1.代码题
今日的代码题分别为24. 两两交换链表中的节点 206.反转链表 24. 两两交换链表中的节点 19.删除链表的倒数第N个节点 142.环形链表II
206.反转链表
参考视频:https://www.bilibili.com/video/BV1nB4y1i7eL?t=951.1
参考文档:206.反转链表 | 代码随想录
力扣题目链接:206. 反转链表 - 力扣(LeetCode)
题目:
题意:反转一个单链表。
示例: 输入: 1->2->3->4->5->NULL 输出: 5->4->3->2->1->NULL
思路
如果再定义一个新的链表,实现链表元素的反转,其实这是对内存空间的浪费。
其实只需要改变链表的next指针的指向,直接将链表反转 ,而不用重新定义一个新的链表,如图所示:
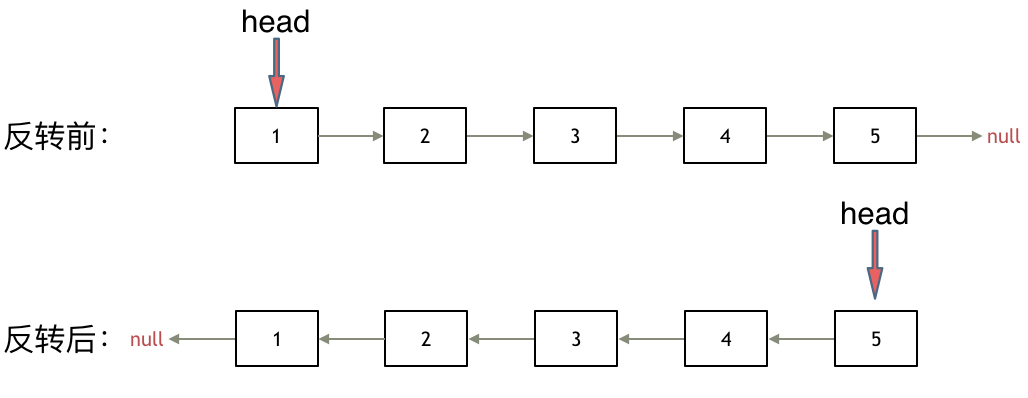
之前链表的头节点是元素1, 反转之后头结点就是元素5 ,这里并没有添加或者删除节点,仅仅是改变next指针的方向。
那么接下来看一看是如何反转的呢?
我们拿有示例中的链表来举例,如动画所示:(纠正:动画应该是先移动pre,在移动cur)
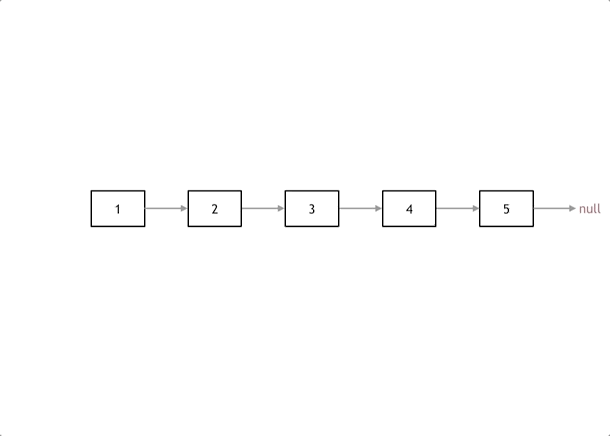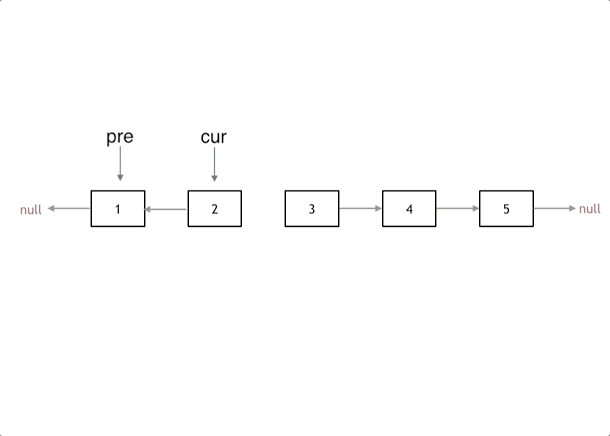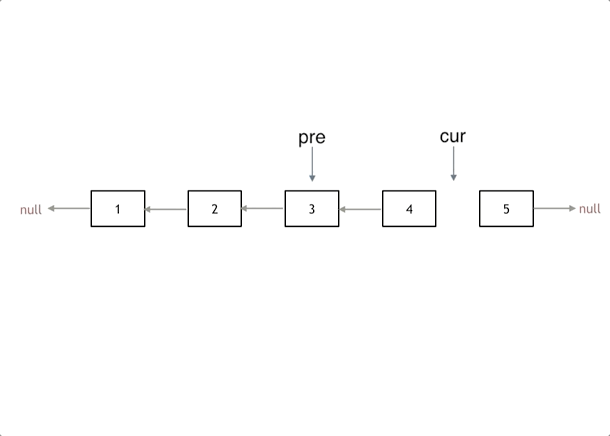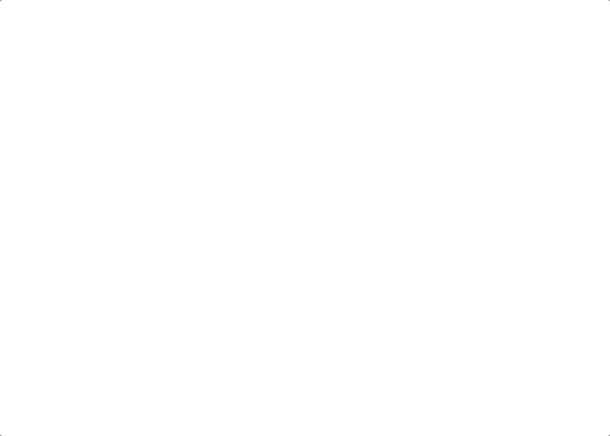
首先定义一个cur指针,指向头结点,再定义一个pre指针,初始化为null。
然后就要开始反转了,首先要把 cur->next 节点用tmp指针保存一下,也就是保存一下这个节点。
为什么要保存一下这个节点呢,因为接下来要改变 cur->next 的指向了,将cur->next 指向pre ,此时已经反转了第一个节点了。
接下来,就是循环走如下代码逻辑了,继续移动pre和cur指针。
最后,cur 指针已经指向了null,循环结束,链表也反转完毕了。 此时我们return pre指针就可以了,pre指针就指向了新的头结点。
#双指针法
class Solution {
public:
ListNode* reverseList(ListNode* head) {
ListNode* temp; // 保存cur的下一个节点
ListNode* cur = head;
ListNode* pre = NULL;
while(cur) {
temp = cur->next; // 保存一下 cur的下一个节点,因为接下来要改变cur->next
cur->next = pre; // 翻转操作
// 更新pre 和 cur指针
pre = cur;
cur = temp;
}
return pre;
}
};- 时间复杂度: O(n)
- 空间复杂度: O(1)
#递归法
递归法相对抽象一些,但是其实和双指针法是一样的逻辑,同样是当cur为空的时候循环结束,不断将cur指向pre的过程。
关键是初始化的地方,可能有的同学会不理解, 可以看到双指针法中初始化 cur = head,pre = NULL,在递归法中可以从如下代码看出初始化的逻辑也是一样的,只不过写法变了。
具体可以看代码(已经详细注释),双指针法写出来之后,理解如下递归写法就不难了,代码逻辑都是一样的。
class Solution {
public:
ListNode* reverse(ListNode* pre,ListNode* cur){
if(cur == NULL) return pre;
ListNode* temp = cur->next;
cur->next = pre;
// 可以和双指针法的代码进行对比,如下递归的写法,其实就是做了这两步
// pre = cur;
// cur = temp;
return reverse(cur,temp);
}
ListNode* reverseList(ListNode* head) {
// 和双指针法初始化是一样的逻辑
// ListNode* cur = head;
// ListNode* pre = NULL;
return reverse(NULL, head);
}
};- 时间复杂度: O(n), 要递归处理链表的每个节点
- 空间复杂度: O(n), 递归调用了 n 层栈空间
我们可以发现,上面的递归写法和双指针法实质上都是从前往后翻转指针指向,其实还有另外一种与双指针法不同思路的递归写法:从后往前翻转指针指向。
具体代码如下(带详细注释):
class Solution {
public:
ListNode* reverseList(ListNode* head) {
// 边缘条件判断
if(head == NULL) return NULL;
if (head->next == NULL) return head;
// 递归调用,翻转第二个节点开始往后的链表
ListNode *last = reverseList(head->next);
// 翻转头节点与第二个节点的指向
head->next->next = head;
// 此时的 head 节点为尾节点,next 需要指向 NULL
head->next = NULL;
return last;
}
}; - 时间复杂度: O(n)
- 空间复杂度: O(n)
注意事项:
1.该题首先要掌握的是双指针法,递归法第一遍看应该会很晕,但本质就是按照双指针法的方法完成的,若非面试官强制要求,熟练掌握双指针法即可
2.注意使用虚拟头结点的好处,本题的pre实际位置为虚拟头结点,但是由于链表末尾为null,所以虚拟头结点直接设为null即可,while循环停止的条件实际为cur指向null时停止,所以直接while(cur)即可
24. 两两交换链表中的节点
题目
给定一个链表,两两交换其中相邻的节点,并返回交换后的链表。
你不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。
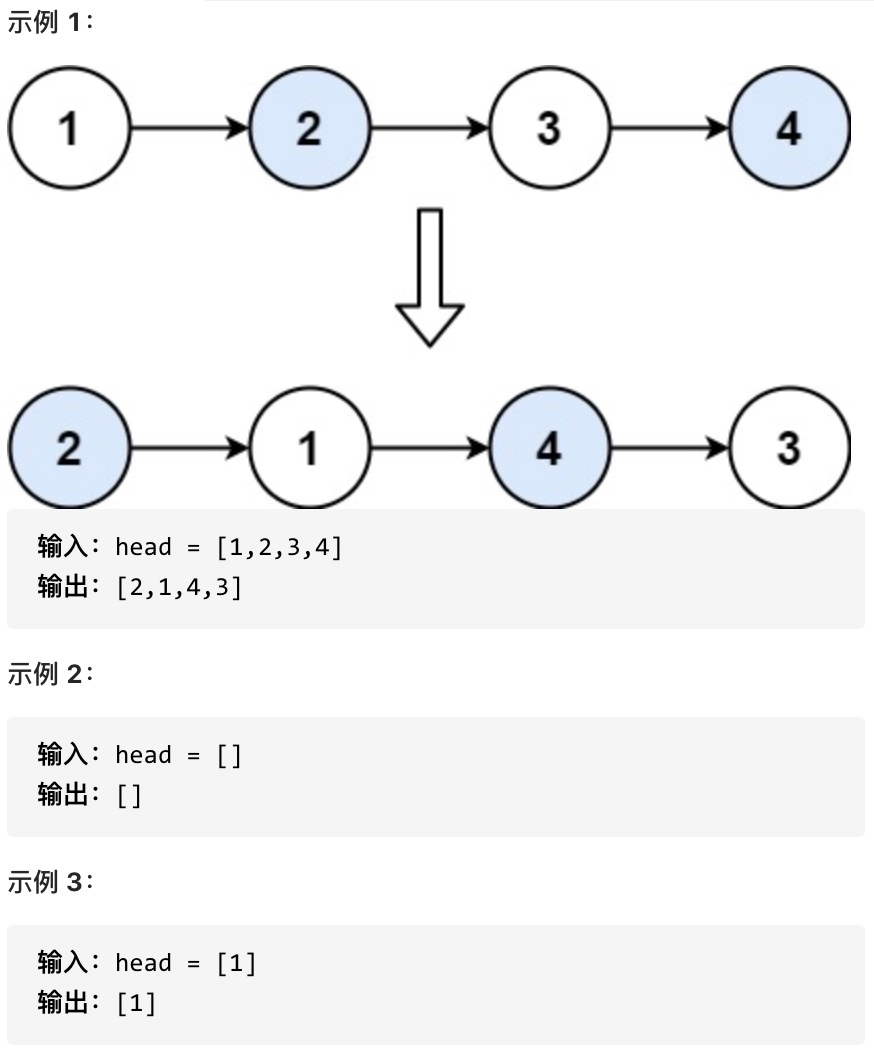
思路
这道题目正常模拟就可以了。
建议使用虚拟头结点,这样会方便很多,要不然每次针对头结点(没有前一个指针指向头结点),还要单独处理。
对虚拟头结点的操作,还不熟悉的话,可以看这篇链表:听说用虚拟头节点会方便很多? (opens new window)。
接下来就是交换相邻两个元素了,此时一定要画图,不画图,操作多个指针很容易乱,而且要操作的先后顺序
初始时,cur指向虚拟头结点,然后进行如下三步:
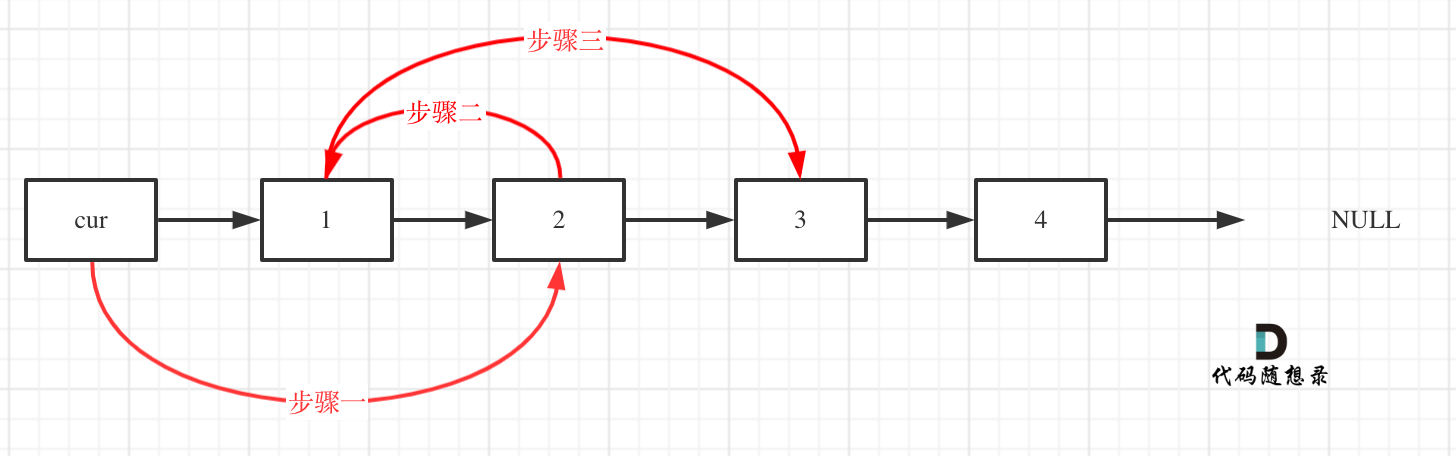
操作之后,链表如下:
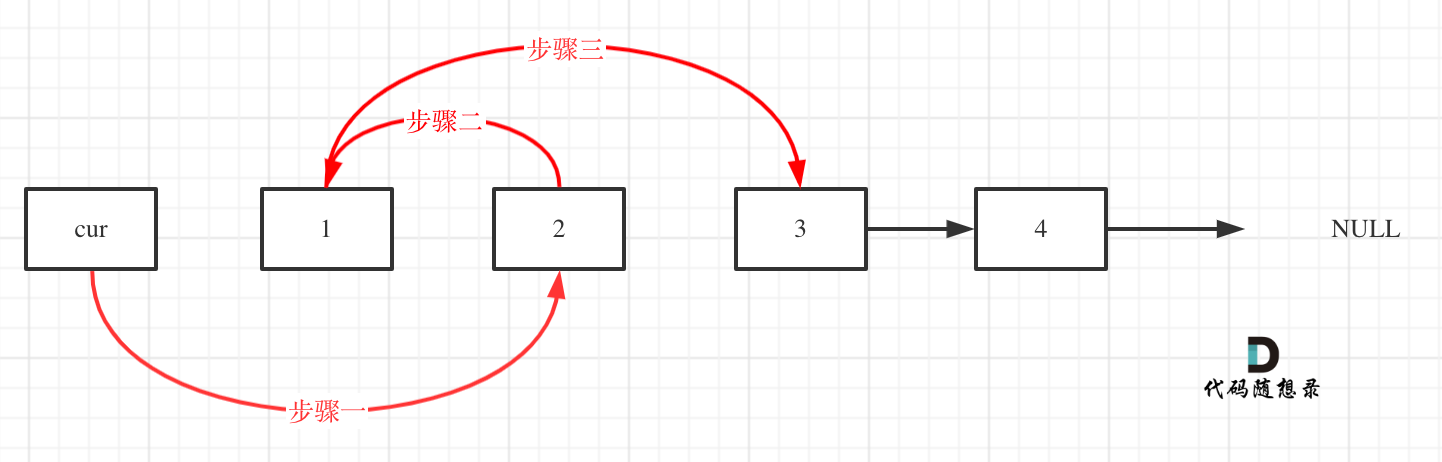
看这个可能就更直观一些了:
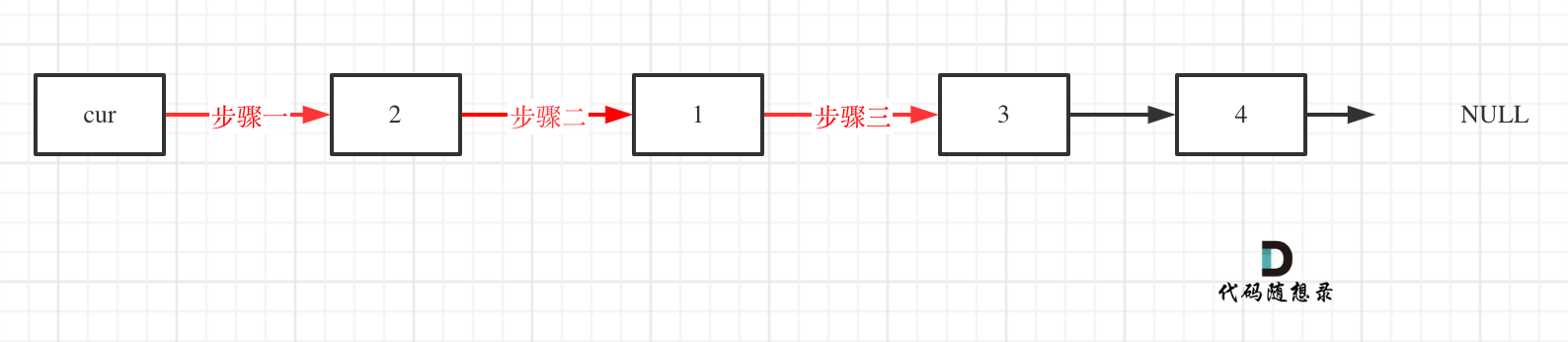
对应的C++代码实现如下: (注释中详细和如上图中的三步做对应)
class Solution {
public:
ListNode* swapPairs(ListNode* head) {
ListNode* dummyHead = new ListNode(0); // 设置一个虚拟头结点
dummyHead->next = head; // 将虚拟头结点指向head,这样方便后面做删除操作
ListNode* cur = dummyHead;
while(cur->next != nullptr && cur->next->next != nullptr) {
ListNode* tmp = cur->next; // 记录临时节点
ListNode* tmp1 = cur->next->next->next; // 记录临时节点
cur->next = cur->next->next; // 步骤一
cur->next->next = tmp; // 步骤二
cur->next->next->next = tmp1; // 步骤三
cur = cur->next->next; // cur移动两位,准备下一轮交换
}
ListNode* result = dummyHead->next;
delete dummyHead;
return result;
}
};- 时间复杂度:O(n)
- 空间复杂度:O(1)
注意事项:
1.代码中while(cur->next != nullptr && cur->next->next != nullptr)是否可以更换位置?
答案是不可以,因为如果先执行后半句cur->next->next != nullptr则可能因为cur->next 为 nullptr而未正确判断导致空指针的错误使用,所以这句话的顺序是不可以换的
2.为什么要新建temp temp1俩个临时指针?
如上图,当我们进行第一步时候,删除了cur->结点1,那么当cur->结点2后我们无法正确找到结点1的地址,所以此时需要先创建一个新的临时指针保存结点1的地址,即temp = cur -> next,同理 当我们执行第二步时候,结点2->结点1则无法争取找到结点3的地址,所以要先建立临时指针temp1保存结点3的地址,防止无法正确找到
3.在交换完成之前,cur的位置都是不会变的,所以最好画图以便更加容易看出cur所指向的位置
以下是笔者的代码
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* swapPairs(ListNode* head) {
ListNode* dummyhead = new ListNode(0);
dummyhead ->next = head;
ListNode *cur = dummyhead;
while(cur ->next!= nullptr && cur ->next ->next !=nullptr){
ListNode* temp = cur ->next;
ListNode* temp1 = cur -> next ->next ->next;
cur->next = cur ->next ->next;
cur ->next ->next = temp; //此处需要注意cur位置还未变动
temp ->next = temp1;
cur = cur ->next ->next;//cur向后移俩位
}
return dummyhead ->next;
}
};19.删除链表的倒数第N个节点
题目:
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
进阶:你能尝试使用一趟扫描实现吗?
示例 1:
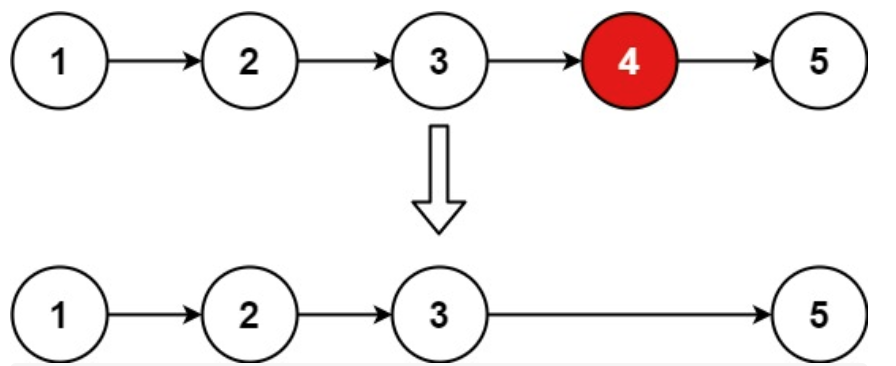
输入:head = 1,2,3,4,5, n = 2 输出:1,2,3,5
示例 2:
输入:head = 1, n = 1 输出:\[\]
示例 3:
输入:head = 1,2, n = 1 输出:1
思路
双指针的经典应用,如果要删除倒数第n个节点,让fast移动n步,然后让fast和slow同时移动,直到fast指向链表末尾。删掉slow所指向的节点就可以了。
思路是这样的,但要注意一些细节。
分为如下几步:
-
首先这里我推荐大家使用虚拟头结点,这样方便处理删除实际头结点的逻辑,如果虚拟头结点不清楚,可以看这篇: 链表:听说用虚拟头节点会方便很多?(opens new window)
-
定义fast指针和slow指针,初始值为虚拟头结点,如图:
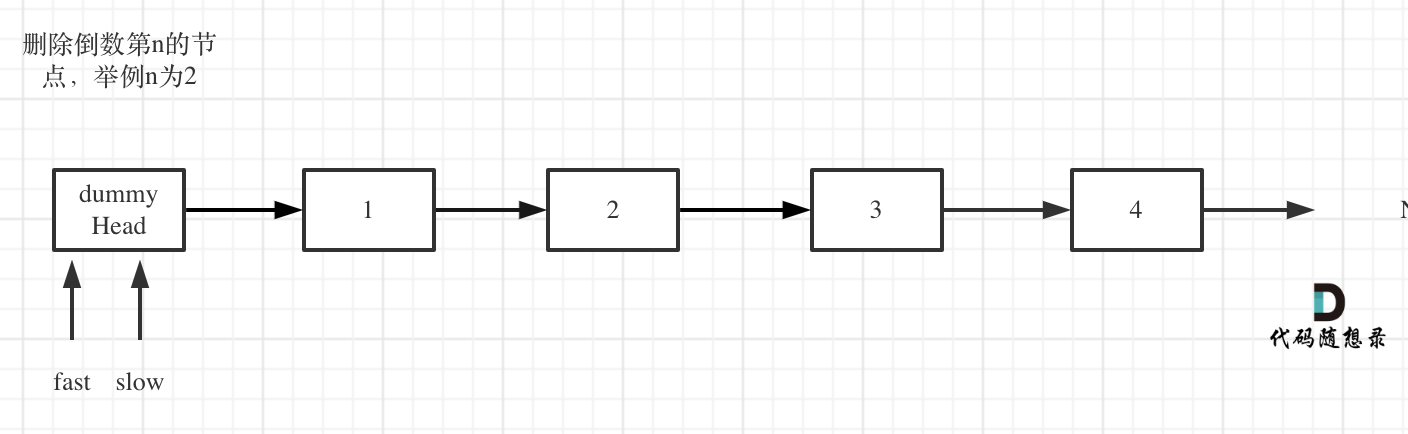
-
fast首先走n + 1步 ,为什么是n+1呢,因为只有这样同时移动的时候slow才能指向删除节点的上一个节点(方便做删除操作),如图:
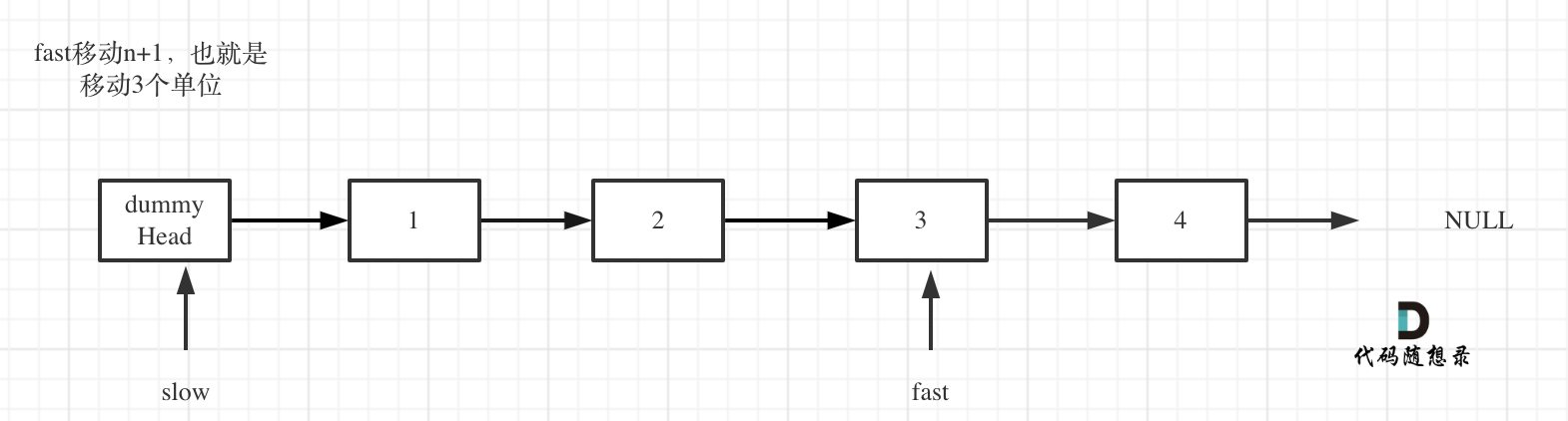
-
fast和slow同时移动,直到fast指向末尾,如题:
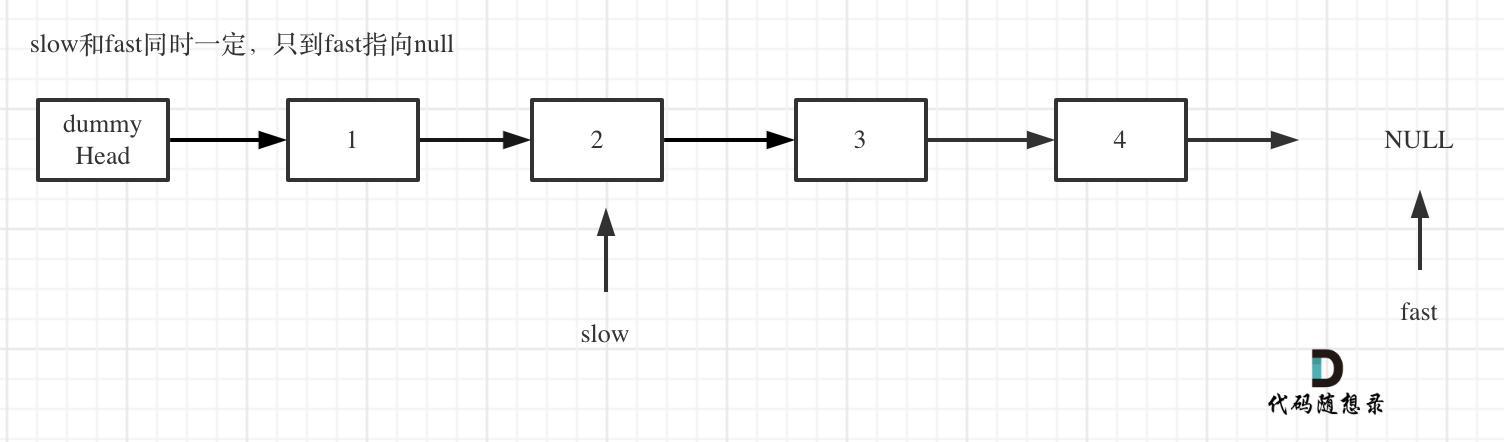
//图片中有错别词:应该将"只到"改为"直到"
-
删除slow指向的下一个节点,如图:
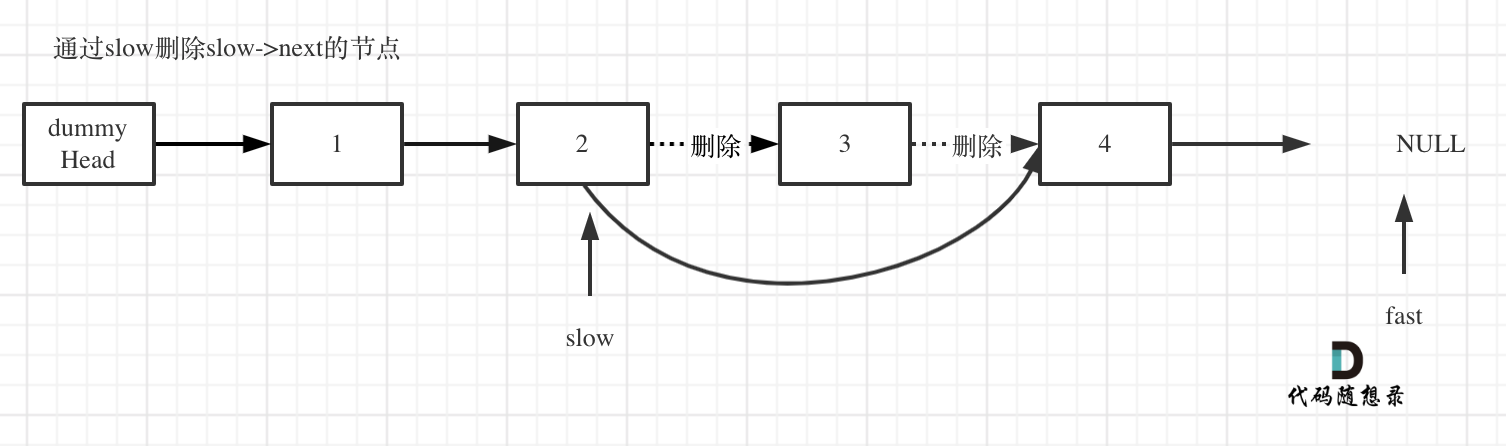
此时不难写出如下C++代码:
class Solution {
public:
ListNode* removeNthFromEnd(ListNode* head, int n) {
ListNode* dummyHead = new ListNode(0);
dummyHead->next = head;
ListNode* slow = dummyHead;
ListNode* fast = dummyHead;
while(n-- && fast != NULL) {
fast = fast->next;
}
fast = fast->next; // fast再提前走一步,因为需要让slow指向删除节点的上一个节点
while (fast != NULL) {
fast = fast->next;
slow = slow->next;
}
slow->next = slow->next->next;
// ListNode *tmp = slow->next; C++释放内存的逻辑
// slow->next = tmp->next;
// delete tmp;
return dummyHead->next;
}
};- 时间复杂度: O(n)
- 空间复杂度: O(1)
注意事项:
1.先要判断fast是否会为空指针,并让fast指针先向前走n步,但由于我们要找到被删除的倒数第n个结点的前一个结点,所以可以让fast先走n+1步后再让fast 和slow指针同时向后走,方便做删除操作,而让fast先走n+1步有俩种操作方式,一种如上,但是可能会在执行fast = fast->next;碰到空指针错误,所以可以如下写
n++; while(n-- && fast != NULL) { fast = fast->next; }
以下是笔者的代码:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* removeNthFromEnd(ListNode* head, int n) {
ListNode* dummyhead = new ListNode(0);
dummyhead -> next = head;
ListNode* fast = dummyhead;
ListNode* slow = dummyhead;
while(n-- && fast -> next != nullptr ){
fast = fast ->next;
}
fast= fast->next;
while(fast != nullptr){
fast = fast ->next;
slow = slow ->next;
}
if(slow->next != nullptr){
slow ->next = slow ->next ->next;
}
return dummyhead->next;
}
};142.环形链表II
参考视频:https://www.bilibili.com/video/BV1if4y1d7ob?t=1167.2
参考文档:142.环形链表II | 代码随想录
力扣题目链接:142. 环形链表 II - 力扣(LeetCode)
题目:
题意: 给定一个链表,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
为了表示给定链表中的环,使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。
说明:不允许修改给定的链表。
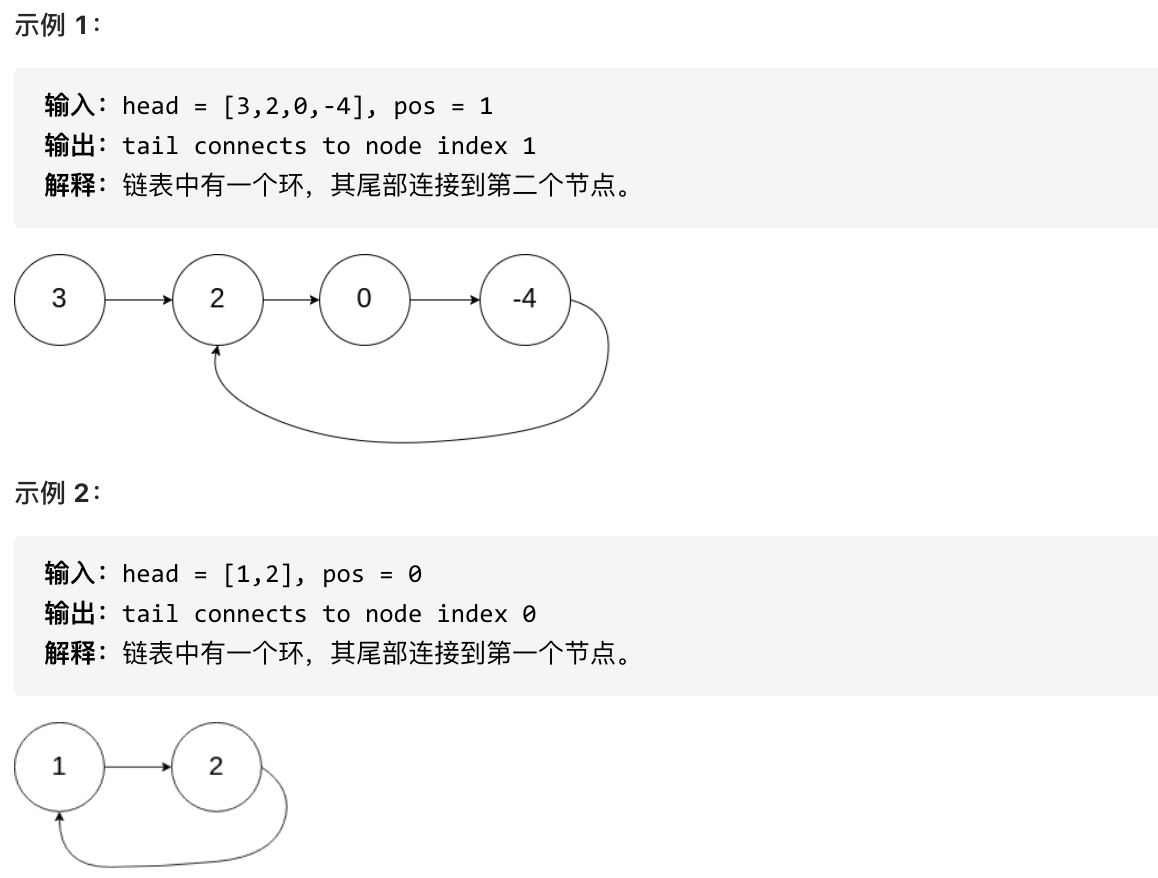
思路
这道题目,不仅考察对链表的操作,而且还需要一些数学运算。
主要考察两知识点:
- 判断链表是否环
- 如果有环,如何找到这个环的入口
#判断链表是否有环
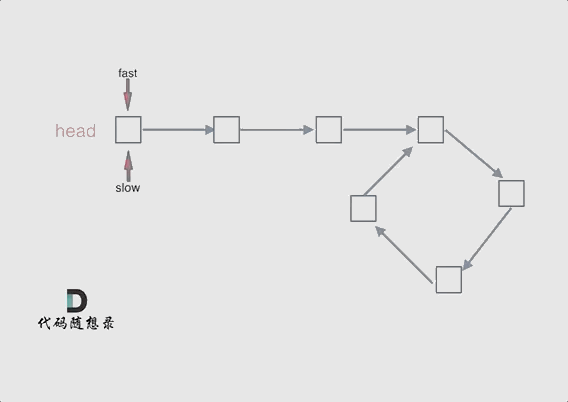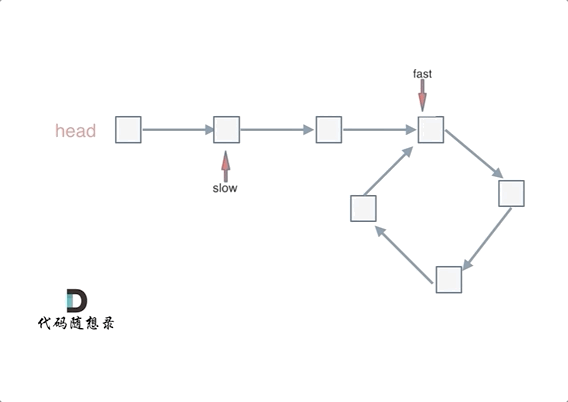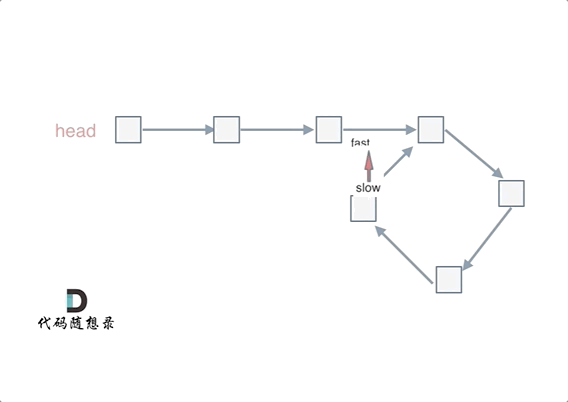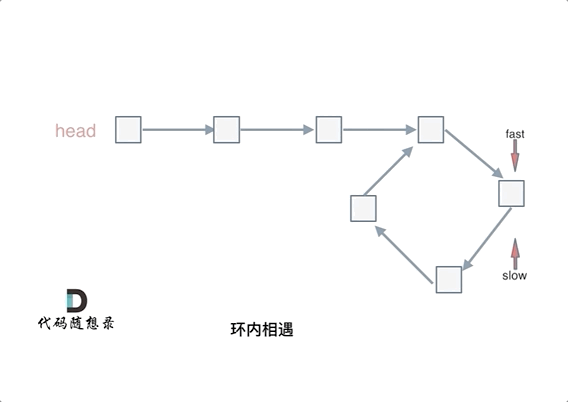
可以使用快慢指针法,分别定义 fast 和 slow 指针,从头结点出发,fast指针每次移动两个节点,slow指针每次移动一个节点,如果 fast 和 slow指针在途中相遇 ,说明这个链表有环。
为什么fast 走两个节点,slow走一个节点,有环的话,一定会在环内相遇呢,而不是永远的错开呢
首先第一点:fast指针一定先进入环中,如果fast指针和slow指针相遇的话,一定是在环中相遇,这是毋庸置疑的。
那么来看一下,为什么fast指针和slow指针一定会相遇呢?
可以画一个环,然后让 fast指针在任意一个节点开始追赶slow指针。
会发现最终都是这种情况, 如下图:
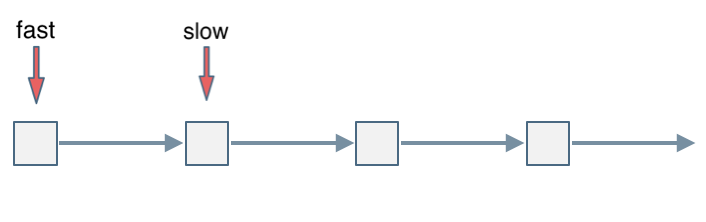
fast和slow各自再走一步, fast和slow就相遇了
这是因为fast是走两步,slow是走一步,其实相对于slow来说,fast是一个节点一个节点的靠近slow的,所以fast一定可以和slow重合。
动画如下:
#如果有环,如何找到这个环的入口
此时已经可以判断链表是否有环了,那么接下来要找这个环的入口了。
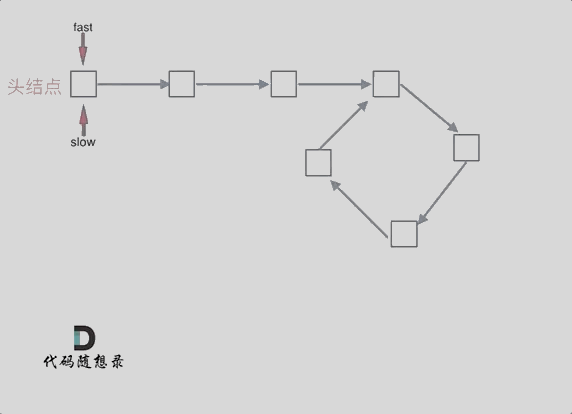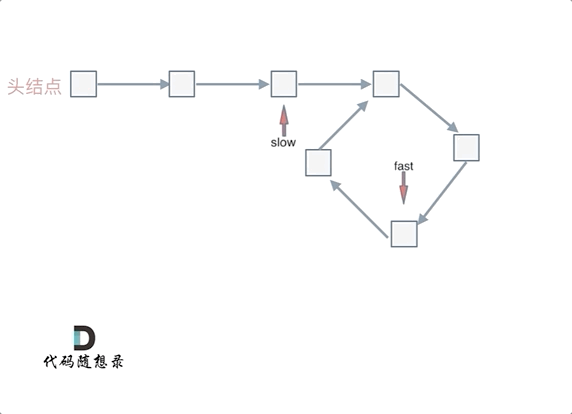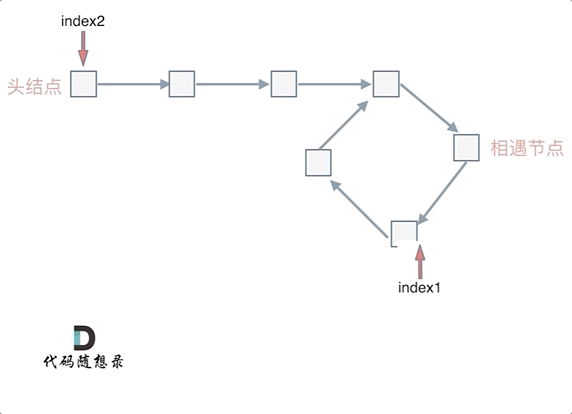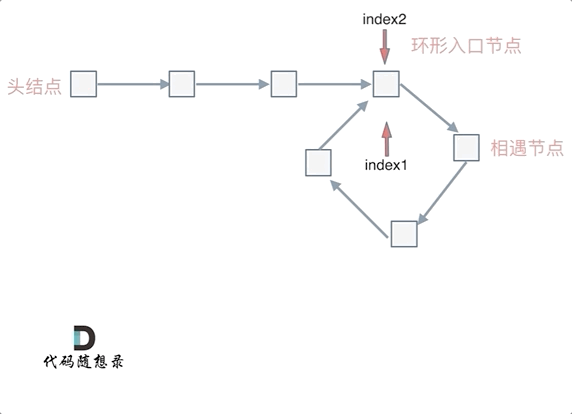
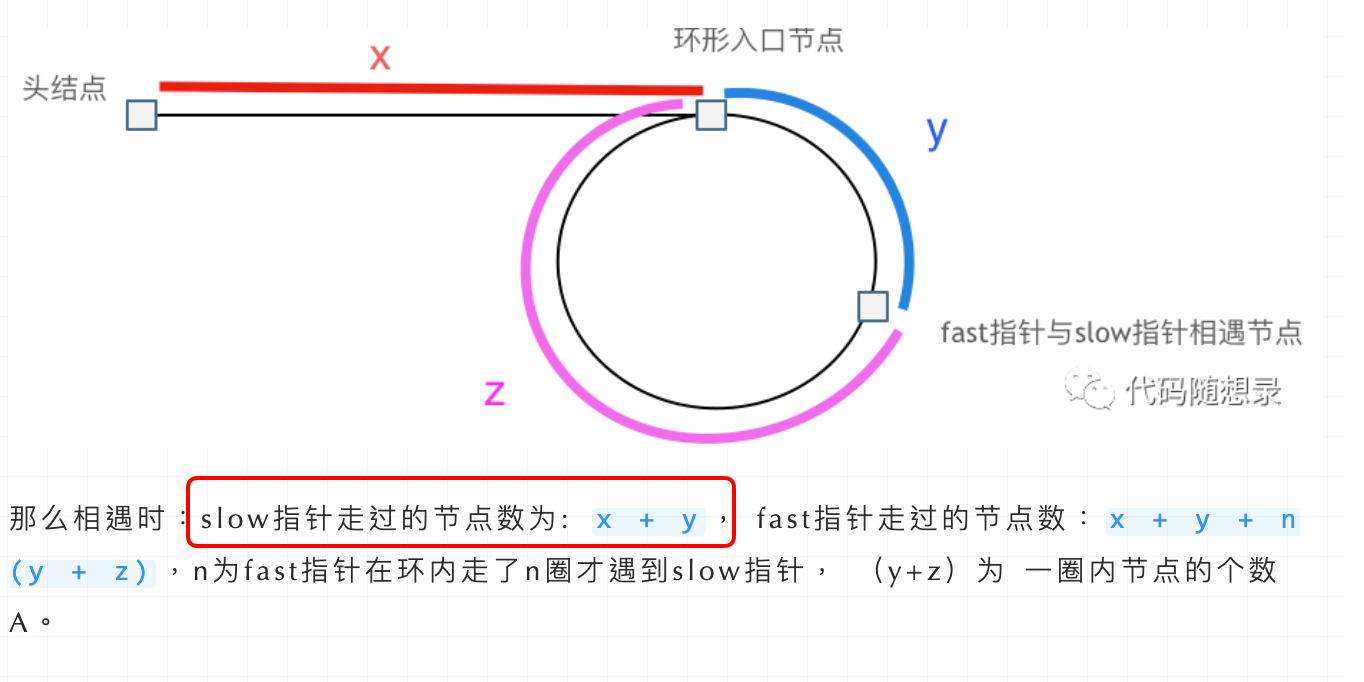
假设从头结点到环形入口节点 的节点数为x。 环形入口节点到 fast指针与slow指针相遇节点 节点数为y。 从相遇节点 再到环形入口节点节点数为 z。 如图所示:
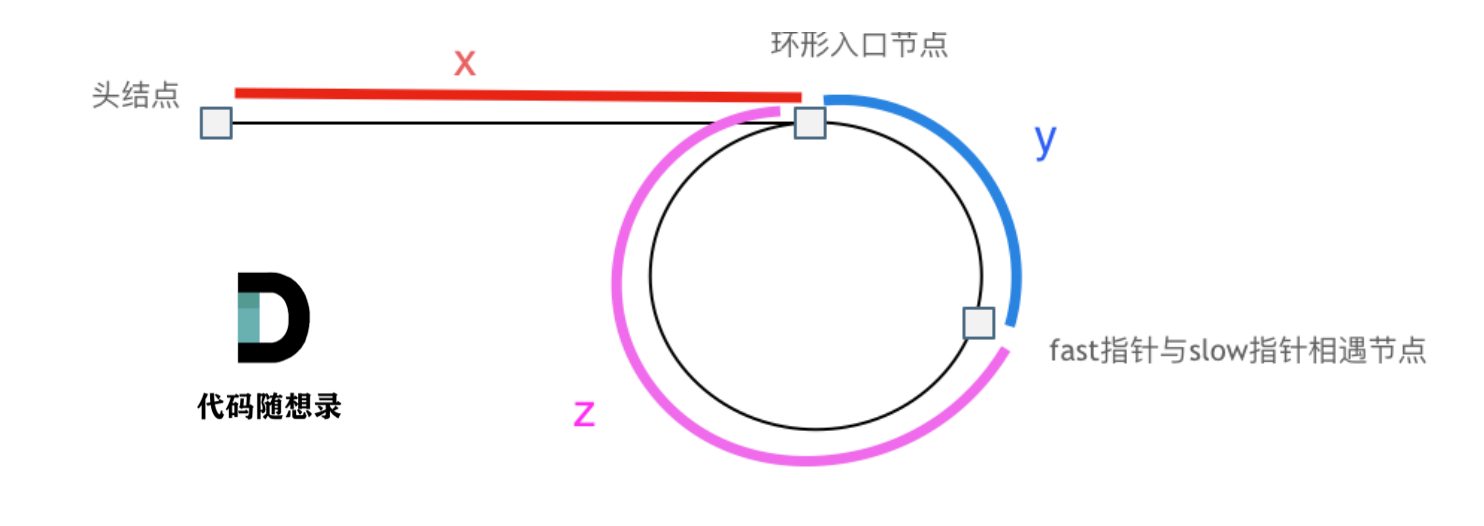
那么相遇时: slow指针走过的节点数为: x + y, fast指针走过的节点数:x + y + n (y + z),n为fast指针在环内走了n圈才遇到slow指针, (y+z)为 一圈内节点的个数A。
因为fast指针是一步走两个节点,slow指针一步走一个节点, 所以 fast指针走过的节点数 = slow指针走过的节点数 * 2:
(x + y) * 2 = x + y + n (y + z)
两边消掉一个(x+y): x + y = n (y + z)
因为要找环形的入口,那么要求的是x,因为x表示 头结点到 环形入口节点的的距离。
所以要求x ,将x单独放在左面:x = n (y + z) - y ,
再从n(y+z)中提出一个 (y+z)来,整理公式之后为如下公式:x = (n - 1) (y + z) + z 注意这里n一定是大于等于1的,因为 fast指针至少要多走一圈才能相遇slow指针。
这个公式说明什么呢?
先拿n为1的情况来举例,意味着fast指针在环形里转了一圈之后,就遇到了 slow指针了。
当 n为1的时候,公式就化解为 x = z,
这就意味着,从头结点出发一个指针,从相遇节点 也出发一个指针,这两个指针每次只走一个节点, 那么当这两个指针相遇的时候就是 环形入口的节点。
也就是在相遇节点处,定义一个指针index1,在头结点处定一个指针index2。
让index1和index2同时移动,每次移动一个节点, 那么他们相遇的地方就是 环形入口的节点。
动画如下:
那么 n如果大于1是什么情况呢,就是fast指针在环形转n圈之后才遇到 slow指针。
其实这种情况和n为1的时候 效果是一样的,一样可以通过这个方法找到 环形的入口节点,只不过,index1 指针在环里 多转了(n-1)圈,然后再遇到index2,相遇点依然是环形的入口节点。
代码如下:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *detectCycle(ListNode *head) {
ListNode* fast = head;
ListNode* slow = head;
while(fast != NULL && fast->next != NULL) {
slow = slow->next;
fast = fast->next->next;
// 快慢指针相遇,此时从head 和 相遇点,同时查找直至相遇
if (slow == fast) {
ListNode* index1 = fast;
ListNode* index2 = head;
while (index1 != index2) {
index1 = index1->next;
index2 = index2->next;
}
return index2; // 返回环的入口
}
}
return NULL;
}
};- 时间复杂度: O(n),快慢指针相遇前,指针走的次数小于链表长度,快慢指针相遇后,两个index指针走的次数也小于链表长度,总体为走的次数小于 2n
- 空间复杂度: O(1)
补充
在推理过程中,大家可能有一个疑问就是:为什么第一次在环中相遇,slow的 步数 是 x+y 而不是 x + 若干环的长度 + y 呢?
即文章链表:环找到了,那入口呢? (opens new window)中如下的地方:
首先slow进环的时候,fast一定是先进环来了。
如果slow进环入口,fast也在环入口,那么把这个环展开成直线,就是如下图的样子:
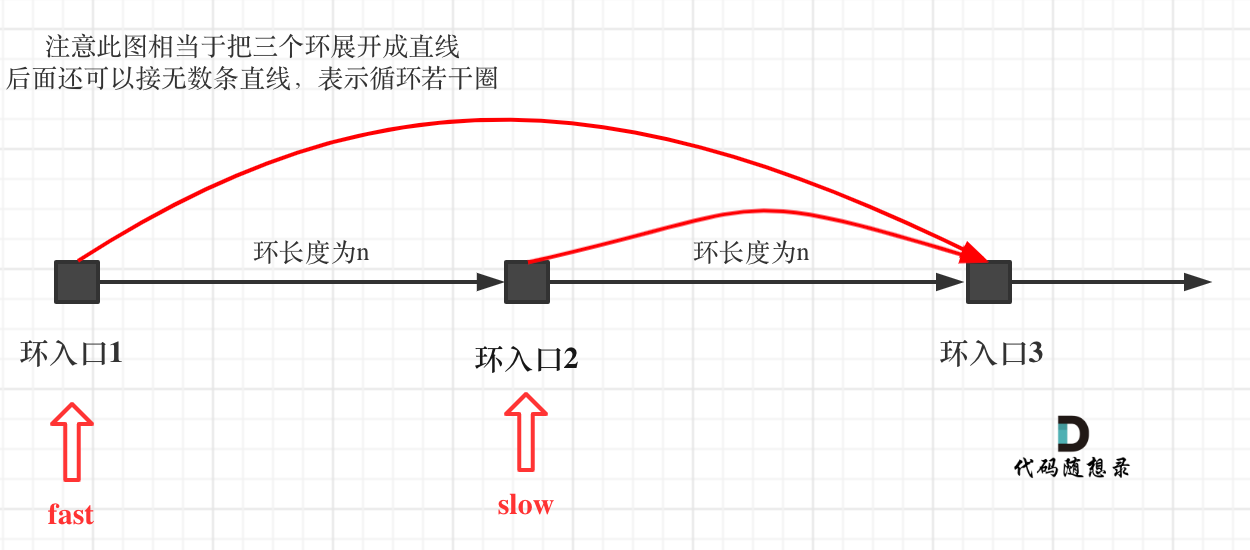
可以看出如果slow 和 fast同时在环入口开始走,一定会在环入口3相遇,slow走了一圈,fast走了两圈。
重点来了,slow进环的时候,fast一定是在环的任意一个位置,如图:
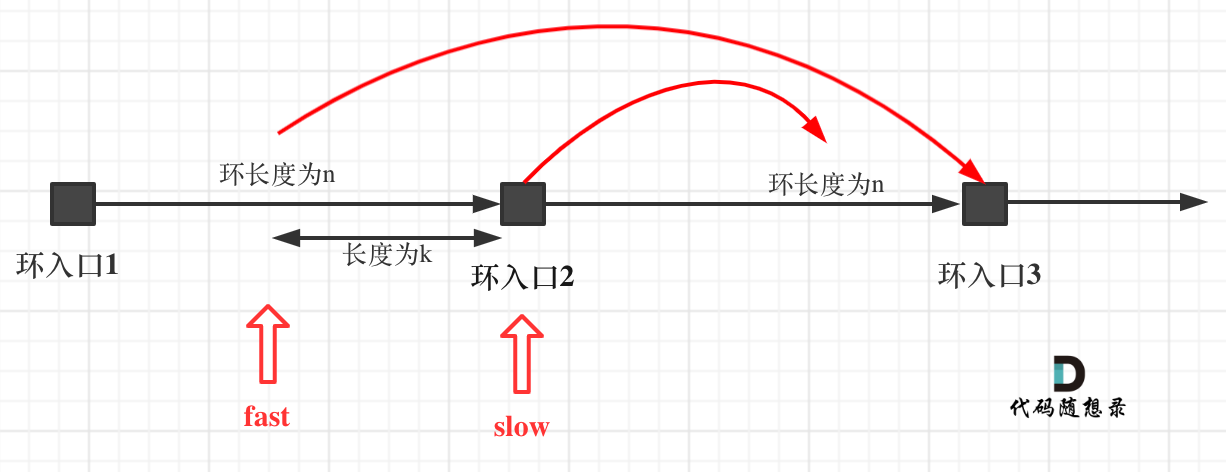
那么fast指针走到环入口3的时候,已经走了k + n 个节点,slow相应的应该走了(k + n) / 2 个节点。
因为k是小于n的(图中可以看出),所以(k + n) / 2 一定小于n。
也就是说slow一定没有走到环入口3,而fast已经到环入口3了。
这说明什么呢?
在slow开始走的那一环已经和fast相遇了。
那有同学又说了,为什么fast不能跳过去呢? 在刚刚已经说过一次了,fast相对于slow是一次移动一个节点,所以不可能跳过去。
好了,这次把为什么第一次在环中相遇,slow的 步数 是 x+y 而不是 x + 若干环的长度 + y ,用数学推理了一下,算是对链表:环找到了,那入口呢? (opens new window)的补充。
可以参考下面这张图:
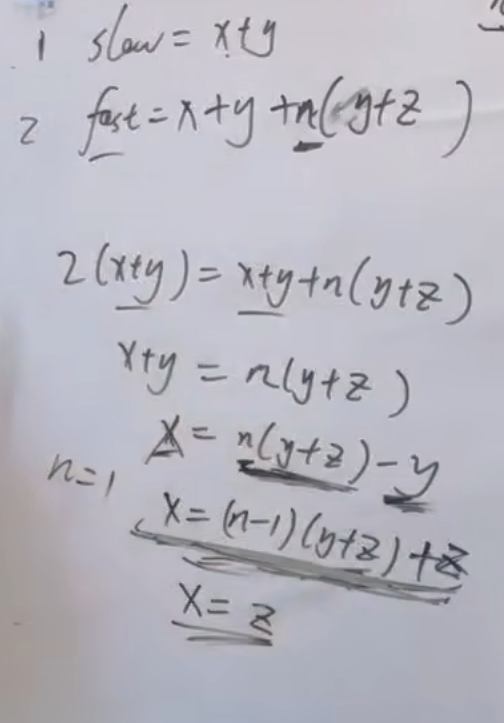
本题up已经讲的很详细了,所以笔者在这就简单给出自己的代码
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *detectCycle(ListNode *head) {
ListNode * fast = head;
ListNode * slow = head;
while(fast != NULL && fast ->next != NULL){
fast = fast ->next ->next;
slow = slow ->next;
if(fast == slow){
ListNode* index1 = fast;
ListNode* index2 = head;
while(index1 != index2 ){
index1 =index1 ->next;
index2 = index2 ->next;
}
return index1;
}
}
return NULL;
}
};同时附上代码随想录的链表总结,以便有助于大家更进一步复习该知识点
链表总结篇
#链表的理论基础
在这篇文章关于链表,你该了解这些! (opens new window)中,介绍了如下几点:
- 链表的种类主要为:单链表,双链表,循环链表
- 链表的存储方式:链表的节点在内存中是分散存储的,通过指针连在一起。
- 链表是如何进行增删改查的。
- 数组和链表在不同场景下的性能分析。
可以说把链表基础的知识都概括了,但又不像教科书那样的繁琐。
#链表经典题目
#虚拟头结点
在链表:听说用虚拟头节点会方便很多? (opens new window)中,我们讲解了链表操作中一个非常重要的技巧:虚拟头节点。
链表的一大问题就是操作当前节点必须要找前一个节点才能操作。这就造成了,头结点的尴尬,因为头结点没有前一个节点了。
每次对应头结点的情况都要单独处理,所以使用虚拟头结点的技巧,就可以解决这个问题。
在链表:听说用虚拟头节点会方便很多? (opens new window)中,我给出了用虚拟头结点和没用虚拟头结点的代码,大家对比一下就会发现,使用虚拟头结点的好处。
#链表的基本操作
在链表:一道题目考察了常见的五个操作! (opens new window)中,我们通过设计链表把链表常见的五个操作练习了一遍。
这是练习链表基础操作的非常好的一道题目,考察了:
- 获取链表第index个节点的数值
- 在链表的最前面插入一个节点
- 在链表的最后面插入一个节点
- 在链表第index个节点前面插入一个节点
- 删除链表的第index个节点的数值
可以说把这道题目做了,链表基本操作就OK了,再也不用担心链表增删改查整不明白了。
这里我依然使用了虚拟头结点的技巧,大家复习的时候,可以去看一下代码。
#反转链表
在链表:听说过两天反转链表又写不出来了? (opens new window)中,讲解了如何反转链表。
因为反转链表的代码相对简单,有的同学可能直接背下来了,但一写还是容易出问题。
反转链表是面试中高频题目,很考察面试者对链表操作的熟练程度。
我在文章 (opens new window)中,给出了两种反转的方式,迭代法和递归法。
建议大家先学透迭代法,然后再看递归法,因为递归法比较绕,如果迭代还写不明白,递归基本也写不明白了。
可以先通过迭代法,彻底弄清楚链表反转的过程!
#删除倒数第N个节点
在链表:删除链表倒数第N个节点,怎么删? (opens new window)中我们结合虚拟头结点 和 双指针法来移除链表倒数第N个节点。
#链表相交
链表:链表相交 (opens new window)使用双指针来找到两个链表的交点(引用完全相同,即:内存地址完全相同的交点)
#环形链表
在链表:环找到了,那入口呢? (opens new window)中,讲解了在链表如何找环,以及如何找环的入口位置。
这道题目可以说是链表的比较难的题目了。 但代码却十分简洁,主要在于一些数学证明。
#总结
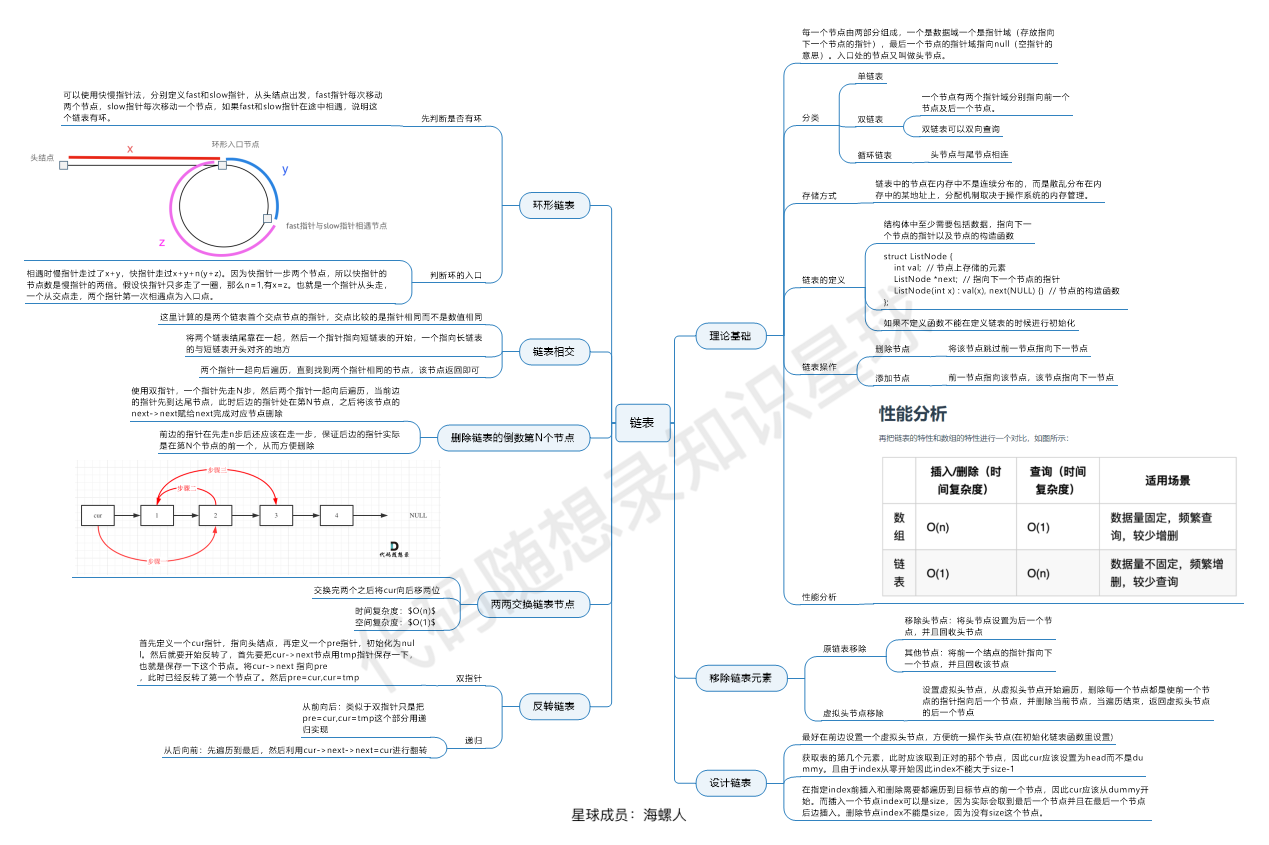
这个图是 代码随想录知识星球 (opens new window)成员:海螺人 (opens new window),所画,总结的非常好,分享给大家。
考察链表的操作其实就是考察指针的操作,是面试中的常见类型。
链表篇中开头介绍链表理论知识 (opens new window),然后分别通过经典题目介绍了如下知识点:
- 关于链表,你该了解这些!(opens new window)
- 虚拟头结点的技巧(opens new window)
- 链表的增删改查(opens new window)
- 反转一个链表(opens new window)
- 删除倒数第N个节点(opens new window)
- 链表相交(opens new window)
- 有否环形,以及环的入口
2.c++学习
前言
配套视频:https://www.bilibili.com/video/BV1et411b73Z
只是为方便学习,不做其他用途,在此发布C++基础入门部分配套讲义,原作者为黑马程序
参考文档:第3阶段-C++核心编程 资料/讲义/C++核心编程.md · 赤伶/Cpp-0-1-Resource - 码云 - 开源中国
由于之前不知为何视频跳了很多,今天笔者学习的是引用和函数提高,并在相应出给出笔者的学习心得
内存分区模型
C++程序在执行时,将内存大方向划分为4个区域
- 代码区:存放函数体的二进制代码,由操作系统进行管理的
- 全局区:存放全局变量和静态变量以及常量
- 栈区:由编译器自动分配释放, 存放函数的参数值,局部变量等
- 堆区:由程序员分配和释放,若程序员不释放,程序结束时由操作系统回收
内存四区意义:
不同区域存放的数据,赋予不同的生命周期, 给我们更大的灵活编程
1.1 程序运行前
在程序编译后,生成了exe可执行程序,未执行该程序前分为两个区域
代码区:
存放 CPU 执行的机器指令
代码区是共享的,共享的目的是对于频繁被执行的程序,只需要在内存中有一份代码即可
代码区是只读的,使其只读的原因是防止程序意外地修改了它的指令
全局区:
全局变量和静态变量存放在此.
全局区还包含了常量区, 字符串常量和其他常量也存放在此.
==该区域的数据在程序结束后由操作系统释放==.
示例:
//全局变量
int g_a = 10;
int g_b = 10;
//全局常量
const int c_g_a = 10;
const int c_g_b = 10;
int main() {
//局部变量
int a = 10;
int b = 10;
//打印地址
cout << "局部变量a地址为: " << (int)&a << endl;
cout << "局部变量b地址为: " << (int)&b << endl;
cout << "全局变量g_a地址为: " << (int)&g_a << endl;
cout << "全局变量g_b地址为: " << (int)&g_b << endl;
//静态变量
static int s_a = 10;
static int s_b = 10;
cout << "静态变量s_a地址为: " << (int)&s_a << endl;
cout << "静态变量s_b地址为: " << (int)&s_b << endl;
cout << "字符串常量地址为: " << (int)&"hello world" << endl;
cout << "字符串常量地址为: " << (int)&"hello world1" << endl;
cout << "全局常量c_g_a地址为: " << (int)&c_g_a << endl;
cout << "全局常量c_g_b地址为: " << (int)&c_g_b << endl;
const int c_l_a = 10;
const int c_l_b = 10;
cout << "局部常量c_l_a地址为: " << (int)&c_l_a << endl;
cout << "局部常量c_l_b地址为: " << (int)&c_l_b << endl;
system("pause");
return 0;
}打印结果:

总结:
- C++中在程序运行前分为全局区和代码区
- 代码区特点是共享和只读
- 全局区中存放全局变量、静态变量、常量
- 常量区中存放 const修饰的全局常量 和 字符串常量
1.2 程序运行后
栈区:
由编译器自动分配释放, 存放函数的参数值,局部变量等
注意事项:不要返回局部变量的地址,栈区开辟的数据由编译器自动释放
示例:
int * func()
{
int a = 10;
return &a;
}
int main() {
int *p = func();
cout << *p << endl;
cout << *p << endl;
system("pause");
return 0;
} 堆区:
由程序员分配释放,若程序员不释放,程序结束时由操作系统回收
在C++中主要利用new在堆区开辟内存
示例:
int* func()
{
int* a = new int(10);
return a;
}
int main() {
int *p = func();
cout << *p << endl;
cout << *p << endl;
system("pause");
return 0;
}总结:
堆区数据由程序员管理开辟和释放
堆区数据利用new关键字进行开辟内存
1.3 new操作符
C++中利用==new==操作符在堆区开辟数据
堆区开辟的数据,由程序员手动开辟,手动释放,释放利用操作符 ==delete==
语法: new 数据类型
利用new创建的数据,会返回该数据对应的类型的指针
示例1: 基本语法
int* func()
{
int* a = new int(10);
return a;
}
int main() {
int *p = func();
cout << *p << endl;
cout << *p << endl;
//利用delete释放堆区数据
delete p;
//cout << *p << endl; //报错,释放的空间不可访问
system("pause");
return 0;
}示例2:开辟数组
//堆区开辟数组
int main() {
int* arr = new int[10];
for (int i = 0; i < 10; i++)
{
arr[i] = i + 100;
}
for (int i = 0; i < 10; i++)
{
cout << arr[i] << endl;
}
//释放数组 delete 后加 []
delete[] arr;
system("pause");
return 0;
}2 引用
2.1 引用的基本使用
**作用: **给变量起别名
语法: 数据类型 &别名 = 原名
示例:
int main() {
int a = 10;
int &b = a;
cout << "a = " << a << endl;
cout << "b = " << b << endl;
b = 100;
cout << "a = " << a << endl;
cout << "b = " << b << endl;
system("pause");
return 0;
}2.2 引用注意事项
- 引用必须初始化
- 引用在初始化后,不可以改变
示例:
int main() {
int a = 10;
int b = 20;
//int &c; //错误,引用必须初始化
int &c = a; //一旦初始化后,就不可以更改
c = b; //这是赋值操作,不是更改引用
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl;
system("pause");
return 0;
}2.3 引用做函数参数
**作用:**函数传参时,可以利用引用的技术让形参修饰实参
**优点:**可以简化指针修改实参
示例:
//1. 值传递
void mySwap01(int a, int b) {
int temp = a;
a = b;
b = temp;
}
//2. 地址传递
void mySwap02(int* a, int* b) {
int temp = *a;
*a = *b;
*b = temp;
}
//3. 引用传递
void mySwap03(int& a, int& b) {
int temp = a;
a = b;
b = temp;
}
int main() {
int a = 10;
int b = 20;
mySwap01(a, b);
cout << "a:" << a << " b:" << b << endl;
mySwap02(&a, &b);
cout << "a:" << a << " b:" << b << endl;
mySwap03(a, b);
cout << "a:" << a << " b:" << b << endl;
system("pause");
return 0;
}总结:通过引用参数产生的效果同按地址传递是一样的。引用的语法更清楚简单
2.4 引用做函数返回值
作用:引用是可以作为函数的返回值存在的
注意:不要返回局部变量引用
用法:函数调用作为左值
示例:
//返回局部变量引用
int& test01() {
int a = 10; //局部变量
return a;
}
//返回静态变量引用
int& test02() {
static int a = 20;
return a;
}
int main() {
//不能返回局部变量的引用
int& ref = test01();
cout << "ref = " << ref << endl;
cout << "ref = " << ref << endl;
//如果函数做左值,那么必须返回引用
int& ref2 = test02();
cout << "ref2 = " << ref2 << endl;
cout << "ref2 = " << ref2 << endl;
test02() = 1000;
cout << "ref2 = " << ref2 << endl;
cout << "ref2 = " << ref2 << endl;
system("pause");
return 0;
}
2.5 引用的本质
本质:引用的本质在c++内部实现是一个指针常量.
讲解示例:
//发现是引用,转换为 int* const ref = &a;
void func(int& ref){
ref = 100; // ref是引用,转换为*ref = 100
}
int main(){
int a = 10;
//自动转换为 int* const ref = &a; 指针常量是指针指向不可改,也说明为什么引用不可更改
int& ref = a;
ref = 20; //内部发现ref是引用,自动帮我们转换为: *ref = 20;
cout << "a:" << a << endl;
cout << "ref:" << ref << endl;
func(a);
return 0;
}结论:C++推荐用引用技术,因为语法方便,引用本质是指针常量,但是所有的指针操作编译器都帮我们做了
2.6 常量引用
**作用:**常量引用主要用来修饰形参,防止误操作
在函数形参列表中,可以加==const修饰形参==,防止形参改变实参
示例:
//引用使用的场景,通常用来修饰形参
void showValue(const int& v) {
//v += 10;
cout << v << endl;
}
int main() {
//int& ref = 10; 引用本身需要一个合法的内存空间,因此这行错误
//加入const就可以了,编译器优化代码,int temp = 10; const int& ref = temp;
const int& ref = 10;
//ref = 100; //加入const后不可以修改变量
cout << ref << endl;
//函数中利用常量引用防止误操作修改实参
int a = 10;
showValue(a);
system("pause");
return 0;
}3 函数提高
3.1 函数默认参数
在C++中,函数的形参列表中的形参是可以有默认值的。
语法: 返回值类型 函数名 (参数= 默认值){}
示例:
int func(int a, int b = 10, int c = 10) {
return a + b + c;
}
//1. 如果某个位置参数有默认值,那么从这个位置往后,从左向右,必须都要有默认值
//2. 如果函数声明有默认值,函数实现的时候就不能有默认参数
int func2(int a = 10, int b = 10);
int func2(int a, int b) {
return a + b;
}
int main() {
cout << "ret = " << func(20, 20) << endl;
cout << "ret = " << func(100) << endl;
system("pause");
return 0;
}3.2 函数占位参数
C++中函数的形参列表里可以有占位参数,用来做占位,调用函数时必须填补该位置
语法: 返回值类型 函数名 (数据类型){}
在现阶段函数的占位参数存在意义不大,但是后面的课程中会用到该技术
示例:
//函数占位参数 ,占位参数也可以有默认参数
void func(int a, int) {
cout << "this is func" << endl;
}
int main() {
func(10,10); //占位参数必须填补
system("pause");
return 0;
}3.3 函数重载
3.3.1 函数重载概述
**作用:**函数名可以相同,提高复用性
函数重载满足条件:
- 同一个作用域下
- 函数名称相同
- 函数参数类型不同 或者 个数不同 或者 顺序不同
注意: 函数的返回值不可以作为函数重载的条件
示例:
//函数重载需要函数都在同一个作用域下
void func()
{
cout << "func 的调用!" << endl;
}
void func(int a)
{
cout << "func (int a) 的调用!" << endl;
}
void func(double a)
{
cout << "func (double a)的调用!" << endl;
}
void func(int a ,double b)
{
cout << "func (int a ,double b) 的调用!" << endl;
}
void func(double a ,int b)
{
cout << "func (double a ,int b)的调用!" << endl;
}
//函数返回值不可以作为函数重载条件
//int func(double a, int b)
//{
// cout << "func (double a ,int b)的调用!" << endl;
//}
int main() {
func();
func(10);
func(3.14);
func(10,3.14);
func(3.14 , 10);
system("pause");
return 0;
}3.3.2 函数重载注意事项
- 引用作为重载条件
- 函数重载碰到函数默认参数
示例:
//函数重载注意事项
//1、引用作为重载条件
void func(int &a)
{
cout << "func (int &a) 调用 " << endl;
}
void func(const int &a)
{
cout << "func (const int &a) 调用 " << endl;
}
//2、函数重载碰到函数默认参数
void func2(int a, int b = 10)
{
cout << "func2(int a, int b = 10) 调用" << endl;
}
void func2(int a)
{
cout << "func2(int a) 调用" << endl;
}
int main() {
int a = 10;
func(a); //调用无const
func(10);//调用有const
//func2(10); //碰到默认参数产生歧义,需要避免
system("pause");
return 0;
}为了看着更加整洁,笔者的相应文件如下
相应的代码如下
目录
<#双指针法>
<#递归法>
[24. 两两交换链表中的节点](#24. 两两交换链表中的节点)
<#判断链表是否有环>
<#链表的理论基础>
<#链表经典题目>
<#虚拟头结点>
<#链表的基本操作>
<#反转链表>
<#链表相交>
<#环形链表>
<#总结>
[1.1 程序运行前](#1.1 程序运行前)
[1.2 程序运行后](#1.2 程序运行后)
[1.3 new操作符](#1.3 new操作符)
[2 引用](#2 引用)
[2.1 引用的基本使用](#2.1 引用的基本使用)
[2.2 引用注意事项](#2.2 引用注意事项)
[2.3 引用做函数参数](#2.3 引用做函数参数)
[2.4 引用做函数返回值](#2.4 引用做函数返回值)
[2.5 引用的本质](#2.5 引用的本质)
[2.6 常量引用](#2.6 常量引用)
[3 函数提高](#3 函数提高)
[3.1 函数默认参数](#3.1 函数默认参数)
[3.2 函数占位参数](#3.2 函数占位参数)
[3.3 函数重载](#3.3 函数重载)
[3.3.1 函数重载概述](#3.3.1 函数重载概述)
[3.3.2 函数重载注意事项](#3.3.2 函数重载注意事项)
#pragma once
#include<iostream>
#include<string>
using namespace std;
//int* func(int b);
//int* func1();
void mySwap01(int a, int b);
void mySwap02(int* a, int* b);
void mySwap03(int& a, int& b);
int* func2();
//void test01();
//
//void test02();
void showValue(const int& v);func.cpp
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
#include<string>
using namespace std;
//栈区数据注意事项 -- 不要返回局部变量的地址
//栈区的数据由编译器管理开辟和释放
int* func(int b) //形参数据也会放在栈区
{
b = 100;
int a = 10; //局部变量 存放在栈区 栈区的数据在函数执行完后自动释放
return &a; //返回局部变量的地址
}
int* func1()
{
//利用new 关键字 可以将数据开辟到堆区
//指针本质也是局部变量 放在栈上 指针保存的数据是放在堆区
int* a = new int(10);
return a;
}
//交换函数
//值传递
void mySwap01(int a, int b) {
int temp = a;
a = b;
b = temp;
}
//2. 地址传递
void mySwap02(int* a, int* b) {
int temp = *a;
*a = *b;
*b = temp;
}
//3. 引用传递
void mySwap03(int& a, int& b) {
int temp = a;
a = b;
b = temp;
}
//new 的基本语法
int* func2()
{
//在堆区创建整型数据
//new返回的是 该数据类型的指针;
int* p = new int(10);
return p;
}
//void test01() {
// int* p = func2();
// cout << *p << endl;
// //堆区的数据由程序员管理开辟,程序员管理释放
// //如果想释放堆区的数据 利用关键字delete
// delete p;
//
// //cout << *p << endl; //内存已经被释放 在此访问就是非法操作,会报错
//}
//
////在堆区利用new开辟数组
//
//void test02() {
// //创建10整型数据的数组,在堆区
// int* arr = new int[10];//10代表数组有10个元素
//
// for (int i = 0; i < 10; i++)
// {
// arr[i] = i + 100; //给10个元素赋值100-109
// }
//
// for (int i = 0; i < 10; i++)
// {
// cout << arr[i] << endl;
// }
// //释放数组 delete 后加 []
// delete[] arr;
//}
//打印数据函数
void showValue(const int& v) {
//v += 10;
cout << v << endl;
}函数.cpp
//#define _CRT_SECURE_NO_WARNINGS 1
//#include<iostream>
//#include<string>
//using namespace std;
//#include "func.h"
//
//
//
////函数默认参数
////在C++中,函数的形参列表中的形参是可以有默认值的。
////如果我们自己传入数据,就用自己的数据 如果没有,就用默认值
//
////int func(int a, int b = 10, int c = 10) {
//// return a + b + c;
////}
////
//////注意事项
//////1. 如果某个位置参数有默认值,那么从这个位置往后,从左向右,必须都要有默认值
//////int func2(int a = 10, int b );
////
//////2. 如果函数声明有默认值,函数实现的时候就不能有默认参数
//////声明和实现智能有一个有默认参数
////int func2(int a, int b);
////int func2(int a, int b) {
//// return a + b;
////}
//
////函数占位参数
////C++中函数的形参列表里可以有占位参数,用来做占位,调用函数时必须填补该位置
////
////语法: 返回值类型 函数名(数据类型) {}
////
////在现阶段函数的占位参数存在意义不大,但是后面的课程中会用到该技术
//
//
////函数重载
////3.3.1 函数重载概述
////* *作用: * *函数名可以相同,提高复用性
////
////函数重载满足条件:
////
////同一个作用域下
////函数名称相同
////函数参数类型不同 或者 个数不同 或者 顺序不同
////注意 : 函数的返回值不可以作为函数重载的条件
//
////
////void func()
////{
//// cout << "func 的调用!" << endl;
////}
////void func(int a)
////{
//// cout << "func (int a) 的调用!" << endl;
////}
////void func(double a)
////{
//// cout << "func (double a)的调用!" << endl;
////}
////void func(int a, double b)
////{
//// cout << "func (int a ,double b) 的调用!" << endl;
////}
////void func(double a, int b)
////{
//// cout << "func (double a ,int b)的调用!" << endl;
////}
//
////函数重载注意事项
////1、引用作为重载条件
//
//void func(int& a)
//{
// cout << "func (int &a) 调用 " << endl;
//}
//
//void func(const int& a)
//{
// cout << "func (const int &a) 调用 " << endl;
//}
//
//
////2、函数重载碰到函数默认参数
//
//void func2(int a, int b = 10)
//{
// cout << "func2(int a, int b = 10) 调用" << endl;
//}
//
//void func2(int a)
//{
// cout << "func2(int a) 调用" << endl;
//}
//
//
//int main() {
//
//
// //cout << "ret = " << func(20, 20) << endl;
// //cout << "ret = " << func(20) << endl;
// //cout << "ret = " << func2(100) << endl;//2. 如果函数声明有默认值,函数实现的时候就不能有默认参数
//
// //func(); //占位参数必须填补
//
// //func();
// //func(10);
// //func(3.14);
// //func(10, 3.14);
// //func(3.14, 10);
//
//
// int a = 10;
// func(a); //调用无const
// func(10);//调用有const
//
// system("pause");
//
// return 0;
//}引用.cpp
//#define _CRT_SECURE_NO_WARNINGS 1
//#include<iostream>
//#include<string>
//using namespace std;
//#include "func.h"
//
////全局变量
//int g_a = 10;
//int g_b = 10;
//
////cosnt 修饰的全局变量 全局常量
//const int c_g_a = 10;
//const int c_g_b = 20;
//
//
////返回局部变量引用
//int& test01() {
// int a = 10; //局部变量
// return a;
//}
//
////返回静态变量引用
//int& test02() {
// static int a = 20; //静态变量,存放在全局区 全局区上的数据在程序结束后系统释放
// return a;
//}
//
//
//int main() {
//
// ////全局区
//
// ////全局变量,静态变量,常量
//
// ////常见普通局部变量
// //int a = 10;
// //int b = 10;
// //cout << "局部变量a的地址为" << (int)&a << endl;
// //cout << "局部变量b的地址为" << (int)&b << endl;
//
//
// //cout << "全局变量g_a的地址为" << (int)&g_a << endl;
// //cout << "全局变量g_b的地址为" << (int)&g_b << endl;
//
// ////静态变量 在普通变量前面加static 属于静态变量 也存放在全局区中
// //static int s_a = 10;
// //static int s_b = 10;
//
// //cout << "静态变量s_a的地址为" << (int)&s_a << endl;
// //cout << "静态变量s_b的地址为" << (int)&s_b << endl;
// //
// ////常量
// ////字符串常量 也放在全局区
// //cout << "字符串常量的地址为" << (int)&"hello word" << endl;
//
// ////const修饰的变量
// ////const 修饰的全局变量 放在全局区
// //// const 修饰的局部变量 放在常量区
// //cout << "全局常量c_g_a的地址为" << (int)&c_g_a << endl;
// //cout << "全局常量c_g_b的地址为" << (int)&c_g_b << endl;
//
// //int c_l_a = 10;//c-const g-global l-local
// //int c_l_b = 10;
// //cout << "局部常量c_l_a的地址为" << (int)&c_l_a << endl;
// //cout << "局部常量c_l_b的地址为" << (int)&c_l_b << endl;
//
//
// //栈区数据注意事项 -- 不要返回局部变量的地址
// ////接受func函数的返回值
// //int* p = func(1);
//
// //cout << *p << endl; //第一次可以正确打印正确的数字,是因为编译器做了保留
// //cout << *p << endl; //第二次这个数据就不再保留了 如果俩次都是10 可以选x86编译一下就会出错
//
// //利用new 关键字 可以将数据开辟到堆区
// //int* p = func1();
//
// //cout << *p << endl;
// //cout << *p << endl;
//
// //new 的基本语法
// //在堆区利用new开辟数组
//
// //test02();
//
//
// ////引用基本语法
// ////数据类型&别名 =原名
// //int a = 10;
// ////创建引用
// //int& b = a;
//
// //cout << "a = " << a << endl;
// //cout << "b = " << b << endl;
//
// //b = 100;
//
// //cout << "a = " << a << endl;
// //cout << "b = " << b << endl;
//
// ////引用注意事项
// ////引用必须初始化
// ////引用在初始化后,不可以改变
// //int a = 10;
// //int b = 20;
// ////int &c; //错误,引用必须初始化
// //int& c = a; //一旦初始化后,就不可以更改
// //c = b; //这是赋值操作,不是更改引用
//
// //cout << "a = " << a << endl;
// //cout << "b = " << b << endl;
// //cout << "c = " << c << endl;
//
//
// //int a = 10;
// //int b = 20;
//
// //mySwap01(a, b); //值传递 形参不会修饰实参
// //cout << "swap01 a:" << a << "swap01 b:" << b << endl;
//
// //mySwap02(&a, &b); //地址传递,形参会修饰实参的
// //cout << "a:" << a << " b:" << b << endl;
//
// //// 重置值,测试引用传递
// //a = 10;
// //b = 20;
//
// ////int& a 表示 a 是实参的 "别名",操作别名等价于操作实参本身,所以交换成功;
// //mySwap03(a, b);//引用传递 形参会修饰实参的
// //cout << "swap03 a:" << a << " swap03 b:" << b << endl;
//
//
// //作用:引用是可以作为函数的返回值存在的
// //
// //注意:不要返回局部变量引用
// //
// //用法:函数调用作为左值
//
// ////不能返回局部变量的引用 是非法操作
// //int& ref = test01();
// //cout << "ref = " << ref << endl;
// //cout << "ref = " << ref << endl;
//
// ////如果函数做左值,那么必须返回引用
// //int& ref2 = test02();
// //cout << "ref2 = " << ref2 << endl;
// //cout << "ref2 = " << ref2 << endl;
//
// //test02() = 1000; //如果函数的返回值是引用,这个函数调用可以作为左值
//
// //cout << "ref2 = " << ref2 << endl;
// //cout << "ref2 = " << ref2 << endl;
//
// //引用的本质
// // 本质:引用的本质在c++内部实现是一个指针常量.
//
// //常量引用
// // ** 作用:** 常量引用主要用来修饰形参,防止误操作
//
// // 在函数形参列表中,可以加 == const修饰形参 == ,防止形参改变实参
// //int a = 10;
// //int& ref = 10; //引用必须引一块合法的内存空间
// //加上const之后 编译器将代码修改 int temp = 10;const int &ref = temp;
// //const int& ref = 10;
// //ref = 20; //加入cosnt之后变为只读 不可以修改
//
// int a = 1000;
// showValue(a);
//
// system("pause");
//
// return 0;
//}许多注意事项都在代码中,如读者有耐心可以跟着代码一步一步去试试,其中包括报错的代码和报错原因
++相信看到这的你也很努力,望与诸君共勉!!!++