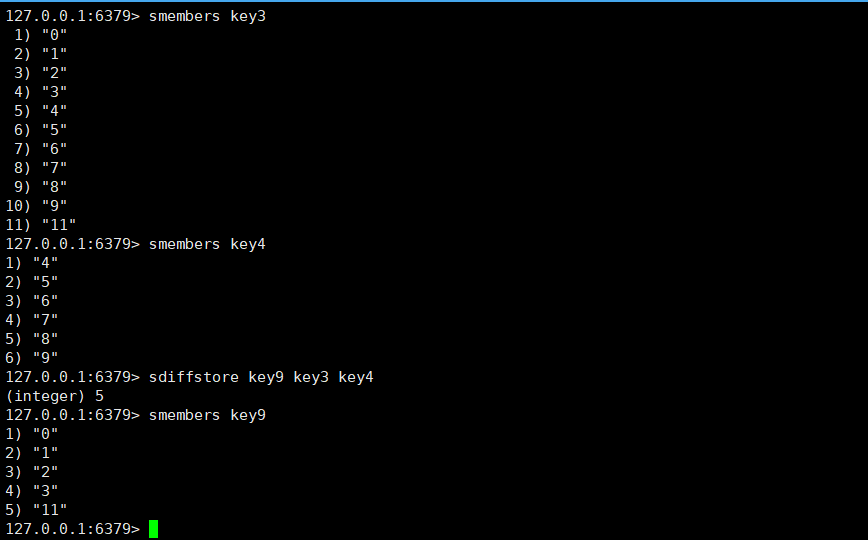
内部编码
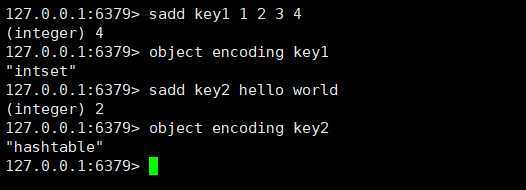
集合内部的编码方式主要有两种,一种是intset(当集合中的元素都是整数并且元素的个数小于 set-max-intset-entries配置时,Redis会选用intset来作为集合的内部实现,从而减少内存的使用),另外一种是哈希表(当集合类型无法满足intset的条件时,Redis会使用hashtable作为集合的内部实现)。
应用场景
- 用于保存用户的标签:也就是用户画像,分析出用户的特征再保存,可以通过交集来找到用户之间的共同标签,找到用户关系。
- 使用set来找到用户之间的共同好友。
zset
基本介绍
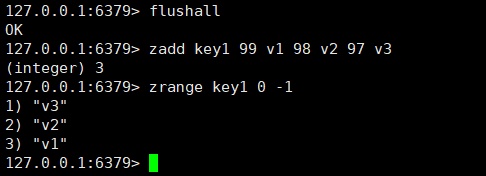
zset是有序的集合,这里的有序是升序的意思。
排序的规则是:给zset中每一个member引入一个属性--分数,是一个浮点类型的值,进行排序的时候,就是依照此处的分数大小进行排序的。
zset存的元素依旧要求不能重复,而分数是可以重复的。
基本命令
zadd
这个命令可以往一个zset有序集合中添加一个元素和分数,时间复杂度为O(log N),这里的N表示此有序集合的元素个数。
bash
zadd key [NX|XX] [GT|LT] [CH] [INCR] score member [score1 member1...]- XX和NX:当不加NX和XX选项的时候,不存在的member就新增,存在的member就更新。XX表示当member存在的时候才会更新,member不存在则不进行操作。NX表示当前不存在的才会新增,如果存在就不进行任何操作。
- LT和GT:表示小于和大于,LT表示在更新分数的时候,给定的分数比之前的分数小才会更新成功,GT表示在更新分数的时候,给定的分数比之前的大,才会更新成功,如果是新增分数,则不会限制添加。
- CH:表示当前的返回值要返回什么信息,zadd返回值表示被添加的元素个数,如果加了CH,不仅会告诉我们添加的元素个数,还会告诉我们被修改的元素个数。
- INCR:针对现有的元素分数去进行一些新增运算。
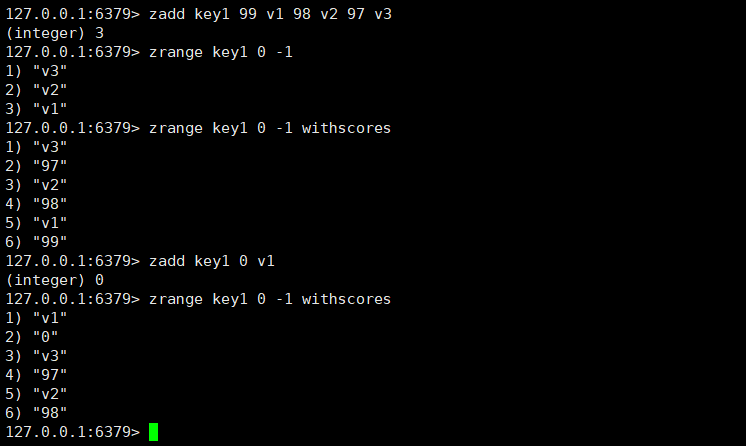
当两个元素的分数相同的时候,就按照元素本身的字典序来排序,如果分数不同,则按照元素的分数来排序。
如果进行修改元素,修改的元素顺序影响到了原本顺序,就会自动进行调整。
zcard和zcount
zcard:用于获取一个zset里元素的个数。
bash
zcard key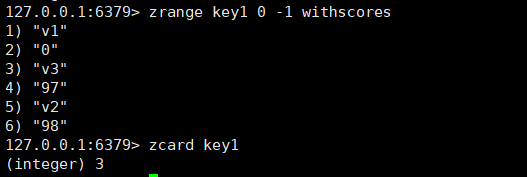
zcount :返回分数在min和max之间的元素个数,默认是一个闭区间的,如果想要开区间,那么可以加上括号。
zcount里是支持inf和-inf写法的,表示无穷大和负无穷大。
bash
zcount key min max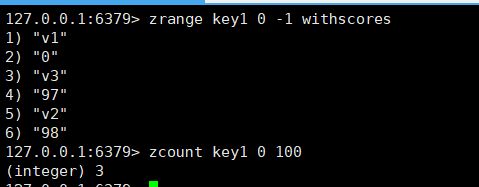
如果想要查询开区间的话,左开右闭的时候:
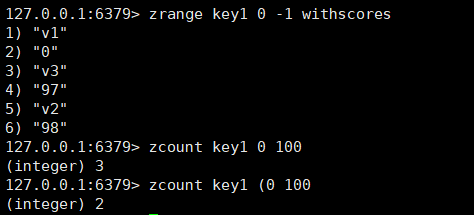
左右都是开区间的时候:
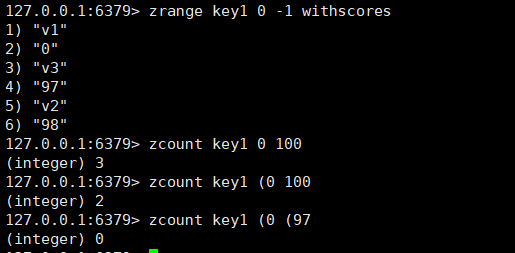
zrange,zrevrange和zrangebyscore
zrange:用于获取start和stop中间的元素,如果加上withscores选项,在展示元素的时候,元素的下一行就是元素的分数。
bash
zrange key start stop [withscores]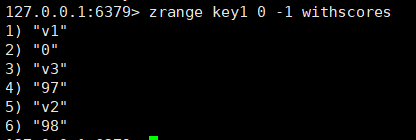
zrevrange:用于获取start和stop中间的元素,并且以逆序的形式展示,如果加上withscores选项,在展示元素的时候,元素的下一行就是元素的分数。
bash
zrevrange key start stop [withscores]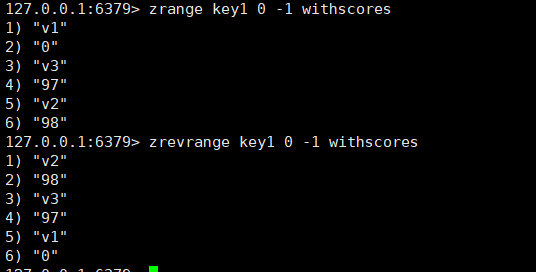
zrangebyscore:按照分数来找元素,zcount是查找min和max区间内元素的个数,而这个命令是将这些元素都打印出来。
bash
zrangebyscore key min max [withscores]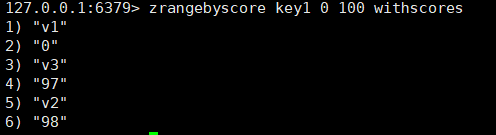
zpopmax
这个指令用于删除并且返回分数最高的元素,如果没有使用count则只删除一个,如果使用count可以删除count个(元素足够的情况下),返回值包括member和score。
bash
zpopmax key [count]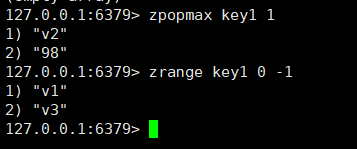
在删除的时候,如果存在多个元素分数相同,且都是最大值,最后会按照member的字典序来区分。
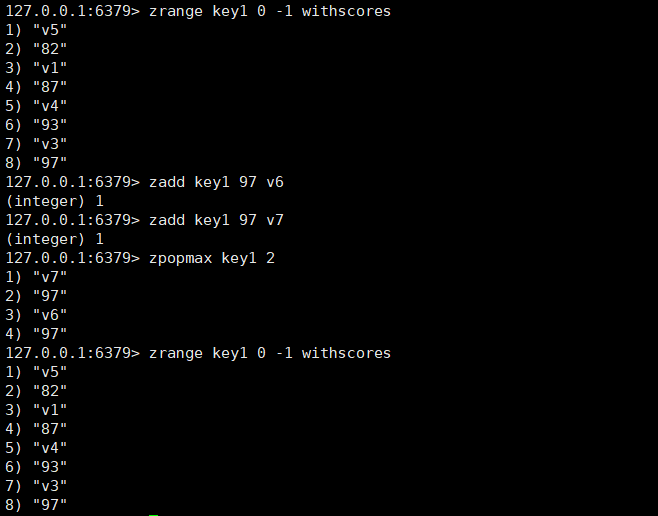
bzpopmax
b表示阻塞,在阻塞集合为空的时候会阻塞,当其中某个key里有元素的时候就会解除阻塞,或者在timeout时间以后会自动解除阻塞,timeout的单位是秒,支持小数。
如果有序集合中已经存在元素,就不会阻塞,没有存在元素的时候才会阻塞。
bash
bzpopmax key1 [key2 key3....] timeout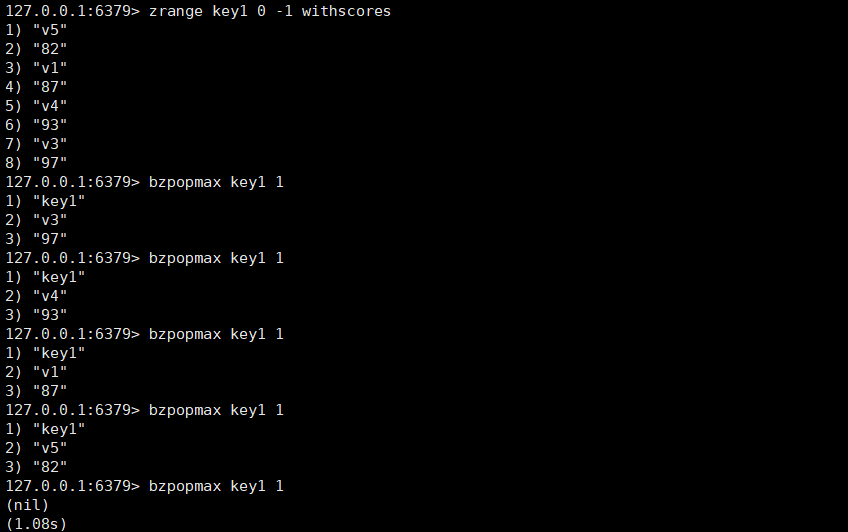
zpopmin和bzpopmin
zpopmin:这个指令用于删除并且返回分数最低的元素,如果没有使用count则只删除一个,如果使用count可以删除count个(元素足够的情况下),返回值包括member和score。
bash
zpopmin key [count]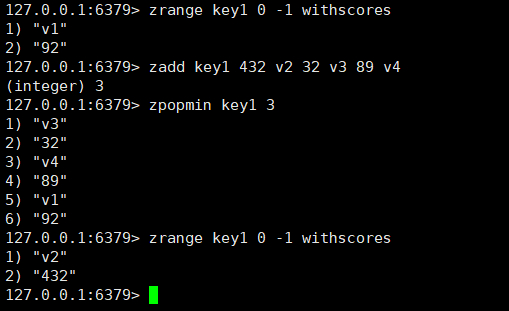
bzpopmin :b表示阻塞,在阻塞集合为空的时候会阻塞,当其中某个key里有元素的时候就会解除阻塞,或者在timeout时间以后会自动解除阻塞,timeout的单位是秒,支持小数。
如果有序集合中已经存在元素,就不会阻塞,没有存在元素的时候才会阻塞。
bash
bzpopmin key1 [key2 key3....] timeout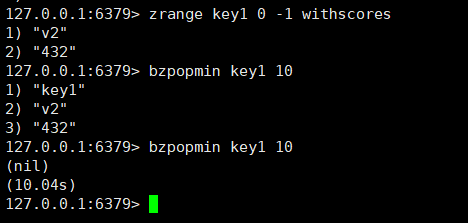
zrank,zrevrank和zscore
zrank:可以查询member 的排名,下标是从小到大算的。
bash
zrank key member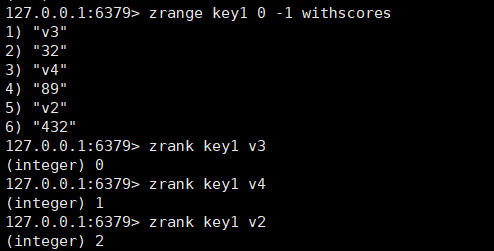
zrevrank:可以查询member的排名,和zrank相反,下标是从大到小算的。
bash
zrevrank key member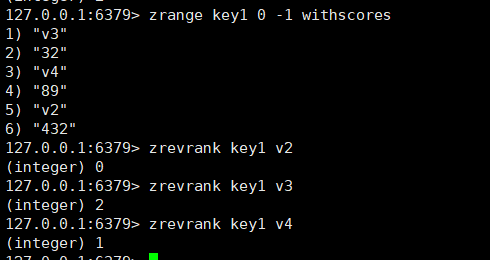
zscore:这个指令可以根据member查询到对应的分数,时间复杂度是O(1),这里原本应该和前面一样,时间复杂度都是O(log N)的,但做了特殊优化,所以现在的时间复杂度为O(1)。
bash
zscore key member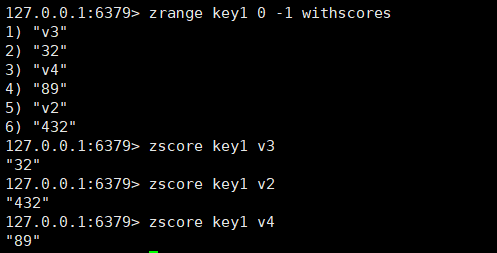
zrem,zremrangebyrank和zremrangebyscore
zrem:这个指令用于删除zset里的元素,返回值表示成功删除的元素个数。
bash
zrem key member1 [member2...]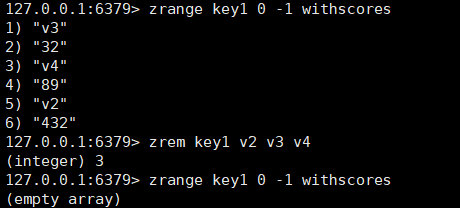
zremrangebyrank:用于根据下标删除指定rank区间里的member,这里的区间是闭区间,时间复杂度为O(M+log N)。
bash
zremrangebyrank key start stop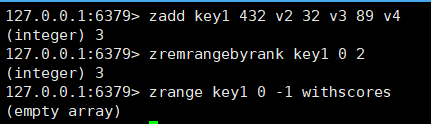
zrangebycore:用于根据分数删除指定区间的member,start和stop是闭区间,可以使用括号来排除边界值的。
bash
zrangebyscore key start stop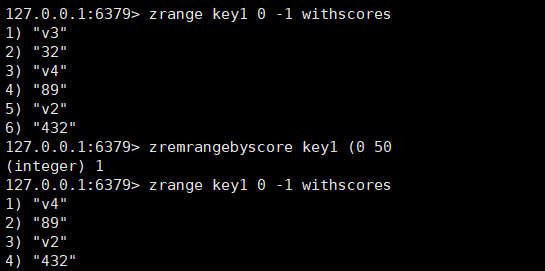
zincrby
这个命令为指定元素的关联分数添加指定的分数值,时间复杂度为O(log N),这里的increment可以是负数,如果添加分数以后,zset的顺序被破坏,会重新调整顺序的。
bash
zincrby key increment member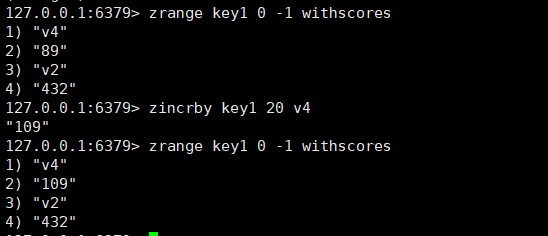
zinterstore和zunionstore
zinterstore :用于求zset集合之间member的交集,把结果存储在destination里。
number表示后续有几个key参与交集运算,需要number的原因是key的后面还存在别的参数。
bash
zinterstore destination number key1 [key2...] [weighs weight1 [weight2....] ] [aggregate <sum |min |max> ]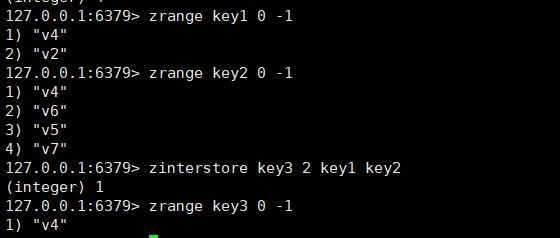
- weights指的是权重:有序集合是有权重的,可能key1权重为1,也就是key1的所有member的分数都乘以1,key2权重为19,也就是key2的所有member的分数都乘以19,以此类推,表示有序集合的重要程度。
- 由于多个集合之间的元素,member相同,但score可能不同,所以就需要aggregate,这个参数指的是分数的计算方式。分为三种,一种是求和,比如说key1有一个member为v1,分数为10,key2有一个member为v1,分数为20,如果我们选择了sum,那么最后得到的有序集合里v1的分数就是30,另外两个参数分别指的是最大和最小值,如果不写默认是求和sum选项。
zunionstore :用于求zset集合之间member的并集,把结果存储在destination里。
number表示后续有几个key参与并集运算,需要number的原因是key的后面还存在别的参数。
bash
zunionstore destination number key1 [key2...] [weighs weight1 [weight2....] ] [aggregate <sum |min |max> ]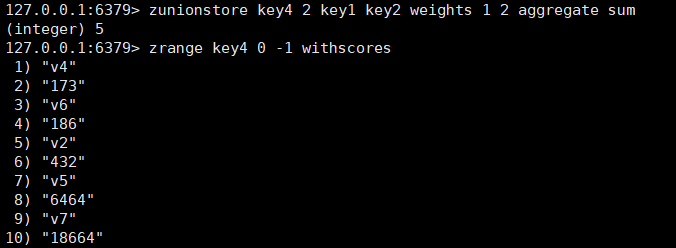
- weights指的是权重:有序集合是有权重的,可能key1权重为1,也就是key1的所有member的分数都乘以1,key2权重为19,也就是key2的所有member的分数都乘以19,以此类推,表示有序集合的重要程度。
- 由于多个集合之间的元素,member相同,但score可能不同,所以就需要aggregate,这个参数指的是分数的计算方式。分为三种,一种是求和,比如说key1有一个member为v1,分数为10,key2有一个member为v1,分数为20,如果我们选择了sum,那么最后得到的有序集合里v1的分数就是30,另外两个参数分别指的是最大和最小值,如果不写默认是求和sum选项。
编码方式
zset主要是两种编码方式,如果zset中的元素个数较少,或者单个元素体积较小,会采用ziplist进行编码,可以节省空间,但消耗的时间比较多。
如果zset中元素较多,或者单个元素体积较大,就会使用skiplist来存储。
