文章目录
- [A Survey of Query Optimization in Large Language Models](#A Survey of Query Optimization in Large Language Models)
-
- 一、研究背景与总体框架
- 二、Expansion:查询扩展
-
- [2.1 内部扩展(Internal Expansion)](#2.1 内部扩展(Internal Expansion))
- [2.2 外部扩展(External Expansion)](#2.2 外部扩展(External Expansion))
- 三、Decomposition:查询分解
- 四、Disambiguation:查询消歧与重写
- 五、Abstraction:查询抽象
- 六、工程视角下的可执行建议
-
- [6.1 如何根据场景选用 QO 方法](#6.1 如何根据场景选用 QO 方法)
- [6.2 如何组合多类原子操作](#6.2 如何组合多类原子操作)
- 七、结语
A Survey of Query Optimization in Large Language Models
一、研究背景与总体框架
在RA中,用户原始查询往往并不适合直接拿去检索:可能太短、太模糊、结构太复杂,或隐含多步推理要求,结果是:
- 检索不到真正相关的证据;
- LLM 生成的答案缺乏支撑,出现幻觉或不完整。
因此,通常会有 Query Optimization(QO, 查询优化) 阶段,对用户问题就行优化,以检索到更相关的结果,得到更精准的答案。
找了一圈,发现关于查询优化的综述居然不多,只找到了一篇相对全面的:《A Survey of Query Optimization in Large Language Models》。作者将目前工作统一抽象为四类"原子操作":
- Expansion(扩展):补信息,让问题更"丰满";
- Decomposition(分解):拆问题,让复杂问题变成一组简单子问题;
- Disambiguation(消歧):澄清,让模糊、含糊的问题变清楚;
- Abstraction(抽象):升维,从更高层概念视角先想清楚,再回到细节。
下面按照这四类,对论文中提到的各项工作做系统、完整的梳理 :
每个工作统一给出:
- 要解决的问题:针对什么场景/痛点;
- 提出的方法:用几句话突出核心机制。
你可以直接把这份报告当作:
- 设计/改进 RAG 系统的"选型手册";
- 撰写自己综述或项目背景时的"方法目录"。
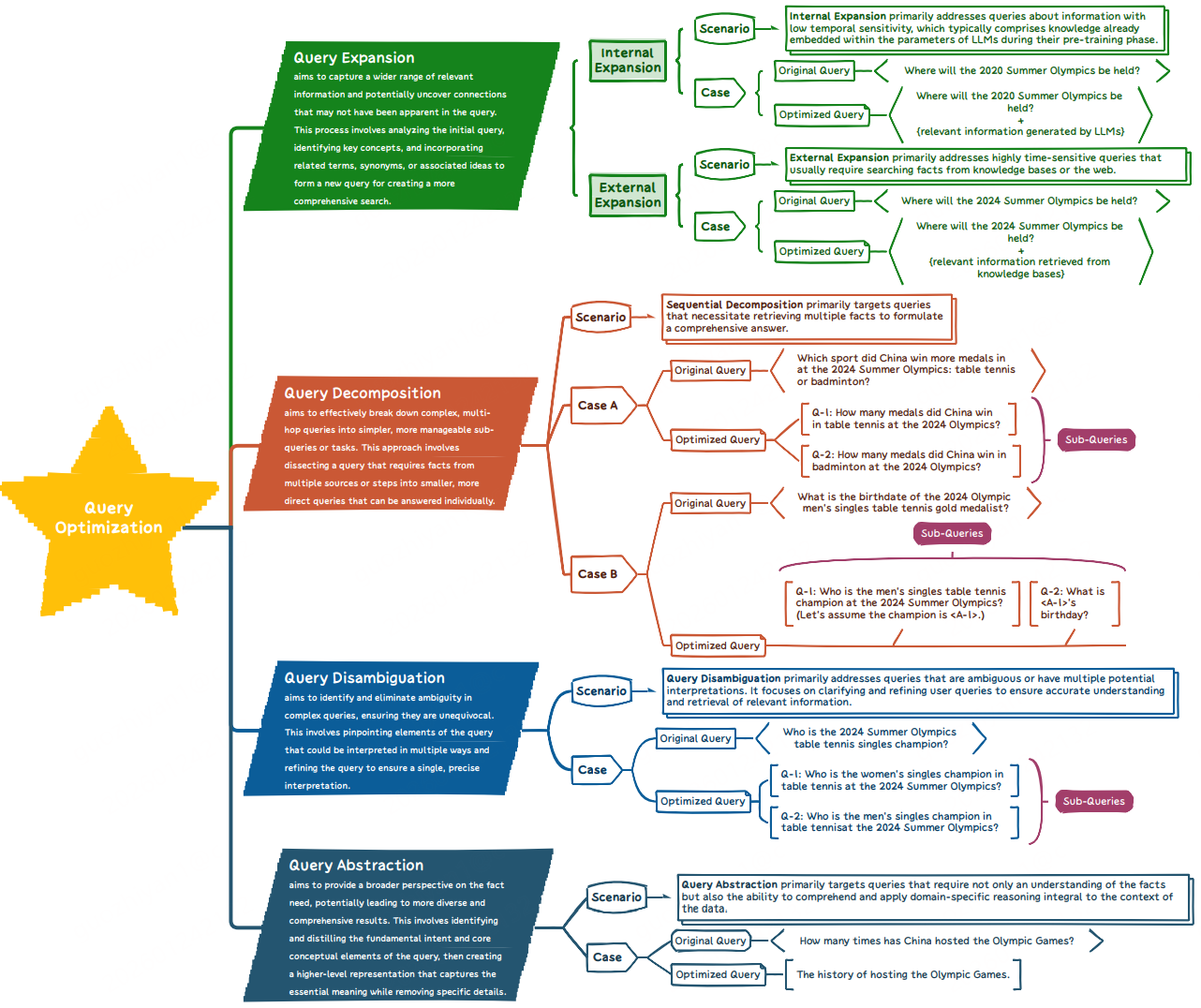
二、Expansion:查询扩展
2.1 内部扩展(Internal Expansion)
依赖 LLM 自身(及现有系统信息)来"把问题写长写好",不必额外访问外部知识库。
GENREAD(Yu et al., 2023a)
- 要解决的问题:原始查询太短、语境不足,检索到的文档难以支撑高质量回答。
- 方法核心:LLM 先根据 query 生成一篇"伪文档/上下文文档",再让模型在这篇文档基础上进行"阅读理解式"回答,相当于用 LLM 先自动补背景,再生成答案。
QUERY2DOC(Wang et al., 2023b)
- 问题:短 query 语义覆盖窄,容易漏掉相关概念与关联信息。
- 方法:"Query→Document",让 LLM 把短问题改写为长文档,作为新queery去检索,显著扩大语义覆盖。
HYDE(Gao et al., 2023a)
- 问题:短查询直接编码为向量,表示能力弱、检索效果差。
- 方法:先让 LLM 生成一个"假想答案文档",再用该文档的向量做检索。真实语料只会与假想文档中"合理部分"相似,从而间接过滤掉幻觉成分。
GQE(Bai et al., 2024)
- 问题:原始 query 显式关键词太少,相关文档召回不足。
- 方法:利用 LLM 生成更丰富的 扩展关键词集合,从而把查询映射到更宽的词汇空间,提高召回。
EQE(Zhang et al., 2023a)
- 问题:带公式或抽象描述的查询,用单一自然语言表述难以覆盖同义变体。
- 方法:生成一组 "等价查询表达"(equivalent queries),用不同自然语言或形式化风格表达同一问题,把"意思相同但写法不同"的查询全纳入检索。
FLARE(Jiang et al., 2023)
- 问题:一次性扩展不稳定,容易引入噪声。
- 方法:采用 "预测下一句 → 不确定片段当作新 query 再检索" 的迭代策略:当预测中出现低置信度 token,就以该片段为新查询进行检索。相当于当模型生成了自身不确定的内容时,就说明需要进行检索了。
INTER(Feng et al., 2024)
- 问题:检索模块与 LLM 生成模块之间交互不充分。
- 方法:让检索模型利用 LLM 生成的"知识集合"扩展 query,同时让 LLM 用检索结果 反过来改写 prompt,在"检索→扩展→生成"之间形成交互闭环。
EAR(Chuang et al., 2023)
- 问题:单一扩展 query 难以覆盖多种潜在检索路径。
- 方法:先生成一组 多样化候选扩展查询,再用 reranker 从中选出最有可能带来优质检索结果的版本。
CSQE(Lei et al., 2024)
- 问题:初次检索的文档中夹杂大量无关句子,直接拿来扩展会把噪声也带进 query。
- 方法:利用 LLM 对句子相关性打分,从初检文档中抽取 关键句子,再与 LLM 生成的扩展文本组合,构造更聚焦的扩展查询。
MUGI(Zhang et al., 2024b)
- 问题:传统稀疏/稠密检索无法充分利用"参考文本"。
- 方法:用 LLM 为每个 query 生成多条 伪参考(pseudo references),并将其与原始 query 结合输入给检索器,从而同时提升 sparse 与 dense 检索性能(既可视为内部生成,也能结合外部反馈)。
MILL(Jia et al., 2024)
- 问题:一次 query→document 的扩展难以覆盖多跳、多路径的推理需求。
- 方法:利用 LLM 的 zero‑shot 能力生成多条 子 query + 文档 ,并通过子 query 间、文档间的 相互验证 融合生成文档和检索文档,形成更高质量的扩展语境。
GENQRE NSEMBLE(Dhole & Agichtein, 2024)
- 问题:单一指令生成的关键词集多样性不足。
- 方法:用多种 paraphrase 的 zero‑shot 指令生成多组关键词,再做 ensemble 融合,提升关键词多样性与冗余度,增强检索覆盖率。
为啥感觉里面不少工作是利用了外部知识进行查询扩展的?
2.2 外部扩展(External Expansion)
这类方法显式依赖 搜索引擎、Web、数据库、知识库 等外部源,把外部知识整合进扩展 query。
KNOWLED GPT(Wang et al., 2023c)
- 问题:需要将外部知识与 LLM 内部知识统一注入查询表示。
- 方法:从外部知识源检索相关信息,让 LLM 把这些知识与原 query 融合,生成 "知识增强版"查询 用于后续检索与回答。
PROMPTAGATOR(Dai et al., 2023)
- 问题:手工设计利用外部数据的 prompt 成本高。
- 方法:自动从外部语料/搜索结果中抽取信息,让 LLM 自动生成对下游检索有用的扩展 query。
RARG(Yue et al., 2024)
- 问题:原始 query 难以一次性检索到所有潜在正确答案。
- 方法:先用原 query 检索一批 候选答案或中间实体,再把这些候选信息显式并入新的 query 做二次检索/推理,缩小搜索空间并提高命中率。
DRAGIN(Su et al., 2024)
- 问题:query 与文档分布存在差异。
- 方法:基于初次检索到的文档,让 LLM 对原 query 做 "文档驱动"的扩展改写,使新 query 更贴合真实语料语言分布。
EWEK‑QA(Dehghan et al., 2024)
- 问题:Web / 外部问答中存在大量未显式体现在 query 中的有用知识。
- 方法:从外部 Q&A 源获取与当前查询相关的问答对,将其中关键信息整合进扩展 query 中。
BLEND FILTER(Wang et al., 2024a)
- 问题:外部证据质量参差不齐,盲目扩展会引入噪声。
- 方法:对外部检索到的证据做 过滤 + 融合(blend),只保留高置信度部分与原 query 组合,构造更可靠的扩展查询。
REFEED(Yu et al., 2023b)
- 问题:单轮"生成→检索"无法及时纠正错误推断。
- 方法:先让 LLM 给出初始回答,再利用该回答去大规模语料库中检索支持/反驳证据,把这些证据 回馈(refeed)给 LLM,促使其修正回答并相应改写/扩展查询。
QUERY2EXPAND(Jagerman et al., 2023)
- 问题:短查询导致召回率低。
- 方法:用 LLM 自动把短 query 改写成更长、更信息密集的描述,增加同义词、上下文等,以提升召回。
DR‑RAG(Hei et al., 2024)
- 问题:标准 RAG 对相关文档覆盖不足。
- 方法:用初次检索到的文档内容驱动新的扩展查询,进行 document‑rich 的二次检索,提高整体 coverage。
COV‑RAG(He et al., 2024)
- 问题:在有限检索预算下,希望覆盖更多真正相关文档。
- 方法:从 "覆盖率(coverage)" 视角来设计扩展策略,使扩展后的 query 在文档空间覆盖更多潜在文档。
MUGI(Zhang et al., 2024b)
- 问题:同上,兼顾内部生成与外部反馈。
- 方法:利用 LLM 生成伪参考并结合外部检索结果,做多轮交互式扩展,提高多种检索器的性能。
LameR(Shen et al., 2024a)
- 问题:只基于原 query 检索,候选答案空间有限。
- 方法:先在目标集合上做一次标准检索获取 in‑domain 候选答案,再将"query + 候选答案"一起输入 LLM,由其生成信息更丰富的扩展查询或直接优化回答,相当于显式把潜在答案"写进"查询空间。
MILL(Jia et al., 2024)
- 问题:需要多轮 query--文档交互与互证。
- 方法:在外部扩展视角下,MILL 把多轮子 query+文档及其互相校验当成一种 基于真实语料的抽象与扩展。
三、Decomposition:查询分解
适用于:多跳问答、多实体对比、复杂逻辑需求等场景。共同特点:
先拆解,再分别检索与推理,最后合成答案。
DSP(Khattab et al., 2022)
- 问题:复杂问题难以用"一步检索+一步生成"搞定。
- 方法:构建 "示范(Demonstrate)→ 检索(Search)→ 预测(Predict)" 的流水线,在 LLM 与检索模型之间用自然语言传递中间态,将大问题拆成一系列小问题。
LEAST‑TO‑MOST(Zhou et al., 2023)
- 问题:模型不会自觉拆解组合推理问题。
- 方法:通过 few‑shot 示例教模型 "先拆成多步小题,再按顺序解",让 LLM 学会把复杂问题转成一串可解子问题。
PLAN‑AND‑SOLVE(Wang et al., 2023a)
- 问题:没有全局求解计划,容易局部乱走。
- 方法:先让 LLM 生成一份 整体任务计划,划分若干子任务,再按计划逐步执行并合成答案。
SELF‑ASK(Press et al., 2023)
- 问题:子问题能答对,但组合时常犯错(组合性缺口)。
- 方法:显式让模型 "自问自答子问题并组合",分析并缓解组合推理中的系统性错误。
COK(Li et al., 2024)
- 问题:多个推理链与答案之间缺乏一致性。
- 方法:先生成多条带推理过程的候选答案,识别知识区域,如无多数共识,就反复 修正这些推理链并补充新知识,直到形成可靠基础再输出最终答案。
ICAT(V et al., 2023)
- 问题:没有额外标注或微调条件下,如何让 LLM 学会分解。
- 方法:通过对现有任务数据的 精挑与重组,把分解模式迁移给 LLM,无需新增标注。
REACT(Yao et al., 2023)
- 问题:既要推理,又要调用外部工具。
- 方法:统一框架下生成 语言推理轨迹(Reason)+ 工具调用动作(Act),形成"为行动而推理/为推理而行动"的循环。
AUTOPRM(Chen et al., 2024)
- 问题:分解太粗效率低,太细子问题爆炸。
- 方法:用可控粒度把复杂问题拆成子 query,并通过强化学习反复优化 "拆多细、怎么解" 的策略。
RA‑ISF(Liu et al., 2024)
- 问题:多轮、多子查询场景下噪声 prompt 太多。
- 方法:将多轮对话拆成独立单轮子 query,以迭代方式解决,并利用文本相关性和模型自知识过滤无关信息。
LPKG(Wang et al., 2024b)
- 问题:LLM 在规划查询时忽视结构化知识图谱。
- 方法:在开放域知识图谱中定义 模式(pattern),把它们实例化为复杂 query 与相应子 query,来指导 LLM 的查询规划与分解。
ALTER(Zhang et al., 2024a)
- 问题:表格推理问题中,单一 query 混合了多个隐含子问题。
- 方法:设计 question augmentor 为原问题生成一组子 queries,从多个角度审视表格数据。
IM‑RAG(Yang et al., 2024)
- 问题:检索模块与推理模块能力不匹配。
- 方法:在二者之间引入 Refiner,对检索结果做再加工,使之与推理需要更匹配。
REAPER(Joshi et al., 2024)
- 问题:复杂查询需要明确规划工具调用顺序。
- 方法:使用小型 LLM 作为 planner,预先生成工具调用计划(含顺序与参数)来执行多步检索+推理。
HIRAG(Zhang et al., 2024d)
- 问题:多跳查询需要跨多轮检索聚合证据。
- 方法:把原 query 分解为一系列多跳子 query,对每个子 query 检索并解答,再通过 CoT 将子答案融合。
MQA‑KEAL(Ali et al., 2024)
- 问题:知识编辑后,如何在多跳场景可靠利用新知识。
- 方法:将知识编辑存入外部记忆,在解多跳 query 时分解子任务,并在每个子任务上查询外部记忆+目标 LLM,迭代生成最终答案。
RICHRAG(Wang et al., 2024c)
- 问题:复杂 query 含多隐含方面,普通检索覆盖不全。
- 方法:用 子方面探索器 挖掘 query 的各个 facet,并对每个 facet 构建独立外部子语料检索,最终合并各 facet 证据。
CONTREGEN(Roy et al., 2024)
- 问题:希望在多个方面上既"查得深"又"整合得好"。
- 方法:采用 树结构检索:上层探索不同 facet,下层深入每条分支,自底向上合并信息。
PLAN×RAG(Verma et al., 2024)
- 问题:子 query 间的中间结果难以共享复用。
- 方法:将推理过程表示为 有向无环图(DAG),节点为原子子 query,边是依赖关系,使子 query 可以共享中间结论。
RAG‑Star(Jiang et al., 2024)
- 问题:需要在"内知识+检索证据"基础上做树式推理搜索。
- 方法:采用 蒙特卡洛树搜索(MCTS) 对中间子 query 进行规划,在每个节点结合检索与 LLM 做决策,寻找全局最优推理树。
四、Disambiguation:查询消歧与重写
主要针对:多轮对话、省略、代词指代、语义多义、歧义等问题。
RSTAR(Qi et al., 2024)
- 问题:模糊 query 引导检索走错方向。
- 方法:通过 检索--生成--再检索 闭环,用新获得的信息不断修正最初理解。
RQ‑RAG(Chan et al., 2024)
- 问题:不知道哪种改写最利于检索。
- 方法:生成多种 rewrite,并结合检索表现(例如召回的高质量文档、答案可获取性)选出效果最好的重写。
RAFE(Mao et al., 2024)
- 问题:多轮对话场景下忽略历史语境会导致 query 歧义。
- 方法:显式整合历史对话,对当前 query 做 上下文补全式重写,生成自包含问题。
TOC(Kim et al., 2023)
- 问题:一个模糊 query 可能有多种解释。
- 方法:用 few‑shot +外部知识递归构建 "歧义树",每个节点是一种解释,并分别检索支持事实,最后给出覆盖多解释的长文本回答。
BEQUE(Peng et al., 2024b)
- 问题:对话中的代词、省略让当前 query 脱离上下文无法理解。
- 方法:基于对话历史重写当前 query,将指代与省略信息显式补入,使之可独立用于检索。
ADAQR(Zhang et al., 2024c)
- 问题:通用 rewrites 没考虑"检索器偏好"。
- 方法:令 rewrite 模型生成多个候选,用目标检索器评估每个重写使答案可被检索到的条件概率,再用 DPO 等方法学习更符合检索器偏好的重写策略。
CHIQ(Mo et al., 2024)
- 问题:未解析的指代严重影响检索。
- 方法:利用 LLM 对对话历史做 指代消解 + 上下文扩展,得到更明确的搜索 query,可在线使用或用作监督信号微调重写模型。
ECHOPROMPT(Mekala et al., 2024)
- 问题:模型对问题理解不到位导致推理跑偏。
- 方法:在 prompt 中指示模型先 用自己的话重复/改述 query 再展开推理,提升理解一致性。
MAFERW(Wang et al., 2024e)
- 问题:重写策略缺乏系统性的反馈信号。
- 方法:从检索结果与生成回答两个方面提取 多维反馈作为奖励,用来探索和优化重写策略,从而提升整体 RAG 性能。
INFOCQR(Ye et al., 2023)
- 问题:一次性重写仍残留歧义。
- 方法:设计 "rewrite‑then‑edit" 两阶段流水线:先做一次重写,再对重写结果进行编辑和校正,逐步去除残余歧义。
NATURAL‑PROGRAM(Ling et al., 2023)
- 问题:整体推理过程不透明,错误无法细粒度定位。
- 方法:把推理拆成一系列 小步自然语言子过程,每步只依赖必要前提,逐步生成与自检,构建可验证的推理链,有利于在消歧时做更可靠判断。
五、Abstraction:查询抽象
适用于:历史统计、归纳总结、规则/图谱推理等,需要先从高层概念视角考虑,再落到具体证据。
STEPBACK(Zheng et al., 2024)
- 问题:直接在细节层面做复杂推理容易中途犯错。
- 方法:通过 prompt 引导模型先 "退一步"在高层抽象层面推理,再把这些抽象结论应用回具体问题,提高稳定性。
CONCEPTUALIZATION‑ABSTRACTION(Zhou et al., 2024)
- 问题:概念性强的问题难以直接验证。
- 方法:要求 LLM 用 抽象 query 进行概念化推理,并在可验证的符号空间给出解答,从抽象层面提高正确性。
COA(Gao et al., 2024)
- 问题:普通 CoT 太贴细节,不利于与工具交互。
- 方法:把推理过程抽象为带 "抽象变量链" 的思路,用这些变量去调用工具(计算器、搜索等),再结合具体信息解决问题。
AOT(Hong et al., 2024)
- 问题:传统 CoT 中抽象与细节混杂。
- 方法:提出 "抽象骨架框架",显式区分多层抽象:上层是下层的压缩版,只保留目标与核心结构。
CRAFTING‑THE‑PATH(Baek et al., 2024)
- 问题:原 query 对目标对象的描述缺乏宏观背景。
- 方法:为现有 query 生成更高层次的 抽象背景信息,作为额外语境来支持检索和推理。
MA‑RIR(Korikov et al., 2024)
- 问题:多方面 query 把多个主题混在一个句子里。
- 方法:把 query 划分为若干 aspect,分别进行推理后再综合,实质上是一种面向多个抽象维度的分解。
META‑REASONING(Wang et al., 2024d)
- 问题:实体与操作语义复杂多样,难以统一抽象。
- 方法:把 query 中的实体与操作解构为一套 通用符号表示,让 LLM 在符号层学习跨任务抽象推理模式。
RULERAG(Anonymous, 2024)
- 问题:RAG 缺乏显式逻辑规则,会检索到"形式相关但逻辑不支撑"的文档。
- 方法:用 逻辑规则 指导检索,只保留在规则方向上逻辑支撑 query 的文档,再基于这些文档+规则联合生成答案。
SIMGRAG(Cai et al., 2024)
- 问题:自然语言 query 与知识图谱结构难以直接对齐。
- 方法:两阶段:先将自然语言 query 映射为 图模式(pattern),再用图语义距离度量 pattern 与候选子图的贴合程度,选中最佳子图。
ABSINSTRUCT(Wang et al., 2024f)
- 问题:缺乏统一的抽象级别指令来指导 LLM。
- 方法:定义一组 抽象化指令模板,引导模型在更高概念层面分析与求解问题。
ABSPYRAMID(Wang et al., 2024g)
- 问题:单级抽象不足以支持多步复杂推理。
- 方法:构建 "金字塔式"多级抽象结构,从高层逐级向下細化,方便在不同粒度间切换推理。
MILL(Jia et al., 2024)
- 问题:一次性 query→document 扩展覆盖不了所有潜在推理路径。
- 方法:采用 "query--query--document" 的多步生成,通过多个子 query 与文档的相互验证,在不同抽象层次上综合信息,得到更稳健的扩展与推理基础。
ERRR(Cong et al., 2024)
- 问题:LLM 中的参数化知识难以显式抽出并用来精确优化查询。
- 方法:从 LLM 中 抽取与 query 相关的参数化知识,再通过专门的查询优化器对其精炼,只保留与答案最关键的部分,用于更准确的检索和回答。
六、工程视角下的可执行建议
6.1 如何根据场景选用 QO 方法
-
用户问题太短、信息不足
- 优先考虑:HYDE、GENREAD、QUERY2DOC、GQE、EQE、MUGI、MILL 等扩展方法。
- 若有外部搜索/知识库:再结合 KNOWLED GPT、PROMPTAGATOR、DR‑RAG、COV‑RAG 等。
-
问题结构复杂、多跳、多目标
- 采用分解类:LEAST‑TO‑MOST、PLAN‑AND‑SOLVE、DSP、PLAN×RAG、RAG‑Star、RICHRAG、CONTREGEN 等。
- 如果任务涉及工具链或知识图谱:优先看 REACT、LPKG、REAPER。
-
多轮对话、指代、省略、歧义严重
- 必须引入消歧/重写模块:BEQUE、CHIQ、INFOCQR、RAFE、ADAQR、RQ‑RAG、MAFERW、ECHOPROMPT。
- 有严格质量要求时,可用 NATURAL‑PROGRAM 来把推理过程拆成可检查的小步。
-
需要历史统计、规则推理、知识图谱推理
- 建议组合抽象类方法:STEPBACK、COA、AOT、RULERAG、SIMGRAG、META‑REASONING、ABSINSTRUCT、ABSPYRAMID 等。
- 若需从 LLM 内部挖"隐性规则":可以引入 ERRR 做参数化知识抽取与精炼。
6.2 如何组合多类原子操作
真实应用往往需要多种原子操作串联,例如:
-
对话式 RAG 助手:
1)先 Disambiguation (BEQUE/CHIQ 重写当前轮);
2)再 Expansion (HYDE/MUGI 扩展信息);
3)遇到复杂任务时 Decomposition (LEAST‑TO‑MOST/PLAN×RAG 拆子问题);
4)最终回答前做一次 Abstraction(STEPBACK 总结与反思)。
-
复杂企业搜索/分析系统:
- 用 Expansion 增强召回;
- 用 Decomposition 显式规划多步查询;
- 用 Abstraction 在决策层给出可解释、高层的结论。
七、结语
这篇综述的核心价值在于:
把原本分散在不同任务中的各种"问好问题"的技巧,统一映射到了四种可组合的原子操作之上。
对实践者来说,可以直接把这四类"查询优化原子操作"当作一套 工程工具箱:
- 根据问题类型先判断需要哪几类操作;
- 在每一类下,从本报告罗列的工作中挑选满足你 场景、延迟、成本、可解释性 约束的具体方法;
- 再把这些方法组合成属于你业务的 Query Optimization 流水线。
这样设计出来的 RAG/LLM 系统,往往在 检索覆盖度、答案准确性、鲁棒性 上,都比"原始 query + 一次检索 + 一次生成"的 naïve 方案有质的提升。
