Prometheus+Grafana构建云原生分布式监控系统(六)![]() https://blog.csdn.net/xiaochenXIHUA/article/details/157256935
https://blog.csdn.net/xiaochenXIHUA/article/details/157256935
一、prometheus监控hadoop集群
1.1、Linux中安装部署Hadoop集群的保姆级安装配置教程
Linux中安装部署Hadoop集群的保姆级安装配置教程![]() https://blog.csdn.net/xiaochenXIHUA/article/details/154075870
https://blog.csdn.net/xiaochenXIHUA/article/details/154075870
1.2、prometheus监控hadoop原理
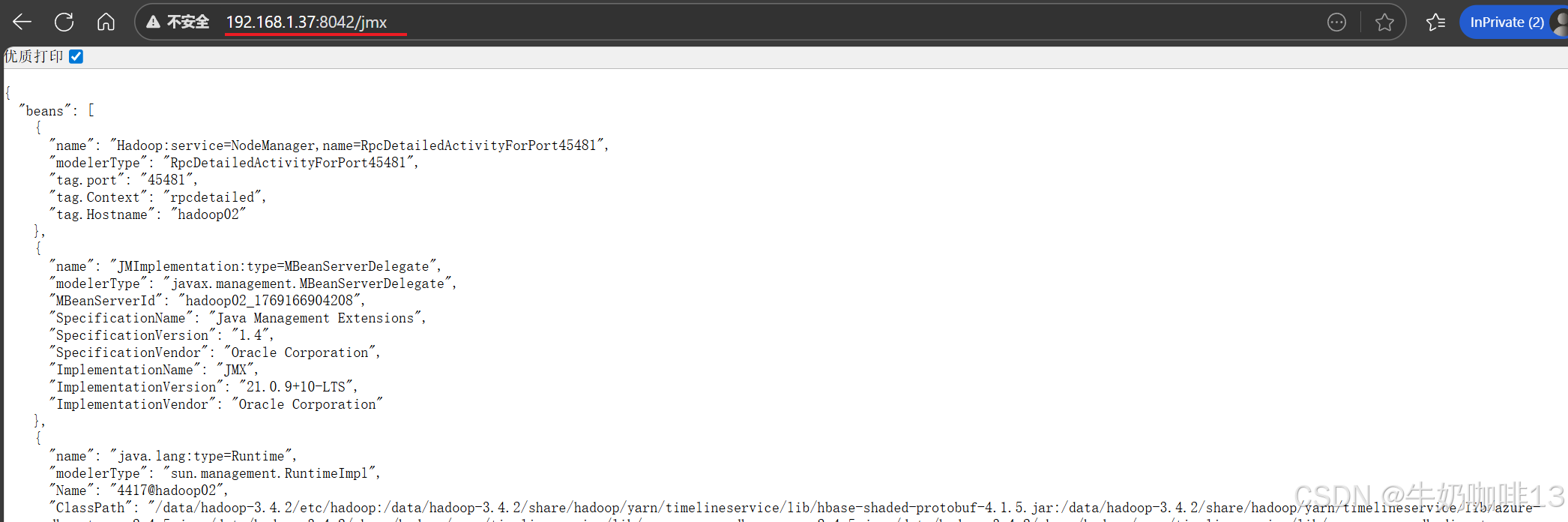
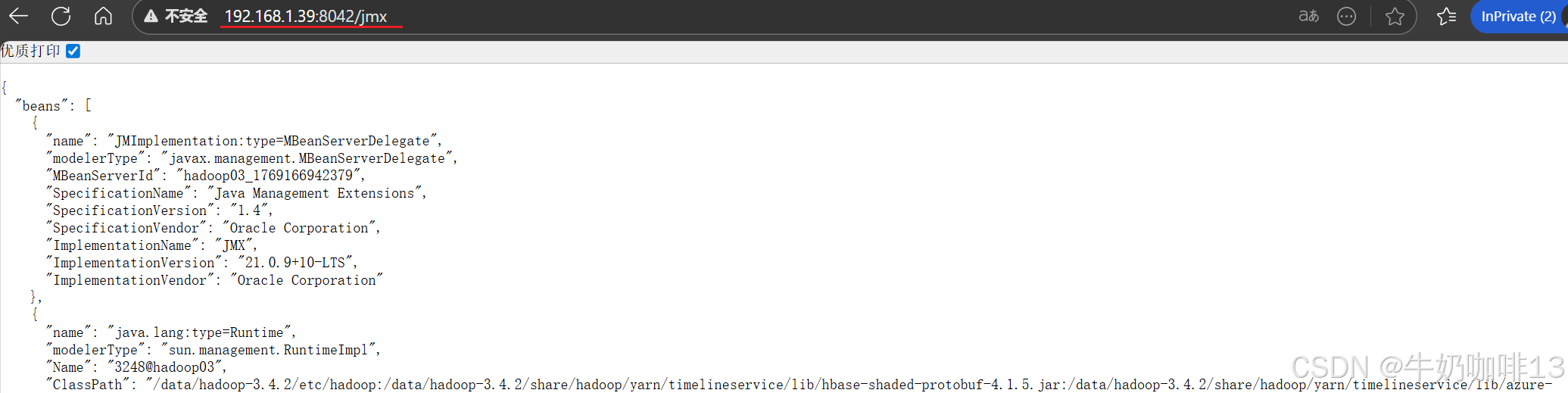
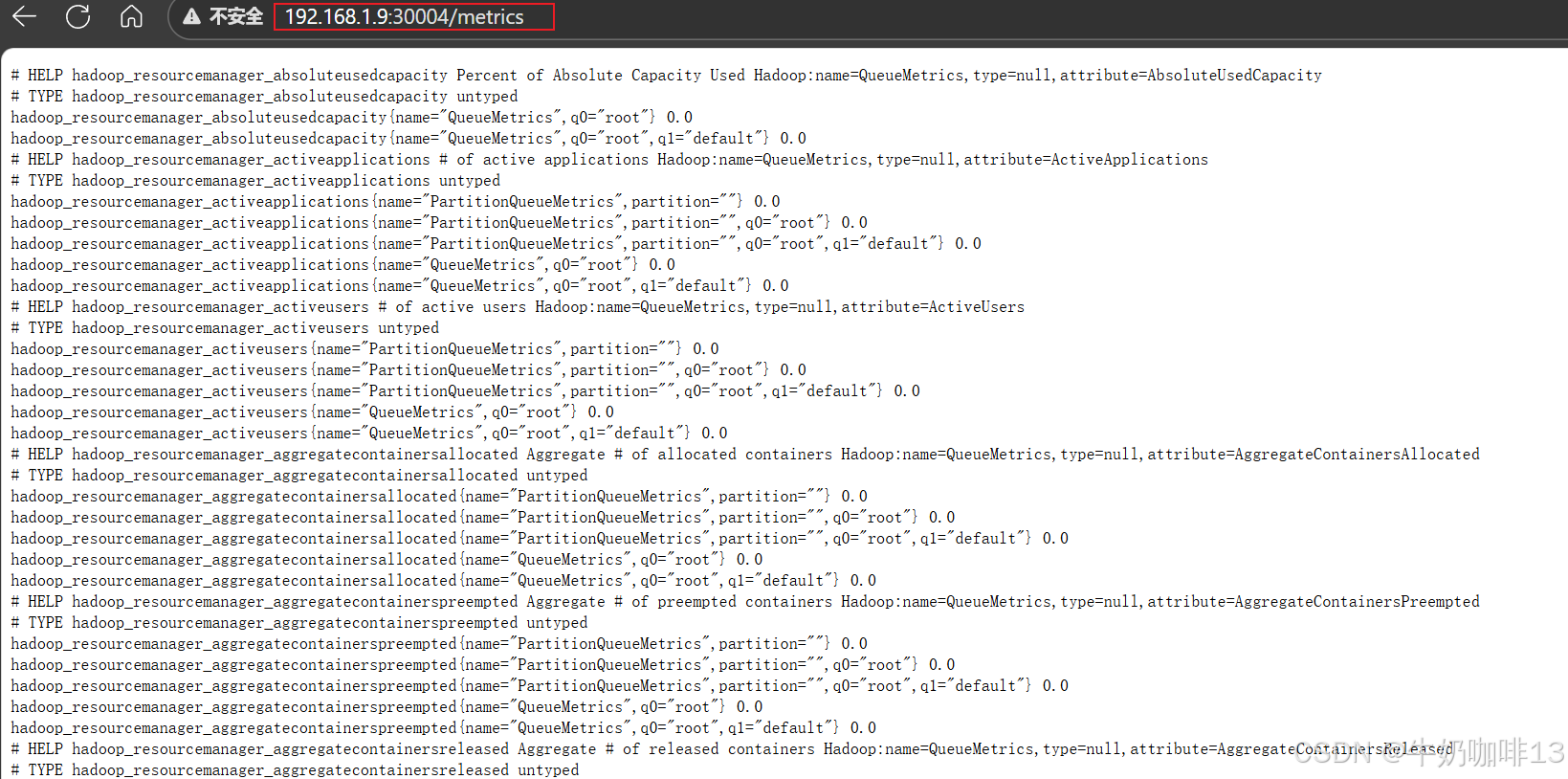
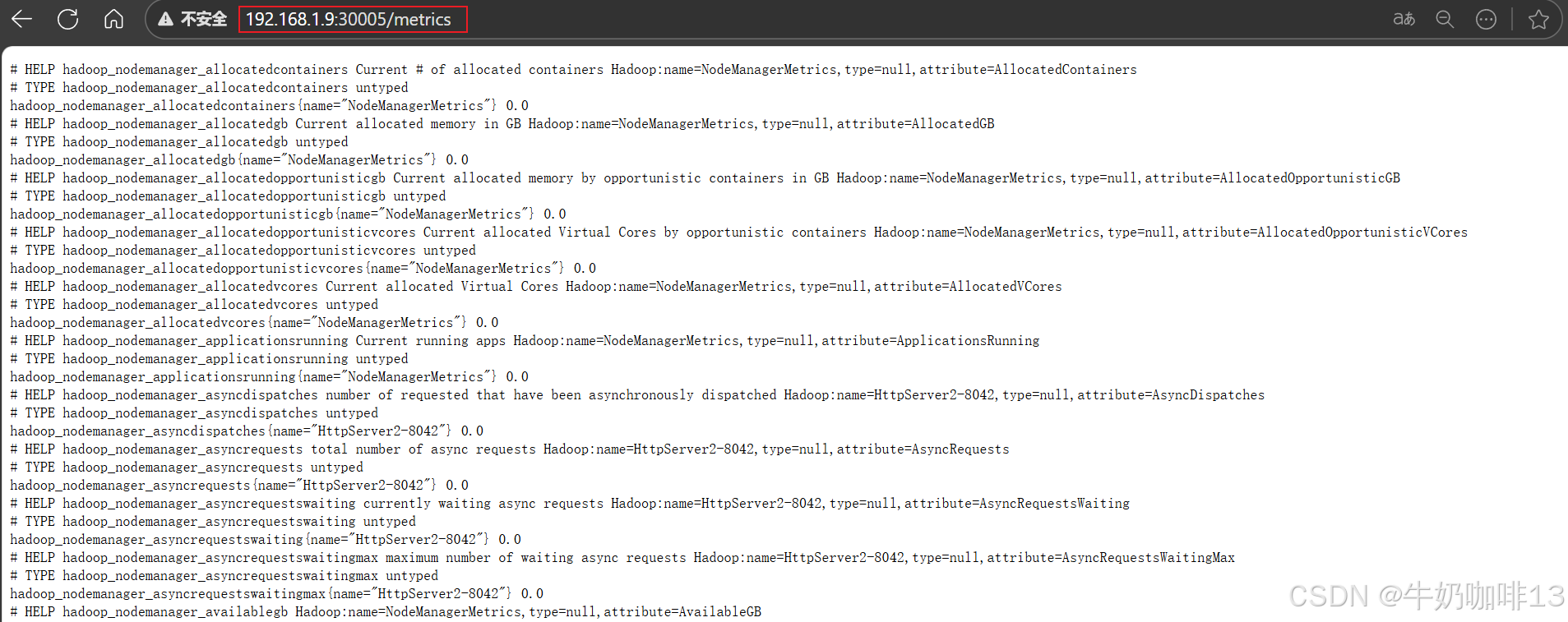
prometheus监控hadoop,其实是通过http方式访问hadoop namenode、resourcemanager、datanode、nodemanager的web页面端口获取监控数据,本文的namenode地址为192.168.1.9(Almalinux9),端口为9870, resourcemanager地址为192.168.1.9,端口为8088,因此获取数据的地址如下(但由于这些界面输出的结果都是json格式数据,prometheus无法识别这些数据,因此要借助【jmx-exporter】来实现数据格式的转换):
bash
#1-namenode的状态页面
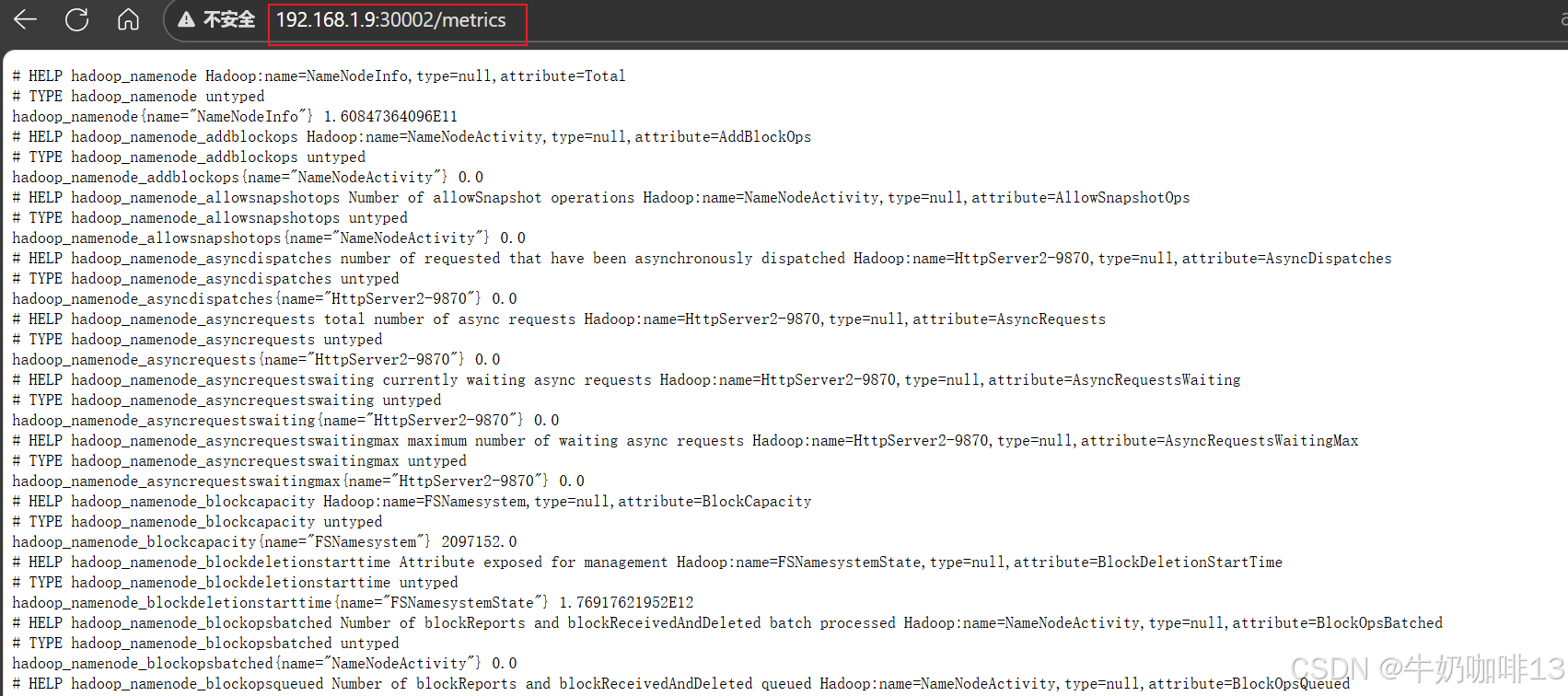
http://192.168.1.9:9870/jmx
#2-resourcemanager状态页面
http://192.168.1.9:8088/jmx
#3-datanode状态页面(有三个)
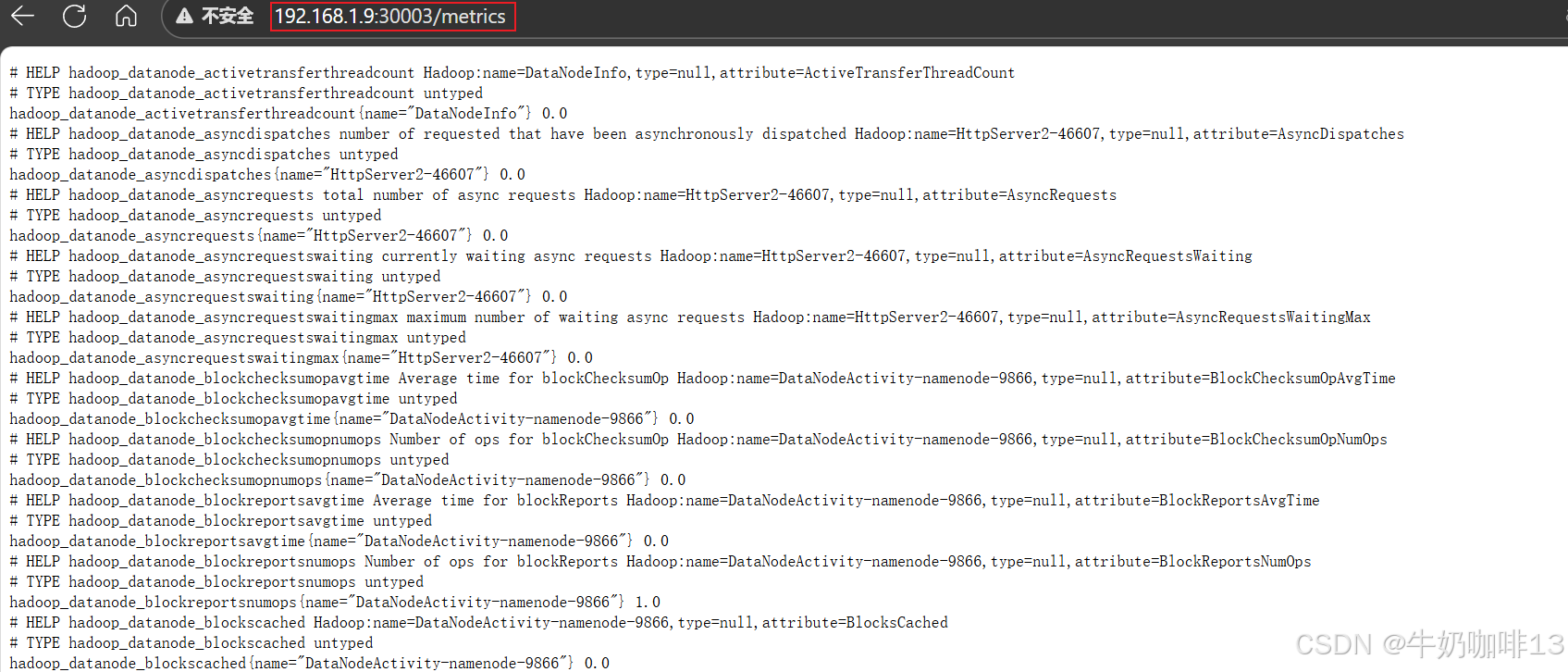
http://192.168.1.9:9864/jmx
http://192.168.1.37:9864/jmx
http://192.168.1.39:9864/jmx
#4-nodemanager状态页面(有三个)
http://192.168.1.9:8042/jmx
http://192.168.1.37:8042/jmx
http://192.168.1.39:8042/jmx
1.3、使用jmx-exporter将数据适配为prometheus可识别格式
对hadoop监控,需要对namenode、resourcemanager、datanode、nodemanager、historyserver、journalnode、zkfc等基础组件进行监控,若hadoop还集成有spark、hbase、hive、kafka等,也需要对这些组件进行监控。操作方法基本一样(首先,需要创建每个组件的配置文件,启动jmx_exporter的时候需要指定配置文件,配置文件可以为空,但不能没有。因此,需要为每个组件创建一下配置文件,暂时设置为空就好。接着,修改hadoop的hadoop-env.sh文件)。
如下是:分别是将namenode、datanode、resourcemanager和nodemanager输出的jmx格式数据转换为prometheus可识别的格式,对应的访问端口分别是3002、3003、3004、3005。若要增加其他组件,操作方法类似:
注意:如下的配置操作要在hadoop集群每个角色都进行配置,配置完成,重启服务即可。
bash
#使用jmx-exporter将数据适配为prometheus可识别格式
#1-下载jmx-exporter
wget https://github.com/prometheus/jmx_exporter/releases/download/1.5.0/jmx_prometheus_javaagent-1.5.0.jar -c -P /data
#2-创建【namenode.yaml】【datanode.yaml】【resourcemanager.yaml】【nodemanager.yaml】文件
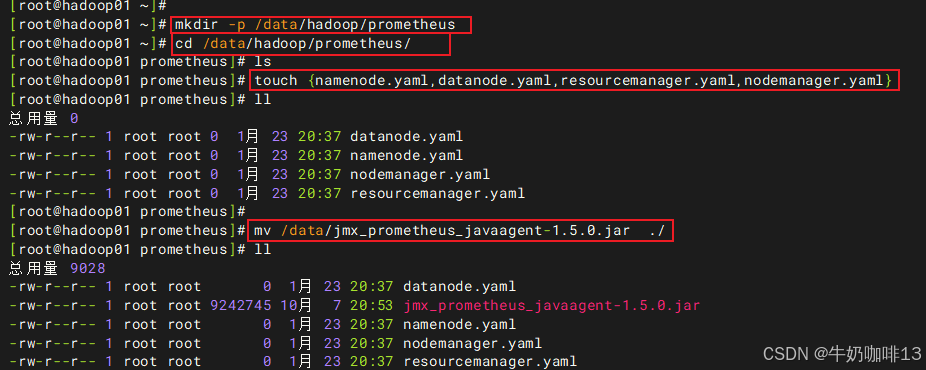
mkdir -p /data/hadoop/prometheus
cd /data/hadoop/prometheus/
touch {namenode.yaml,datanode.yaml,resourcemanager.yaml,nodemanager.yaml}
mv /data/jmx_prometheus_javaagent-1.5.0.jar ./
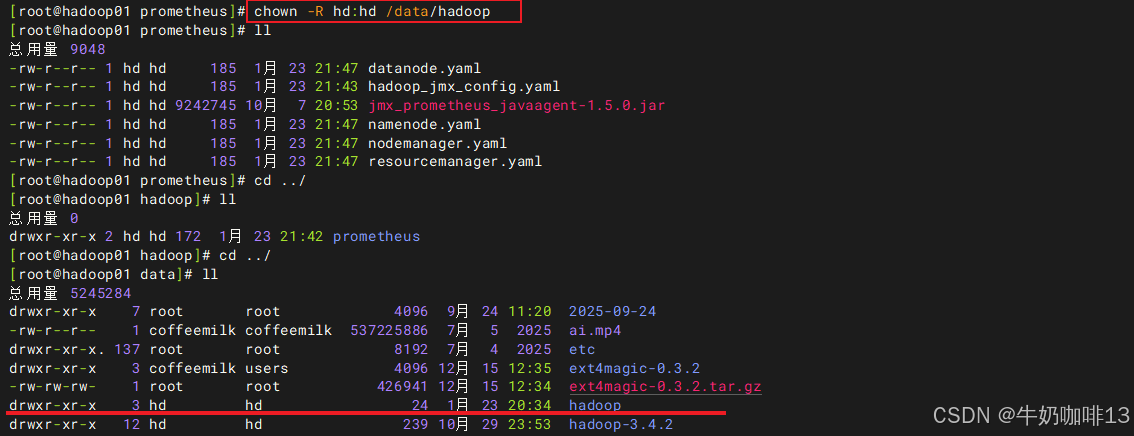
chown -R hd:hd /data/hadoop
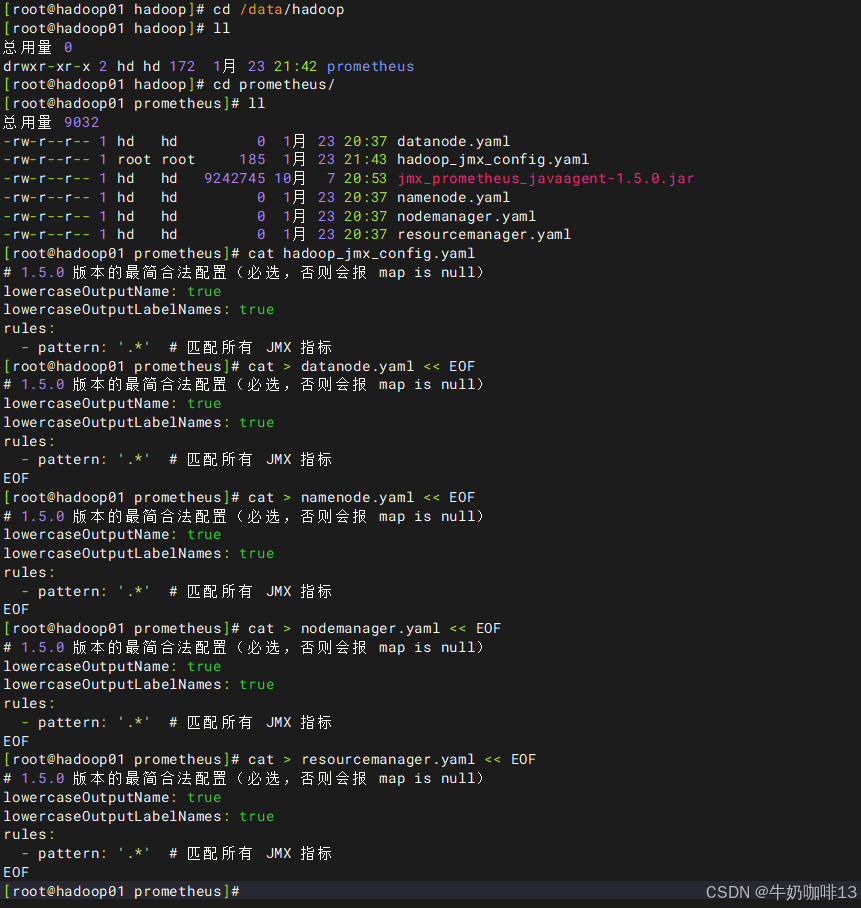
cat > datanode.yaml << EOF
# 1.5.0 版本的最简合法配置(必选,否则会报 map is null)
lowercaseOutputName: true
lowercaseOutputLabelNames: true
rules:
- pattern: '.*' # 匹配所有 JMX 指标
EOF
cat > namenode.yaml << EOF
# 1.5.0 版本的最简合法配置(必选,否则会报 map is null)
lowercaseOutputName: true
lowercaseOutputLabelNames: true
rules:
- pattern: '.*' # 匹配所有 JMX 指标
EOF
cat > nodemanager.yaml << EOF
# 1.5.0 版本的最简合法配置(必选,否则会报 map is null)
lowercaseOutputName: true
lowercaseOutputLabelNames: true
rules:
- pattern: '.*' # 匹配所有 JMX 指标
EOF
cat > resourcemanager.yaml << EOF
# 1.5.0 版本的最简合法配置(必选,否则会报 map is null)
lowercaseOutputName: true
lowercaseOutputLabelNames: true
rules:
- pattern: '.*' # 匹配所有 JMX 指标
EOF
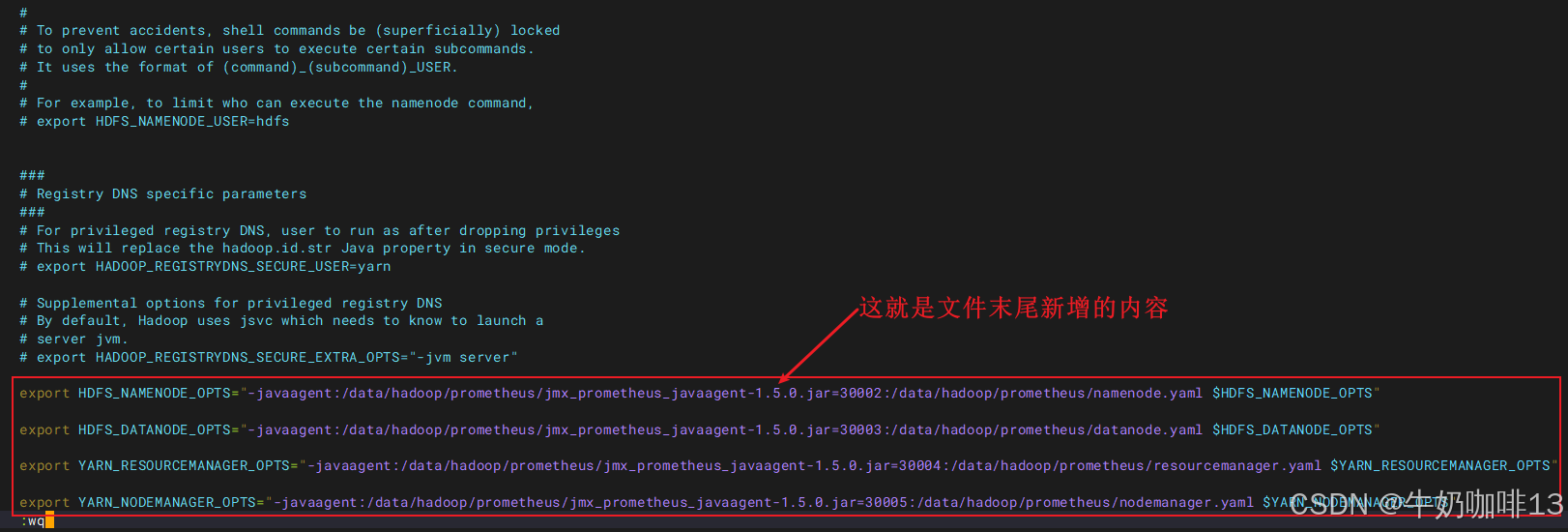
#3-打开hadoop的【hadoop-env.sh】文件末尾添加如下内容
cd /data/hadoop-3.4.2/etc/hadoop/
vi hadoop-env.sh
export HDFS_NAMENODE_OPTS="-javaagent:/data/hadoop/prometheus/jmx_prometheus_javaagent-1.5.0.jar=30002:/data/hadoop/prometheus/namenode.yaml $HDFS_NAMENODE_OPTS"
export HDFS_DATANODE_OPTS="-javaagent:/data/hadoop/prometheus/jmx_prometheus_javaagent-1.5.0.jar=30003:/data/hadoop/prometheus/datanode.yaml $HDFS_DATANODE_OPTS"
export YARN_RESOURCEMANAGER_OPTS="-javaagent:/data/hadoop/prometheus/jmx_prometheus_javaagent-1.5.0.jar=30004:/data/hadoop/prometheus/resourcemanager.yaml $YARN_RESOURCEMANAGER_OPTS"
export YARN_NODEMANAGER_OPTS="-javaagent:/data/hadoop/prometheus/jmx_prometheus_javaagent-1.5.0.jar=30005:/data/hadoop/prometheus/nodemanager.yaml $YARN_NODEMANAGER_OPTS"
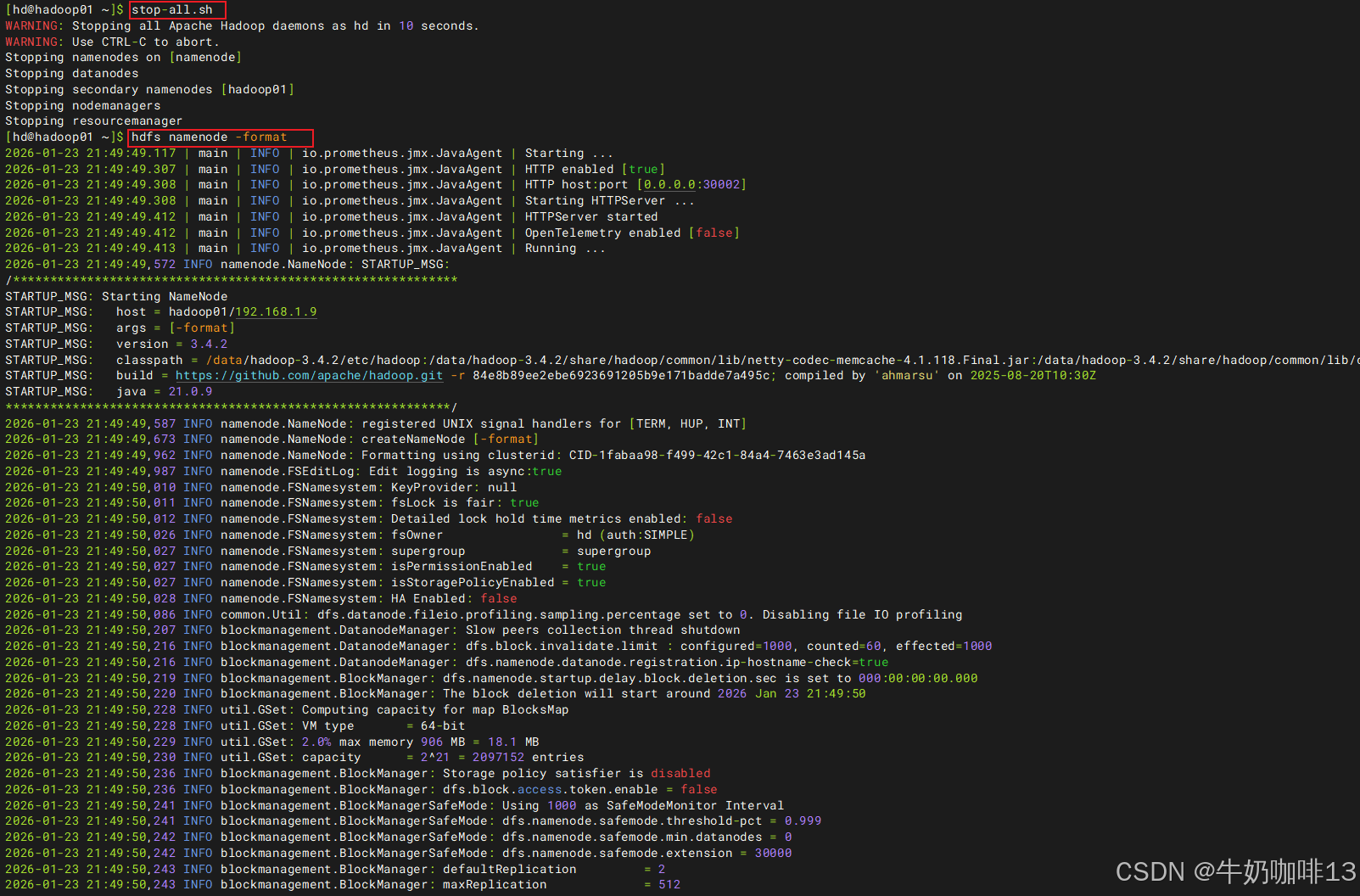
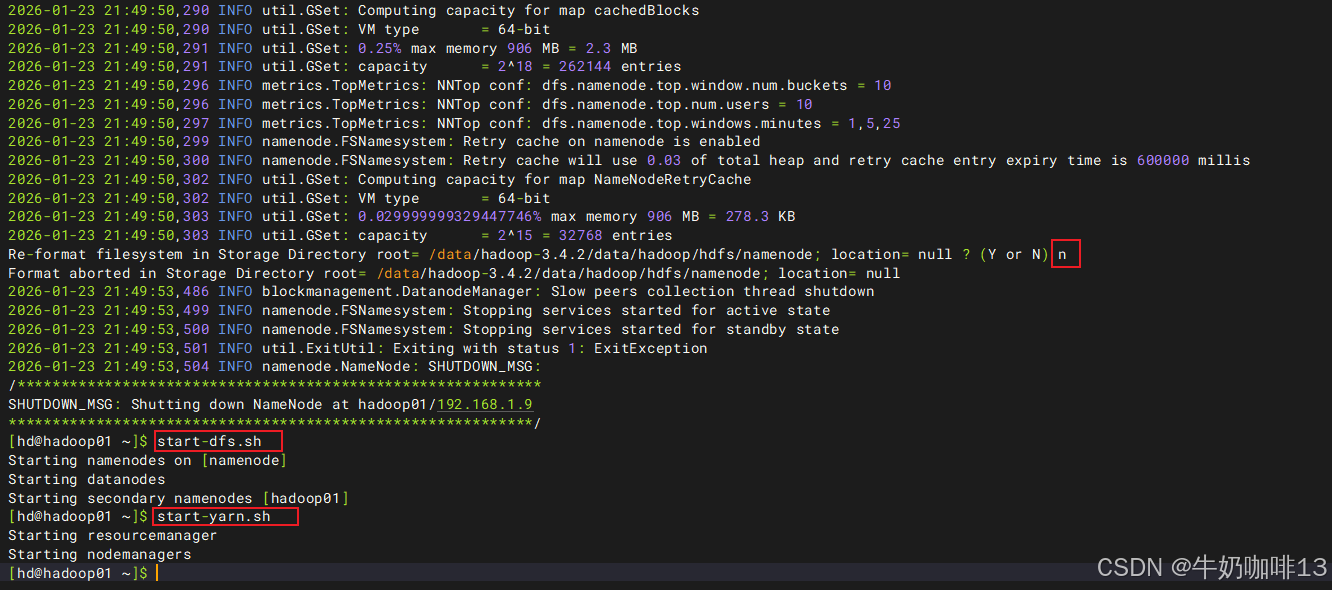
#4-重启hadoop集群
su - hd
stop-all.sh
hdfs namenode -format
start-dfs.sh
start-yarn.sh
#5-最后,就可以通过IP:[30002、30003、30004、30005]/metrics端口访问prometheus可识别的格式数据了
ip a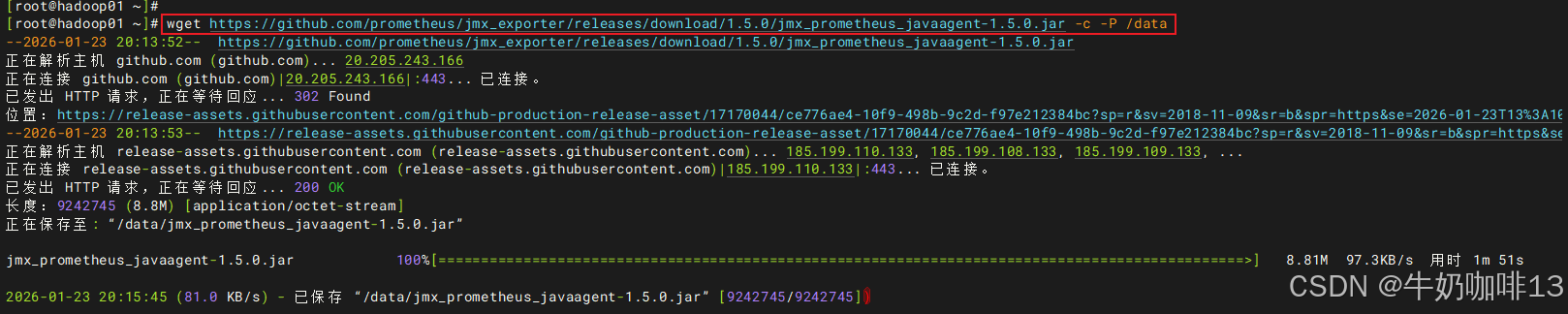

1.4、hadoop需要监控的指标
|--------|----------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 对hadoop的监控,重点是要监控哪些指标;这里从错误、饱和度、延时、流量四个方面来说明 |||
| 序号 | 指标类型 | hadoop需要监控的重要指标 |
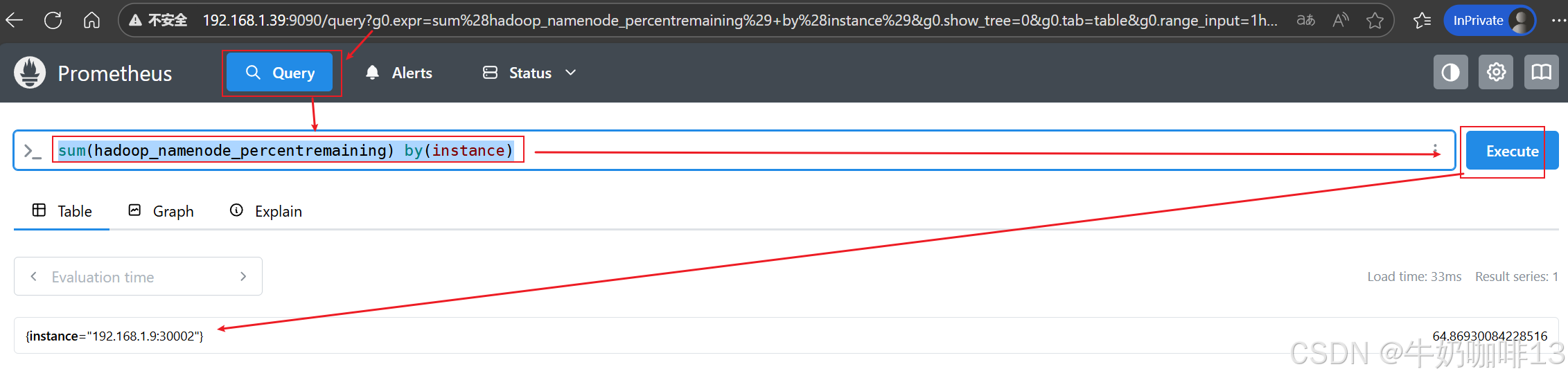
| 1 | 错误 | bash #HDFS存储模块 #1-故障或下线的节点数量 Hadoop_NameNode_NumDeadDataNodes #2-正在下线的节点数量 Hadoop_NameNode_NumDecommissioningDataNodes #3-异常复制块数量 Hadoop_NameNode_UnderReplicatedBlocks #4-HDFS剩余容量百分比 Hadoop_NameNode_PercentRemaining |
| 1 | 错误 | bash #分布式计算yarn #1-不健康的nodemanager节点数 Hadoop_ResourceManager_NumUnhealthyNMs #2-正在退役的节点状态 Hadoop_ResourceManager_NumDecommissioningNMs #3-总内存计算资源量 Hadoop_ResourceManager_CapabilityMB #4-总CPU计算资源量 Hadoop_ResourceManager_CapabilityVirtualCores #5-已经使用的资源量 Hadoop_ResourceManager_UsedCapacity #6-挂起的app的数量 Hadoop_ResourceManager_AppsPending #7-被kill的app的数量 Hadoop_ResourceManager_AppsKilled |
| 其他类型的重要指标【饱和度】【延时】【流量】类型则可参照【错误】类型根据业务需要挑选出来监控即可 |||
[hadoop需要监控的重要指标]
二、修改prometheus配置实现自动发现_基于文件发现
prometheus支持静态发现、文件发现、dns发现,kubernetes服务发现、consul发现等,本文用【基于文件的发现】功能实现(给【prometheus.yml】文件添加如下job_name内容):
bash
#prometheus基于【文件发现】的操作
#1-编辑prometheus.yml文件新增job_name内容
cd /usr/local/prometheus-3.5.0/
vi prometheus.yml
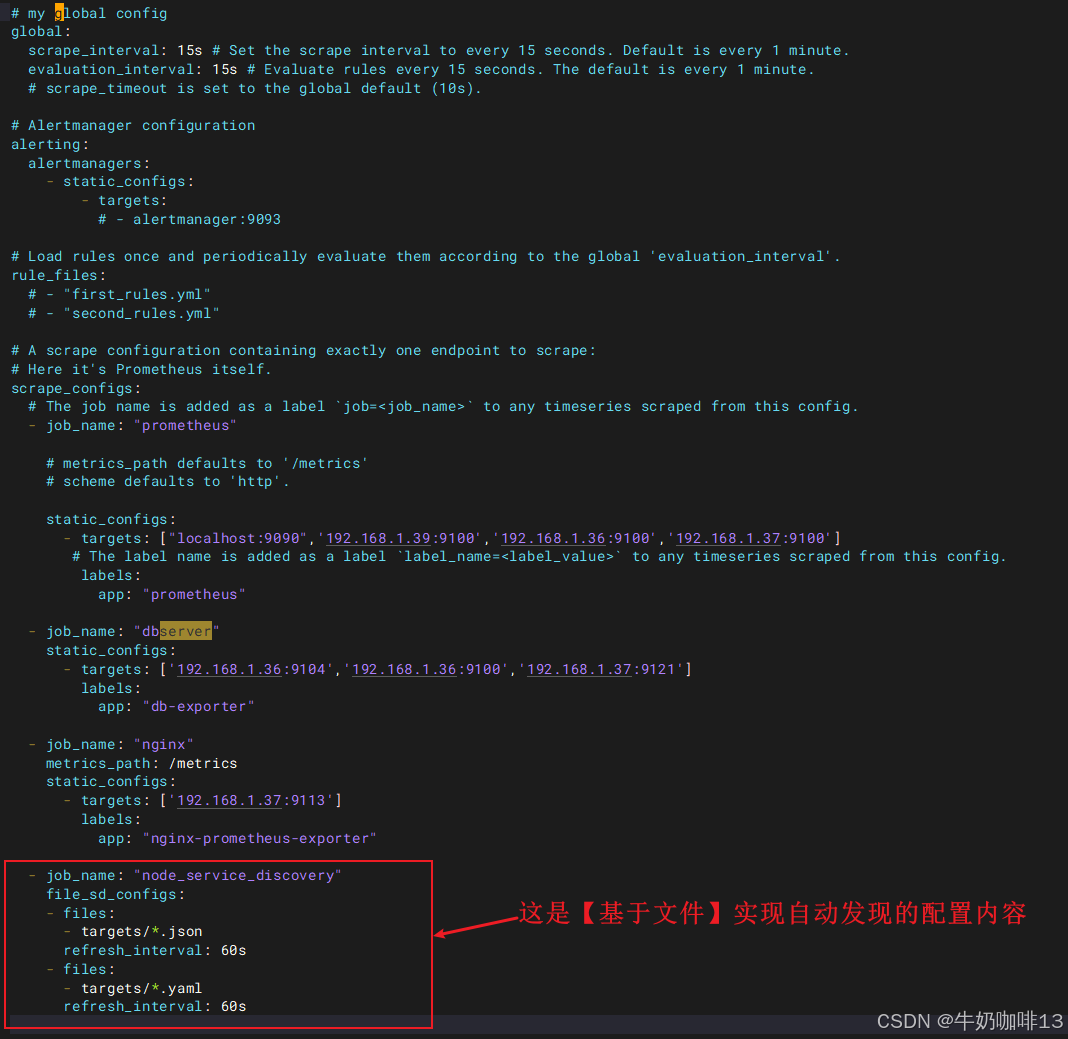
#【prometheus.yml】文件新增的基于文件发现的完整配置如下:
- job_name: "node_service_discovery"
file_sd_configs:
- files:
- targets/*.json
refresh_interval: 60s
- files:
- targets/*.yaml
refresh_interval: 60s
#2-验证修改后的prometheus.yml文件的语法是否正确(结果显示SUCCESS则表示正确)
./promtool check config prometheus.yml
#3-验证prometheus.yml文件中的语法正确后热重载让配置生效
curl -XPOST localhost:9090/-/reload
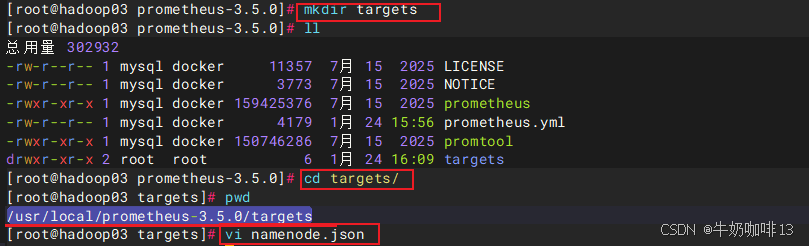
#4-在【prometheus.yml】所在目录创建【targets】目录并创建对应的.json与.yaml的配置文件
mkdir targets
cd targets/
#4.1-在【/usr/local/prometheus-3.5.0/targets】目录下新建【namenode.json】配置文件
vi namenode.json
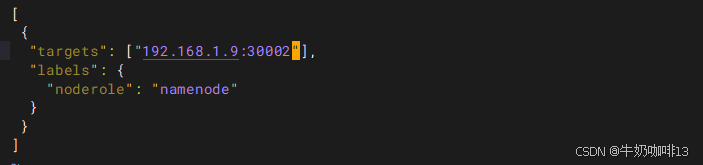
#【namenode.json】文件的完整内容如下:
[
{
"targets": ["192.168.1.9:30002"],
"labels": {
"noderole": "namenode"
}
}
]
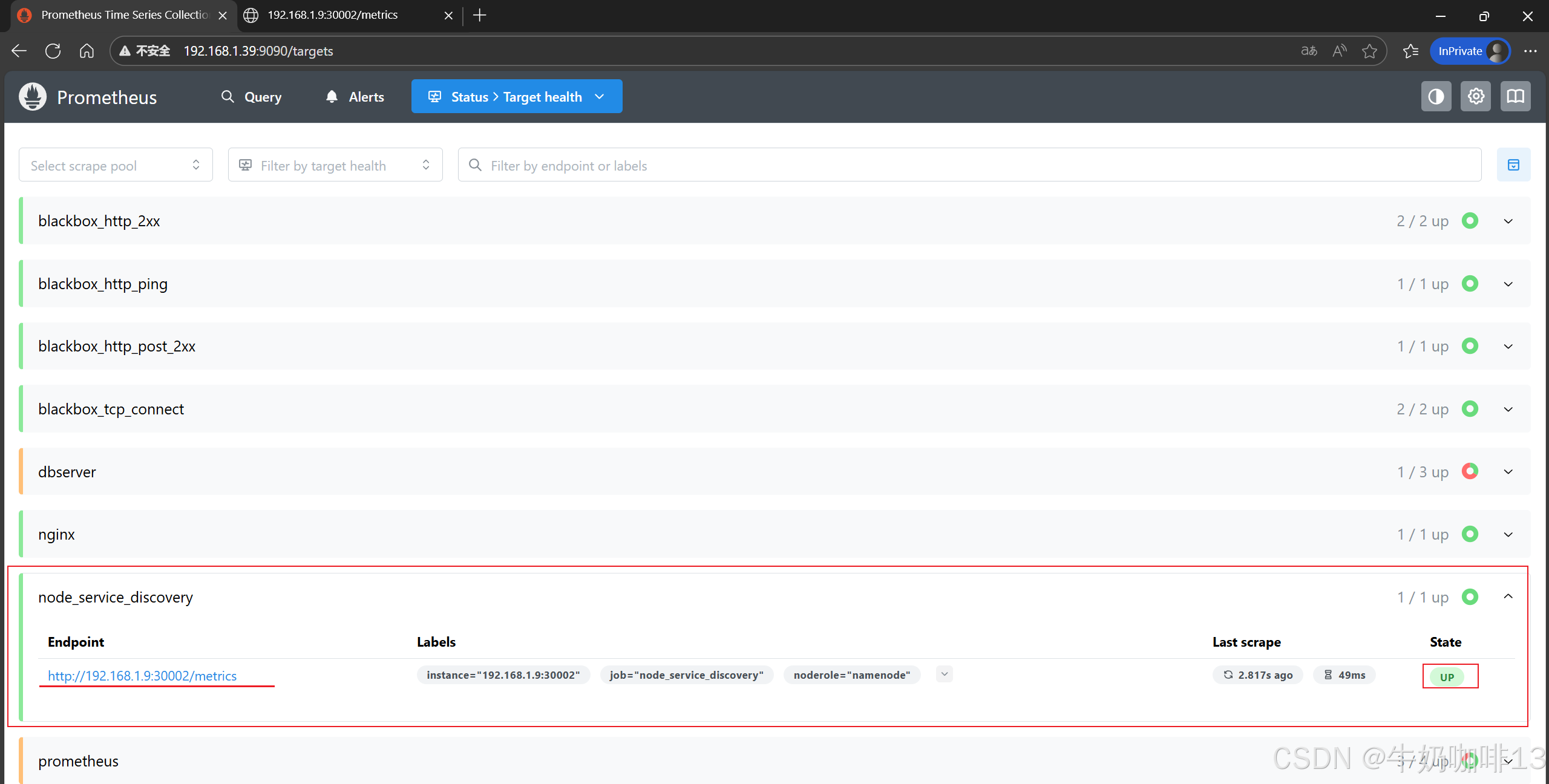
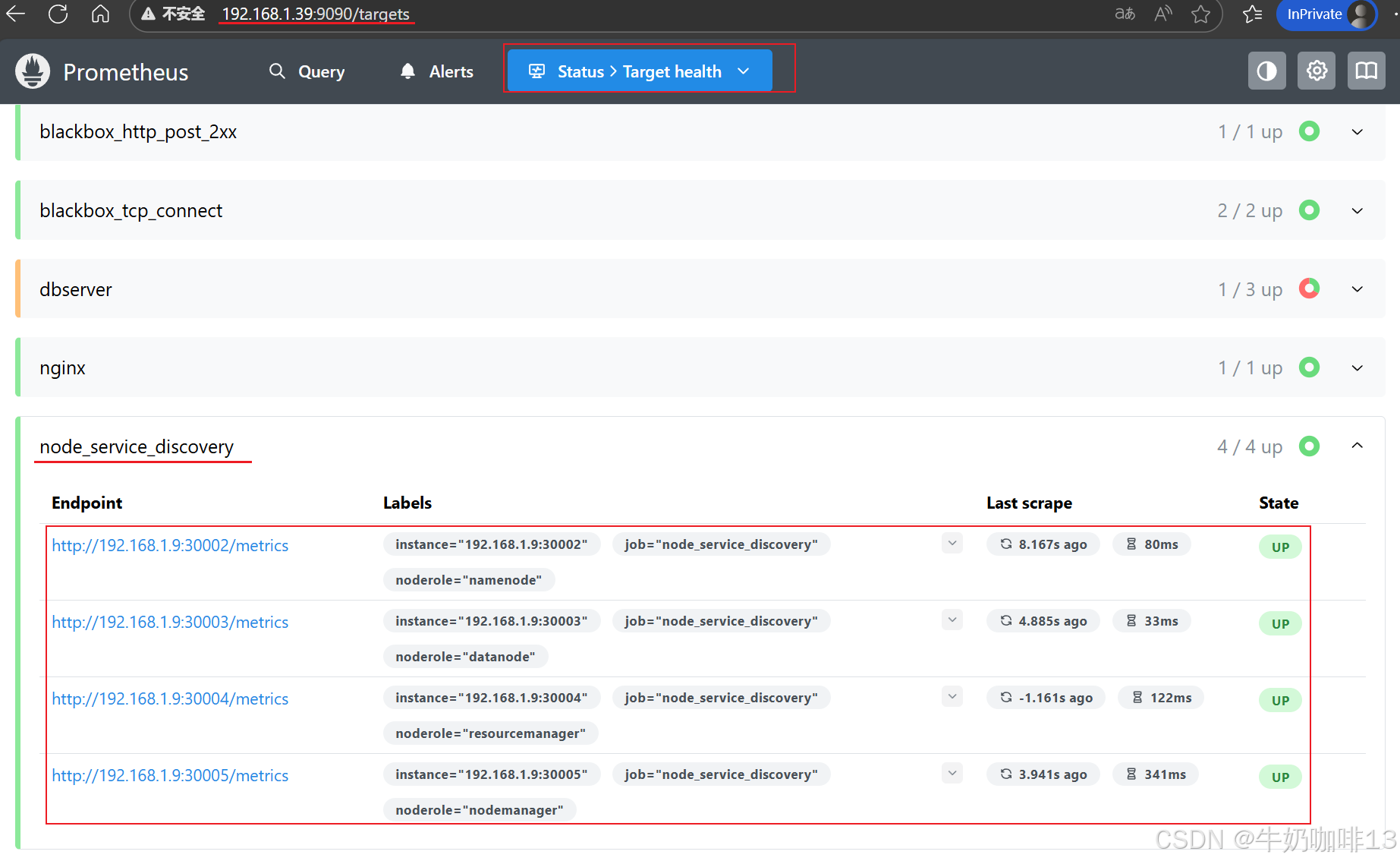
#4.2-然后打开浏览器进入Prometheus Server的Web界面【IP:9090】查看【Status-->Target health】即可看到【node_service_discovery】job_name下添加的这个节点内容(如:192.168.1.9:30002)
#4.3-在【/usr/local/prometheus-3.5.0/targets】目录下新建
#【datanode.json】【resourcemanager.json】【nodemanager.json】配置文件
vi datanode.json
#【namenode.json】文件的完整内容如下:
[
{
"targets": ["192.168.1.9:30003"],
"labels": {
"noderole": "datanode"
}
}
]
vi resourcemanager.json
#【resourcemanager.json】文件的完整内容如下:
{
"targets": ["192.168.1.9:30004"],
"labels": {
"noderole": "resourcemanager"
}
}
]
vi nodemanager.json
#【nodemanager.json】文件的完整内容如下:
[
{
"targets": ["192.168.1.9:30005"],
"labels": {
"noderole": "nodemanager"
}
}
]

三、Grafana中配置prometheus的hadoop数据可视化
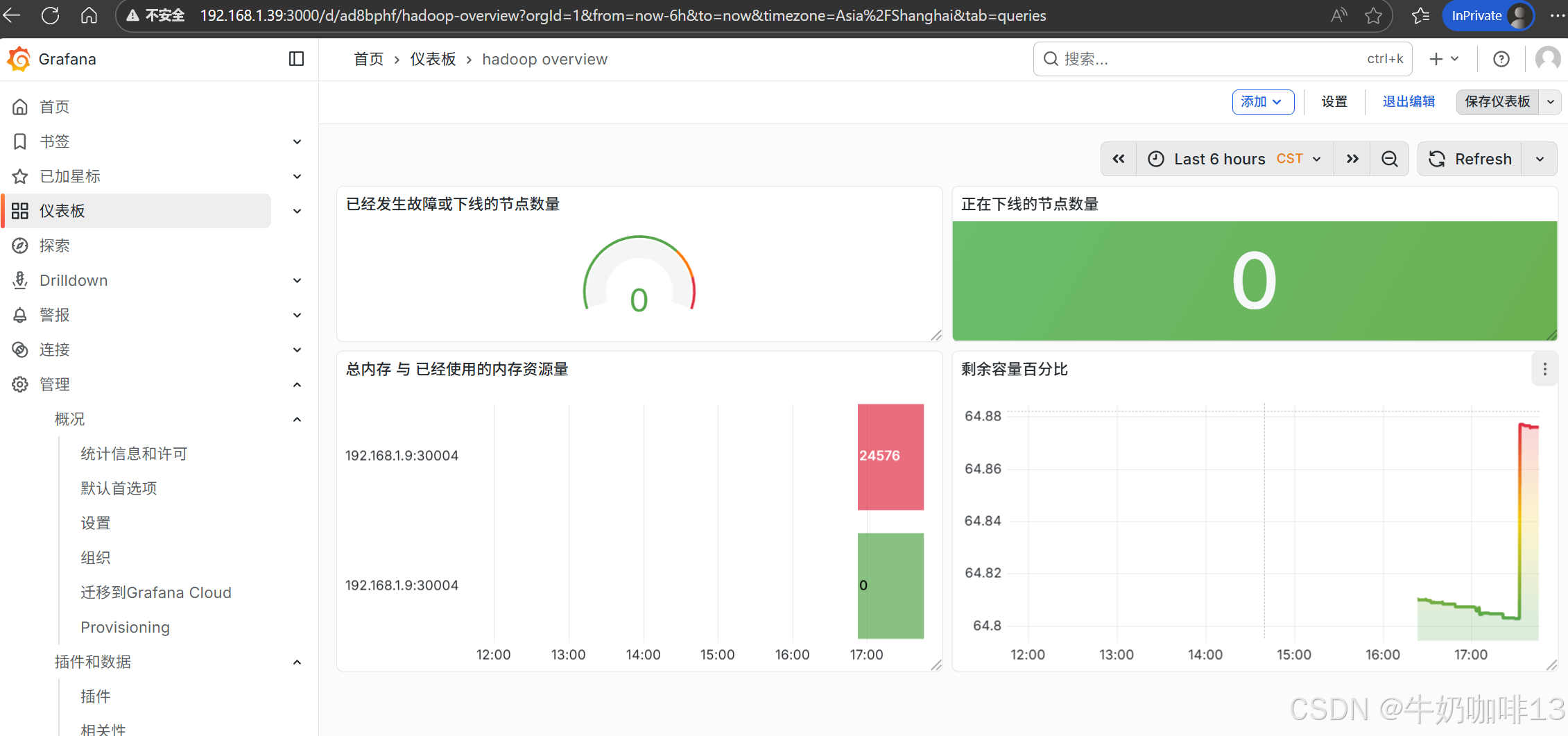
由于Grafana的仪表盘官网中没有较为好用的仪表盘内容,因此需要我们自己手动编写自己的仪表盘,在编写前需要先想清楚自己想要监控哪些重要数据,不要什么数据都监控(这样既没有必要,也没有意义)。
自己制作Grafana中仪表盘(需要自己编写对应的PromQL语句)的步骤如下:
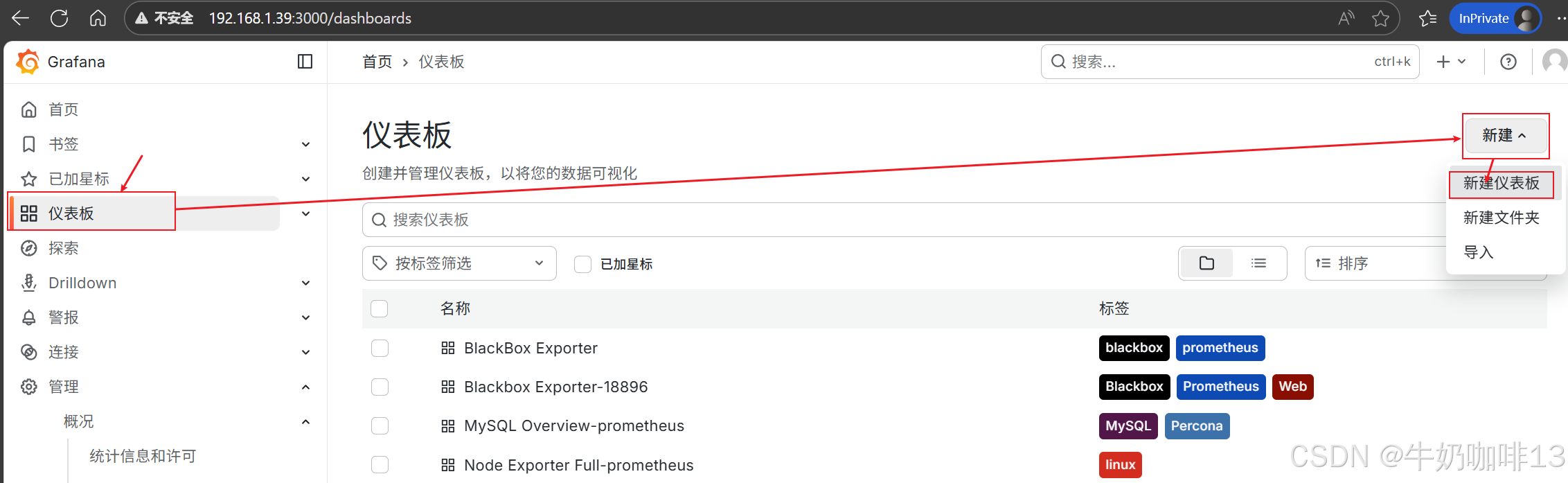
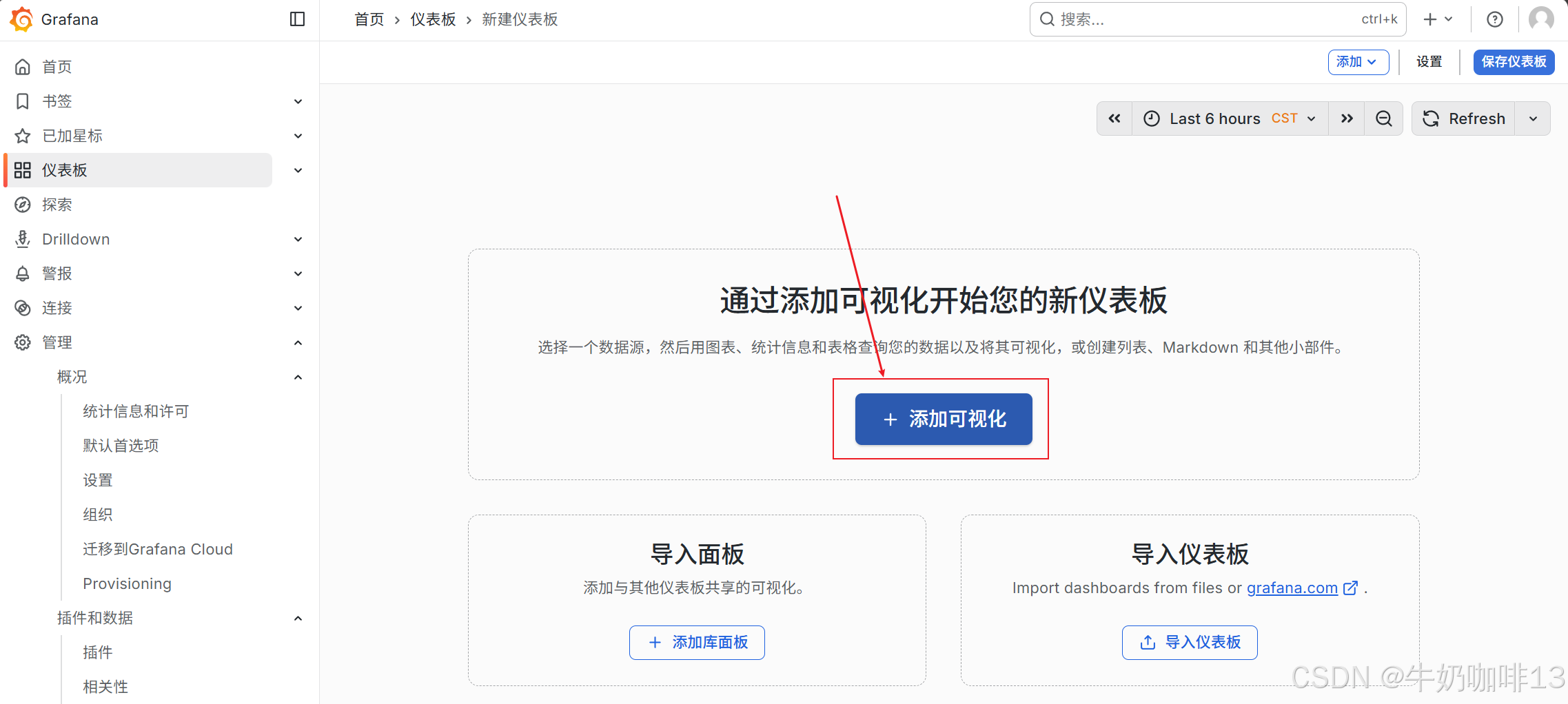
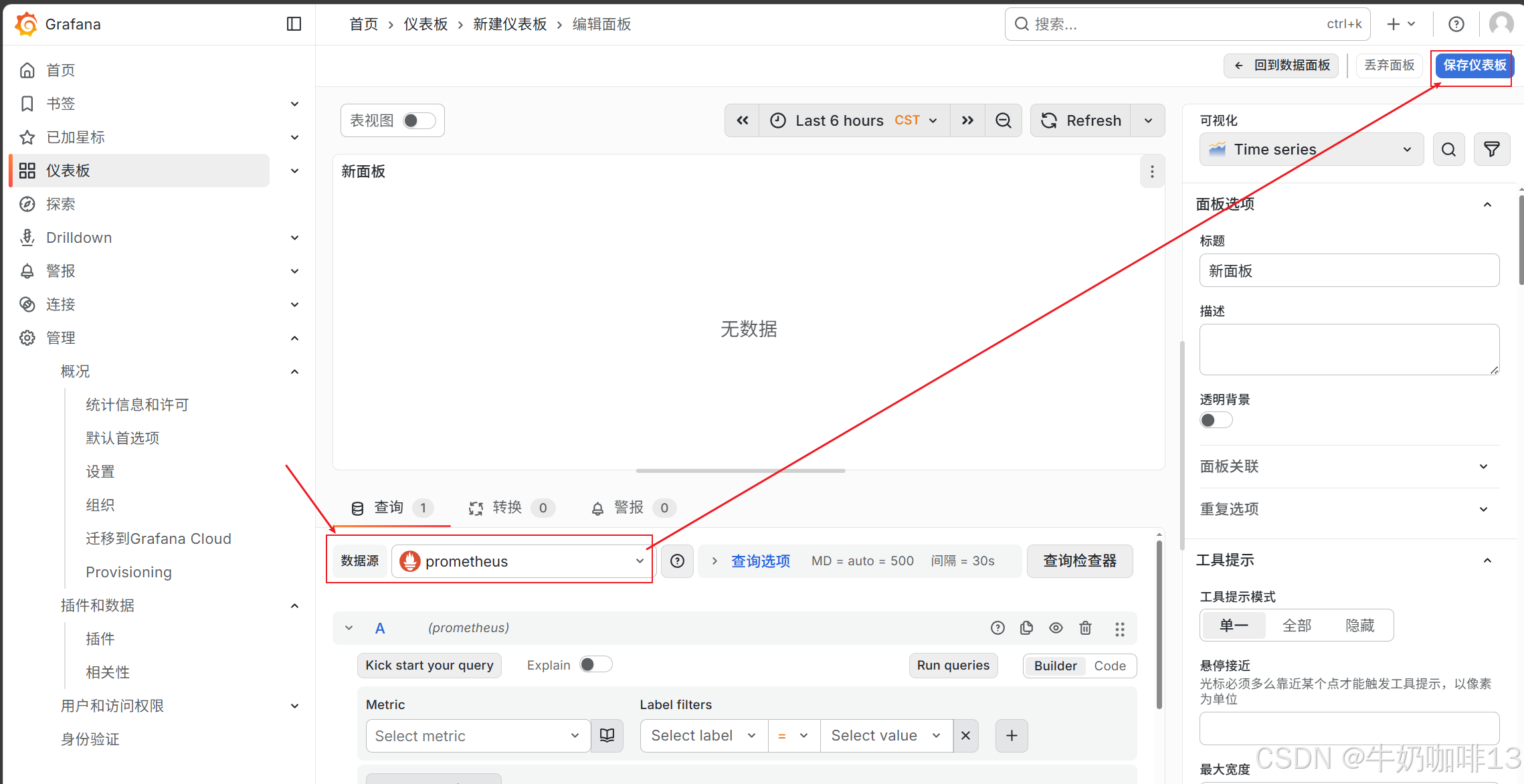
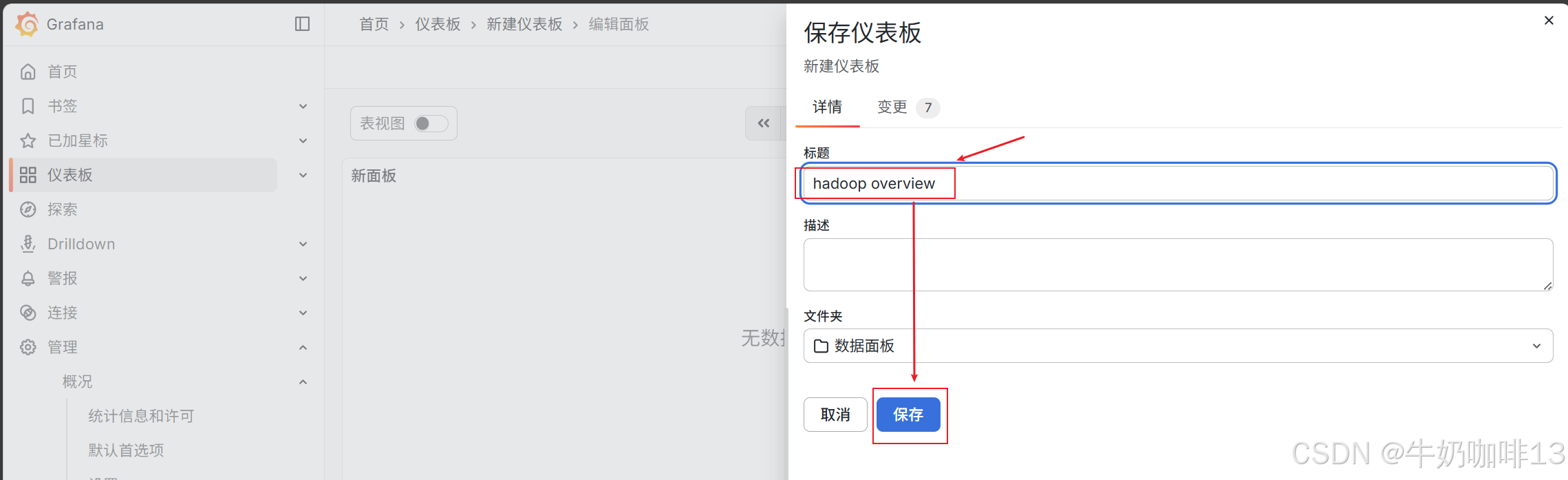
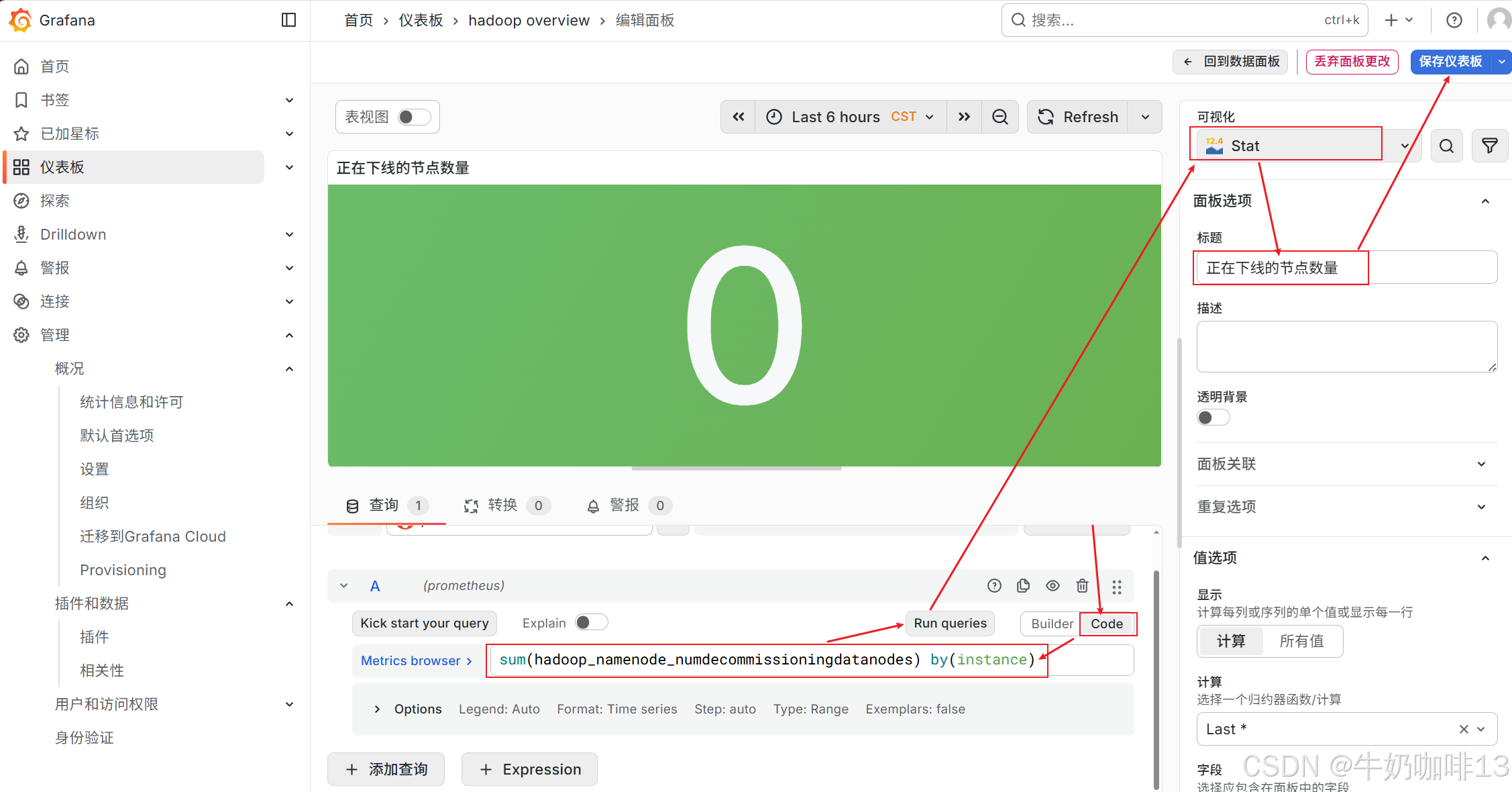
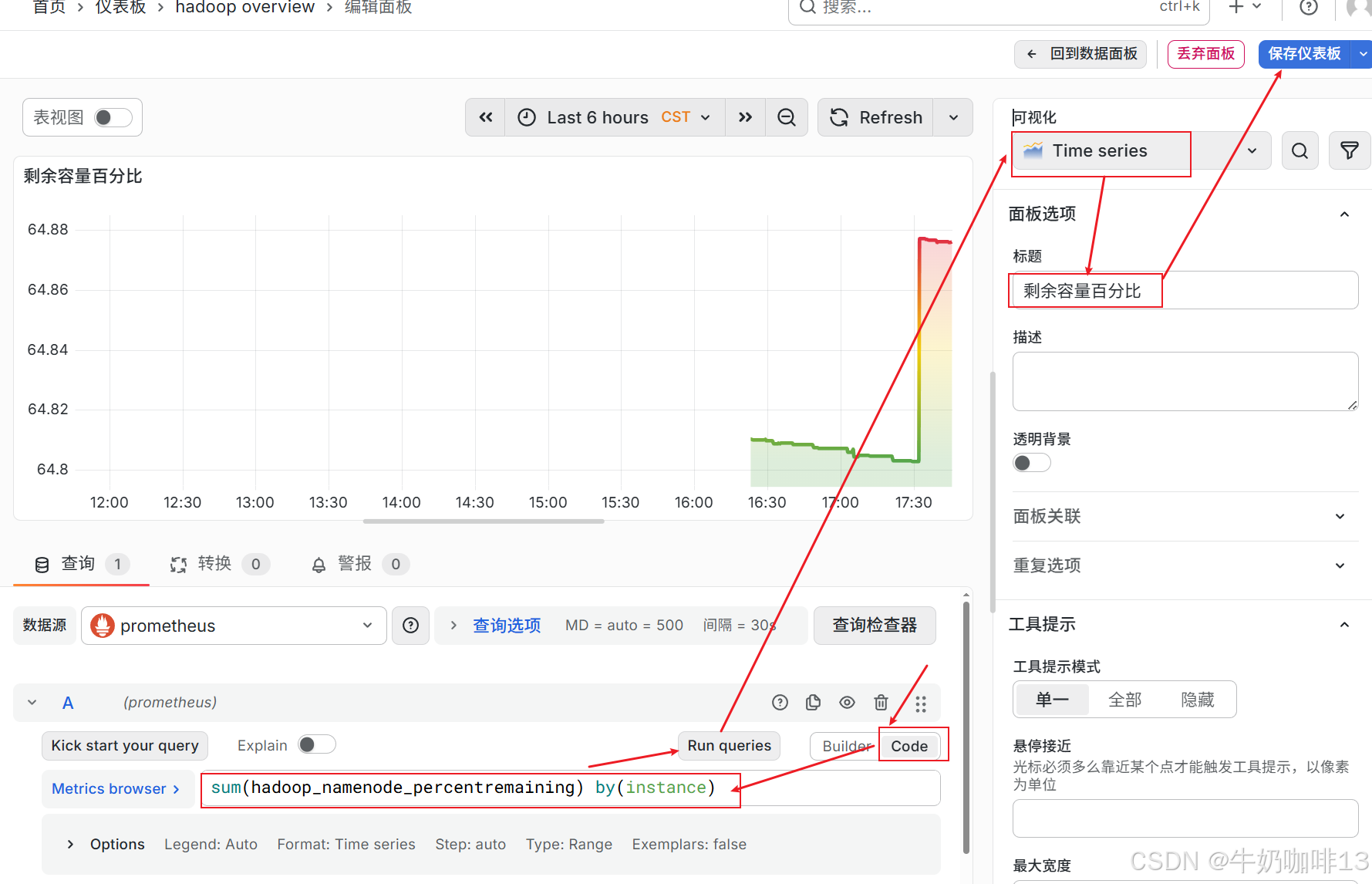
《1》点击【仪表盘】-->【新建】-->【新建仪表板】-->【添加可视化】界面选择【数据源(prometheus)】后点击【保存仪表板】(输入名称【hadoop overview】)。
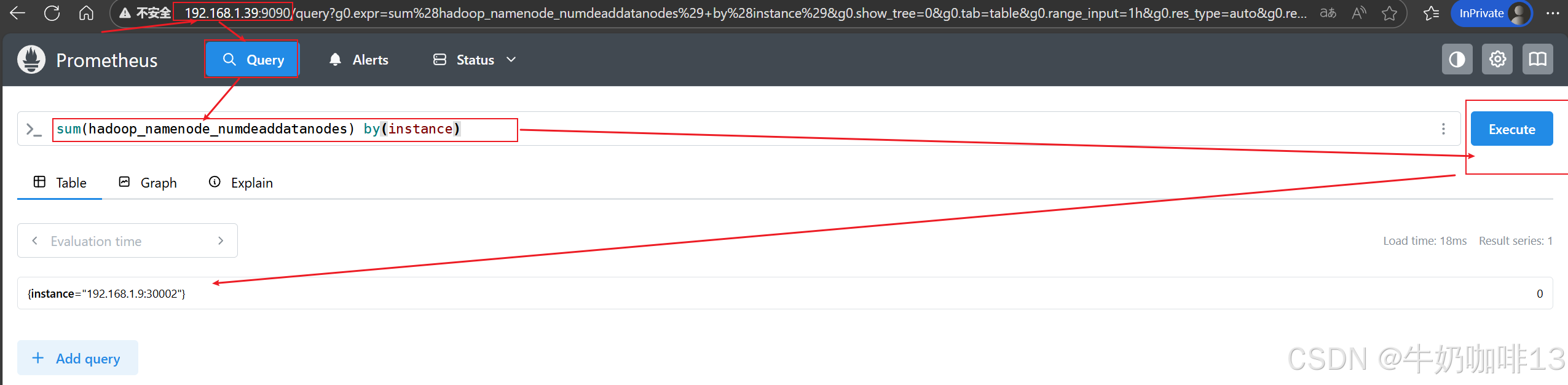
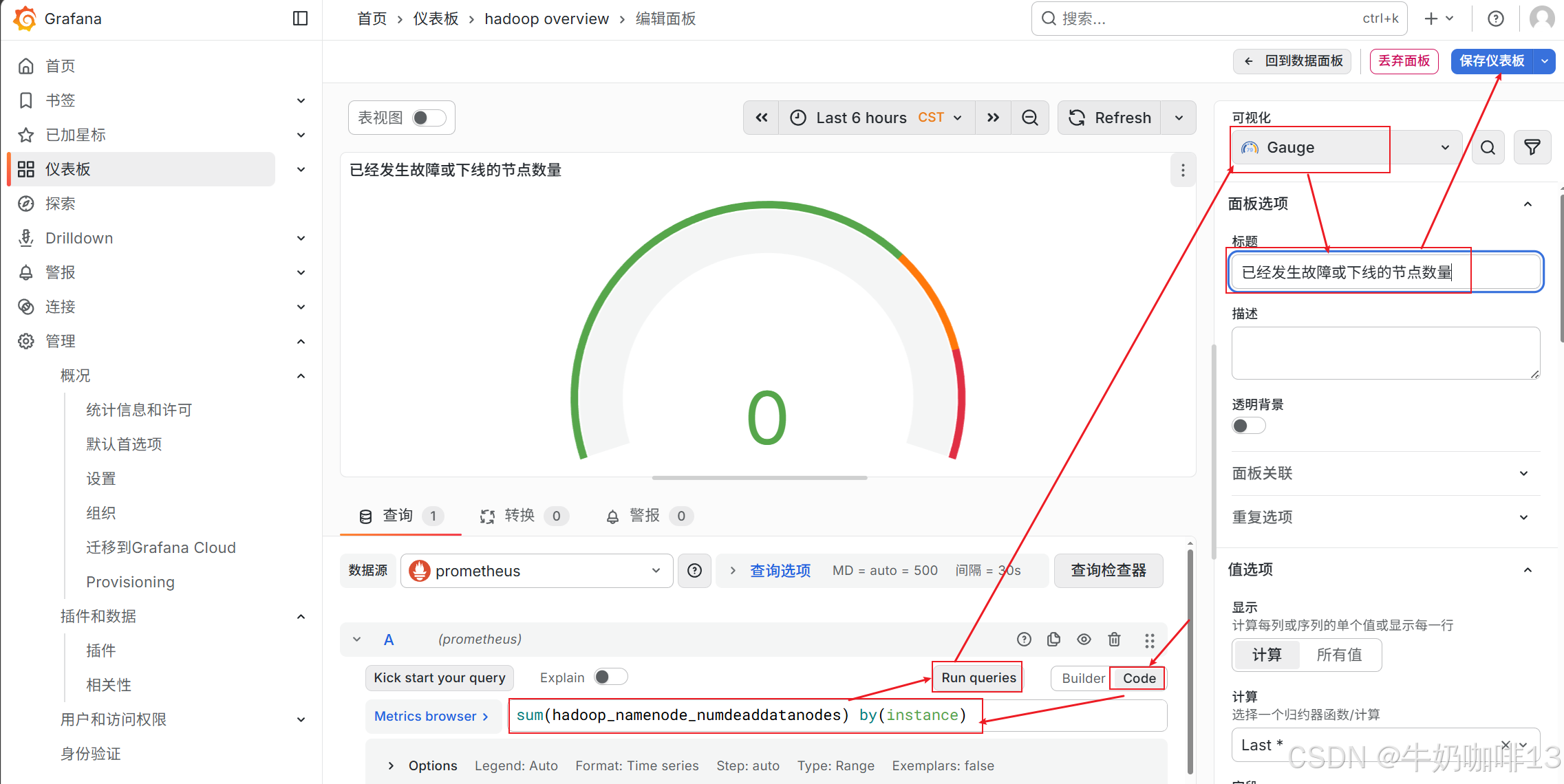
《2》比如我这里实现统计【已经发生故障或已经下线的节点数量】的PromQL语句为【sum(hadoop_namenode_numdeaddatanodes) by(instance)】可将这个语句先到prometheus的query命令行里查询,然后在将这个语句复制到Grafana的新建仪表板中,详细操作如下: